Complexité algorithmique#
Pourquoi mesurer la complexité ?#
Lorsqu’on dispose de plusieurs algorithmes pour résoudre le même problème, comment choisir le plus efficace ? La réponse naïve serait de les exécuter et de mesurer le temps. Mais cette approche présente des défauts majeurs.
Le temps d’exécution dépend de la machine. Un algorithme lent sur une machine ancienne peut paraître rapide sur un serveur moderne. Deux implémentations du même algorithme dans des langages différents peuvent différer d’un facteur dix, cent, voire mille — sans que cela reflète une différence algorithmique.
Le temps d’exécution dépend de l’implémentation. Des optimisations de bas niveau (gestion du cache, vectorisation SIMD, compilation JIT) peuvent masquer des différences algorithmiques fondamentales sur de petites entrées.
Le temps d’exécution dépend de l’entrée. Un algorithme peut être rapide sur certaines entrées et lent sur d’autres. Quelle mesure retenir ?
La complexité algorithmique répond à ces problèmes en comptant les opérations élémentaires plutôt qu’en mesurant le temps. Elle donne une mesure intrinsèque de l’algorithme, indépendante du matériel et du langage, valable pour des entrées de toute taille.
Définition 12 (Taille d’une entrée)
La taille d’une instance d’un problème est une mesure de la quantité d’information qu’elle contient, notée \(n\). Cette mesure dépend du problème :
Pour un tableau : \(n\) est sa longueur.
Pour une chaîne de caractères : \(n\) est sa longueur.
Pour un entier \(N\) : \(n = \lfloor \log_2 N \rfloor + 1\) est le nombre de bits nécessaires pour le représenter.
Pour un graphe : \(n\) est le nombre de sommets, \(m\) le nombre d’arêtes (on parle de paramètres multiples).
Définition 13 (Complexité en temps)
La complexité en temps d’un algorithme \(A\) est une fonction \(T_A : \mathbb{N} \to \mathbb{N}\) telle que \(T_A(n)\) est le nombre maximal d’opérations élémentaires effectuées par \(A\) sur une entrée de taille \(n\).
Par opération élémentaire, on entend une opération dont le coût est borné par une constante indépendante de \(n\) : comparaison, addition, affectation, accès à un tableau, etc.
La complexité exacte est souvent difficile à calculer et peu utile : elle dépend de la définition précise des opérations élémentaires et de détails d’implémentation. Ce qui importe, c’est le comportement asymptotique : comment la complexité croît-elle quand \(n\) tend vers l’infini ?
Notation grand-O#
La notation grand-\(O\) (lire : « grand O de ») est le standard universel pour exprimer le comportement asymptotique d’une fonction.
Définition 14 (Notation grand-O)
Soient \(f, g : \mathbb{N} \to \mathbb{R}^+\) deux fonctions. On dit que \(f(n) = O(g(n))\) (« \(f\) est un grand-\(O\) de \(g\) ») s’il existe deux constantes \(c > 0\) et \(n_0 \in \mathbb{N}\) telles que :
Intuitivement, \(f = O(g)\) signifie que \(f\) ne croît pas plus vite que \(g\) à un facteur multiplicatif constant près, pour \(n\) suffisamment grand.
Exemple 3 (Exemples de notations grand-O)
\(3n^2 + 5n + 7 = O(n^2)\). En effet, pour \(n \geq 7\) : \(3n^2 + 5n + 7 \leq 3n^2 + 5n^2 + 7n^2 = 15n^2\), donc \(c = 15\) et \(n_0 = 7\) conviennent.
\(\log_2 n = O(\log_{10} n)\) car les logarithmes de bases différentes ne diffèrent que d’un facteur multiplicatif constant (\(\log_2 n = \log_2(10) \cdot \log_{10} n\)). On note donc simplement \(O(\log n)\) sans préciser la base.
\(n! = O(n^n)\) car \(n! = \prod_{k=1}^{n} k \leq \prod_{k=1}^{n} n = n^n\).
\(2^n \neq O(n^k)\) pour tout entier \(k\) fixé : les exponentielles croissent plus vite que tout polynôme.
Règles de calcul#
La notation grand-\(O\) obéit à des règles algébriques qui permettent de calculer la complexité de programmes composés.
Remarque 4
Règles fondamentales de la notation grand-\(O\) :
Règle d’addition. \(O(f) + O(g) = O(\max(f, g))\). Deux blocs de code exécutés séquentiellement ont une complexité égale à la plus grande des deux. En particulier, \(O(n^2) + O(n) = O(n^2)\).
Règle de multiplication. \(O(f) \cdot O(g) = O(f \cdot g)\). Une boucle de \(O(f)\) itérations, chacune de coût \(O(g)\), a un coût total \(O(f \cdot g)\).
Règle de domination. Si \(f(n) = O(g(n))\) et \(f(n) \neq O(h(n))\) pour \(h\) dominée par \(g\), alors le terme \(g\) domine. On ignore les termes dominés : \(5n^3 + 100n^2 + 10^6 n = O(n^3)\).
Règle des constantes. Les constantes multiplicatives s’absorbent dans le \(O\) : \(O(7n) = O(n)\). La notation grand-\(O\) ne s’intéresse pas aux facteurs constants.
Notations Ω et Θ#
La notation grand-\(O\) exprime une borne supérieure. Pour caractériser complètement le comportement d’un algorithme, on utilise aussi des bornes inférieures.
Définition 15 (Notation grand-Ω (oméga))
On dit que \(f(n) = \Omega(g(n))\) s’il existe deux constantes \(c > 0\) et \(n_0 \in \mathbb{N}\) telles que :
\(f = \Omega(g)\) signifie que \(f\) croît au moins aussi vite que \(g\) à un facteur constant près. C’est la notation de borne inférieure : \(T(n) = \Omega(g(n))\) signifie que l’algorithme ne peut pas être plus rapide qu’un facteur constant de \(g(n)\).
Définition 16 (Notation grand-Θ (thêta))
On dit que \(f(n) = \Theta(g(n))\) si \(f(n) = O(g(n))\) et \(f(n) = \Omega(g(n))\) simultanément. Autrement dit, il existent des constantes \(c_1, c_2 > 0\) et \(n_0 \in \mathbb{N}\) telles que :
\(f = \Theta(g)\) signifie que \(f\) et \(g\) ont exactement le même ordre de croissance. C’est la notation d’encadrement exact.
Remarque 5
En pratique, on utilise \(O\) pour les bornes supérieures (pire cas) et \(\Theta\) lorsqu’on peut établir un encadrement exact. Par exemple :
La recherche linéaire sur un tableau de taille \(n\) a une complexité \(\Theta(n)\) au pire cas (l’élément est absent ou en dernière position).
La recherche binaire sur un tableau trié de taille \(n\) a une complexité \(\Theta(\log n)\) au pire cas.
Le tri par insertion a une complexité \(O(n^2)\) au pire cas et \(\Theta(n)\) au meilleur cas (tableau déjà trié).
Lorsqu’on affirme \(O(n^2)\) sans préciser le cas, on sous-entend généralement le pire cas.
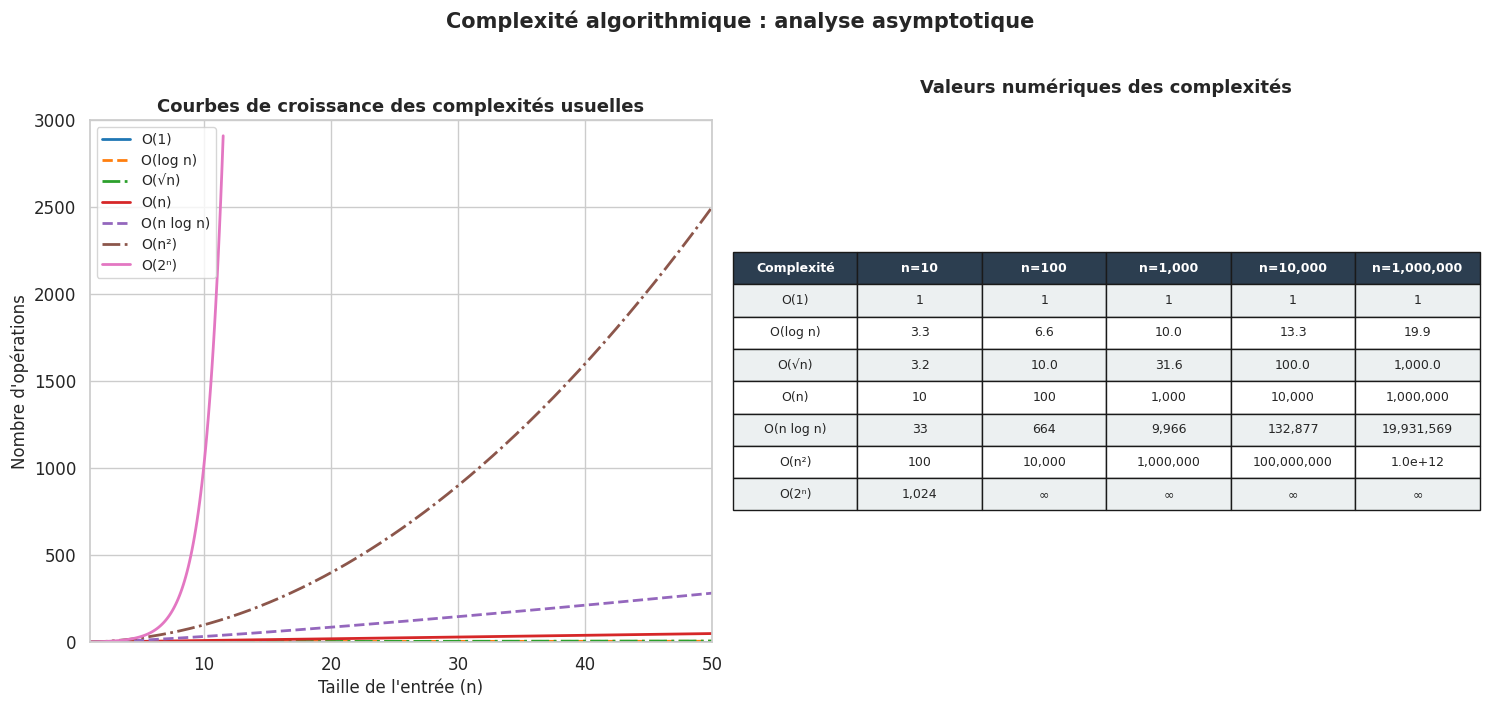
Complexités usuelles#
Les complexités qui apparaissent le plus fréquemment en algorithmique forment une hiérarchie bien connue.
Définition 17 (Hiérarchie des complexités)
Pour \(n\) suffisamment grand, les ordres de croissance suivants sont strictement ordonnés :
Chaque classe est strictement plus lente que la précédente : aucune constante multiplicative ne permet de rattraper la différence pour \(n\) assez grand.
Voici une description précise de chaque complexité, avec des exemples canoniques.
\(O(1)\) — Temps constant. L’algorithme effectue un nombre borné d’opérations, indépendamment de la taille de l’entrée. Exemple : accès à un élément d’un tableau par son indice (A[i]), insertion en tête d’une liste chaînée, consultation du premier élément d’une file.
\(O(\log n)\) — Temps logarithmique. Le problème est divisé par une fraction constante à chaque étape. Exemple : recherche binaire dans un tableau trié, recherche dans un arbre binaire équilibré. Ces algorithmes sont remarquablement efficaces : sur \(10^9\) éléments, \(\log_2(10^9) \approx 30\) étapes suffisent.
\(O(\sqrt{n})\) — Temps sous-linéaire. Apparaît notamment dans des algorithmes de théorie des nombres, comme le test de primalité naïf par division d’essai jusqu’à \(\sqrt{n}\).
\(O(n)\) — Temps linéaire. L’algorithme doit examiner chaque élément de l’entrée au moins une fois. C’est souvent optimal pour des problèmes où chaque donnée est pertinente. Exemple : recherche linéaire, calcul de la somme d’un tableau, premier parcours d’un graphe.
\(O(n \log n)\) — Temps quasi-linéaire. Typique des algorithmes de tri optimaux (tri fusion, tri rapide en moyenne, tri par tas). C’est la borne inférieure pour le tri par comparaison : aucun algorithme de tri basé sur des comparaisons ne peut faire mieux.
\(O(n^2)\) — Temps quadratique. Typique des algorithmes naïfs sur les tableaux : tri à bulles, tri par insertion au pire cas, recherche du plus proche voisin naïve. Acceptable pour \(n \leq 10^4\), rédhibitoire pour \(n \geq 10^6\).
\(O(n^3)\) — Temps cubique. Multiplication matricielle naïve, certains algorithmes de programmation dynamique. Acceptable pour \(n \leq 10^3\).
\(O(2^n)\) — Temps exponentiel. Apparaît dans les algorithmes d’exploration exhaustive : toutes les sous-séquences d’un tableau, toutes les partitions d’un ensemble. Pratiquement inutilisable dès \(n > 30\).
\(O(n!)\) — Temps factoriel. Exploration de toutes les permutations. Inutilisable dès \(n > 12\) ou \(13\).
Exemple 4 (Illustrations des complexités usuelles)
A[i]est \(O(1)\) : un accès mémoire, indépendamment de la taille du tableau.bisect.bisect_left(A, x)est \(O(\log n)\) : recherche binaire sur une liste triée.sum(A)est \(O(n)\) : une addition par élément.sorted(A)est \(O(n \log n)\) : tri par fusion de Timsort (Python).Deux boucles imbriquées sur \(A\) donnent \(O(n^2)\).
fibonacci_naif(n)est \(O(2^n)\) : chaque appel se divise en deux sous-appels.
Analyse par cas#
La complexité d’un algorithme peut varier considérablement selon l’entrée. On distingue trois analyses.
Définition 18 (Analyse au pire cas, meilleur cas, cas moyen)
Pire cas (worst case) : \(T_{\max}(n) = \max_{|x|=n} T(x)\), le maximum sur toutes les entrées de taille \(n\). C’est la garantie absolue : l’algorithme ne prendra jamais plus que \(T_{\max}(n)\) opérations.
Meilleur cas (best case) : \(T_{\min}(n) = \min_{|x|=n} T(x)\). Souvent peu informatif, car le meilleur cas peut être artificiel ou rare.
Cas moyen (average case) : \(T_{\text{moy}}(n) = \mathbb{E}_{|x|=n}[T(x)]\), l’espérance sur une distribution de probabilité sur les entrées de taille \(n\). L’analyse en cas moyen est plus réaliste mais requiert de spécifier la distribution.
Exemple 5 (Analyse du tri rapide (quicksort))
Le tri rapide choisit un élément pivot et partitionne le tableau en deux sous-tableaux : éléments inférieurs au pivot, éléments supérieurs.
Pire cas \(O(n^2)\) : le pivot est toujours le plus petit ou le plus grand élément (tableau déjà trié avec pivot au bord). Chaque appel récursif ne réduit la taille que de 1.
Meilleur cas \(O(n \log n)\) : le pivot est toujours la médiane, divisant le tableau exactement en deux.
Cas moyen \(O(n \log n)\) (en supposant les pivots uniformément distribués) : même si la division n’est pas parfaite, une division constante en deux parties proportionnelles suffit.
En pratique, on utilise des stratégies de choix du pivot (médiane de trois, pivot aléatoire) pour éviter le pire cas et garantir le comportement moyen.
Règles de calcul de la complexité#
Voici les règles pratiques pour déterminer la complexité d’un programme.
Boucle simple. Une boucle for i in range(n) avec un corps en \(O(1)\) a une complexité totale \(O(n)\).
Boucles imbriquées. Deux boucles imbriquées de \(n\) et \(m\) itérations avec un corps en \(O(1)\) donnent \(O(n \cdot m)\). Si \(m = n\), on obtient \(O(n^2)\).
Boucle avec croissance géométrique. Une boucle while i < n: i *= 2 effectue \(\Theta(\log n)\) itérations.
Instruction conditionnelle. if ... else ... a une complexité égale au maximum des deux branches.
Appel de fonction. Le coût d’un appel de fonction est la complexité de cette fonction, plus le coût éventuel des paramètres.
Récursion. On établit une relation de récurrence et on la résout (par le théorème maître, par dépliage, ou par substitution).
Exemple 6 (Récurrence de la recherche binaire)
La recherche binaire sur un tableau de taille \(n\) satisfait la récurrence :
En déroulant : \(T(n) = T(n/2) + c = T(n/4) + 2c = \cdots = T(1) + c \log_2 n = O(\log n)\).
Exemple 7 (Récurrence du tri fusion)
Le tri fusion divise le tableau en deux moitiés, trie chacune récursivement, puis fusionne les deux sous-tableaux triés en \(O(n)\) :
C’est le cas emblématique du théorème maître (forme \(a = 2\), \(b = 2\), \(f(n) = n = n^{\log_2 2}\)) : \(T(n) = \Theta(n \log n)\).
Implémentation et analyse en Python#
def fibonacci_naif(n: int) -> int:
"""
Fibonacci naïf : récursion sans mémoïsation.
Complexité : O(2^n) en temps, O(n) en espace (pile d'appels).
"""
if n <= 1:
return n
return fibonacci_naif(n - 1) + fibonacci_naif(n - 2)
def fibonacci_iteratif(n: int) -> int:
"""
Fibonacci itératif : une seule passe.
Complexité : O(n) en temps, O(1) en espace.
"""
if n <= 1:
return n
a, b = 0, 1
for _ in range(n - 1):
a, b = b, a + b
return b
def tri_bulles(tableau: list) -> list:
"""
Tri à bulles : O(n^2) au pire cas et en moyenne.
"""
t = tableau.copy()
n = len(t)
for i in range(n):
for j in range(0, n - i - 1):
if t[j] > t[j + 1]:
t[j], t[j + 1] = t[j + 1], t[j]
return t
def tri_fusion(tableau: list) -> list:
"""
Tri fusion : O(n log n) dans tous les cas.
"""
if len(tableau) <= 1:
return tableau
milieu = len(tableau) // 2
gauche = tri_fusion(tableau[:milieu])
droite = tri_fusion(tableau[milieu:])
return _fusionner(gauche, droite)
def _fusionner(gauche: list, droite: list) -> list:
resultat = []
i, j = 0, 0
while i < len(gauche) and j < len(droite):
if gauche[i] <= droite[j]:
resultat.append(gauche[i])
i += 1
else:
resultat.append(droite[j])
j += 1
resultat.extend(gauche[i:])
resultat.extend(droite[j:])
return resultat
# Vérification
import random
random.seed(0)
T = [random.randint(0, 100) for _ in range(15)]
print("Entrée :", T)
print("Tri à bulles:", tri_bulles(T))
print("Tri fusion :", tri_fusion(T))
print("sorted() :", sorted(T))
Entrée : [49, 97, 53, 5, 33, 65, 62, 51, 100, 38, 61, 45, 74, 27, 64]
Tri à bulles: [5, 27, 33, 38, 45, 49, 51, 53, 61, 62, 64, 65, 74, 97, 100]
Tri fusion : [5, 27, 33, 38, 45, 49, 51, 53, 61, 62, 64, 65, 74, 97, 100]
sorted() : [5, 27, 33, 38, 45, 49, 51, 53, 61, 62, 64, 65, 74, 97, 100]
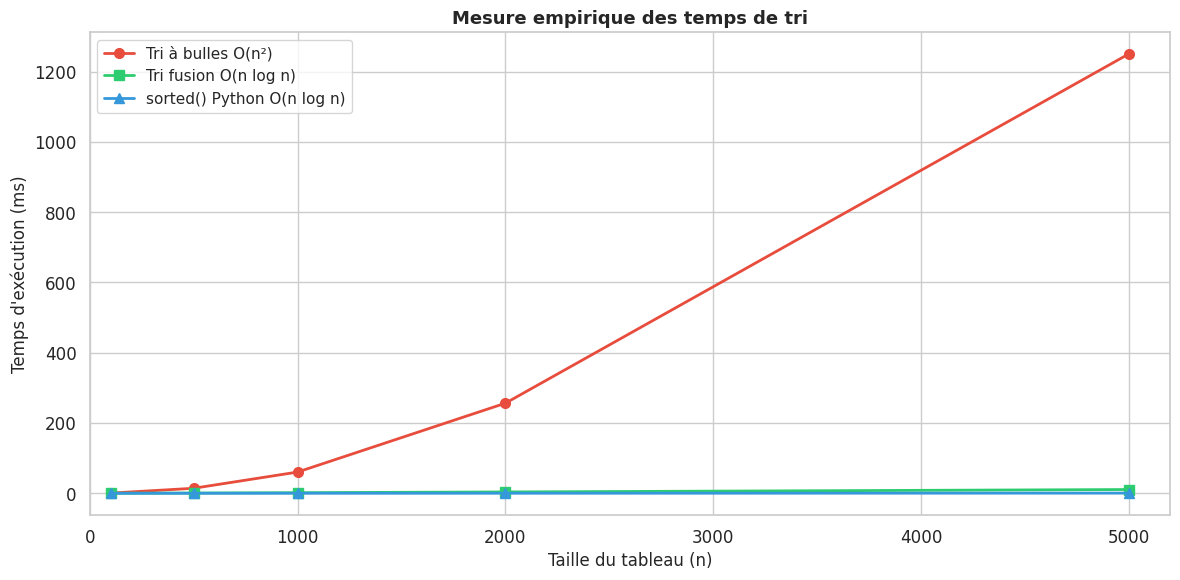
Mesure empirique avec timeit#
import timeit
import random
def mesurer_temps(fonction, generateur_entree, tailles, repetitions=5):
"""
Mesure le temps médian d'exécution de 'fonction' pour chaque taille.
'generateur_entree(n)' produit une entrée de taille n.
"""
resultats = {}
for n in tailles:
entree = generateur_entree(n)
timer = timeit.Timer(lambda e=entree: fonction(e))
temps = timer.repeat(repeat=repetitions, number=1)
resultats[n] = min(temps) # meilleur temps parmi les répétitions
return resultats
random.seed(42)
tailles_tri = [100, 500, 1000, 2000, 5000]
gen = lambda n: [random.randint(0, 10000) for _ in range(n)]
temps_bulles = mesurer_temps(tri_bulles, gen, tailles_tri)
temps_fusion = mesurer_temps(tri_fusion, gen, tailles_tri)
temps_builtin = mesurer_temps(sorted, gen, tailles_tri)
print(f"{'Taille':>8} {'Tri bulles (s)':>16} {'Tri fusion (s)':>16} {'sorted() (s)':>14}")
print("-" * 58)
for n in tailles_tri:
print(f"{n:>8} {temps_bulles[n]:>16.6f} {temps_fusion[n]:>16.6f} {temps_builtin[n]:>14.6f}")
Taille Tri bulles (s) Tri fusion (s) sorted() (s)
----------------------------------------------------------
100 0.000489 0.000125 0.000005
500 0.014272 0.000779 0.000036
1000 0.060398 0.001713 0.000080
2000 0.256370 0.003788 0.000180
5000 1.250481 0.010681 0.000507
Visualisation des complexités#
Résumé#
Dans ce chapitre, nous avons établi les outils fondamentaux de l’analyse d’algorithmes :
La complexité algorithmique mesure le nombre d’opérations élémentaires en fonction de la taille de l’entrée, indépendamment de la machine et du langage. Elle révèle le comportement intrinsèque d’un algorithme.
La notation grand-\(O\) borne la croissance supérieure : \(f = O(g)\) signifie que \(f\) ne croît pas plus vite que \(g\) à un facteur constant près. La notation \(\Omega\) borne inférieurement ; la notation \(\Theta\) encadre exactement.
La hiérarchie des complexités — \(O(1), O(\log n), O(n), O(n \log n), O(n^2), O(2^n)\) — ordonne strictement les algorithmes. Un algorithme \(O(\log n)\) surpassera toujours un \(O(n)\) pour \(n\) assez grand, quel que soit le facteur constant.
Les règles de calcul permettent d’analyser tout programme : addition pour les blocs séquentiels, multiplication pour les boucles imbriquées, récurrences pour la récursion.
La mesure empirique avec
timeitconfirme les prédictions théoriques mais ne les remplace pas : elle dépend de la machine, du système d’exploitation et de la charge courante.
Dans le chapitre suivant, nous explorerons la récursivité — une technique de conception d’algorithmes où une fonction s’appelle elle-même — et verrons comment analyser sa complexité par des relations de récurrence.