Diviser pour régner#
Le paradigme diviser pour régner (divide and conquer) est l’une des idées les plus puissantes et les plus élégantes de l’algorithmique. Elle consiste à résoudre un problème difficile de taille n en le découpant en sous-problèmes de taille réduite, en résolvant ces sous-problèmes (souvent de façon récursive), puis en combinant leurs solutions pour obtenir la solution globale. Le tri fusion, le tri rapide et la recherche binaire que nous avons déjà étudiés appartiennent tous à cette famille.
Dans ce chapitre, nous formalisons le paradigme et introduisons l’outil mathématique qui permet d’analyser la complexité de tels algorithmes : le master theorem (théorème maître). Nous étudierons ensuite trois applications classiques — la recherche simultanée du maximum et du minimum, la multiplication de Karatsuba et l’algorithme quickselect — qui illustrent comment diviser pour régner permet de faire mieux que les approches naïves.
Le paradigme général#
Définition 78 (Paradigme diviser pour régner)
Un algorithme diviser pour régner résout un problème de taille n en trois phases :
Diviser. On décompose le problème en a sous-problèmes de taille n/b chacun (avec a ≥ 1 et b > 1).
Résoudre. On résout chaque sous-problème de façon récursive. Si la taille est suffisamment petite (cas de base), on le résout directement.
Combiner. On assemble les solutions des sous-problèmes pour obtenir la solution du problème original.
La relation de récurrence associée est : $\(T(n) = a \cdot T\!\left(\frac{n}{b}\right) + f(n)\)\( où \)f(n)$ est le coût de la phase de division et de combinaison.
Exemple 11 (Exemples de la relation de récurrence)
Plusieurs algorithmes classiques s’expriment sous cette forme :
Tri fusion : \(T(n) = 2T(n/2) + O(n)\) — deux sous-problèmes de moitié, fusion en O(n). Solution : T(n) = O(n log n).
Recherche binaire : \(T(n) = T(n/2) + O(1)\) — un seul sous-problème, combinaison triviale. Solution : T(n) = O(log n).
Tour de Hanoï : \(T(n) = 2T(n-1) + O(1)\) — deux sous-problèmes de taille n-1 (b = n/(n-1), non constant). Solution : T(n) = O(2ⁿ). Attention : ici b n’est pas constant, le master theorem ne s’applique pas directement.
Karatsuba : \(T(n) = 3T(n/2) + O(n)\) — trois sous-problèmes de moitié. Solution : T(n) = O(n^{log₂ 3}) ≈ O(n^{1.585}).
Le master theorem#
Le master theorem fournit une solution fermée à la plupart des récurrences de la forme \(T(n) = aT(n/b) + f(n)\).
Définition 79 (Master theorem (théorème maître))
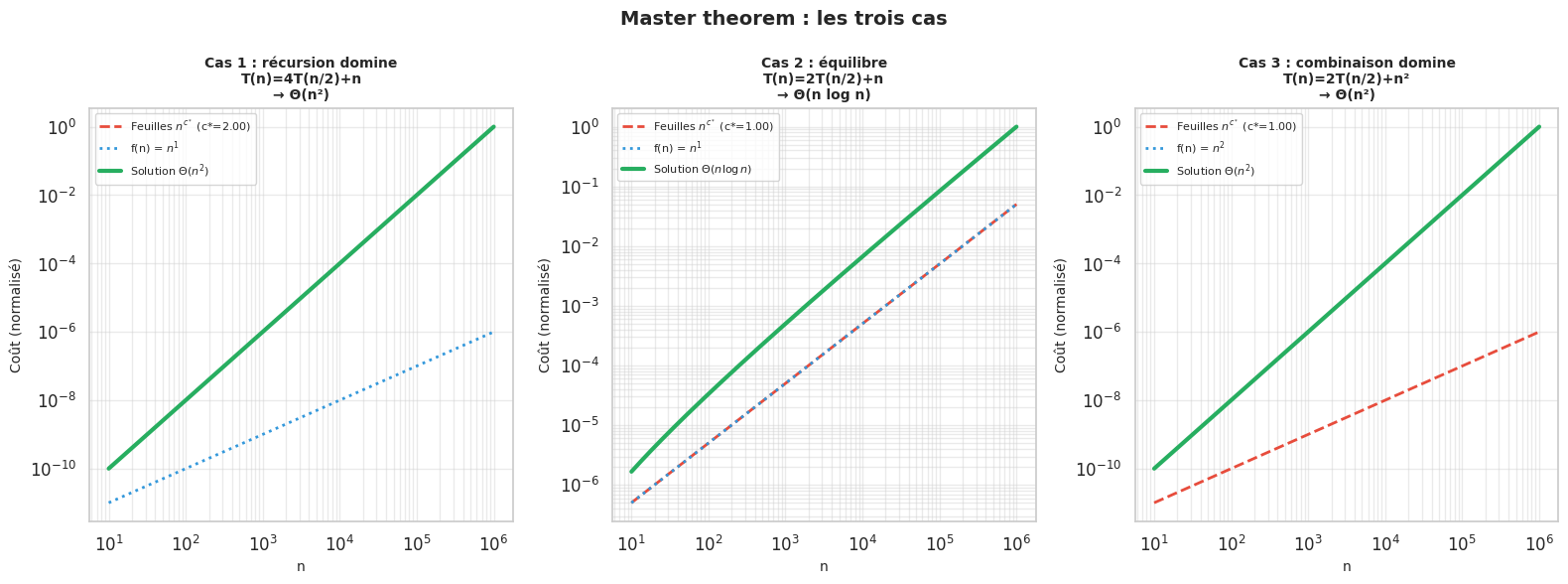
Soit \(T(n) = aT(n/b) + f(n)\) avec \(a \geq 1\), \(b > 1\) et \(f(n)\) asymptotiquement positive. Posons \(c^* = \log_b a\) (l’exposant critique).
Cas 1 (dominance de la récursion). Si \(f(n) = O(n^{c^* - \varepsilon})\) pour un certain \(\varepsilon > 0\), alors : $\(T(n) = \Theta(n^{c^*})\)$
Cas 2 (équilibre). Si \(f(n) = \Theta(n^{c^*} \log^k n)\) pour un certain \(k \geq 0\), alors : $\(T(n) = \Theta(n^{c^*} \log^{k+1} n)\)$
Cas 3 (dominance de la combinaison). Si \(f(n) = \Omega(n^{c^* + \varepsilon})\) pour un certain \(\varepsilon > 0\) et si \(a \cdot f(n/b) \leq c \cdot f(n)\) pour un certain \(c < 1\) et des n suffisamment grands (condition de régularité), alors : $\(T(n) = \Theta(f(n))\)$
Remarque 33
L’intuition derrière le master theorem est la suivante : on compare le coût des feuilles de l’arbre de récursion (il y en a \(a^{\log_b n} = n^{c^*}\)) avec le coût de la combinaison à chaque niveau.
Cas 1 : le travail aux feuilles domine — la récursion est le goulot d’étranglement. La solution est proportionnelle au nombre de feuilles.
Cas 2 : le travail est équilibré entre les niveaux — chaque niveau coûte le même montant, et comme il y a O(log n) niveaux, on gagne un facteur log.
Cas 3 : le travail à la racine domine — la combinaison est coûteuse et les sous-problèmes sont relativement légers.
Il existe des récurrences pour lesquelles le master theorem ne s’applique pas : quand \(f(n)\) n’est pas polynomial par rapport à \(n^{c^*}\) (par exemple \(f(n) = n \log \log n\) avec \(c^* = 1\)) ou quand les sous-problèmes n’ont pas tous la même taille.
def analyze_recurrence(a, b, k=0, f_description=None):
"""
Applique le master theorem à T(n) = a·T(n/b) + Θ(n^c* · log^k(n)).
Paramètres
----------
a : int
Nombre de sous-problèmes.
b : float
Facteur de réduction.
k : int
Exposant du log dans f(n) (0 si f(n) = Θ(n^c)).
f_description : str
Description textuelle de f(n).
"""
c_star = math.log(a, b)
print(f"T(n) = {a}·T(n/{b}) + f(n) [f(n) = {f_description or 'Θ(n^c*)'}]")
print(f" c* = log_{b}({a}) = {c_star:.4f}")
print(f" Cas 2 (f(n) = Θ(n^c* · log^{k} n)) → T(n) = Θ(n^{c_star:.3f} · log^{k+1} n)")
print()
# Application du master theorem aux exemples classiques
print("=" * 60)
print("Tri fusion : a=2, b=2, f(n)=Θ(n)")
c = math.log(2, 2) # c* = 1
print(f" c* = 1, f(n) = Θ(n^1) → Cas 2 (k=0) → T(n) = Θ(n log n)")
print()
print("Recherche binaire : a=1, b=2, f(n)=Θ(1)")
c = math.log(1, 2) # c* = 0
print(f" c* = 0, f(n) = Θ(n^0) = Θ(1) → Cas 2 (k=0) → T(n) = Θ(log n)")
print()
print("Karatsuba : a=3, b=2, f(n)=Θ(n)")
c = math.log(3, 2) # c* ≈ 1.585
print(f" c* = log_2(3) ≈ {c:.4f}")
print(f" f(n) = Θ(n^1) = O(n^{{c*-ε}}) car 1 < {c:.4f} → Cas 1")
print(f" T(n) = Θ(n^{{log_2 3}}) = Θ(n^{c:.4f})")
print()
print("Tri par sélection récursif : a=1, b=2, f(n)=Θ(n)")
c = math.log(1, 2) # c* = 0
print(f" c* = 0, f(n) = Θ(n) = Ω(n^{{c*+ε}}) → Cas 3 → T(n) = Θ(n)")
print()
print("Strassен : a=7, b=2, f(n)=Θ(n²)")
c = math.log(7, 2) # c* ≈ 2.807
print(f" c* = log_2(7) ≈ {c:.4f}")
print(f" f(n) = Θ(n²) = O(n^{{c*-ε}}) car 2 < {c:.4f} → Cas 1")
print(f" T(n) = Θ(n^{{log_2 7}}) = Θ(n^{c:.4f})")
============================================================
Tri fusion : a=2, b=2, f(n)=Θ(n)
c* = 1, f(n) = Θ(n^1) → Cas 2 (k=0) → T(n) = Θ(n log n)
Recherche binaire : a=1, b=2, f(n)=Θ(1)
c* = 0, f(n) = Θ(n^0) = Θ(1) → Cas 2 (k=0) → T(n) = Θ(log n)
Karatsuba : a=3, b=2, f(n)=Θ(n)
c* = log_2(3) ≈ 1.5850
f(n) = Θ(n^1) = O(n^{c*-ε}) car 1 < 1.5850 → Cas 1
T(n) = Θ(n^{log_2 3}) = Θ(n^1.5850)
Tri par sélection récursif : a=1, b=2, f(n)=Θ(n)
c* = 0, f(n) = Θ(n) = Ω(n^{c*+ε}) → Cas 3 → T(n) = Θ(n)
Strassен : a=7, b=2, f(n)=Θ(n²)
c* = log_2(7) ≈ 2.8074
f(n) = Θ(n²) = O(n^{c*-ε}) car 2 < 2.8074 → Cas 1
T(n) = Θ(n^{log_2 7}) = Θ(n^2.8074)
Recherche du maximum et du minimum simultanés#
Un problème classique illustre comment diviser pour régner permet de faire mieux que l’approche naïve : trouver simultanément le maximum et le minimum d’un tableau.
Remarque 34
L’approche naïve effectue deux parcours indépendants (ou un seul avec deux comparaisons par élément), pour un total de 2n - 2 comparaisons dans le pire cas. L’approche diviser pour régner ramène ce nombre à \(\frac{3n}{2} - 2\) comparaisons pour n pair, soit une réduction de 25 %. Cette borne est optimale pour ce problème.
def min_max_naive(arr):
"""Approche naïve : 2(n-1) comparaisons."""
if not arr:
return None, None
mn, mx = arr[0], arr[0]
for x in arr[1:]:
if x < mn:
mn = x
if x > mx:
mx = x
return mn, mx
def min_max_divide(arr, lo=0, hi=None):
"""
Diviser pour régner : trouve min et max en ≤ 3n/2 - 2 comparaisons.
Stratégie : comparer les éléments par paires, envoyer le plus petit
côté min et le plus grand côté max. En pratique implémenté ici
de manière récursive pour illustrer le paradigme.
"""
if hi is None:
hi = len(arr) - 1
if lo == hi:
return arr[lo], arr[lo]
if hi == lo + 1:
# Cas de base : 1 comparaison pour 2 éléments
return (arr[lo], arr[hi]) if arr[lo] <= arr[hi] else (arr[hi], arr[lo])
mid = (lo + hi) // 2
lo_min, lo_max = min_max_divide(arr, lo, mid)
hi_min, hi_max = min_max_divide(arr, mid + 1, hi)
return min(lo_min, hi_min), max(lo_max, hi_max)
def min_max_pairs(arr):
"""
Approche par paires : exactement ⌊3n/2⌋ - 2 comparaisons.
Procède en comparant d'abord chaque paire, puis en cherchant
le min parmi les petits et le max parmi les grands.
"""
n = len(arr)
if n == 0:
return None, None
if n == 1:
return arr[0], arr[0]
# Initialisation selon la parité
if n % 2 == 0:
mn, mx = (arr[0], arr[1]) if arr[0] <= arr[1] else (arr[1], arr[0])
start = 2
else:
mn = mx = arr[0]
start = 1
# Traitement par paires
for i in range(start, n - 1, 2):
if arr[i] <= arr[i + 1]:
small, large = arr[i], arr[i + 1]
else:
small, large = arr[i + 1], arr[i]
if small < mn:
mn = small
if large > mx:
mx = large
return mn, mx
# Tests et comptage des comparaisons
import random
def count_comparisons_minmax_naive(arr):
"""Version instrumentée."""
comps = 0
if not arr:
return 0
mn, mx = arr[0], arr[0]
for x in arr[1:]:
comps += 1
if x < mn:
mn = x
comps += 1
if x > mx:
mx = x
return comps
def count_comparisons_minmax_pairs(arr):
"""Version instrumentée."""
n = len(arr)
comps = 0
if n <= 1:
return 0
if n % 2 == 0:
comps += 1
start = 2
else:
start = 1
for i in range(start, n - 1, 2):
comps += 3 # 1 paire + 1 min + 1 max
return comps
# Vérification de la correction
test_arrs = [[random.randint(-100, 100) for _ in range(random.randint(1, 50))]
for _ in range(1000)]
for arr in test_arrs:
mn1, mx1 = min_max_naive(arr)
mn2, mx2 = min_max_divide(arr)
mn3, mx3 = min_max_pairs(arr)
assert (mn1, mx1) == (mn2, mx2) == (mn3, mx3), \
f"Divergence sur {arr}"
print("Toutes les implémentations sont correctes.")
# Comparaison du nombre de comparaisons
sizes = [10, 100, 1000, 10000]
for n in sizes:
arr = [random.randint(0, 10000) for _ in range(n)]
c_naive = count_comparisons_minmax_naive(arr)
c_pairs = count_comparisons_minmax_pairs(arr)
print(f"n={n:6d} : naïf={c_naive:6d} ({2*(n-1):.0f} théorique), "
f"paires={c_pairs:6d} ({3*n//2 - 2:.0f} théorique)")
Toutes les implémentations sont correctes.
n= 10 : naïf= 18 (18 théorique), paires= 13 (13 théorique)
n= 100 : naïf= 198 (198 théorique), paires= 148 (148 théorique)
n= 1000 : naïf= 1998 (1998 théorique), paires= 1498 (1498 théorique)
n= 10000 : naïf= 19998 (19998 théorique), paires= 14998 (14998 théorique)
Multiplication de Karatsuba#
L’algorithme#
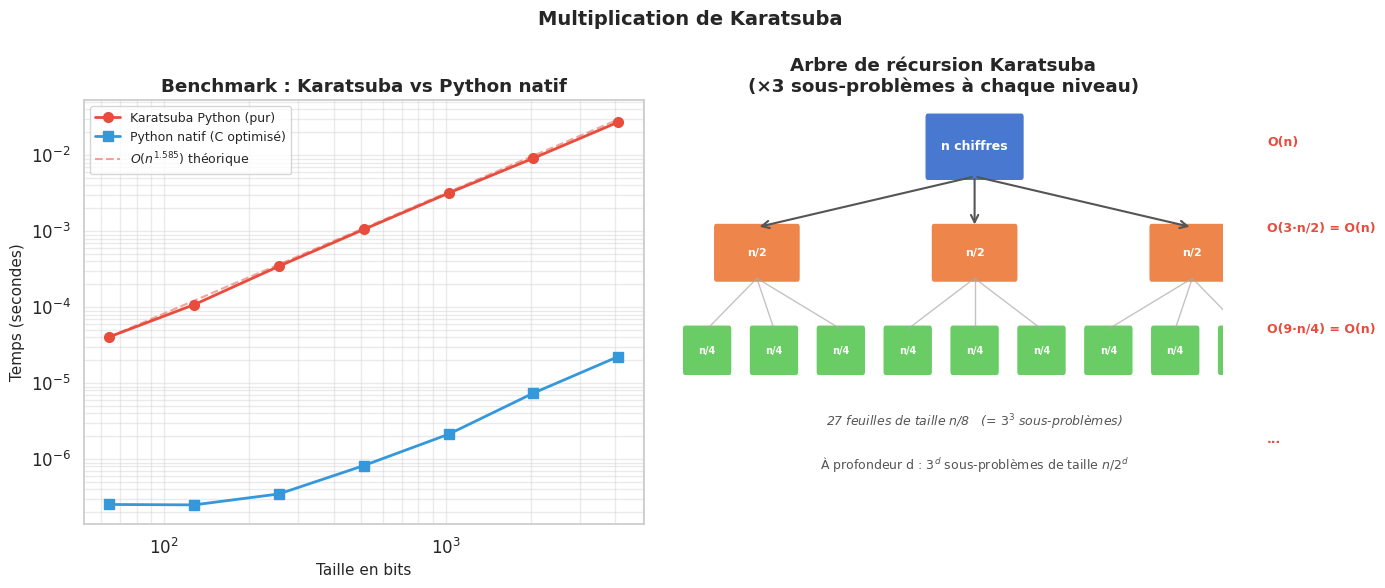
La multiplication de deux entiers à n chiffres est l’une des opérations les plus fondamentales en arithmétique. L’algorithme scolaire prend O(n²) opérations. Karatsuba (1960) a découvert comment faire en O(n^{log₂ 3}) ≈ O(n^{1.585}).
Définition 80 (Algorithme de Karatsuba)
Soient x et y deux entiers à n chiffres. On les décompose en deux moitiés : $\(x = x_1 \cdot B^m + x_0, \quad y = y_1 \cdot B^m + y_0\)\( où \)B\( est la base, \)m = \lfloor n/2 \rfloor\(, et \)x_1, x_0, y_1, y_0$ sont des entiers à environ m chiffres.
Le produit naïf nécessite quatre multiplications de taille m : $\(xy = x_1 y_1 \cdot B^{2m} + (x_1 y_0 + x_0 y_1) \cdot B^m + x_0 y_0\)$
Karatsuba réduit à trois multiplications en observant que : $\(x_1 y_0 + x_0 y_1 = (x_1 + x_0)(y_1 + y_0) - x_1 y_1 - x_0 y_0\)$
Les termes \(z_0 = x_0 y_0\), \(z_2 = x_1 y_1\) et \(z_1 = (x_1 + x_0)(y_1 + y_0) - z_2 - z_0\) ne requièrent que 3 multiplications récursives.
La récurrence est \(T(n) = 3T(n/2) + O(n)\), dont la solution est \(T(n) = \Theta(n^{\log_2 3}) \approx \Theta(n^{1.585})\).
def karatsuba(x, y):
"""
Multiplication de Karatsuba.
Complexité : O(n^log₂(3)) ≈ O(n^1.585) où n est le nombre de chiffres.
Paramètres
----------
x, y : int
Entiers non négatifs.
Retourne
-------
int
Produit x * y.
"""
# Cas de base : multiplication directe pour les petits entiers
if x < 100 or y < 100:
return x * y
# Nombre de chiffres (en base 10) du plus grand des deux
n = max(len(str(x)), len(str(y)))
m = n // 2
# Décomposition : x = x1 * 10^m + x0
power = 10 ** m
x1, x0 = divmod(x, power)
y1, y0 = divmod(y, power)
# Trois multiplications récursives (au lieu de quatre)
z0 = karatsuba(x0, y0)
z2 = karatsuba(x1, y1)
z1 = karatsuba(x0 + x1, y0 + y1) - z0 - z2
return z2 * (power ** 2) + z1 * power + z0
# Tests de correction
assert karatsuba(0, 12345) == 0
assert karatsuba(1, 99999) == 99999
assert karatsuba(123, 456) == 123 * 456
assert karatsuba(12345678, 87654321) == 12345678 * 87654321
assert karatsuba(10**50, 10**50) == 10**100
# Grands entiers
import random
for _ in range(100):
x = random.randint(0, 10**30)
y = random.randint(0, 10**30)
assert karatsuba(x, y) == x * y
print("Karatsuba correct pour tous les tests.")
print(f"karatsuba(123456, 789012) = {karatsuba(123456, 789012)}")
print(f"Vérification : 123456 × 789012 = {123456 * 789012}")
Karatsuba correct pour tous les tests.
karatsuba(123456, 789012) = 97408265472
Vérification : 123456 × 789012 = 97408265472
Quickselect : le k-ième plus petit élément#
Principe#
Définition 81 (Problème de sélection)
Le problème de sélection consiste à trouver le k-ième plus petit élément d’un tableau de n éléments (le k-ième ordre statistique) sans trier l’intégralité du tableau.
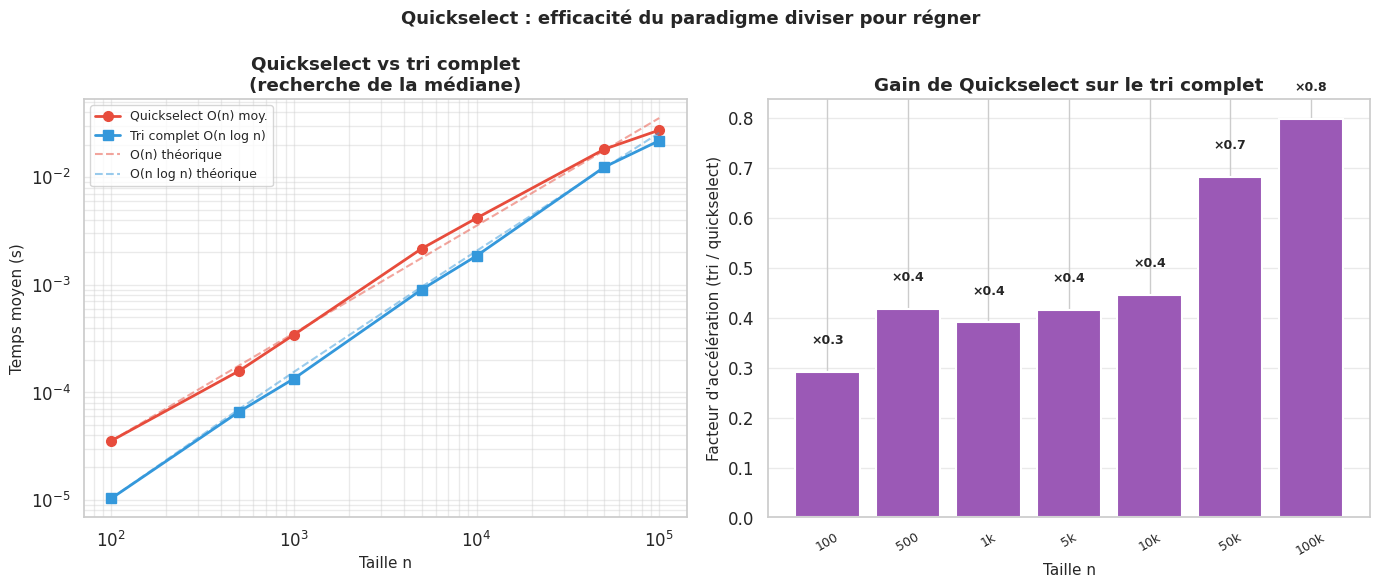
Approche naïve : trier puis indexer — O(n log n).
Quickselect : O(n) en moyenne, O(n²) dans le pire cas.
Médiane des médianes : O(n) dans le pire cas (plus complexe à implémenter).
Définition 82 (Algorithme Quickselect)
Quickselect (ou algorithme de Hoare) est une variante du tri rapide qui exploite le partitionnement pour ne récurser que sur la moitié contenant le k-ième élément :
Partitionner le tableau autour d’un pivot : les éléments plus petits que le pivot sont à sa gauche, les plus grands à sa droite.
Soit p la position finale du pivot.
Si p == k, le pivot est la réponse.
Si p > k, la réponse est dans la moitié gauche.
Si p < k, la réponse est dans la moitié droite (avec k ajusté).
La récurrence est \(T(n) = T(n/2) + O(n)\) en moyenne (pivot aléatoire divise en deux), soit T(n) = O(n). Avec un pivot non représentatif, la récurrence peut dégénérer en \(T(n) = T(n-1) + O(n) = O(n²)\).
def quickselect(arr, k, lo=0, hi=None):
"""
Quickselect : retourne le k-ième plus petit élément de arr[lo:hi+1]
(k indexé à partir de 0).
Modifie arr en place. Complexité : O(n) en moyenne, O(n²) pire cas.
"""
if hi is None:
hi = len(arr) - 1
if lo == hi:
return arr[lo]
# Partitionnement avec pivot aléatoire
pivot_idx = random.randint(lo, hi)
arr[pivot_idx], arr[hi] = arr[hi], arr[pivot_idx]
pivot = arr[hi]
# Partition à la Lomuto
i = lo
for j in range(lo, hi):
if arr[j] <= pivot:
arr[i], arr[j] = arr[j], arr[i]
i += 1
arr[i], arr[hi] = arr[hi], arr[i]
p = i # Position finale du pivot
if p == k:
return arr[p]
elif k < p:
return quickselect(arr, k, lo, p - 1)
else:
return quickselect(arr, k, p + 1, hi)
def quickselect_iteratif(arr, k):
"""
Version itérative de Quickselect, évite la pile de récursion.
"""
arr = list(arr) # Copie
lo, hi = 0, len(arr) - 1
while lo < hi:
pivot_idx = random.randint(lo, hi)
arr[pivot_idx], arr[hi] = arr[hi], arr[pivot_idx]
pivot = arr[hi]
i = lo
for j in range(lo, hi):
if arr[j] <= pivot:
arr[i], arr[j] = arr[j], arr[i]
i += 1
arr[i], arr[hi] = arr[hi], arr[i]
p = i
if p == k:
return arr[p]
elif k < p:
hi = p - 1
else:
lo = p + 1
return arr[lo]
# Tests
def kth_smallest_naive(arr, k):
return sorted(arr)[k]
random.seed(42)
for _ in range(500):
n = random.randint(1, 100)
arr = [random.randint(-50, 50) for _ in range(n)]
k = random.randint(0, n - 1)
result = quickselect(list(arr), k)
expected = kth_smallest_naive(arr, k)
assert result == expected, f"Erreur : arr={arr}, k={k}, got={result}, exp={expected}"
print("Quickselect correct.")
print(f"[3, 1, 4, 1, 5, 9, 2, 6, 5] → 3e plus petit = {quickselect([3,1,4,1,5,9,2,6,5], 2)}")
print(f"[3, 1, 4, 1, 5, 9, 2, 6, 5] → médiane (indice 4) = {quickselect([3,1,4,1,5,9,2,6,5], 4)}")
Quickselect correct.
[3, 1, 4, 1, 5, 9, 2, 6, 5] → 3e plus petit = 2
[3, 1, 4, 1, 5, 9, 2, 6, 5] → médiane (indice 4) = 4
Implémentation Rust#
use rand::Rng;
/// Quickselect itératif en Rust : k-ième plus petit élément (0-indexé).
/// Complexité : O(n) en moyenne, O(n²) pire cas.
pub fn quickselect<T: Ord>(arr: &mut [T], k: usize) -> &T {
let mut lo = 0;
let mut hi = arr.len() - 1;
loop {
if lo == hi {
return &arr[lo];
}
// Pivot aléatoire
let pivot_idx = rand::thread_rng().gen_range(lo..=hi);
arr.swap(pivot_idx, hi);
// Partition à la Lomuto
let mut i = lo;
for j in lo..hi {
if arr[j] <= arr[hi] {
arr.swap(i, j);
i += 1;
}
}
arr.swap(i, hi);
let p = i;
if p == k {
return &arr[p];
} else if k < p {
hi = p - 1;
} else {
lo = p + 1;
}
}
}
/// Multiplication de Karatsuba en Rust (sur des BigUint ou u128 simplifiés).
/// Pour illustrer le paradigme ; en production on utiliserait la crate `num-bigint`.
pub fn karatsuba_u128(x: u128, y: u128) -> u128 {
// Cas de base
if x < 1000 || y < 1000 {
return x.saturating_mul(y);
}
// Nombre de chiffres en base 10
let n = x.to_string().len().max(y.to_string().len());
let m = n / 2;
let power = 10u128.pow(m as u32);
let x1 = x / power;
let x0 = x % power;
let y1 = y / power;
let y0 = y % power;
let z0 = karatsuba_u128(x0, y0);
let z2 = karatsuba_u128(x1, y1);
let z1 = karatsuba_u128(x0 + x1, y0 + y1)
.saturating_sub(z0)
.saturating_sub(z2);
z2.saturating_mul(power.saturating_mul(power))
.saturating_add(z1.saturating_mul(power))
.saturating_add(z0)
}
/// Minimum et maximum simultanés en ≤ 3n/2 comparaisons.
pub fn min_max_pairs<T: Ord + Copy>(arr: &[T]) -> Option<(T, T)> {
let n = arr.len();
if n == 0 {
return None;
}
if n == 1 {
return Some((arr[0], arr[0]));
}
let (mut mn, mut mx) = if arr[0] <= arr[1] {
(arr[0], arr[1])
} else {
(arr[1], arr[0])
};
let mut i = 2;
while i + 1 < n {
let (small, large) = if arr[i] <= arr[i + 1] {
(arr[i], arr[i + 1])
} else {
(arr[i + 1], arr[i])
};
if small < mn { mn = small; }
if large > mx { mx = large; }
i += 2;
}
// Élément orphelin si n est impair
if i < n {
if arr[i] < mn { mn = arr[i]; }
if arr[i] > mx { mx = arr[i]; }
}
Some((mn, mx))
}
Résumé#
Dans ce chapitre, nous avons formalisé le paradigme diviser pour régner et développé les outils nécessaires à son analyse :
Le paradigme se structure en trois phases — diviser, résoudre récursivement, combiner — et génère des récurrences de la forme \(T(n) = aT(n/b) + f(n)\).
Le master theorem résout ces récurrences selon trois cas : quand la récursion domine (Cas 1, solution \(\Theta(n^{c^*})\)), quand les coûts s’équilibrent (Cas 2, solution \(\Theta(n^{c^*} \log n)\)), ou quand la combinaison domine (Cas 3, solution \(\Theta(f(n))\)).
La recherche du min et du max simultanés illustre comment diviser pour régner peut réduire le nombre de comparaisons de 2n - 2 à 3n/2 - 2, une amélioration de 25 % qui est optimale.
La multiplication de Karatsuba passe de O(n²) à O(n^{log₂ 3}) ≈ O(n^{1.585}) en réduisant quatre multiplications récursives à trois grâce à une identité algébrique astucieuse — une idée qui a révolutionné l’arithmétique multi-précision.
Quickselect trouve le k-ième plus petit élément en O(n) en moyenne sans trier le tableau, en appliquant le partitionnement du tri rapide et en ne récursant que sur la moitié pertinente.
Le chapitre suivant aborde la programmation dynamique, un paradigme complémentaire de diviser pour régner : là où diviser pour régner convient aux problèmes dont les sous-problèmes sont indépendants, la programmation dynamique excelle quand les sous-problèmes se chevauchent — évitant ainsi de recalculer des résultats déjà obtenus.