24. Maturité DevOps et évolutions#
Ce chapitre de clôture prend du recul sur les pratiques vues tout au long du livre. Il propose un modèle de maturité pour situer votre organisation, présente les résultats du rapport DORA 2023, et explore les tendances qui façonnent le DevOps des prochaines années : Platform Engineering, FinOps, AIOps et eBPF.
Modèle de maturité DevOps#
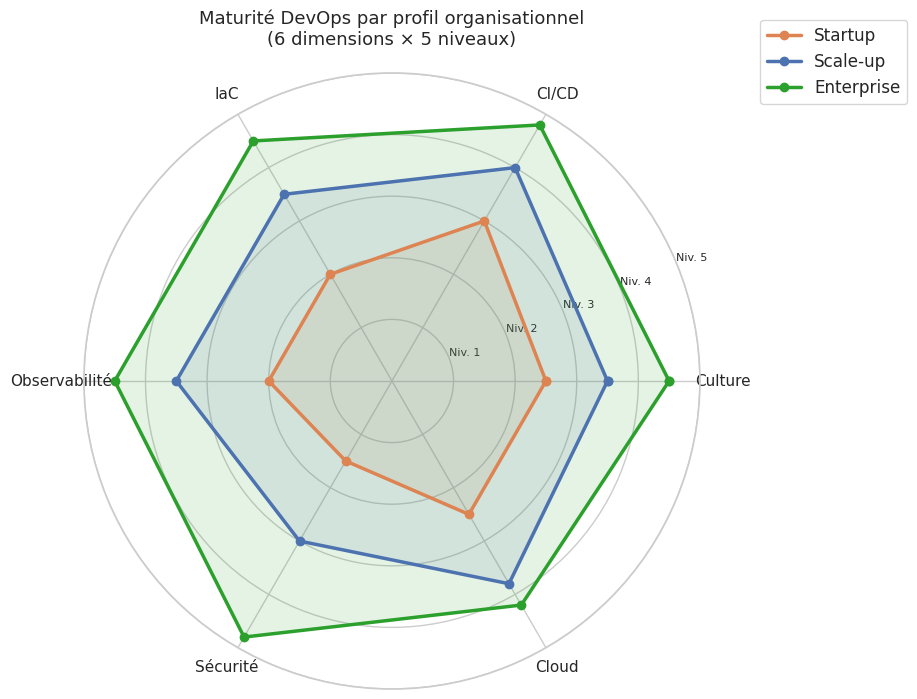
Cinq niveaux, six dimensions#
Le modèle de maturité DevOps structure la progression selon deux axes : le niveau de maturité (1 à 5) et la dimension évaluée.
Niveaux de maturité :
Niveau 1 — Initial : processus ad hoc, déploiements manuels, pas de visibilité
Niveau 2 — Reproductible : CI basique, quelques tests automatisés, pipelines informels
Niveau 3 — Défini : pipelines standardisés, IaC partielle, métriques de base
Niveau 4 — Géré : SLO définis, déploiements automatisés, observabilité complète
Niveau 5 — Optimisé : amélioration continue mesurée, chaos engineering, Platform Engineering
Six dimensions d’évaluation :
Culture : collaboration Dev/Ops, blameless postmortems, partage de l’on-call
CI/CD : automatisation des pipelines, fréquence de déploiement, lead time
IaC : reproductibilité de l’infrastructure, drift detection, modules réutilisables
Observabilité : métriques, logs, traces corrélés, alerting actionnable
Sécurité : shift-left security, Policy as Code, SBOM, scanning dans le pipeline
Cloud : adoption cloud native, containers, Kubernetes, FinOps
DORA 2023 : résultats et corrélations#
Le rapport DORA (DevOps Research and Assessment) de Google Cloud identifie chaque année les pratiques corrélées à la performance business. L’édition 2023 analyse 36 000 professionnels dans 2 700 organisations.
Les quatre métriques DORA#
Deployment Frequency : à quelle fréquence déploie-t-on en production ?
Lead Time for Changes : temps entre le premier commit et le déploiement en production
Change Failure Rate : pourcentage de déploiements qui nécessitent un hotfix ou rollback
Failed Deployment Recovery Time (ex-MTTR) : temps pour restaurer le service après un incident
Résultats 2023#
Les organisations « Elite » (top 18 %) déploient plusieurs fois par jour, avec un lead time inférieur à une heure, un taux d’échec inférieur à 5 % et une restauration en moins d’une heure. Les organisations « Low » déploient tous les six mois à un an, avec un taux d’échec supérieur à 45 %.
La corrélation clé de 2023 : la qualité de la documentation est le prédicteur le plus fort de la performance organisationnelle, devant les pratiques techniques. Les équipes qui documentent leurs systèmes et leurs processus ont 3,8× plus de chances d’atteindre le niveau Elite.
DORA et causalité
Les corrélations DORA ne sont pas des causalités. Déployer plus souvent est la conséquence de bons tests automatisés et de petits changements, pas leur cause. L’objectif est d’améliorer les pratiques fondamentales, pas de maximiser les métriques directement.
Platform Engineering#
Internal Developer Platform (IDP)#
Le Platform Engineering consiste à construire une plateforme interne (IDP — Internal Developer Platform) qui abstrait la complexité opérationnelle. Les développeurs interagissent avec la plateforme via un portail self-service au lieu de gérer directement Kubernetes, Terraform, ou les pipelines CI.
Une IDP typique propose :
Provisioning d’environnements on-demand (dev, preview, staging)
Templates de projets (scaffolding) avec les bonnes pratiques intégrées
Catalogue de services (bases de données, queues, secrets)
Observabilité pré-configurée (dashboards, alertes)
Pipeline CI/CD standardisé
Backstage : le catalogue de services#
Backstage (Spotify, CNCF) est le framework de référence pour construire un portail développeur. Ses composants principaux :
Software Catalog : inventaire de tous les services, APIs et librairies, avec leurs propriétaires et leurs dépendances
Software Templates : scaffolding de nouveaux projets avec les bonnes pratiques intégrées (Dockerfile, tests, pipeline CI, RBAC)
Plugins : intégrations avec GitHub, ArgoCD, Kubernetes, PagerDuty, Grafana…
TechDocs : documentation as code générée depuis les dépôts et centralisée dans le portail
Quand investir dans Platform Engineering ?
Le Platform Engineering devient rentable à partir de 30 à 50 développeurs. En dessous, les pratiques partagées (conventions, templates) suffisent. Au-delà, le coût cognitif de la gestion de l’infrastructure pour chaque équipe dépasse le coût de construction d’une plateforme commune.
Developer Experience (DX) et SPACE framework#
Le framework SPACE (Microsoft Research, 2021) propose cinq dimensions pour mesurer la productivité développeur sans réduire à une seule métrique :
Satisfaction and well-being : sentiment d’efficacité, satisfaction au travail
Performance : résultats produits, qualité perçue
Activity : volumétrie mesurable (PRs, commits, déploiements)
Communication and collaboration : revues de code, documentation, partage de connaissance
Efficiency and flow : interruptions, context switching, time-to-first-commit
Le DX (Developer Experience) se mesure principalement par des enquêtes périodiques (pulse surveys) combinées à des métriques DORA. L’objectif est de réduire le cognitive load : la charge mentale imposée aux développeurs pour accomplir leur travail.
FinOps : économie du cloud#
Visibilité et responsabilisation#
Le FinOps est la pratique qui allie la finance, les opérations et l’engineering pour optimiser les coûts cloud. Ses trois phases selon la FinOps Foundation :
Inform : rendre les coûts visibles par service, équipe et environnement (tagging, cost allocation)
Optimize : rightsizing, instances Spot/Preemptible, Savings Plans, Committed Use
Operate : budgets, alertes de dérive, unit economics (coût par requête, par utilisateur actif)
Techniques d’optimisation#
Rightsizing : réduire les tailles d’instances sous-utilisées (CloudWatch, Azure Monitor, Cloud Monitoring détectent automatiquement les candidats)
Instances Spot/Preemptible : 60 à 90 % moins chères pour les charges interruptibles (jobs CI, workers, batch)
Réservations et Savings Plans : 30 à 60 % d’économie pour les charges stables avec engagement 1 ou 3 ans
Unit economics : exprimer les coûts en termes business (\(/1000 requêtes API, \)/utilisateur actif mensuel) pour aligner engineering et finance
AIOps : l’IA au service des opérations#
Analyse d’incidents par LLM#
Les LLM transforment la réponse aux incidents en proposant :
Corrélation automatique : relier une alerte Prometheus à des logs Loki et des traces Jaeger pour identifier la cause racine sans investigation manuelle
Génération de runbooks : à partir de l’historique des incidents, générer automatiquement des runbooks avec les étapes de diagnostic et de remédiation
Résumés d’incidents : produire en temps réel un résumé de la timeline de l’incident pour les stakeholders non techniques
Anomaly detection#
Les outils d’anomaly detection (Prometheus avec DBSCAN, Grafana ML, Datadog Watchdog) identifient les déviations statistiques sans seuils manuels. Ils sont particulièrement efficaces pour les métriques à saisonnalité forte (trafic web, batch nocturne).
Limites de l’AIOps
L’AIOps amplifie les capacités humaines mais ne les remplace pas. Un LLM peut suggérer une cause racine erronée avec une confiance élevée. La validation humaine reste indispensable avant toute action en production.
eBPF : fondation des outils DevOps modernes#
eBPF (extended Berkeley Packet Filter) est une technologie du noyau Linux qui permet d’exécuter des programmes sandboxés dans l’espace noyau sans modifier le code noyau. Elle est devenue la fondation de nombreux outils DevOps modernes.
Observabilité :
Pixie : observabilité automatique sans instrumentation (traces, profiling, métriques réseau)
Parca : profiling continu en production (CPU, mémoire) avec faible overhead
Réseau et sécurité :
Cilium : CNI Kubernetes basé sur eBPF, remplace iptables, supporte le service mesh sans sidecar
Tetragon : détection d’intrusion au niveau noyau (appels système, ouverture de fichiers, connexions réseau)
L’avantage clé d’eBPF est l”overhead quasi-nul : instrumenter une application eBPF coûte 1 à 3 % de CPU, contre 5 à 15 % pour un sidecar Envoy.
Roadmap d’adoption DevOps#
Selon le contexte organisationnel#
Startup (< 10 développeurs) :
GitHub Actions avec runners hosted — pas d’infrastructure CI à gérer
Docker Compose en production initiale, migration Kubernetes à 5+ services
Terraform pour les ressources cloud dès le début (évite la dette technique)
Observabilité basique : Grafana Cloud free tier
PagerDuty ou Opsgenie pour l’on-call dès le premier service en production
Scale-up (10–100 développeurs) :
Runners self-hosted Spot pour réduire les coûts CI de 60 %
Kubernetes multi-environnements avec ArgoCD
Kyverno pour les premières politiques de sécurité
Stack d’observabilité auto-hébergée (Prometheus, Loki, Tempo, Grafana)
SLO définis et tableau de bord error budget
Enterprise (> 100 développeurs) :
Platform Engineering avec Backstage
Multi-cluster Kubernetes (régions, BUs) avec ArgoCD fleet management
OPA Gatekeeper + Conftest pour la conformité SOC 2/ISO 27001
FinOps avec chargeback par équipe
Chaos engineering avec Litmus ou Chaos Monkey
Ce que ce livre ne couvre pas#
Ce livre couvre les fondations du DevOps moderne, mais plusieurs domaines méritent une exploration approfondie :
Chaos Engineering : Chaos Monkey (Netflix) et Litmus (CNCF) permettent d’injecter des pannes contrôlées en production pour valider la résilience. Le principe de Chaos Engineering — tester les hypothèses sur le comportement du système sous stress — complète naturellement les SLO.
SRE Book Google : « Site Reliability Engineering » (O’Reilly, disponible gratuitement en ligne) reste la référence théorique sur les error budgets, la gestion de la capacité et la culture de l’ingénierie de fiabilité.
Service Mesh avancé : Istio et Linkerd 2 offrent des capacités de traffic management (circuit breaker, retry, fault injection) et de sécurité mTLS qui dépassent ce qui a été vu dans ce livre.
Kubernetes Operators : le pattern Operator (controller custom + CRD) permet d’encoder la connaissance opérationnelle d’une application dans Kubernetes. C’est la prochaine étape après la maîtrise des ressources standard.
Visualisations#
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import pandas as pd
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Radar chart de maturité DevOps multi-profils
# 6 axes × 3 profils : startup / scale-up / enterprise
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
dimensions = ["Culture", "CI/CD", "IaC", "Observabilité", "Sécurité", "Cloud"]
N = len(dimensions)
profils = {
"Startup": [2.5, 3.0, 2.0, 2.0, 1.5, 2.5],
"Scale-up": [3.5, 4.0, 3.5, 3.5, 3.0, 3.8],
"Enterprise": [4.5, 4.8, 4.5, 4.5, 4.8, 4.2],
}
couleurs = ["#dd8452", "#4c72b0", "#2ca02c"]
angles = [n / float(N) * 2 * np.pi for n in range(N)]
angles += angles[:1]
fig, ax = plt.subplots(figsize=(8, 8), subplot_kw=dict(polar=True))
for (label, scores), couleur in zip(profils.items(), couleurs):
vals = scores + scores[:1]
ax.plot(angles, vals, "o-", linewidth=2.5, color=couleur, label=label)
ax.fill(angles, vals, alpha=0.12, color=couleur)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(dimensions, size=11)
ax.set_ylim(0, 5)
ax.set_yticks([1, 2, 3, 4, 5])
ax.set_yticklabels(["Niv. 1", "Niv. 2", "Niv. 3", "Niv. 4", "Niv. 5"], size=8)
ax.set_title("Maturité DevOps par profil organisationnel\n(6 dimensions × 5 niveaux)",
size=13, pad=20)
ax.legend(loc="upper right", bbox_to_anchor=(1.35, 1.1))
plt.show()
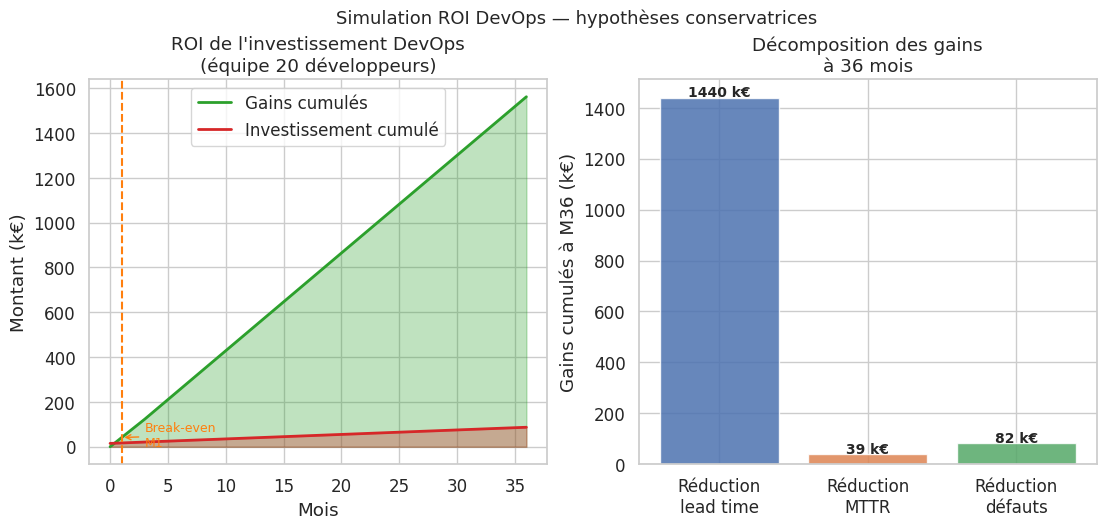
# Simulation du ROI d'un investissement DevOps
# Réduction du MTTR et du lead time → économies cumulées
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(21)
mois = np.arange(0, 37) # 3 ans
# Hypothèses (équipe de 20 développeurs, salaire moyen 60 k€/an)
cout_heure_dev = 60_000 / (12 * 20 * 8) # ~31 €/heure
# Investissement DevOps : 15 k€ en M0 + 2 k€/mois (tooling, formation)
investissement_cumule = 15_000 + 2_000 * mois
# Gains cumulés mensuels
# Réduction lead time : de 5 jours à 1 jour → 4 jours × 20 devs × 2 fois/mois
gain_lead_time = 4 * 8 * cout_heure_dev * 20 * 2 * mois # cumulé
# Réduction MTTR : de 4h à 30min → 3.5h économisées × 2 incidents/mois
gain_mttr = 3.5 * cout_heure_dev * 5 * 2 * mois # 5 personnes mobilisées
# Réduction des défauts en production : -70 % de bugs prod → -10 jours de rework/mois
gain_qualite = 10 * 8 * cout_heure_dev * np.clip(mois - 3, 0, None) # commence à M3
gains_cumules = gain_lead_time + gain_mttr + gain_qualite
roi = gains_cumules - investissement_cumule
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(13, 5))
ax1.fill_between(mois, gains_cumules / 1000, alpha=0.3, color="#2ca02c")
ax1.fill_between(mois, investissement_cumule / 1000, alpha=0.3, color="#d62728")
ax1.plot(mois, gains_cumules / 1000, color="#2ca02c", linewidth=2, label="Gains cumulés")
ax1.plot(mois, investissement_cumule / 1000, color="#d62728", linewidth=2,
label="Investissement cumulé")
# Point de break-even
breakeven = np.argmax(roi >= 0)
if breakeven > 0:
ax1.axvline(x=breakeven, color="#ff7f0e", linestyle="--", linewidth=1.5)
ax1.annotate(f"Break-even\nM{breakeven}",
xy=(breakeven, gains_cumules[breakeven] / 1000),
xytext=(breakeven + 2, gains_cumules[breakeven] / 1000 - 40),
fontsize=9, color="#ff7f0e",
arrowprops=dict(arrowstyle="->", color="#ff7f0e"))
ax1.set_xlabel("Mois")
ax1.set_ylabel("Montant (k€)")
ax1.set_title("ROI de l'investissement DevOps\n(équipe 20 développeurs)")
ax1.legend()
# Décomposition des gains en M36
gains_m36 = {
"Réduction\nlead time": gain_lead_time[-1] / 1000,
"Réduction\nMTTR": gain_mttr[-1] / 1000,
"Réduction\ndéfauts": gain_qualite[-1] / 1000,
}
couleurs_bar = ["#4c72b0", "#dd8452", "#55a868"]
bars = ax2.bar(gains_m36.keys(), gains_m36.values(),
color=couleurs_bar, alpha=0.85)
for bar, val in zip(bars, gains_m36.values()):
ax2.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 5,
f"{val:.0f} k€", ha="center", fontsize=10, fontweight="bold")
ax2.set_ylabel("Gains cumulés à M36 (k€)")
ax2.set_title("Décomposition des gains\nà 36 mois")
plt.suptitle("Simulation ROI DevOps — hypothèses conservatrices",
fontsize=13, y=1.02)
plt.show()
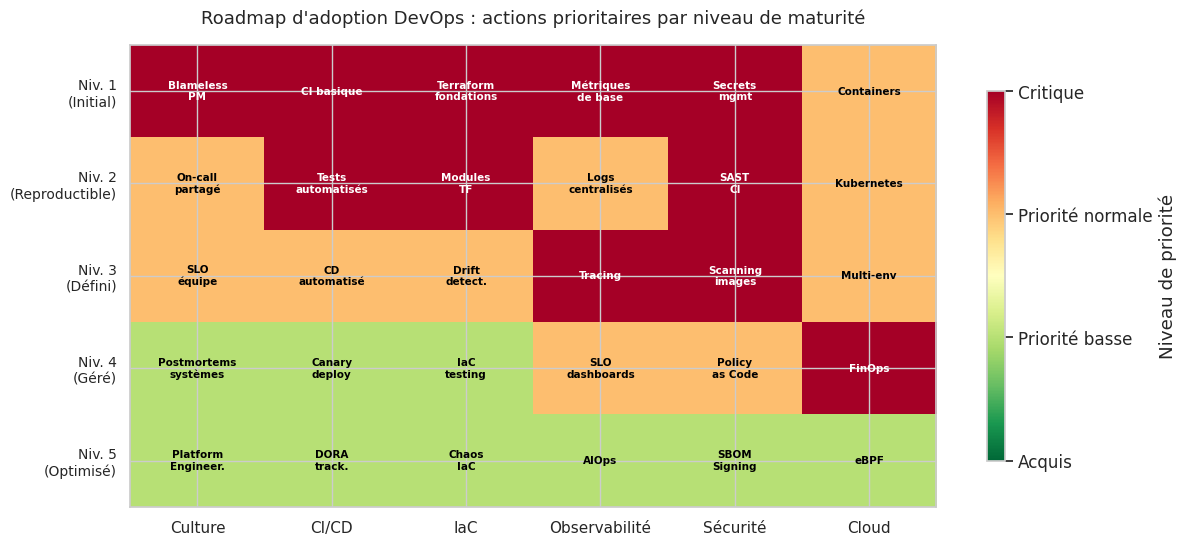
# Heatmap roadmap : actions prioritaires selon niveau de maturité actuel
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
niveaux = ["Niv. 1\n(Initial)", "Niv. 2\n(Reproductible)",
"Niv. 3\n(Défini)", "Niv. 4\n(Géré)", "Niv. 5\n(Optimisé)"]
dimensions_hm = ["Culture", "CI/CD", "IaC", "Observabilité", "Sécurité", "Cloud"]
# Priorité d'action : 0 = déjà acquis, 1 = priorité basse, 2 = priorité normale, 3 = critique
# Lignes = niveau actuel, colonnes = dimension
# Lecture : si vous êtes au niveau X, quelle est la priorité de travailler la dimension Y ?
priorites = np.array([
# Culture CI/CD IaC Observ Sécu Cloud
[3, 3, 3, 3, 3, 2], # Niv. 1 : tout est urgent
[2, 3, 3, 2, 3, 2], # Niv. 2 : CI/CD et IaC restent critiques
[2, 2, 2, 3, 3, 2], # Niv. 3 : observabilité et sécurité
[1, 1, 1, 2, 2, 3], # Niv. 4 : cloud et optimisation
[1, 1, 1, 1, 1, 1], # Niv. 5 : maintenance et innovation
], dtype=float)
etiquettes = np.array([
["Blameless\nPM", "CI basique", "Terraform\nfondations", "Métriques\nde base", "Secrets\nmgmt", "Containers"],
["On-call\npartagé", "Tests\nautomatisés", "Modules\nTF", "Logs\ncentralisés", "SAST\nCI", "Kubernetes"],
["SLO\néquipe", "CD\nautomatisé", "Drift\ndetect.", "Tracing", "Scanning\nimages", "Multi-env"],
["Postmortems\nsystèmes", "Canary\ndeploy", "IaC\ntesting", "SLO\ndashboards", "Policy\nas Code", "FinOps"],
["Platform\nEngineer.", "DORA\ntrack.", "Chaos\nIaC", "AIOps", "SBOM\nSigning", "eBPF"],
])
fig, ax = plt.subplots(figsize=(13, 6))
im = ax.imshow(priorites, cmap="RdYlGn_r", vmin=0, vmax=3, aspect="auto")
ax.set_xticks(range(len(dimensions_hm)))
ax.set_xticklabels(dimensions_hm, fontsize=11)
ax.set_yticks(range(len(niveaux)))
ax.set_yticklabels(niveaux, fontsize=10)
for i in range(len(niveaux)):
for j in range(len(dimensions_hm)):
priorite = priorites[i, j]
couleur_txt = "white" if priorite >= 2.5 else "black"
ax.text(j, i, etiquettes[i, j],
ha="center", va="center", fontsize=7.5,
color=couleur_txt, fontweight="bold")
cbar = plt.colorbar(im, ax=ax, shrink=0.8)
cbar.set_ticks([0, 1, 2, 3])
cbar.set_ticklabels(["Acquis", "Priorité basse", "Priorité normale", "Critique"])
cbar.set_label("Niveau de priorité")
ax.set_title("Roadmap d'adoption DevOps : actions prioritaires par niveau de maturité",
fontsize=13, pad=15)
plt.show()
Résumé#
Le modèle de maturité DevOps à cinq niveaux et six dimensions fournit une grille d’autoévaluation objective qui permet d’identifier les gaps et de prioriser les investissements selon le contexte organisationnel.
Le rapport DORA 2023 confirme que les organisations « Elite » déploient plusieurs fois par jour avec un lead time inférieur à une heure ; la qualité de la documentation est le prédicteur le plus fort de performance, devant les pratiques techniques.
Le Platform Engineering devient rentable au-delà de 30 à 50 développeurs ; Backstage (CNCF) est le framework de référence pour construire un portail self-service réduisant le cognitive load des équipes produit.
Le framework SPACE offre une vision multidimensionnelle de la productivité développeur qui évite les dérives d’une optimisation sur une seule métrique (nombre de commits, vitesse des PRs).
Le FinOps structure l’optimisation des coûts cloud en trois phases (Inform → Optimize → Operate) ; les unit economics (coût par requête, par utilisateur actif) alignent engineering et finance sur des objectifs partagés.
L’AIOps accélère la réponse aux incidents par la corrélation automatique des signaux et la génération de runbooks, mais ne remplace pas le jugement humain pour les décisions en production.
eBPF est la technologie sous-jacente aux outils d’observabilité et de sécurité les plus modernes (Cilium, Tetragon, Pixie, Parca) ; son faible overhead (1 à 3 % CPU) en fait une alternative sérieuse aux sidecars traditionnels.
La roadmap d’adoption dépend fortement du contexte : une startup doit d’abord poser des fondations CI/CD et IaC solides, tandis qu’une enterprise doit investir dans le Platform Engineering et la gouvernance à l’échelle.
Le chaos engineering (Litmus, Chaos Monkey) et le SRE Book Google sont les prochaines étapes naturelles après la maîtrise des SLO et de l’observabilité : valider les hypothèses de résilience par des expériences contrôlées.
Le DevOps n’est pas une destination mais un processus d’amélioration continue : les organisations qui atteignent le niveau 5 ne s’arrêtent pas — elles mesurent, expérimentent, et élèvent continuellement leur niveau d’exigence.