Tris élémentaires#
Le tri est l’un des problèmes les plus fondamentaux de l’informatique. Trier une collection, c’est réorganiser ses éléments selon un ordre total — le plus souvent croissant. Cette opération est omniprésente : on trie des résultats de recherche, des enregistrements dans une base de données, des événements par date, des fichiers par taille. La plupart des algorithmes avancés (recherche binaire, tri-fusion, sélection de médiane…) supposent ou produisent des données triées.
Ce chapitre présente trois algorithmes de tri dits élémentaires : le tri par sélection, le tri par insertion et le tri à bulles. Tous trois ont une complexité \(O(n^2)\) dans le pire cas, ce qui les rend inadaptés aux grandes collections. Leur intérêt est double : d’abord pédagogique (leur analyse fine forge les outils pour comprendre les tris efficaces du chapitre suivant), ensuite pratique (ils surpassent les algorithmes \(O(n \log n)\) pour les très petits tableaux ou les tableaux quasi-triés).
Préliminaires : définitions#
Problème du tri
Entrée : un tableau \(A[0..n-1]\) de \(n\) éléments munis d’un ordre total \(\leq\).
Sortie : une permutation \(A'\) de \(A\) telle que \(A'[0] \leq A'[1] \leq \dots \leq A'[n-1]\).
Stabilité d’un tri
Un algorithme de tri est dit stable si, pour toute paire d’éléments de valeurs égales, leur ordre relatif dans le tableau de sortie est le même que dans le tableau d’entrée.
Formellement : si \(A[i] = A[j]\) et \(i < j\), alors la position de \(A[i]\) dans le résultat est inférieure à celle de \(A[j]\).
La stabilité est cruciale lorsqu’on trie des objets selon plusieurs critères successifs (tri en cascade) ou lorsque les éléments portent une information d’ordre non reflétée dans leur clé de tri.
Tri en place (in-place)
Un tri est dit en place (in-place) s’il n’utilise qu’une quantité constante (\(O(1)\)) de mémoire auxiliaire, en dehors du tableau d’entrée. Autrement dit, le tri se fait par réarrangement des éléments au sein du tableau lui-même, sans allouer un second tableau de taille proportionnelle à \(n\).
Tri adaptatif
Un tri est dit adaptatif s’il tire parti d’un ordre déjà partiellement présent dans le tableau d’entrée. Formellement, sa complexité dépend d’une mesure du « désordre » (comme le nombre d’inversions) et est meilleure que \(O(n^2)\) sur des entrées presque triées.
Tri par sélection (Selection Sort)#
Principe#
L’algorithme de tri par sélection repose sur une idée intuitive : à l’étape \(i\), on sélectionne le minimum parmi les éléments non encore triés \(A[i..n-1]\), puis on l’échange avec \(A[i]\).
Tri par sélection
Invariant de boucle : après \(i\) itérations, le sous-tableau \(A[0..i-1]\) contient les \(i\) plus petits éléments, triés.
Algorithme :
pour i de 0 à n-2 :
i_min ← i
pour j de i+1 à n-1 :
si A[j] < A[i_min] : i_min ← j
échanger A[i] et A[i_min]
Analyse de complexité#
Note
Comparaisons. L’étape \(i\) effectue exactement \(n - 1 - i\) comparaisons. Le total est : $\(\sum_{i=0}^{n-2}(n - 1 - i) = \sum_{k=1}^{n-1} k = \frac{n(n-1)}{2} = \Theta(n^2)\)$
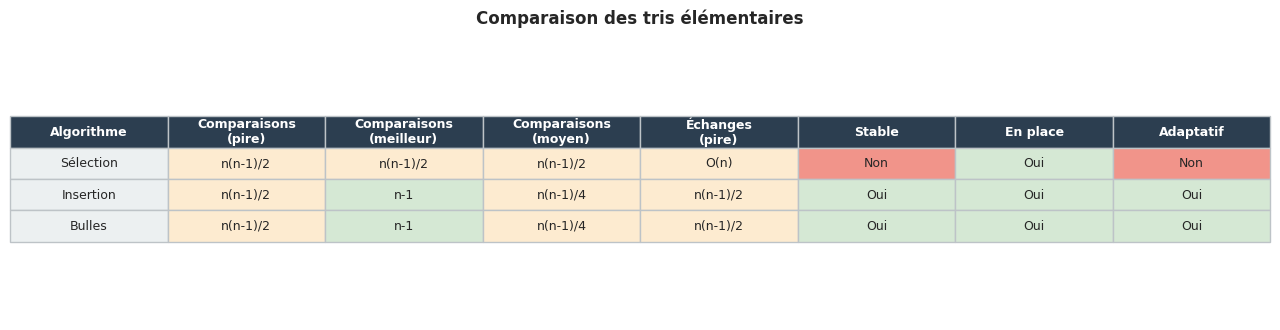
Ce nombre est indépendant de l’entrée : le tri par sélection effectue toujours exactement \(\frac{n(n-1)}{2}\) comparaisons, que le tableau soit déjà trié ou complètement désordonné.
Échanges. Au plus \(n - 1\) échanges (un par itération externe). Le tri par sélection est donc optimal en nombre d’échanges pour un tri \(O(n^2)\), ce qui en fait un bon choix quand les échanges coûtent très cher (écriture sur support lent).
Stabilité. Le tri par sélection est non stable dans son implémentation naïve. Exemple : \([2_a, 2_b, 1]\) — après la première itération, \(1\) est échangé avec \(2_a\), ce qui place \(2_a\) après \(2_b\).
En place. Oui : \(O(1)\) mémoire auxiliaire.
Tri par insertion (Insertion Sort)#
Principe#
Le tri par insertion s’inspire de la façon dont on trie des cartes dans la main : on prend chaque nouvelle carte et on l’insère à la bonne place parmi les cartes déjà triées.
Tri par insertion
Invariant de boucle : après \(i\) itérations, le sous-tableau \(A[0..i]\) est trié (mais ne contient pas nécessairement les \(i+1\) plus petits éléments).
Algorithme :
pour i de 1 à n-1 :
clé ← A[i]
j ← i - 1
tant que j ≥ 0 et A[j] > clé :
A[j+1] ← A[j]
j ← j - 1
A[j+1] ← clé
Analyse de complexité#
Note
Pire cas : tableau trié à l’envers. L’insertion de \(A[i]\) nécessite \(i\) comparaisons. Le total est \(\sum_{i=1}^{n-1} i = \frac{n(n-1)}{2} = \Theta(n^2)\).
Meilleur cas : tableau déjà trié. Chaque insertion ne nécessite qu’une comparaison (l’élément est déjà à sa place). Le total est \(n - 1 = \Theta(n)\).
Cas moyen. Pour une permutation aléatoire, le nombre moyen de comparaisons est \(\frac{n(n-1)}{4} = \Theta(n^2)\).
Inversions. Le tri par insertion effectue exactement autant de déplacements qu’il y a d”inversions dans le tableau. Une inversion est une paire \((i, j)\) avec \(i < j\) et \(A[i] > A[j]\). Le nombre d’inversions mesure le « désordre » du tableau.
Stabilité. Oui : l’algorithme n’échange pas deux éléments égaux (la condition est \(A[j] > \text{clé}\), stricte).
Adaptatif. Oui : sur un tableau presque trié (peu d’inversions), le tri par insertion est très rapide.
Tri par insertion sur données presque triées
Pour un tableau de \(n\) éléments avec au plus \(k\) éléments hors de place, le tri par insertion s’exécute en \(O(nk)\). Si \(k = O(1)\) (tableau quasi-trié), la complexité est \(O(n)\).
C’est pourquoi Timsort (l’algorithme de tri de Python, présenté au chapitre suivant) utilise le tri par insertion pour traiter les petits blocs : en pratique, les données réelles présentent souvent des séquences déjà partiellement ordonnées (runs).
Tri à bulles (Bubble Sort)#
Principe#
Le tri à bulles compare successivement des paires d’éléments adjacents et les échange s’ils sont dans le mauvais ordre. Les grands éléments « remontent » vers la fin du tableau, comme des bulles.
Tri à bulles
Algorithme de base :
pour i de 0 à n-2 :
pour j de 0 à n-2-i :
si A[j] > A[j+1] :
échanger A[j] et A[j+1]
Variante optimisée avec drapeau d’arrêt :
répéter :
échangé ← Faux
pour j de 0 à n-2 :
si A[j] > A[j+1] :
échanger A[j] et A[j+1]
échangé ← Vrai
jusqu'à Non échangé
La variante avec drapeau permet de détecter que le tableau est déjà trié et de s’arrêter prématurément.
Analyse de complexité#
Note
Sans optimisation. Le nombre de comparaisons est toujours \(\frac{n(n-1)}{2} = \Theta(n^2)\), identique au tri par sélection. Le nombre d’échanges est au pire \(\frac{n(n-1)}{2}\) (tableau inversé), soit nettement plus que le tri par sélection (\(n-1\) échanges).
Avec drapeau d’arrêt. Meilleur cas \(O(n)\) sur tableau trié (une seule passe), pire cas \(O(n^2)\) sur tableau inversé. Le cas moyen reste \(O(n^2)\).
Pourquoi le tri à bulles est-il peu pratique ? Bien que sa complexité théorique soit identique à celle du tri par insertion, il effectue en moyenne deux fois plus d’échanges, et les accès mémoire sont moins cohérents. Il est généralement plus lent en pratique. Sa valeur est essentiellement pédagogique.
Stabilité. Oui : on n’échange deux éléments que s’ils sont strictement dans le mauvais ordre.
Visualisation comparée des étapes#
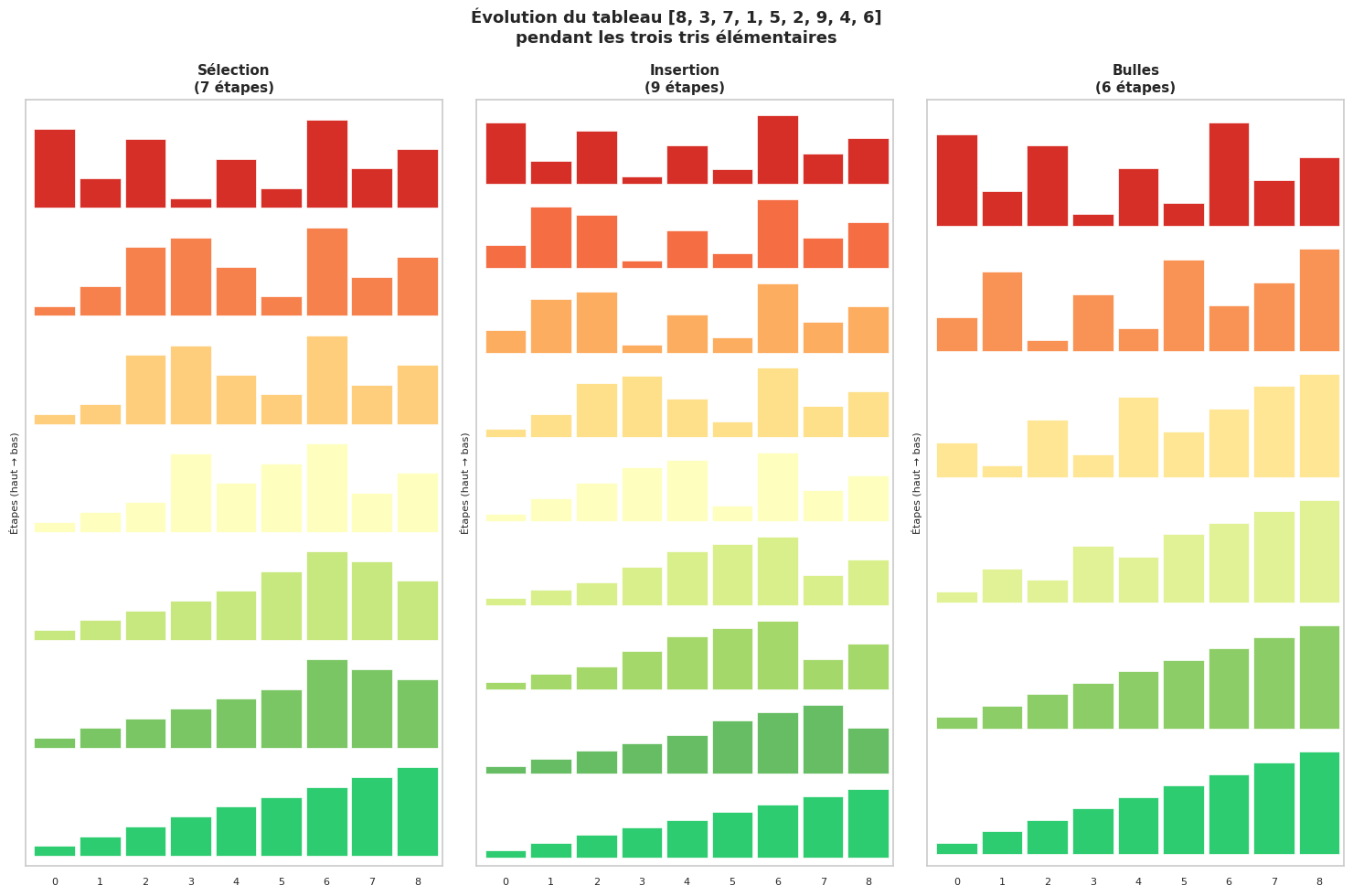
Tableau comparatif#
Implémentation Rust#
/// Tri par sélection générique.
fn tri_selection<T: Ord>(arr: &mut Vec<T>) {
let n = arr.len();
for i in 0..n.saturating_sub(1) {
let mut i_min = i;
for j in (i + 1)..n {
if arr[j] < arr[i_min] {
i_min = j;
}
}
if i_min != i {
arr.swap(i, i_min);
}
}
}
/// Tri par insertion générique.
fn tri_insertion<T: Ord>(arr: &mut Vec<T>) {
let n = arr.len();
for i in 1..n {
let mut j = i;
while j > 0 && arr[j - 1] > arr[j] {
arr.swap(j - 1, j);
j -= 1;
}
}
}
/// Tri à bulles avec drapeau d'arrêt.
fn tri_bulles<T: Ord>(arr: &mut Vec<T>) {
let n = arr.len();
for i in 0..n.saturating_sub(1) {
let mut echange = false;
for j in 0..(n - 1 - i) {
if arr[j] > arr[j + 1] {
arr.swap(j, j + 1);
echange = true;
}
}
if !echange {
break;
}
}
}
fn main() {
let mut v1 = vec![64, 25, 12, 22, 11];
let mut v2 = v1.clone();
let mut v3 = v1.clone();
tri_selection(&mut v1);
tri_insertion(&mut v2);
tri_bulles(&mut v3);
println!("Sélection : {:?}", v1);
println!("Insertion : {:?}", v2);
println!("Bulles : {:?}", v3);
// Test sur chaînes de caractères
let mut mots = vec!["zèbre", "abeille", "ours", "loup", "cerf"];
tri_insertion(&mut mots);
println!("Mots triés : {:?}", mots);
}
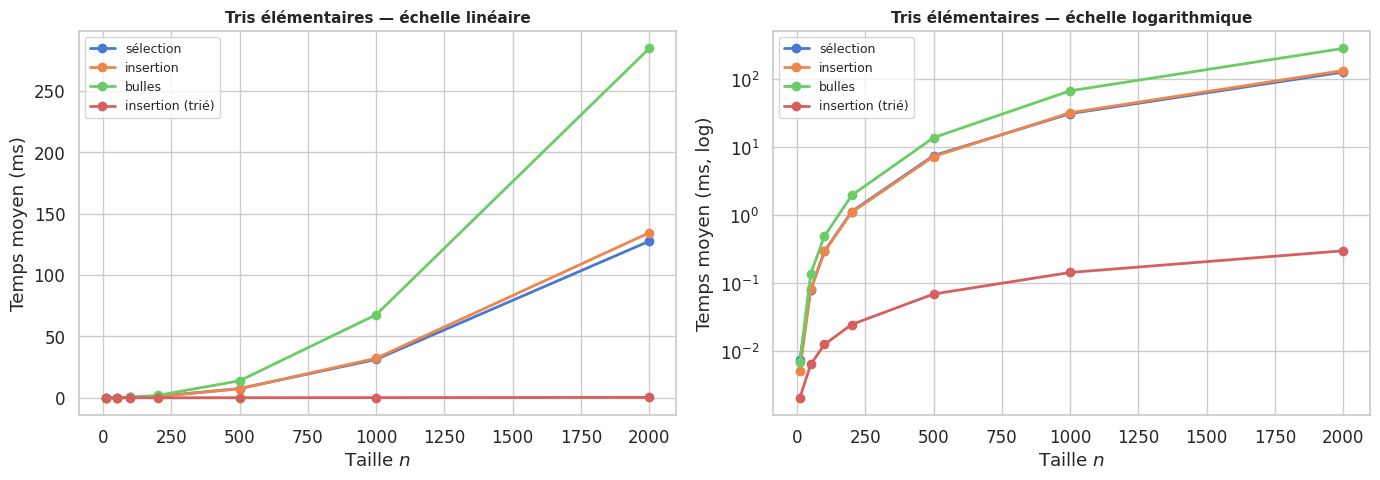
Benchmark comparatif#
Quand utiliser ces tris ?#
Note
Malgré leur complexité \(O(n^2)\), les tris élémentaires trouvent des applications légitimes dans deux situations :
1. Très petits tableaux (\(n \lesssim 20\)). Les constantes cachées dans les tris efficaces (\(O(n \log n)\)) deviennent significatives pour de petites valeurs de \(n\). Le tri par insertion est souvent plus rapide que le tri rapide ou le tri fusion en dessous de 10 à 20 éléments. C’est pourquoi Timsort et d’autres implémentations hybrides utilisent le tri par insertion pour les petits blocs.
2. Données quasi-triées. Le tri par insertion est exceptionnel sur des données presque triées : \(O(n)\) sur un tableau avec un nombre constant d’inversions. Si l’on sait que les données arrivent « à peu près » dans l’ordre (flux de capteurs, logs temporels, mise à jour incrémentale…), le tri par insertion est souvent le meilleur choix.
3. Échanges coûteux. Le tri par sélection minimise le nombre d’échanges (\(O(n)\) au total). Si écrire en mémoire est très coûteux (flash memory, disque dur lent), il peut être préférable.
En revanche, pour \(n > 100\) sur des données génériques, les tris \(O(n \log n)\) du chapitre suivant — tri fusion, tri rapide, tri par tas — sont invariablement plus performants.
Résumé#
Ce chapitre a analysé en détail les trois tris élémentaires :
Le tri par sélection effectue toujours exactement \(\frac{n(n-1)}{2}\) comparaisons mais seulement \(O(n)\) échanges. Il est en place, non stable et non adaptatif : ses performances sont indépendantes de l’entrée.
Le tri par insertion est stable et adaptatif : \(O(n)\) sur tableau trié, \(O(n^2)\) au pire. C’est le meilleur des trois pour les petits tableaux et les données quasi-triées.
Le tri à bulles est stable et peut détecter un tableau trié en une passe (avec le drapeau d’arrêt), mais effectue en moyenne deux fois plus d’échanges que le tri par insertion et est le plus lent des trois en pratique.
La stabilité est une propriété précieuse lors des tris multicritères. La notion d”inversion lie directement le désordre d’un tableau au coût du tri par insertion.
En Rust, ces tris s’implémentent de façon générique avec le trait
Ord, et la méthodeswapintégrée permet des échanges sans variable temporaire.
Le chapitre suivant présentera les tris efficaces — tri fusion, tri rapide, tri par tas — qui atteignent la borne optimale de \(O(n \log n)\) et sont utilisés dans les bibliothèques standard des langages modernes.