Chapitre 16 — Prometheus et Grafana#
L’observabilité d’un système de production repose sur trois piliers : métriques, logs et traces. Prometheus est devenu le standard de facto pour la collecte et le stockage des métriques, et Grafana pour leur visualisation. Ce chapitre couvre leur architecture, leur langage de requête, et leur intégration dans un cluster Kubernetes.
Architecture Prometheus#
Prometheus adopte un modèle pull : il interroge activement les cibles (targets) à intervalles réguliers plutôt que de recevoir des métriques poussées. Ce choix architectural a des conséquences importantes.
Composants principaux :
Prometheus Server : collecte (scrape), stockage dans une TSDB (Time Series Database) locale, évaluation des règles et alertes
Service Discovery : découverte dynamique des cibles via Kubernetes, Consul, EC2, fichiers statiques, etc.
Pushgateway : passerelle pour les jobs batch éphémères qui ne peuvent pas être scrappés
Alertmanager : routage, déduplication et envoi des alertes
Client libraries : instrumentation du code applicatif (Go, Java, Python, Ruby, Node.js, Rust…)
Modèle pull :
Prometheus contrôle la fréquence de scrape (typiquement 15–30 s)
Les cibles exposent un endpoint
/metricsen texte simpleAvantages : détection facile des cibles tombées (scrape échoue), contrôle centralisé de la configuration
Limite : difficile pour les jobs batch très courts → Pushgateway
TSDB de Prometheus
La TSDB de Prometheus stocke les données par blocs de 2 heures sur disque. Chaque série temporelle est identifiée par son nom de métrique et ses labels. La rétention par défaut est 15 jours. Au-delà, il faut un système de stockage distant (Thanos, Mimir, Cortex) via le protocole remote_write.
Types de métriques#
Prometheus définit quatre types de métriques, chacun adapté à un use case précis.
Counter — valeur qui ne fait que croître (remise à zéro uniquement au redémarrage) :
Nombre de requêtes HTTP reçues
Nombre d’erreurs
Octets transmis
Usage :
rate()ouincrease()sur un counter pour obtenir un débit
Gauge — valeur qui peut monter et descendre :
Utilisation CPU, mémoire utilisée
Nombre de goroutines actives
Température
Usage : valeur directe,
min_over_time(),max_over_time()
Histogram — échantillonne des observations dans des buckets prédéfinis :
Distribue les latences dans des buckets (
le="0.1",le="0.5",le="1", etc.)Expose
_bucket{},_sum,_countUsage :
histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[5m]))pour le P99
Summary — calcule des quantiles côté client :
Plus précis que l’histogram pour les quantiles, mais pas agrégeable entre instances
Déprécié au profit de l’histogram dans les nouvelles applications
Histogram vs Summary
Préférer l”histogram dans presque tous les cas. Il permet l’agrégation entre instances (sum() sur les buckets) et le calcul de percentiles côté serveur avec histogram_quantile(). Les Summary calculent les quantiles côté client, ce qui les rend non-agrégeables : si vous avez 10 instances, vous ne pouvez pas calculer le P99 global depuis les P99 individuels.
Exposition des métriques#
Le format texte Prometheus est simple et lisible :
# HELP http_requests_total Nombre total de requêtes HTTP
# TYPE http_requests_total counter
http_requests_total{method="GET",status="200",handler="/api/users"} 1234567
http_requests_total{method="POST",status="201",handler="/api/users"} 45678
http_requests_total{method="GET",status="500",handler="/api/users"} 123
# HELP http_request_duration_seconds Latence des requêtes HTTP
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.005"} 24054
http_request_duration_seconds_bucket{le="0.01"} 33444
http_request_duration_seconds_bucket{le="0.1"} 100392
http_request_duration_seconds_bucket{le="0.5"} 129389
http_request_duration_seconds_bucket{le="1"} 133988
http_request_duration_seconds_bucket{le="+Inf"} 144320
http_request_duration_seconds_sum 53423.147
http_request_duration_seconds_count 144320
# HELP go_goroutines Nombre de goroutines actives
# TYPE go_goroutines gauge
go_goroutines 42
Chaque ligne non-commentée est nom_métrique{label1="v1",label2="v2"} valeur [timestamp].
PromQL — le langage de requête#
PromQL est un langage fonctionnel orienté séries temporelles. Ses abstractions clés :
Sélecteurs instantanés :
# Toutes les séries nommées http_requests_total
http_requests_total
# Filtre sur labels (égalité, regexp, négation)
http_requests_total{status="500"}
http_requests_total{status=~"5.."}
http_requests_total{handler!="/healthz"}
Sélecteurs en plage (range vectors) :
# Valeurs des 5 dernières minutes — utilisé avec les fonctions
http_requests_total[5m]
Fonctions essentielles :
# Taux de requêtes par seconde (sur les 5 dernières minutes)
rate(http_requests_total[5m])
# Augmentation absolue sur la fenêtre
increase(http_requests_total[1h])
# Percentile 99 de latence
histogram_quantile(0.99,
sum(rate(http_request_duration_seconds_bucket[5m])) by (le)
)
# Top 5 des handlers les plus lents
topk(5, histogram_quantile(0.99,
sum(rate(http_request_duration_seconds_bucket[5m])) by (le, handler)
))
# Détecter l'absence d'une métrique (service down)
absent(up{job="api"})
# Agrégation multi-instances
sum(rate(http_requests_total{status=~"5.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
Recording rules — pré-calcul pour les dashboards lourds :
groups:
- name: slo_rules
interval: 1m
rules:
- record: job:http_requests_total:rate5m
expr: sum(rate(http_requests_total[5m])) by (job)
- record: job:http_error_rate:rate5m
expr: |
sum(rate(http_requests_total{status=~"5.."}[5m])) by (job)
/
sum(rate(http_requests_total[5m])) by (job)
Alertmanager#
L’Alertmanager reçoit les alertes de Prometheus et les route vers les bons destinataires avec déduplication et groupement.
# alertmanager.yml
global:
resolve_timeout: 5m
slack_api_url: "${SLACK_WEBHOOK_URL}"
route:
group_by: ["alertname", "cluster", "service"]
group_wait: 30s # Attendre avant d'envoyer (regrouper les alertes)
group_interval: 5m # Délai entre envois pour le même groupe
repeat_interval: 4h # Répéter si non résolue
receiver: "default"
routes:
- match:
severity: critical
receiver: "pagerduty"
continue: false
- match:
severity: warning
receiver: "slack-warnings"
receivers:
- name: "default"
slack_configs:
- channel: "#alerts"
title: "{{ .GroupLabels.alertname }}"
text: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
- name: "pagerduty"
pagerduty_configs:
- service_key: "${PAGERDUTY_KEY}"
description: "{{ .GroupLabels.alertname }}: {{ .CommonAnnotations.summary }}"
- name: "slack-warnings"
slack_configs:
- channel: "#alerts-warning"
send_resolved: true
inhibit_rules:
# Si une alerte "critical" est active, inhiber les "warning" du même service
- source_match:
severity: "critical"
target_match:
severity: "warning"
equal: ["alertname", "service"]
Règles d’alerte Prometheus :
groups:
- name: slo_alerts
rules:
- alert: HighErrorRate
expr: |
(
sum(rate(http_requests_total{status=~"5.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
) > 0.01
for: 5m
labels:
severity: warning
annotations:
summary: "Taux d'erreur élevé pour {{ $labels.service }}"
description: "Le service {{ $labels.service }} a un taux d'erreur de {{ $value | humanizePercentage }}"
- alert: SLOBurnRateFast
expr: |
(
sum(rate(http_requests_total{status=~"5.."}[1h])) by (service)
/
sum(rate(http_requests_total[1h])) by (service)
) > (14.4 * 0.001)
for: 2m
labels:
severity: critical
annotations:
summary: "Fast burn rate SLO — {{ $labels.service }}"
description: "Le budget mensuel sera épuisé en moins de 2h si ce rythme se maintient"
Grafana — visualisation et dashboards#
Grafana se connecte à Prometheus comme datasource et permet de construire des dashboards riches.
Types de panels clés :
Time series : courbes temporelles, idéal pour
rate(),gaugeStat : valeur unique avec tendance, idéal pour le SLO courant en pourcentage
Gauge : jauge circulaire, idéal pour l’error budget restant (0–100 %)
Table : requêtes PromQL tabulaires, idéal pour comparer des services
Heatmap : distribution des latences dans le temps via les histograms
Variables de dashboard : permettent de filtrer par cluster, namespace, service — transformant un dashboard générique en outil de drill-down interactif.
Annotations : marquent les événements sur les graphes (déploiements, incidents) via l’API Grafana ou une datasource Prometheus. Indispensable pour corréler les métriques avec les changements.
Exemplars — lien métriques → traces#
Les exemplars (OpenMetrics / Prometheus 2.26+) enrichissent les métriques d’histogram avec des pointeurs vers des traces individuelles.
http_request_duration_seconds_bucket{le="0.5"} 129389 # {traceID="abc123"} 0.321 1680000000
Dans Grafana, un click sur un point du graphe de latence P99 ouvre directement la trace Jaeger/Tempo correspondante. C’est le chaînon manquant entre métriques agrégées et traces distribuées individuelles.
Prometheus Operator et kube-prometheus-stack#
En environnement Kubernetes, le Prometheus Operator simplifie le déploiement et la configuration de Prometheus via des CRDs.
CRDs introduites :
Prometheus : déclare une instance Prometheus avec ses paramètres (rétention, réplicas, storage)
ServiceMonitor : sélectionne automatiquement les Services Kubernetes à scraper
PodMonitor : scrape directement les pods sans Service
PrometheusRule : déclare des règles d’alerte et recording rules
AlertmanagerConfig : configure des routes et receivers Alertmanager
# ServiceMonitor — scraper automatiquement tous les Services avec le label app=api
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: api-monitor
namespace: monitoring
spec:
selector:
matchLabels:
app: api
namespaceSelector:
matchNames:
- production
endpoints:
- port: metrics
interval: 15s
path: /metrics
# PrometheusRule — alerte via l'Operator
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: api-slo-rules
namespace: monitoring
labels:
prometheus: kube-prometheus
role: alert-rules
spec:
groups:
- name: api.slo
rules:
- alert: APIHighLatency
expr: histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket{job="api"}[5m])) by (le)) > 0.5
for: 10m
labels:
severity: warning
annotations:
summary: "P99 latence API > 500ms"
Installation de kube-prometheus-stack :
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
--set grafana.adminPassword=secret \
--set prometheus.prometheusSpec.retention=30d \
--set prometheus.prometheusSpec.storageSpec.volumeClaimTemplate.spec.resources.requests.storage=50Gi
Cet unique chart déploie Prometheus, Alertmanager, Grafana, node-exporter, kube-state-metrics et tous les dashboards Kubernetes pré-configurés.
Remote write et scalabilité long terme#
La TSDB locale de Prometheus est limitée à un seul nœud. Pour la rétention longue durée et la haute disponibilité, remote_write envoie les données vers un système externe.
# prometheus.yml — remote write vers Mimir ou Thanos
remote_write:
- url: https://mimir.example.com/api/v1/push
headers:
X-Scope-OrgID: my-tenant
queue_config:
max_samples_per_send: 5000
max_shards: 30
capacity: 2500
Comparaison des solutions :
Thanos : overlay sur Prometheus, stockage objet (S3/GCS), queries globales multi-cluster
Cortex : service multi-tenant, idéal pour les hébergeurs (Grafana Cloud utilise une version dérivée)
Mimir (Grafana Labs) : successeur de Cortex, meilleure performance, recommandé pour les nouveaux déploiements
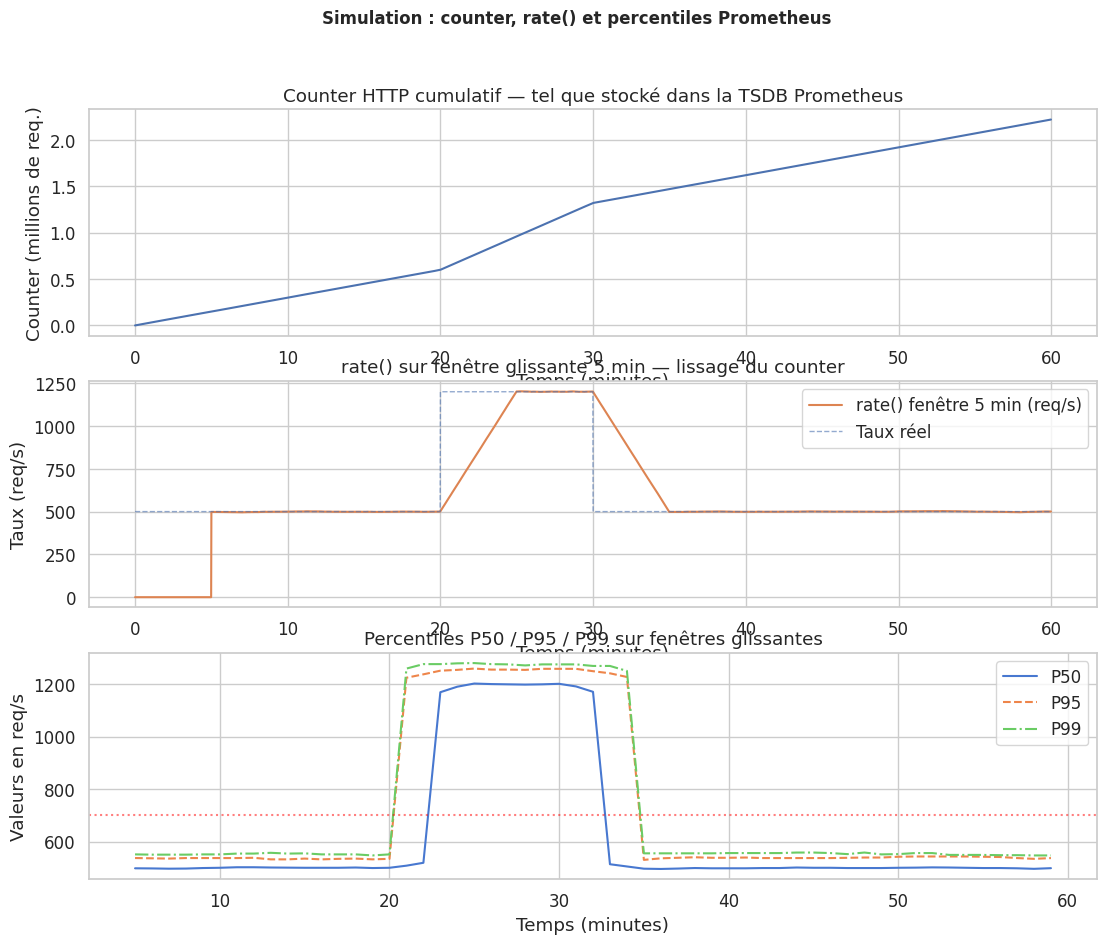
Simulation : séries temporelles et calcul de rate()#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
# Simulation d'un counter de requêtes HTTP sur 1 heure (3600 scrapes à 1s)
duration_s = 3600
t = np.arange(duration_s)
# Taux de base : 500 req/s, pic à mi-parcours
base_rate = 500
peak_rate = 1200
spike_duration = 600 # 10 min de pic
rate_true = np.where(
(t >= 1200) & (t < 1200 + spike_duration), peak_rate, base_rate
)
# Bruit de Poisson
rate_noisy = np.random.poisson(rate_true)
# Counter cumulatif (comme Prometheus le stocke)
counter = np.cumsum(rate_noisy)
# Calcul de rate() sur une fenêtre glissante de 5 min (300 s)
# rate() = (valeur_fin - valeur_debut) / durée_fenêtre
window = 300
rate_computed = np.zeros(duration_s)
for i in range(window, duration_s):
rate_computed[i] = (counter[i] - counter[i - window]) / window
# Percentiles sur fenêtres glissantes de 5 min
p50 = []
p95 = []
p99 = []
step = 60 # calculer toutes les minutes
t_perc = []
for i in range(window, duration_s, step):
window_rates = rate_noisy[i - window:i]
p50.append(np.percentile(window_rates, 50))
p95.append(np.percentile(window_rates, 95))
p99.append(np.percentile(window_rates, 99))
t_perc.append(i / 60)
t_min = t / 60
fig, axes = plt.subplots(3, 1, figsize=(13, 10), sharex=False)
# Graphe 1 : Counter brut
ax1 = axes[0]
ax1.plot(t_min, counter / 1e6, linewidth=1.5, color="#4C72B0")
ax1.set_ylabel("Counter (millions de req.)")
ax1.set_title("Counter HTTP cumulatif — tel que stocké dans la TSDB Prometheus")
ax1.set_xlabel("Temps (minutes)")
# Graphe 2 : rate() calculé
ax2 = axes[1]
ax2.plot(t_min, rate_computed, linewidth=1.5, color="#DD8452",
label="rate() fenêtre 5 min (req/s)")
ax2.plot(t_min, rate_true, linewidth=1, color="#4C72B0", linestyle="--",
alpha=0.6, label="Taux réel")
ax2.set_ylabel("Taux (req/s)")
ax2.set_title("rate() sur fenêtre glissante 5 min — lissage du counter")
ax2.set_xlabel("Temps (minutes)")
ax2.legend()
# Graphe 3 : percentiles (comme histogram_quantile)
ax3 = axes[2]
ax3.plot(t_perc, p50, label="P50", linewidth=1.5)
ax3.plot(t_perc, p95, label="P95", linewidth=1.5, linestyle="--")
ax3.plot(t_perc, p99, label="P99", linewidth=1.5, linestyle="-.")
ax3.axhline(y=700, color="red", linestyle=":", alpha=0.5)
ax3.annotate("SLO taux max 700 req/s", xy=(2, 710), color="red", fontsize=8)
ax3.set_ylabel("Valeurs en req/s")
ax3.set_title("Percentiles P50 / P95 / P99 sur fenêtres glissantes")
ax3.set_xlabel("Temps (minutes)")
ax3.legend()
plt.suptitle("Simulation : counter, rate() et percentiles Prometheus", fontsize=12, fontweight="bold")
plt.show()
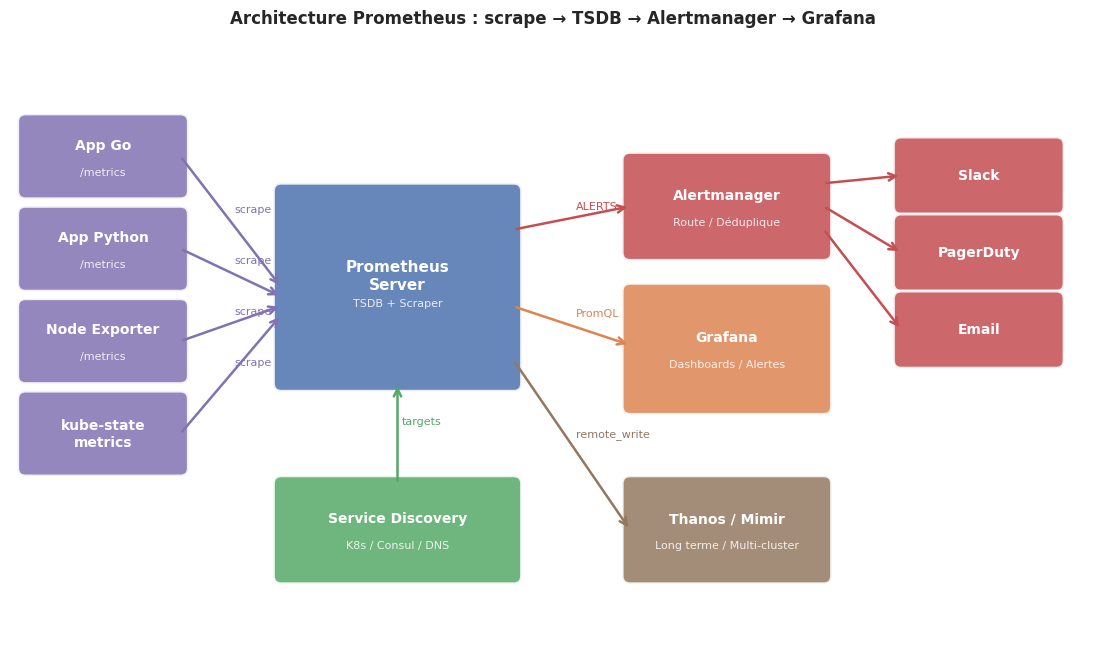
Visualisation de l’architecture Prometheus#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from matplotlib.patches import FancyBboxPatch
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(14, 8))
ax.set_xlim(0, 14)
ax.set_ylim(0, 8)
ax.axis("off")
def box(ax, x, y, w, h, label, sublabel="", color="#4C72B0", fontsize=10):
patch = FancyBboxPatch((x, y), w, h,
boxstyle="round,pad=0.1",
facecolor=color, edgecolor="white",
linewidth=2, alpha=0.85)
ax.add_patch(patch)
ax.text(x + w / 2, y + h / 2 + (0.15 if sublabel else 0),
label, ha="center", va="center",
fontsize=fontsize, fontweight="bold", color="white")
if sublabel:
ax.text(x + w / 2, y + h / 2 - 0.2, sublabel,
ha="center", va="center", fontsize=8, color="white", alpha=0.85)
def arrow(ax, x1, y1, x2, y2, label="", color="#555555"):
ax.annotate("", xy=(x2, y2), xytext=(x1, y1),
arrowprops=dict(arrowstyle="->", color=color, lw=1.8))
if label:
mx, my = (x1 + x2) / 2, (y1 + y2) / 2
ax.text(mx + 0.05, my + 0.12, label, fontsize=8, color=color)
# --- Sources (targets) ---
box(ax, 0.2, 6.0, 2.0, 0.9, "App Go", "/metrics", "#8172B2")
box(ax, 0.2, 4.8, 2.0, 0.9, "App Python", "/metrics", "#8172B2")
box(ax, 0.2, 3.6, 2.0, 0.9, "Node Exporter", "/metrics", "#8172B2")
box(ax, 0.2, 2.4, 2.0, 0.9, "kube-state\nmetrics", "", "#8172B2")
# --- Prometheus ---
box(ax, 3.5, 3.5, 3.0, 2.5, "Prometheus\nServer", "TSDB + Scraper", "#4C72B0", fontsize=11)
# --- Service Discovery ---
box(ax, 3.5, 1.0, 3.0, 1.2, "Service Discovery", "K8s / Consul / DNS", "#55A868")
# --- Alertmanager ---
box(ax, 8.0, 5.2, 2.5, 1.2, "Alertmanager", "Route / Déduplique", "#C44E52")
# --- Grafana ---
box(ax, 8.0, 3.2, 2.5, 1.5, "Grafana", "Dashboards / Alertes", "#DD8452")
# --- Remote Write ---
box(ax, 8.0, 1.0, 2.5, 1.2, "Thanos / Mimir", "Long terme / Multi-cluster", "#937860")
# --- Receivers ---
box(ax, 11.5, 5.8, 2.0, 0.8, "Slack", "", "#C44E52")
box(ax, 11.5, 4.8, 2.0, 0.8, "PagerDuty", "", "#C44E52")
box(ax, 11.5, 3.8, 2.0, 0.8, "Email", "", "#C44E52")
# Scrape arrows (targets → Prometheus)
for y_target in [6.45, 5.25, 4.05, 2.85]:
arrow(ax, 2.2, y_target, 3.5, 4.75 - (6.45 - y_target) * 0.1, "scrape", "#8172B2")
# SD → Prometheus
arrow(ax, 5.0, 2.2, 5.0, 3.5, "targets", "#55A868")
# Prometheus → Alertmanager
arrow(ax, 6.5, 5.5, 8.0, 5.8, "ALERTS", "#C44E52")
# Prometheus → Grafana
arrow(ax, 6.5, 4.5, 8.0, 4.0, "PromQL", "#DD8452")
# Prometheus → Remote Write
arrow(ax, 6.5, 3.8, 8.0, 1.6, "remote_write", "#937860")
# Alertmanager → receivers
arrow(ax, 10.5, 6.1, 11.5, 6.2, "", "#C44E52")
arrow(ax, 10.5, 5.8, 11.5, 5.2, "", "#C44E52")
arrow(ax, 10.5, 5.5, 11.5, 4.2, "", "#C44E52")
ax.set_title("Architecture Prometheus : scrape → TSDB → Alertmanager → Grafana",
fontsize=12, fontweight="bold", pad=10)
plt.show()
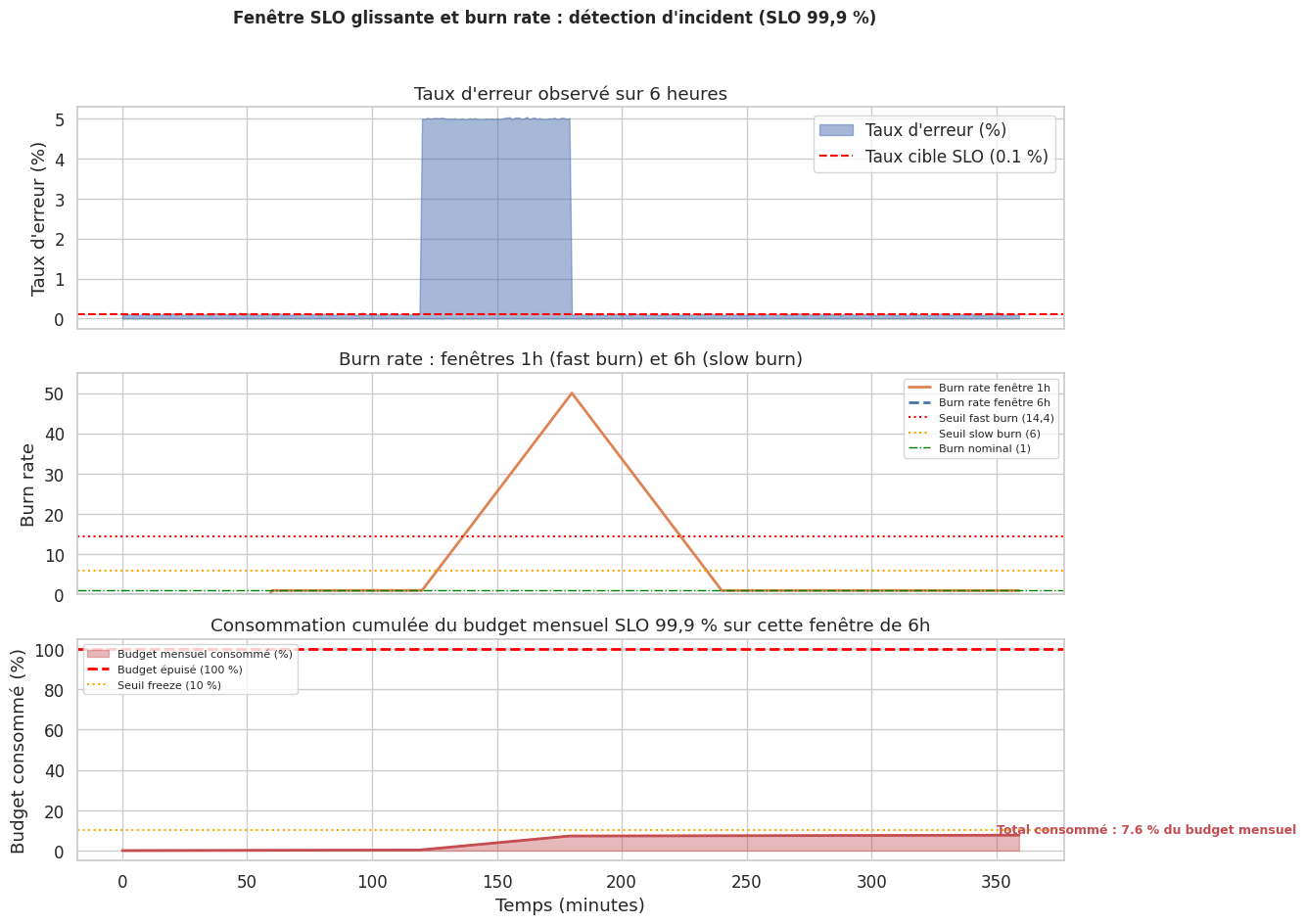
Simulation d’une fenêtre SLO glissante et burn rate#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(7)
# Simulation sur 6 heures (en minutes)
duration_min = 360
t = np.arange(duration_min)
# Taux d'erreur base + incident entre min 120 et 180
error_rate_base = 0.001 # 0,1 % en régime normal
error_rate = np.where(
(t >= 120) & (t < 180), 0.05, # 5 % d'erreurs pendant 1h
error_rate_base
) + np.random.normal(0, 0.0002, duration_min).clip(-0.0002, 0.001)
error_rate = error_rate.clip(0, 1)
slo_target = 0.999
budget_rate = 1 - slo_target # 0.001
# Burn rate sur fenêtre glissante 1h et 6h (en minutes)
def rolling_burn_rate(error_rate, window_min):
br = np.zeros(len(error_rate))
for i in range(window_min, len(error_rate)):
avg_error = error_rate[i - window_min:i].mean()
br[i] = avg_error / budget_rate
return br
br_1h = rolling_burn_rate(error_rate, 60)
br_6h = rolling_burn_rate(error_rate, 360)
# Error budget consommé (cumul en % du budget mensuel)
minutes_per_month = 30 * 24 * 60
budget_total_min = minutes_per_month * budget_rate
# Chaque minute avec des erreurs consomme error_rate[t] minutes de budget
budget_consumed_pct = np.cumsum(error_rate) / budget_total_min * 100
fig, axes = plt.subplots(3, 1, figsize=(13, 10), sharex=True)
# Graphe 1 : taux d'erreur
ax1 = axes[0]
ax1.fill_between(t, error_rate * 100, alpha=0.5, color="#4C72B0", label="Taux d'erreur (%)")
ax1.axhline(y=budget_rate * 100,
color="red", linestyle="--", linewidth=1.5, label=f"Taux cible SLO ({budget_rate*100:.1f} %)")
ax1.set_ylabel("Taux d'erreur (%)")
ax1.set_title("Taux d'erreur observé sur 6 heures")
ax1.legend(loc="upper right")
# Graphe 2 : burn rate
ax2 = axes[1]
ax2.plot(t, br_1h, linewidth=2, label="Burn rate fenêtre 1h", color="#DD8452")
ax2.plot(t, br_6h, linewidth=2, label="Burn rate fenêtre 6h", color="#4C72B0", linestyle="--")
ax2.axhline(y=14.4, color="red", linestyle=":", linewidth=1.5, label="Seuil fast burn (14,4)")
ax2.axhline(y=6, color="orange", linestyle=":", linewidth=1.5, label="Seuil slow burn (6)")
ax2.axhline(y=1, color="green", linestyle="-.", linewidth=1, label="Burn nominal (1)")
ax2.set_ylim(0, max(br_1h.max() * 1.1, 20))
ax2.set_ylabel("Burn rate")
ax2.set_title("Burn rate : fenêtres 1h (fast burn) et 6h (slow burn)")
ax2.legend(loc="upper right", fontsize=8)
# Graphe 3 : budget consommé
ax3 = axes[2]
ax3.fill_between(t, budget_consumed_pct, alpha=0.4, color="#C44E52",
label="Budget mensuel consommé (%)")
ax3.plot(t, budget_consumed_pct, color="#C44E52", linewidth=2)
ax3.axhline(y=100, color="red", linestyle="--", linewidth=2, label="Budget épuisé (100 %)")
ax3.axhline(y=10, color="orange", linestyle=":", linewidth=1.5, label="Seuil freeze (10 %)")
ax3.set_xlabel("Temps (minutes)")
ax3.set_ylabel("Budget consommé (%)")
ax3.set_title("Consommation cumulée du budget mensuel SLO 99,9 % sur cette fenêtre de 6h")
ax3.legend(loc="upper left", fontsize=8)
ax3.annotate(f"Total consommé : {budget_consumed_pct[-1]:.1f} % du budget mensuel",
xy=(350, budget_consumed_pct[-1] + 1),
fontsize=9, color="#C44E52", fontweight="bold")
plt.suptitle("Fenêtre SLO glissante et burn rate : détection d'incident (SLO 99,9 %)",
fontsize=12, fontweight="bold")
plt.show()
Résumé#
Prometheus adopte un modèle pull : il scrape les cibles à intervalles réguliers, ce qui simplifie la détection des services tombés et centralise la configuration.
Les quatre types de métriques (Counter, Gauge, Histogram, Summary) couvrent tous les use cases ; le Histogram est préféré au Summary car ses buckets sont agrégeables entre instances.
L’endpoint
/metricsexpose les métriques dans un format texte simple lisible par un humain et par Prometheus — chaque ligne est une série temporelle avec ses labels.PromQL est un langage fonctionnel puissant :
rate()transforme un counter en débit,histogram_quantile()calcule des percentiles côté serveur,absent()détecte les métriques manquantes.Les recording rules pré-calculent des expressions PromQL coûteuses pour accélérer les dashboards Grafana et réduire la charge sur Prometheus.
L”Alertmanager centralise le routage, la déduplication, le groupement et l’inhibition des alertes — une alerte critique peut inhiber les alertes warning du même service.
Grafana consomme Prometheus via PromQL et offre variables de dashboard, annotations d’événements et alertes visuelles — les exemplars relient les métriques aux traces individuelles.
Le Prometheus Operator gère Prometheus en Kubernetes via des CRDs (ServiceMonitor, PrometheusRule) — le chart
kube-prometheus-stackdéploie l’ensemble de la stack en une commande.remote_writevers Thanos, Cortex ou Mimir étend la rétention au-delà des 15 jours locaux et permet des requêtes globales multi-cluster.Le burn rate alerting à deux vitesses (fast burn 1h, slow burn 6h) détecte à la fois les pannes franches et les dégradations lentes — deux signaux complémentaires indispensables pour respecter un SLO 99,9 %.