23. Pipeline de production de bout en bout#
Ce chapitre est la synthèse du livre. Il assemble toutes les briques vues précédemment — intégration continue, sécurité, GitOps, canary deployment, observabilité, notifications — dans un pipeline cohérent et opérationnel. L’architecture cible est une application microservices avec un frontend React, un backend FastAPI, et une base de données PostgreSQL.
Architecture cible#
L’application est découpée en trois services :
frontend : application React servie par Nginx, image ~50 Mo
api : backend FastAPI avec authentification JWT, image ~120 Mo
worker : consommateur Celery pour les tâches asynchrones, image ~130 Mo
Les trois services partagent :
Une base PostgreSQL (StatefulSet ou RDS selon l’environnement)
Un broker Redis (StatefulSet ou ElastiCache)
Un service de tracing Jaeger (sidecar ou collector centralisé)
Trois environnements : dev (déploiement automatique à chaque merge), staging (approbation manuelle après les tests d’intégration), production (canary progressif avec SLO check).
Pipeline CI complet#
Étapes du pipeline CI#
Le pipeline CI s’exécute sur chaque pull request et sur chaque merge vers main.
# .github/workflows/ci.yml — Pipeline CI complet annoté
name: CI Pipeline
on:
push:
branches: [main, "release/**"]
pull_request:
branches: [main]
env:
REGISTRY: ghcr.io
IMAGE_NAME: ${{ github.repository }}
jobs:
# ─── Qualité du code ────────────────────────────────────────────────────────
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with: { python-version: "3.12" }
- run: pip install ruff mypy
- run: ruff check src/
- run: mypy src/ --ignore-missing-imports
# ─── Tests unitaires ────────────────────────────────────────────────────────
test-unit:
runs-on: ubuntu-latest
needs: lint
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with: { python-version: "3.12" }
- run: pip install -r requirements-dev.txt
- run: pytest tests/unit/ --cov=src --cov-report=xml -q
- uses: codecov/codecov-action@v4
with: { files: coverage.xml }
# ─── Tests d'intégration ────────────────────────────────────────────────────
test-integration:
runs-on: ubuntu-latest
needs: lint
services:
postgres:
image: postgres:16
env:
POSTGRES_PASSWORD: testpass
POSTGRES_DB: testdb
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
steps:
- uses: actions/checkout@v4
- run: pip install -r requirements-dev.txt
- run: pytest tests/integration/ -q
env:
DATABASE_URL: postgresql://postgres:testpass@localhost/testdb
# ─── SAST : analyse statique de sécurité ────────────────────────────────────
sast:
runs-on: ubuntu-latest
needs: lint
steps:
- uses: actions/checkout@v4
- uses: returntocorp/semgrep-action@v1
with:
config: >-
p/python
p/owasp-top-ten
p/secrets
# ─── Build et push de l'image ───────────────────────────────────────────────
build:
runs-on: ubuntu-latest
needs: [test-unit, test-integration, sast]
permissions:
contents: read
packages: write
id-token: write # Pour Cosign keyless
outputs:
image-digest: ${{ steps.build.outputs.digest }}
steps:
- uses: actions/checkout@v4
- uses: docker/setup-buildx-action@v3
- uses: docker/login-action@v3
with:
registry: ${{ env.REGISTRY }}
username: ${{ github.actor }}
password: ${{ secrets.GITHUB_TOKEN }}
- name: Build et push
id: build
uses: docker/build-push-action@v5
with:
context: .
push: ${{ github.ref == 'refs/heads/main' }}
tags: |
${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}:${{ github.sha }}
${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}:latest
cache-from: type=gha
cache-to: type=gha,mode=max
provenance: true
sbom: true # Génère le SBOM automatiquement
# ─── Scan de vulnérabilités ──────────────────────────────────────────────────
scan:
runs-on: ubuntu-latest
needs: build
steps:
- uses: aquasecurity/trivy-action@master
with:
image-ref: >-
${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}@${{ needs.build.outputs.image-digest }}
format: sarif
output: trivy.sarif
severity: CRITICAL,HIGH
exit-code: 1 # Échoue le pipeline si des CVE CRITICAL sont trouvées
- uses: github/codeql-action/upload-sarif@v3
with:
sarif_file: trivy.sarif
# ─── Signature Cosign ───────────────────────────────────────────────────────
sign:
runs-on: ubuntu-latest
needs: [build, scan]
permissions:
id-token: write
packages: write
steps:
- uses: sigstore/cosign-installer@v3
- name: Signer l'image avec Cosign keyless
run: |
cosign sign --yes \
${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}@${{ needs.build.outputs.image-digest }}
Pipeline CD complet#
Gestion des environnements#
# .github/workflows/cd.yml — Pipeline CD complet
name: CD Pipeline
on:
workflow_run:
workflows: ["CI Pipeline"]
types: [completed]
branches: [main]
jobs:
# ─── Déploiement dev : automatique ──────────────────────────────────────────
deploy-dev:
if: ${{ github.event.workflow_run.conclusion == 'success' }}
runs-on: ubuntu-latest
environment: dev
steps:
- uses: actions/checkout@v4
with:
repository: myorg/k8s-manifests
token: ${{ secrets.GIT_TOKEN }}
- name: Mettre à jour le tag d'image (dev)
run: |
cd apps/api/overlays/dev
kustomize edit set image \
api=${{ env.REGISTRY }}/${{ env.IMAGE_NAME }}:${{ github.sha }}
git config user.email "ci@myorg.com"
git config user.name "CI Bot"
git add .
git commit -m "chore(dev): update api image to ${{ github.sha }}"
git push
- name: Attendre la sync ArgoCD
run: |
argocd app wait api-dev \
--sync --health \
--timeout 300 \
--auth-token ${{ secrets.ARGOCD_TOKEN }} \
--server argocd.myorg.com
# ─── Déploiement staging : approbation manuelle ─────────────────────────────
deploy-staging:
needs: deploy-dev
runs-on: ubuntu-latest
environment:
name: staging
url: https://staging.myorg.com
steps:
- name: Mettre à jour le tag d'image (staging)
run: |
echo "Deploying ${{ github.sha }} to staging..."
- name: Tests de smoke staging
run: |
sleep 30
curl -f https://staging.myorg.com/health || exit 1
curl -f https://staging.myorg.com/api/v1/status || exit 1
# ─── Déploiement production : canary progressif ─────────────────────────────
deploy-production:
needs: deploy-staging
runs-on: ubuntu-latest
environment:
name: production
url: https://myorg.com
steps:
- name: Déploiement canary (10 %)
run: |
kubectl patch rollout api-rollout \
-n production \
--type merge \
-p '{"spec":{"steps":[{"setWeight":10}]}}'
- name: Vérification SLO (10 min)
run: |
python scripts/check_slo.py \
--error-rate-threshold 0.01 \
--p99-threshold 500 \
--duration 600
- name: Promotion complète
run: |
kubectl argo rollouts promote api-rollout -n production
# ─── Notifications Slack ────────────────────────────────────────────────────
notify:
needs: [deploy-production]
runs-on: ubuntu-latest
if: always()
steps:
- name: Notification Slack
uses: slackapi/slack-github-action@v1
with:
payload: |
{
"text": "Déploiement production : ${{ github.sha }} — ${{ needs.deploy-production.result }}",
"blocks": [{
"type": "section",
"text": {
"type": "mrkdwn",
"text": "*Statut :* ${{ needs.deploy-production.result }}\n*SHA :* `${{ github.sha }}`\n*Auteur :* ${{ github.actor }}"
}
}]
}
env:
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }}
Pipeline pour les librairies#
Les librairies (packages Python, npm) nécessitent un pipeline distinct axé sur le versioning sémantique et la publication.
# Pipeline librairie : semver automatique + publication PyPI
name: Release Library
on:
push:
branches: [main]
jobs:
release:
runs-on: ubuntu-latest
permissions:
contents: write
id-token: write
steps:
- uses: actions/checkout@v4
with: { fetch-depth: 0 }
# semantic-release analyse les commits conventionnels
# et détermine le prochain numéro de version
- uses: python-semantic-release/python-semantic-release@v9
id: release
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
# Publie sur PyPI uniquement si une nouvelle version a été créée
- name: Publier sur PyPI
if: steps.release.outputs.released == 'true'
uses: pypa/gh-action-pypi-publish@release/v1
Conventional commits et semantic-release#
semantic-release analyse l’historique des commits pour déterminer la prochaine version :
fix:→ patch (1.2.3 → 1.2.4)feat:→ minor (1.2.3 → 1.3.0)feat!:ouBREAKING CHANGE:→ major (1.2.3 → 2.0.0)chore:,docs:,style:→ pas de release
Le changelog est généré automatiquement depuis ces commits et inclus dans la GitHub Release.
Coût et dimensionnement#
Estimation pour une équipe de 10 développeurs#
Composant |
Spécification |
Coût mensuel estimé |
|---|---|---|
Runners CI (GitHub-hosted) |
3 000 min/mois |
~24 € |
Runners CI (self-hosted, 4 vCPU) |
2× EC2 t3.xlarge |
~130 € |
Registry OCI (GHCR) |
50 Go stockage |
~5 € |
Cluster Kubernetes (staging) |
3× t3.medium |
~90 € |
Cluster Kubernetes (prod) |
3× t3.large |
~180 € |
Observabilité (Grafana Cloud) |
50 Go logs, 10k métriques |
~45 € |
Total self-hosted runners |
~450 €/mois |
Optimisation des coûts CI
Les runners self-hosted sur des instances Spot EC2 ou Preemptible GCE réduisent le coût des runners de 60 à 70 %. Le cache Buildx (GitHub Actions Cache) réduit les temps de build de 40 à 60 % et donc la consommation de minutes CI.
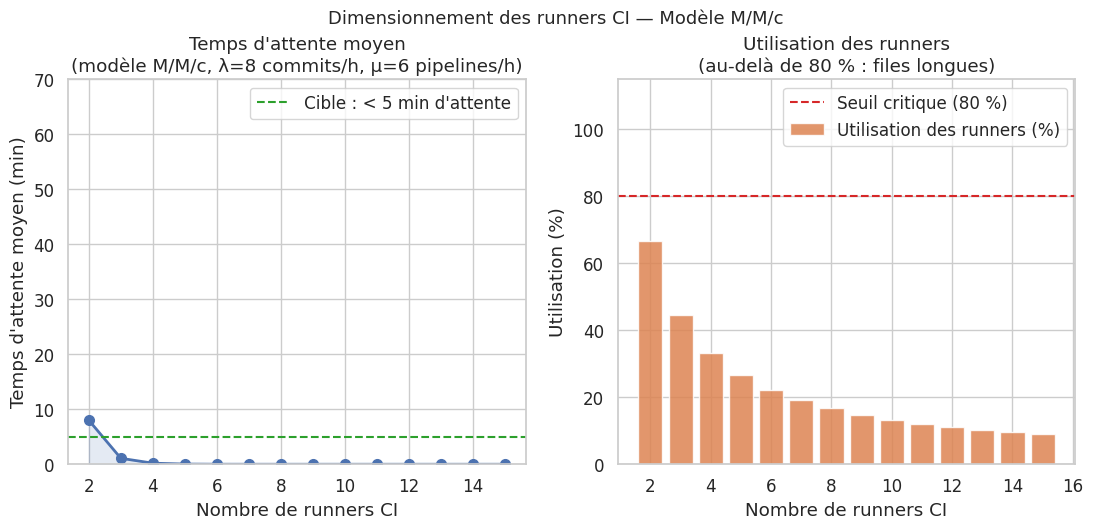
Théorie des files d’attente appliquée aux pipelines CI#
Un pipeline CI peut être modélisé comme une file d’attente M/M/c :
M (arrivées) : les commits suivent approximativement un processus de Poisson
M (service) : les durées de pipeline suivent une loi exponentielle
c : le nombre de runners en parallèle
La formule de Little donne le temps moyen en système : W = L / λ où L est le nombre moyen de pipelines en cours et λ le débit d’arrivée. Augmenter c (runners) réduit W selon une courbe hyperbolique : en dessous de 80 % d’utilisation, les temps d’attente restent faibles ; au-delà, ils explosent.
Visualisations#
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch
import networkx as nx
import seaborn as sns
import pandas as pd
from scipy.special import factorial
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Modèle M/M/c : temps d'attente en fonction du nombre de runners
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
def erlang_c(c, a):
"""Probabilité d'attente dans un système M/M/c (formule d'Erlang C)."""
r = a / c
if r >= 1.0:
return 1.0
sum_terms = sum((a**n) / factorial(n) for n in range(c))
last_term = (a**c) / (factorial(c) * (1 - r))
p0 = 1.0 / (sum_terms + last_term)
return (last_term * p0)
def wq_mmс(c, lam, mu):
"""Temps d'attente moyen en file M/M/c (en unités de 1/mu)."""
a = lam / mu
if a / c >= 1.0:
return float("inf")
ec = erlang_c(int(c), a)
return ec / (c * mu - lam) # en heures
# Paramètres : équipe de 10 développeurs
# 8 commits/heure, durée pipeline ~10 min → mu = 6 pipelines/heure/runner
lam = 8.0
mu = 6.0
runners = np.arange(2, 16)
temps_attente_min = []
utilisation_pct = []
for c in runners:
wq = wq_mmс(int(c), lam, mu)
temps_attente_min.append(min(wq * 60, 65))
utilisation_pct.append(min(lam / (int(c) * mu) * 100, 105))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(13, 5))
ax1.plot(runners, temps_attente_min, "o-", color="#4c72b0",
linewidth=2, markersize=7)
ax1.fill_between(runners, temps_attente_min, alpha=0.15, color="#4c72b0")
ax1.axhline(y=5, color="#2ca02c", linestyle="--",
linewidth=1.5, label="Cible : < 5 min d'attente")
ax1.set_xlabel("Nombre de runners CI")
ax1.set_ylabel("Temps d'attente moyen (min)")
ax1.set_title("Temps d'attente moyen\n(modèle M/M/c, λ=8 commits/h, μ=6 pipelines/h)")
ax1.legend()
ax1.set_ylim(0, 70)
ax2.bar(runners, utilisation_pct, color="#dd8452", alpha=0.85,
label="Utilisation des runners (%)")
ax2.axhline(y=80, color="#d62728", linestyle="--",
linewidth=1.5, label="Seuil critique (80 %)")
ax2.set_xlabel("Nombre de runners CI")
ax2.set_ylabel("Utilisation (%)")
ax2.set_title("Utilisation des runners\n(au-delà de 80 % : files longues)")
ax2.legend()
ax2.set_ylim(0, 115)
plt.suptitle("Dimensionnement des runners CI — Modèle M/M/c",
fontsize=13, y=1.02)
plt.show()
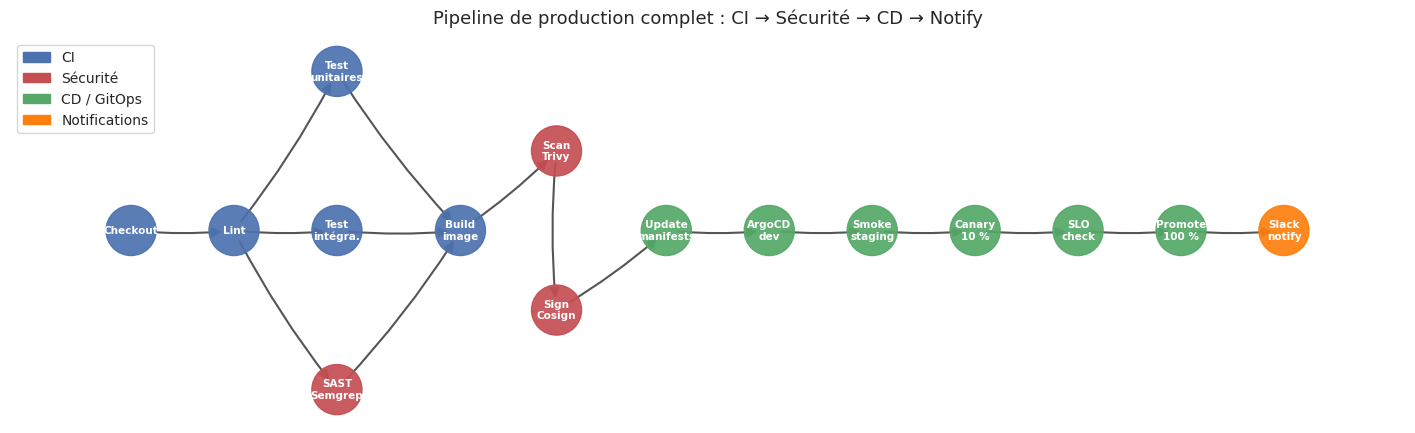
# DAG du pipeline complet : CI + Security + CD + Notify
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
G = nx.DiGraph()
noeuds = {
"Checkout": "ci",
"Lint": "ci",
"Test\nunitaires": "ci",
"Test\nintégra.": "ci",
"SAST\nSemgrep": "security",
"Build\nimage": "ci",
"Scan\nTrivy": "security",
"Sign\nCosign": "security",
"Update\nmanifests": "cd",
"ArgoCD\ndev": "cd",
"Smoke\nstaging": "cd",
"Canary\n10 %": "cd",
"SLO\ncheck": "cd",
"Promote\n100 %": "cd",
"Slack\nnotify": "notify",
}
for n in noeuds:
G.add_node(n, type=noeuds[n])
deps = [
("Checkout", "Lint"),
("Lint", "Test\nunitaires"),
("Lint", "Test\nintégra."),
("Lint", "SAST\nSemgrep"),
("Test\nunitaires", "Build\nimage"),
("Test\nintégra.", "Build\nimage"),
("SAST\nSemgrep", "Build\nimage"),
("Build\nimage", "Scan\nTrivy"),
("Scan\nTrivy", "Sign\nCosign"),
("Sign\nCosign", "Update\nmanifests"),
("Update\nmanifests", "ArgoCD\ndev"),
("ArgoCD\ndev", "Smoke\nstaging"),
("Smoke\nstaging", "Canary\n10 %"),
("Canary\n10 %", "SLO\ncheck"),
("SLO\ncheck", "Promote\n100 %"),
("Promote\n100 %", "Slack\nnotify"),
]
G.add_edges_from(deps)
pos = {
"Checkout": (0, 0),
"Lint": (1.5, 0),
"Test\nunitaires": (3, 1),
"Test\nintégra.": (3, 0),
"SAST\nSemgrep": (3, -1),
"Build\nimage": (4.8, 0),
"Scan\nTrivy": (6.2, 0.5),
"Sign\nCosign": (6.2, -0.5),
"Update\nmanifests": (7.8, 0),
"ArgoCD\ndev": (9.3, 0),
"Smoke\nstaging": (10.8, 0),
"Canary\n10 %": (12.3, 0),
"SLO\ncheck": (13.8, 0),
"Promote\n100 %": (15.3, 0),
"Slack\nnotify": (16.8, 0),
}
couleurs_types = {
"ci": "#4c72b0",
"security": "#c44e52",
"cd": "#55a868",
"notify": "#ff7f0e",
}
node_colors = [couleurs_types[G.nodes[n]["type"]] for n in G.nodes()]
fig, ax = plt.subplots(figsize=(18, 5))
ax.axis("off")
nx.draw_networkx_nodes(G, pos, node_color=node_colors, node_size=1300,
ax=ax, alpha=0.92)
nx.draw_networkx_labels(G, pos, font_size=7.5, font_color="white",
font_weight="bold", ax=ax)
nx.draw_networkx_edges(G, pos, ax=ax, arrows=True, arrowsize=14,
edge_color="#555555", width=1.5,
connectionstyle="arc3,rad=0.05")
legend_elements = [
mpatches.Patch(color="#4c72b0", label="CI"),
mpatches.Patch(color="#c44e52", label="Sécurité"),
mpatches.Patch(color="#55a868", label="CD / GitOps"),
mpatches.Patch(color="#ff7f0e", label="Notifications"),
]
ax.legend(handles=legend_elements, loc="upper left", fontsize=10)
ax.set_title("Pipeline de production complet : CI → Sécurité → CD → Notify",
fontsize=13, pad=10)
plt.show()
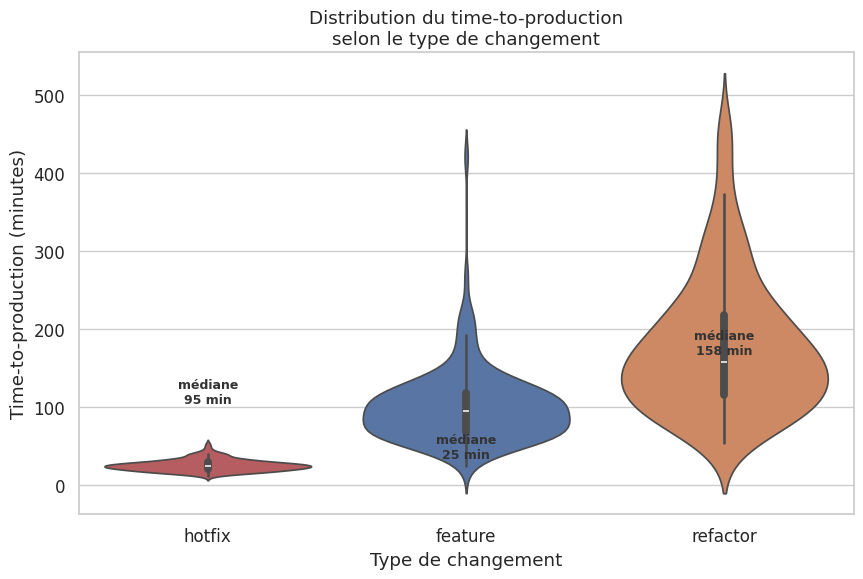
# Time-to-production selon le type de changement (violin plot)
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
n = 150
types_changement = {
"hotfix": np.random.lognormal(mean=np.log(25), sigma=0.3, size=n),
"feature": np.random.lognormal(mean=np.log(90), sigma=0.4, size=n),
"refactor": np.random.lognormal(mean=np.log(155), sigma=0.5, size=n),
}
donnees = []
for type_chg, durees in types_changement.items():
for d in durees:
donnees.append({"type": type_chg, "time_to_production_min": d})
df = pd.DataFrame(donnees)
fig, ax = plt.subplots(figsize=(10, 6))
sns.violinplot(
data=df,
x="type", y="time_to_production_min",
palette={"hotfix": "#c44e52", "feature": "#4c72b0", "refactor": "#dd8452"},
inner="box",
ax=ax
)
ax.set_xlabel("Type de changement")
ax.set_ylabel("Time-to-production (minutes)")
ax.set_title("Distribution du time-to-production\nselon le type de changement")
medians = df.groupby("type")["time_to_production_min"].median()
for i, (type_chg, med) in enumerate(medians.items()):
ax.text(i, med + 10, f"médiane\n{med:.0f} min",
ha="center", fontsize=9, color="#333333", fontweight="bold")
plt.show()
/tmp/ipykernel_10117/4022486463.py:23: FutureWarning:
Passing `palette` without assigning `hue` is deprecated and will be removed in v0.14.0. Assign the `x` variable to `hue` and set `legend=False` for the same effect.
sns.violinplot(
Résumé#
L’architecture microservices (frontend, API, worker) impose un pipeline CI par service mais une orchestration CD unifiée via GitOps pour garantir la cohérence des versions déployées simultanément.
Le pipeline CI suit un ordre non négociable : lint → tests → SAST → build → scan Trivy → sign Cosign ; les étapes de sécurité sont bloquantes et non-optionnelles en production.
La stratégie d’environnements (dev automatique, staging avec approbation, production en canary) équilibre vélocité et sécurité : les régressions sont détectées en staging avant d’atteindre l’intégralité des utilisateurs.
Le canary deployment avec SLO check est la protection finale avant la promotion complète ; un taux d’erreur ou une latence P99 dépassant les seuils déclenche un rollback automatique sans intervention humaine.
Les notifications Slack sur le job
notifyavecif: always()assurent la visibilité des succès et des échecs, y compris des rollbacks, sans configuration supplémentaire dans chaque pipeline.Le pipeline des librairies avec
semantic-releaseautomatise le versioning sémantique, le changelog et la publication sur PyPI ou npm à partir des conventional commits, sans décision humaine sur le numéro de version.Le modèle M/M/c démontre qu’en dessous de 80 % d’utilisation des runners, les temps d’attente restent faibles ; au-delà, ils croissent hyperboliquement — la capacité CI doit être dimensionnée avec une marge de sécurité.
Le cache Buildx est le levier d’optimisation le plus accessible pour réduire les temps de build de 40 à 60 % sans infrastructure supplémentaire ; il doit être activé dès le premier pipeline.
Le coût total d’un pipeline de production complet pour une équipe de 10 développeurs se situe entre 300 et 500 €/mois avec des runners self-hosted Spot, observabilité incluse.
La visualisation du pipeline comme DAG révèle le chemin critique (la séquence la plus longue sans parallélisation possible) et identifie les opportunités de réduction du lead time sans augmenter les ressources.