Algorithmes de recherche#
Rechercher un élément dans une collection est l’une des opérations les plus fondamentales en informatique. La question est apparemment simple : étant donné un tableau A et une valeur cible x, existe-t-il un indice i tel que A[i] = x ? Mais derrière cette simplicité se cache une riche théorie qui met en jeu la structure des données, le coût des comparaisons et les propriétés statistiques de l’entrée.
Nous commencerons par la recherche linéaire — applicable à tout tableau — puis nous exploiterons l’ordre pour réduire la complexité à O(log n) grâce à la recherche binaire et à ses nombreuses variantes. Nous étudierons ensuite la bibliothèque bisect de Python, la recherche dans un arbre binaire de recherche, la recherche par interpolation et la recherche exponentielle.
Recherche linéaire#
Principe et analyse#
Définition 63 (Recherche linéaire)
La recherche linéaire (ou recherche séquentielle) parcourt le tableau de gauche à droite et compare chaque élément à la valeur cible jusqu’à trouver une occurrence ou épuiser le tableau.
Complexité dans le meilleur cas : O(1) (l’élément est en première position).
Complexité en moyenne : O(n/2) = O(n) si l’élément est présent (position uniforme).
Complexité dans le pire cas : O(n) (élément absent ou en dernière position).
Elle ne nécessite aucune hypothèse sur l’ordre des éléments et fonctionne sur tout tableau, même non trié.
def linear_search(arr, target):
"""
Recherche linéaire : retourne l'indice de la première occurrence de
target dans arr, ou -1 si absent.
Complexité : O(n) pire cas.
"""
for i, x in enumerate(arr):
if x == target:
return i
return -1
def linear_search_all(arr, target):
"""Retourne tous les indices où target apparaît."""
return [i for i, x in enumerate(arr) if x == target]
# Tests
assert linear_search([3, 1, 4, 1, 5, 9, 2, 6], 5) == 4
assert linear_search([3, 1, 4, 1, 5, 9, 2, 6], 7) == -1
assert linear_search([], 5) == -1
assert linear_search_all([1, 2, 1, 3, 1], 1) == [0, 2, 4]
print("Recherche linéaire correcte.")
Recherche linéaire correcte.
Remarque 29
La recherche linéaire peut être améliorée par la technique de la sentinelle : on place la cible en fin de tableau avant de parcourir, ce qui élimine le test de fin de tableau dans la boucle (une comparaison par itération au lieu de deux). Cela divise le nombre d’opérations par deux en pratique, sans changer la complexité asymptotique.
def linear_search_sentinel(arr, target):
"""
Recherche linéaire avec sentinelle.
Réduit le nombre de comparaisons par itération de 2 à 1.
"""
if not arr:
return -1
arr_copy = arr + [target] # Sentinelle
i = 0
while arr_copy[i] != target:
i += 1
return i if i < len(arr) else -1
assert linear_search_sentinel([3, 1, 4, 1, 5], 4) == 2
assert linear_search_sentinel([3, 1, 4, 1, 5], 7) == -1
print("Sentinelle correcte.")
Sentinelle correcte.
Recherche binaire#
Principe et correction#
La recherche binaire est l’algorithme de recherche par comparaisons le plus efficace possible sur un tableau trié.
Définition 64 (Recherche binaire)
La recherche binaire opère sur un tableau trié en ordre croissant. Elle maintient un intervalle de recherche \([\mathit{lo}, \mathit{hi}]\) et, à chaque étape, compare la cible au milieu \(\mathit{mid} = \lfloor (\mathit{lo} + \mathit{hi}) / 2 \rfloor\) :
Si \(A[\mathit{mid}] = \mathit{target}\), on a trouvé la cible.
Si \(A[\mathit{mid}] < \mathit{target}\), la cible est dans la moitié droite : \(\mathit{lo} = \mathit{mid} + 1\).
Si \(A[\mathit{mid}] > \mathit{target}\), la cible est dans la moitié gauche : \(\mathit{hi} = \mathit{mid} - 1\).
À chaque étape, la taille de l’intervalle est divisée par deux. Après au plus \(\lfloor \log_2 n \rfloor + 1\) étapes, l’intervalle est vide et la recherche se termine.
Complexité : O(log n) dans le pire cas.
Remarque 30
Un piège classique dans l’implémentation de la recherche binaire est le calcul du milieu. L’expression naïve (lo + hi) // 2 peut provoquer un dépassement d’entier (overflow) en C/Java si lo et hi sont de grands entiers 32 bits. La formule correcte est lo + (hi - lo) // 2, qui évite ce problème. En Python, les entiers sont de précision arbitraire, mais cette bonne pratique reste recommandée.
def binary_search(arr, target):
"""
Recherche binaire classique : retourne un indice quelconque où
target apparaît, ou -1 si absent.
Précondition : arr est trié en ordre croissant.
Complexité : O(log n).
"""
lo, hi = 0, len(arr) - 1
while lo <= hi:
mid = lo + (hi - lo) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
lo = mid + 1
else:
hi = mid - 1
return -1
def binary_search_recursive(arr, target, lo=0, hi=None):
"""Version récursive de la recherche binaire."""
if hi is None:
hi = len(arr) - 1
if lo > hi:
return -1
mid = lo + (hi - lo) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
return binary_search_recursive(arr, target, mid + 1, hi)
else:
return binary_search_recursive(arr, target, lo, mid - 1)
# Tests exhaustifs
arr = sorted([3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5])
for val in range(11):
idx = binary_search(arr, val)
idx_r = binary_search_recursive(arr, val)
ref = val in arr
assert (idx != -1) == ref, f"Erreur pour val={val}"
assert (idx_r != -1) == ref
print("Recherche binaire (itérative et récursive) correcte.")
print(f"arr = {arr}")
print(f"Recherche de 5 : indice {binary_search(arr, 5)}")
print(f"Recherche de 7 : indice {binary_search(arr, 7)}")
Recherche binaire (itérative et récursive) correcte.
arr = [1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
Recherche de 5 : indice 8
Recherche de 7 : indice -1
Variantes : première et dernière occurrence#
Définition 65 (Borne inférieure et borne supérieure)
Pour un tableau trié pouvant contenir des doublons, on définit :
La borne inférieure (lower bound) de target : le plus petit indice i tel que \(A[i] \geq \mathit{target}\). C’est la position où target serait inséré pour maintenir le tri (insertion à gauche des éléments égaux).
La borne supérieure (upper bound) de target : le plus petit indice i tel que \(A[i] > \mathit{target}\). C’est la position d’insertion à droite des éléments égaux.
Ces deux opérations s’exécutent en O(log n).
def lower_bound(arr, target):
"""
Retourne le plus petit indice i tel que arr[i] >= target.
Équivalent à bisect_left.
Si tous les éléments sont < target, retourne len(arr).
"""
lo, hi = 0, len(arr)
while lo < hi:
mid = lo + (hi - lo) // 2
if arr[mid] < target:
lo = mid + 1
else:
hi = mid
return lo
def upper_bound(arr, target):
"""
Retourne le plus petit indice i tel que arr[i] > target.
Équivalent à bisect_right.
Si tous les éléments sont <= target, retourne len(arr).
"""
lo, hi = 0, len(arr)
while lo < hi:
mid = lo + (hi - lo) // 2
if arr[mid] <= target:
lo = mid + 1
else:
hi = mid
return lo
def first_occurrence(arr, target):
"""Retourne l'indice de la première occurrence de target, ou -1."""
idx = lower_bound(arr, target)
if idx < len(arr) and arr[idx] == target:
return idx
return -1
def last_occurrence(arr, target):
"""Retourne l'indice de la dernière occurrence de target, ou -1."""
idx = upper_bound(arr, target) - 1
if idx >= 0 and arr[idx] == target:
return idx
return -1
def count_occurrences(arr, target):
"""Nombre d'occurrences de target dans arr trié."""
return upper_bound(arr, target) - lower_bound(arr, target)
# Tests
arr = [1, 2, 2, 2, 3, 4, 4, 5]
assert lower_bound(arr, 2) == 1
assert upper_bound(arr, 2) == 4
assert first_occurrence(arr, 2) == 1
assert last_occurrence(arr, 2) == 3
assert count_occurrences(arr, 2) == 3
assert count_occurrences(arr, 6) == 0
assert first_occurrence(arr, 6) == -1
print("Bornes inférieure et supérieure correctes.")
print(f"arr = {arr}")
print(f"first_occurrence(arr, 2) = {first_occurrence(arr, 2)}")
print(f"last_occurrence(arr, 2) = {last_occurrence(arr, 2)}")
print(f"count_occurrences(arr, 2) = {count_occurrences(arr, 2)}")
print(f"count_occurrences(arr, 4) = {count_occurrences(arr, 4)}")
Bornes inférieure et supérieure correctes.
arr = [1, 2, 2, 2, 3, 4, 4, 5]
first_occurrence(arr, 2) = 1
last_occurrence(arr, 2) = 3
count_occurrences(arr, 2) = 3
count_occurrences(arr, 4) = 2
Le module bisect de Python#
Python fournit dans sa bibliothèque standard le module bisect, qui implémente efficacement les opérations de borne inférieure et borne supérieure sur des listes triées. Ces fonctions sont écrites en C et sont donc très rapides en pratique.
Définition 66 (Fonctions du module bisect)
Le module bisect expose quatre fonctions principales :
bisect_left(a, x): retourne la borne inférieure de x dans a (indice d’insertion à gauche). Équivalent à notrelower_bound.bisect_right(a, x)(oubisect(a, x)) : retourne la borne supérieure de x dans a (indice d’insertion à droite). Équivalent à notreupper_bound.insort_left(a, x): insère x à sa position triée en utilisantbisect_left.insort_right(a, x): insère x à sa position triée en utilisantbisect_right.
Toutes ces fonctions supposent que a est déjà trié.
import bisect
# Démonstration des fonctions bisect
arr = [1, 2, 2, 2, 3, 4, 4, 5]
print(f"arr = {arr}")
print()
# bisect_left et bisect_right
print(f"bisect_left(arr, 2) = {bisect.bisect_left(arr, 2)}")
print(f"bisect_right(arr, 2) = {bisect.bisect_right(arr, 2)}")
print(f"bisect_left(arr, 3) = {bisect.bisect_left(arr, 3)}")
print(f"bisect_right(arr, 0) = {bisect.bisect_right(arr, 0)}")
print(f"bisect_left(arr, 6) = {bisect.bisect_left(arr, 6)}")
print()
# Insertion maintenant l'ordre trié
arr2 = [1, 3, 5, 7, 9]
bisect.insort(arr2, 4)
print(f"Après insort([1,3,5,7,9], 4) : {arr2}")
bisect.insort(arr2, 3)
print(f"Après insort([1,3,4,5,7,9], 3) : {arr2}")
arr = [1, 2, 2, 2, 3, 4, 4, 5]
bisect_left(arr, 2) = 1
bisect_right(arr, 2) = 4
bisect_left(arr, 3) = 4
bisect_right(arr, 0) = 0
bisect_left(arr, 6) = 8
Après insort([1,3,5,7,9], 4) : [1, 3, 4, 5, 7, 9]
Après insort([1,3,4,5,7,9], 3) : [1, 3, 3, 4, 5, 7, 9]
def grade_from_score(score):
"""
Détermine la mention d'un étudiant à partir de son score (0-100).
Utilisation typique de bisect pour du découpage en tranches.
"""
breakpoints = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
grades = ['F', 'F', 'E', 'D', 'D', 'C', 'C', 'B', 'B', 'A', 'A+']
return grades[bisect.bisect(breakpoints, score)]
# Application : gestion d'un tableau trié en temps réel
class SortedList:
"""Liste maintenue triée avec insertion O(n) mais recherche O(log n)."""
def __init__(self):
self._data = []
def add(self, value):
bisect.insort(self._data, value)
def __contains__(self, value):
idx = bisect.bisect_left(self._data, value)
return idx < len(self._data) and self._data[idx] == value
def rank(self, value):
"""Rang de value (nombre d'éléments strictement inférieurs)."""
return bisect.bisect_left(self._data, value)
def __repr__(self):
return f"SortedList({self._data})"
sl = SortedList()
for v in [5, 2, 8, 1, 9, 3]:
sl.add(v)
print(f"SortedList : {sl}")
print(f"5 in sl : {5 in sl}")
print(f"7 in sl : {7 in sl}")
print(f"Rang de 4 : {sl.rank(4)}")
SortedList : SortedList([1, 2, 3, 5, 8, 9])
5 in sl : True
7 in sl : False
Rang de 4 : 3
Recherche par interpolation#
La recherche binaire divise toujours l’intervalle en deux parties égales. La recherche par interpolation exploite la valeur de la cible pour estimer sa position probable, comme on cherche un mot dans un dictionnaire papier.
Définition 67 (Recherche par interpolation)
La recherche par interpolation s’applique à des tableaux triés dont les valeurs sont uniformément distribuées. Au lieu de toujours prendre le milieu, elle estime la position de la cible par interpolation linéaire :
Complexité moyenne : O(log log n) pour des données uniformes.
Complexité pire cas : O(n) si les données sont très inégalement réparties.
def interpolation_search(arr, target):
"""
Recherche par interpolation.
Précondition : arr trié, valeurs uniformément distribuées.
Complexité : O(log log n) en moyenne, O(n) pire cas.
"""
lo, hi = 0, len(arr) - 1
while lo <= hi and arr[lo] <= target <= arr[hi]:
if arr[hi] == arr[lo]:
if arr[lo] == target:
return lo
else:
return -1
# Interpolation linéaire de la position
mid = lo + (target - arr[lo]) * (hi - lo) // (arr[hi] - arr[lo])
mid = max(lo, min(hi, mid)) # Clamp pour sécurité
if arr[mid] == target:
return mid
elif arr[mid] < target:
lo = mid + 1
else:
hi = mid - 1
return -1
# Tests
arr_uniform = sorted(random.sample(range(0, 10000), 500))
for _ in range(100):
val = random.randint(0, 10000)
idx_bin = binary_search(arr_uniform, val)
idx_int = interpolation_search(arr_uniform, val)
assert (idx_bin != -1) == (idx_int != -1), f"Divergence pour val={val}"
print("Recherche par interpolation correcte.")
Recherche par interpolation correcte.
Recherche exponentielle#
La recherche exponentielle est utile lorsqu’on ne connaît pas la taille du tableau à l’avance (par exemple pour des tableaux de taille inconnue ou des flux de données) ou lorsque la cible est supposée proche du début.
Définition 68 (Recherche exponentielle)
La recherche exponentielle (exponential search) fonctionne en deux phases sur un tableau trié de taille n :
Phase exponentielle. On parcourt les indices 1, 2, 4, 8, 16, … jusqu’à trouver un indice \(i\) tel que \(A[i] \geq \mathit{target}\) ou épuiser le tableau. Cette phase prend O(log p) comparaisons, où p est la position de la cible.
Phase binaire. On effectue une recherche binaire dans l’intervalle \([i/2, \min(i, n-1)]\).
La complexité totale est O(log p) où p est l’indice de la première occurrence, ce qui est meilleur que O(log n) quand la cible est proche du début.
def exponential_search(arr, target):
"""
Recherche exponentielle.
Complexité : O(log p) où p est l'indice de la cible.
Efficace quand la cible est proche du début du tableau.
"""
n = len(arr)
if n == 0:
return -1
if arr[0] == target:
return 0
# Phase exponentielle : doubler l'indice
i = 1
while i < n and arr[i] <= target:
i *= 2
# Phase binaire dans [i//2, min(i, n-1)]
lo = i // 2
hi = min(i, n - 1)
while lo <= hi:
mid = lo + (hi - lo) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
lo = mid + 1
else:
hi = mid - 1
return -1
# Tests
arr = sorted(random.sample(range(1000), 200))
for val in random.sample(range(1000), 50):
assert (exponential_search(arr, val) != -1) == (val in arr)
print("Recherche exponentielle correcte.")
Recherche exponentielle correcte.
Recherche dans un arbre binaire de recherche#
Définition 69 (Recherche dans un BST)
Un arbre binaire de recherche (BST, Binary Search Tree) est un arbre binaire dans lequel chaque nœud v satisfait :
Toutes les valeurs dans le sous-arbre gauche de v sont strictement inférieures à la valeur de v.
Toutes les valeurs dans le sous-arbre droit de v sont supérieures ou égales à la valeur de v.
La recherche d’une valeur cible suit le même principe que la recherche binaire : on compare la cible à la racine et on descend à gauche ou à droite selon le résultat. La complexité est O(h) où h est la hauteur de l’arbre.
Pour un BST équilibré, \(h = O(\log n)\) ; pour un BST dégénéré (liste chaînée), \(h = O(n)\).
class BSTNode:
"""Nœud d'un arbre binaire de recherche."""
__slots__ = ('val', 'left', 'right')
def __init__(self, val):
self.val = val
self.left = None
self.right = None
class BST:
"""Arbre binaire de recherche simple."""
def __init__(self):
self.root = None
def insert(self, val):
"""Insère val dans le BST. O(h)."""
if self.root is None:
self.root = BSTNode(val)
return
node = self.root
while True:
if val < node.val:
if node.left is None:
node.left = BSTNode(val)
return
node = node.left
else:
if node.right is None:
node.right = BSTNode(val)
return
node = node.right
def search(self, target):
"""Recherche target dans le BST. Retourne True si trouvé. O(h)."""
node = self.root
while node is not None:
if target == node.val:
return True
elif target < node.val:
node = node.left
else:
node = node.right
return False
def lower_bound(self, target):
"""Retourne la plus petite valeur >= target dans le BST. O(h)."""
result = None
node = self.root
while node is not None:
if node.val >= target:
result = node.val
node = node.left
else:
node = node.right
return result
def height(self):
"""Calcule la hauteur du BST."""
def _height(node):
if node is None:
return 0
return 1 + max(_height(node.left), _height(node.right))
return _height(self.root)
# Test
bst = BST()
values = [5, 3, 7, 1, 4, 6, 8, 2]
for v in values:
bst.insert(v)
assert bst.search(4) is True
assert bst.search(9) is False
assert bst.lower_bound(4) == 4
assert bst.lower_bound(0) == 1
assert bst.lower_bound(9) is None
print("BST correct.")
print(f"Hauteur du BST : {bst.height()} (attendu ~3 pour {len(values)} éléments)")
BST correct.
Hauteur du BST : 4 (attendu ~3 pour 8 éléments)
Recherche en Rust avec BTreeMap#
use std::collections::BTreeMap;
/// Recherche dans un BTreeMap (arbre B équilibré) :
/// la bibliothèque standard Rust fournit des méthodes
/// analogues à bisect_left / bisect_right via les curseurs.
fn recherche_btreemap() {
let mut map: BTreeMap<i32, &str> = BTreeMap::new();
map.insert(1, "un");
map.insert(3, "trois");
map.insert(5, "cinq");
map.insert(7, "sept");
map.insert(9, "neuf");
// Recherche exacte
println!("5 -> {:?}", map.get(&5)); // Some("cinq")
println!("4 -> {:?}", map.get(&4)); // None
// Borne inférieure : premier élément >= 4
if let Some((&k, &v)) = map.range(4..).next() {
println!("lower_bound(4) = {} -> {}", k, v); // 5 -> cinq
}
// Borne supérieure : premier élément > 5
if let Some((&k, &v)) = map.range((std::ops::Bound::Excluded(5), std::ops::Bound::Unbounded)).next() {
println!("upper_bound(5) = {} -> {}", k, v); // 7 -> sept
}
}
/// Recherche binaire sur un slice trié, idiomatique en Rust.
fn binary_search_rust(arr: &[i32], target: i32) -> Result<usize, usize> {
// La méthode standard retourne Ok(idx) si trouvé,
// Err(idx_insertion) sinon.
arr.binary_search(&target)
}
fn lower_bound_rust(arr: &[i32], target: i32) -> usize {
arr.partition_point(|&x| x < target)
}
fn upper_bound_rust(arr: &[i32], target: i32) -> usize {
arr.partition_point(|&x| x <= target)
}
fn main() {
let arr = vec![1, 2, 2, 3, 4, 4, 5];
println!("{:?}", binary_search_rust(&arr, 3)); // Ok(3)
println!("{:?}", binary_search_rust(&arr, 6)); // Err(7)
println!("lower_bound(2) = {}", lower_bound_rust(&arr, 2)); // 1
println!("upper_bound(2) = {}", upper_bound_rust(&arr, 2)); // 3
recherche_btreemap();
}
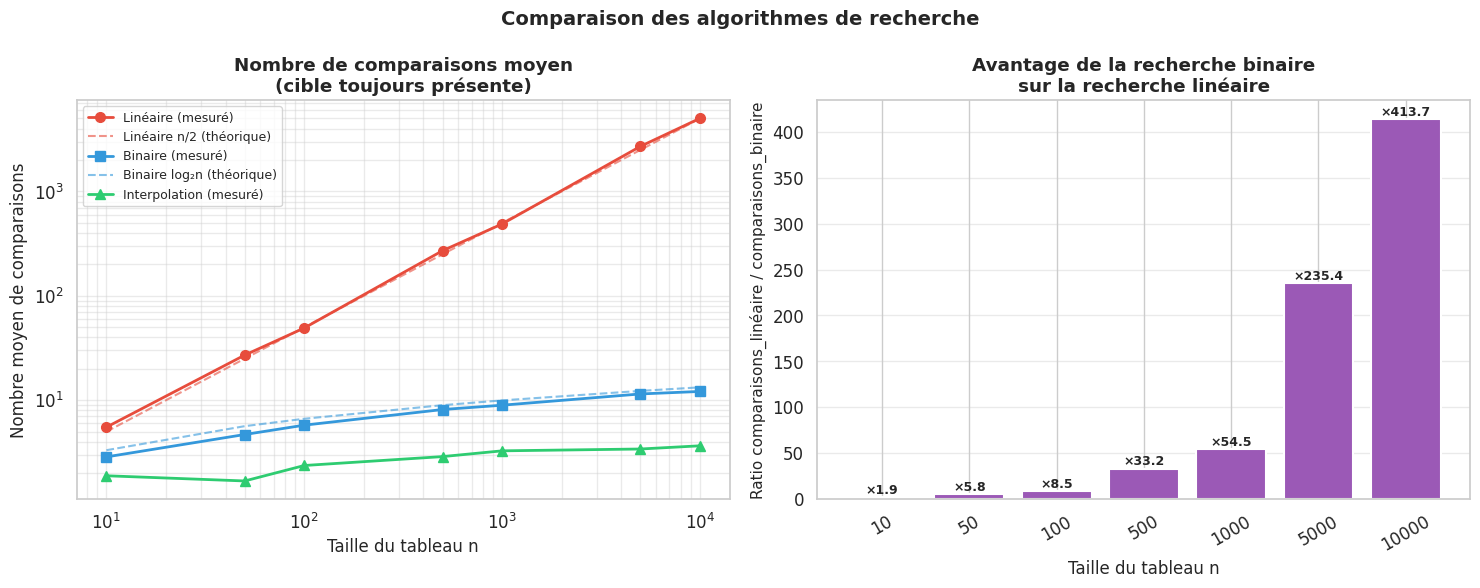
Comparaison expérimentale#
def count_comparisons_linear(arr, target):
"""Compte le nombre de comparaisons effectuées."""
comparisons = 0
for x in arr:
comparisons += 1
if x == target:
return comparisons
return comparisons
def count_comparisons_binary(arr, target):
"""Compte le nombre de comparaisons en recherche binaire."""
lo, hi = 0, len(arr) - 1
comparisons = 0
while lo <= hi:
comparisons += 1
mid = lo + (hi - lo) // 2
if arr[mid] == target:
return comparisons
elif arr[mid] < target:
lo = mid + 1
else:
hi = mid - 1
return comparisons
def count_comparisons_interpolation(arr, target):
"""Compte le nombre de comparaisons en recherche par interpolation."""
lo, hi = 0, len(arr) - 1
comparisons = 0
while lo <= hi and arr[lo] <= target <= arr[hi]:
if arr[hi] == arr[lo]:
comparisons += 1
return comparisons
mid = lo + (target - arr[lo]) * (hi - lo) // (arr[hi] - arr[lo])
mid = max(lo, min(hi, mid))
comparisons += 1
if arr[mid] == target:
return comparisons
elif arr[mid] < target:
lo = mid + 1
else:
hi = mid - 1
return comparisons
sizes = [10, 50, 100, 500, 1000, 5000, 10000]
n_trials = 200
results = {
'linear': [],
'binary': [],
'interpolation': [],
'theoretical_linear': [],
'theoretical_binary': [],
}
for n in sizes:
arr = sorted(random.sample(range(n * 10), n))
lin_comps, bin_comps, int_comps = [], [], []
for _ in range(n_trials):
# Cible toujours présente (recherche interne)
target = random.choice(arr)
lin_comps.append(count_comparisons_linear(arr, target))
bin_comps.append(count_comparisons_binary(arr, target))
int_comps.append(count_comparisons_interpolation(arr, target))
results['linear'].append(np.mean(lin_comps))
results['binary'].append(np.mean(bin_comps))
results['interpolation'].append(np.mean(int_comps))
results['theoretical_linear'].append(n / 2)
results['theoretical_binary'].append(math.log2(n))
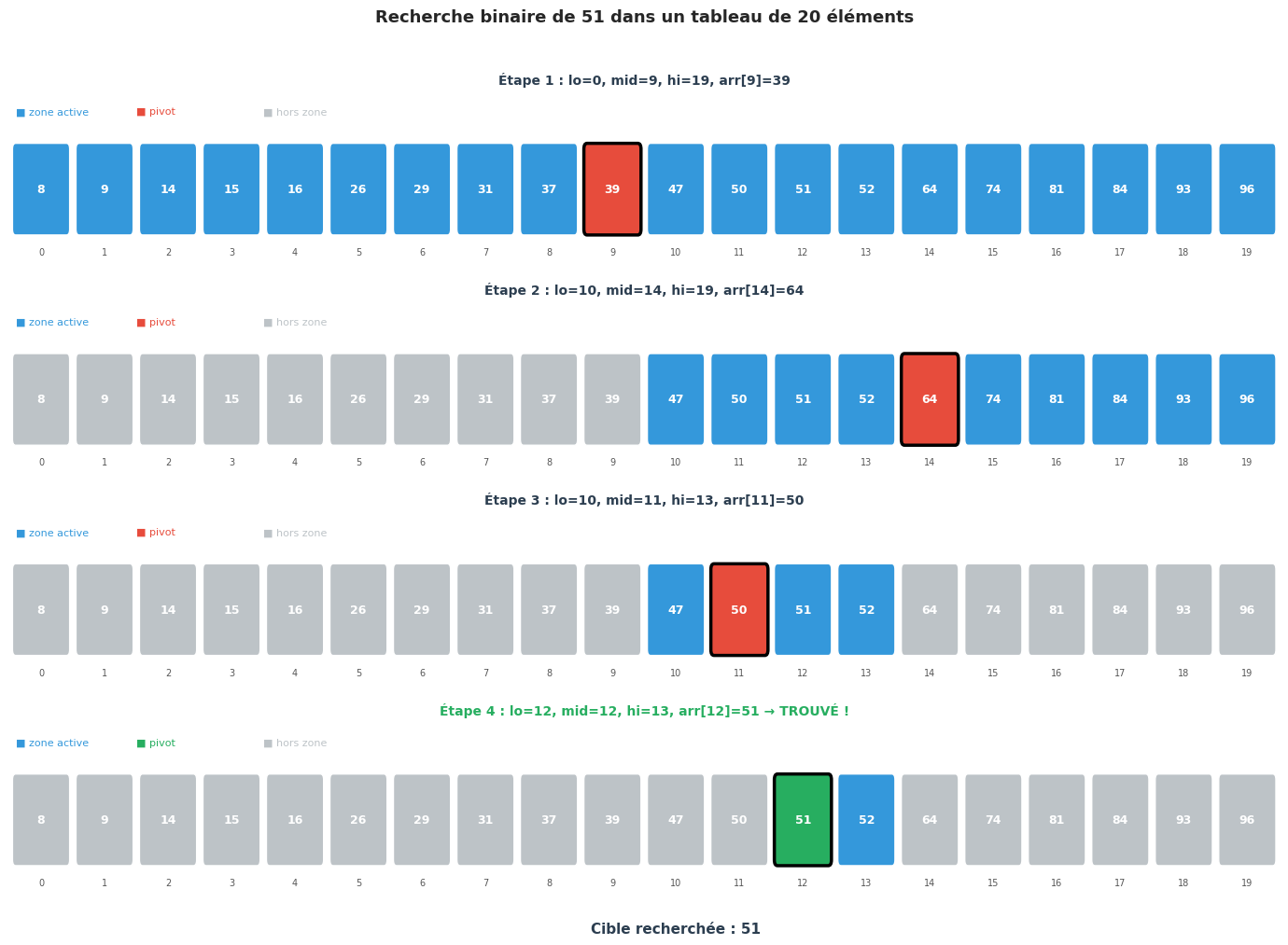
Visualisation de la recherche binaire#
Résumé#
Dans ce chapitre, nous avons parcouru le spectre des algorithmes de recherche, depuis la recherche linéaire jusqu’aux variantes avancées de la recherche binaire :
La recherche linéaire est universelle (applicable à tout tableau non trié) mais coûteuse en O(n). La technique de la sentinelle en réduit le coût pratique de moitié.
La recherche binaire exploite le tri pour réduire la complexité à O(log n) : à chaque étape, l’espace de recherche est divisé par deux. Les variantes lower_bound et upper_bound permettent de gérer les doublons et de localiser les bornes d’un intervalle.
Le module
bisectde Python fournit ces opérations en C, avecbisect_left,bisect_rightetinsort, et constitue la brique de base pour maintenir efficacement des listes triées.La recherche par interpolation atteint O(log log n) en moyenne pour des données uniformes en estimant la position de la cible par interpolation linéaire, au prix d’un pire cas en O(n).
La recherche exponentielle est adaptée aux tableaux de taille inconnue ou aux cibles proches du début, avec une complexité de O(log p).
La recherche dans un BST est O(h) et tire parti de la structure arborescente; en Rust,
BTreeMapet la méthodepartition_pointsur les slices offrent des primitives idiomatiques équivalentes.
Le chapitre suivant se consacre aux algorithmes sur les graphes : plus-court chemin avec Dijkstra et Bellman-Ford, arbre couvrant minimal avec Kruskal et Prim, et tri topologique — des algorithmes fondamentaux pour modéliser et résoudre des problèmes de réseau, de planification et d’optimisation.