Tris efficaces#
Les tris élémentaires du chapitre précédent souffrent tous d’une même limite : une complexité \(\Theta(n^2)\) dans le cas moyen et le pire cas. Pour \(n = 10^6\) éléments, cela représente \(10^{12}\) opérations — rédhibitoire. Les tris efficaces surmontent cet obstacle en atteignant la complexité \(O(n \log n)\), qui est également la borne inférieure optimale pour tout tri par comparaison.
Ce chapitre étudie les trois grands tris efficaces : le tri fusion (diviser-pour-régner, stable, garanti en \(O(n \log n)\)), le tri rapide (en place, très performant en pratique malgré un pire cas \(O(n^2)\)), et le tri par tas (en place, garanti en \(O(n \log n)\)). Nous démontrerons ensuite que \(\Omega(n \log n)\) est une borne inférieure infranchissable pour les tris par comparaison, et analyserons Timsort, l’algorithme sophistiqué utilisé par Python.
La borne inférieure \(\Omega(n \log n)\)#
Avant d’étudier les algorithmes, il est éclairant de comprendre pourquoi l’on ne peut pas trier plus vite que \(O(n \log n)\) par comparaison.
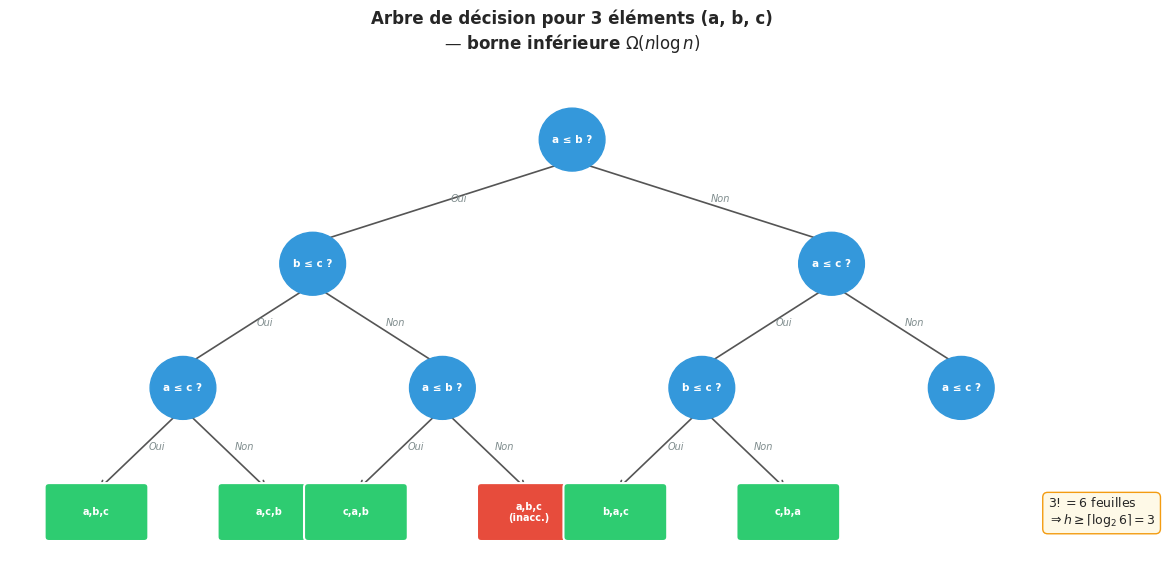
Borne inférieure des tris par comparaison
Un tri par comparaison est un algorithme de tri dont les seules opérations autorisées sur les éléments sont des comparaisons deux à deux. On peut modéliser tout tel algorithme par un arbre de décision : un arbre binaire dont chaque nœud interne représente une comparaison \(A[i] \leq A[j]\) (branche gauche si vrai, droite si faux), et dont chaque feuille représente une permutation résultante.
Un arbre de décision pour \(n\) éléments doit avoir au moins \(n!\) feuilles (une par permutation possible). La hauteur minimale d’un arbre binaire à \(n!\) feuilles est \(\lceil \log_2(n!) \rceil\). Par la formule de Stirling, \(\log_2(n!) = \Theta(n \log n)\).
Donc, tout tri par comparaison nécessite \(\Omega(n \log n)\) comparaisons dans le pire cas.
Note
Ce résultat est fondamental : il signifie que le tri fusion et le tri par tas, qui atteignent \(O(n \log n)\), sont optimaux asymptotiquement pour les tris par comparaison. Il est impossible d’aller plus vite en utilisant seulement des comparaisons.
Cependant, si l’on dispose d’informations supplémentaires sur les clés (elles sont des entiers bornés, des chaînes courtes…), des algorithmes comme le tri par base ou le tri par dénombrement peuvent trier en \(O(n)\) — ils ne sont pas des tris par comparaison et échappent donc à cette borne.
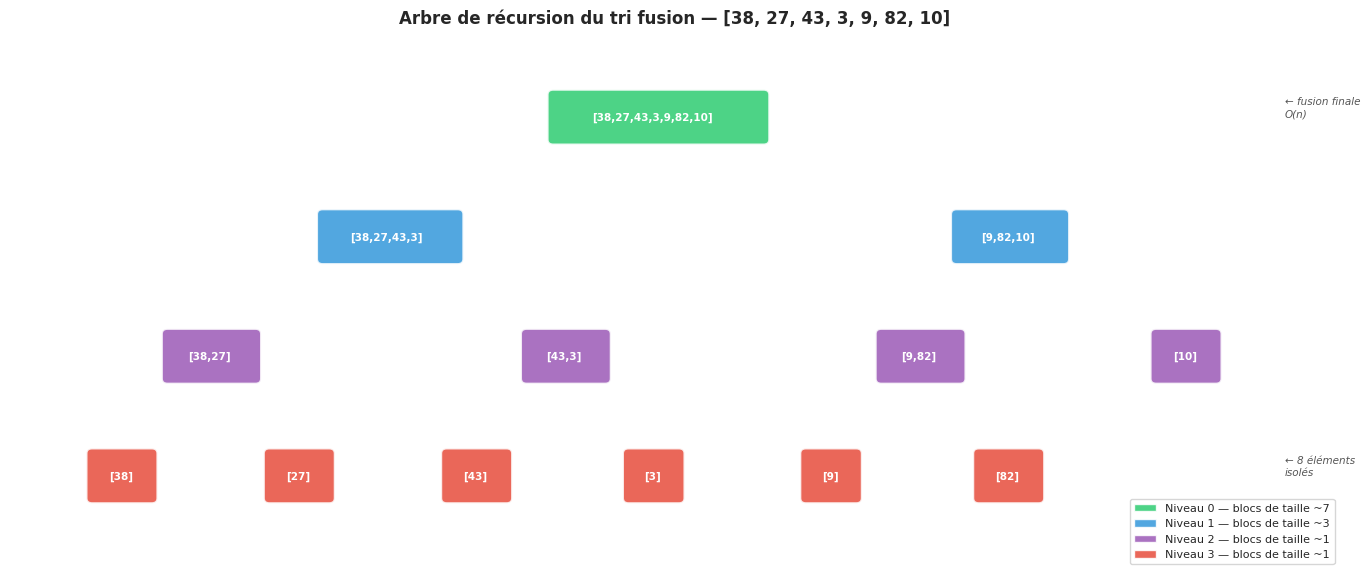
Tri fusion (Merge Sort)#
Principe diviser-pour-régner#
Le tri fusion est un algorithme classique de type diviser-pour-régner (divide and conquer) :
Diviser : couper le tableau en deux moitiés.
Régner : trier récursivement chaque moitié.
Combiner : fusionner les deux moitiés triées en une séquence triée.
La puissance de cette approche vient de la phase de fusion : fusionner deux séquences triées de taille \(n/2\) prend \(O(n)\), et la récursion s’effectue sur \(\log n\) niveaux.
Tri fusion
Complexité :
Pire cas, meilleur cas, cas moyen : \(\Theta(n \log n)\).
Espace auxiliaire : \(O(n)\) (nécessite un tableau temporaire pour la fusion).
Stable : oui.
Adaptatif : non (dans la version classique).
La récurrence de complexité est \(T(n) = 2T(n/2) + \Theta(n)\). Par le théorème maître (cas 2 avec \(a = 2\), \(b = 2\), \(f(n) = n\)), la solution est \(T(n) = \Theta(n \log n)\).
def fusionner(A, debut, milieu, fin):
"""
Fusionne les sous-tableaux triés A[debut..milieu] et A[milieu+1..fin].
Modifie A en place. Utilise O(n) espace auxiliaire.
"""
gauche = A[debut:milieu + 1]
droit = A[milieu + 1:fin + 1]
i = j = 0
k = debut
while i < len(gauche) and j < len(droit):
if gauche[i] <= droit[j]: # ≤ garantit la stabilité
A[k] = gauche[i]
i += 1
else:
A[k] = droit[j]
j += 1
k += 1
while i < len(gauche):
A[k] = gauche[i]
i += 1
k += 1
while j < len(droit):
A[k] = droit[j]
j += 1
k += 1
def tri_fusion_rec(A, debut=0, fin=None):
"""Tri fusion récursif. O(n log n) temps, O(n) espace."""
if fin is None:
fin = len(A) - 1
if debut < fin:
milieu = (debut + fin) // 2
tri_fusion_rec(A, debut, milieu)
tri_fusion_rec(A, milieu + 1, fin)
fusionner(A, debut, milieu, fin)
def tri_fusion(arr):
"""Interface publique : trie une copie de arr."""
A = arr.copy()
tri_fusion_rec(A)
return A
# Version itérative (bottom-up) — sans récursion
def tri_fusion_iteratif(arr):
"""
Tri fusion ascendant (bottom-up). Même complexité, sans pile d'appels.
Fusionne d'abord des blocs de taille 1, puis 2, 4, 8…
"""
A = arr.copy()
n = len(A)
taille = 1 # taille des blocs à fusionner
while taille < n:
for debut in range(0, n, 2 * taille):
milieu = min(debut + taille - 1, n - 1)
fin = min(debut + 2 * taille - 1, n - 1)
if milieu < fin:
fusionner(A, debut, milieu, fin)
taille *= 2
return A
# Démonstration
A_test = [38, 27, 43, 3, 9, 82, 10]
print(f"Entrée : {A_test}")
print(f"Tri fusion récursif : {tri_fusion(A_test)}")
print(f"Tri fusion itératif : {tri_fusion_iteratif(A_test)}")
print(f"Stabilité (vérification): {tri_fusion([3, 1, 4, 1, 5, 9, 2, 6, 5])}")
Entrée : [38, 27, 43, 3, 9, 82, 10]
Tri fusion récursif : [3, 9, 10, 27, 38, 43, 82]
Tri fusion itératif : [3, 9, 10, 27, 38, 43, 82]
Stabilité (vérification): [1, 1, 2, 3, 4, 5, 5, 6, 9]
Tri rapide (Quicksort)#
Principe#
Le tri rapide est également un algorithme diviser-pour-régner, mais son approche est différente : le travail est fait avant la récursion (lors du partitionnement), et la phase de combinaison est triviale.
Tri rapide
Choisir un pivot \(p\) dans le tableau.
Partitionner le tableau en deux parties : les éléments \(\leq p\) à gauche, les éléments \(\geq p\) à droite.
Trier récursivement les deux parties.
Complexité :
Cas moyen : \(\Theta(n \log n)\) (avec un pivot aléatoire).
Pire cas : \(\Theta(n^2)\) (pivot toujours minimal ou maximal, tableau déjà trié si pivot = premier élément).
Espace auxiliaire : \(O(\log n)\) en moyenne (profondeur de la pile de récursion).
Stable : non.
En place : oui (hors pile de récursion).
Partitionnement de Lomuto#
def partition_lomuto(A, bas, haut):
"""
Partitionnement de Lomuto : pivot = A[haut].
Place le pivot à sa position finale et retourne son indice.
O(haut - bas) temps.
"""
pivot = A[haut]
i = bas - 1 # indice du dernier élément ≤ pivot
for j in range(bas, haut):
if A[j] <= pivot:
i += 1
A[i], A[j] = A[j], A[i]
# Placer le pivot à sa position finale
A[i + 1], A[haut] = A[haut], A[i + 1]
return i + 1
def tri_rapide_lomuto(A, bas=0, haut=None):
"""Tri rapide avec partitionnement de Lomuto. Non stable, en place."""
if haut is None:
haut = len(A) - 1
if bas < haut:
p = partition_lomuto(A, bas, haut)
tri_rapide_lomuto(A, bas, p - 1)
tri_rapide_lomuto(A, p + 1, haut)
# Test
A = [10, 7, 8, 9, 1, 5]
tri_rapide_lomuto(A)
print("Lomuto :", A)
Lomuto : [1, 5, 7, 8, 9, 10]
Partitionnement de Hoare#
def partition_hoare(A, bas, haut):
"""
Partitionnement de Hoare : pivot = A[bas].
Deux indices convergent vers le centre. Moins d'échanges que Lomuto.
Retourne l'indice de séparation (pas nécessairement la position finale du pivot).
"""
pivot = A[bas]
i = bas - 1
j = haut + 1
while True:
i += 1
while A[i] < pivot:
i += 1
j -= 1
while A[j] > pivot:
j -= 1
if i >= j:
return j
A[i], A[j] = A[j], A[i]
def tri_rapide_hoare(A, bas=0, haut=None):
"""Tri rapide avec partitionnement de Hoare."""
if haut is None:
haut = len(A) - 1
if bas < haut:
p = partition_hoare(A, bas, haut)
tri_rapide_hoare(A, bas, p)
tri_rapide_hoare(A, p + 1, haut)
# Test
A = [10, 7, 8, 9, 1, 5]
tri_rapide_hoare(A)
print("Hoare :", A)
Hoare : [1, 5, 7, 8, 9, 10]
Choix du pivot#
Note
Le choix du pivot est crucial pour la performance du tri rapide :
Premier élément : simple mais désastreux sur tableau trié ou inversé — \(O(n^2)\).
Élément aléatoire : en pratique excellent. Le pire cas a une probabilité \(O(1/n!)\) de se produire pour un tri aléatoire.
Médiane de trois : on prend la médiane parmi le premier, le milieu et le dernier élément. Excellent en pratique, réduit la probabilité du pire cas et fonctionne bien sur les entrées partiellement triées.
Médiane des médianes : garantit un partitionnement en \(n/4\) et \(3n/4\), donc \(O(n \log n)\) garanti, mais la constante est trop grande pour être utile en pratique.
def mediane_de_trois(A, bas, haut):
"""Retourne l'indice de la médiane parmi A[bas], A[milieu], A[haut]."""
milieu = (bas + haut) // 2
# Trier les trois pour que A[milieu] soit la médiane
if A[bas] > A[milieu]:
A[bas], A[milieu] = A[milieu], A[bas]
if A[bas] > A[haut]:
A[bas], A[haut] = A[haut], A[bas]
if A[milieu] > A[haut]:
A[milieu], A[haut] = A[haut], A[milieu]
# Placer la médiane juste avant haut (position du pivot pour Lomuto)
A[milieu], A[haut - 1] = A[haut - 1], A[milieu]
return haut - 1
def tri_rapide_median3(arr):
"""
Tri rapide avec médiane de trois + partitionnement de Lomuto.
Bonne performance sur données triées, inversées, ou avec doublons.
"""
A = arr.copy()
def quicksort(bas, haut):
if haut - bas < 2:
# Cas de base : 0, 1 ou 2 éléments
if haut > bas and A[bas] > A[haut]:
A[bas], A[haut] = A[haut], A[bas]
return
pivot_idx = mediane_de_trois(A, bas, haut)
p = partition_lomuto(A, bas, haut)
quicksort(bas, p - 1)
quicksort(p + 1, haut)
quicksort(0, len(A) - 1)
return A
# Test
A_test = [3, 6, 8, 10, 1, 2, 1]
print("Médiane de trois :", tri_rapide_median3(A_test))
# Pivot aléatoire
def tri_rapide_aleatoire(arr):
"""Tri rapide avec pivot aléatoire. O(n log n) en moyenne."""
A = arr.copy()
def quicksort(bas, haut):
if bas < haut:
# Pivot aléatoire : échanger avec haut avant Lomuto
pivot_idx = random.randint(bas, haut)
A[pivot_idx], A[haut] = A[haut], A[pivot_idx]
p = partition_lomuto(A, bas, haut)
quicksort(bas, p - 1)
quicksort(p + 1, haut)
quicksort(0, len(A) - 1)
return A
print("Pivot aléatoire :", tri_rapide_aleatoire([5, 3, 8, 1, 9, 2, 7]))
Médiane de trois : [1, 1, 2, 3, 6, 8, 10]
Pivot aléatoire : [1, 2, 3, 5, 7, 8, 9]
Tri par tas (Heapsort)#
Le tri par tas exploite la structure de tas-max présentée au chapitre 6 pour trier un tableau en place et en \(O(n \log n)\) garanti.
Tri par tas
Le tri par tas procède en deux phases :
Phase 1 — Construction du tas. Transformer le tableau en un tas-max par l’algorithme de Floyd (heapify) en \(O(n)\).
Phase 2 — Extraction successive. Répéter \(n - 1\) fois : échanger le maximum (racine \(A[0]\)) avec le dernier élément non extrait, puis rétablir la propriété de tas par percolation vers le bas en \(O(\log n)\).
Complexité : \(\Theta(n \log n)\) dans tous les cas. En place : oui. Stable : non.
def percoler_bas(A, i, n):
"""
Rétablit la propriété de tas-max pour le nœud i dans A[0..n-1].
O(log n).
"""
plus_grand = i
g = 2 * i + 1 # fils gauche
d = 2 * i + 2 # fils droit
if g < n and A[g] > A[plus_grand]:
plus_grand = g
if d < n and A[d] > A[plus_grand]:
plus_grand = d
if plus_grand != i:
A[i], A[plus_grand] = A[plus_grand], A[i]
percoler_bas(A, plus_grand, n)
def construire_tas(A):
"""
Construit un tas-max à partir du tableau A par l'algorithme de Floyd.
O(n) — contre-intuitif mais prouvable.
"""
n = len(A)
# Partir du dernier nœud interne et percoler vers le bas
for i in range(n // 2 - 1, -1, -1):
percoler_bas(A, i, n)
def tri_tas(arr):
"""Tri par tas. O(n log n) garanti, en place, non stable."""
A = arr.copy()
n = len(A)
# Phase 1 : construction du tas en O(n)
construire_tas(A)
# Phase 2 : extraction successive en O(n log n)
for i in range(n - 1, 0, -1):
A[0], A[i] = A[i], A[0] # le max va en position i
percoler_bas(A, 0, i) # rétablir le tas sur A[0..i-1]
return A
# Démonstration
A_test = [4, 10, 3, 5, 1, 8, 2, 9, 7, 6]
print(f"Entrée : {A_test}")
resultat = tri_tas(A_test)
print(f"Tri tas : {resultat}")
# Vérification de la phase de construction
A_heapify = A_test.copy()
construire_tas(A_heapify)
print(f"Après heapify : {A_heapify} (A[0]={A_heapify[0]} est le max)")
Entrée : [4, 10, 3, 5, 1, 8, 2, 9, 7, 6]
Tri tas : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Après heapify : [10, 9, 8, 7, 6, 3, 2, 5, 4, 1] (A[0]=10 est le max)
Note
Pourquoi la construction du tas est-elle \(O(n)\) et non \(O(n \log n)\) ?
On part du dernier nœud interne (indice \(\lfloor n/2 \rfloor - 1\)) et on descend jusqu’à la racine. La percolation vers le bas d’un nœud de hauteur \(h\) coûte au plus \(h\) échanges. Le nombre de nœuds de hauteur \(h\) est au plus \(\lceil n / 2^{h+1} \rceil\). Le coût total est donc : $\(\sum_{h=0}^{\lfloor \log n \rfloor} \left\lceil \frac{n}{2^{h+1}} \right\rceil \cdot O(h) = O\!\left(n \sum_{h=0}^{\infty} \frac{h}{2^h}\right) = O(n \cdot 2) = O(n)\)\( car \)\sum_{h=0}^{\infty} h / 2^h = 2$.
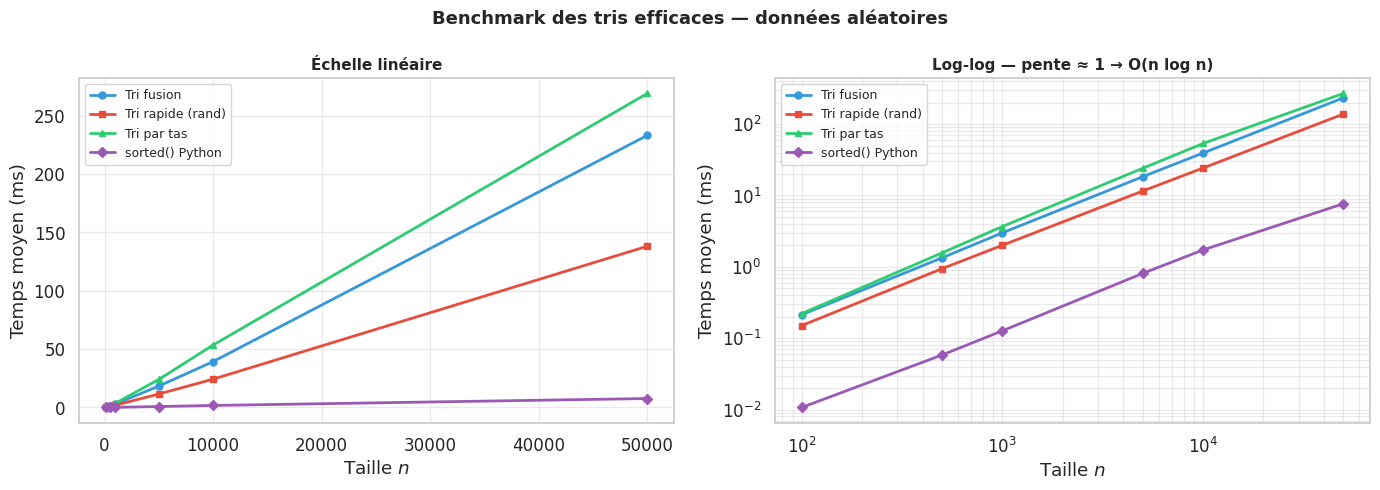
sorted() et list.sort() Python : Timsort#
Python utilise Timsort, un algorithme hybride conçu par Tim Peters en 2002. C’est l’un des algorithmes de tri les plus sophistiqués qui soient, et il est maintenant utilisé dans Java (Arrays.sort pour les objets), GNU Octave, Swift, et d’autres.
Timsort
Timsort est un tri hybride qui combine le tri par insertion (pour les petits blocs) et le tri fusion (pour combiner les blocs). Ses caractéristiques clés :
Runs naturels : il détecte les séquences déjà ordonnées (runs) dans le tableau. Si un run est décroissant, il le renverse pour le rendre croissant. Les runs ont une longueur minimale
minrun(entre 32 et 64 éléments), calculée de façon à ce que le tri-fusion se comporte de façon optimale.Tri par insertion des petits runs : si un run est plus court que
minrun, on l’allonge et on le trie par insertion.Fusion contrôlée : Timsort maintient une pile de runs et les fusionne de façon à toujours avoir des runs de tailles comparables (invariant de pile), garantissant \(O(n \log n)\) dans le pire cas.
Galloping mode : lors des fusions, si un tableau « gagne » de nombreuses comparaisons consécutives, Timsort passe en mode exponentiel pour chercher la position d’insertion, réduisant le nombre de comparaisons sur les données partiellement ordonnées.
Complexité : \(\Theta(n \log n)\) pire cas, \(\Theta(n)\) sur données déjà triées. Stable : oui.
# Démonstration de l'efficacité de Timsort sur données partiellement ordonnées
import timeit
def generer_partiellement_trie(n, k):
"""Génère un tableau de n éléments avec k inversions aléatoires."""
arr = list(range(n))
for _ in range(k):
i, j = random.randint(0, n-1), random.randint(0, n-1)
arr[i], arr[j] = arr[j], arr[i]
return arr
n = 10_000
reps = 20
# Comparaison sur différents niveaux de désordre
niveaux_desordre = {
'Trié (0 inversions)': generer_partiellement_trie(n, 0),
'Quasi-trié (100 inv.)': generer_partiellement_trie(n, 100),
'Modérément désordonné': generer_partiellement_trie(n, 1000),
'Aléatoire': [random.randint(0, 10*n) for _ in range(n)],
}
print(f"{'Niveau de désordre':<35} {'Timsort (ms)':<18} {'Tri fusion (ms)':<18} {'Tri tas (ms)'}")
print('-' * 90)
for desc, data in niveaux_desordre.items():
t_tim = timeit.timeit(lambda d=data: sorted(d), number=reps) / reps * 1000
t_fus = timeit.timeit(lambda d=data: tri_fusion(d), number=reps) / reps * 1000
t_tas = timeit.timeit(lambda d=data: tri_tas(d), number=reps) / reps * 1000
print(f"{desc:<35} {t_tim:<18.3f} {t_fus:<18.3f} {t_tas:.3f}")
Niveau de désordre Timsort (ms) Tri fusion (ms) Tri tas (ms)
------------------------------------------------------------------------------------------
Trié (0 inversions) 0.064 32.792 57.177
Quasi-trié (100 inv.) 0.242 38.937 57.758
Modérément désordonné 0.892 37.998 57.080
Aléatoire 1.718 39.708 54.102
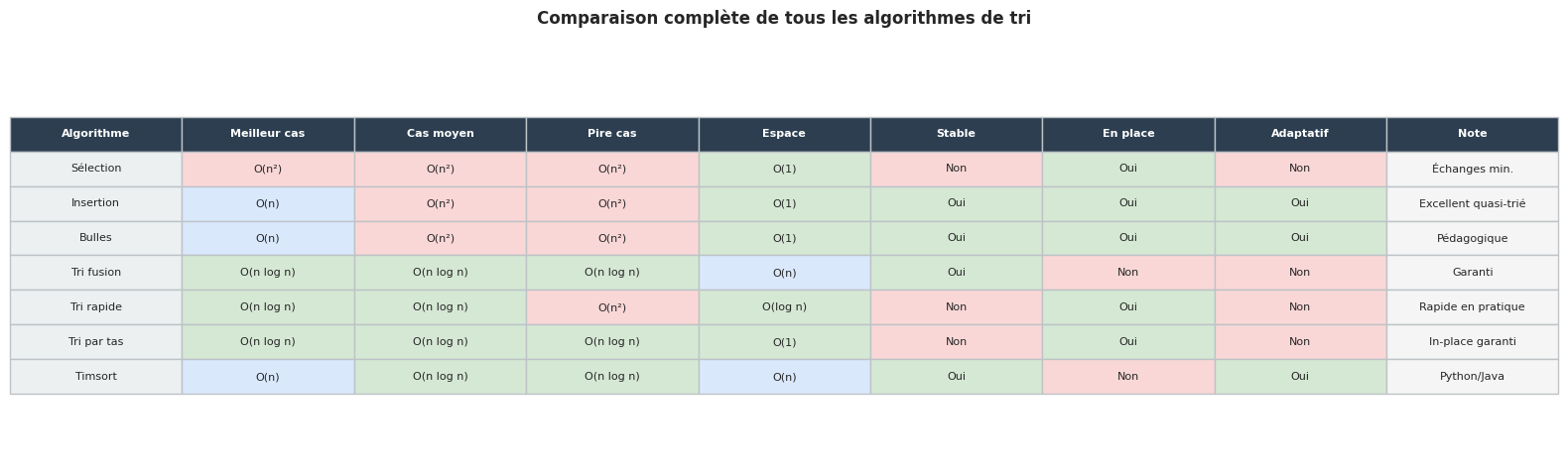
Comparaison complète#
Implémentation Rust#
/// Tri fusion générique. Stable, O(n log n), O(n) espace.
fn tri_fusion<T: Ord + Clone>(arr: &mut Vec<T>) {
let n = arr.len();
if n <= 1 { return; }
let milieu = n / 2;
let mut gauche = arr[..milieu].to_vec();
let mut droit = arr[milieu..].to_vec();
tri_fusion(&mut gauche);
tri_fusion(&mut droit);
// Fusion
let (mut i, mut j, mut k) = (0, 0, 0);
while i < gauche.len() && j < droit.len() {
if gauche[i] <= droit[j] {
arr[k] = gauche[i].clone();
i += 1;
} else {
arr[k] = droit[j].clone();
j += 1;
}
k += 1;
}
while i < gauche.len() { arr[k] = gauche[i].clone(); i += 1; k += 1; }
while j < droit.len() { arr[k] = droit[j].clone(); j += 1; k += 1; }
}
/// Tri rapide avec pivot aléatoire. O(n log n) moyen, en place.
fn tri_rapide<T: Ord>(arr: &mut [T]) {
if arr.len() <= 1 { return; }
// Pivot = dernier élément (Lomuto)
let haut = arr.len() - 1;
let mut i = 0usize;
for j in 0..haut {
if arr[j] <= arr[haut] {
arr.swap(i, j);
i += 1;
}
}
arr.swap(i, haut);
let (gauche, reste) = arr.split_at_mut(i);
tri_rapide(gauche);
tri_rapide(&mut reste[1..]); // reste[0] est le pivot
}
/// Tri par tas. O(n log n) garanti, en place.
fn tri_tas<T: Ord>(arr: &mut Vec<T>) {
let n = arr.len();
// Construire le tas-max (heapify de Floyd)
for i in (0..n / 2).rev() {
percoler_bas(arr, i, n);
}
// Extraire successivement le maximum
for fin in (1..n).rev() {
arr.swap(0, fin);
percoler_bas(arr, 0, fin);
}
}
fn percoler_bas<T: Ord>(arr: &mut Vec<T>, mut i: usize, n: usize) {
loop {
let mut plus_grand = i;
let g = 2 * i + 1;
let d = 2 * i + 2;
if g < n && arr[g] > arr[plus_grand] { plus_grand = g; }
if d < n && arr[d] > arr[plus_grand] { plus_grand = d; }
if plus_grand == i { break; }
arr.swap(i, plus_grand);
i = plus_grand;
}
}
fn main() {
let mut v = vec![38, 27, 43, 3, 9, 82, 10];
let mut v_fusion = v.clone();
tri_fusion(&mut v_fusion);
println!("Tri fusion : {:?}", v_fusion);
let mut v_rapide = v.clone();
tri_rapide(&mut v_rapide);
println!("Tri rapide : {:?}", v_rapide);
let mut v_tas = v.clone();
tri_tas(&mut v_tas);
println!("Tri par tas : {:?}", v_tas);
// Rust dispose également d'un sort stable extrêmement optimisé
v.sort();
println!("v.sort() : {:?}", v);
// et d'un sort instable (souvent plus rapide)
v.sort_unstable();
println!("v.sort_unstable() : {:?}", v);
}
Note
En Rust, slice::sort() implémente un tri stable basé sur une variante de Timsort adaptée à Rust, tandis que slice::sort_unstable() utilise pdqsort (pattern-defeating quicksort), un algorithme qui combine le tri rapide, le tri par tas et le tri par insertion selon la structure des données. sort_unstable() est généralement plus rapide car il n’a pas besoin de préserver l’ordre relatif des éléments égaux.
Il est très rare d’avoir besoin d’implémenter manuellement un algorithme de tri en Rust : les méthodes de la bibliothèque standard sont hautement optimisées et couvrent l’immense majorité des besoins.
Résumé#
Ce chapitre a présenté les tris efficaces et leurs fondements théoriques :
La borne inférieure \(\Omega(n \log n)\) est prouvée par l’argument de l’arbre de décision : tout tri par comparaison doit effectuer au moins \(\log_2(n!)= \Theta(n \log n)\) comparaisons dans le pire cas. Les tris élémentaires \(O(n^2)\) sont donc structurellement sous-optimaux.
Le tri fusion est l’archétype du diviser-pour-régner : \(O(n \log n)\) garanti, stable, mais nécessite \(O(n)\) d’espace auxiliaire. Son implémentation ascendante (bottom-up) évite la pile de récursion.
Le tri rapide est le plus rapide en pratique pour les données génériques : \(O(n \log n)\) en moyenne, en place, mais \(O(n^2)\) dans le pire cas. Le choix du pivot (aléatoire ou médiane de trois) est crucial pour éviter le pire cas.
Le tri par tas combine le meilleur des deux mondes : \(O(n \log n)\) garanti et en place, mais non stable et légèrement plus lent que le tri rapide en pratique à cause de moins bonnes propriétés de localité mémoire.
Timsort est l’algorithme de Python (
sorted(),list.sort()) : hybride fusion + insertion, adaptatif (exploit les runs), stable, \(O(n)\) sur données triées et \(O(n \log n)\) pire cas. C’est l’un des tris généraux les plus efficaces connus.En Rust,
sort()(stable, Timsort) etsort_unstable()(pdqsort) offrent des performances de référence sans effort d’implémentation.
Le chapitre suivant présentera les tris linéaires — tri par dénombrement, tri par base, tri par paquets — qui brisent la borne \(\Omega(n \log n)\) en exploitant des propriétés spécifiques des clés au lieu de simples comparaisons.