Introduction à l’algorithmique#
Qu’est-ce qu’un algorithme ?#
Le mot algorithme est aujourd’hui omniprésent : on parle de l’algorithme de recommandation d’une plateforme vidéo, de l’algorithme de tri d’un moteur de recherche, de l’algorithme de détection de fraude d’une banque. Pourtant, derrière ce terme se cache une notion mathématique précise, ancienne et profondément structurée, qui mérite d’être définie avec rigueur avant d’en explorer les ramifications.
L”algorithmique est la discipline qui étudie les algorithmes : leur conception, leur analyse et leur mise en œuvre. Elle constitue le cœur théorique de l’informatique et irrigue toutes ses branches applicatives, depuis les systèmes d’exploitation jusqu’à l’intelligence artificielle, en passant par les bases de données et les réseaux.
Définition 1 (Algorithme (Knuth, 1968))
Un algorithme est un ensemble fini de règles précises qui définit une suite d’opérations destinées à résoudre un problème ou une classe de problèmes. Knuth identifie cinq propriétés fondamentales qu’un algorithme doit satisfaire :
Finitude. Un algorithme doit toujours se terminer après un nombre fini d’étapes. Un processus qui ne se terminerait jamais n’est pas un algorithme au sens strict — c’est une procédure de calcul.
Définitude. Chaque étape de l’algorithme doit être définie avec précision et sans ambiguïté. Les instructions doivent être suffisamment claires pour être exécutées mécaniquement, sans recours à l’intuition ou au jugement humain.
Entrées. Un algorithme possède zéro ou plusieurs entrées, c’est-à-dire des quantités qui lui sont fournies avant ou pendant son exécution. Ces entrées appartiennent à des ensembles bien définis.
Sorties. Un algorithme produit une ou plusieurs sorties, c’est-à-dire des quantités qui entretiennent une relation précise avec les entrées. Un algorithme sans sortie ne présente aucun intérêt.
Effectivité. Chaque opération élémentaire doit être suffisamment simple pour pouvoir être effectuée exactement, en un temps fini, par un humain muni d’un papier et d’un crayon.
Cette définition, formulée par Donald Knuth dans The Art of Computer Programming, est aujourd’hui la référence canonique. Elle distingue l’algorithme de simples recettes ou de méthodes informelles : un algorithme est une procédure formelle, finie et déterministe.
Remarque 1
La condition de finitude est souvent la plus délicate à vérifier en pratique. Il est facile d’écrire un algorithme dont on ne sait pas démontrer qu’il se termine toujours. Le problème de l’arrêt (halting problem), démontré indécidable par Alan Turing en 1936, établit qu’il n’existe pas d’algorithme universel capable de déterminer si un programme arbitraire se terminera sur une entrée donnée. Cela ne signifie pas que la question est sans réponse pour des algorithmes particuliers — mais qu’il n’existe pas de méthode automatique et générale pour y répondre.
Une brève histoire de l’algorithmique#
L’algorithmique est une science ancienne, bien antérieure à l’informatique. L’histoire de ses figures fondatrices éclaire la nature profonde de la discipline.
Al-Khwarizmi et l’origine du mot#
Le terme algorithme est une latinisation du nom de Muḥammad ibn Mūsā al-Khwārizmī (vers 780 – vers 850), mathématicien et astronome de la Maison de la Sagesse à Bagdad. Son traité Kitāb al-mukhtaṣar fī ḥisāb al-jabr wa-l-muqābalah (vers 820) a donné naissance au mot algèbre, et les procédures systématiques qu’il y décrit pour résoudre des équations du second degré constituent de véritables algorithmes. Le mot algorithme lui-même provient de la translittération latine de son nom : Algoritmi.
Al-Khwārizmī ne se contentait pas de donner des règles abstraites : il fournissait des procédures pas à pas, valides pour une classe entière de problèmes, et il démontrait leur correction. C’est précisément l’esprit algorithmique.
L’algorithme d’Euclide#
Bien avant al-Khwārizmī, Euclide (vers 300 avant J.-C.) avait décrit dans les Éléments (Livre VII, propositions 1 et 2) un procédé pour calculer le plus grand commun diviseur (PGCD) de deux entiers. Cet algorithme, connu sous le nom d”algorithme d’Euclide, est sans doute le premier algorithme non trivial de l’histoire, et il reste l’un des plus beaux exemples de la discipline : simple à comprendre, rapide à exécuter, et dont la correction et la terminaison se démontrent élégamment.
Exemple 1 (Algorithme d’Euclide)
Le PGCD de deux entiers \(a\) et \(b\) (avec \(a \geq b > 0\)) est calculé par la règle suivante :
Par exemple, pour calculer \(\text{pgcd}(48, 18)\) :
\(\text{pgcd}(48, 18) = \text{pgcd}(18, 12)\) car \(48 \bmod 18 = 12\)
\(\text{pgcd}(18, 12) = \text{pgcd}(12, 6)\) car \(18 \bmod 12 = 6\)
\(\text{pgcd}(12, 6) = \text{pgcd}(6, 0)\) car \(12 \bmod 6 = 0\)
\(\text{pgcd}(6, 0) = 6\)
L’algorithme se termine toujours car le second argument décroît strictement à chaque étape et reste positif.
Ada Lovelace et le premier programme#
Ada Lovelace (1815–1852), fille de Lord Byron et collaboratrice de Charles Babbage, est souvent citée comme la première programmeuse de l’histoire. En 1843, dans ses notes de traduction d’un article de Luigi Menabrea sur la machine analytique de Babbage, elle décrit un algorithme pour calculer les nombres de Bernoulli — considéré comme le premier programme informatique explicite jamais écrit. Lovelace avait compris avant tout le monde que la machine analytique pouvait traiter non seulement des nombres, mais toute quantité représentable par des symboles.
Alan Turing et la fondation théorique#
Alan Turing (1912–1954) est le père fondateur de l’informatique théorique. En 1936, son article On Computable Numbers, with an Application to the Entscheidungsproblem introduit le concept de machine de Turing : un modèle mathématique abstrait capable de simuler tout calcul mécanique. Ce faisant, il donne une définition formelle de ce que signifie calculer et établit les limites absolues du calculable.
La machine de Turing est le modèle de référence pour définir la notion de complexité calculatoire, que nous explorerons au chapitre suivant.
John von Neumann et l’architecture moderne#
John von Neumann (1903–1957) a formalisé l’architecture des ordinateurs modernes : programme et données stockés en mémoire, unité de calcul, unité de contrôle. Il a également contribué à l’algorithmique avec, entre autres, la description du tri fusion (merge sort) en 1945. L’architecture von Neumann est celle qui sous-tend pratiquement tous les ordinateurs actuels.
Problème, instance et algorithme#
La pratique de l’algorithmique repose sur une distinction fondamentale entre trois niveaux d’abstraction.
Définition 2 (Problème algorithmique)
Un problème algorithmique est une relation entre un ensemble d’entrées (instances) et un ensemble de sorties souhaitées. Il est défini par :
une description générale de l’entrée (ce qui est donné) ;
une description de la sortie souhaitée (ce que l’on cherche) ;
les contraintes que la sortie doit satisfaire.
Un problème n’est pas une question sur un cas particulier, mais une famille de questions partageant la même structure.
Définition 3 (Instance)
Une instance d’un problème est un cas particulier de ce problème, c’est-à-dire une valeur spécifique de l’entrée. Pour le problème du tri, l’instance \([5, 3, 8, 1]\) est un tableau particulier à trier. Pour le problème du PGCD, l’instance \((48, 18)\) est une paire d’entiers particuliers.
Définition 4 (Algorithme pour un problème)
Un algorithme pour un problème \(P\) est une procédure finie et précise qui, pour toute instance de \(P\), produit une sortie correcte. Un algorithme résout un problème dans sa généralité, pas seulement quelques cas particuliers.
Remarque 2
La distinction entre problème et instance est cruciale pour l’analyse de complexité. Lorsqu’on dit qu’un algorithme a une complexité en \(O(n \log n)\), on ne parle pas d’une instance particulière mais du comportement de l’algorithme sur toutes les instances de taille \(n\). La taille \(n\) d’une instance est une mesure de la quantité d’information qu’elle contient : pour un tableau, c’est sa longueur ; pour un graphe, c’est le nombre de sommets et d’arêtes ; pour un entier \(N\), c’est le nombre de bits \(\lfloor \log_2 N \rfloor + 1\).
Correction et terminaison#
Concevoir un algorithme ne suffit pas : il faut s’assurer qu’il fait ce qu’on attend de lui. Deux propriétés sont à distinguer.
Définition 5 (Correction partielle)
Un algorithme est partiellement correct par rapport à une spécification si, lorsqu’il se termine, sa sortie satisfait la spécification. La correction partielle ne dit rien sur la terminaison : un algorithme qui boucle indéfiniment est trivialement partiellement correct pour n’importe quelle spécification.
Définition 6 (Terminaison)
Un algorithme se termine (ou termine) si, pour toute entrée valide, il s’arrête après un nombre fini d’étapes. La terminaison est la condition de finitude de Knuth, exprimée comme propriété à vérifier.
Définition 7 (Correction totale)
Un algorithme est totalement correct par rapport à une spécification s’il est à la fois partiellement correct et s’il se termine pour toute entrée valide. La correction totale est la propriété que l’on cherche en pratique : l’algorithme produit toujours la bonne réponse, en temps fini.
La technique classique pour prouver la correction partielle d’un algorithme itératif est le variant de boucle et l”invariant de boucle.
Définition 8 (Invariant de boucle)
Un invariant de boucle est une propriété logique qui est vraie avant l’entrée dans la boucle, reste vraie après chaque itération, et permet de conclure la correction de l’algorithme à la sortie de la boucle. Un invariant de boucle se prouve en trois étapes :
Initialisation : l’invariant est vrai avant la première itération.
Conservation : si l’invariant est vrai au début d’une itération, il est vrai à la fin.
Terminaison : quand la boucle se termine, l’invariant implique la correction de la sortie.
Définition 9 (Variant de boucle)
Un variant de boucle est une quantité entière positive qui décroît strictement à chaque itération. L’existence d’un tel variant garantit la terminaison de la boucle.
L’exemple fil rouge : recherche dans une liste#
Tout au long de ce livre, nous utiliserons des problèmes concrets pour illustrer les concepts. Commençons par le problème de recherche dans une liste, l’un des plus fondamentaux en algorithmique.
Problème. Étant donné un tableau \(A\) de \(n\) éléments et une valeur cible \(x\), déterminer si \(x\) appartient à \(A\), et si oui, retourner son indice.
Algorithme de recherche linéaire#
L’approche la plus immédiate consiste à parcourir le tableau de gauche à droite, en comparant chaque élément à la valeur cible.
Définition 10 (Recherche linéaire (ou séquentielle))
La recherche linéaire parcourt séquentiellement tous les éléments d’un tableau \(A[0..n-1]\) jusqu’à trouver la valeur cible \(x\) ou épuiser le tableau. Son invariant de boucle est : la valeur \(x\) ne se trouve pas dans \(A[0..i-1]\). Son variant de boucle est \(n - i\).
Exemple 2 (Trace de la recherche linéaire)
Rechercher \(x = 7\) dans \(A = [3, 1, 7, 9, 2]\) :
\(i = 0\) : \(A[0] = 3 \neq 7\), continuer.
\(i = 1\) : \(A[1] = 1 \neq 7\), continuer.
\(i = 2\) : \(A[2] = 7 = 7\), retourner \(2\).
Rechercher \(x = 5\) dans \(A = [3, 1, 7, 9, 2]\) :
\(i = 0, 1, 2, 3, 4\) : aucun élément ne vaut \(5\).
Retourner \(-1\) (non trouvé).
Algorithme de recherche binaire#
Si le tableau est trié, on peut faire beaucoup mieux. La recherche binaire exploite l’ordre pour éliminer la moitié des candidats restants à chaque étape.
Définition 11 (Recherche binaire (ou par dichotomie))
La recherche binaire s’applique à un tableau trié \(A[0..n-1]\). Elle maintient deux bornes \(\ell\) et \(r\) délimitant la zone de recherche et compare \(x\) à l’élément médian \(A[m]\) où \(m = \lfloor (\ell + r) / 2 \rfloor\) :
Si \(A[m] = x\) : trouvé, retourner \(m\).
Si \(A[m] < x\) : \(x\) ne peut être que dans \(A[m+1..r]\), poser \(\ell = m + 1\).
Si \(A[m] > x\) : \(x\) ne peut être que dans \(A[\ell..m-1]\), poser \(r = m - 1\).
L’invariant est : si \(x\) se trouve dans \(A\), alors \(x \in A[\ell..r]\). Le variant est \(r - \ell + 1\), qui est divisé par deux à chaque étape, garantissant la terminaison.
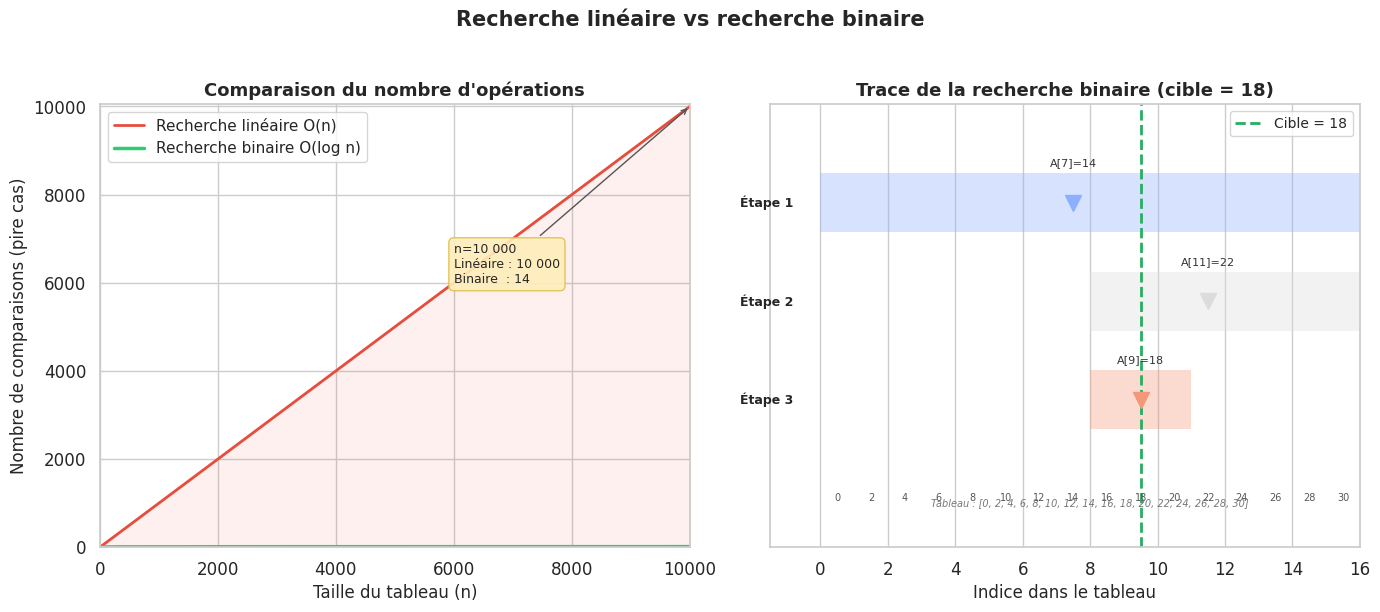
La différence entre les deux algorithmes est saisissante. Sur un tableau de \(10^9\) éléments, la recherche linéaire peut nécessiter jusqu’à \(10^9\) comparaisons. La recherche binaire n’en effectue jamais plus de \(\lceil \log_2(10^9) \rceil = 30\). Ce gain est la première illustration du pouvoir de l’algorithmique : non pas coder plus vite, mais penser mieux.
Implémentation Python#
from typing import Optional
def recherche_lineaire(tableau: list, cible) -> int:
"""
Recherche linéaire : parcours séquentiel du tableau.
Retourne l'indice de la première occurrence de 'cible' dans 'tableau',
ou -1 si la valeur est absente.
Complexité temporelle : O(n) au pire cas.
Complexité spatiale : O(1).
"""
for i, element in enumerate(tableau):
if element == cible:
return i
return -1
def recherche_binaire(tableau: list, cible) -> int:
"""
Recherche binaire : le tableau doit être trié par ordre croissant.
Retourne l'indice d'une occurrence de 'cible' dans 'tableau',
ou -1 si la valeur est absente.
Complexité temporelle : O(log n) au pire cas.
Complexité spatiale : O(1).
"""
gauche, droite = 0, len(tableau) - 1
while gauche <= droite:
milieu = (gauche + droite) // 2
if tableau[milieu] == cible:
return milieu
elif tableau[milieu] < cible:
gauche = milieu + 1
else:
droite = milieu - 1
return -1
# --- Tests ---
import random
random.seed(42)
n = 20
tableau_trie = sorted(random.sample(range(1, 100), n))
print("Tableau trié :", tableau_trie)
cible_presente = tableau_trie[7]
cible_absente = 99
print(f"\nRecherche de {cible_presente} (présent) :")
print(f" Linéaire → indice {recherche_lineaire(tableau_trie, cible_presente)}")
print(f" Binaire → indice {recherche_binaire(tableau_trie, cible_presente)}")
print(f"\nRecherche de {cible_absente} (absent) :")
print(f" Linéaire → indice {recherche_lineaire(tableau_trie, cible_absente)}")
print(f" Binaire → indice {recherche_binaire(tableau_trie, cible_absente)}")
Tableau trié : [4, 5, 12, 14, 15, 18, 28, 29, 30, 32, 36, 55, 65, 70, 72, 76, 78, 82, 87, 95]
Recherche de 29 (présent) :
Linéaire → indice 7
Binaire → indice 7
Recherche de 99 (absent) :
Linéaire → indice -1
Binaire → indice -1
Version instrumentée : compter les comparaisons#
Pour visualiser la différence entre les deux algorithmes, nous ajoutons un compteur de comparaisons.
def recherche_lineaire_compte(tableau: list, cible) -> tuple[int, int]:
"""Retourne (indice, nombre de comparaisons)."""
for i, element in enumerate(tableau):
if element == cible:
return i, i + 1
return -1, len(tableau)
def recherche_binaire_compte(tableau: list, cible) -> tuple[int, int]:
"""Retourne (indice, nombre de comparaisons)."""
gauche, droite = 0, len(tableau) - 1
comparaisons = 0
while gauche <= droite:
comparaisons += 1
milieu = (gauche + droite) // 2
if tableau[milieu] == cible:
return milieu, comparaisons
elif tableau[milieu] < cible:
gauche = milieu + 1
else:
droite = milieu - 1
return -1, comparaisons
# Comparaison sur le pire cas (cible absente, plus grande que tout élément)
tailles = [10, 50, 100, 500, 1000, 5000, 10000]
resultats_lin = []
resultats_bin = []
for n in tailles:
t = list(range(n))
_, c_lin = recherche_lineaire_compte(t, n) # pire cas
_, c_bin = recherche_binaire_compte(t, n) # pire cas
resultats_lin.append(c_lin)
resultats_bin.append(c_bin)
print(f"{'Taille':>8} {'Linéaire':>12} {'Binaire':>12} {'Rapport':>10}")
print("-" * 46)
for n, cl, cb in zip(tailles, resultats_lin, resultats_bin):
print(f"{n:>8} {cl:>12} {cb:>12} {cl/cb:>10.1f}x")
Taille Linéaire Binaire Rapport
----------------------------------------------
10 10 4 2.5x
50 50 6 8.3x
100 100 7 14.3x
500 500 9 55.6x
1000 1000 10 100.0x
5000 5000 13 384.6x
10000 10000 14 714.3x
Implémentation Rust#
Rust offre un cadre idéal pour implémenter des algorithmes à haute performance. Sa garantie d’absence de data races et son système de types permettent d’exprimer clairement les invariants.
/// Recherche linéaire dans un slice trié ou non.
/// Retourne `Some(indice)` si trouvé, `None` sinon.
fn recherche_lineaire<T: PartialEq>(tableau: &[T], cible: &T) -> Option<usize> {
for (i, element) in tableau.iter().enumerate() {
if element == cible {
return Some(i);
}
}
None
}
/// Recherche binaire dans un slice trié par ordre croissant.
/// Retourne `Some(indice)` si trouvé, `None` sinon.
///
/// Cette implémentation est équivalente à `slice::binary_search` de la bibliothèque standard.
fn recherche_binaire<T: Ord>(tableau: &[T], cible: &T) -> Option<usize> {
let mut gauche = 0usize;
let mut droite = tableau.len();
while gauche < droite {
// Calcul du milieu sans risque de dépassement entier.
let milieu = gauche + (droite - gauche) / 2;
match tableau[milieu].cmp(cible) {
std::cmp::Ordering::Equal => return Some(milieu),
std::cmp::Ordering::Less => gauche = milieu + 1,
std::cmp::Ordering::Greater => droite = milieu,
}
}
None
}
fn main() {
let tableau = vec![1, 3, 5, 7, 9, 11, 13, 17, 19, 23];
println!("Tableau : {:?}", tableau);
println!("Recherche de 7 (linéaire) : {:?}", recherche_lineaire(&tableau, &7));
println!("Recherche de 7 (binaire) : {:?}", recherche_binaire(&tableau, &7));
println!("Recherche de 6 (linéaire) : {:?}", recherche_lineaire(&tableau, &6));
println!("Recherche de 6 (binaire) : {:?}", recherche_binaire(&tableau, &6));
// La bibliothèque standard offre binary_search directement :
println!("std binary_search(7) : {:?}", tableau.binary_search(&7));
println!("std binary_search(6) : {:?}", tableau.binary_search(&6));
}
Remarque 3
En Rust, le calcul du milieu s’écrit gauche + (droite - gauche) / 2 plutôt que (gauche + droite) / 2. Cette précaution évite le dépassement entier (integer overflow) pour de très grands tableaux : si gauche et droite sont tous deux proches de usize::MAX, leur somme déborderait. Ce bug, présent dans l’implémentation Java de Arrays.binarySearch pendant des années (rapporté par Joshua Bloch en 2006), illustre que même les algorithmes les plus simples recèlent des pièges subtils.
Visualisation comparative#
Résumé#
Dans ce chapitre, nous avons posé les fondements conceptuels de l’algorithmique :
Un algorithme satisfait cinq propriétés (Knuth) : finitude, définitude, entrées, sorties et effectivité. Ces propriétés le distinguent d’une simple heuristique ou d’un processus informel.
L’algorithmique est une science millénaire : d’Euclide à al-Khwārizmī, d’Ada Lovelace à Turing et von Neumann, chaque époque a apporté des formalisations décisives.
Il convient de distinguer le problème (spécification générale), l”instance (cas particulier) et l”algorithme (procédure générale de résolution).
La correction totale combine la correction partielle (si l’algorithme se termine, sa sortie est correcte) et la terminaison (il se termine toujours). Les invariants et variants de boucle sont les outils formels pour établir ces propriétés.
L’exemple de la recherche dans une liste illustre déjà l’essence de l’algorithmique : la recherche binaire effectue au plus \(\lceil \log_2 n \rceil\) comparaisons là où la recherche linéaire en effectue jusqu’à \(n\) — un avantage qui devient astronomique pour de grandes données.
Dans le chapitre suivant, nous formaliserons la notion d’efficacité avec la complexité algorithmique et les notations asymptotiques grand-\(O\), \(\Omega\) et \(\Theta\).