Programmation dynamique#
La programmation dynamique (dynamic programming, DP) est sans doute le paradigme algorithmique le plus puissant et le plus difficile à maîtriser. Elle résout des problèmes d’optimisation et de dénombrement en exploitant deux propriétés fondamentales : la sous-structure optimale — la solution optimale d’un problème peut être construite à partir des solutions optimales de ses sous-problèmes — et les sous-problèmes chevauchants — les mêmes sous-problèmes sont résolus plusieurs fois lors d’une approche naïve récursive.
Là où le paradigme diviser pour régner convient aux problèmes dont les sous-problèmes sont disjoints (comme dans le tri fusion), la programmation dynamique est le bon outil quand ces sous-problèmes se recouvrent (comme dans le calcul des nombres de Fibonacci). En mémorisant les résultats déjà calculés, on évite les recalculs exponentiels pour atteindre des complexités polynomiales.
Richard Bellman a formalisé ce paradigme dans les années 1950. Le mot « dynamique » ne se réfère pas à la nature dynamique des calculs, mais était un terme choisi pour impressionner les commanditaires militaires de l’époque — c’est Bellman lui-même qui l’a confié.
Principe et définitions#
Définition 83 (Sous-structure optimale)
Un problème possède la propriété de sous-structure optimale si une solution optimale du problème peut être construite à partir des solutions optimales de ses sous-problèmes.
Formellement, si \(\text{OPT}(n)\) désigne la valeur optimale du problème de taille n et si \(\text{OPT}(n)\) peut s’exprimer en fonction de \(\text{OPT}(n_1), \text{OPT}(n_2), \ldots\) pour des tailles \(n_i < n\), alors le problème possède cette propriété.
Contre-exemple : le plus long chemin simple dans un graphe ne possède pas la sous-structure optimale : le plus long chemin de u à w passant par v n’est pas nécessairement la concaténation des plus longs chemins u-v et v-w (ceux-ci pourraient se chevaucher).
Définition 84 (Sous-problèmes chevauchants)
Un problème présente des sous-problèmes chevauchants si un algorithme récursif naïf résout les mêmes sous-problèmes de manière répétée.
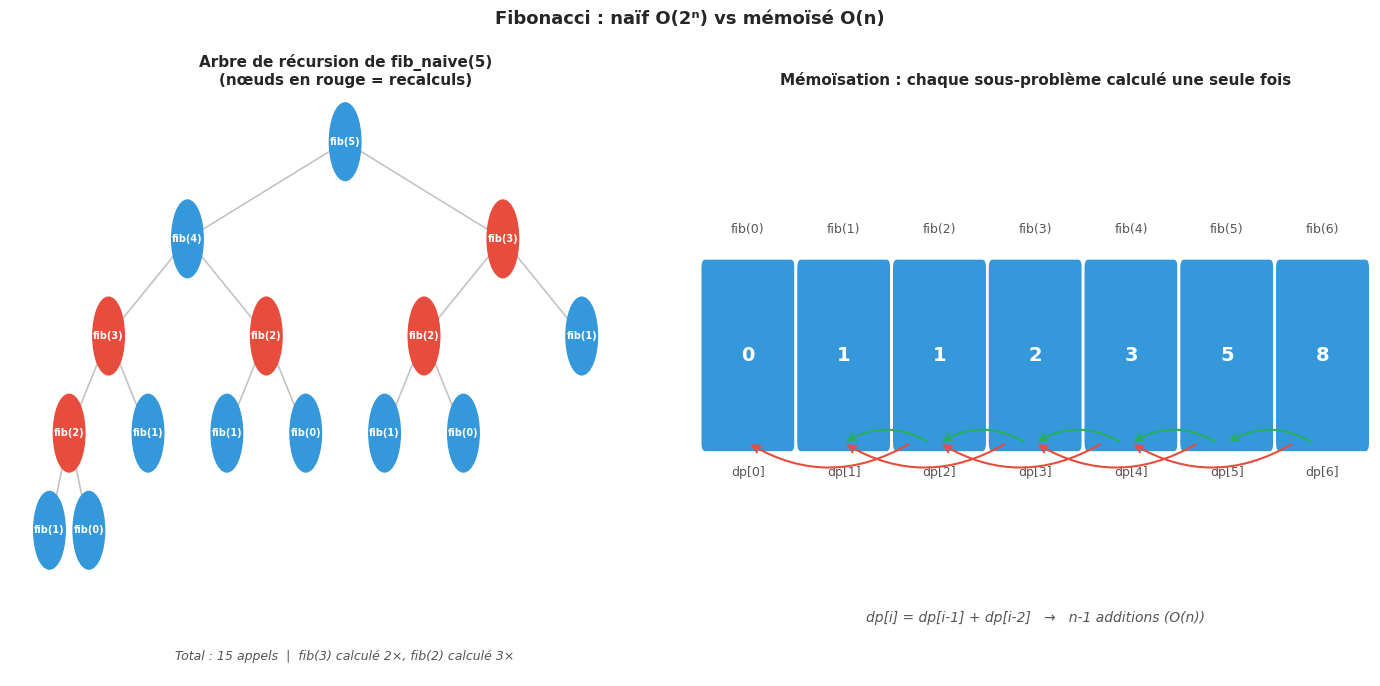
C’est ce qui distingue la programmation dynamique du paradigme diviser pour régner : dans le tri fusion, les sous-problèmes sont disjoints (on ne trie jamais deux fois le même sous-tableau) ; dans le calcul naïf de Fibonacci, fib(n-2) est recalculé par l’appel fib(n) et par l’appel fib(n-1), et ce phénomène se propage exponentiellement.
Définition 85 (Mémoïsation et tabulation)
Il existe deux façons de mettre en œuvre la programmation dynamique :
Mémoïsation (top-down) : on écrit l’algorithme récursif naturel, mais on stocke le résultat de chaque sous-problème dans une table la première fois qu’il est calculé. Les appels suivants retournent immédiatement la valeur mémoïsée.
Tabulation (bottom-up) : on identifie l’ordre dans lequel les sous-problèmes doivent être résolus (du plus petit au plus grand), et on remplit itérativement une table en garantissant que les sous-problèmes nécessaires sont déjà calculés.
Les deux approches ont la même complexité asymptotique, mais la tabulation évite la surcharge des appels récursifs et le risque de débordement de pile. La mémoïsation ne calcule que les sous-problèmes réellement nécessaires.
Fibonacci : du naïf à l’optimal#
L’exemple du calcul des nombres de Fibonacci illustre parfaitement la progression des complexités que la DP permet d’atteindre.
Version naïve : O(2ⁿ)#
def fib_naive(n):
"""
Fibonacci naïf par récursion directe.
Complexité : O(2^n) — chaque appel génère deux appels récursifs.
"""
if n <= 1:
return n
return fib_naive(n - 1) + fib_naive(n - 2)
# Comptage du nombre d'appels
call_count = [0]
def fib_naive_counted(n):
call_count[0] += 1
if n <= 1:
return n
return fib_naive_counted(n - 1) + fib_naive_counted(n - 2)
print("Nombre d'appels récursifs pour fib_naive(n) :")
for n in [5, 10, 15, 20, 25]:
call_count[0] = 0
result = fib_naive_counted(n)
print(f" fib({n:2d}) = {result:8d} → {call_count[0]:8d} appels "
f"(2^{n} = {2**n})")
Nombre d'appels récursifs pour fib_naive(n) :
fib( 5) = 5 → 15 appels (2^5 = 32)
fib(10) = 55 → 177 appels (2^10 = 1024)
fib(15) = 610 → 1973 appels (2^15 = 32768)
fib(20) = 6765 → 21891 appels (2^20 = 1048576)
fib(25) = 75025 → 242785 appels (2^25 = 33554432)
Remarque 35
L’inefficacité de l’approche naïve est dramatique : pour calculer fib(5), on calcule fib(3) deux fois, fib(2) trois fois, fib(1) cinq fois et fib(0) trois fois. Plus généralement, le nombre d’appels est exactement 2·fib(n+1) - 1, ce qui est exponentiel. L’arbre de récursion a une structure de sous-problèmes chevauchants massivement redondante.
Version mémoïsée : O(n)#
def fib_memo(n, cache=None):
"""
Fibonacci avec mémoïsation (top-down).
Complexité : O(n) temps, O(n) espace (cache + pile de récursion).
"""
if cache is None:
cache = {}
if n in cache:
return cache[n]
if n <= 1:
return n
cache[n] = fib_memo(n - 1, cache) + fib_memo(n - 2, cache)
return cache[n]
# Version avec functools.lru_cache (équivalent idiomatique Python)
@functools.lru_cache(maxsize=None)
def fib_lru(n):
"""Fibonacci avec cache LRU de Python (mémoïsation automatique)."""
if n <= 1:
return n
return fib_lru(n - 1) + fib_lru(n - 2)
# Tests de correction
for n in range(20):
assert fib_naive(n) == fib_memo(n) == fib_lru(n), f"Divergence à n={n}"
print("Fibonacci mémoïsé : tous les tests passent.")
print(f"fib_memo(50) = {fib_memo(50)}")
print(f"fib_lru(100) = {fib_lru(100)}")
Fibonacci mémoïsé : tous les tests passent.
fib_memo(50) = 12586269025
fib_lru(100) = 354224848179261915075
Version tabulée : O(n) temps, O(1) espace#
def fib_tabulated(n):
"""
Fibonacci tabulé (bottom-up).
Complexité : O(n) temps, O(n) espace.
"""
if n <= 1:
return n
dp = [0] * (n + 1)
dp[1] = 1
for i in range(2, n + 1):
dp[i] = dp[i - 1] + dp[i - 2]
return dp[n]
def fib_optimised(n):
"""
Fibonacci avec espace O(1) : on ne garde que les deux dernières valeurs.
Complexité : O(n) temps, O(1) espace.
"""
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n + 1):
a, b = b, a + b
return b
# Vérification
for n in range(50):
assert fib_tabulated(n) == fib_optimised(n) == fib_lru(n)
print("Toutes les versions de Fibonacci sont cohérentes.")
print()
# Comparaison des performances
import time
sizes = [10, 20, 30, 35]
print("Comparaison des temps d'exécution :")
print(f"{'n':>5} {'Naïf (s)':>12} {'Mémoïsé (s)':>14} {'Tabulé (s)':>13}")
for n in sizes:
t0 = time.perf_counter()
if n <= 35:
fib_naive(n)
t_naive = time.perf_counter() - t0
t0 = time.perf_counter()
for _ in range(1000):
fib_memo(n)
t_memo = (time.perf_counter() - t0) / 1000
t0 = time.perf_counter()
for _ in range(1000):
fib_tabulated(n)
t_tab = (time.perf_counter() - t0) / 1000
print(f" {n:3d} {t_naive:12.6f} {t_memo:14.9f} {t_tab:13.9f}")
Toutes les versions de Fibonacci sont cohérentes.
Comparaison des temps d'exécution :
n Naïf (s) Mémoïsé (s) Tabulé (s)
10 0.000019 0.000003210 0.000001180
20 0.001898 0.000006637 0.000002034
30 0.228026 0.000009984 0.000002854
35 2.468651 0.000011646 0.000003251
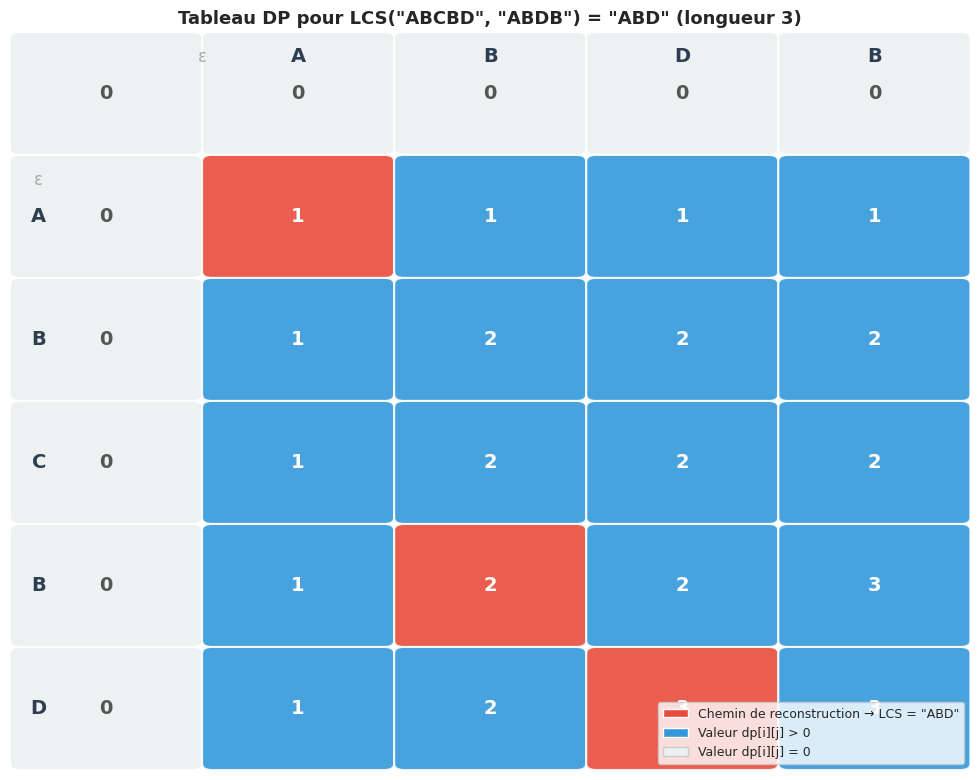
Plus longue sous-séquence commune (LCS)#
Définition et formulation#
Définition 86 (Plus longue sous-séquence commune)
La plus longue sous-séquence commune (Longest Common Subsequence, LCS) de deux séquences X et Y est la séquence Z de longueur maximale telle que Z soit une sous-séquence de X et une sous-séquence de Y (sans nécessairement être contiguë).
Formule de récurrence. Notons \(\text{LCS}(i, j)\) la longueur de la LCS de \(X[0..i]\) et \(Y[0..j]\) :
Complexité : O(mn) en temps et espace, où m = |X| et n = |Y|. On peut réduire l’espace à O(min(m, n)) en ne conservant que deux lignes consécutives du tableau.
def lcs_length(X, Y):
"""
Calcule la longueur de la LCS de X et Y par tabulation.
Complexité : O(mn) temps et espace.
Retourne le tableau dp complet (nécessaire pour la reconstruction).
"""
m, n = len(X), len(Y)
# dp[i][j] = longueur LCS de X[:i] et Y[:j]
dp = [[0] * (n + 1) for _ in range(m + 1)]
for i in range(1, m + 1):
for j in range(1, n + 1):
if X[i - 1] == Y[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp
def lcs_reconstruct(dp, X, Y):
"""
Reconstruit la LCS à partir du tableau dp.
Complexité : O(m + n).
"""
i, j = len(X), len(Y)
lcs = []
while i > 0 and j > 0:
if X[i - 1] == Y[j - 1]:
lcs.append(X[i - 1])
i -= 1
j -= 1
elif dp[i - 1][j] > dp[i][j - 1]:
i -= 1
else:
j -= 1
return ''.join(reversed(lcs)) if isinstance(X, str) else list(reversed(lcs))
def lcs(X, Y):
"""Retourne la LCS de X et Y (longueur + séquence)."""
dp = lcs_length(X, Y)
seq = lcs_reconstruct(dp, X, Y)
return dp[len(X)][len(Y)], seq
# Tests
assert lcs("ABCBDAB", "BDCAB")[0] == 4
length, seq = lcs("ABCBDAB", "BDCAB")
print(f"LCS('ABCBDAB', 'BDCAB') = '{seq}' (longueur {length})")
length2, seq2 = lcs("AGGTAB", "GXTXAYB")
print(f"LCS('AGGTAB', 'GXTXAYB') = '{seq2}' (longueur {length2})")
# Application : diff entre deux fichiers
lines_v1 = ['def foo():', ' x = 1', ' y = 2', ' return x + y']
lines_v2 = ['def foo():', ' x = 10', ' y = 2', ' z = 3', ' return x + y + z']
_, common = lcs(lines_v1, lines_v2)
print("\nLignes communes entre les deux versions :")
for line in common:
print(f" {line}")
LCS('ABCBDAB', 'BDCAB') = 'BDAB' (longueur 4)
LCS('AGGTAB', 'GXTXAYB') = 'GTAB' (longueur 4)
Lignes communes entre les deux versions :
def foo():
y = 2
Visualisation du tableau DP#
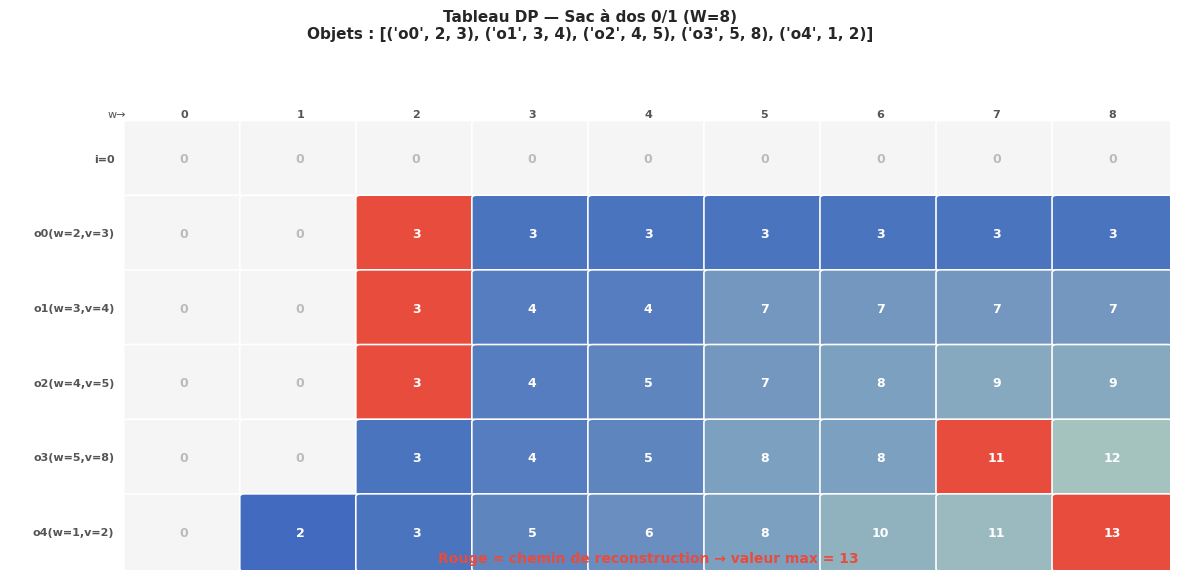
Problème du sac à dos 0/1 (Knapsack)#
Formulation et récurrence#
Définition 87 (Problème du sac à dos 0/1)
Étant donné n objets, chacun caractérisé par un poids \(w_i > 0\) et une valeur \(v_i > 0\), et un sac à dos de capacité maximale W, le problème du sac à dos 0/1 consiste à sélectionner un sous-ensemble d’objets (chaque objet est soit pris, soit laissé — d’où « 0/1 ») de poids total ≤ W maximisant la valeur totale.
Formule de récurrence. Notons \(\text{dp}[i][w]\) la valeur maximale obtenue en utilisant uniquement les i premiers objets avec une capacité de poids w :
Complexité : O(nW) en temps et espace. Ce problème est NP-difficile en général (W peut être exponentiel en la taille de l’entrée), mais l’algorithme DP est pseudo-polynomial car sa complexité dépend de la valeur W, pas de sa représentation binaire.
def knapsack_01(weights, values, W):
"""
Sac à dos 0/1 par programmation dynamique.
Paramètres
----------
weights : list[int]
Poids des objets.
values : list[int]
Valeurs des objets.
W : int
Capacité maximale du sac.
Retourne
-------
max_value : int
Valeur maximale réalisable.
selected : list[int]
Indices des objets sélectionnés.
dp : list[list[int]]
Tableau DP complet (pour la reconstruction et la visualisation).
"""
n = len(weights)
dp = [[0] * (W + 1) for _ in range(n + 1)]
for i in range(1, n + 1):
wi, vi = weights[i - 1], values[i - 1]
for w in range(W + 1):
if wi > w:
dp[i][w] = dp[i - 1][w]
else:
dp[i][w] = max(dp[i - 1][w], vi + dp[i - 1][w - wi])
# Reconstruction : quels objets ont été sélectionnés ?
selected = []
w = W
for i in range(n, 0, -1):
if dp[i][w] != dp[i - 1][w]:
selected.append(i - 1) # Objet i-1 sélectionné
w -= weights[i - 1]
selected.reverse()
return dp[n][W], selected, dp
# Exemple
weights = [2, 3, 4, 5, 1]
values = [3, 4, 5, 8, 2]
W = 8
max_val, selected, dp_table = knapsack_01(weights, values, W)
print(f"Capacité W = {W}")
print(f"Objets : poids={weights}, valeurs={values}")
print(f"Valeur maximale : {max_val}")
print(f"Objets sélectionnés : {selected}")
total_weight = sum(weights[i] for i in selected)
total_value = sum(values[i] for i in selected)
print(f" → poids total={total_weight}, valeur totale={total_value}")
print(f" → contrainte respectée : {total_weight <= W}")
Capacité W = 8
Objets : poids=[2, 3, 4, 5, 1], valeurs=[3, 4, 5, 8, 2]
Valeur maximale : 13
Objets sélectionnés : [0, 3, 4]
→ poids total=8, valeur totale=13
→ contrainte respectée : True
def knapsack_01_space_optimised(weights, values, W):
"""
Sac à dos 0/1 avec espace O(W) (une seule ligne).
On ne peut pas reconstruire la solution avec cette version.
"""
n = len(weights)
dp = [0] * (W + 1)
for i in range(n):
# Parcours en décroissant pour éviter d'utiliser l'objet i deux fois
for w in range(W, weights[i] - 1, -1):
dp[w] = max(dp[w], values[i] + dp[w - weights[i]])
return dp[W]
assert knapsack_01_space_optimised(weights, values, W) == max_val
print(f"\nVersion optimisée espace : valeur = {knapsack_01_space_optimised(weights, values, W)}")
Version optimisée espace : valeur = 13
Distance d’édition (Levenshtein)#
Définition 88 (Distance d’édition)
La distance d’édition (ou distance de Levenshtein) entre deux chaînes s et t est le nombre minimal d’opérations élémentaires nécessaires pour transformer s en t, où les opérations autorisées sont :
Insertion d’un caractère.
Suppression d’un caractère.
Substitution d’un caractère par un autre.
Formule de récurrence. Notons \(\text{dp}[i][j]\) la distance d’édition entre \(s[0..i]\) et \(t[0..j]\) :
Complexité : O(mn) en temps, O(mn) en espace (réductible à O(min(m,n))).
def edit_distance(s, t):
"""
Distance d'édition de Levenshtein entre s et t.
Complexité : O(mn) temps et espace.
"""
m, n = len(s), len(t)
dp = [[0] * (n + 1) for _ in range(m + 1)]
# Cas de base : transformer depuis/vers la chaîne vide
for i in range(m + 1):
dp[i][0] = i
for j in range(n + 1):
dp[0][j] = j
for i in range(1, m + 1):
for j in range(1, n + 1):
if s[i - 1] == t[j - 1]:
dp[i][j] = dp[i - 1][j - 1]
else:
dp[i][j] = 1 + min(
dp[i - 1][j], # Suppression dans s
dp[i][j - 1], # Insertion dans s
dp[i - 1][j - 1], # Substitution
)
return dp[m][n], dp
def edit_distance_space_opt(s, t):
"""Distance d'édition avec espace O(min(m,n))."""
if len(s) < len(t):
s, t = t, s
m, n = len(s), len(t)
prev = list(range(n + 1))
for i in range(1, m + 1):
curr = [i] + [0] * n
for j in range(1, n + 1):
if s[i - 1] == t[j - 1]:
curr[j] = prev[j - 1]
else:
curr[j] = 1 + min(prev[j], curr[j - 1], prev[j - 1])
prev = curr
return prev[n]
def edit_distance_operations(s, t):
"""Retourne la séquence d'opérations pour transformer s en t."""
dist, dp = edit_distance(s, t)
operations = []
i, j = len(s), len(t)
while i > 0 or j > 0:
if i > 0 and j > 0 and s[i-1] == t[j-1]:
i -= 1
j -= 1
elif i > 0 and j > 0 and dp[i][j] == dp[i-1][j-1] + 1:
operations.append(f"Substitution : s[{i-1}]='{s[i-1]}' → '{t[j-1]}'")
i -= 1
j -= 1
elif i > 0 and dp[i][j] == dp[i-1][j] + 1:
operations.append(f"Suppression : s[{i-1}]='{s[i-1]}'")
i -= 1
else:
operations.append(f"Insertion : '{t[j-1]}' après position {i}")
j -= 1
return dist, list(reversed(operations))
# Tests et exemples
assert edit_distance("", "abc")[0] == 3
assert edit_distance("abc", "")[0] == 3
assert edit_distance("abc", "abc")[0] == 0
assert edit_distance("kitten", "sitting")[0] == 3
assert edit_distance("sunday", "saturday")[0] == 3
print("Distance d'édition correcte.")
print()
exemples = [
("kitten", "sitting"),
("dimanche", "samedi"),
("algorithme", "logarithme"),
("python", "cython"),
]
for s, t in exemples:
d, ops = edit_distance_operations(s, t)
print(f"dist('{s}', '{t}') = {d}")
for op in ops:
print(f" {op}")
print()
Distance d'édition correcte.
dist('kitten', 'sitting') = 3
Substitution : s[0]='k' → 's'
Substitution : s[4]='e' → 'i'
Insertion : 'g' après position 6
dist('dimanche', 'samedi') = 7
Suppression : s[0]='d'
Suppression : s[1]='i'
Substitution : s[2]='m' → 's'
Substitution : s[4]='n' → 'm'
Substitution : s[5]='c' → 'e'
Substitution : s[6]='h' → 'd'
Substitution : s[7]='e' → 'i'
dist('algorithme', 'logarithme') = 3
Substitution : s[0]='a' → 'l'
Substitution : s[1]='l' → 'o'
Substitution : s[3]='o' → 'a'
dist('python', 'cython') = 1
Substitution : s[0]='p' → 'c'
Récapitulatif des quatre problèmes DP#
Implémentation Rust#
/// Fibonacci tabulé en Rust avec espace O(1).
/// Retourne le n-ième nombre de Fibonacci.
pub fn fibonacci(n: u64) -> u128 {
if n <= 1 {
return n as u128;
}
let (mut a, mut b) = (0u128, 1u128);
for _ in 2..=n {
let c = a.saturating_add(b);
a = b;
b = c;
}
b
}
/// Plus longue sous-séquence commune (LCS) tabulée.
/// Retourne la longueur de la LCS.
pub fn lcs_length(x: &[u8], y: &[u8]) -> usize {
let (m, n) = (x.len(), y.len());
// Optimisation : deux lignes seulement
let mut prev = vec![0usize; n + 1];
let mut curr = vec![0usize; n + 1];
for i in 1..=m {
for j in 1..=n {
curr[j] = if x[i - 1] == y[j - 1] {
prev[j - 1] + 1
} else {
prev[j].max(curr[j - 1])
};
}
std::mem::swap(&mut prev, &mut curr);
curr.iter_mut().for_each(|x| *x = 0);
}
prev[n]
}
/// Sac à dos 0/1 avec espace O(W).
pub fn knapsack_01(weights: &[usize], values: &[usize], capacity: usize) -> usize {
let mut dp = vec![0usize; capacity + 1];
for (i, &wi) in weights.iter().enumerate() {
// Parcours en décroissant : garantit que chaque objet est utilisé au plus une fois
for w in (wi..=capacity).rev() {
dp[w] = dp[w].max(values[i] + dp[w - wi]);
}
}
dp[capacity]
}
/// Distance d'édition de Levenshtein avec espace O(min(m, n)).
pub fn edit_distance(s: &[u8], t: &[u8]) -> usize {
let (s, t) = if s.len() >= t.len() { (s, t) } else { (t, s) };
let n = t.len();
let mut prev: Vec<usize> = (0..=n).collect();
for (i, &sc) in s.iter().enumerate() {
let mut curr = vec![0usize; n + 1];
curr[0] = i + 1;
for (j, &tc) in t.iter().enumerate() {
curr[j + 1] = if sc == tc {
prev[j]
} else {
1 + prev[j + 1].min(curr[j]).min(prev[j])
};
}
prev = curr;
}
prev[n]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_fibonacci() {
assert_eq!(fibonacci(0), 0);
assert_eq!(fibonacci(1), 1);
assert_eq!(fibonacci(10), 55);
assert_eq!(fibonacci(20), 6765);
}
#[test]
fn test_lcs() {
assert_eq!(lcs_length(b"ABCBDAB", b"BDCAB"), 4);
assert_eq!(lcs_length(b"AGGTAB", b"GXTXAYB"), 4);
assert_eq!(lcs_length(b"", b"ABC"), 0);
}
#[test]
fn test_edit_distance() {
assert_eq!(edit_distance(b"kitten", b"sitting"), 3);
assert_eq!(edit_distance(b"", b"abc"), 3);
assert_eq!(edit_distance(b"abc", b"abc"), 0);
}
}
Résumé#
Ce chapitre a introduit la programmation dynamique, paradigme d’optimisation fondé sur deux propriétés — la sous-structure optimale et les sous-problèmes chevauchants — et deux implémentations complémentaires : la mémoïsation (top-down) et la tabulation (bottom-up).
À travers quatre exemples canoniques, nous avons illustré la démarche complète : identifier la structure des sous-problèmes, écrire la récurrence, choisir l’ordre de remplissage du tableau, et reconstruire la solution optimale :
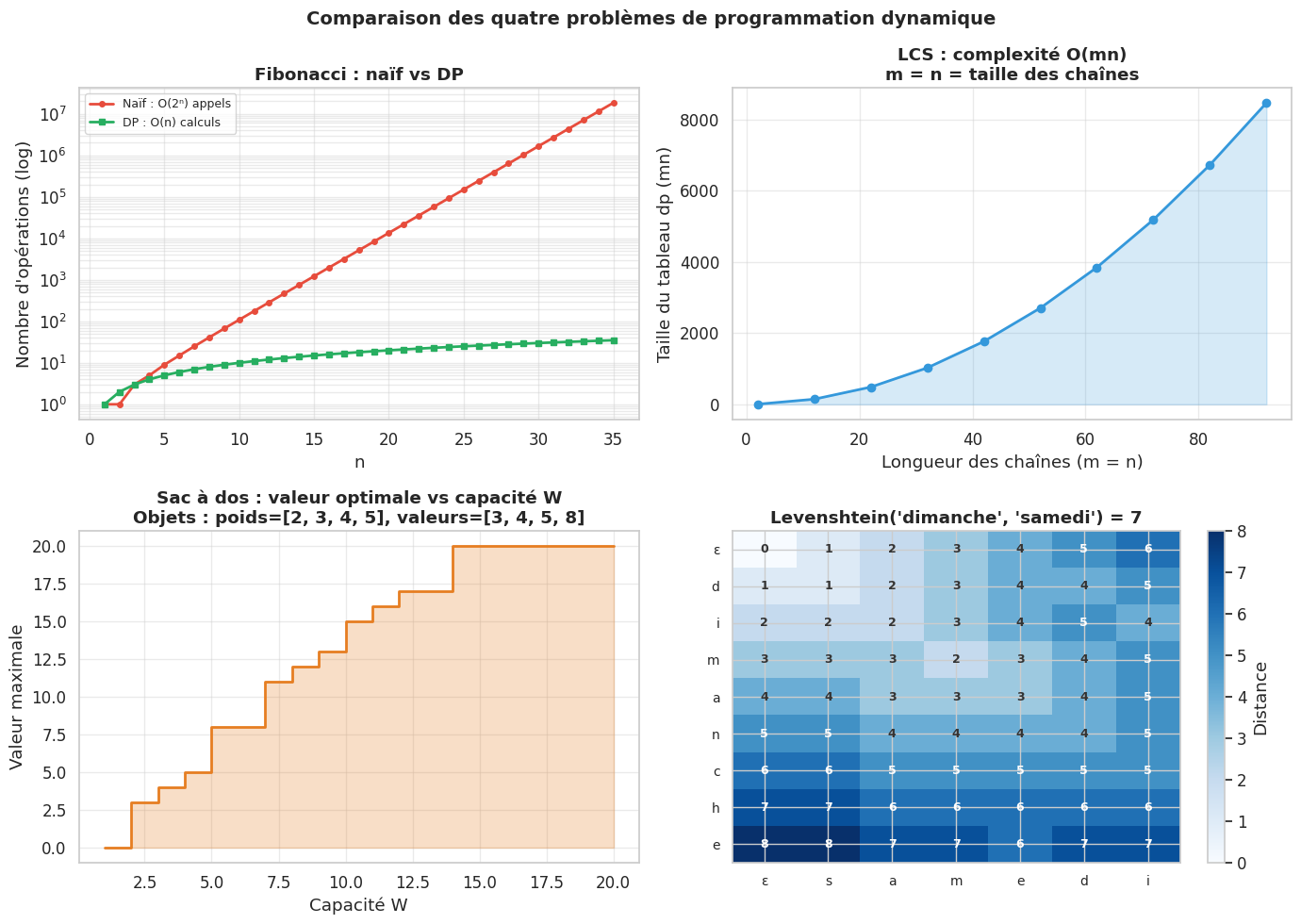
Fibonacci : la progression de O(2ⁿ) à O(n) puis à O(1) espace illustre comment la mémoïsation élimine des recalculs exponentiels, et comment la tabulation permet d’optimiser encore l’espace en ne conservant que l’essentiel.
LCS : le tableau 2D dp[i][j] capture la longueur de la sous-séquence commune optimale entre les i premiers caractères de X et les j premiers de Y. La reconstruction par remontée du tableau produit la séquence elle-même.
Sac à dos 0/1 : problème NP-difficile résolu en temps pseudo-polynomial O(nW). Le parcours en décroissant de la capacité dans la version optimisée espace garantit que chaque objet n’est sélectionné qu’une seule fois.
Distance de Levenshtein : le tableau dp[i][j] compte le nombre minimal d’insertions, suppressions et substitutions pour transformer les i premiers caractères de s en les j premiers de t. Ce problème est omniprésent dans les correcteurs orthographiques, les outils de comparaison de textes et la bioinformatique.
Le chapitre suivant abordera les algorithmes gloutons, un paradigme plus rapide mais plus limité que la programmation dynamique : à chaque étape, on prend la décision localement optimale sans revenir en arrière. Nous verrons sur quels problèmes cette stratégie est correcte et quand elle échoue.