02 — Intégration continue — principes et patterns#
L’intégration continue (CI) est la pratique qui consiste à intégrer fréquemment le travail de chaque développeur dans un tronc commun, et à valider automatiquement cette intégration via un pipeline d’automatisation. Ce chapitre détaille les principes fondamentaux, les patterns éprouvés, et les pièges à éviter.
Le contrat CI#
La règle fondamentale de l’intégration continue peut s’énoncer ainsi :
Un build vert signifie que le code est déployable en production à tout moment.
Ce contrat implique plusieurs obligations :
Le pipeline doit être rapide — idéalement sous 10 minutes pour la boucle de feedback initiale.
Le pipeline doit être fiable — pas de tests flaky, pas de faux positifs.
Tout commit qui casse le build est la priorité absolue de l’équipe — avant toute nouvelle feature.
Les branches qui ne passent pas le pipeline ne sont pas mergées.
Ce contrat n’a de valeur que s’il est respecté avec rigueur. Un pipeline ignoré ou systématiquement « skipé » n’apporte aucune valeur et donne une fausse impression de sécurité.
La règle des dix minutes
Kent Beck, créateur de l’Extreme Programming, recommande que le feedback du pipeline de CI arrive en moins de dix minutes. Au-delà, les développeurs arrêtent d’attendre le résultat et reprennent d’autres tâches, brisant la boucle de feedback rapide qui est au cœur de la CI.
La pyramide des tests#
La pyramide des tests, conceptualisée par Mike Cohn, structure les différents niveaux de tests selon leur coût, leur vitesse d’exécution et leur périmètre de couverture.
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(10, 7))
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
ax.axis('off')
# Trapèzes pour chaque niveau (xl_bas, xl_haut, y_bas, y_haut, couleur, label, sous-label)
levels = [
(0.5, 9.5, 0.3, 2.5, '#81C784', 'Tests Unitaires', '~70% du total · ms · coût faible'),
(1.5, 8.5, 2.7, 4.9, '#FFB74D', 'Tests d\'intégration', '~20% du total · secondes · coût moyen'),
(2.8, 7.2, 5.1, 7.0, '#EF9A9A', 'Tests E2E', '~8% du total · minutes · coût élevé'),
(3.9, 6.1, 7.2, 8.8, '#CE93D8', 'Tests de contrat', '~2% du total · secondes · CDC'),
]
for (xl_b, xr_b, y_b, y_h, color, label, sublabel) in levels:
# Trapèze
xs = [xl_b, xr_b, xr_b - 0.6, xl_b + 0.6, xl_b]
ys = [y_b, y_b, y_h, y_h, y_b]
ax.fill(xs, ys, color=color, alpha=0.85, zorder=2)
ax.plot(xs, ys, color='white', linewidth=1.5, zorder=3)
# Label principal
mid_y = (y_b + y_h) / 2
ax.text(5, mid_y + 0.2, label, ha='center', va='center', fontsize=12,
fontweight='bold', color='#212121', zorder=4)
ax.text(5, mid_y - 0.4, sublabel, ha='center', va='center', fontsize=9,
color='#424242', zorder=4, style='italic')
# Flèches de contexte
ax.annotate('', xy=(0.1, 8.8), xytext=(0.1, 0.5),
arrowprops=dict(arrowstyle='->', color='#37474F', lw=2))
ax.text(0.0, 4.5, 'Vitesse\nd\'exécution', ha='center', va='center', rotation=90,
fontsize=10, color='#37474F')
ax.annotate('', xy=(9.9, 0.5), xytext=(9.9, 8.8),
arrowprops=dict(arrowstyle='->', color='#B71C1C', lw=2))
ax.text(10.0, 4.5, 'Coût &\nfragilité', ha='center', va='center', rotation=270,
fontsize=10, color='#B71C1C')
ax.set_title('Pyramide des tests — coût, vitesse et couverture', fontsize=14,
fontweight='bold', pad=15)
plt.show()

Tests unitaires#
Les tests unitaires vérifient une unité de code isolée (fonction, méthode, classe) sans dépendances externes réelles. Ils doivent être :
Rapides : exécutables en millisecondes.
Déterministes : même résultat à chaque exécution.
Indépendants : pas d’ordre d’exécution imposé.
Focalisés : un seul comportement par test.
Tests d’intégration#
Les tests d’intégration vérifient l’interaction entre plusieurs composants. Ils peuvent nécessiter une base de données, un cache, un broker de messages — généralement provisionnés via des conteneurs éphémères (Testcontainers, Docker Compose dans le pipeline).
Tests End-to-End (E2E)#
Les tests E2E simulent un utilisateur réel interagissant avec le système complet. Ils sont lents, coûteux à maintenir, et sujets aux faux positifs (tests flaky). Leur nombre doit être minimisé ; ils couvrent uniquement les parcours critiques.
Tests de contrat (Consumer-Driven Contract)#
Dans une architecture microservices, les tests de contrat (Pact, Spring Cloud Contract) vérifient que les interfaces entre services respectent un contrat formalisé. Ils permettent de tester les interactions sans déployer tous les services.
L’antipattern de la pyramide inversée
Une suite de tests composée principalement de tests E2E (le « cône de glace ») est un signal d’alarme. Les tests E2E sont lents, instables et coûteux à déboguer. Investir dans les tests unitaires et d’intégration est systématiquement plus rentable.
Gestion des dépendances de test#
Isoler le code testé de ses dépendances est fondamental pour obtenir des tests rapides et fiables. Le vocabulaire des test doubles est souvent mal maîtrisé.
Dummy : objet passé en paramètre mais jamais utilisé (satisfaire une signature).
Stub : objet qui retourne des valeurs prédéfinies sans logique propre.
Fake : implémentation simplifiée mais fonctionnelle (base de données en mémoire, serveur HTTP local).
Spy : stub qui enregistre les appels reçus pour vérification a posteriori.
Mock : objet préconfigure les attentes sur les appels et vérifie qu’elles sont bien satisfaites lors de l’assertion.
Mocks vs Fakes — le débat
Martin Fowler distingue les « mockistes » (tester les interactions, usage intensif de mocks) des « classicistes » (tester les comportements, préférence pour les fakes et les objets réels). En pratique, les fakes (base SQLite en mémoire, serveur HTTP de test) produisent des tests plus robustes aux refactorings que les mocks stricts.
Fail Fast — ordonner les étapes#
Le principe Fail Fast consiste à placer en début de pipeline les étapes les plus rapides et les plus susceptibles d’échouer. Cela minimise le temps perdu par les développeurs et la consommation de ressources CI.
Ordre recommandé :
Lint / format — quelques secondes, détecte 80% des erreurs triviales.
Tests unitaires — dizaines de secondes, feedback immédiat sur la logique.
Build / compilation — valide la cohérence du projet.
Tests d’intégration — minutes, nécessitent des services externes.
Analyse statique de sécurité (SAST) — minutes.
Tests E2E — dizaines de minutes, réservés aux branches principales.
Scan de vulnérabilités — analyse des dépendances, images Docker.
Parallélisation et matrice de tests#
La parallélisation est le levier principal pour réduire la durée du pipeline sans sacrifier la couverture.
Parallélisation horizontale#
Exécuter plusieurs jobs simultanément : tests unitaires en parallèle des lints, tests d’intégration en parallèle du build de l’image Docker.
Matrice de tests#
La matrice permet de tester plusieurs configurations en parallèle : plusieurs versions du runtime (Python 3.10, 3.11, 3.12), plusieurs OS (Ubuntu, Windows, macOS), plusieurs versions de la base de données.
# Exemple de matrice de tests (générique, non exécutable)
strategy:
matrix:
python-version: ["3.10", "3.11", "3.12"]
os: [ubuntu-latest, windows-latest]
fail-fast: false # continuer malgré les échecs partiels
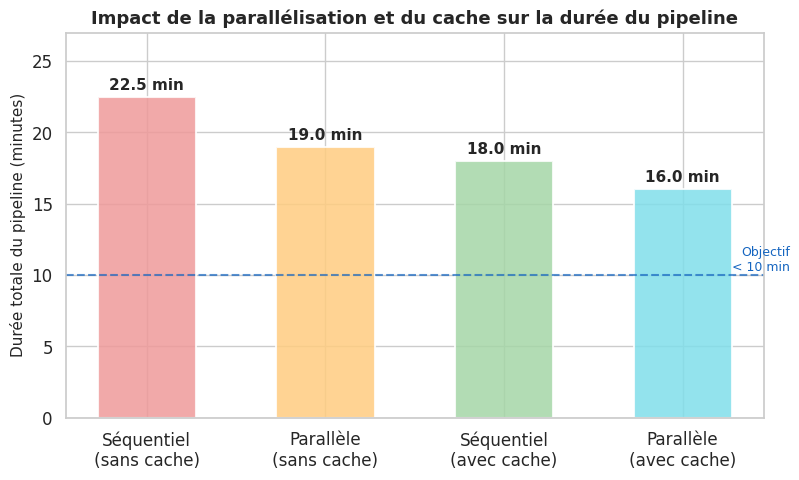
Cache des dépendances#
Le cache des dépendances (node_modules, pip packages, Maven local repo) réduit drastiquement la durée des pipelines. La clé de cache doit être basée sur un fichier de lock (requirements.txt, package-lock.json, pom.xml) pour garantir la cohérence.
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
strategies = ['Séquentiel\n(sans cache)', 'Parallèle\n(sans cache)', 'Séquentiel\n(avec cache)', 'Parallèle\n(avec cache)']
# Durées en minutes pour chaque étape
etapes = ['Lint/Format', 'Tests unitaires', 'Build', 'Tests intégration', 'SAST', 'E2E']
durees_seq = [0.5, 2.0, 3.0, 5.0, 4.0, 8.0]
durees_par = [0.5, 2.0, 3.0, 5.0, 4.0, 8.0] # parallèle = max des branches
durees_seq_cache = [0.5, 1.5, 1.5, 4.0, 3.5, 7.0]
durees_par_cache = [0.5, 1.5, 1.5, 4.0, 3.5, 7.0]
# Durée totale simulée
totals = {
'Séquentiel\n(sans cache)': sum(durees_seq), # 22.5 min
'Parallèle\n(sans cache)': max(0.5, 2.0) + max(3.0, 4.0) + max(5.0, 4.0) + 8.0, # ~19 min
'Séquentiel\n(avec cache)': sum(durees_seq_cache), # 18 min
'Parallèle\n(avec cache)': max(0.5, 1.5) + max(1.5, 3.5) + max(4.0, 3.5) + 7.0, # ~13 min
}
strats = list(totals.keys())
vals = list(totals.values())
colors = ['#EF9A9A', '#FFCC80', '#A5D6A7', '#80DEEA']
fig, ax = plt.subplots(figsize=(9, 5))
bars = ax.bar(strats, vals, color=colors, alpha=0.85, width=0.55, edgecolor='white', linewidth=1.5)
for bar, val in zip(bars, vals):
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.3,
f'{val:.1f} min', ha='center', va='bottom', fontsize=11, fontweight='bold')
ax.set_ylabel('Durée totale du pipeline (minutes)', fontsize=11)
ax.set_title('Impact de la parallélisation et du cache sur la durée du pipeline', fontsize=13, fontweight='bold')
ax.set_ylim(0, 27)
ax.axhline(y=10, color='#1565C0', linestyle='--', linewidth=1.5, alpha=0.7)
ax.text(3.6, 10.3, 'Objectif\n< 10 min', color='#1565C0', fontsize=9, ha='right')
plt.show()
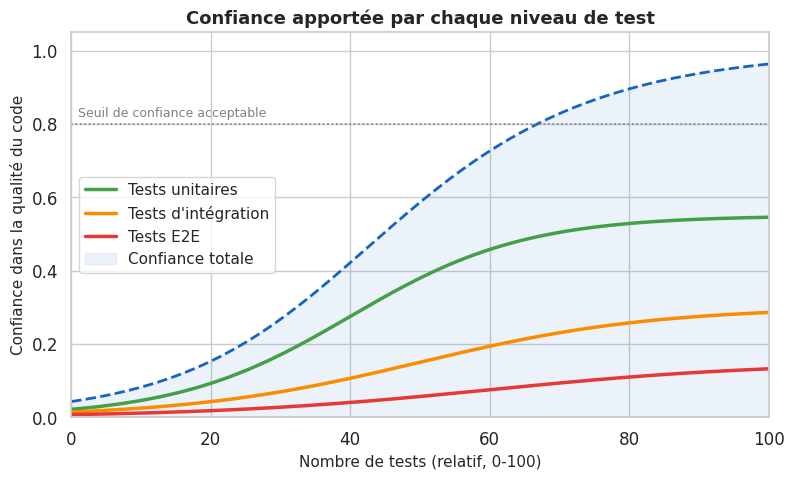
Couverture de code — indicateur, pas objectif#
La couverture de code mesure le pourcentage de lignes (ou branches) exécutées lors des tests. C’est un indicateur utile pour détecter des zones non testées, mais ce n’est pas un objectif en soi.
Pièges courants :
Viser 100% de couverture incite à écrire des tests sans assertions (tests creux).
La couverture ne dit rien sur la qualité des tests ni sur leur capacité à détecter des régressions.
Une couverture de 80% avec des tests bien conçus vaut mieux que 100% avec des tests superficiels.
Utilisation saine :
Utiliser la couverture comme détecteur de zones critiques non testées.
Fixer un seuil minimal raisonnable (70-80%) et ne pas bloquer le pipeline pour quelques points de plus.
Analyser les branches non couvertes plutôt que les lignes — l’analyse de branches est plus révélatrice.
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
x = np.linspace(0, 100, 300)
# Confiance apportée par les tests à chaque niveau (courbes sigmoïdes)
def confiance(x, midpoint, steepness, max_conf):
return max_conf / (1 + np.exp(-steepness * (x - midpoint)))
conf_unit = confiance(x, 40, 0.08, 0.55)
conf_integ = confiance(x, 50, 0.06, 0.30)
conf_e2e = confiance(x, 60, 0.05, 0.15)
fig, ax = plt.subplots(figsize=(9, 5))
ax.plot(x, conf_unit, label='Tests unitaires', color='#43A047', linewidth=2.5)
ax.plot(x, conf_integ, label="Tests d'intégration", color='#FB8C00', linewidth=2.5)
ax.plot(x, conf_e2e, label='Tests E2E', color='#E53935', linewidth=2.5)
ax.fill_between(x, conf_unit + conf_integ + conf_e2e, alpha=0.08, color='#1565C0', label='Confiance totale')
# Somme
total = conf_unit + conf_integ + conf_e2e
ax.plot(x, total, color='#1565C0', linewidth=2, linestyle='--')
ax.set_xlabel('Nombre de tests (relatif, 0-100)', fontsize=11)
ax.set_ylabel('Confiance dans la qualité du code', fontsize=11)
ax.set_title('Confiance apportée par chaque niveau de test', fontsize=13, fontweight='bold')
ax.legend(fontsize=11)
ax.set_ylim(0, 1.05)
ax.set_xlim(0, 100)
ax.axhline(y=0.8, color='grey', linestyle=':', linewidth=1.2)
ax.text(1, 0.82, 'Seuil de confiance acceptable', fontsize=9, color='grey')
plt.show()
Artifacts et cache dans les pipelines#
Artifacts#
Un artifact est un fichier ou un ensemble de fichiers produit par une étape du pipeline et consommé par une étape ultérieure ou conservé pour audit.
Types courants :
Binaires compilés, archives JAR/WAR, wheels Python.
Rapports de tests (JUnit XML, couverture HTML).
Images Docker taguées et poussées vers un registry.
Rapports de sécurité (SARIF, HTML).
Les artifacts ont une durée de vie configurable (1 jour pour les builds de feature branches, 90 jours pour les releases).
Cache#
Le cache stocke des données coûteuses à recréer entre les runs : dépendances installées, couches Docker intermédiaires, résultats de compilation incrémentale.
# Pattern de cache générique (non exécutable)
- name: Cache des dépendances Python
uses: actions/cache@v4
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-${{ hashFiles('requirements.txt') }}
restore-keys: |
${{ runner.os }}-pip-
La clé de cache doit être suffisamment spécifique pour éviter les faux hits (utiliser le hash du fichier de lock) et suffisamment générale pour maximiser les hits (préfixe restore-keys).
Qualité du code — linting, formatting, SAST#
Linting#
Le linter analyse le code source à la recherche de problèmes stylistiques, de bugs potentiels, et de violations des conventions. Exemples :
Python :
ruff,flake8,pylintJavaScript/TypeScript :
eslintGo :
golangci-lintSQL :
sqlfluff
Formatting#
Le formateur automatique normalise le style du code. Il doit être exécuté en mode « check » dans le pipeline (fail si le code n’est pas formaté) et en mode « fix » localement.
Python :
black,isort,ruff formatJavaScript :
prettierGo :
gofmt(intégré au langage)Terraform :
terraform fmt
SAST (Static Application Security Testing)#
L’analyse statique de sécurité détecte les vulnérabilités courantes sans exécuter le code : injections SQL, XSS, utilisation de fonctions dangereuses, secrets en dur, configurations non sécurisées.
# Pipeline CI commenté — générique (non exécutable)
# Déclenchement sur chaque push et pull request
on: [push, pull_request]
jobs:
quality:
runs-on: ubuntu-latest
steps:
# 1. Checkout du code
- uses: actions/checkout@v4
# 2. Lint — fail fast, quelques secondes
- name: Lint
run: ruff check .
# 3. Format check
- name: Format
run: ruff format --check .
# 4. Tests unitaires avec couverture
- name: Tests unitaires
run: pytest tests/unit/ --cov=src --cov-fail-under=75
# 5. SAST — analyse de sécurité statique
- name: SAST Bandit
run: bandit -r src/ -ll
integration:
needs: quality # Attend que quality soit vert
runs-on: ubuntu-latest
services:
postgres: # Service Docker éphémère
image: postgres:16
env:
POSTGRES_PASSWORD: test
steps:
- uses: actions/checkout@v4
- name: Tests d'intégration
run: pytest tests/integration/
Résumé#
Le contrat CI stipule qu’un build vert est synonyme de code déployable en production — ce contrat doit être respecté sans exception.
La pyramide des tests oriente l’investissement vers les tests unitaires (rapides, stables, peu coûteux) et limite les tests E2E aux parcours critiques.
Le vocabulary des test doubles (dummy, stub, fake, spy, mock) permet de choisir le bon outil d’isolation selon le besoin.
Le principe Fail Fast consiste à placer les étapes les plus rapides et les plus susceptibles d’échouer en tête de pipeline pour minimiser le feedback time.
La parallélisation des jobs et la mise en cache des dépendances sont les deux leviers principaux pour maintenir un pipeline sous dix minutes.
La couverture de code est un indicateur de zones non testées, non un objectif — un seuil raisonnable (75-80%) est préférable à une course aux 100%.
Les artifacts permettent de transmettre les résultats entre étapes du pipeline et de conserver une trace des builds pour audit.
Linting, formatting et SAST doivent être intégrés en tout début de pipeline — leur exécution est rapide et leur valeur élevée.
Les tests flaky (résultat non déterministe) doivent être traités comme des bugs de premier ordre : ils érodent la confiance dans le pipeline.
Un pipeline CI mature inclut des gates de qualité (couverture minimale, zéro vulnérabilité critique) qui bloquent le merge automatiquement.