Tables de hachage#
Les structures vues jusqu’ici — tableaux triés, arbres BST, AVL — permettent la recherche d’une clé en \(O(\log n)\). Peut-on faire mieux ? Dans de nombreuses situations pratiques, la réponse est oui : les tables de hachage offrent une recherche, une insertion et une suppression en \(O(1)\) en moyenne. C’est cette performance spectaculaire qui en fait l’une des structures de données les plus utilisées dans les langages modernes : les dictionnaires Python, les HashMap de Rust et de Java, les objets JavaScript, les ensembles (set) de nombreux langages — tous reposent sur le hachage.
Motivation : la recherche en \(O(1)\)#
L’idée centrale est simple : au lieu de chercher une clé en la comparant successivement à d’autres (comme dans un arbre ou une liste triée), on calcule directement l”emplacement où elle devrait se trouver, grâce à une fonction de hachage.
Définition 52 (Table de hachage)
Une table de hachage est une structure de données qui associe des clés à des valeurs. Elle est composée :
d’un tableau \(T\) de taille \(m\) (les alvéoles ou buckets) ;
d’une fonction de hachage \(h : \mathcal{U} \to \{0, 1, \dots, m-1\}\), où \(\mathcal{U}\) est l’univers des clés possibles.
Pour stocker une paire \((k, v)\), on place \(v\) dans l’alvéole \(T[h(k)]\). Pour rechercher la clé \(k\), on calcule \(h(k)\) et on examine \(T[h(k)]\).
Si \(h\) était une bijection parfaite entre les clés stockées et les indices du tableau, chaque opération serait exactement \(O(1)\). En pratique, \(|\mathcal{U}|\) est bien supérieur à \(m\), et des collisions surviennent.
Fonction de hachage#
Définition 53 (Propriétés d’une bonne fonction de hachage)
Une bonne fonction de hachage doit être :
Déterministe : \(h(k)\) retourne toujours la même valeur pour une même clé \(k\).
Rapide à calculer : idéalement \(O(1)\) ou \(O(|k|)\) pour les clés de longueur variable.
Uniforme : les clés doivent être réparties aussi uniformément que possible dans \(\{0, \dots, m-1\}\).
Effet avalanche : un changement d’un seul bit dans \(k\) modifie environ la moitié des bits de \(h(k)\).
Exemples de fonctions de hachage#
Hachage modulo. Pour une clé entière \(k\) : \(h(k) = k \bmod m\). On choisit \(m\) premier pour minimiser les regroupements.
Hachage polynomial (polynomial rolling hash). Pour une chaîne de caractères \(s = s_0 s_1 \dots s_{L-1}\) : $\(h(s) = \left(\sum_{i=0}^{L-1} s_i \cdot p^i\right) \bmod m\)\( où \)p\( est un nombre premier (souvent \)31\( ou \)131\() et \)m$ est la taille de la table (souvent une puissance de 2 en pratique, ou un grand premier).
def hachage_modulo(cle: int, m: int) -> int:
"""Hachage d'un entier par modulo. O(1)."""
return cle % m
def hachage_polynomial(chaine: str, m: int, p: int = 31) -> int:
"""
Hachage polynomial d'une chaîne de caractères.
Robuste aux collisions, O(|chaine|).
"""
h = 0
puissance = 1
for caractere in chaine:
h = (h + ord(caractere) * puissance) % m
puissance = (puissance * p) % m
return h
# Démonstration
m = 13
mots = ["chat", "chien", "oiseau", "lapin", "hamster", "tortue", "poisson"]
print(f"Taille de la table : {m}")
print(f"{'Clé':<12} {'Hash modulo (int)':<22} {'Hash polynomial'}")
print("-" * 50)
for mot in mots:
h_int = hachage_modulo(sum(ord(c) for c in mot), m)
h_poly = hachage_polynomial(mot, m)
print(f"{mot:<12} {h_int:<22} {h_poly}")
Taille de la table : 13
Clé Hash modulo (int) Hash polynomial
--------------------------------------------------
chat 0 7
chien 12 2
oiseau 9 9
lapin 12 1
hamster 2 9
tortue 12 1
poisson 12 1
Remarque 22
En Python, la fonction hash() est disponible pour tout objet hashable (entiers, chaînes, tuples). Elle est conçue pour être uniforme et rapide. Cependant, depuis Python 3.3, le hachage des chaînes est randomisé par défaut (via PYTHONHASHSEED) pour éviter les attaques par déni de service basées sur les collisions de hachage. Ainsi, hash("abc") retourne une valeur différente à chaque exécution du programme.
Collisions#
Une collision survient quand deux clés distinctes \(k_1 \neq k_2\) ont le même hash : \(h(k_1) = h(k_2)\). Les collisions sont inévitables dès que \(|\mathcal{U}| > m\) (pigeonhole principle). La question n’est pas d’éviter les collisions, mais de les gérer efficacement.
Les deux stratégies principales sont le chaînage et l”adressage ouvert.
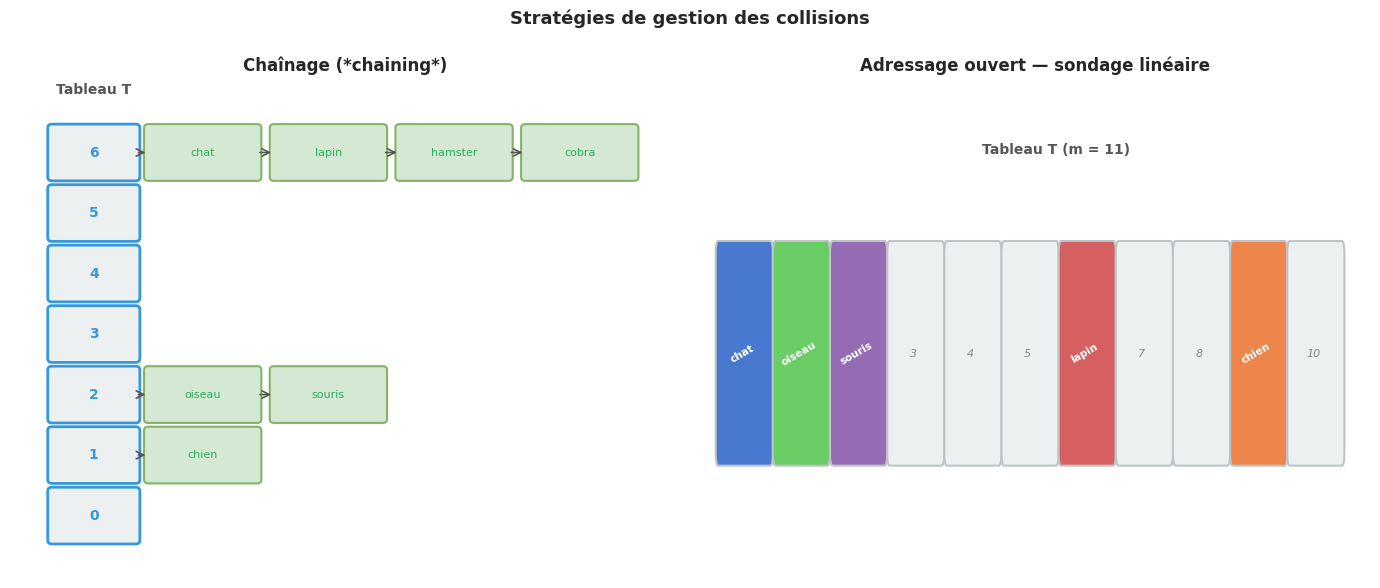
Chaînage (chaining)#
Définition 54 (Chaînage)
Dans la stratégie de chaînage, chaque alvéole \(T[i]\) est une liste chaînée (ou toute autre structure de données dynamique) contenant tous les couples \((k, v)\) de clé de hash \(i\). Pour insérer \((k, v)\), on ajoute en tête de \(T[h(k)]\). Pour rechercher \(k\), on parcourt \(T[h(k)]\).
Complexité (cas moyen) : \(O(1 + \alpha)\) où \(\alpha = n/m\) est le facteur de charge.
Complexité (pire cas) : \(O(n)\) si toutes les clés ont le même hash.
class TableHachageChainage:
"""Table de hachage par chaînage. Implémentation pédagogique."""
def __init__(self, taille_initiale: int = 8):
self.m = taille_initiale
self.n = 0 # nombre d'éléments
self.table = [[] for _ in range(self.m)]
self._seuil_redimension = 0.75
def _hash(self, cle) -> int:
return hash(cle) % self.m
def _redimensionner(self):
"""Double la taille de la table et rehache toutes les clés. O(n)."""
ancienne_table = self.table
self.m *= 2
self.table = [[] for _ in range(self.m)]
self.n = 0
for alvéole in ancienne_table:
for cle, valeur in alvéole:
self.inserer(cle, valeur)
def inserer(self, cle, valeur):
"""Insère ou met à jour (cle, valeur). O(1) amorti."""
idx = self._hash(cle)
for i, (k, _) in enumerate(self.table[idx]):
if k == cle:
self.table[idx][i] = (cle, valeur) # mise à jour
return
self.table[idx].append((cle, valeur))
self.n += 1
if self.n / self.m > self._seuil_redimension:
self._redimensionner()
def rechercher(self, cle):
"""Retourne la valeur associée à cle, ou None. O(1) moyen."""
idx = self._hash(cle)
for k, v in self.table[idx]:
if k == cle:
return v
return None
def supprimer(self, cle) -> bool:
"""Supprime la clé. Retourne True si trouvée, False sinon. O(1) moyen."""
idx = self._hash(cle)
for i, (k, _) in enumerate(self.table[idx]):
if k == cle:
self.table[idx].pop(i)
self.n -= 1
return True
return False
@property
def facteur_charge(self) -> float:
return self.n / self.m
def __contains__(self, cle) -> bool:
return self.rechercher(cle) is not None
def __setitem__(self, cle, valeur):
self.inserer(cle, valeur)
def __getitem__(self, cle):
val = self.rechercher(cle)
if val is None:
raise KeyError(cle)
return val
def statistiques(self):
longueurs = [len(alv) for alv in self.table]
return {
'taille': self.m,
'elements': self.n,
'facteur_charge': self.facteur_charge,
'max_collision': max(longueurs),
'alvéoles_vides': longueurs.count(0),
}
# Test
table = TableHachageChainage()
mots_freq = [("algorithme", 42), ("structure", 17), ("hachage", 99),
("collision", 3), ("python", 7), ("rust", 12)]
for k, v in mots_freq:
table[k] = v
print("Recherches :")
for mot, _ in mots_freq:
print(f" table['{mot}'] = {table[mot]}")
print(f"\nStatistiques : {table.statistiques()}")
table.supprimer("collision")
print(f"Après suppression de 'collision' : {table.statistiques()}")
Recherches :
table['algorithme'] = 42
table['structure'] = 17
table['hachage'] = 99
table['collision'] = 3
table['python'] = 7
table['rust'] = 12
Statistiques : {'taille': 8, 'elements': 6, 'facteur_charge': 0.75, 'max_collision': 2, 'alvéoles_vides': 3}
Après suppression de 'collision' : {'taille': 8, 'elements': 5, 'facteur_charge': 0.625, 'max_collision': 2, 'alvéoles_vides': 4}
Adressage ouvert (open addressing)#
Définition 55 (Adressage ouvert)
Dans la stratégie d”adressage ouvert, toutes les paires \((k, v)\) sont stockées directement dans le tableau \(T\) (pas de liste chaînée). En cas de collision à l’indice \(h(k)\), on sonde d’autres alvéoles selon une séquence prédéfinie jusqu’à trouver une alvéole libre.
Les trois variantes principales de sondage sont :
Sondage linéaire : \(h(k, i) = (h(k) + i) \bmod m\)
Sondage quadratique : \(h(k, i) = (h(k) + c_1 i + c_2 i^2) \bmod m\)
Double hachage : \(h(k, i) = (h_1(k) + i \cdot h_2(k)) \bmod m\)
Remarque 23
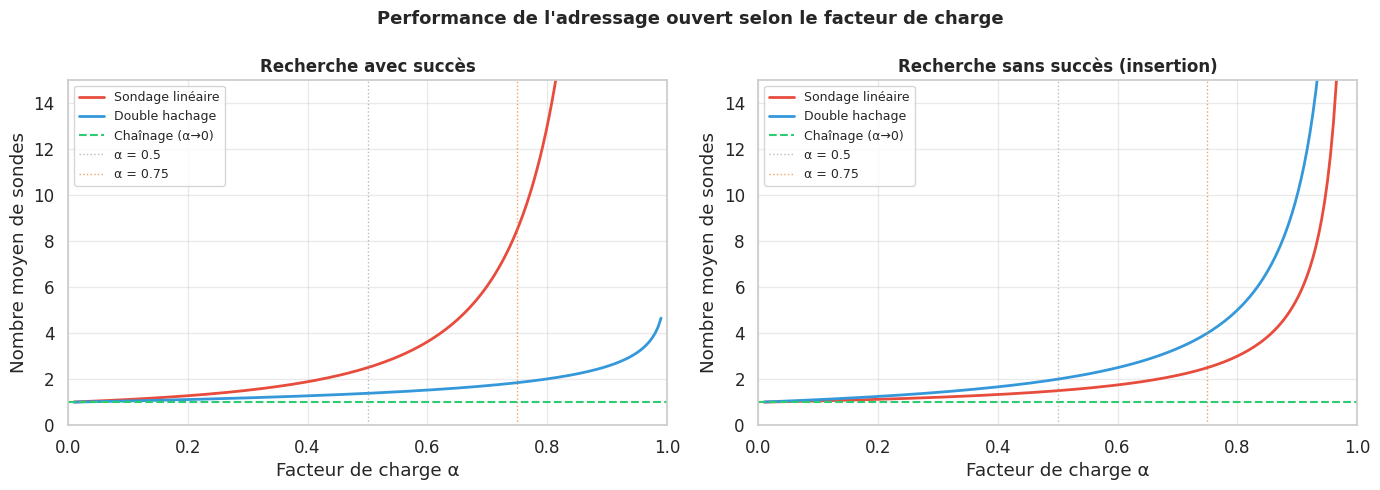
Le sondage linéaire souffre du phénomène de regroupement primaire (primary clustering) : les clés occupées tendent à se concentrer en longs blocs contigus, ce qui dégrade les performances à mesure que le facteur de charge augmente. Le sondage quadratique réduit ce phénomène mais introduit un regroupement secondaire. Le double hachage est la meilleure des trois variantes en pratique.
L’adressage ouvert exige que le facteur de charge \(\alpha = n/m < 1\) (le tableau ne peut jamais être plein). En pratique, on redimensionne dès que \(\alpha\) dépasse \(0{,}5\) (sondage linéaire) à \(0{,}7\) (double hachage).
_VIDE = object() # sentinelle : alvéole vide
_SUPPRIME = object() # sentinelle : alvéole supprimée (tombstone)
class TableHachageLineaire:
"""
Table de hachage par adressage ouvert avec sondage linéaire.
Implémentation pédagogique à facteur de charge ≤ 0.5.
"""
def __init__(self, taille_initiale: int = 8):
self.m = taille_initiale
self.n = 0
self.cles = [_VIDE] * self.m
self.valeurs = [None] * self.m
self._seuil = 0.5
def _hash(self, cle) -> int:
return hash(cle) % self.m
def _sonder(self, cle):
"""Retourne l'indice de la clé ou de la première place libre."""
idx = self._hash(cle)
premier_tombstone = None
for i in range(self.m):
j = (idx + i) % self.m
if self.cles[j] is _VIDE:
# Clé absente ; si on a vu un tombstone, c'est la meilleure place
return premier_tombstone if premier_tombstone is not None else j, False
elif self.cles[j] is _SUPPRIME:
if premier_tombstone is None:
premier_tombstone = j
elif self.cles[j] == cle:
return j, True # clé trouvée
return premier_tombstone, False
def _redimensionner(self):
anciennes_cles = self.cles
anciennes_valeurs = self.valeurs
self.m *= 2
self.n = 0
self.cles = [_VIDE] * self.m
self.valeurs = [None] * self.m
for k, v in zip(anciennes_cles, anciennes_valeurs):
if k is not _VIDE and k is not _SUPPRIME:
self.inserer(k, v)
def inserer(self, cle, valeur):
if self.n / self.m >= self._seuil:
self._redimensionner()
idx, trouve = self._sonder(cle)
if not trouve:
self.n += 1
self.cles[idx] = cle
self.valeurs[idx] = valeur
def rechercher(self, cle):
idx, trouve = self._sonder(cle)
return self.valeurs[idx] if trouve else None
def supprimer(self, cle) -> bool:
idx, trouve = self._sonder(cle)
if trouve:
self.cles[idx] = _SUPPRIME
self.valeurs[idx] = None
self.n -= 1
return True
return False
def etat_tableau(self):
"""Retourne une liste lisible de l'état interne pour visualisation."""
etats = []
for k, v in zip(self.cles, self.valeurs):
if k is _VIDE:
etats.append(('VIDE', None))
elif k is _SUPPRIME:
etats.append(('DEL', None))
else:
etats.append((k, v))
return etats
# Démonstration
tl = TableHachageLineaire(taille_initiale=16)
donnees = {"a": 1, "b": 2, "c": 3, "d": 4, "e": 5}
for k, v in donnees.items():
tl.inserer(k, v)
print("Recherches :")
for k in donnees:
print(f" '{k}' → {tl.rechercher(k)}")
print(f"Facteur de charge : {tl.n}/{tl.m} = {tl.n/tl.m:.2f}")
Recherches :
'a' → 1
'b' → 2
'c' → 3
'd' → 4
'e' → 5
Facteur de charge : 5/16 = 0.31
Facteur de charge et redimensionnement#
Définition 56 (Facteur de charge)
Le facteur de charge d’une table de hachage de taille \(m\) contenant \(n\) éléments est : $\(\alpha = \frac{n}{m}\)$
Pour le chaînage, la longueur moyenne des listes est \(\alpha\) (qui peut dépasser 1). Pour l’adressage ouvert, \(\alpha < 1\) est une contrainte stricte.
Le redimensionnement (rehashing) consiste à créer un nouveau tableau de taille \(2m\) (ou \(m\) premier suivant) et à réinsérer tous les éléments. Cette opération coûte \(O(n)\), mais comme elle est effectuée doublement moins souvent que les insertions, son coût amorti est \(O(1)\) par insertion.
Le dict Python : implémentation interne#
Le dictionnaire Python est l’une des implémentations de tables de hachage les plus sophistiquées qui soient. Il mérite une attention particulière.
Remarque 24
Depuis Python 3.6, les dictionnaires sont ordonnés (ils conservent l’ordre d’insertion des clés), ce qui est une garantie du langage depuis Python 3.7. Cette propriété est obtenue en maintenant, en parallèle du tableau de hachage, un tableau d’indices compact qui préserve l’ordre d’insertion.
Les clés d’un dictionnaire Python doivent être hashables : elles doivent implémenter __hash__() et __eq__(). Une règle fondamentale est que deux objets égaux (a == b) doivent avoir le même hash (hash(a) == hash(b)). L’inverse n’est pas requis : deux objets de hash identique peuvent être différents (collision).
# Hashabilité et protocole __hash__ / __eq__
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __eq__(self, autre):
return isinstance(autre, Point) and self.x == autre.x and self.y == autre.y
def __hash__(self):
# Combiner les hashes des composantes avec XOR et décalage
return hash((self.x, self.y))
def __repr__(self):
return f"Point({self.x}, {self.y})"
p1 = Point(1, 2)
p2 = Point(1, 2)
p3 = Point(3, 4)
print(f"p1 == p2 : {p1 == p2}")
print(f"hash(p1) == hash(p2) : {hash(p1) == hash(p2)}")
print(f"hash(p1) == hash(p3) : {hash(p1) == hash(p3)}")
# Utilisation comme clé de dictionnaire
distances = {p1: 0.0, p3: 5.0}
print(f"distances[p2] = {distances[p2]}") # p2 == p1, donc trouvé
# Les listes ne sont pas hashables (mutables)
try:
d = {[1, 2]: "valeur"}
except TypeError as e:
print(f"Erreur : {e}")
# Les tuples (immuables) sont hashables
d = {(1, 2): "valeur"}
print(f"dict avec tuple-clé : {d}")
p1 == p2 : True
hash(p1) == hash(p2) : True
hash(p1) == hash(p3) : False
distances[p2] = 0.0
Erreur : unhashable type: 'list'
dict avec tuple-clé : {(1, 2): 'valeur'}
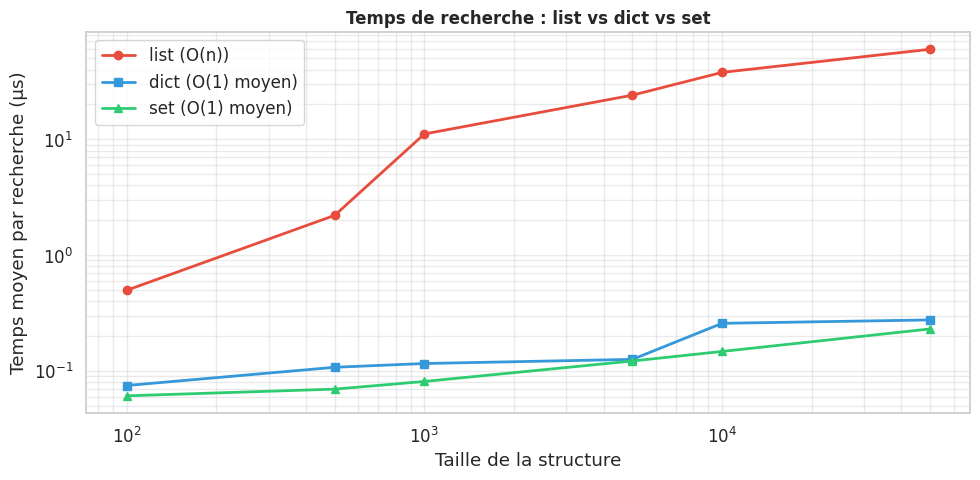
# Performance du dict vs liste : recherche
import timeit
n = 10_000
data = list(range(n))
cibles = [random.randint(0, n - 1) for _ in range(1000)]
# Préparation
liste = data.copy()
random.shuffle(liste)
dico = {v: True for v in liste}
t_liste = timeit.timeit(
stmt=lambda: all(c in liste for c in cibles),
number=100
)
t_dict = timeit.timeit(
stmt=lambda: all(c in dico for c in cibles),
number=100
)
print(f"Recherche dans une liste ({n} éléments) : {t_liste:.4f} s (100 répétitions)")
print(f"Recherche dans un dict ({n} éléments) : {t_dict:.4f} s (100 répétitions)")
print(f"Accélération : {t_liste / t_dict:.0f}×")
Recherche dans une liste (10000 éléments) : 5.1572 s (100 répétitions)
Recherche dans un dict (10000 éléments) : 0.0084 s (100 répétitions)
Accélération : 614×
HashSet et HashMap en Rust#
En Rust, la bibliothèque standard propose std::collections::HashMap<K, V> et std::collections::HashSet<T>. Ces structures utilisent par défaut l’algorithme SipHash (résistant aux attaques par collision), mais on peut substituer un hasher plus rapide (FxHashMap, AHashMap) pour les cas où la sécurité n’est pas une préoccupation.
use std::collections::{HashMap, HashSet};
fn compter_frequences(texte: &str) -> HashMap<char, usize> {
let mut freq = HashMap::new();
for c in texte.chars() {
*freq.entry(c).or_insert(0) += 1;
}
freq
}
fn dedoublonner(valeurs: Vec<i32>) -> Vec<i32> {
let mut vu = HashSet::new();
valeurs.into_iter().filter(|&x| vu.insert(x)).collect()
}
fn main() {
// Comptage de fréquences
let texte = "algorithme de hachage";
let freq = compter_frequences(texte);
let mut paires: Vec<_> = freq.iter().collect();
paires.sort_by_key(|&(c, _)| c);
for (c, n) in &paires {
if *c != ' ' {
println!("'{}' : {}", c, n);
}
}
// Dédoublonnage
let valeurs = vec![3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5];
let uniques = dedoublonner(valeurs);
println!("\nValeurs uniques : {:?}", uniques);
// Opérations ensemblistes
let a: HashSet<i32> = [1, 2, 3, 4].into_iter().collect();
let b: HashSet<i32> = [3, 4, 5, 6].into_iter().collect();
let intersection: HashSet<_> = a.intersection(&b).collect();
let union: HashSet<_> = a.union(&b).collect();
let difference: HashSet<_> = a.difference(&b).collect();
println!("A ∩ B : {:?}", intersection);
println!("A ∪ B : {:?}", union);
println!("A − B : {:?}", difference);
}
Applications pratiques#
Dédoublonnage#
def dedoublonner(lst):
"""Retourne la liste sans doublons, en préservant l'ordre d'apparition. O(n)."""
vu = set()
return [x for x in lst if not (x in vu or vu.add(x))]
data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
print("Dédoublonnage :", dedoublonner(data))
Dédoublonnage : [3, 1, 4, 5, 9, 2, 6]
Comptage de fréquences#
from collections import Counter
texte = "le hachage est une technique algorithmique fondamentale"
mots = texte.split()
# Avec Counter (basé sur dict)
compteur = Counter(mots)
print("Fréquences des mots :")
for mot, freq in sorted(compteur.items(), key=lambda x: -x[1]):
print(f" '{mot}' : {freq}")
Fréquences des mots :
'le' : 1
'hachage' : 1
'est' : 1
'une' : 1
'technique' : 1
'algorithmique' : 1
'fondamentale' : 1
Cache LRU (Least Recently Used)#
from collections import OrderedDict
class CacheLRU:
"""
Cache LRU de capacité fixe.
Implémenté avec un OrderedDict (dict + liste doublement chaînée) en Python.
Toutes les opérations sont O(1).
"""
def __init__(self, capacite: int):
self.capacite = capacite
self._cache = OrderedDict()
def obtenir(self, cle):
"""Retourne la valeur ou None. Marque la clé comme récemment utilisée."""
if cle not in self._cache:
return None
self._cache.move_to_end(cle) # déplace vers la fin (plus récent)
return self._cache[cle]
def mettre(self, cle, valeur):
"""Insère ou met à jour. Évince le LRU si capacité dépassée."""
if cle in self._cache:
self._cache.move_to_end(cle)
self._cache[cle] = valeur
if len(self._cache) > self.capacite:
self._cache.popitem(last=False) # évince le moins récemment utilisé
def __repr__(self):
return f"CacheLRU({dict(self._cache)})"
cache = CacheLRU(3)
for k, v in [("a", 1), ("b", 2), ("c", 3)]:
cache.mettre(k, v)
print("Cache initial :", cache)
cache.obtenir("a") # "a" devient le plus récent
cache.mettre("d", 4) # "b" est éjecté (LRU)
print("Après accès à 'a' et insertion de 'd' :", cache)
print("Recherche de 'b' :", cache.obtenir("b")) # None (éjecté)
print("Recherche de 'a' :", cache.obtenir("a")) # 1
Cache initial : CacheLRU({'a': 1, 'b': 2, 'c': 3})
Après accès à 'a' et insertion de 'd' : CacheLRU({'c': 3, 'a': 1, 'd': 4})
Recherche de 'b' : None
Recherche de 'a' : 1
Benchmark comparatif#
Résumé#
Ce chapitre a exploré les tables de hachage, une structure fondamentale pour l’accès en temps constant :
Une table de hachage mappe des clés à des valeurs via une fonction de hachage \(h(k) \in \{0, \dots, m-1\}\). Les opérations de recherche, insertion et suppression s’effectuent en \(O(1)\) en moyenne.
Une bonne fonction de hachage doit être rapide, uniforme et présenter un fort effet avalanche. Le hachage polynomial est robuste pour les chaînes de caractères.
Les collisions sont inévitables. Le chaînage les gère en stockant les collisions dans des listes liées (complexité moyenne \(O(1 + \alpha)\)). L”adressage ouvert les résout en sondant d’autres alvéoles — sondage linéaire, quadratique ou double hachage.
Le facteur de charge \(\alpha = n/m\) est le paramètre critique. Un redimensionnement en \(O(n)\) (amorti \(O(1)\)) maintient \(\alpha\) sous un seuil raisonnable.
Le
dictPython est une implémentation de haute qualité : ordonné depuis Python 3.7, utilisant l’adressage ouvert, redimensionné dynamiquement. Les clés doivent implémenter__hash__et__eq__de façon cohérente.En Rust,
HashMap<K, V>etHashSet<T>utilisent SipHash par défaut pour la robustesse cryptographique, avec la possibilité de substituer un hasher alternatif pour des performances maximales.Les applications classiques des tables de hachage incluent le dédoublonnage en \(O(n)\), le comptage de fréquences, la mémoïsation, et le cache LRU.
Le chapitre suivant aborde les algorithmes de tri, en commençant par les tris élémentaires dont l’analyse détaillée permet de forger intuitions et outils pour les tris plus avancés.