Chapitre 15 — SRE, SLO et SLI#
La fiabilité des systèmes ne s’improvise pas. Le Site Reliability Engineering (SRE) est une discipline née chez Google pour appliquer l’ingénierie logicielle aux problèmes d’exploitation. Son fondement est un contrat de fiabilité mesurable : les SLI, SLO et SLA. Ce chapitre couvre les concepts, les calculs et les décisions opérationnelles qui découlent de cette approche.
Le rôle du Site Reliability Engineer#
Le SRE opère à l’intersection du développement et de l’exploitation. Sa mission : garantir que les systèmes sont fiables, scalables et suffisamment efficaces pour que les équipes produit puissent livrer rapidement.
SRE vs Ops traditionnel :
L’Ops traditionnel réagit aux incidents, gère des runbooks manuels, applique des changements prudemment (souvent via des fenêtres de maintenance rigides)
Le SRE traite les problèmes opérationnels comme des problèmes d’ingénierie : automatisation, élimination du toil, amélioration continue des systèmes
SRE vs DevOps :
DevOps est une culture et un ensemble de pratiques (CI/CD, collaboration dev/ops, feedback loops)
SRE est une implémentation spécifique de cette culture avec des mécanismes concrets : error budgets, SLO, post-mortems blameless
Google décrit le SRE comme « ce que vous obtenez quand vous demandez à un ingénieur logiciel de concevoir une fonction d’exploitation »
SRE n’est pas un titre universel
Chez Google, les SRE passent environ 50 % de leur temps sur des tâches de développement (automatisation, outillage, amélioration des systèmes) et 50 % sur des tâches opérationnelles. Si le ratio toil dépasse 50 %, c’est un signal d’alarme. Dans d’autres entreprises, le titre « SRE » peut couvrir des réalités très différentes.
Hiérarchie SLI → SLO → SLA#
SLI — Service Level Indicator#
Un SLI est une mesure quantitative d’un aspect du comportement du service. C’est un ratio ou une valeur numérique observable.
Exemples concrets :
Disponibilité :
requêtes_réussies / requêtes_totalesLatence P99 : 99e percentile du temps de réponse sur une fenêtre glissante de 1 heure
Fraîcheur : délai maximum entre la dernière mise à jour d’un cache et l’heure courante
Débit : nombre de messages traités par seconde
Durabilité : proportion de données écrites qui peuvent être relues correctement
SLO — Service Level Objective#
Un SLO est un objectif sur un SLI, exprimé pour une fenêtre de temps :
Disponibilité ≥ 99,9 % sur 30 jours glissantsP99 latence ≤ 200 ms pour 95 % des fenêtres d'1 heure
Le SLO est interne : il guide les décisions de l’équipe (vitesse de déploiement, priorité des bugs). Il est généralement plus strict que le SLA pour garder une marge.
SLA — Service Level Agreement#
Le SLA est un contrat juridique avec les clients, définissant les pénalités en cas de non-respect. Il est toujours moins ambitieux que le SLO interne :
Si le SLO est à 99,9 %, le SLA est typiquement à 99,5 %
La différence constitue la marge de sécurité avant activation des pénalités contractuelles
Ne pas confondre SLO et SLA
Le SLA est un contrat externe avec des conséquences financières. Le SLO est un objectif interne qui déclenche des actions techniques (freeze des déploiements, priorisation des bugs). Publier un SLA sans SLO interne plus strict est une erreur classique.
Types de SLI#
Chaque type de service a des SLI naturels différents :
Services de requête/réponse (APIs, sites web) :
Disponibilité :
(requêtes HTTP 2xx + 3xx) / total_requêtesLatence : percentiles P50, P95, P99 — le P99 est critique car il représente l’expérience des utilisateurs les plus mal lotis
Taux d’erreur :
requêtes_5xx / total_requêtes
Services de pipeline/batch :
Fraîcheur : âge des données les plus récentes traitées
Complétude : proportion de records attendus effectivement traités
Débit : vitesse de traitement en records/s
Services de stockage :
Durabilité : probabilité qu’une donnée écrite soit retrouvable
Latence d’écriture et de lecture (percentiles)
Calcul de l’error budget#
L”error budget est la quantité d’indisponibilité autorisée par le SLO sur une période donnée.
error_budget = 1 - SLO
Pour un SLO à 99,9 % sur 30 jours :
error_budget = 1 - 0,999 = 0,001 = 0,1 %
minutes_par_mois = 30 × 24 × 60 = 43 200 minutes
budget_minutes = 43 200 × 0,001 = 43,2 minutes
Ce budget est consommé par :
Les incidents (pannes, ralentissements)
Les déploiements qui causent des erreurs transitoires
La maintenance planifiée (si incluse dans le SLO)
Error budget policy#
La politique d’error budget définit les règles de décision selon l’état du budget :
Budget > 50 % : fonctionnement normal, déploiements autorisés, features prioritaires
Budget entre 10 % et 50 % : déploiements soumis à validation renforcée, focus sur la fiabilité
Budget < 10 % : freeze des déploiements non-critiques, toute la capacité vers la fiabilité
Budget épuisé : freeze total, post-mortem obligatoire, plan de remédiation avant reprise
L’error budget comme outil de dialogue
L’error budget transforme le débat « déployer vite vs déployer prudemment » en une décision objective. Si le budget est plein, l’équipe peut prendre des risques. S’il est épuisé, la conversation est close : la fiabilité prime. C’est l’un des apports les plus puissants du framework SRE.
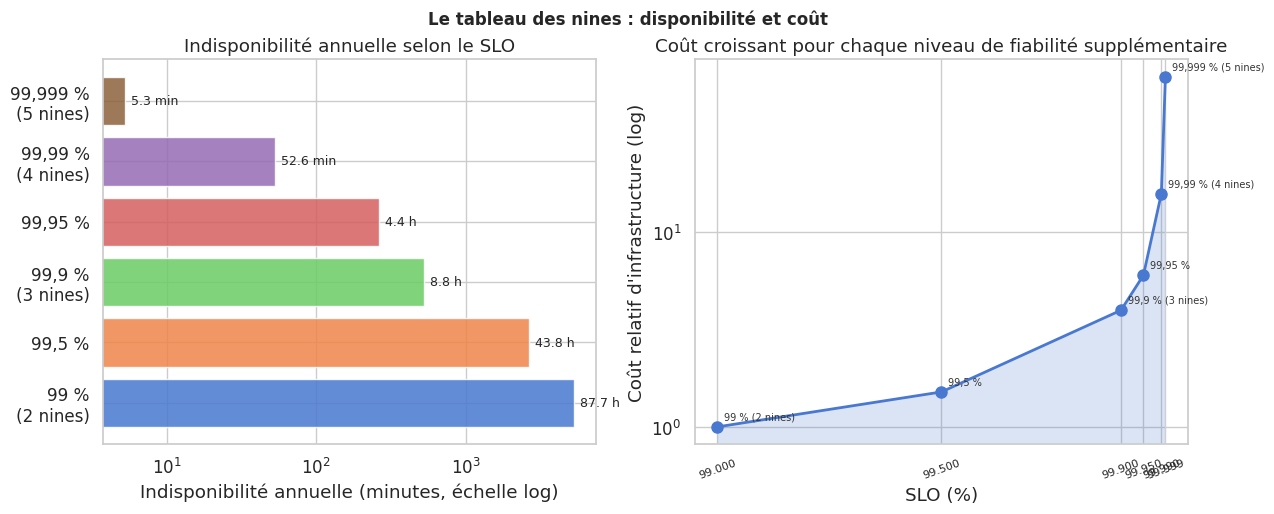
Tableau des « nines »#
SLO |
Indisponibilité/an |
Indisponibilité/mois |
Indisponibilité/semaine |
|---|---|---|---|
99 % (2 nines) |
87,6 h |
7,3 h |
1,68 h |
99,5 % |
43,8 h |
3,65 h |
50 min |
99,9 % (3 nines) |
8,76 h |
43,8 min |
10,1 min |
99,95 % |
4,38 h |
21,9 min |
5 min |
99,99 % (4 nines) |
52,6 min |
4,38 min |
1 min |
99,999 % (5 nines) |
5,26 min |
26,3 s |
6,1 s |
Atteindre les 5 nines est extrêmement coûteux et souvent injustifié. La plupart des services SaaS B2B visent 99,9 % à 99,99 % selon leur criticité.
Toil : définition, mesure et réduction#
Le toil est le travail opérationnel répétitif, manuel, sans valeur ajoutée permanente, qui croît proportionnellement à la charge du service.
Caractéristiques du toil :
Manuel : nécessite une intervention humaine (redémarrer un service, rejouer un batch)
Répétitif : revient régulièrement sans apprentissage progressif
Automatisable : un robot pourrait le faire aussi bien qu’un humain
Réactif : déclenché par un événement externe, pas par un choix de l’ingénieur
Sans valeur permanente : le travail ne construit pas quelque chose de durable
Mesurer le toil : tracer le temps passé par chaque SRE sur du toil vs du travail d’ingénierie. Google fixe un objectif : moins de 50 % du temps en toil. Au-delà, c’est un signal que le service nécessite plus d’automatisation.
Réduire le toil :
Automatiser les runbooks récurrents (scripts, opérateurs Kubernetes)
Améliorer les self-healing capabilities (redémarrage automatique, circuit-breaker)
Éliminer les causes racines d’incidents récurrents plutôt que de les corriger manuellement
Investir dans l’outillage interne pour accélérer les tâches répétitives
Post-mortems blameless#
Un post-mortem est un document d’analyse rédigé après chaque incident significatif. L’adjectif blameless (sans blâme) est fondamental : l’objectif est de comprendre les causes systémiques, pas de punir les individus.
Structure d’un post-mortem#
En-tête :
Date et durée de l’incident
Impact (utilisateurs affectés, SLO consommé, perte de revenus estimée)
Sévérité (P1/P2/P3)
Auteurs et reviewers
Corps :
Timeline : chronologie précise des événements (détection, actions, résolution)
Cause racine : analyse en profondeur — technique ET organisationnelle (les 5 pourquoi)
Impact détaillé : métriques SLI pendant l’incident, error budget consommé
Actions correctives : liste de tâches concrètes, assignées, avec date cible
Culture blameless :
On n’identifie pas « qui a fait l’erreur » mais « pourquoi le système a permis l’erreur »
Un ingénieur qui a fait une erreur l’a fait avec les outils et informations disponibles à ce moment
La vraie question : comment rendre le système plus résistant aux erreurs humaines ?
Le post-mortem comme document vivant
Un post-mortem sans actions de suivi est inutile. Chaque action corrective doit être un ticket dans le backlog, assigné à un responsable, avec une date limite. Le SRE lead revoit les actions ouvertes chaque semaine jusqu’à clôture.
Window-based SLO vs request-based SLO#
Request-based SLO : compte les requêtes bonnes vs mauvaises.
SLI = requêtes_bonnes / requêtes_totales
Exemple : 999 000 requêtes réussies / 1 000 000 totales = 99,9 %
Avantages : précis, pas de biais par fenêtre temporelle, adapté aux APIs haute fréquence.
Window-based SLO : découpe le temps en fenêtres (1 min, 5 min) et classe chaque fenêtre comme « bonne » ou « mauvaise ».
SLI = fenêtres_bonnes / fenêtres_totales
Une fenêtre est "bonne" si le taux d'erreur < seuil pendant cette fenêtre
Avantages : capture mieux les périodes de dégradation, même si le volume de requêtes est faible. Adapté aux services à trafic variable.
Burn rate alerting#
Le burn rate mesure la vitesse à laquelle l’error budget est consommé, relativement à la vitesse « normale ».
burn_rate = taux_erreur_actuel / (1 - SLO)
Un burn rate de 1 signifie que le budget est consommé exactement au rythme prévu. Un burn rate de 14,4 signifie que le budget mensuel sera épuisé en 2 heures.
Stratégie à deux fenêtres#
Google recommande des alertes à deux vitesses pour couvrir les incidents rapides et les dégradations lentes :
Fast burn (alerte immédiate, réveille l’astreinte) :
Fenêtre courte : 1 heure
Burn rate seuil : 14,4 (consomme 2 % du budget mensuel en 1 heure)
Fenêtre longue : 5 minutes (pour éviter les faux positifs)
Slow burn (ticket haute priorité, pas de réveil nocturne) :
Fenêtre : 6 heures
Burn rate seuil : 6 (consomme 5 % du budget mensuel en 6 heures)
Ou fenêtre de 3 jours, burn rate 1
Simulation : consommation d’error budget sur 30 jours#
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
# Paramètres
slo = 0.999 # SLO 99,9 %
days = 30
minutes_per_day = 1440
total_minutes = days * minutes_per_day
error_budget_minutes = total_minutes * (1 - slo) # 43,2 min
print(f"Error budget total : {error_budget_minutes:.1f} minutes sur {days} jours")
# Simulation des incidents (arrêt partiel du service)
incidents = [
{"start": 3 * 1440 + 120, "duration": 8}, # Incident J3 : 8 min
{"start": 8 * 1440 + 600, "duration": 15}, # Incident J8 : 15 min (majeur)
{"start": 15 * 1440 + 200, "duration": 5}, # Incident J15 : 5 min
{"start": 22 * 1440 + 900, "duration": 12}, # Incident J22 : 12 min
{"start": 28 * 1440 + 400, "duration": 6}, # Incident J28 : 6 min
]
# Calcul de la consommation cumulée minute par minute
budget_consumed = np.zeros(total_minutes)
for inc in incidents:
s = inc["start"]
d = min(inc["duration"], total_minutes - s)
budget_consumed[s:s + d] = 1
cumul_consumed = np.cumsum(budget_consumed)
budget_remaining = error_budget_minutes - cumul_consumed
budget_pct_remaining = budget_remaining / error_budget_minutes * 100
# Axe temps en jours
t_days = np.linspace(0, 30, total_minutes)
fig, axes = plt.subplots(2, 1, figsize=(13, 8), sharex=True)
# Graphe 1 : budget restant en minutes
ax1 = axes[0]
ax1.fill_between(t_days, budget_remaining.clip(0), color="#4C72B0", alpha=0.4, label="Budget restant (min)")
ax1.plot(t_days, budget_remaining.clip(0), color="#4C72B0", linewidth=1.5)
ax1.axhline(y=0, color="red", linewidth=1.5, linestyle="--")
ax1.axhline(y=error_budget_minutes * 0.1,
color="orange", linewidth=1, linestyle=":", label="Seuil freeze déploiements (10 %)")
ax1.set_ylabel("Budget restant (minutes)")
ax1.set_title(f"Consommation de l'error budget (SLO {slo*100:.1f} % — budget : {error_budget_minutes:.0f} min/mois)")
ax1.legend(loc="upper right")
# Marquer les incidents
for inc in incidents:
day_pos = inc["start"] / minutes_per_day
ax1.axvline(x=day_pos, color="red", alpha=0.3, linewidth=2)
# Graphe 2 : burn rate
# Burn rate sur fenêtre glissante 1h
window_size = 60 # minutes
kernel = np.ones(window_size) / window_size
error_rate_smooth = np.convolve(budget_consumed, kernel, mode="same")
burn_rate = error_rate_smooth / (1 - slo)
ax2 = axes[1]
ax2.plot(t_days, burn_rate, color="#DD8452", linewidth=1.5, label="Burn rate (fenêtre 1h)")
ax2.axhline(y=14.4, color="red", linestyle="--", linewidth=1.5, label="Seuil fast burn (14,4)")
ax2.axhline(y=6, color="orange", linestyle=":", linewidth=1.5, label="Seuil slow burn (6)")
ax2.axhline(y=1, color="green", linestyle="-.", linewidth=1, label="Burn rate nominal (1)")
ax2.set_ylim(0, 30)
ax2.set_xlabel("Jours")
ax2.set_ylabel("Burn rate")
ax2.set_title("Burn rate sur fenêtre glissante 1h")
ax2.legend(loc="upper right", fontsize=9)
plt.suptitle("Simulation de consommation d'error budget sur 30 jours", fontsize=12, fontweight="bold")
plt.show()
print(f"\nBilan final :")
print(f" Budget consommé : {cumul_consumed[-1]:.1f} min ({cumul_consumed[-1]/error_budget_minutes*100:.0f} %)")
print(f" Budget restant : {max(0, budget_remaining[-1]):.1f} min")
print(f" SLO respecté : {'OUI' if cumul_consumed[-1] <= error_budget_minutes else 'NON'}")
Error budget total : 43.2 minutes sur 30 jours
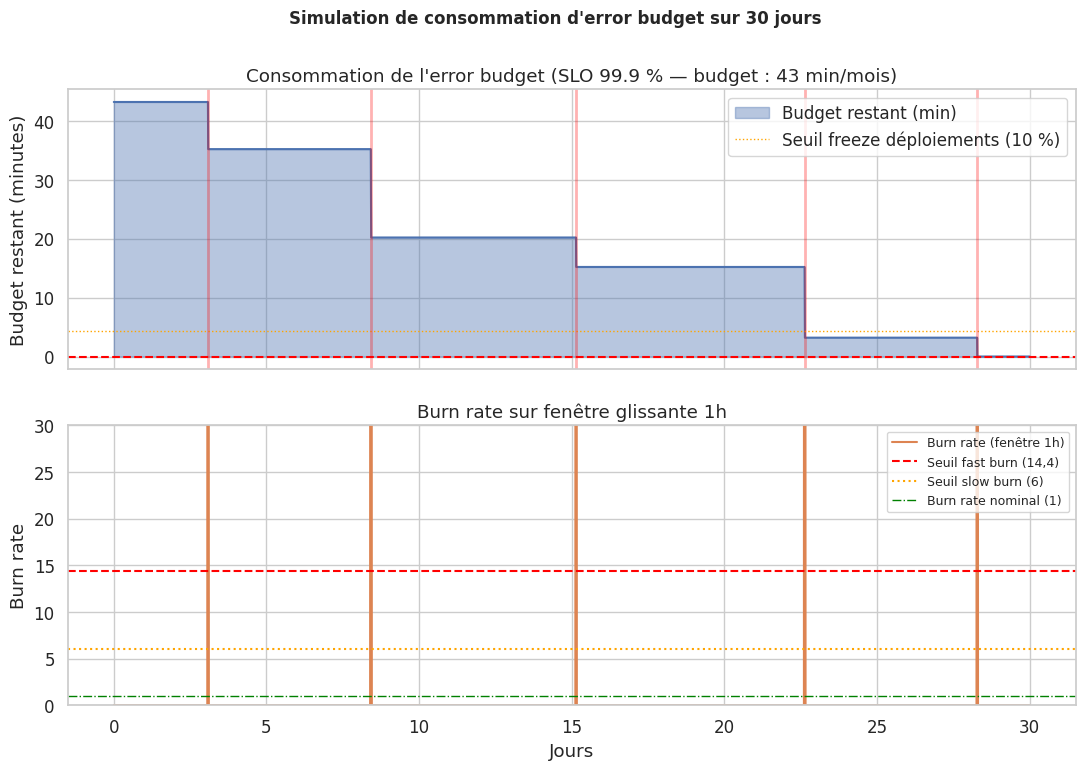
Bilan final :
Budget consommé : 46.0 min (106 %)
Budget restant : 0.0 min
SLO respecté : NON
Visualisation : tableau des nines#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
slo_values = [99.0, 99.5, 99.9, 99.95, 99.99, 99.999]
labels = ["99 %\n(2 nines)", "99,5 %", "99,9 %\n(3 nines)", "99,95 %", "99,99 %\n(4 nines)", "99,999 %\n(5 nines)"]
minutes_per_year = 365.25 * 24 * 60
downtime_minutes = [(1 - slo / 100) * minutes_per_year for slo in slo_values]
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
palette = sns.color_palette("muted", len(slo_values))
# Graphe 1 : indisponibilité annuelle (échelle log)
ax1 = axes[0]
bars = ax1.barh(labels, downtime_minutes, color=palette, alpha=0.85)
ax1.set_xscale("log")
ax1.set_xlabel("Indisponibilité annuelle (minutes, échelle log)")
ax1.set_title("Indisponibilité annuelle selon le SLO")
for bar, val in zip(bars, downtime_minutes):
if val >= 60:
label = f"{val/60:.1f} h"
else:
label = f"{val:.1f} min"
ax1.text(val * 1.1, bar.get_y() + bar.get_height() / 2,
label, va="center", fontsize=9)
# Graphe 2 : coût relatif d'atteindre chaque niveau
# Modèle simplifié : le coût d'infrastructure croît exponentiellement avec les nines
nines_count = [2, 2.3, 3, 3.3, 4, 5]
relative_cost = [10 ** ((n - 2) * 0.6) for n in nines_count]
ax2 = axes[1]
ax2.plot(slo_values, relative_cost, "o-", linewidth=2, markersize=8)
ax2.fill_between(slo_values, relative_cost, alpha=0.2)
ax2.set_yscale("log")
ax2.set_xlabel("SLO (%)")
ax2.set_ylabel("Coût relatif d'infrastructure (log)")
ax2.set_title("Coût croissant pour chaque niveau de fiabilité supplémentaire")
ax2.set_xticks(slo_values)
ax2.set_xticklabels([f"{v:.3f}" for v in slo_values], rotation=20, fontsize=8)
for x, y, lbl in zip(slo_values, relative_cost, labels):
ax2.annotate(lbl.replace("\n", " "), xy=(x, y), xytext=(5, 5),
textcoords="offset points", fontsize=7, color="#333333")
plt.suptitle("Le tableau des nines : disponibilité et coût", fontsize=12, fontweight="bold")
plt.show()
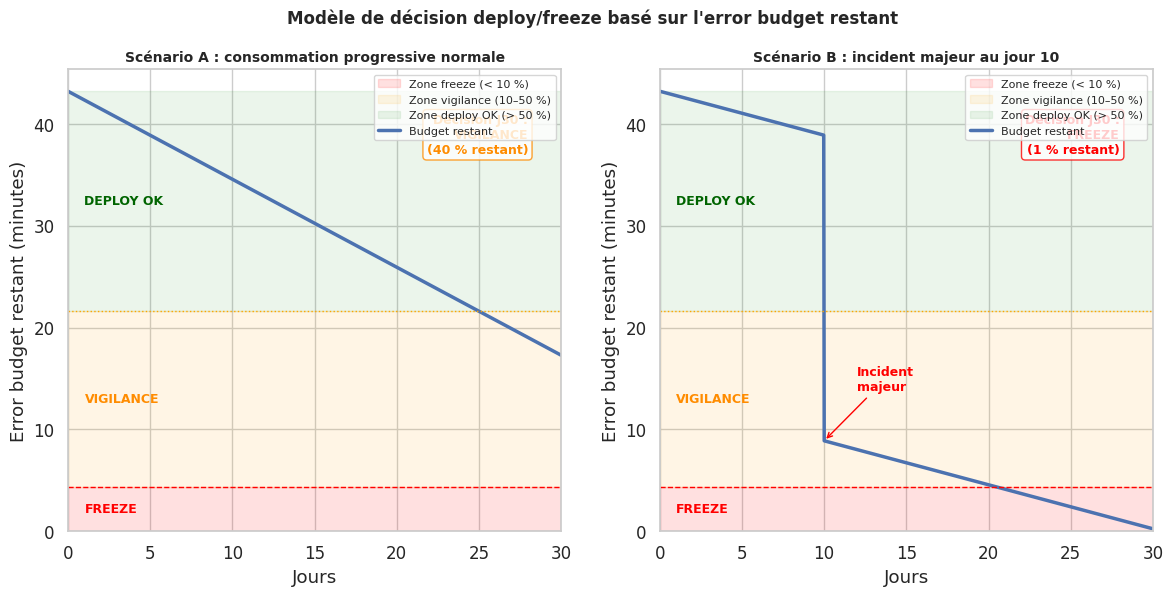
Modèle de décision « deploy or freeze »#
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(0)
# Paramètres de simulation
slo = 0.999
error_budget_total = (1 - slo) * 30 * 24 * 60 # ~43 min
days = np.linspace(0, 30, 1000)
# Scénario 1 : consommation normale (pas d'incident grave)
budget_normal = error_budget_total * (1 - 0.6 * days / 30)
budget_normal = np.maximum(budget_normal, 0)
# Scénario 2 : incident majeur au J10, budget épuisé
budget_incident = error_budget_total * (1 - 0.3 * days / 30)
# Incident au J10 : perte de 30 min
idx_incident = np.searchsorted(days, 10)
budget_incident[idx_incident:] -= 30
budget_incident = np.maximum(budget_incident, 0)
# Zones de décision
freeze_threshold = error_budget_total * 0.10 # < 10 % → freeze
warn_threshold = error_budget_total * 0.50 # < 50 % → vigilance
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
for ax, budget, title, scenario in [
(axes[0], budget_normal, "Scénario A : consommation progressive normale", "normal"),
(axes[1], budget_incident, "Scénario B : incident majeur au jour 10", "incident"),
]:
# Zones colorées
ax.axhspan(0, freeze_threshold, alpha=0.12, color="red", label="Zone freeze (< 10 %)")
ax.axhspan(freeze_threshold, warn_threshold, alpha=0.10, color="orange", label="Zone vigilance (10–50 %)")
ax.axhspan(warn_threshold, error_budget_total, alpha=0.08, color="green", label="Zone deploy OK (> 50 %)")
ax.plot(days, budget, linewidth=2.5, color="#4C72B0", label="Budget restant")
ax.axhline(y=freeze_threshold, color="red", linestyle="--", linewidth=1)
ax.axhline(y=warn_threshold, color="orange", linestyle=":", linewidth=1)
if scenario == "incident":
ax.annotate("Incident\nmajeur", xy=(10, budget_incident[idx_incident]),
xytext=(12, budget_incident[idx_incident] + 5),
arrowprops=dict(arrowstyle="->", color="red"),
color="red", fontsize=9, fontweight="bold")
# Annotations des zones
ax.text(1, freeze_threshold / 2, "FREEZE", color="red", fontsize=9,
fontweight="bold", va="center")
ax.text(1, (freeze_threshold + warn_threshold) / 2, "VIGILANCE",
color="darkorange", fontsize=9, fontweight="bold", va="center")
ax.text(1, (warn_threshold + error_budget_total) / 2, "DEPLOY OK",
color="darkgreen", fontsize=9, fontweight="bold", va="center")
# Décision finale
final_pct = budget[-1] / error_budget_total * 100
decision = "DEPLOY OK" if budget[-1] > warn_threshold else (
"FREEZE" if budget[-1] <= freeze_threshold else "VIGILANCE")
color_dec = "darkgreen" if "OK" in decision else ("red" if "FREEZE" in decision else "darkorange")
ax.text(28, error_budget_total * 0.95, f"Décision J30 :\n{decision}\n({final_pct:.0f} % restant)",
ha="right", va="top", fontsize=9, color=color_dec, fontweight="bold",
bbox=dict(boxstyle="round,pad=0.3", facecolor="white", edgecolor=color_dec, alpha=0.8))
ax.set_xlabel("Jours")
ax.set_ylabel("Error budget restant (minutes)")
ax.set_title(title, fontsize=10, fontweight="bold")
ax.set_ylim(0, error_budget_total * 1.05)
ax.set_xlim(0, 30)
ax.legend(loc="upper right", fontsize=8)
plt.suptitle("Modèle de décision deploy/freeze basé sur l'error budget restant", fontsize=12, fontweight="bold")
plt.show()
Résumé#
Le SRE traite les problèmes d’exploitation comme des problèmes d’ingénierie : automatisation, mesure rigoureuse et amélioration continue plutôt que réaction manuelle aux incidents.
La hiérarchie SLI → SLO → SLA donne un langage commun entre les équipes produit, technique et commerciale pour parler de fiabilité avec des chiffres précis.
Un SLI est une mesure observable ; un SLO est l’objectif interne sur ce SLI ; un SLA est le contrat externe, toujours moins ambitieux que le SLO.
L”error budget (
1 - SLO) est la quantité d’indisponibilité autorisée : il transforme la tension « livrer vite vs rester stable » en une décision objective basée sur un solde de compte.L”error budget policy définit des seuils automatiques de décision (deploy, vigilance, freeze) qui retirent l’arbitraire des discussions entre équipes.
Passer de 99,9 % à 99,99 % de disponibilité réduit l’indisponibilité annuelle de 8,76 h à 52 min, mais le coût d’infrastructure et opérationnel croît de manière exponentielle.
Le toil est le travail opérationnel répétitif et automatisable ; le dépasser à 50 % du temps SRE est un signal que le service est sous-dimensionné en ingénierie.
Les post-mortems blameless cherchent les causes systémiques des incidents, pas les responsables individuels — culture indispensable pour que les ingénieurs signalent les problèmes sans crainte.
Le burn rate alerting à deux vitesses (fast burn 1h + slow burn 6h) permet de détecter à la fois les pannes franches (budget épuisé en 2h) et les dégradations insidieuses (budget épuisé en 3 jours).
Les SLO window-based conviennent aux services à trafic variable (les fenêtres « mauvaises » comptent indépendamment du volume) ; les SLO request-based sont plus précis pour les APIs haute fréquence.