09 — Gestion des environnements#
La gestion rigoureuse des environnements est l’une des disciplines fondamentales du DevOps. Un pipeline qui déploie du code non testé en production, ou dont le staging ne ressemble pas à la prod, génère des incidents évitables et érode la confiance dans le système de déploiement. Ce chapitre couvre les patterns éprouvés pour maintenir des environnements cohérents, reproductibles et contrôlés.
Le modèle dev / staging / prod#
Rôles de chaque environnement#
Un projet mature distingue au minimum trois environnements avec des responsabilités clairement séparées :
Développement (dev) L’environnement de développement est personnel ou partagé par une équipe restreinte. Il tolère l’instabilité : bases de données éphémères, mocks de services externes, données synthétiques. L’objectif est la vélocité, pas la fiabilité.
Staging (pré-production) Le staging est le miroir de la production. Il doit recevoir les mêmes versions de services, la même topologie réseau, les mêmes volumes de données représentatifs (anonymisés). C’est ici que les tests d’intégration, de charge et de smoke tests s’exécutent avant toute promotion. Un staging non représentatif de la prod est plus dangereux qu’utile : il génère une fausse confiance.
Production (prod) L’environnement qui sert les utilisateurs réels. Toute modification doit être validée en staging. Le principe de moindre surprise s’applique : rien ne doit apparaître en prod sans avoir transité par le pipeline complet.
Parité staging / prod#
Les divergences entre staging et prod sont la source principale des « works on staging, breaks in prod ». Les causes communes :
Versions de services différentes (BDD, cache, broker de messages)
Ressources allouées non représentatives (staging sur 1 nœud, prod sur 10)
Données de test trop simplistes (pas de cas limites)
Variables d’environnement manquantes ou incorrectes
Certificats TLS autosignés en staging vs certificats valides en prod
La parité se maintient par l’Infrastructure as Code : si staging et prod sont décrites dans le même code Terraform/Helm avec des paramètres différents uniquement pour la taille et les secrets, la dérive structurelle est impossible.
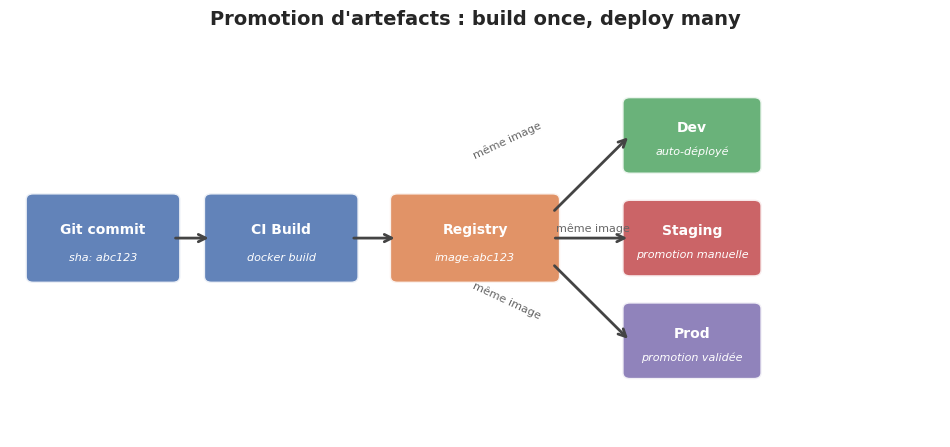
Promotion d’artefacts : « build once, deploy many »#
Le principe#
L’artefact (image Docker, bundle JAR, archive npm) doit être construit une seule fois et promu à travers les environnements. Reconstruire en staging puis en prod introduit un risque : deux builds du même commit peuvent produire des binaires légèrement différents si les dépendances transitives ont changé entre-temps.
Git commit SHA → build → image:sha256-abc123
│
push registry
│
┌──────────────┼──────────────┐
▼ ▼ ▼
dev staging prod
(same image) (same image) (same image)
L’image Docker taguée avec le SHA du commit est la source de vérité. Les tags latest ou main ne doivent jamais être utilisés en déploiement automatisé : ils masquent quelle version exacte tourne.
Registre et promotion#
# Workflow de promotion — GitHub Actions
on:
workflow_dispatch:
inputs:
image_tag:
description: "SHA de l'image à promouvoir"
required: true
target_env:
type: choice
options: [staging, prod]
jobs:
promote:
runs-on: ubuntu-latest
steps:
- name: Re-tag image pour l'environnement cible
run: |
docker pull ghcr.io/myorg/myapp:${{ inputs.image_tag }}
docker tag ghcr.io/myorg/myapp:${{ inputs.image_tag }} \
ghcr.io/myorg/myapp:${{ inputs.target_env }}-stable
docker push ghcr.io/myorg/myapp:${{ inputs.target_env }}-stable
Immuabilité des artefacts
Ne jamais modifier une image après sa construction. Si un correctif est nécessaire, créer un nouveau build avec un nouveau SHA. L’immuabilité garantit la traçabilité : on peut toujours savoir exactement ce qui tourne en prod.
Les 12 facteurs appliqués à la configuration#
L’application des 12 Factor App reste la référence pour les applications cloud-native. Les facteurs les plus pertinents pour la gestion d’environnements sont :
Facteur III — Configuration Toute configuration qui varie entre les environnements (URLs de bases de données, clés API, flags de fonctionnalités) doit provenir de variables d’environnement, jamais du code source. Cela inclut les modes debug, les timeouts, les seuils.
Facteur IV — Services externes (Backing services) Traiter les bases de données, queues, caches comme des ressources attachées via URL/credentials. Passer de MySQL local à RDS en production ne doit nécessiter qu’un changement de variable d’environnement.
Facteur X — Parité dev/prod Minimiser les écarts entre dev et prod : temps (déployer souvent), personnes (les devs déploient), outils (même stack).
ConfigMaps Kubernetes#
# configmap-prod.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: myapp-config
namespace: production
data:
DATABASE_POOL_SIZE: "20"
CACHE_TTL_SECONDS: "300"
LOG_LEVEL: "warn"
FEATURE_NEW_DASHBOARD: "false"
API_RATE_LIMIT: "1000"
---
# configmap-staging.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: myapp-config
namespace: staging
data:
DATABASE_POOL_SIZE: "5"
CACHE_TTL_SECONDS: "60"
LOG_LEVEL: "debug"
FEATURE_NEW_DASHBOARD: "true"
API_RATE_LIMIT: "100"
Secrets et SOPS#
Les secrets ne doivent jamais apparaître en clair dans Git. SOPS (Secrets OPerationS) chiffre les valeurs sensibles tout en laissant le fichier versionnable :
# Chiffrer avec une clé Age ou KMS
sops --encrypt --age age1abc123... secrets.yaml > secrets.enc.yaml
# Déchiffrer dans le pipeline CI
sops --decrypt secrets.enc.yaml | kubectl apply -f -
Helm values par environnement#
# values-prod.yaml
replicaCount: 3
image:
repository: ghcr.io/myorg/myapp
tag: "sha256-abc123" # épinglé, jamais "latest"
pullPolicy: IfNotPresent
resources:
requests:
cpu: "500m"
memory: "512Mi"
limits:
cpu: "2000m"
memory: "2Gi"
autoscaling:
enabled: true
minReplicas: 3
maxReplicas: 20
ingress:
enabled: true
host: api.myapp.fr
tls: true
config:
logLevel: warn
dbPoolSize: 20
postgresql:
enabled: false # RDS externe en prod
externalHost: prod-db.rds.amazonaws.com
Feature flags#
Définition et cas d’usage#
Un feature flag (ou feature toggle) est un mécanisme qui permet d’activer ou désactiver une fonctionnalité sans déployer de nouveau code. Les cas d’usage principaux :
Déploiement progressif : activer pour 5% des utilisateurs, observer, étendre
Trunk-based development : fusionner du code incomplet caché derrière un flag
Tests A/B : exposer deux variantes à des segments d’utilisateurs
Kill switch : désactiver d’urgence une fonctionnalité défaillante sans rollback
Canary de fonctionnalité : activer uniquement pour les utilisateurs internes d’abord
Implémentation Python pédagogique#
import hashlib
import random
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class FeatureFlag:
"""
Feature flag avec rollout progressif basé sur le hash de l'identifiant utilisateur.
Garantit la cohérence : le même utilisateur voit toujours le même résultat.
"""
name: str
enabled: bool = False
rollout_percentage: float = 0.0 # 0.0 → 100.0
allowed_user_ids: list = field(default_factory=list) # liste blanche explicite
environment_overrides: dict = field(default_factory=dict)
def is_active(self, user_id: str, environment: str = "prod") -> bool:
"""Détermine si le flag est actif pour un utilisateur donné."""
# Override par environnement (ex: toujours actif en staging)
if environment in self.environment_overrides:
return self.environment_overrides[environment]
if not self.enabled:
return False
# Liste blanche explicite
if user_id in self.allowed_user_ids:
return True
# Rollout déterministe basé sur le hash
if self.rollout_percentage >= 100.0:
return True
if self.rollout_percentage <= 0.0:
return False
# Hachage stable : même user_id → même bucket → même résultat
bucket = int(hashlib.md5(f"{self.name}:{user_id}".encode()).hexdigest(), 16) % 100
return bucket < self.rollout_percentage
# --- Registre de flags ---
class FeatureFlagRegistry:
def __init__(self):
self._flags: dict[str, FeatureFlag] = {}
def register(self, flag: FeatureFlag):
self._flags[flag.name] = flag
def is_active(self, flag_name: str, user_id: str, environment: str = "prod") -> bool:
flag = self._flags.get(flag_name)
if flag is None:
return False # flag inconnu = désactivé par défaut
return flag.is_active(user_id, environment)
# Démonstration
registry = FeatureFlagRegistry()
registry.register(FeatureFlag(
name="new_dashboard",
enabled=True,
rollout_percentage=20.0,
environment_overrides={"staging": True, "dev": True}
))
registry.register(FeatureFlag(
name="ai_recommendations",
enabled=True,
rollout_percentage=5.0,
allowed_user_ids=["user_beta_001", "user_beta_002"]
))
# Simuler 1000 utilisateurs
users = [f"user_{i:04d}" for i in range(1000)]
for flag_name in ["new_dashboard", "ai_recommendations"]:
active_count = sum(
1 for u in users if registry.is_active(flag_name, u, "prod")
)
print(f"[{flag_name}] actif pour {active_count}/1000 utilisateurs en prod "
f"({active_count/10:.1f}%)")
# Vérification cohérence : même user → même résultat
u = "user_0042"
results = [registry.is_active("new_dashboard", u, "prod") for _ in range(5)]
print(f"\nCohérence pour {u} : {results} (doit être constant)")
[new_dashboard] actif pour 194/1000 utilisateurs en prod (19.4%)
[ai_recommendations] actif pour 51/1000 utilisateurs en prod (5.1%)
Cohérence pour user_0042 : [False, False, False, False, False] (doit être constant)
LaunchDarkly et Unleash
Pour les projets d’envergure, des plateformes comme LaunchDarkly ou Unleash (open-source) offrent une interface graphique, des règles de ciblage avancées, des audits et des intégrations avec les outils de monitoring. L’implémentation maison suffit pour débuter, mais devient rapidement un fardeau de maintenance au-delà d’une vingtaine de flags.
Épinglage de version#
Pourquoi épingler ?#
La reproductibilité est le fondement de la fiabilité. Un déploiement doit produire exactement le même résultat aujourd’hui et dans six mois. Cela impose d’épingler :
Images Docker :
image: nginx:1.25.3et nonnginx:latestDépendances Python :
requirements.txtavec versions exactes (pip freeze), oupyproject.tomlavec contraintes +uv.lockCharts Helm :
version: 1.4.2dansChart.yamlet danshelmfile.yamlModules Terraform :
source = "hashicorp/kubernetes" version = "~> 2.25"Actions GitHub :
uses: actions/checkout@v4.1.1(et non@v4)
SHA plutôt que tag pour les actions critiques
Un tag Git peut être réécrit. Pour les workflows CI/CD critiques, épingler sur le SHA du commit :
uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683
Cela immunise contre les attaques de supply chain sur les dépendances GitHub Actions.
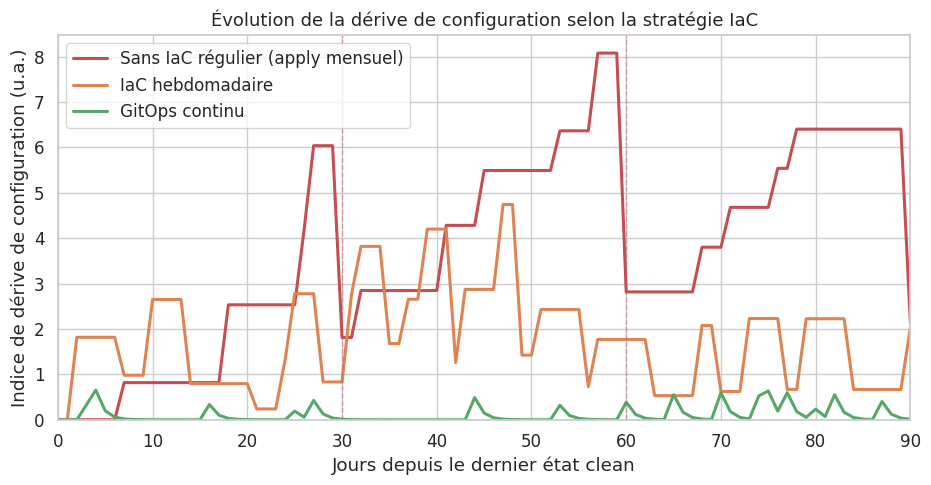
Dérive de configuration (configuration drift)#
Causes et risques#
La dérive (drift) se produit quand l’état réel d’un environnement diverge de l’état décrit dans le code. Causes fréquentes :
Modifications manuelles « d’urgence » en production sans mise à jour du code IaC
Mises à jour automatiques de packages OS non maîtrisées
Opérateurs humains qui ajustent des paramètres directement via kubectl/console AWS
Exécution partielle d’un playbook Ansible interrompue
La dérive est insidieuse : les environnements fonctionnent, mais la prochaine application du code IaC peut tout casser.
Détection#
terraform plan: signale toute différence entre l’état souhaité et l’état réelkubectl diff -f manifests/: diff des manifestes K8s vs clusteransible --check: dry-run qui liste les changements qui seraient appliquésOutils spécialisés : Driftctl (cloud resources vs Terraform), Config Connector (GCP)
Prévention#
La stratégie la plus efficace est d’interdire les modifications manuelles :
Droits IAM en lecture seule sur la prod pour tous sauf le pipeline CI/CD
Alertes sur toute modification hors pipeline (CloudTrail, audit logs K8s)
GitOps (voir chapitre 22) : l’état du cluster est en permanence réconcilié avec Git
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Modèle probabiliste de divergence de configuration dans le temps
# Hypothèse : chaque modification manuelle augmente la dérive
# Les runs IaC (terraform apply) la réduisent (réconciliation)
np.random.seed(42)
days = np.arange(0, 91) # 3 mois
def simulate_drift(iac_apply_days, manual_change_rate=0.15, drift_reduction=0.7):
"""
Simule la dérive de configuration sur 90 jours.
- iac_apply_days : jours où un `terraform apply` est exécuté (reset partiel)
- manual_change_rate : probabilité journalière de modification manuelle
"""
drift = np.zeros(len(days))
for i in range(1, len(days)):
# Accumulation de dérive par modifications manuelles
manual = np.random.binomial(1, manual_change_rate) * np.random.uniform(0.5, 2.0)
drift[i] = drift[i-1] + manual
# Réconciliation par IaC
if i in iac_apply_days:
drift[i] *= (1 - drift_reduction)
drift[i] = max(0, drift[i])
return drift
# Scénario 1 : Sans discipline IaC (apply rare)
drift_no_iac = simulate_drift(iac_apply_days=[30, 60, 90], manual_change_rate=0.18)
# Scénario 2 : IaC hebdomadaire
drift_weekly = simulate_drift(
iac_apply_days=list(range(7, 91, 7)), manual_change_rate=0.18
)
# Scénario 3 : GitOps continu (réconciliation quasi-quotidienne)
drift_gitops = simulate_drift(
iac_apply_days=list(range(1, 91)), manual_change_rate=0.10
)
fig, ax = plt.subplots(figsize=(11, 5))
ax.plot(days, drift_no_iac, label="Sans IaC régulier (apply mensuel)", color="#C44E52", lw=2.2)
ax.plot(days, drift_weekly, label="IaC hebdomadaire", color="#DD8452", lw=2.2)
ax.plot(days, drift_gitops, label="GitOps continu", color="#55A868", lw=2.2)
# Marquer les apply manuels (scénario 1)
for d in [30, 60, 90]:
ax.axvline(x=d, color="#C44E52", linestyle="--", alpha=0.4, lw=1)
ax.set_xlabel("Jours depuis le dernier état clean")
ax.set_ylabel("Indice de dérive de configuration (u.a.)")
ax.set_title("Évolution de la dérive de configuration selon la stratégie IaC", fontsize=13)
ax.legend(loc="upper left")
ax.set_xlim(0, 90)
ax.set_ylim(bottom=0)
plt.savefig("_static/09_drift_configuration.png", dpi=120, bbox_inches="tight")
plt.show()
Stratégie de branches et d’environnements#
Le mapping branche ↔ environnement automatise la promotion et réduit les ambiguïtés :
Branche |
Environnement |
Déclencheur de déploiement |
|---|---|---|
|
Éphémère (preview env) |
Push → déploiement auto |
|
Dev |
Merge → déploiement auto |
|
Staging |
Création de tag RC → déploiement auto |
|
Prod |
Tag annoté → déploiement après approbation |
Environnements éphémères (Preview environments)#
Les environnements éphémères (preview apps chez Heroku/Render, Review Apps chez GitLab) créent un environnement complet pour chaque pull request. Avantages :
Tests d’intégration isolés par feature
Validation UX sur URL partageable avant merge
Destruction automatique à la fermeture de la PR (économies cloud)
Coût des environnements éphémères
Sur un projet avec 20 développeurs actifs, les preview environments peuvent multiplier les coûts cloud par 3 à 5. Il faut implémenter des mécanismes de mise en veille automatique (scale to zero avec Knative ou Karpenter) et des TTL stricts.
Résumé#
Les trois environnements (dev, staging, prod) ont des rôles distincts ; la parité staging/prod est non négociable et s’obtient par l’IaC.
Le principe « build once, deploy many » garantit que l’artefact promu en prod est identique à celui testé en staging — les images Docker sont taguées avec le SHA du commit.
Les 12 facteurs, en particulier le facteur III (config via variables d’environnement) et le facteur X (parité dev/prod), structurent la gestion de configuration.
Les ConfigMaps Kubernetes externalisent la configuration non sensible ; SOPS chiffre les secrets tout en les versionnant dans Git.
Les feature flags permettent de séparer le déploiement de l’activation : trunk-based development, rollout progressif, kill switch d’urgence.
L’implémentation d’un feature flag déterministe (hash de l’identifiant) garantit la cohérence de l’expérience utilisateur pendant le rollout.
L’épinglage de version (images, dépendances, modules IaC, actions CI) est le fondement de la reproductibilité des builds et déploiements.
La dérive de configuration est inévitable sans discipline :
terraform plan,kubectl diffet le GitOps permettent de la détecter et de la prévenir.Le mapping branche ↔ environnement automatise la promotion et clarifie le flux de livraison ; les environnements éphémères par PR amplifient l’isolation des tests.
La convergence vers le GitOps (chapitre 22) est la conclusion naturelle de la gestion d’environnements : l’état souhaité est dans Git, la réconciliation est continue et automatique.