11 — Kubernetes : workloads avancés#
Le livre Docker a couvert les fondamentaux de Kubernetes : Deployments, Services, Ingress, Helm de base, HPA simple, ConfigMaps et Secrets. Ce chapitre va plus loin en explorant les workloads spécialisés, les mécanismes d’autoscaling avancés et les contraintes de scheduling qui permettent de tirer parti d’un cluster de production multi-nœuds.
StatefulSets#
Les Deployments traitent les pods comme interchangeables. Les StatefulSets garantissent à chaque pod une identité stable et persistante : nom prévisible (mysql-0, mysql-1, mysql-2), volume persistant dédié et ordre de démarrage/arrêt strict.
Headless service et PVC templates#
# statefulset-postgres.yaml
apiVersion: v1
kind: Service
metadata:
name: postgres-headless
spec:
clusterIP: None # headless : pas de VIP, DNS résout directement vers les pods
selector:
app: postgres
ports:
- port: 5432
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: postgres-headless
replicas: 3
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:16.2
env:
- name: PGDATA
value: /var/lib/postgresql/data/pgdata
volumeMounts:
- name: data
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ReadWriteOnce]
storageClassName: fast-ssd
resources:
requests:
storage: 50Gi
Avec ce manifeste, postgres-0 accède toujours au PVC data-postgres-0, même après un redémarrage sur un autre nœud. Le headless service permet d’adresser chaque pod individuellement : postgres-0.postgres-headless.default.svc.cluster.local.
Mises à jour d’un StatefulSet#
La stratégie par défaut RollingUpdate met à jour les pods du plus grand index vers le plus petit (N-1 → 0), garantissant que le leader (souvent pod-0) est le dernier à redémarrer.
StatefulSets et opérateurs
Pour les bases de données complexes (PostgreSQL HA, Kafka, Elasticsearch), préférer un opérateur Kubernetes (CloudNative PG, Strimzi, ECK) qui encapsule la logique de failover, de sauvegarde et de restauration. Les StatefulSets bruts suffisent pour des cas simples ou des démos.
DaemonSets#
Un DaemonSet garantit qu”un pod tourne sur chaque nœud (ou sur un sous-ensemble filtré par sélecteur). Les pods sont automatiquement créés sur les nouveaux nœuds et supprimés quand un nœud est retiré du cluster.
Cas d’usage typiques :
Agents de logging (Fluentd, Fluent Bit) : collecter les logs de tous les nœuds
Agents de monitoring (Prometheus Node Exporter, Datadog Agent)
Plugins réseau CNI (Calico, Cilium)
Agents de sécurité (Falco, Tetragon)
# daemonset-fluent-bit.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: monitoring
spec:
selector:
matchLabels:
app: fluent-bit
template:
metadata:
labels:
app: fluent-bit
spec:
tolerations:
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
operator: Exists
containers:
- name: fluent-bit
image: fluent/fluent-bit:3.0
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
La toleration control-plane: NoSchedule permet au DaemonSet de s’exécuter aussi sur les nœuds master, ce qui est nécessaire pour la collecte exhaustive des logs.
Jobs et CronJobs#
Jobs#
Un Job crée un ou plusieurs pods et s’assure qu’un nombre défini d’entre eux se terminent avec succès.
# job-migration.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: db-migration-v2-1-0
spec:
completions: 1 # nombre de pods à compléter avec succès
parallelism: 1 # pods simultanés
backoffLimit: 3 # tentatives avant échec définitif
ttlSecondsAfterFinished: 3600 # nettoyage automatique 1h après
template:
spec:
restartPolicy: OnFailure
containers:
- name: migrate
image: ghcr.io/myorg/myapp:v2.1.0
command: ["python", "manage.py", "migrate", "--run-syncdb"]
CronJobs#
# cronjob-report.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: daily-report
spec:
schedule: "0 6 * * 1-5" # du lundi au vendredi à 6h UTC
concurrencyPolicy: Forbid # interdit le chevauchement d'exécutions
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 5
jobTemplate:
spec:
backoffLimit: 2
template:
spec:
restartPolicy: OnFailure
containers:
- name: report
image: ghcr.io/myorg/reporter:1.4.2
env:
- name: REPORT_TYPE
value: daily
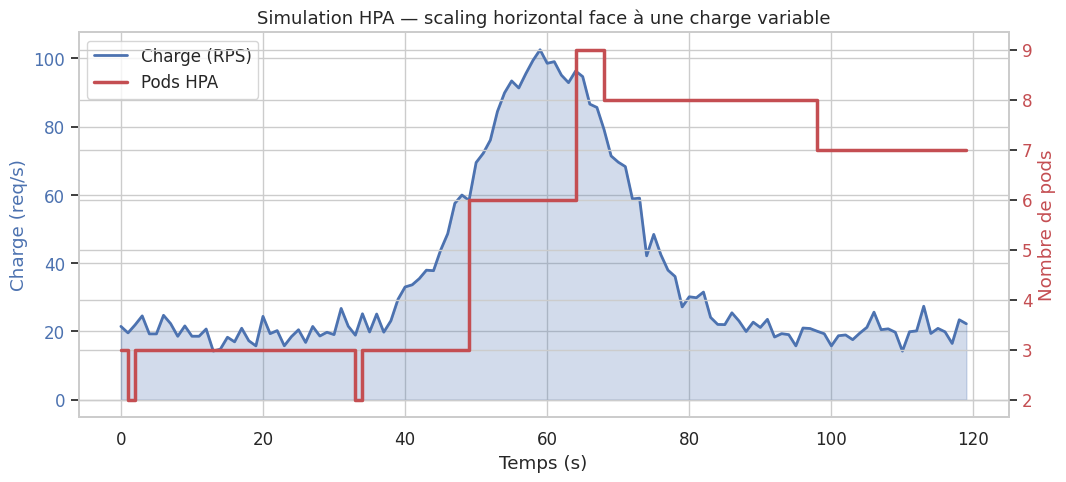
Autoscaling avancé#
HPA avec métriques custom et externes#
Le HPA standard scale sur CPU et mémoire. Pour des métriques applicatives (longueur de queue, requêtes par seconde), il faut enregistrer des métriques custom via l’API custom.metrics.k8s.io.
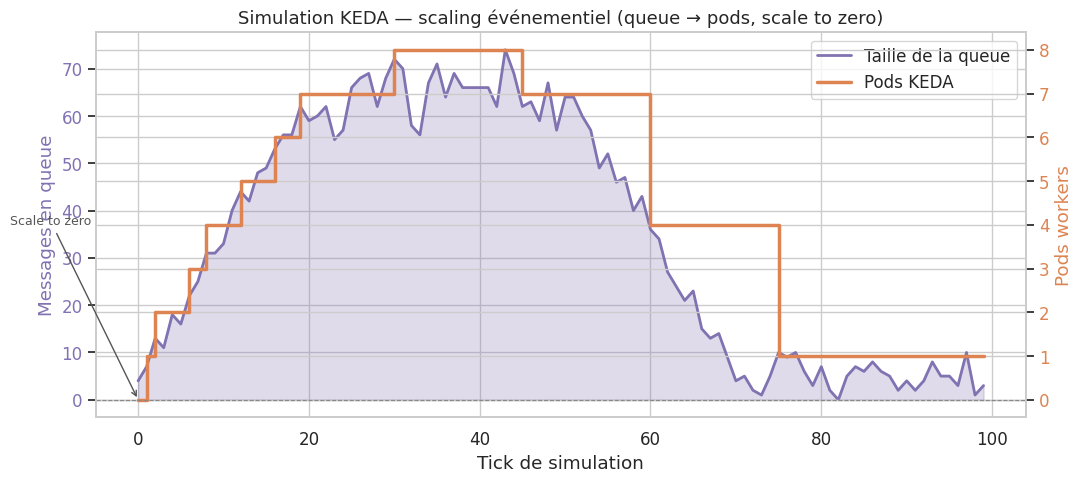
KEDA — Kubernetes Event-Driven Autoscaling#
KEDA étend le HPA avec des ScaledObjects qui réagissent à des sources d’événements externes : queues RabbitMQ, topics Kafka, métriques Prometheus, planification cron.
# keda-scaledobject-rabbitmq.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: worker-scaledobject
spec:
scaleTargetRef:
name: worker-deployment
minReplicaCount: 0 # scale to zero si la queue est vide
maxReplicaCount: 50
pollingInterval: 15
cooldownPeriod: 30
triggers:
- type: rabbitmq
metadata:
host: amqp://rabbitmq.default.svc.cluster.local
queueName: tasks
queueLength: "10" # 1 pod par tranche de 10 messages en attente
- type: prometheus
metadata:
serverAddress: http://prometheus.monitoring.svc:9090
metricName: http_requests_per_second
threshold: "100"
query: sum(rate(http_requests_total[2m]))
Scale to zero avec KEDA
KEDA peut réduire le nombre de replicas à zéro quand la source d’événements est vide — ce que le HPA standard ne peut pas faire (minimum 1 replica). C’est idéal pour les workers de traitement de lots qui n’ont pas besoin de tourner en permanence, réduisant les coûts de façon significative.
VPA — Vertical Pod Autoscaler#
Le VPA analyse l’utilisation réelle des ressources et recommande (ou applique automatiquement) des ajustements des requests et limits.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: myapp-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
updatePolicy:
updateMode: "Auto" # Off | Initial | Recreate | Auto
resourcePolicy:
containerPolicies:
- containerName: myapp
minAllowed:
cpu: 100m
memory: 128Mi
maxAllowed:
cpu: 4
memory: 4Gi
HPA et VPA ensemble
HPA et VPA ne doivent pas cibler la même métrique en même temps (risque de conflits de décisions). L’usage courant est : VPA en mode Off pour les recommandations, HPA pour le scaling horizontal. KEDA est souvent la meilleure alternative à HPA+VPA pour les workloads événementiels.
Scheduling avancé#
Node affinity et anti-affinity#
L’affinity de nœud permet de contraindre le placement des pods sur des nœuds présentant certains labels.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # hard constraint
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values: [eu-west-1a, eu-west-1b]
preferredDuringSchedulingIgnoredDuringExecution: # soft constraint
- weight: 80
preference:
matchExpressions:
- key: node.kubernetes.io/instance-type
operator: In
values: [c6i.4xlarge]
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: myapp
topologyKey: kubernetes.io/hostname # 1 pod par nœud physique
Taints et tolerations#
Les taints marquent des nœuds comme réservés ; seuls les pods portant la toleration correspondante peuvent y être schedulés.
# Taint sur un nœud GPU
# kubectl taint nodes gpu-node-01 dedicated=gpu:NoSchedule
# Pod avec toleration
tolerations:
- key: dedicated
operator: Equal
value: gpu
effect: NoSchedule # NoSchedule | PreferNoSchedule | NoExecute
NoSchedule: les nouveaux pods sans toleration ne sont pas schedulés sur ce nœudPreferNoSchedule: Kubernetes évite le nœud mais peut y placer des pods si nécessaireNoExecute: éviction des pods existants sans toleration (avectolerationSecondsoptionnel)
Pod Disruption Budgets#
Un PDB garantit un niveau minimal de disponibilité pendant les opérations de maintenance (drain de nœud, rolling update).
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: myapp-pdb
spec:
minAvailable: 2 # ou maxUnavailable: 1
selector:
matchLabels:
app: myapp
Avec minAvailable: 2, un kubectl drain refusera de terminer un pod de myapp si cela ferait passer le nombre de pods disponibles en dessous de 2.
Topology spread constraints#
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: myapp
maxSkew: 1 garantit que la différence de pods entre les zones disponibles ne dépasse pas 1 — les pods sont répartis équitablement entre eu-west-1a, eu-west-1b, eu-west-1c.
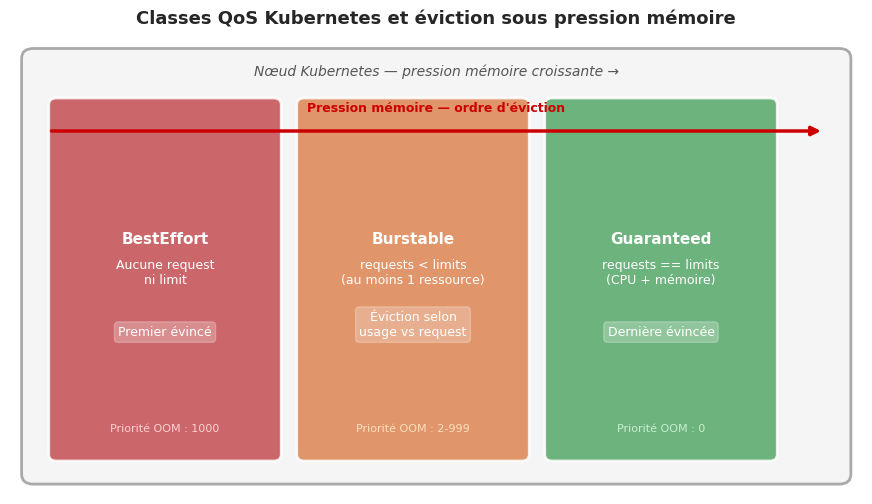
QoS classes et resource management#
Kubernetes classe les pods en trois catégories de QoS selon leurs requests et limits :
QoS class |
Condition |
Éviction sous pression |
|---|---|---|
Guaranteed |
requests == limits pour CPU et mémoire |
Dernier évincé |
Burstable |
requests < limits (au moins une ressource) |
Éviction intermédiaire |
BestEffort |
Aucune request ni limit définies |
Premier évincé |
Priority classes et Preemption#
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "Workloads critiques de production"
---
# Dans le pod spec :
priorityClassName: high-priority
Quand les ressources du cluster sont épuisées, Kubernetes peut évincer des pods de faible priorité pour libérer de la place à un pod de haute priorité en attente (preemption).
Simulations Python#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(11, 6))
ax.set_xlim(0, 11)
ax.set_ylim(0, 7)
ax.axis("off")
ax.set_title("Classes QoS Kubernetes et éviction sous pression mémoire", fontsize=13, fontweight="bold")
# Nœud (fond)
node_box = FancyBboxPatch((0.3, 0.3), 10.4, 6.3,
boxstyle="round,pad=0.15",
facecolor="#F5F5F5", edgecolor="#AAAAAA", linewidth=2)
ax.add_patch(node_box)
ax.text(5.5, 6.35, "Nœud Kubernetes — pression mémoire croissante →", ha="center",
fontsize=10, color="#555", style="italic")
# QoS BestEffort (évincé en premier)
be = FancyBboxPatch((0.6, 0.6), 2.8, 5.3,
boxstyle="round,pad=0.1",
facecolor="#C44E52", edgecolor="white", linewidth=2, alpha=0.85)
ax.add_patch(be)
ax.text(2.0, 3.8, "BestEffort", ha="center", fontsize=11, fontweight="bold", color="white")
ax.text(2.0, 3.2, "Aucune request\nni limit", ha="center", fontsize=9, color="white")
ax.text(2.0, 2.4, "Premier évincé", ha="center", fontsize=9, color="white",
bbox=dict(boxstyle="round", facecolor="white", alpha=0.25))
ax.text(2.0, 0.95, "Priorité OOM : 1000", ha="center", fontsize=8, color="#FFD0D0")
# QoS Burstable
bu = FancyBboxPatch((3.8, 0.6), 2.8, 5.3,
boxstyle="round,pad=0.1",
facecolor="#DD8452", edgecolor="white", linewidth=2, alpha=0.85)
ax.add_patch(bu)
ax.text(5.2, 3.8, "Burstable", ha="center", fontsize=11, fontweight="bold", color="white")
ax.text(5.2, 3.2, "requests < limits\n(au moins 1 ressource)", ha="center", fontsize=9, color="white")
ax.text(5.2, 2.4, "Éviction selon\nusage vs request", ha="center", fontsize=9, color="white",
bbox=dict(boxstyle="round", facecolor="white", alpha=0.25))
ax.text(5.2, 0.95, "Priorité OOM : 2-999", ha="center", fontsize=8, color="#FFE0C0")
# QoS Guaranteed (dernière à être évincée)
gu = FancyBboxPatch((7.0, 0.6), 2.8, 5.3,
boxstyle="round,pad=0.1",
facecolor="#55A868", edgecolor="white", linewidth=2, alpha=0.85)
ax.add_patch(gu)
ax.text(8.4, 3.8, "Guaranteed", ha="center", fontsize=11, fontweight="bold", color="white")
ax.text(8.4, 3.2, "requests == limits\n(CPU + mémoire)", ha="center", fontsize=9, color="white")
ax.text(8.4, 2.4, "Dernière évincée", ha="center", fontsize=9, color="white",
bbox=dict(boxstyle="round", facecolor="white", alpha=0.25))
ax.text(8.4, 0.95, "Priorité OOM : 0", ha="center", fontsize=8, color="#C8F0D0")
# Flèche de pression
ax.annotate("", xy=(10.5, 5.5), xytext=(0.5, 5.5),
arrowprops=dict(arrowstyle="-|>", color="#CC0000", lw=2.5))
ax.text(5.5, 5.8, "Pression mémoire — ordre d'éviction", ha="center",
fontsize=9, color="#CC0000", fontweight="bold")
plt.savefig("_static/11_qos_classes.png", dpi=120, bbox_inches="tight")
plt.show()
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(21)
# Simulation KEDA : taille de queue → nombre de pods
# La queue monte puis descend, KEDA scale up rapidement et down avec cooldown
T = 100
t = np.arange(T)
# Queue simulée : montée rapide, plateau, descente
def queue_size(tick):
if tick < 20:
return int(5 + tick * 3 + np.random.normal(0, 2))
elif tick < 50:
return int(65 + np.random.normal(0, 5))
elif tick < 70:
return int(65 - (tick - 50) * 3 + np.random.normal(0, 3))
else:
return int(max(0, 5 + np.random.normal(0, 2)))
queue = np.array([max(0, queue_size(i)) for i in t])
# KEDA : 1 pod par tranche de 10 messages, minReplicas=0, maxReplicas=20
# scale-up immédiat, cooldown de 15 ticks avant scale-down
MSGS_PER_POD = 10
MIN_PODS = 0
MAX_PODS = 20
COOLDOWN = 15
pods_keda = np.zeros(T, dtype=int)
last_change = -COOLDOWN
for i in range(1, T):
desired = min(MAX_PODS, max(MIN_PODS, int(np.ceil(queue[i] / MSGS_PER_POD))))
if desired > pods_keda[i-1]:
pods_keda[i] = desired # scale-up immédiat
last_change = i
elif desired < pods_keda[i-1] and (i - last_change) >= COOLDOWN:
pods_keda[i] = max(desired, pods_keda[i-1] - 3)
last_change = i
else:
pods_keda[i] = pods_keda[i-1]
fig, ax1 = plt.subplots(figsize=(12, 5))
ax2 = ax1.twinx()
ax1.fill_between(t, queue, alpha=0.25, color="#8172B2")
ax1.plot(t, queue, color="#8172B2", lw=2, label="Taille de la queue")
ax2.step(t, pods_keda, color="#DD8452", lw=2.5, where="post", label="Pods KEDA")
ax1.axhline(y=0, color="#888", lw=0.8, linestyle="--")
ax2.axhline(y=0, color="#888", lw=0.8, linestyle="--")
ax1.set_xlabel("Tick de simulation")
ax1.set_ylabel("Messages en queue", color="#8172B2")
ax2.set_ylabel("Pods workers", color="#DD8452")
ax1.tick_params(axis="y", labelcolor="#8172B2")
ax2.tick_params(axis="y", labelcolor="#DD8452")
ax1.set_title("Simulation KEDA — scaling événementiel (queue → pods, scale to zero)", fontsize=13)
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc="upper right")
# Annoter le scale-to-zero
zero_idx = np.where(pods_keda == 0)[0]
if len(zero_idx) > 0:
ax2.annotate("Scale to zero", xy=(zero_idx[0], 0), xytext=(zero_idx[0] - 15, 4),
arrowprops=dict(arrowstyle="->", color="#555"),
fontsize=9, color="#555")
plt.savefig("_static/11_keda_simulation.png", dpi=120, bbox_inches="tight")
plt.show()
print(f"Ticks à zero pod : {np.sum(pods_keda == 0)} / {T} "
f"({np.sum(pods_keda == 0)/T*100:.1f} % d'économies potentielles)")
Ticks à zero pod : 1 / 100 (1.0 % d'économies potentielles)
Résumé#
Les StatefulSets garantissent une identité stable aux pods (nom prévisible, PVC dédié, ordre de démarrage) — indispensables pour les bases de données et les systèmes distribués avec état.
Les DaemonSets assurent la présence d’un agent sur chaque nœud du cluster ; les tolerations permettent de cibler aussi les nœuds de contrôle.
Les Jobs et CronJobs gèrent les tâches batch avec
completions,parallelismetbackoffLimit;ttlSecondsAfterFinishedévite l’accumulation de ressources terminées.Le HPA standard scale sur CPU/mémoire ; les métriques custom et externes nécessitent l’API
custom.metrics.k8s.ioou KEDA.KEDA est le mécanisme de scaling événementiel de référence : il réagit à des sources externes (queues, Prometheus, cron) et peut réduire les replicas à zéro, ce que le HPA ne peut pas faire.
Le VPA analyse l’utilisation réelle des ressources et ajuste
requests/limits— à utiliser en modeOffpour les recommandations, pas simultanément avec HPA sur la même métrique.Le node affinity et l’anti-affinity permettent d’exprimer des contraintes de placement
required(hard) oupreferred(soft) sur les caractéristiques des nœuds.Les taints et tolerations réservent des nœuds à des workloads spécifiques (
NoSchedule) ou évincent des pods existants incompatibles (NoExecute).Les Pod Disruption Budgets protègent la disponibilité pendant les opérations de maintenance en bloquant les drains qui violeraient le seuil
minAvailable.Les classes QoS (Guaranteed, Burstable, BestEffort) déterminent l’ordre d’éviction sous pression mémoire ; les priority classes et la preemption complètent le mécanisme pour les workloads critiques.