17. Logs structurés et tracing distribué#
L’observabilité repose sur trois piliers : les métriques, les logs et les traces. Ce chapitre couvre les deux derniers en détail — la structuration des logs pour l’agrégation à grande échelle, les architectures de collecte, puis le tracing distribué pour comprendre le comportement d’un système microservices bout en bout.
Logs structurés vs logs textuels#
Un log textuel classique ressemble à ceci :
2024-03-15 14:32:07 ERROR [auth-service] Failed to validate token for user 42: timeout after 3000ms
Utile pour un humain, mais difficile à exploiter programmatiquement. Un log structuré en JSON expose les mêmes informations sous forme de champs indexables :
{
"timestamp": "2024-03-15T14:32:07.341Z",
"level": "error",
"service": "auth-service",
"event": "token_validation_failed",
"user_id": 42,
"error": "timeout",
"duration_ms": 3000,
"trace_id": "4bf92f3577b34da6",
"span_id": "00f067aa0ba902b7"
}
Les avantages sont décisifs à l’échelle :
Filtrage précis :
level:error AND service:auth-service AND duration_ms:>1000Agrégation : compter les erreurs par
user_id, calculer le P99 deduration_msCorrélation : le
trace_idrelie ce log à sa trace distribuée dans Jaeger ou TempoAlerting : les règles d’alerte opèrent sur des champs, pas sur des regex fragiles
Les bibliothèques modernes génèrent du JSON nativement : structlog (Python), zerolog (Go), winston (Node.js), logback avec logstash-logback-encoder (Java).
Stack ELK : Elasticsearch, Logstash, Kibana#
La stack ELK est la référence historique de l’agrégation de logs.
Elasticsearch stocke les logs sous forme de documents JSON dans des index (ou des data streams en mode moderne). Il offre une recherche plein texte et des agrégations analytiques performantes via son moteur basé sur Lucene.
Logstash est le pipeline ETL : il ingère des logs depuis de nombreuses sources (Beats, syslog, Kafka), les transforme (parsing grok, enrichissement GeoIP, ajout de champs) et les envoie vers Elasticsearch ou d’autres destinations.
Kibana est l’interface de visualisation : tableaux de bord, Discover pour l’exploration ad hoc, alerting, et depuis la version 8.x, une interface ML pour la détection d’anomalies.
Filebeat et Metricbeat sont des agents légers (la famille Beats) qui collectent les données sur les hôtes et les forwarded vers Logstash ou directement vers Elasticsearch.
Architecture typique en production :
Pods/Containers → Filebeat (DaemonSet) → Logstash (parsing) → Elasticsearch (cluster) → Kibana
L’inconvénient majeur d’Elasticsearch est son coût opérationnel : il est gourmand en RAM et en disque, et la gestion des index (ILM — Index Lifecycle Management) demande une attention soutenue.
Loki (Grafana) : alternative légère#
Loki est conçu selon le principe « index minimal ». Contrairement à Elasticsearch qui indexe tous les champs JSON, Loki n’indexe que les labels (paires clé-valeur attachées au stream de logs) et stocke le contenu brut compressé (Snappy/gzip).
{namespace="production", app="auth-service", pod="auth-7d4b9c-xkj2p"}
LogQL est le langage de requête, inspiré de PromQL :
# Taux d'erreurs sur les 5 dernières minutes
sum(rate({app="auth-service"} |= "error" [5m])) by (namespace)
# Extraire la latence depuis les logs JSON et calculer le P99
quantile_over_time(0.99, {app="api-gateway"} | json | unwrap duration_ms [10m])
L’intégration native avec Grafana permet d’afficher logs et métriques Prometheus dans le même tableau de bord, avec une corrélation par trace_id vers Tempo.
Promtail est l’agent de collecte standard pour Loki, déployé en DaemonSet. Il lit les fichiers de logs des pods, attache les labels Kubernetes (namespace, pod, container) et forward vers Loki.
Loki est significativement moins cher qu’Elasticsearch en stockage et en compute, au prix d’une recherche moins performante sur le contenu des logs.
Fluent Bit vs Fluentd#
Fluentd est l’agent de collecte de référence de la CNCF, écrit en Ruby/C. Il dispose d’un écosystème de plugins très riche (>1000 plugins) mais sa consommation mémoire (~40 MB) le rend moins adapté aux environnements à forte densité de pods.
Fluent Bit est son successeur allégé, écrit entièrement en C. Il consomme ~1 MB de RAM et est le choix par défaut pour les DaemonSets Kubernetes. Il supporte la plupart des destinations (Elasticsearch, Loki, Splunk, Kafka, S3…).
Exemple de configuration Fluent Bit pour Kubernetes → Loki :
[SERVICE]
Flush 1
Log_Level info
Parsers_File parsers.conf
[INPUT]
Name tail
Path /var/log/containers/*.log
multiline.parser docker, cri
Tag kube.*
Mem_Buf_Limit 50MB
Skip_Long_Lines On
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Merge_Log On
Keep_Log Off
K8S-Logging.Parser On
[OUTPUT]
Name loki
Match kube.*
Host loki.monitoring.svc.cluster.local
Port 3100
Labels job=fluent-bit, namespace=$kubernetes['namespace_name'], app=$kubernetes['labels']['app']
Label_keys $level,$severity
Auto_Kubernetes_Labels On
OpenTelemetry : standard unifié#
OpenTelemetry (OTel) est le projet CNCF qui standardise la collecte de logs, métriques et traces sous un seul SDK et un seul protocole de transport : OTLP (OpenTelemetry Protocol).
L’architecture se compose de :
SDK OTel : instrumentation dans le code applicatif (ou auto-instrumentation via agent)
OpenTelemetry Collector : agent/gateway qui reçoit, transforme et exporte les signaux vers les backends (Jaeger, Prometheus, Loki, Tempo, Datadog…)
OTLP : protocole gRPC/HTTP standardisé pour le transport
Exemple de configuration du Collector :
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
processors:
batch:
timeout: 1s
send_batch_size: 1024
resource:
attributes:
- key: deployment.environment
value: production
action: insert
exporters:
jaeger:
endpoint: jaeger-collector:14250
tls:
insecure: false
prometheusremotewrite:
endpoint: http://prometheus:9090/api/v1/write
loki:
endpoint: http://loki:3100/loki/api/v1/push
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch, resource]
exporters: [jaeger]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [prometheusremotewrite]
logs:
receivers: [otlp]
processors: [batch]
exporters: [loki]
OTel est désormais supporté nativement par la quasi-totalité des frameworks (FastAPI, Spring Boot, Express, gRPC…) et des clouds publics.
Tracing distribué : concepts fondamentaux#
Dans une architecture microservices, une requête utilisateur traverse plusieurs services. Le tracing distribué permet de reconstituer ce chemin complet.
Vocabulaire :
Trace : représentation complète d’une requête de bout en bout, identifiée par un
trace_id(16 octets, ex.4bf92f3577b34da6a3ce929d0e0e4736)Span : unité de travail au sein d’une trace (appel HTTP, requête SQL, opération queue). Chaque span a un
span_id, unparent_span_id, unstart_time, unedurationet des attributsParent-child : les spans forment un arbre ; le span racine n’a pas de parent
Baggage : données de contexte propagées de span en span (ex.
user_id,tenant_id)
Propagation de contexte W3C TraceContext (RFC standard) :
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
tracestate: vendor1=value1,vendor2=value2
Le header traceparent transporte version-trace_id-parent_span_id-flags. Chaque service qui reçoit ce header continue la trace ; chaque service qui initie une nouvelle trace génère un nouveau trace_id.
Jaeger et Grafana Tempo#
Jaeger (CNCF, origine Uber) est le système de tracing open-source le plus mature. Il propose :
Un agent (UDP, déployé en sidecar ou DaemonSet) qui reçoit les spans des applications
Un collector qui valide et écrit dans le backend de stockage
Elasticsearch, Cassandra ou Badger comme backends
Une UI pour visualiser les traces en waterfall et comparer deux traces
Grafana Tempo est l’alternative moderne, conçue pour être économique : il stocke les traces dans un object store (S3, GCS, Azure Blob) sans index, et récupère les traces uniquement par trace_id. La recherche par attribut est possible via TraceQL depuis Tempo 2.0. L’intégration avec Grafana permet la corrélation directe depuis les logs Loki et les métriques Prometheus.
Corrélation logs-traces-métriques#
La corrélation est la valeur ajoutée de l’observabilité unifiée. Le principe :
Trace ID dans les logs : le SDK OTel injecte automatiquement
trace_idetspan_iddans les entrées de log. Dans Grafana, cliquer sur une ligne de log ouvre la trace correspondante dans Tempo.Exemplars Prometheus : des métriques Prometheus peuvent embarquer un
trace_idcomme exemplar. Sur un graphe de latence, cliquer sur un pic ouvre la trace de la requête qui a causé ce pic.Service graph : Tempo peut générer des métriques de span (taux d’erreur, latence) et les envoyer à Prometheus pour construire un service graph automatique — sans instrumentation supplémentaire.
Sampling : head-based vs tail-based#
À grande échelle, enregistrer 100% des traces est coûteux. Le sampling réduit le volume.
Head-based sampling : la décision est prise au premier span, avant de connaître le résultat de la requête. Simple et peu coûteux (pas de buffering), mais aveugle : les requêtes erreurs rares peuvent ne pas être échantillonnées.
Tail-based sampling : la décision est prise après que tous les spans d’une trace sont collectés. Permet de toujours garder les traces d’erreurs et les traces lentes, au prix d’un buffering côté collector (OTel Collector tailsampling processor).
Stratégie recommandée :
100% des traces avec erreurs ou latence > P99
1-5% des traces nominales
100% des traces des utilisateurs VIP (via baggage)
Rétention et archivage#
La rétention des logs doit équilibrer coût et besoin opérationnel :
Hot storage (Elasticsearch/Loki, disque SSD) : 7-30 jours, requêtes rapides
Warm storage (disque HDD ou object store avec indexation) : 30-90 jours
Cold storage (S3 Glacier, GCS Nearline) : 1-7 ans selon les obligations réglementaires (RGPD, PCI-DSS, SOC 2)
Loki supporte nativement les compactors et les règles de rétention par label stream. Elasticsearch utilise l’ILM (Index Lifecycle Management) avec des phases hot → warm → cold → delete.
Visualisations#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch
import seaborn as sns
import numpy as np
import pandas as pd
import json
import random
from datetime import datetime, timedelta
import networkx as nx
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
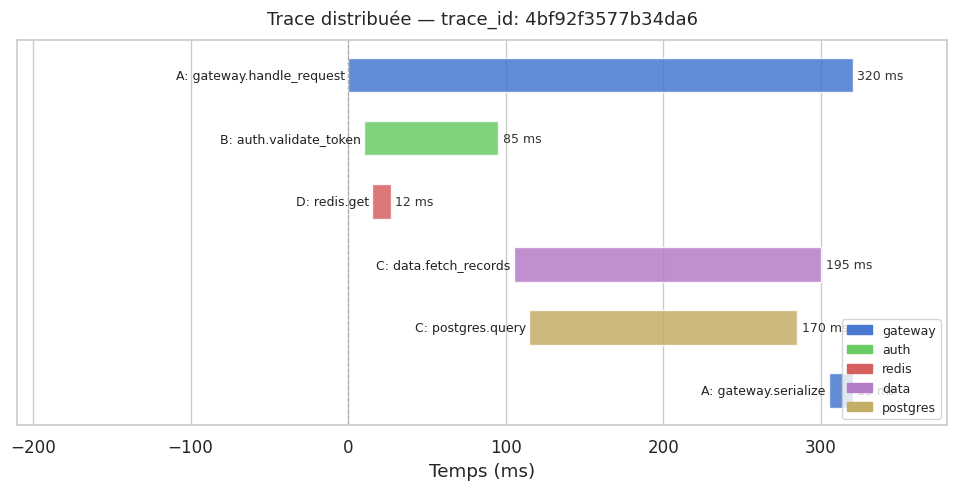
Simulation d’une trace distribuée — waterfall#
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Simulation d'une trace distribuée avec spans imbriqués
# Service A (gateway) → B (auth) et C (data), B → D (cache)
trace_id = "4bf92f3577b34da6"
spans = [
{"name": "A: gateway.handle_request", "service": "gateway", "start": 0, "duration": 320, "parent": None, "status": "ok"},
{"name": "B: auth.validate_token", "service": "auth", "start": 10, "duration": 85, "parent": "A", "status": "ok"},
{"name": "D: redis.get", "service": "redis", "start": 15, "duration": 12, "parent": "B", "status": "ok"},
{"name": "C: data.fetch_records", "service": "data", "start": 105, "duration": 195, "parent": "A", "status": "ok"},
{"name": "C: postgres.query", "service": "postgres", "start": 115, "duration": 170, "parent": "C", "status": "ok"},
{"name": "A: gateway.serialize", "service": "gateway", "start": 305, "duration": 15, "parent": "A", "status": "ok"},
]
service_colors = {
"gateway": "#4878CF",
"auth": "#6ACC65",
"redis": "#D65F5F",
"data": "#B47CC7",
"postgres": "#C4AD66",
}
fig, ax = plt.subplots(figsize=(12, 5))
for i, span in enumerate(spans):
color = service_colors[span["service"]]
y = len(spans) - 1 - i
ax.barh(y, span["duration"], left=span["start"],
color=color, alpha=0.85, height=0.55, edgecolor="white")
ax.text(span["start"] + span["duration"] + 3, y,
f"{span['duration']} ms", va="center", fontsize=9, color="#333333")
ax.text(span["start"] - 2, y, span["name"],
ha="right", va="center", fontsize=9, color="#222222")
ax.set_xlabel("Temps (ms)")
ax.set_title(f"Trace distribuée — trace_id: {trace_id}", fontsize=13, pad=12)
ax.set_yticks([])
ax.set_xlim(-210, 380)
legend_patches = [mpatches.Patch(color=c, label=s) for s, c in service_colors.items()]
ax.legend(handles=legend_patches, loc="lower right", fontsize=9, framealpha=0.8)
ax.axvline(x=0, color="#aaaaaa", linewidth=0.8, linestyle="--")
plt.show()
Analyse d’un corpus de logs JSON simulés#
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
random.seed(42)
np.random.seed(42)
# Génération d'un corpus de 2000 logs JSON simulés
n = 2000
http_codes = random.choices([200, 200, 200, 200, 201, 400, 401, 404, 500, 502, 503],
k=n)
latencies = []
for code in http_codes:
if code == 200:
latencies.append(max(5, np.random.lognormal(mean=4.5, sigma=0.6)))
elif code in (500, 502, 503):
latencies.append(max(100, np.random.lognormal(mean=6.5, sigma=0.8)))
else:
latencies.append(max(5, np.random.lognormal(mean=3.8, sigma=0.5)))
df_logs = pd.DataFrame({
"http_code": http_codes,
"latency_ms": latencies,
"service": random.choices(["gateway", "auth", "data", "notif"], k=n),
})
# Sous-figure 1 : distribution par code HTTP
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
code_counts = df_logs["http_code"].value_counts().sort_index()
palette = {200: "#4878CF", 201: "#6ACC65", 400: "#C4AD66",
401: "#B47CC7", 404: "#D65F5F", 500: "#e06c75",
502: "#c678dd", 503: "#e5c07b"}
colors = [palette.get(c, "#aaaaaa") for c in code_counts.index]
axes[0].bar(code_counts.index.astype(str), code_counts.values,
color=colors, edgecolor="white")
axes[0].set_title("Distribution des codes HTTP")
axes[0].set_xlabel("Code HTTP")
axes[0].set_ylabel("Nombre de logs")
# Sous-figure 2 : distribution de latence avec percentiles
p50 = np.percentile(df_logs["latency_ms"], 50)
p95 = np.percentile(df_logs["latency_ms"], 95)
p99 = np.percentile(df_logs["latency_ms"], 99)
axes[1].hist(df_logs["latency_ms"].clip(upper=2000), bins=60,
color="#4878CF", alpha=0.75, edgecolor="white")
axes[1].axvline(p50, color="#6ACC65", linewidth=2, linestyle="--",
label=f"P50 = {p50:.0f} ms")
axes[1].axvline(p95, color="#C4AD66", linewidth=2, linestyle="--",
label=f"P95 = {p95:.0f} ms")
axes[1].axvline(p99, color="#D65F5F", linewidth=2, linestyle="--",
label=f"P99 = {p99:.0f} ms")
axes[1].set_title("Distribution de latence (ms, clippée à 2000)")
axes[1].set_xlabel("Latence (ms)")
axes[1].set_ylabel("Fréquence")
axes[1].legend(fontsize=9)
fig.suptitle("Analyse du corpus de logs JSON simulés (n=2 000)", fontsize=13, y=1.01)
plt.show()
print(f"Taux d'erreurs 5xx : {(df_logs['http_code'] >= 500).mean()*100:.1f}%")
print(f"P50 latence : {p50:.0f} ms | P95 : {p95:.0f} ms | P99 : {p99:.0f} ms")
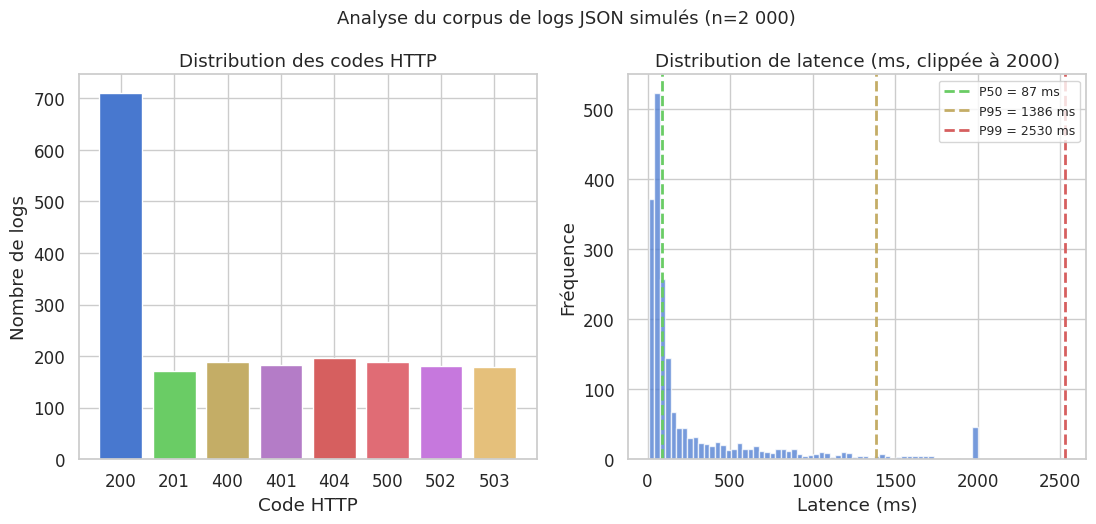
Taux d'erreurs 5xx : 27.4%
P50 latence : 87 ms | P95 : 1386 ms | P99 : 2530 ms
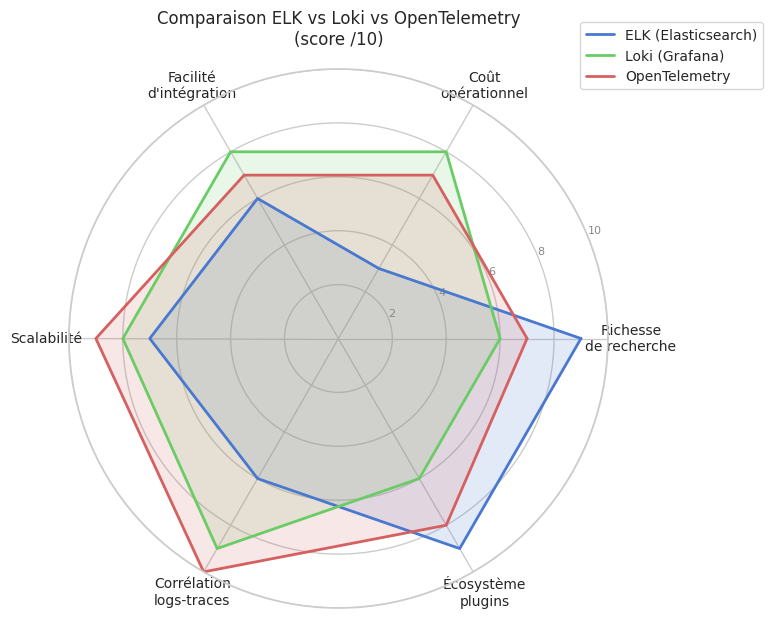
Comparaison ELK vs Loki vs OpenTelemetry — radar chart#
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
categories = [
"Richesse\nde recherche",
"Coût\nopérationnel",
"Facilité\nd'intégration",
"Scalabilité",
"Corrélation\nlogs-traces",
"Écosystème\nplugins",
]
N = len(categories)
scores = {
"ELK (Elasticsearch)": [9, 3, 6, 7, 6, 9],
"Loki (Grafana)": [6, 8, 8, 8, 9, 6],
"OpenTelemetry": [7, 7, 7, 9, 10, 8],
}
angles = np.linspace(0, 2 * np.pi, N, endpoint=False).tolist()
angles += angles[:1]
fig, ax = plt.subplots(figsize=(7, 7), subplot_kw=dict(polar=True))
colors_radar = ["#4878CF", "#6ACC65", "#D65F5F"]
for (label, vals), color in zip(scores.items(), colors_radar):
vals_plot = vals + vals[:1]
ax.plot(angles, vals_plot, color=color, linewidth=2, label=label)
ax.fill(angles, vals_plot, color=color, alpha=0.15)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=10)
ax.set_ylim(0, 10)
ax.set_yticks([2, 4, 6, 8, 10])
ax.set_yticklabels(["2", "4", "6", "8", "10"], fontsize=8, color="#888888")
ax.set_title("Comparaison ELK vs Loki vs OpenTelemetry\n(score /10)", fontsize=12, pad=18)
ax.legend(loc="upper right", bbox_to_anchor=(1.3, 1.1), fontsize=10)
plt.show()
Résumé#
Les logs structurés en JSON sont indispensables à l’échelle : ils permettent le filtrage, l’agrégation et la corrélation sans fragiles expressions régulières.
La stack ELK offre la recherche la plus riche mais son coût opérationnel (mémoire, ILM) est élevé ; Loki est l’alternative économique pour les équipes centrées sur Grafana.
Fluent Bit est le collecteur de référence pour Kubernetes grâce à son empreinte mémoire minimale (~1 MB) ; il remplace avantageusement Fluentd dans les DaemonSets.
OpenTelemetry unifie logs, métriques et traces sous un seul SDK et un seul protocole (OTLP), réduisant la dette d’instrumentation et facilitant la migration entre backends.
Une trace distribuée se compose de spans formant un arbre ; le
trace_idest propagé entre services via le header W3Ctraceparent.Jaeger convient aux équipes qui ont déjà Elasticsearch ; Grafana Tempo est plus économique grâce à son stockage sur object store sans index.
La corrélation logs-traces-métriques (trace ID dans les logs, exemplars Prometheus) transforme le débogage : on passe d’une alerte à la trace incriminée en un clic.
Le tail-based sampling permet de conserver 100% des traces d’erreurs et lentes tout en ne stockant qu’1-5% des traces nominales, maîtrisant ainsi le coût de l’observabilité.
La rétention doit être stratifiée : hot (7-30 j), warm (30-90 j), cold (1-7 ans) selon les SLA de consultation et les obligations réglementaires.
L’adoption d’OTel comme couche d’instrumentation unique découple le code applicatif des backends d’observabilité, évitant le vendor lock-in.