18. Alerting et on-call#
Une alerte qui se déclenche sans qu’un ingénieur sache quoi faire est pire qu’une absence d’alerte : elle génère de l’anxiété, de la fatigue et érode la confiance dans le système d’alerting. Ce chapitre couvre la conception d’alertes actionnables, les stratégies de réduction du bruit, l’organisation des astreintes et la boucle de rétroaction post-mortem.
Anatomie d’une bonne alerte#
Une alerte de qualité satisfait quatre critères :
Actionnabilité : chaque alerte doit correspondre à une action définie. Si personne ne sait quoi faire, l’alerte ne doit pas exister ou doit être rétrogradée en ticket.
Urgence justifiée : l’alerte interrompt un être humain à n’importe quelle heure. Cette interruption doit être proportionnée à l’impact réel. Une alerte qui se déclenche à 3h du matin pour un problème qui peut attendre le matin est un défaut de conception.
Contexte embarqué : l’alerte doit inclure les informations nécessaires pour commencer le diagnostic — service impacté, environnement, valeur courante vs seuil, durée depuis le déclenchement, et un lien vers le runbook.
Lien vers le runbook : la documentation de réponse doit être accessible depuis l’alerte elle-même. Un runbook sans lien est un runbook qui ne sera pas consulté à 3h du matin.
Structure d’annotation Prometheus recommandée :
groups:
- name: availability
rules:
- alert: HighErrorRate
expr: |
sum(rate(http_requests_total{status=~"5.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
> 0.05
for: 5m
labels:
severity: critical
team: backend
annotations:
summary: "Taux d'erreurs élevé sur {{ $labels.service }}"
description: |
Le service {{ $labels.service }} présente un taux d'erreurs de
{{ $value | humanizePercentage }} depuis 5 minutes.
runbook_url: "https://wiki.example.com/runbooks/high-error-rate"
dashboard_url: "https://grafana.example.com/d/abc123"
Alerte sur symptôme vs cause vs SLO#
Alerte sur cause (à éviter comme règle principale) : « Le CPU est à 90% ». La cause n’implique pas toujours un impact utilisateur — un batch CPU-intensif peut tourner à 90% sans dégradation de service.
Alerte sur symptôme : « Le taux d’erreurs HTTP 5xx dépasse 5% ». Le symptôme traduit directement une dégradation vécue par l’utilisateur. C’est la base de l’alerting SRE.
Alerte sur SLO : la forme la plus mature. Au lieu d’alerter sur un seuil fixe, on alerte lorsque le budget d’erreur (error budget) se consume trop vite. Si votre SLO est 99,9% de disponibilité sur 30 jours, votre budget d’erreur est 43,2 minutes. Une alerte sur SLO se déclenche quand la vitesse de consommation menace d’épuiser ce budget avant la fin de la fenêtre.
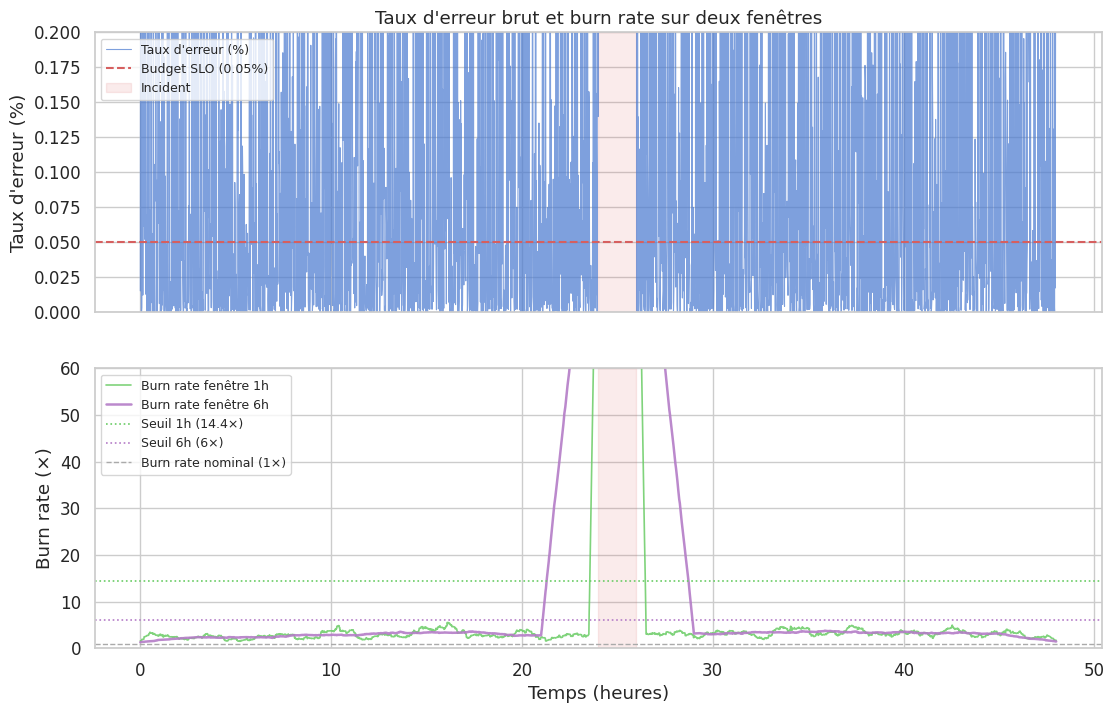
Burn rate alerting#
Le burn rate mesure la vitesse à laquelle le budget d’erreur est consommé, exprimée en multiples de la vitesse nominale.
Un burn rate de 1 consomme exactement le budget en 30 jours. Un burn rate de 14,4 consomme le budget en 2 heures (30 jours × 24 heures / 14,4 ≈ 50 heures… mais la formule est : budget_window / (burn_rate × window_duration)).
La stratégie à deux fenêtres (Google SRE Workbook) :
Fenêtre courte (1h) — détection rapide, peut être bruyante :
# Burn rate sur 1 heure
(
sum(rate(http_requests_total{status=~"5.."}[1h]))
/
sum(rate(http_requests_total[1h]))
) / 0.001 > 14.4
Fenêtre longue (6h) — confirmation, moins de faux positifs :
# Burn rate sur 6 heures
(
sum(rate(http_requests_total{status=~"5.."}[6h]))
/
sum(rate(http_requests_total[6h]))
) / 0.001 > 6
L’alerte se déclenche si les deux fenêtres dépassent leur seuil simultanément — ce qui élimine les pics transitoires tout en garantissant une détection rapide des incidents sérieux.
Seuils recommandés (SLO 99,9%, fenêtre 30j) :
Sévérité |
Fenêtre courte |
Seuil court |
Fenêtre longue |
Seuil long |
Budget consommé |
|---|---|---|---|---|---|
Page critique |
1h |
14,4× |
6h |
6× |
5% en 1h |
Page warning |
6h |
6× |
24h |
3× |
10% en 6h |
Ticket |
3j |
1× |
— |
— |
Tout dépassement |
Réduction du bruit avec Alertmanager#
Alertmanager est le composant Prometheus qui reçoit les alertes et gère leur routage, leur déduplication et leur silence.
Grouping : regrouper les alertes similaires pour éviter une tempête de notifications lors d’une panne transversale.
Inhibition : une alerte critique peut inhiber des alertes de moindre sévérité corrélées. Si le datacenter est down, on n’envoie pas 200 alertes individuelles pour chaque service.
Silences : suspension temporaire d’une alerte pendant une maintenance planifiée.
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'pagerduty-critical'
routes:
- match:
severity: warning
receiver: 'slack-warning'
continue: false
- match:
severity: critical
receiver: 'pagerduty-critical'
inhibit_rules:
- source_match:
severity: 'critical'
alertname: 'ClusterDown'
target_match:
severity: 'warning'
equal: ['cluster']
receivers:
- name: 'pagerduty-critical'
pagerduty_configs:
- routing_key: '<PAGERDUTY_KEY>'
description: '{{ .CommonAnnotations.summary }}'
details:
runbook: '{{ .CommonAnnotations.runbook_url }}'
- name: 'slack-warning'
slack_configs:
- api_url: '<SLACK_WEBHOOK>'
channel: '#alerts-warning'
title: '[{{ .Status | toUpper }}] {{ .CommonAnnotations.summary }}'
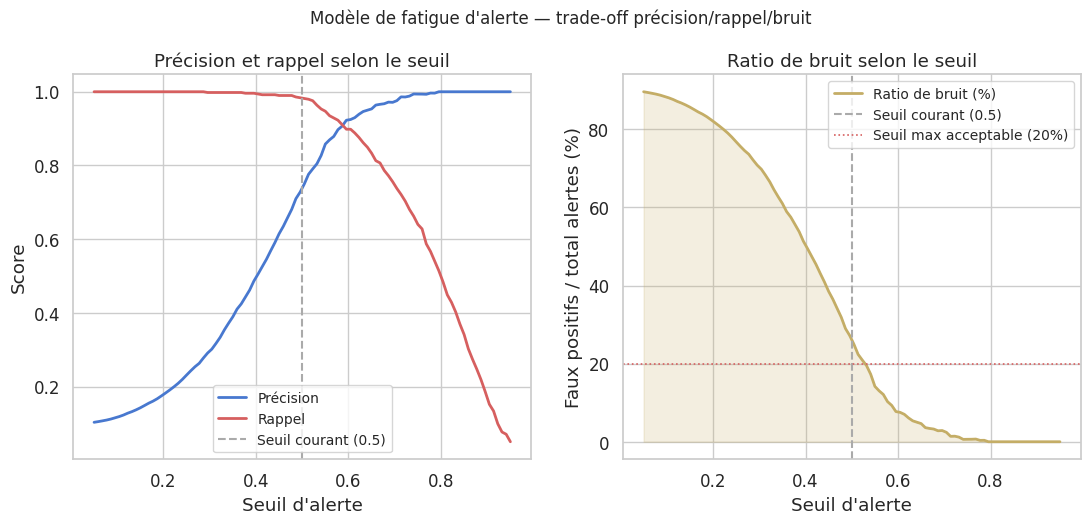
Fatigue d’alerte : diagnostic et remédiation#
La fatigue d’alerte survient quand le ratio signal/bruit devient trop faible : les ingénieurs commencent à ignorer les alertes, y compris les critiques.
Symptômes :
MTTA (Mean Time To Acknowledge) en hausse
Alertes acquittées sans action corrective
Rotation d’astreinte crainte plutôt qu’acceptée
Alertes dupliquées ou trop fréquentes pour un même événement
Causes principales :
Seuils trop bas (alerter sur la cause, pas le symptôme)
Absence de
for:(alerte sur un pic d’une seconde)Pas d’inhibitions pour les pannes transversales
Runbooks inexistants ou obsolètes
Remédiation :
Audit mensuel : classer chaque alerte par signal (action corrective effectuée) vs bruit (ignoré/silence)
Supprimer ou convertir en ticket toute alerte dont le taux d’action est < 20%
Implémenter le burn rate alerting pour remplacer les seuils fixes
Enrichir les runbooks avec des liens vers les dashboards
Runbooks : structure et automatisation#
Un runbook efficace suit une structure en trois parties :
Contexte : que mesure cette alerte ? Quel SLO est menacé ? Quel est l’impact utilisateur attendu ?
Diagnostic : liste ordonnée de vérifications à effectuer, avec les commandes exactes et les liens vers les dashboards. Chaque étape doit inclure l’interprétation des résultats.
Remédiation : actions correctives par scénario (rollback, redémarrage, basculement), avec les commandes exactes et les précautions.
L”automatisation partielle des runbooks (via des scripts ou des workflows PagerDuty) réduit le temps de résolution et les erreurs humaines sous stress. La partie diagnostic peut souvent être entièrement automatisée ; la remédiation nécessite souvent une validation humaine.
PagerDuty, OpsGenie et Grafana OnCall#
Les trois plateformes partagent les mêmes concepts fondamentaux :
Rotations d’astreinte (on-call schedules) : définissent qui est de garde à chaque moment. Les rotations peuvent être hebdomadaires, par couches (primary/secondary), ou par compétence.
Escalade : si le primary ne répond pas dans N minutes, l’alerte est transmise au secondary, puis au manager. L’escalade automatique est essentielle pour éviter les alertes silencieuses.
Runbook automation (PagerDuty) : des webhooks peuvent déclencher des scripts de diagnostic automatique, dont les résultats sont attachés à l’incident.
Grafana OnCall est l’alternative open-source, intégrée nativement à Grafana. Elle supporte les rotations, les escalades, et les intégrations avec Alertmanager, PagerDuty et Slack.
Post-mortem et boucle de rétroaction#
Chaque incident sévère doit produire un post-mortem blameless (sans recherche de coupable) dont la section alerting répond à :
L’alerte s’est-elle déclenchée assez tôt ?
L’alerte contenait-elle les informations nécessaires ?
Le runbook était-il à jour ?
Y a-t-il eu du bruit supplémentaire qui a ralenti le diagnostic ?
Les action items du post-mortem doivent inclure des améliorations concrètes de l’alerting : ajustement des seuils, enrichissement des annotations, création ou mise à jour du runbook. C’est la boucle de rétroaction qui fait converger le système d’alerting vers la qualité.
Visualisations#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch
import seaborn as sns
import numpy as np
import pandas as pd
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
Simulation du burn rate sur deux fenêtres#
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
# Simulation sur 48h avec un incident à t=24h
t_hours = np.linspace(0, 48, 2880) # point toutes les minutes
# Taux d'erreur de base : 0.05% (SLO 99.95%), avec incident à t=24-26h
error_rate = np.where(
(t_hours >= 24) & (t_hours <= 26),
np.random.uniform(0.08, 0.15, 2880), # incident : 8-15% d'erreurs
np.random.beta(0.3, 200, 2880) # nominal : ~0.15% d'erreurs
)
slo_error_budget = 0.0005 # SLO 99.95% → budget d'erreur = 0.05%
# Burn rate = taux d'erreur actuel / taux d'erreur nominal du budget
burn_rate_1h = np.convolve(error_rate, np.ones(60)/60, mode='same') / slo_error_budget
burn_rate_6h = np.convolve(error_rate, np.ones(360)/360, mode='same') / slo_error_budget
fig, axes = plt.subplots(2, 1, figsize=(13, 8), sharex=True)
# Taux d'erreur brut
axes[0].plot(t_hours, error_rate * 100, color="#4878CF", linewidth=0.8, alpha=0.7, label="Taux d'erreur (%)")
axes[0].axhline(y=slo_error_budget * 100, color="#D65F5F", linewidth=1.5,
linestyle="--", label=f"Budget SLO ({slo_error_budget*100}%)")
axes[0].axvspan(24, 26, color="#D65F5F", alpha=0.12, label="Incident")
axes[0].set_ylabel("Taux d'erreur (%)")
axes[0].set_title("Taux d'erreur brut et burn rate sur deux fenêtres")
axes[0].legend(fontsize=9)
axes[0].set_ylim(0, 0.2)
# Burn rates
axes[1].plot(t_hours, burn_rate_1h, color="#6ACC65", linewidth=1.2,
label="Burn rate fenêtre 1h", alpha=0.85)
axes[1].plot(t_hours, burn_rate_6h, color="#B47CC7", linewidth=1.8,
label="Burn rate fenêtre 6h", alpha=0.9)
axes[1].axhline(y=14.4, color="#6ACC65", linewidth=1.2, linestyle=":",
label="Seuil 1h (14.4×)")
axes[1].axhline(y=6.0, color="#B47CC7", linewidth=1.2, linestyle=":",
label="Seuil 6h (6×)")
axes[1].axhline(y=1.0, color="#aaaaaa", linewidth=1.0, linestyle="--",
label="Burn rate nominal (1×)")
axes[1].axvspan(24, 26, color="#D65F5F", alpha=0.12)
axes[1].set_xlabel("Temps (heures)")
axes[1].set_ylabel("Burn rate (×)")
axes[1].set_ylim(0, 60)
axes[1].legend(fontsize=9, loc="upper left")
plt.show()
Modèle de fatigue d’alerte : précision / rappel selon le seuil#
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(7)
n_events = 5000
# Génération de vrais incidents (10%) et de faux positifs (90%)
true_incident = np.random.binomial(1, 0.10, n_events).astype(bool)
signal_score = np.where(true_incident,
np.random.beta(7, 2, n_events), # incidents → score élevé
np.random.beta(2, 7, n_events)) # bruit → score faible
thresholds = np.linspace(0.05, 0.95, 100)
precision_list, recall_list, noise_ratio_list = [], [], []
for thr in thresholds:
predicted = signal_score >= thr
tp = (predicted & true_incident).sum()
fp = (predicted & ~true_incident).sum()
fn = (~predicted & true_incident).sum()
prec = tp / (tp + fp) if (tp + fp) > 0 else 1.0
rec = tp / (tp + fn) if (tp + fn) > 0 else 0.0
noise = fp / (fp + tp) if (fp + tp) > 0 else 0.0
precision_list.append(prec)
recall_list.append(rec)
noise_ratio_list.append(noise)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
axes[0].plot(thresholds, precision_list, color="#4878CF", linewidth=2, label="Précision")
axes[0].plot(thresholds, recall_list, color="#D65F5F", linewidth=2, label="Rappel")
axes[0].axvline(x=0.5, color="#aaaaaa", linewidth=1.5, linestyle="--",
label="Seuil courant (0.5)")
axes[0].set_xlabel("Seuil d'alerte")
axes[0].set_ylabel("Score")
axes[0].set_title("Précision et rappel selon le seuil")
axes[0].legend(fontsize=10)
axes[1].plot(thresholds, [n * 100 for n in noise_ratio_list],
color="#C4AD66", linewidth=2, label="Ratio de bruit (%)")
axes[1].fill_between(thresholds, [n * 100 for n in noise_ratio_list],
alpha=0.2, color="#C4AD66")
axes[1].axvline(x=0.5, color="#aaaaaa", linewidth=1.5, linestyle="--",
label="Seuil courant (0.5)")
axes[1].axhline(y=20, color="#D65F5F", linewidth=1.2, linestyle=":",
label="Seuil max acceptable (20%)")
axes[1].set_xlabel("Seuil d'alerte")
axes[1].set_ylabel("Faux positifs / total alertes (%)")
axes[1].set_title("Ratio de bruit selon le seuil")
axes[1].legend(fontsize=10)
fig.suptitle("Modèle de fatigue d'alerte — trade-off précision/rappel/bruit", fontsize=12, y=1.01)
plt.show()
Matrice urgence / impact pour le triage des alertes#
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Matrice 4×4 : urgence (axe x) vs impact (axe y)
# Valeurs = nombre d'alertes typiques dans chaque cellule
matrix = np.array([
[1, 2, 5, 12], # impact critique
[3, 6, 9, 4], # impact élevé
[8, 14, 6, 2], # impact moyen
[20, 10, 3, 1], # impact faible
])
urgence_labels = ["Faible\nurgence", "Urgence\nmoyenne", "Urgence\nélevée", "Immédiate"]
impact_labels = ["Impact\ncritique", "Impact\nélevé", "Impact\nmoyen", "Impact\nfaible"]
fig, ax = plt.subplots(figsize=(9, 7))
im = ax.imshow(matrix, cmap="YlOrRd", vmin=0, vmax=20, aspect="auto")
for i in range(4):
for j in range(4):
ax.text(j, i, str(matrix[i, j]), ha="center", va="center",
fontsize=14, fontweight="bold",
color="white" if matrix[i, j] > 12 else "#333333")
ax.set_xticks(range(4))
ax.set_yticks(range(4))
ax.set_xticklabels(urgence_labels, fontsize=10)
ax.set_yticklabels(impact_labels, fontsize=10)
ax.set_xlabel("Urgence", fontsize=11)
ax.set_ylabel("Impact métier", fontsize=11)
ax.set_title("Matrice urgence / impact — nombre d'alertes par quadrant\n"
"(rouge = alertes critiques à page, jaune = tickets)", fontsize=12)
# Annotations des quadrants
quad_labels = {
(0, 3): "PAGE\nimmédiat",
(0, 2): "Page\n(sévérité haute)",
(1, 3): "Page\n(sévérité haute)",
(3, 0): "Ticket",
(2, 0): "Ticket",
}
for (j, i), label in quad_labels.items():
pass # labels déjà portés par les valeurs numériques
cbar = plt.colorbar(im, ax=ax, fraction=0.035)
cbar.set_label("Nombre d'alertes", fontsize=10)
plt.show()
Résumé#
Une bonne alerte est actionnable, urgente de façon justifiée, riche en contexte et liée à un runbook — toute alerte qui ne satisfait pas ces critères doit être supprimée ou rétrogradée en ticket.
Alerter sur les symptômes (taux d’erreurs, latence) plutôt que sur les causes (CPU, mémoire) réduit les faux positifs et aligne l’alerting sur l’expérience utilisateur.
L’alerting basé sur le burn rate des SLO est supérieur aux seuils fixes : il détecte les incidents impactants tôt sans noyer les équipes lors de pics transitoires.
La stratégie à deux fenêtres (1h + 6h) combine réactivité et robustesse : la fenêtre courte détecte, la fenêtre longue confirme.
Alertmanager réduit le bruit via le grouping (agrégation), les inhibitions (suppression des alertes corrélées) et les silences (maintenance planifiée).
La fatigue d’alerte se mesure via le MTTA et le taux d’action corrective ; toute alerte avec moins de 20% d’action doit être revue.
Les runbooks en trois parties (contexte, diagnostic, remédiation) avec commandes exactes et liens vers les dashboards réduisent le temps de résolution et les erreurs sous stress.
PagerDuty, OpsGenie et Grafana OnCall partagent les mêmes concepts (rotations, escalades) ; Grafana OnCall est l’alternative open-source intégrée à l’écosystème Grafana.
Le post-mortem blameless doit inclure une section alerting systématique pour fermer la boucle de rétroaction et améliorer continuellement la qualité des alertes.
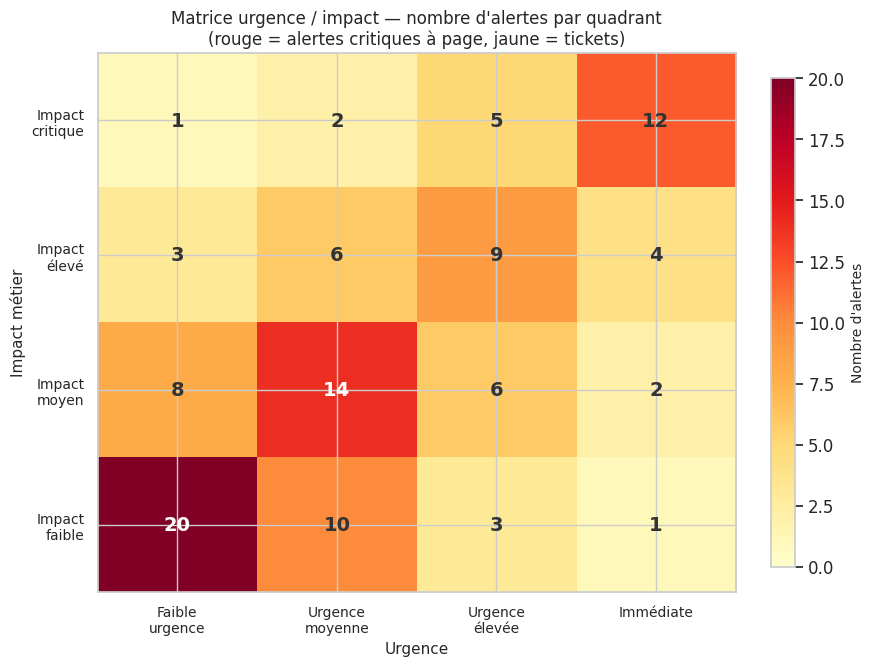
La matrice urgence/impact permet de catégoriser les alertes en trois niveaux d’action : page immédiat, page différé, et ticket — avec des seuils explicites et documentés.