Algorithmes gloutons#
Principe et intuition#
Un algorithme glouton (greedy algorithm) construit une solution à un problème d’optimisation en effectuant, à chaque étape, le choix qui semble localement le meilleur — sans jamais revenir sur les décisions prises. L’adjectif « glouton » traduit parfaitement cette impulsivité : l’algorithme avale le meilleur morceau disponible à l’instant présent, sans se préoccuper des conséquences futures.
Cette philosophie tranche radicalement avec la programmation dynamique, qui explore systématiquement tous les sous-problèmes possibles avant de combiner les solutions optimales, et encore plus avec la recherche exhaustive, qui énumère toutes les solutions candidates. La stratégie gloutonne est, par nature, irrévocable : aucun retour arrière, aucune remise en question. Cette simplicité lui confère une efficacité remarquable — souvent linéaire ou quasi-linéaire — mais aussi une fragilité : la solution gloutonne n’est optimale que si le problème possède certaines propriétés structurelles précises.
Définition 89 (Algorithme glouton)
Un algorithme glouton est une stratégie de résolution de problèmes d’optimisation qui construit la solution élément par élément, en choisissant à chaque étape l’option localement optimale selon un critère fixé, sans jamais remettre en question les choix déjà effectués. Un algorithme glouton est dit correct pour un problème donné si cette stratégie locale conduit systématiquement à une solution globalement optimale.
L’intuition est séduisante : si à chaque carrefour on prend la meilleure direction locale, on finira bien par atteindre la meilleure destination globale. Mais cette intuition est souvent trompeuse. Considérons un graphe pondéré où l’on cherche le chemin le moins coûteux : choisir à chaque nœud l’arête de poids minimal peut mener dans une impasse coûteuse, alors qu’un détour aurait abouti à un chemin bien moins cher au total. L’algorithme de Dijkstra est glouton et correct pour les graphes à poids positifs ; il est incorrect sur les graphes à poids négatifs.
Conditions d’applicabilité#
Deux propriétés structurelles, lorsqu’elles sont réunies, garantissent qu’un algorithme glouton produit une solution optimale.
Définition 90 (Propriété de choix glouton)
Un problème possède la propriété de choix glouton (greedy-choice property) si une solution optimale globale peut toujours être construite en effectuant le choix localement optimal à chaque étape. Autrement dit, le meilleur choix local est compatible avec au moins une solution optimale : il n’est jamais nécessaire de sacrifier le gain immédiat pour obtenir le gain global maximal.
Définition 91 (Sous-structure optimale)
Un problème possède la propriété de sous-structure optimale si une solution optimale du problème global contient des solutions optimales de ses sous-problèmes. Cette propriété est également requise par la programmation dynamique, mais elle s’exploite différemment : là où la DP combine les solutions de tous les sous-problèmes, l’algorithme glouton n’en résout qu’un seul à chaque étape — celui déterminé par le choix glouton.
Remarque 36
La preuve de correction d’un algorithme glouton suit généralement le schéma de l’échange (exchange argument) :
Supposer qu’il existe une solution optimale
OPTdifférente de la solution gloutonneG.Identifier la première position où
OPTetGdiffèrent.Montrer que l’on peut modifier
OPTpour qu’elle coïncide avecGen ce point, sans dégrader la qualité de la solution.En itérant, transformer
OPTenGsans jamais diminuer la qualité, prouvant ainsi queGest au moins aussi bonne queOPT.
Rendu de monnaie#
Le problème du rendu de monnaie est l’exemple pédagogique par excellence des algorithmes gloutons : simple à énoncer, illustrant parfaitement à la fois la puissance et les limites de l’approche.
Problème. Étant donné un système de pièces (par exemple {1, 2, 5, 10, 20, 50, 100, 200} centimes pour le système euro) et une somme S à rendre, trouver le nombre minimal de pièces permettant de rendre exactement S.
Stratégie gloutonne. À chaque étape, choisir la pièce de valeur maximale qui ne dépasse pas le montant restant à rendre.
Exemple 12 (Rendu de monnaie avec le système euro)
Rendre 83 centimes avec les pièces euro {1, 2, 5, 10, 20, 50} :
Reste 83 : on choisit 50 → reste 33
Reste 33 : on choisit 20 → reste 13
Reste 13 : on choisit 10 → reste 3
Reste 3 : on choisit 2 → reste 1
Reste 1 : on choisit 1 → reste 0
Total : 5 pièces {50, 20, 10, 2, 1}. C’est optimal.
Remarque 37
Contre-exemple. Le système glouton n’est pas universellement optimal. Avec les pièces {1, 3, 4} et la somme 6 :
Stratégie gloutonne : 4 + 1 + 1 → 3 pièces
Solution optimale : 3 + 3 → 2 pièces
Le système euro est dit canonique : la stratégie gloutonne y est prouvée optimale. Cette propriété ne se vérifie pas pour un système arbitraire de pièces. En général, le problème du rendu de monnaie sur un système arbitraire est NP-difficile et requiert la programmation dynamique.
def rendu_monnaie_glouton(pieces, somme):
"""Rendu de monnaie glouton. Retourne la liste des pièces choisies."""
pieces_triees = sorted(pieces, reverse=True)
resultat = []
reste = somme
for piece in pieces_triees:
while reste >= piece:
resultat.append(piece)
reste -= piece
if reste != 0:
return None # Impossible de rendre exactement la somme
return resultat
def rendu_monnaie_dp(pieces, somme):
"""Rendu de monnaie optimal par programmation dynamique."""
INF = float('inf')
dp = [INF] * (somme + 1)
dp[0] = 0
pred = [-1] * (somme + 1)
for s in range(1, somme + 1):
for p in pieces:
if p <= s and dp[s - p] + 1 < dp[s]:
dp[s] = dp[s - p] + 1
pred[s] = p
# Reconstruction
if dp[somme] == INF:
return None
chemin = []
s = somme
while s > 0:
chemin.append(pred[s])
s -= pred[s]
return chemin
# Test : système canonique (euro)
pieces_euro = [1, 2, 5, 10, 20, 50, 100, 200]
for somme in [83, 47, 199]:
glouton = rendu_monnaie_glouton(pieces_euro, somme)
dp = rendu_monnaie_dp(pieces_euro, somme)
print(f"Somme {somme:3d} : glouton={sorted(glouton, reverse=True)} ({len(glouton)} pièces), "
f"DP={sorted(dp, reverse=True)} ({len(dp)} pièces)")
print()
# Test : système non canonique
pieces_nc = [1, 3, 4]
for somme in [6, 7, 8]:
glouton = rendu_monnaie_glouton(pieces_nc, somme)
dp = rendu_monnaie_dp(pieces_nc, somme)
n_g = len(glouton) if glouton else '∞'
n_dp = len(dp) if dp else '∞'
statut = "OK" if glouton and dp and len(glouton) == len(dp) else "SOUS-OPTIMAL"
print(f"Somme {somme} ({pieces_nc}) : glouton={glouton} ({n_g}), DP={dp} ({n_dp}) → {statut}")
Somme 83 : glouton=[50, 20, 10, 2, 1] (5 pièces), DP=[50, 20, 10, 2, 1] (5 pièces)
Somme 47 : glouton=[20, 20, 5, 2] (4 pièces), DP=[20, 20, 5, 2] (4 pièces)
Somme 199 : glouton=[100, 50, 20, 20, 5, 2, 2] (7 pièces), DP=[100, 50, 20, 20, 5, 2, 2] (7 pièces)
Somme 6 ([1, 3, 4]) : glouton=[4, 1, 1] (3), DP=[3, 3] (2) → SOUS-OPTIMAL
Somme 7 ([1, 3, 4]) : glouton=[4, 3] (2), DP=[3, 4] (2) → OK
Somme 8 ([1, 3, 4]) : glouton=[4, 4] (2), DP=[4, 4] (2) → OK
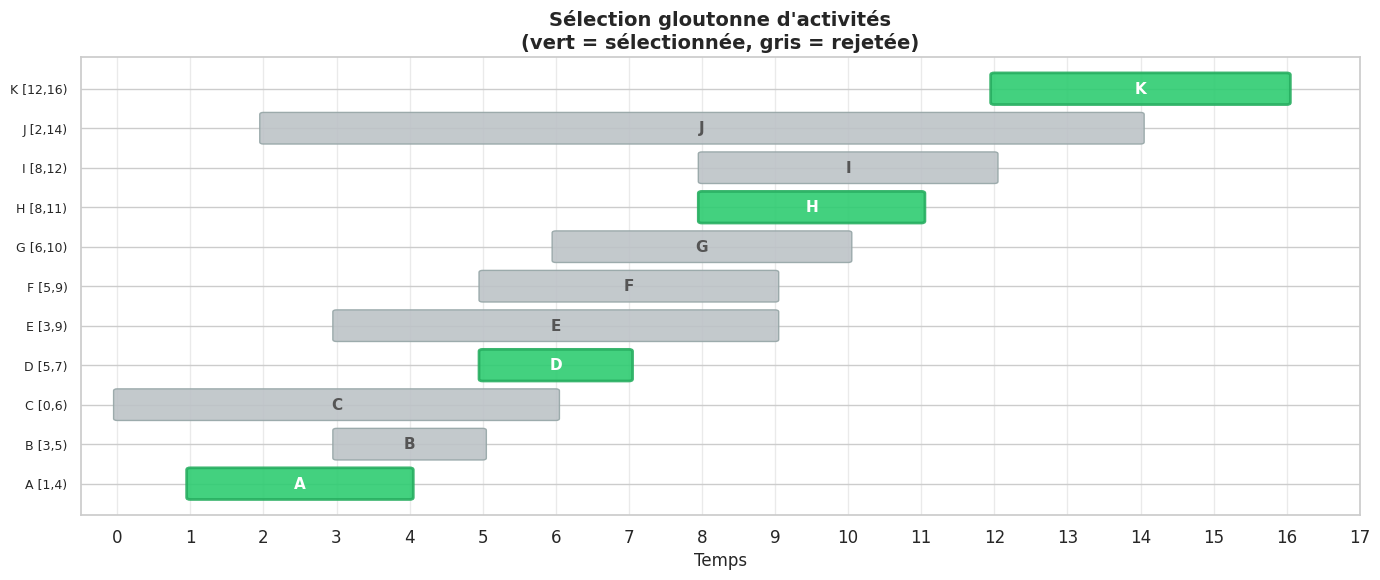
Sélection d’activités#
Le problème de sélection d’activités (interval scheduling) est un problème classique où le choix glouton est prouvé optimal par un argument d’échange élégant.
Problème. On dispose de n activités, chacune caractérisée par un temps de début s_i et un temps de fin f_i. Deux activités sont compatibles si leurs intervalles ne se chevauchent pas. Trouver un sous-ensemble de taille maximale d’activités mutuellement compatibles.
Stratégie gloutonne. Trier les activités par temps de fin croissant, puis sélectionner chaque activité compatible avec la dernière sélectionnée.
Définition 92 (Problème de sélection d’activités)
Étant donné n activités avec des intervalles [s_i, f_i) (début inclus, fin exclue), le problème de sélection d’activités consiste à trouver le sous-ensemble maximum d’activités mutuellement compatibles, c’est-à-dire tel que pour toute paire d’activités sélectionnées i ≠ j, les intervalles [s_i, f_i) et [s_j, f_j) soient disjoints.
Remarque 38
Preuve de correction par échange. Soit G = {a_1, a_2, ..., a_k} la solution gloutonne (activités triées par fin croissante) et OPT = {b_1, b_2, ..., b_m} une solution optimale quelconque. On montre que k = m.
Pour tout indice r, on montre par induction que f(a_r) ≤ f(b_r) : l’activité gloutonne de rang r se termine toujours au plus tard que l’activité optimale de rang r. En effet, a_1 est l’activité de fin minimale parmi toutes les activités, donc f(a_1) ≤ f(b_1). Si f(a_r) ≤ f(b_r), alors toute activité compatible avec {b_1,...,b_r} est aussi compatible avec {a_1,...,a_r}, donc l’algorithme glouton trouve bien une activité a_{r+1} si b_{r+1} existe. On conclut que k ≥ m, d’où k = m.
def selection_activites(activites):
"""
Sélection gloutonne d'activités mutuellement compatibles.
activites : liste de tuples (debut, fin, nom)
Retourne la liste des activités sélectionnées.
"""
# Tri par temps de fin croissant
triees = sorted(activites, key=lambda x: x[1])
selectionnees = []
fin_derniere = -float('inf')
for debut, fin, nom in triees:
if debut >= fin_derniere:
selectionnees.append((debut, fin, nom))
fin_derniere = fin
return selectionnees
# Instance exemple
activites = [
(1, 4, 'A'), (3, 5, 'B'), (0, 6, 'C'), (5, 7, 'D'),
(3, 9, 'E'), (5, 9, 'F'), (6, 10, 'G'), (8, 11, 'H'),
(8, 12, 'I'), (2, 14, 'J'), (12, 16, 'K'),
]
selection = selection_activites(activites)
print(f"Activités disponibles : {len(activites)}")
print(f"Activités sélectionnées ({len(selection)}) :")
for debut, fin, nom in selection:
print(f" {nom} : [{debut}, {fin})")
Activités disponibles : 11
Activités sélectionnées (4) :
A : [1, 4)
D : [5, 7)
H : [8, 11)
K : [12, 16)
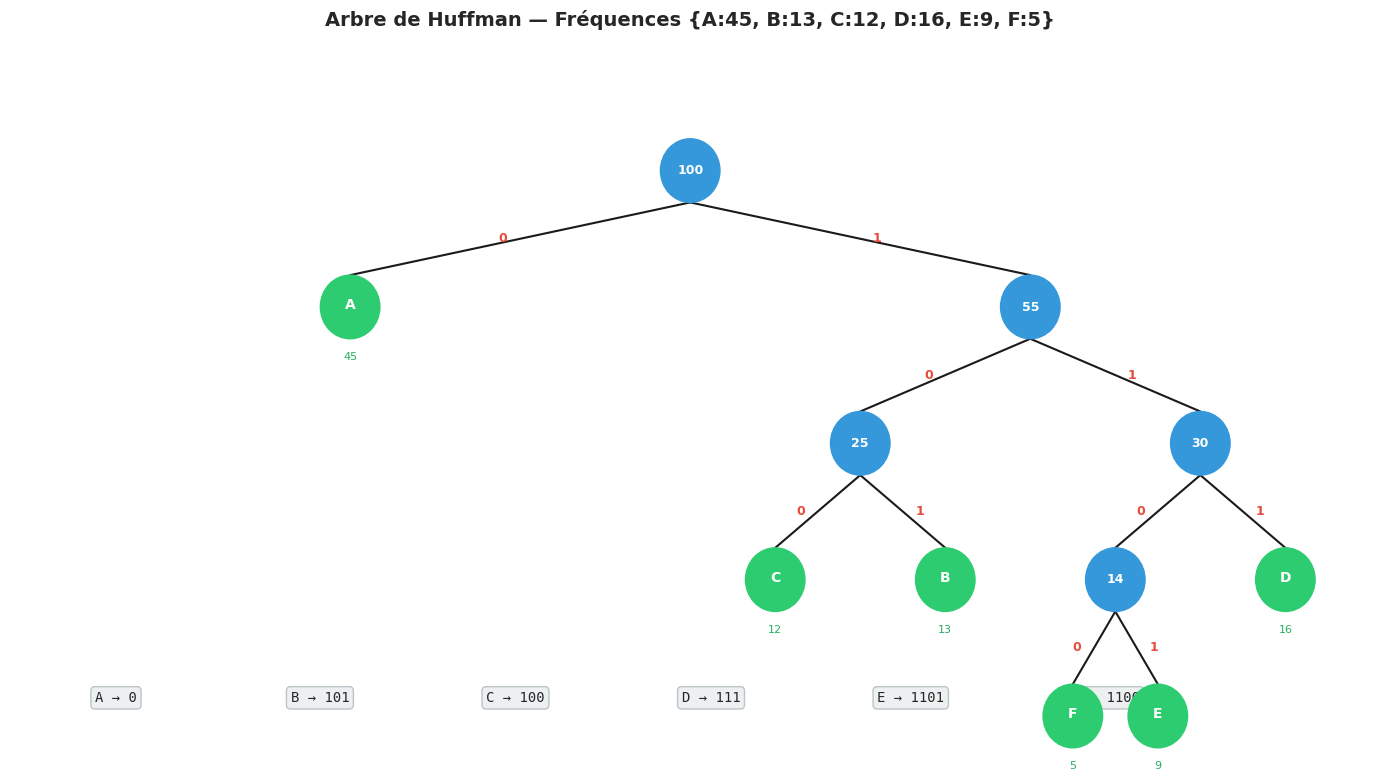
Codage de Huffman#
Le codage de Huffman est l’un des algorithmes gloutons les plus beaux et les plus utiles en pratique. Il construit un code binaire à longueur variable minimisant la longueur moyenne des mots codés, et est utilisé dans des formats de compression comme ZIP, JPEG et PNG.
Problème. Étant donné un alphabet de n symboles avec leurs fréquences d’apparition, construire un code binaire préfixé (aucun code n’est préfixe d’un autre) qui minimise la longueur totale du message codé.
Définition 93 (Code préfixé optimal de Huffman)
Un code préfixé (prefix-free code) est un code binaire dans lequel aucun mot de code n’est préfixe d’un autre. Il peut être représenté par un arbre binaire où chaque feuille correspond à un symbole : les 0 correspondent aux arêtes gauches, les 1 aux arêtes droites. La profondeur d’une feuille est la longueur du code du symbole correspondant.
La longueur attendue d’un tel code est L = Σ f_i · d_i où f_i est la fréquence du symbole i et d_i sa profondeur dans l’arbre. L”algorithme de Huffman construit l’arbre minimisant L.
Algorithme. On maintient une file de priorité (tas-min) des nœuds de l’arbre, ordonnés par fréquence. À chaque étape, on retire les deux nœuds de fréquence minimale et on les fusionne en un nouveau nœud interne dont la fréquence est la somme des deux.
Remarque 39
Optimalité. L’algorithme de Huffman est optimal : l’arbre construit minimise la longueur attendue parmi tous les codes préfixés possibles. La preuve repose sur deux observations gloutonne :
Dans tout arbre optimal, les deux symboles de plus basse fréquence sont à la profondeur maximale et sont frères.
Si l’on remplace ces deux feuilles par leur parent (avec la somme des fréquences), on obtient un problème de taille
n-1dont la solution optimale correspond à la solution optimale du problème original.
Ces deux propriétés permettent d’appliquer l’argument d’échange et de conclure par induction sur n.
import heapq
from dataclasses import dataclass, field
from typing import Optional
@dataclass(order=True)
class NœudHuffman:
frequence: float
symbole: Optional[str] = field(default=None, compare=False)
gauche: Optional['NœudHuffman'] = field(default=None, compare=False)
droite: Optional['NœudHuffman'] = field(default=None, compare=False)
def construire_arbre_huffman(frequences):
"""
Construit l'arbre de Huffman à partir d'un dictionnaire {symbole: fréquence}.
Retourne la racine de l'arbre.
"""
tas = [NœudHuffman(freq, sym) for sym, freq in frequences.items()]
heapq.heapify(tas)
while len(tas) > 1:
gauche = heapq.heappop(tas)
droite = heapq.heappop(tas)
parent = NœudHuffman(
frequence=gauche.frequence + droite.frequence,
gauche=gauche,
droite=droite
)
heapq.heappush(tas, parent)
return tas[0] if tas else None
def extraire_codes(racine, prefixe='', codes=None):
"""Parcourt l'arbre et retourne le dictionnaire {symbole: code binaire}."""
if codes is None:
codes = {}
if racine is None:
return codes
if racine.symbole is not None:
codes[racine.symbole] = prefixe if prefixe else '0'
else:
extraire_codes(racine.gauche, prefixe + '0', codes)
extraire_codes(racine.droite, prefixe + '1', codes)
return codes
# Exemple : fréquences de lettres dans un texte
frequences = {'A': 45, 'B': 13, 'C': 12, 'D': 16, 'E': 9, 'F': 5}
total = sum(frequences.values())
racine = construire_arbre_huffman(frequences)
codes = extraire_codes(racine)
print(f"{'Symbole':>8} {'Fréq':>6} {'Code':>10} {'Longueur':>9} {'Contribution':>14}")
print("-" * 55)
longueur_totale = 0
for sym in sorted(codes):
freq = frequences[sym]
code = codes[sym]
contrib = freq * len(code)
longueur_totale += contrib
print(f"{sym:>8} {freq:>6} {code:>10} {len(code):>9} {contrib:>14}")
print("-" * 55)
print(f"{'Total':>8} {total:>6} {'':>10} {'':>9} {longueur_totale:>14} bits")
print(f"\nLongueur moyenne : {longueur_totale / total:.3f} bits/symbole")
print(f"Code fixe (3 bits) aurait nécessité : {3 * total} bits au total")
print(f"Compression : {100 * (1 - longueur_totale / (3 * total)):.1f}%")
Symbole Fréq Code Longueur Contribution
-------------------------------------------------------
A 45 0 1 45
B 13 101 3 39
C 12 100 3 36
D 16 111 3 48
E 9 1101 4 36
F 5 1100 4 20
-------------------------------------------------------
Total 100 224 bits
Longueur moyenne : 2.240 bits/symbole
Code fixe (3 bits) aurait nécessité : 300 bits au total
Compression : 25.3%
Problème du sac à dos fractionnel#
Le problème du sac à dos (knapsack problem) existe en deux variantes : fractionnelle et 0/1. La distinction est cruciale car seule la version fractionnelle admet une solution gloutonne optimale.
Définition 94 (Sac à dos fractionnel)
Dans le problème du sac à dos fractionnel, on dispose de n objets, chacun caractérisé par un poids w_i et une valeur v_i. La capacité du sac est W. On peut prendre une fraction quelconque de chaque objet. L’objectif est de maximiser la valeur totale chargée sans dépasser la capacité W.
La stratégie gloutonne optimale consiste à trier les objets par rapport valeur/poids décroissant et à les charger dans cet ordre, en prenant autant que possible de chaque objet jusqu’à saturation du sac.
Remarque 40
Pourquoi le glouton échoue pour le sac à dos 0/1. Dans la version 0/1, on doit prendre un objet en entier ou ne pas le prendre du tout. Le glouton par rapport valeur/poids n’est plus optimal : considérons W=10, objets (poids=6, valeur=12) et (poids=5, valeur=10) et (poids=5, valeur=10). Le glouton choisit l’objet de rapport 2 (valeur 12), puis ne peut plus rien ajouter : total 12. La solution optimale est de prendre les deux objets de poids 5 : total 20. La version 0/1 requiert la programmation dynamique en O(nW).
def sac_dos_fractionnel(objets, capacite):
"""
objets : liste de (poids, valeur, nom)
Retourne la valeur maximale et la liste des fractions prises.
"""
# Tri par rapport valeur/poids décroissant
objets_tries = sorted(objets, key=lambda x: x[1] / x[0], reverse=True)
valeur_totale = 0.0
reste = capacite
selection = []
for poids, valeur, nom in objets_tries:
if reste <= 0:
break
fraction = min(1.0, reste / poids)
valeur_totale += fraction * valeur
selection.append((nom, fraction, fraction * poids, fraction * valeur))
reste -= fraction * poids
return valeur_totale, selection
objets = [
(2, 10, 'Or'), # rapport 5.0
(3, 15, 'Argent'), # rapport 5.0
(5, 20, 'Cuivre'), # rapport 4.0
(7, 21, 'Fer'), # rapport 3.0
(4, 8, 'Bois'), # rapport 2.0
]
capacite = 10
valeur, selection = sac_dos_fractionnel(objets, capacite)
print(f"Capacité : {capacite} kg")
print(f"\n{'Objet':>8} {'Fraction':>9} {'Poids pris':>11} {'Valeur':>8}")
print("-" * 45)
for nom, frac, pds, val in selection:
print(f"{nom:>8} {frac:>9.1%} {pds:>11.2f} kg {val:>7.2f}")
print("-" * 45)
print(f"{'Total':>8} {'':>9} {sum(p for _,_,p,_ in selection):>11.2f} kg {valeur:>7.2f}")
Capacité : 10 kg
Objet Fraction Poids pris Valeur
---------------------------------------------
Or 100.0% 2.00 kg 10.00
Argent 100.0% 3.00 kg 15.00
Cuivre 100.0% 5.00 kg 20.00
---------------------------------------------
Total 10.00 kg 45.00
Comparaison avec la programmation dynamique#
Remarque 41
Quand utiliser le glouton, quand utiliser la DP ?
Critère |
Glouton |
Programmation dynamique |
|---|---|---|
Complexité typique |
O(n log n) |
O(n²) à O(nW) |
Optimalité garantie |
Seulement si propriété de choix glouton |
Toujours (si sous-structure optimale) |
Retour arrière |
Non |
Oui (mémoïsation) |
Exemples |
Huffman, Dijkstra, MST |
Sac à dos 0/1, LCS, Floyd-Warshall |
Difficulté de preuve |
Argument d’échange |
Équation de Bellman |
En pratique, on tente d’abord l’approche gloutonne pour sa simplicité et son efficacité. Si la preuve de correction échoue (on trouve un contre-exemple), on recourt à la programmation dynamique.
Implémentation Rust#
use std::collections::BinaryHeap;
use std::cmp::Reverse;
/// Nœud d'un arbre de Huffman.
#[derive(Debug)]
pub enum NœudHuffman {
Feuille { symbole: char, frequence: usize },
Interne {
frequence: usize,
gauche: Box<NœudHuffman>,
droite: Box<NœudHuffman>,
},
}
impl NœudHuffman {
pub fn frequence(&self) -> usize {
match self {
NœudHuffman::Feuille { frequence, .. } => *frequence,
NœudHuffman::Interne { frequence, .. } => *frequence,
}
}
}
impl PartialEq for NœudHuffman {
fn eq(&self, other: &Self) -> bool {
self.frequence() == other.frequence()
}
}
impl Eq for NœudHuffman {}
impl PartialOrd for NœudHuffman {
fn partial_cmp(&self, other: &Self) -> Option<std::cmp::Ordering> {
Some(self.cmp(other))
}
}
impl Ord for NœudHuffman {
fn cmp(&self, other: &Self) -> std::cmp::Ordering {
self.frequence().cmp(&other.frequence())
}
}
/// Construit l'arbre de Huffman à partir des fréquences.
pub fn construire_huffman(frequences: &[(char, usize)]) -> Option<Box<NœudHuffman>> {
let mut tas: BinaryHeap<Reverse<Box<NœudHuffman>>> = frequences
.iter()
.map(|&(sym, freq)| {
Reverse(Box::new(NœudHuffman::Feuille {
symbole: sym,
frequence: freq,
}))
})
.collect();
while tas.len() > 1 {
let Reverse(gauche) = tas.pop().unwrap();
let Reverse(droite) = tas.pop().unwrap();
let freq = gauche.frequence() + droite.frequence();
let parent = Box::new(NœudHuffman::Interne {
frequence: freq,
gauche,
droite,
});
tas.push(Reverse(parent));
}
tas.pop().map(|Reverse(racine)| racine)
}
/// Extrait les codes binaires de l'arbre.
pub fn extraire_codes(
nœud: &NœudHuffman,
prefixe: &str,
codes: &mut Vec<(char, String)>,
) {
match nœud {
NœudHuffman::Feuille { symbole, .. } => {
let code = if prefixe.is_empty() { "0" } else { prefixe };
codes.push((*symbole, code.to_string()));
}
NœudHuffman::Interne { gauche, droite, .. } => {
extraire_codes(gauche, &format!("{}0", prefixe), codes);
extraire_codes(droite, &format!("{}1", prefixe), codes);
}
}
}
/// Sélection gloutonne d'activités par fin croissante.
pub fn selection_activites(activites: &mut Vec<(usize, usize, &str)>) -> Vec<(usize, usize, &str)> {
activites.sort_by_key(|a| a.1); // tri par fin
let mut selectionnees = Vec::new();
let mut fin_derniere = 0;
for &(debut, fin, nom) in activites.iter() {
if debut >= fin_derniere {
selectionnees.push((debut, fin, nom));
fin_derniere = fin;
}
}
selectionnees
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_huffman() {
let freq = vec![('A', 45), ('B', 13), ('C', 12), ('D', 16), ('E', 9), ('F', 5)];
let racine = construire_huffman(&freq).unwrap();
let mut codes = Vec::new();
extraire_codes(&racine, "", &mut codes);
// A doit avoir le code le plus court (fréquence maximale)
let code_a = codes.iter().find(|(c, _)| *c == 'A').unwrap();
let code_f = codes.iter().find(|(c, _)| *c == 'F').unwrap();
assert!(code_a.1.len() <= code_f.1.len());
}
#[test]
fn test_selection_activites() {
let mut activites = vec![
(1, 4, "A"), (3, 5, "B"), (0, 6, "C"),
(5, 7, "D"), (8, 11, "H"), (12, 16, "K"),
];
let sel = selection_activites(&mut activites);
assert_eq!(sel.len(), 4);
}
}
Résumé#
Dans ce chapitre, nous avons étudié les algorithmes gloutons — une stratégie de conception algorithmique qui, lorsqu’elle s’applique, offre des solutions élégantes et efficaces :
Un algorithme glouton construit la solution en effectuant à chaque étape le choix localement optimal, sans retour arrière.
Deux propriétés garantissent la correction : la propriété de choix glouton (le choix local est compatible avec une solution optimale) et la sous-structure optimale (les sous-problèmes ont également des solutions optimales).
La preuve par échange est l’outil standard pour démontrer la correction d’un algorithme glouton.
Le rendu de monnaie illustre à la fois la puissance (systèmes canoniques) et les limites (systèmes arbitraires) de l’approche gloutonne.
La sélection d’activités montre un cas où le glouton est prouvé optimal grâce à un argument d’échange rigoureux.
Le codage de Huffman est l’un des algorithmes gloutons les plus utiles en pratique, minimisant la longueur attendue d’un code préfixé.
Le sac à dos fractionnel est soluble par le glouton, contrairement à la version 0/1 qui requiert la programmation dynamique.
Dans le chapitre suivant, nous explorerons les algorithmes sur les chaînes de caractères, un domaine fondamental pour la recherche de motifs, la bioinformatique et le traitement du texte.