Chapitre 1 — Culture DevOps et métriques DORA#
Le mouvement DevOps n’est pas un outil ni une certification : c’est une transformation culturelle qui brise la frontière entre les équipes qui construisent le logiciel et celles qui l’opèrent. Ce chapitre pose les fondements conceptuels — les métriques objectives qui mesurent la performance, les modèles de branching qui structurent le flux de travail, et le modèle de maturité qui guide la progression.
Objectifs du chapitre
À l’issue de ce chapitre, vous saurez interpréter les quatre métriques DORA, positionner votre organisation dans un profil de performance, choisir une stratégie de branching adaptée, et comprendre pourquoi la sécurité doit être intégrée dès le début du pipeline.
— Les quatre métriques DORA#
Le programme DORA (DevOps Research and Assessment), fondé par le Dr Nicole Forsgren, Gene Kim et Jez Humble, a analysé plus de 33 000 professionnels sur six ans. Il en résulte quatre métriques qui distinguent statistiquement les organisations performantes des autres.
Deployment Frequency (fréquence de déploiement)#
Combien de fois l’équipe déploie-t-elle en production ? C’est l’indicateur le plus direct de la taille des lots. Les équipes d’élite déploient plusieurs fois par jour ; les équipes faibles déploient une fois par mois ou moins. Des lots petits impliquent des risques faibles, des retours rapides, et une confiance accrue.
Lead Time for Changes (délai de mise en production)#
Temps entre le premier commit et le déploiement en production. Les équipes d’élite atteignent moins d’une heure ; les équipes faibles, plus de six mois. Ce délai capture la friction totale du système : revues lentes, pipelines cassés, processus manuels.
Mean Time To Restore — MTTR (temps moyen de rétablissement)#
Durée pour restaurer le service après un incident. Les équipes d’élite réparent en moins d’une heure ; les équipes faibles mettent plus d’une semaine. Ce chiffre reflète directement la qualité de l’observabilité, des runbooks et de la culture d’incident.
Change Failure Rate (taux d’échec des changements)#
Pourcentage des déploiements qui causent un incident nécessitant un correctif ou un rollback. Les équipes d’élite maintiennent 0–5 % ; les équipes faibles atteignent 46–60 %. Paradoxalement, déployer plus souvent réduit ce taux — chaque déploiement est plus petit et donc moins risqué.
Piège fréquent
La Change Failure Rate ne mesure pas la qualité du code — elle mesure la qualité du processus de livraison. Une équipe peut avoir un code excellent mais un CFR élevé à cause de tests d’intégration insuffisants ou d’environnements non représentatifs.
Valeurs de référence par profil#
Profil |
Deploy Freq |
Lead Time |
MTTR |
CFR |
|---|---|---|---|---|
Élite |
Plusieurs/jour |
< 1 heure |
< 1 heure |
0–5 % |
Haute |
1/jour à 1/semaine |
1 jour à 1 semaine |
< 1 jour |
5–10 % |
Moyenne |
1/semaine à 1/mois |
1 semaine à 1 mois |
1 jour à 1 semaine |
10–15 % |
Faible |
< 1/mois |
1 à 6 mois |
> 1 semaine |
46–60 % |
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import pandas as pd
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Radar chart DORA : 4 profils x 4 métriques
# Normalisation : score 0-10, 10 = performance maximale (élite)
categories = ["Fréquence\ndéploiement", "Lead Time\n(inversé)", "MTTR\n(inversé)", "CFR\n(inversé)"]
N = len(categories)
# Scores normalisés (10 = élite, 1 = faible)
profiles = {
"Élite": [10, 10, 10, 10],
"Haute": [7, 7, 8, 8],
"Moyenne": [4, 4, 5, 6],
"Faible": [1, 1, 2, 2],
}
colors = ["#2ecc71", "#3498db", "#f39c12", "#e74c3c"]
angles = [n / float(N) * 2 * np.pi for n in range(N)]
angles += angles[:1]
fig, ax = plt.subplots(figsize=(7, 7), subplot_kw=dict(polar=True))
for (label, values), color in zip(profiles.items(), colors):
vals = values + values[:1]
ax.plot(angles, vals, linewidth=2, linestyle="solid", label=label, color=color)
ax.fill(angles, vals, alpha=0.12, color=color)
ax.set_theta_offset(np.pi / 2)
ax.set_theta_direction(-1)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=11)
ax.set_ylim(0, 10)
ax.set_yticks([2, 4, 6, 8, 10])
ax.set_yticklabels(["2", "4", "6", "8", "10"], fontsize=8, color="grey")
ax.set_title("Profils DORA — performance relative par métrique", fontsize=13, pad=20, fontweight="bold")
ax.legend(loc="upper right", bbox_to_anchor=(1.35, 1.1), fontsize=10)
plt.show()
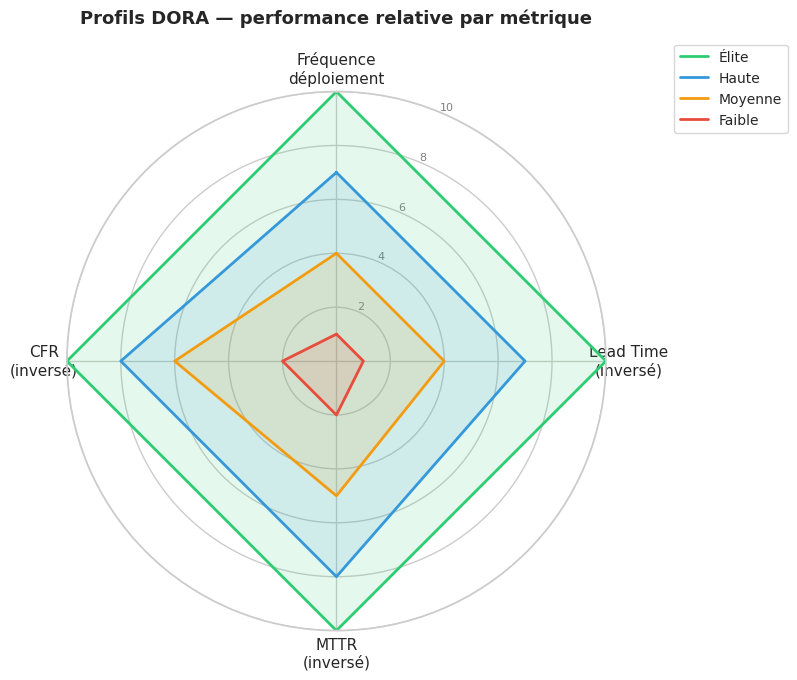
Le graphe radar illustre l’écart considérable entre les profils. Un profil Élite domine sur toutes les dimensions simultanément — ce n’est pas un compromis, c’est le résultat d’une amélioration systémique du flux de travail.
— Stratégies de branching#
Le choix d’une stratégie de branching est l’une des décisions d’ingénierie les plus structurantes. Elle détermine la fréquence d’intégration, la complexité des merges, et la vitesse de livraison.
Trunk-based Development#
Une seule branche principale (main / trunk). Les développeurs commitent directement ou via des branches de très courte durée (moins de 24 heures). Les feature flags permettent de livrer du code incomplet sans l’activer. C’est la stratégie des équipes d’élite DORA.
Avantages : intégration continue réelle, pas de merge hell, feedback immédiat. Prérequis : suite de tests solide, feature flags, revues asynchrones ou pair programming.
GitHub Flow#
Deux niveaux : main + branches de feature. Chaque feature branch crée une Pull Request ; après approbation et CI vert, merge dans main. Simple et efficace pour les équipes de taille moyenne.
Avantages : traçabilité des changements, processus de revue clair. Limites : si les branches vivent plusieurs semaines, les merges deviennent pénibles.
Gitflow#
Modèle complet : main, develop, branches feature/, release/, hotfix/. Conçu pour des logiciels avec des cycles de release définis (SaaS enterprise, librairies versionnées).
Avantages : isolation claire des environnements, gestion fine des hotfixes. Limites : complexité élevée, intégration retardée, incompatible avec le déploiement continu.
Feature Branches longue durée#
Anti-pattern courant : des branches qui vivent des semaines. Le coût de merge explose de façon non linéaire avec la durée. À éviter sauf contrainte absolue.
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
strategies = ["Trunk-based\nDevelopment", "GitHub Flow", "GitFlow", "Feature Branches\nlongue durée"]
complexite = [1, 3, 8, 7]
velocite = [10, 7, 4, 3]
x = np.arange(len(strategies))
width = 0.35
fig, ax = plt.subplots(figsize=(9, 5))
bars1 = ax.bar(x - width/2, complexite, width, label="Complexité (1=simple, 10=complexe)",
color="#e74c3c", alpha=0.82, edgecolor="white")
bars2 = ax.bar(x + width/2, velocite, width, label="Vélocité de livraison (1=lente, 10=rapide)",
color="#2ecc71", alpha=0.82, edgecolor="white")
ax.set_xticks(x)
ax.set_xticklabels(strategies, fontsize=10)
ax.set_ylabel("Score (1–10)", fontsize=11)
ax.set_title("Stratégies de branching — complexité vs vélocité", fontsize=13, fontweight="bold")
ax.set_ylim(0, 12)
ax.legend(fontsize=9)
for bar in bars1:
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.2,
str(int(bar.get_height())), ha="center", va="bottom", fontsize=9, color="#c0392b", fontweight="bold")
for bar in bars2:
ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.2,
str(int(bar.get_height())), ha="center", va="bottom", fontsize=9, color="#27ae60", fontweight="bold")
plt.show()

Le Trunk-based Development inverse la logique intuitive : moins de complexité de branching produit plus de vélocité, pas moins.
— Les trois manières du DevOps#
Gene Kim formule le DevOps en trois principes fondamentaux, appelés les Trois Manières (The Three Ways).
Première manière : le Flux#
Optimiser le flux de gauche à droite, du développement vers la production. Cela implique de rendre le travail visible (kanban, WIP limits), de réduire la taille des lots, et d’éliminer les transferts de responsabilité. Chaque étape du pipeline doit être aussi rapide que la précédente — un goulot d’étranglement en amont rend inutile toute optimisation en aval.
Deuxième manière : le Feedback#
Créer des boucles de feedback rapides et continues, de droite à gauche. Les métriques de production alimentent les décisions de développement. Les tests automatisés fournissent un signal immédiat. Les alertes détectent les régressions en minutes. Sans feedback rapide, les problèmes se découvrent trop tard pour être corrigés à faible coût.
Troisième manière : l’Apprentissage continu#
Créer une culture d’expérimentation et d’apprentissage. Les post-mortems sont blameless — l’objectif est de comprendre le système, pas de punir les individus. Les expériences en production (canary deployments, A/B tests, chaos engineering) sont des instruments de connaissance. L’échec est une information précieuse si et seulement si l’organisation sait en extraire des enseignements.
Post-mortem blameless
Un post-mortem efficace se concentre sur les causes systémiques, pas sur les erreurs individuelles. La question n’est pas « qui a fait l’erreur ? » mais « pourquoi le système a-t-il rendu cette erreur possible ? ». Les organisations qui pratiquent le blame voient leurs ingénieurs dissimuler les incidents — exactement l’inverse de l’apprentissage.
— DevSecOps : la sécurité dans le flux#
Le DevSecOps n’est pas un département ni un outil : c’est l’intégration de la sécurité dans le pipeline CI/CD, à chaque étape, plutôt qu’une vérification finale avant la mise en production.
Le problème du « bolt-on security »#
Dans le modèle traditionnel, la sécurité intervient en fin de cycle (pen tests, audits). Résultat : les vulnérabilités sont découvertes trop tard, les correctifs sont coûteux, et les équipes perçoivent la sécurité comme un obstacle. Le coût de correction d’une vulnérabilité en production est 30 à 100 fois supérieur à son coût de détection en phase de développement (NIST).
Les couches de sécurité dans le pipeline#
SAST (Static Application Security Testing) : analyse du code source à la recherche de patterns vulnérables (injections SQL, XSS, secrets codés en dur). Outils : Semgrep, Bandit (Python), SonarQube. S’exécute en quelques secondes, intégrable dès le pre-commit.
SCA (Software Composition Analysis) : analyse des dépendances tierces pour détecter les CVE connues. Outils : Dependabot, Snyk, OWASP Dependency Check. Critique depuis l’incident Log4Shell.
DAST (Dynamic Application Security Testing) : tests de sécurité sur une instance en cours d’exécution. Plus lent, réservé aux pipelines de staging. Outils : OWASP ZAP, Burp Suite.
Secrets scanning : détection des credentials accidentellement commités. Outils : GitLeaks, TruffleHog, GitHub Advanced Security. Doit s’exécuter en pre-commit ET dans le pipeline.
Container scanning : analyse des images Docker pour les vulnérabilités du système de base. Outils : Trivy, Grype, Clair.
Règle d’or DevSecOps
Chaque contrôle de sécurité doit fournir un résultat exploitable en moins de 5 minutes pour être intégré dans le flux de développement sans créer de friction. Au-delà, les développeurs contournent les contrôles.
— Modèle de maturité DevOps#
La transformation DevOps est un voyage progressif. Le modèle de maturité à cinq niveaux structure la progression sur cinq dimensions.
Niveaux :
Niveau 1 — Initial : processus manuels, siloes, déploiements chaotiques
Niveau 2 — Défini : quelques automatisations, processus documentés
Niveau 3 — Géré : CI/CD partiel, métriques collectées
Niveau 4 — Optimisé : pipeline complet, observabilité, retours rapides
Niveau 5 — Innovant : expérimentation continue, chaos engineering, AI Ops
Dimensions :
Culture & organisation
Processus & flux
Architecture & technique
Mesure & observabilité
Sécurité & conformité
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
dimensions = [
"Culture &\norganisation",
"Processus\n& flux",
"Architecture\n& technique",
"Mesure &\nobservabilité",
"Sécurité\n& conformité",
]
niveaux = ["Niveau 1\nInitial", "Niveau 2\nDéfini", "Niveau 3\nGéré", "Niveau 4\nOptimisé", "Niveau 5\nInnovant"]
# Scores de maturité typiques d'une organisation en transition (0-10)
data = np.array([
[9, 7, 5, 3, 1], # Culture
[8, 7, 6, 4, 2], # Processus
[9, 8, 6, 3, 2], # Architecture
[7, 6, 5, 4, 2], # Mesure
[8, 6, 4, 3, 1], # Sécurité
])
fig, ax = plt.subplots(figsize=(10, 5))
im = ax.imshow(data, cmap="RdYlGn", aspect="auto", vmin=0, vmax=10)
ax.set_xticks(range(len(niveaux)))
ax.set_xticklabels(niveaux, fontsize=10)
ax.set_yticks(range(len(dimensions)))
ax.set_yticklabels(dimensions, fontsize=10)
ax.set_title("Modèle de maturité DevOps — score par dimension et niveau", fontsize=13, fontweight="bold")
for i in range(len(dimensions)):
for j in range(len(niveaux)):
val = data[i, j]
color = "white" if val < 4 else "black"
ax.text(j, i, str(val), ha="center", va="center", fontsize=11, color=color, fontweight="bold")
cbar = fig.colorbar(im, ax=ax, shrink=0.8)
cbar.set_label("Score de maturité (0–10)", fontsize=10)
plt.show()
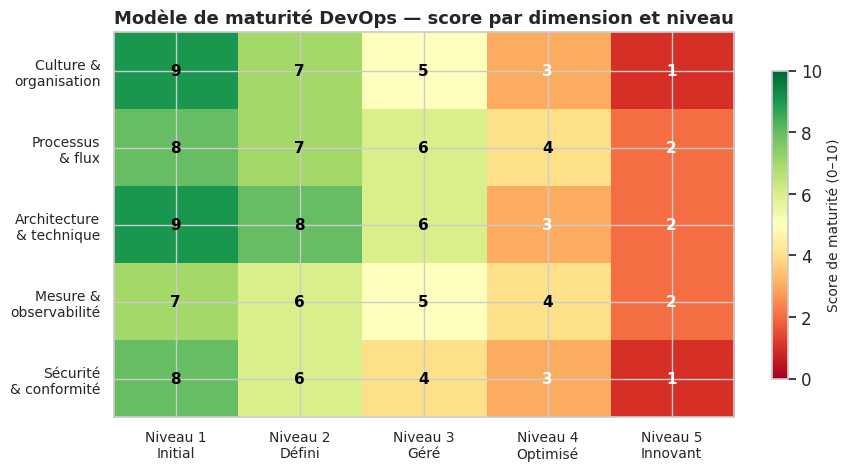
La heatmap illustre un pattern typique : la plupart des organisations maîtrisent les niveaux 1 et 2 mais stagnent aux niveaux 3 et 4. La dimension « Sécurité & conformité » est systématiquement en retard par rapport aux dimensions techniques — justifiant l’approche DevSecOps.
— Résumé#
Les métriques DORA sont les seuls indicateurs de performance DevOps validés empiriquement sur plus de 33 000 professionnels et six années de recherche.
Les quatre métriques (fréquence de déploiement, lead time, MTTR, CFR) mesurent conjointement la vitesse et la stabilité — elles ne sont pas en opposition.
Les équipes d’élite déploient plusieurs fois par jour avec 0 à 5 % de changements en échec — la vitesse et la fiabilité sont corrélées positivement.
Le Trunk-based Development est la stratégie de branching des équipes d’élite DORA ; Gitflow est associé aux profils de performance moyenne et faible.
La taille des lots est le levier le plus puissant : réduire la taille d’un déploiement réduit son risque, sa durée de test, et son délai de feedback.
Les Trois Manières du DevOps (Flux, Feedback, Apprentissage) forment un système cohérent — optimiser l’une sans les autres produit des résultats limités.
Le DevSecOps intègre la sécurité dans le pipeline dès la phase de développement ; le coût de correction d’une vulnérabilité en production est 30 à 100 fois supérieur à sa détection en développement.
SAST, SCA, DAST, secrets scanning et container scanning couvrent des surfaces d’attaque complémentaires et doivent tous être présents dans un pipeline mature.
Le modèle de maturité à cinq niveaux montre que la dimension « Sécurité & conformité » est systématiquement la plus en retard dans les transformations DevOps réelles.
Une culture blameless est un prérequis pour l’apprentissage continu : sans elle, les incidents sont dissimulés et le système ne peut pas s’améliorer.