Tris linéaires#
Les algorithmes de tri que nous avons étudiés jusqu’ici — tri fusion, tri rapide, tri par tas — partagent une propriété fondamentale : ils procèdent par comparaisons entre éléments. On compare deux éléments, on décide lequel est le plus petit, et on organise les données en conséquence. Cette approche est universelle et s’applique à n’importe quel type de données pourvu qu’il existe une relation d’ordre total. Mais elle a un coût : il existe une borne inférieure théorique de O(n log n) comparaisons pour trier n éléments par cette méthode.
Dans ce chapitre, nous allons d’abord prouver rigoureusement cette borne, puis nous verrons comment la briser en exploitant des hypothèses supplémentaires sur les données. Les tris linéaires — tri par comptage, tri par base et tri par casiers — atteignent O(n) en temps, au prix d’une restriction sur la nature des données triées.
La borne inférieure Ω(n log n) pour les tris par comparaison#
L’arbre de décision#
Pour prouver que tout algorithme de tri par comparaison nécessite au moins Ω(n log n) comparaisons dans le pire cas, on modélise l’exécution de l’algorithme par un arbre de décision.
Définition 57 (Arbre de décision d’un algorithme de tri)
L”arbre de décision d’un algorithme de tri par comparaison sur n éléments est un arbre binaire dont :
Chaque nœud interne est étiqueté par une comparaison entre deux éléments, notée \(i : j\) (« comparer l’élément d’indice i à l’élément d’indice j »).
La branche gauche correspond au résultat \(a_i \leq a_j\), la branche droite à \(a_i > a_j\).
Chaque feuille correspond à une permutation particulière de l’entrée, c’est-à-dire à un ordre final des éléments.
Chaque chemin de la racine à une feuille représente la séquence de comparaisons effectuées par l’algorithme pour un ordre d’entrée donné.
Remarque 25
Un arbre de décision pour trier n éléments doit avoir au moins n! feuilles, car il doit être capable de distinguer les n! permutations possibles de l’entrée. En effet, si deux permutations distinctes menaient à la même feuille, l’algorithme produirait le même résultat pour deux ordres d’entrée différents, ce qui est incorrect pour au moins l’un d’eux.
La preuve formelle#
Définition 58 (Hauteur d’un arbre binaire)
La hauteur d’un arbre binaire est la longueur du chemin le plus long de la racine à une feuille. Un arbre de hauteur h possède au plus \(2^h\) feuilles.
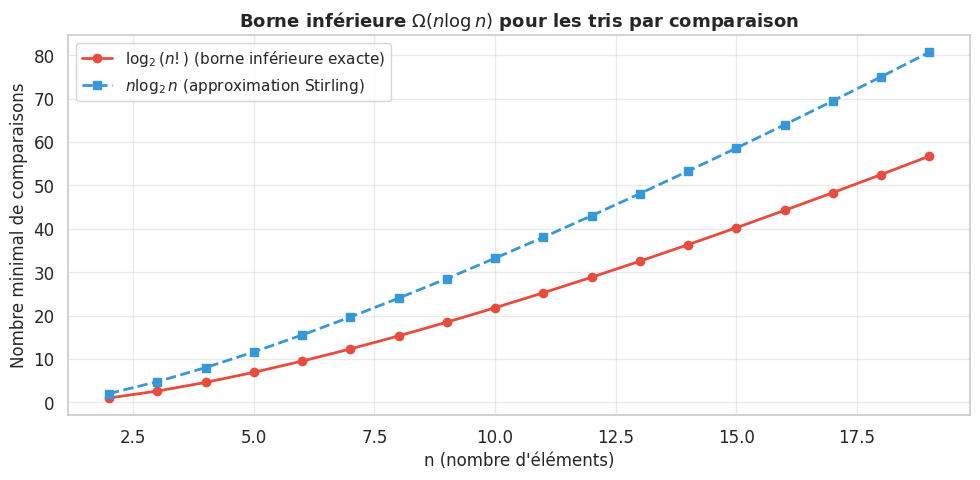
Puisque l’arbre de décision a au moins n! feuilles et au plus \(2^h\) feuilles pour une hauteur h, on obtient :
Par la formule de Stirling, \(\ln(n!) = n \ln n - n + O(\ln n)\), ce qui donne :
Définition 59 (Borne inférieure des tris par comparaison)
Tout algorithme de tri par comparaison effectue au moins \(\Omega(n \log n)\) comparaisons dans le pire cas. Cette borne est atteinte par les algorithmes de tri fusion et tri par tas, qui sont donc optimaux dans ce modèle.
Exemple 10 (Calcul pour n = 3)
Pour n = 3 éléments, il existe 3! = 6 permutations possibles. L’arbre de décision doit avoir au moins 6 feuilles, donc une hauteur h telle que \(2^h \geq 6\), soit \(h \geq \lceil \log_2 6 \rceil = 3\).
Autrement dit, il faut au moins 3 comparaisons dans le pire cas pour trier 3 éléments. On peut vérifier qu’aucun algorithme ne fait mieux : les algorithmes naïfs comme le tri par insertion font exactement 3 comparaisons dans le pire cas sur 3 éléments.
Tri par comptage (Counting Sort)#
Principe et complexité#
Le tri par comptage est le premier algorithme qui brise la barrière O(n log n). Il repose sur une hypothèse forte : les éléments à trier sont des entiers appartenant à un intervalle connu \([0, k-1]\).
Définition 60 (Tri par comptage)
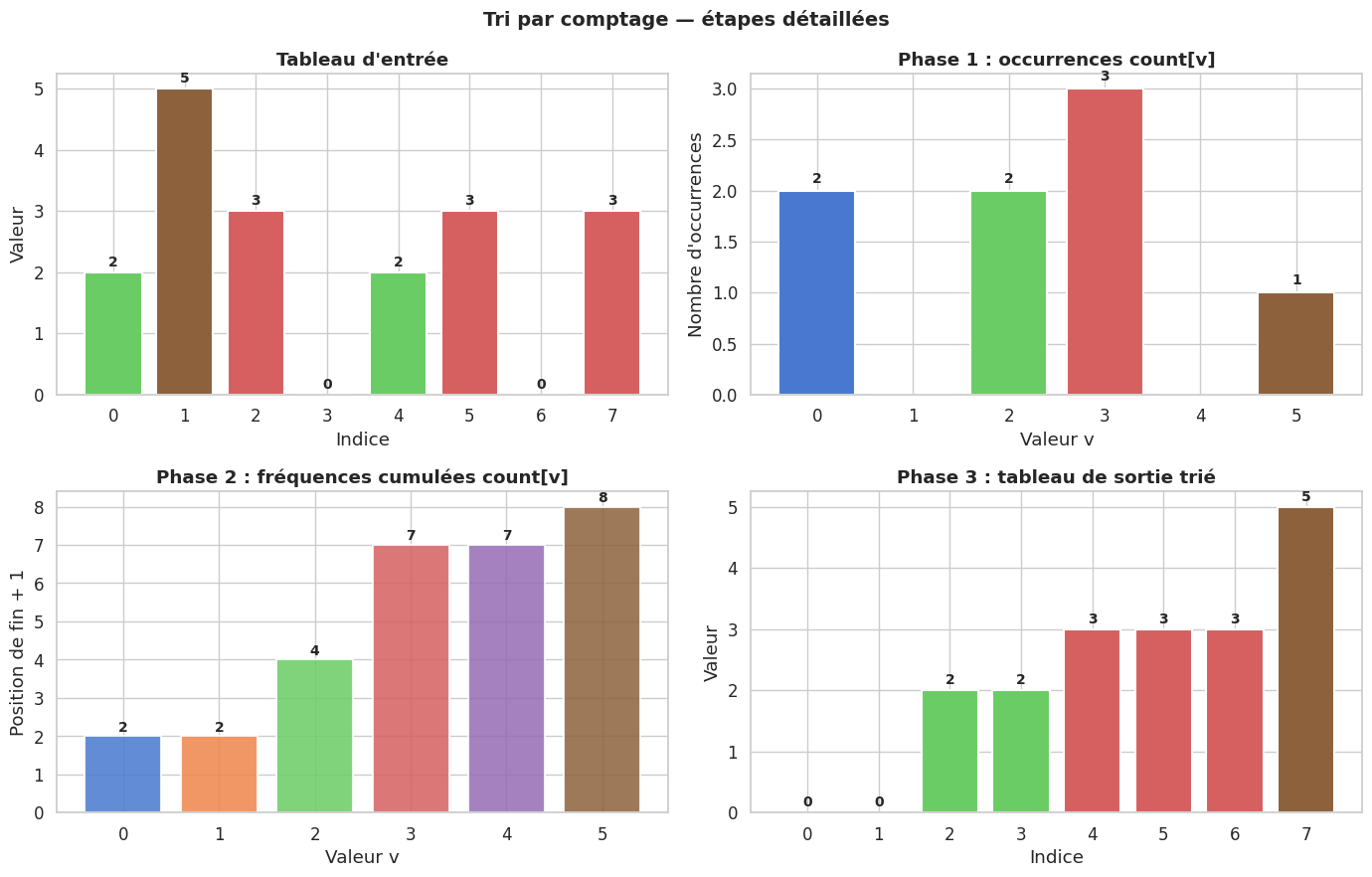
Le tri par comptage (counting sort) trie n entiers appartenant à \(\{0, 1, \ldots, k-1\}\) en trois phases :
Comptage. On parcourt le tableau d’entrée et on compte le nombre d’occurrences de chaque valeur dans un tableau auxiliaire
countde taille k.Cumul. On transforme
counten tableau de fréquences cumulées :count[i]indique désormais le nombre d’éléments inférieurs ou égaux à i.Placement. On parcourt le tableau d’entrée à rebours et on place chaque élément à sa position correcte dans le tableau de sortie, en décrémentant
countà chaque placement.
La complexité est O(n + k) en temps et O(n + k) en espace auxiliaire.
Remarque 26
La traversée à rebours dans la phase de placement est cruciale pour garantir la stabilité de l’algorithme : deux éléments de même valeur conservent leur ordre relatif d’entrée dans la sortie. Cette propriété est essentielle lorsque le tri par comptage est utilisé comme sous-routine du tri par base.
Si k = O(n), la complexité totale est O(n), ce qui est linéaire. En pratique, le tri par comptage est particulièrement efficace lorsque k est significativement plus petit que n, par exemple pour trier des notes (0-100) ou des âges (0-150).
Implémentation Python#
def counting_sort(arr, k=None):
"""
Trie un tableau d'entiers non négatifs par comptage.
Paramètres
----------
arr : list[int]
Tableau d'entiers dans [0, k-1].
k : int, optionnel
Borne supérieure exclusive des valeurs. Si None, calculée automatiquement.
Retourne
-------
list[int]
Tableau trié (stable).
"""
if not arr:
return []
if k is None:
k = max(arr) + 1
# Phase 1 : comptage des occurrences
count = [0] * k
for x in arr:
count[x] += 1
# Phase 2 : transformation en fréquences cumulées
for i in range(1, k):
count[i] += count[i - 1]
# Phase 3 : placement à rebours (stabilité)
output = [0] * len(arr)
for x in reversed(arr):
count[x] -= 1
output[count[x]] = x
return output
# Tests de correction
assert counting_sort([]) == []
assert counting_sort([3, 1, 4, 1, 5, 9, 2, 6, 5, 3]) == [1, 1, 2, 3, 3, 4, 5, 5, 6, 9]
assert counting_sort([0]) == [0]
assert counting_sort([5, 4, 3, 2, 1, 0]) == [0, 1, 2, 3, 4, 5]
assert counting_sort([2, 2, 2, 2]) == [2, 2, 2, 2]
print("Tous les tests passent.")
print("Exemple : counting_sort([3, 1, 4, 1, 5, 9, 2, 6, 5, 3]) =",
counting_sort([3, 1, 4, 1, 5, 9, 2, 6, 5, 3]))
Tous les tests passent.
Exemple : counting_sort([3, 1, 4, 1, 5, 9, 2, 6, 5, 3]) = [1, 1, 2, 3, 3, 4, 5, 5, 6, 9]
def counting_sort_trace(arr, k=None):
"""Version avec trace détaillée des étapes."""
if not arr:
return []
if k is None:
k = max(arr) + 1
print(f"Tableau d'entrée : {arr}")
print(f"Plage des valeurs : [0, {k-1}]")
print()
count = [0] * k
for x in arr:
count[x] += 1
print(f"Phase 1 — Comptage : count = {count}")
for i in range(1, k):
count[i] += count[i - 1]
print(f"Phase 2 — Cumul : count = {count}")
output = [0] * len(arr)
for x in reversed(arr):
count[x] -= 1
output[count[x]] = x
print(f"Phase 3 — Placement: output = {output}")
return output
counting_sort_trace([2, 5, 3, 0, 2, 3, 0, 3])
Tableau d'entrée : [2, 5, 3, 0, 2, 3, 0, 3]
Plage des valeurs : [0, 5]
Phase 1 — Comptage : count = [2, 0, 2, 3, 0, 1]
Phase 2 — Cumul : count = [2, 2, 4, 7, 7, 8]
Phase 3 — Placement: output = [0, 0, 2, 2, 3, 3, 3, 5]
[0, 0, 2, 2, 3, 3, 3, 5]
Implémentation Rust#
/// Tri par comptage pour des entiers dans [0, k-1].
/// Complexité : O(n + k) temps, O(n + k) espace.
pub fn counting_sort(arr: &[usize], k: usize) -> Vec<usize> {
if arr.is_empty() {
return Vec::new();
}
// Phase 1 : comptage
let mut count = vec![0usize; k];
for &x in arr {
count[x] += 1;
}
// Phase 2 : fréquences cumulées
for i in 1..k {
count[i] += count[i - 1];
}
// Phase 3 : placement à rebours (stable)
let mut output = vec![0usize; arr.len()];
for &x in arr.iter().rev() {
count[x] -= 1;
output[count[x]] = x;
}
output
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_counting_sort() {
assert_eq!(counting_sort(&[], 0), vec![]);
assert_eq!(
counting_sort(&[3, 1, 4, 1, 5, 2, 6, 5, 3], 10),
vec![1, 1, 2, 3, 3, 4, 5, 5, 6]
);
assert_eq!(counting_sort(&[0, 0, 0], 1), vec![0, 0, 0]);
}
}
Visualisation étape par étape#
Tri par base (Radix Sort)#
Principe général#
Le tri par base généralise le tri par comptage aux entiers de grande valeur en les traitant chiffre par chiffre, de la position la moins significative (LSD, Least Significant Digit) à la plus significative (MSD, Most Significant Digit), ou inversement.
Définition 61 (Tri par base LSD)
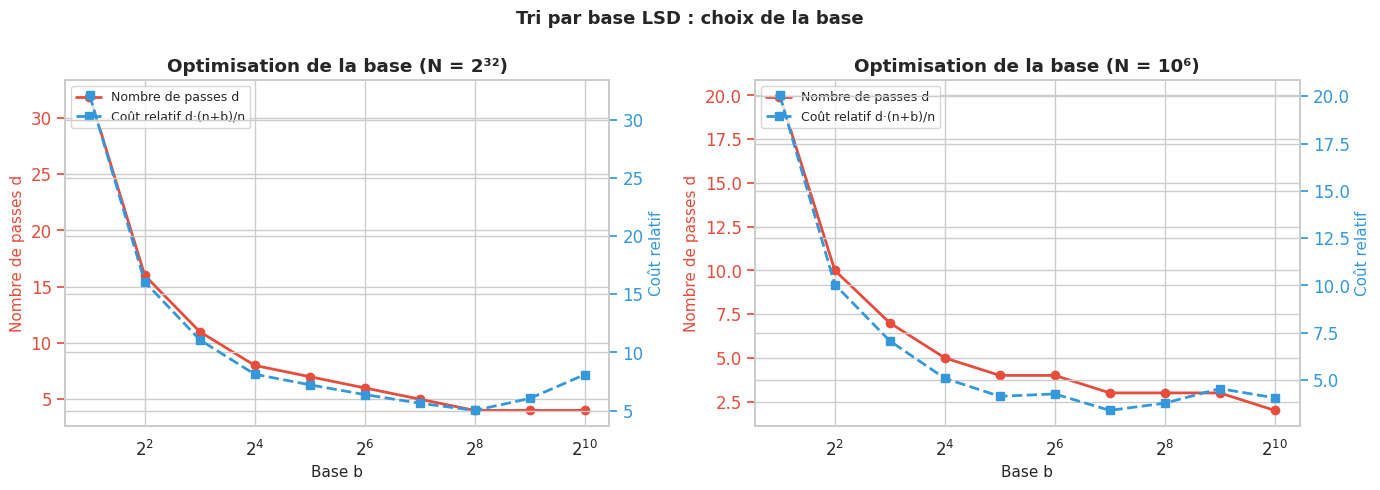
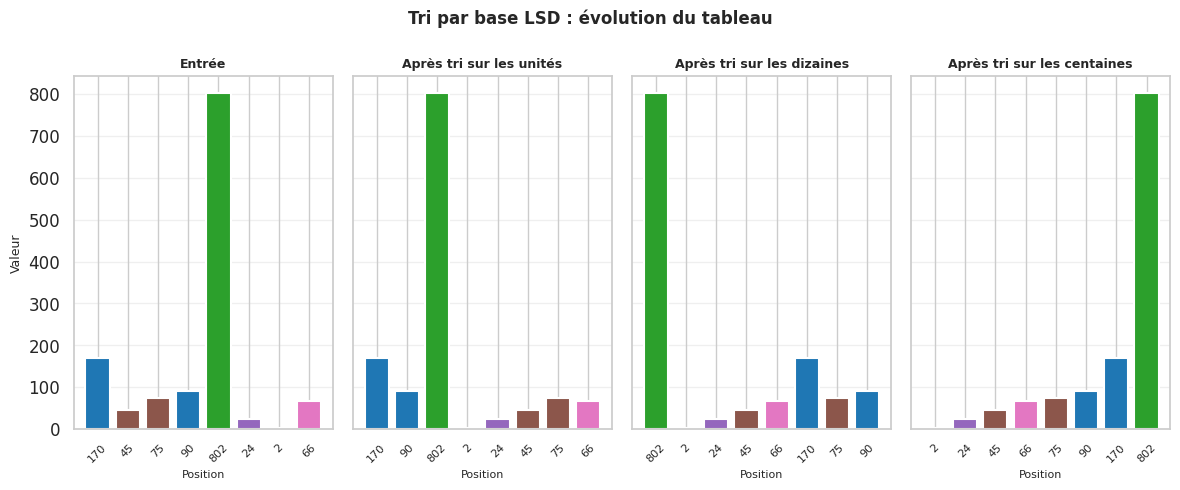
Le tri par base LSD (Least Significant Digit radix sort) trie des entiers écrits en base b en d passes, où d est le nombre de chiffres dans la représentation en base b. À chaque passe p (de 0 à d-1), on trie le tableau sur le p-ième chiffre (en partant du moins significatif) en utilisant un tri stable, typiquement le tri par comptage.
La complexité est O(d · (n + b)) en temps et O(n + b) en espace auxiliaire.
Remarque 27
La stabilité du sous-tri est absolument cruciale pour le tri LSD. Voici pourquoi : après avoir trié sur le chiffre des unités, les éléments sont en ordre croissant sur ce chiffre. Lorsqu’on trie ensuite sur le chiffre des dizaines, les éléments ayant le même chiffre des dizaines doivent rester dans leur ordre relatif issu du tri précédent (les unités). Si le sous-tri n’était pas stable, cette information serait perdue.
Pour des entiers dans \([0, N-1]\), on choisit généralement \(b = 2^8 = 256\) et \(d = \lceil \log_{256} N \rceil\), ce qui donne en pratique 1 à 4 passes pour des entiers 32 bits.
Implémentation Python (LSD et MSD)#
def radix_sort_lsd(arr, base=10):
"""
Tri par base LSD (du moins significatif au plus significatif).
Paramètres
----------
arr : list[int]
Tableau d'entiers non négatifs.
base : int
Base de numération (10 par défaut).
Retourne
-------
list[int]
Tableau trié.
"""
if not arr:
return []
max_val = max(arr)
exp = 1 # On commence par les unités
result = list(arr)
while max_val // exp > 0:
# Tri par comptage sur le chiffre de rang exp
count = [0] * base
for x in result:
digit = (x // exp) % base
count[digit] += 1
# Fréquences cumulées
for i in range(1, base):
count[i] += count[i - 1]
# Placement à rebours (stable)
output = [0] * len(result)
for x in reversed(result):
digit = (x // exp) % base
count[digit] -= 1
output[count[digit]] = x
result = output
exp *= base
return result
def radix_sort_msd(arr, base=10, lo=0, hi=None, exp=None):
"""
Tri par base MSD (du plus significatif au moins significatif).
Version récursive.
Paramètres
----------
arr : list[int]
Tableau d'entiers non négatifs (modifié en place).
base : int
Base de numération.
lo, hi : int
Sous-tableau à trier (indices [lo, hi]).
exp : int
Puissance de la base correspondant au chiffre courant.
"""
if hi is None:
hi = len(arr) - 1
if exp is None:
if not arr or lo >= hi:
return arr
max_val = max(arr[lo:hi + 1])
exp = 1
while max_val // exp >= base:
exp *= base
if lo >= hi or exp < 1:
return arr
# Distribution dans les seaux selon le chiffre courant
count = [0] * (base + 1)
for i in range(lo, hi + 1):
digit = (arr[i] // exp) % base
count[digit + 1] += 1
for i in range(1, base + 1):
count[i] += count[i - 1]
aux = [0] * (hi - lo + 1)
starts = count[:]
for i in range(lo, hi + 1):
digit = (arr[i] // exp) % base
aux[count[digit]] = arr[i]
count[digit] += 1
for i, v in enumerate(aux):
arr[lo + i] = v
# Récursion sur chaque seau
for d in range(base):
bucket_lo = lo + starts[d]
bucket_hi = lo + starts[d + 1] - 1
if bucket_lo < bucket_hi:
radix_sort_msd(arr, base, bucket_lo, bucket_hi, exp // base)
return arr
# Tests
import random
data = [random.randint(0, 9999) for _ in range(20)]
sorted_ref = sorted(data)
assert radix_sort_lsd(data) == sorted_ref, "LSD échoue"
data2 = data.copy()
radix_sort_msd(data2)
assert data2 == sorted_ref, "MSD échoue"
print("LSD et MSD corrects.")
print("Exemple (LSD) :", radix_sort_lsd([170, 45, 75, 90, 802, 24, 2, 66]))
LSD et MSD corrects.
Exemple (LSD) : [2, 24, 45, 66, 75, 90, 170, 802]
Visualisation du tri par base LSD#
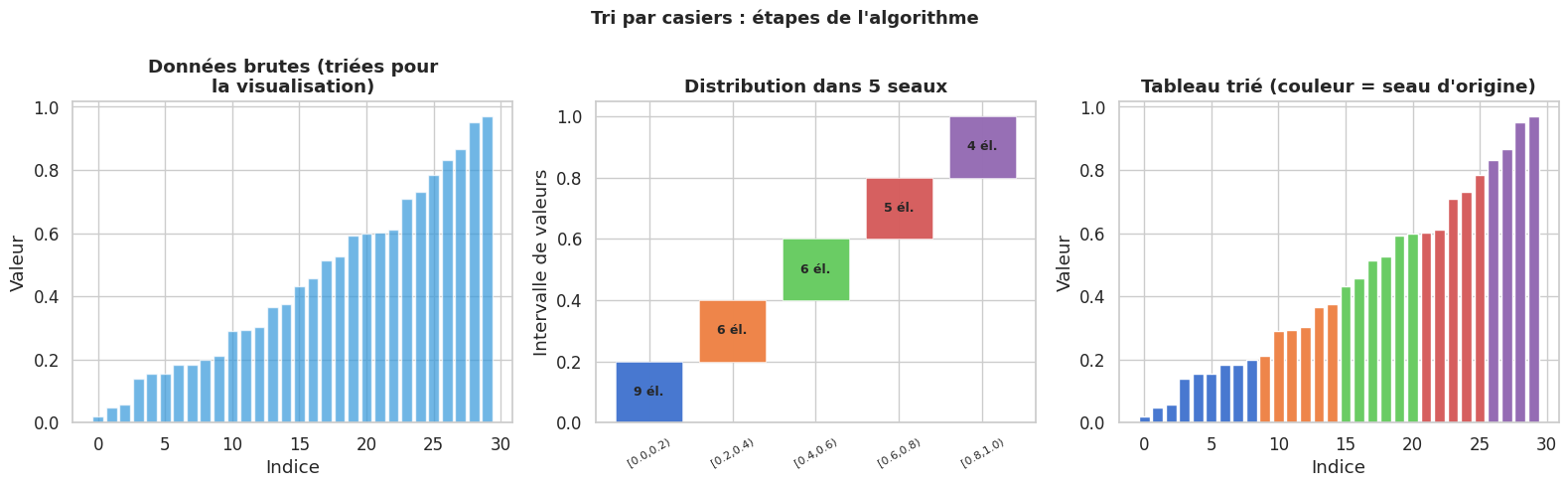
Tri par casiers (Bucket Sort)#
Principe et analyse#
Définition 62 (Tri par casiers)
Le tri par casiers (bucket sort) trie n valeurs réelles supposées tirées uniformément dans \([0, 1)\) (ou dans un intervalle connu) en les distribuant dans n seaux (buckets) de taille égale, en triant chaque seau indépendamment (typiquement par insertion), puis en concaténant les seaux triés.
La complexité attendue est O(n) lorsque les données sont uniformément distribuées.
Remarque 28
L’analyse de complexité repose sur l’espérance du nombre d’éléments par seau. Avec n éléments et n seaux de largeur 1/n, chaque élément tombe dans le i-ème seau si \(\lfloor n \cdot x \rfloor = i\). Si les éléments sont uniformément distribués, le nombre d’éléments dans le seau i suit une loi binomiale B(n, 1/n). L’espérance du nombre d’éléments par seau est 1, et la variance est \(1 - 1/n\). Le temps de tri par insertion dans un seau de taille m est O(m²) en pire cas, mais O(1) en espérance. En sommant sur tous les seaux, on obtient O(n) en espérance.
Dans le pire cas (tous les éléments dans le même seau), la complexité est O(n²) si on utilise le tri par insertion, ou O(n log n) avec un tri plus efficace.
Implémentation Python#
def insertion_sort(arr):
"""Tri par insertion en place."""
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
return arr
def bucket_sort(arr, n_buckets=None):
"""
Tri par casiers pour des valeurs réelles dans [0, 1).
Paramètres
----------
arr : list[float]
Valeurs dans [0, 1).
n_buckets : int, optionnel
Nombre de seaux. Par défaut égal à len(arr).
Retourne
-------
list[float]
Tableau trié.
"""
if not arr:
return []
n = len(arr)
if n_buckets is None:
n_buckets = n
# Normalisation si les données ne sont pas dans [0, 1)
min_val = min(arr)
max_val = max(arr)
if max_val == min_val:
return list(arr)
# Création des seaux
buckets = [[] for _ in range(n_buckets)]
for x in arr:
# Indice du seau proportionnel à la valeur
idx = int(n_buckets * (x - min_val) / (max_val - min_val + 1e-10))
idx = min(idx, n_buckets - 1)
buckets[idx].append(x)
# Tri de chaque seau et concaténation
result = []
for bucket in buckets:
insertion_sort(bucket)
result.extend(bucket)
return result
# Tests
import random
random.seed(42)
data_uniform = [random.random() for _ in range(1000)]
sorted_result = bucket_sort(data_uniform)
assert sorted_result == sorted(data_uniform), "bucket_sort incorrect"
data_general = [random.uniform(-50, 50) for _ in range(20)]
assert bucket_sort(data_general) == sorted(data_general), "bucket_sort (général) incorrect"
print("Tri par casiers correct.")
print("Exemple sur 8 valeurs :")
ex = [0.78, 0.17, 0.39, 0.26, 0.72, 0.94, 0.21, 0.12]
print(f" Entrée : {ex}")
print(f" Sortie : {bucket_sort(ex)}")
Tri par casiers correct.
Exemple sur 8 valeurs :
Entrée : [0.78, 0.17, 0.39, 0.26, 0.72, 0.94, 0.21, 0.12]
Sortie : [0.12, 0.17, 0.21, 0.26, 0.39, 0.72, 0.78, 0.94]
Comparaison des tris linéaires#
import time
def benchmark_sorts(sizes):
"""Compare les temps d'exécution des différents algorithmes de tri."""
results = {'counting': [], 'radix_lsd': [], 'bucket': [], 'python_sort': []}
for n in sizes:
# Données entières pour counting sort et radix sort
arr_int = [random.randint(0, 999) for _ in range(n)]
arr_float = [random.random() for _ in range(n)]
# counting_sort
t0 = time.perf_counter()
counting_sort(arr_int, 1000)
results['counting'].append(time.perf_counter() - t0)
# radix_sort_lsd
t0 = time.perf_counter()
radix_sort_lsd(arr_int)
results['radix_lsd'].append(time.perf_counter() - t0)
# bucket_sort
t0 = time.perf_counter()
bucket_sort(arr_float)
results['bucket'].append(time.perf_counter() - t0)
# tri natif Python (Timsort, O(n log n))
t0 = time.perf_counter()
sorted(arr_int)
results['python_sort'].append(time.perf_counter() - t0)
return results
sizes = [100, 500, 1000, 5000, 10000, 50000]
bench = benchmark_sorts(sizes)
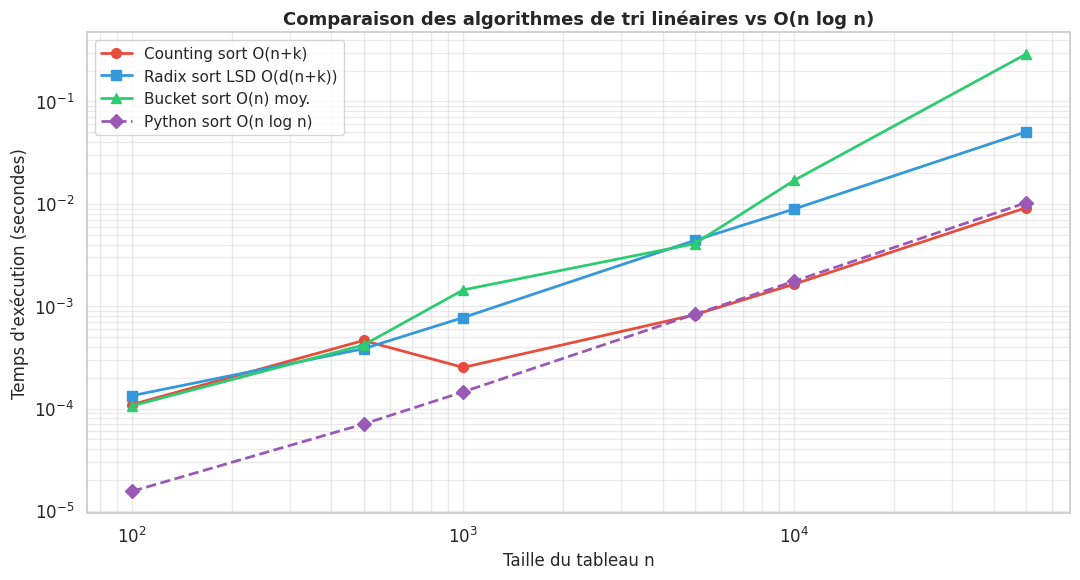
Résumé#
Dans ce chapitre, nous avons établi la borne inférieure théorique Ω(n log n) pour les tris par comparaison, prouvée par le modèle de l’arbre de décision : tout algorithme qui trie n éléments uniquement par comparaisons deux à deux doit effectuer au moins log₂(n!) = Θ(n log n) comparaisons dans le pire cas. Cette borne est atteinte par le tri fusion et le tri par tas, qui sont donc optimaux dans ce modèle.
Nous avons ensuite présenté trois algorithmes qui contournent cette limite en exploitant des hypothèses sur la structure des données :
Le tri par comptage atteint O(n + k) pour des entiers dans [0, k-1] en comptant les occurrences puis en plaçant chaque élément à sa position exacte. Il est stable, ce qui est crucial pour son utilisation comme brique du tri par base.
Le tri par base LSD enchaîne d passes de tri par comptage, traitant les chiffres du moins au plus significatif, pour un coût total de O(d · (n + b)). La stabilité des passes intermédiaires est la clé de la correction.
Le tri par casiers distribue n valeurs uniformes dans n seaux, trie chaque seau par insertion et concatène, atteignant O(n) en espérance. Il est sensible à la distribution réelle des données.
Le chapitre suivant aborde un problème dual du tri : la recherche. Nous verrons comment la structure triée d’un tableau permet de répondre à des requêtes de recherche en O(log n) au lieu de O(n), et nous explorerons les variantes de la recherche binaire ainsi que la bibliothèque bisect de Python.