Bonnes pratiques ops#
Documentation#
Pourquoi documenter#
La documentation est souvent perçue comme une corvée secondaire. En pratique, c’est une assurance collective : celui qui documente aujourd’hui se protège lui-même des appels à 3h du matin dans six mois.
Les trois formes essentielles de documentation opérationnelle sont :
Runbooks : procédures pas-à-pas pour les opérations courantes et les incidents. Ils permettent à un collègue moins expérimenté d’intervenir en autonomie.
Wikis : documentation de référence (architectures, décisions techniques, contacts, accès). Confluence, Notion, ou un simple dépôt git avec des fichiers Markdown conviennent.
README serveur : fichier
/etc/motdou/etc/READMEdécrivant le rôle du serveur, ses contacts, et ses services critiques. Visible à chaque connexion SSH.
Diagrammes d’architecture#
Un diagramme vaut mille commandes ifconfig. Les outils recommandés :
draw.io / diagrams.net : gratuit, stockage XML versionnable, intégré à Confluence.
Mermaid : diagrammes en Markdown, compatible GitLab/GitHub.
PlantUML : infrastructure as diagram, intégrable dans les wikis.
Documentation vivante
Une documentation jamais mise à jour est pire qu’une absence de documentation : elle induit en erreur. Intégrer la mise à jour de la documentation dans la définition de « terminé » pour toute modification d’infrastructure. Un changement non documenté n’est pas terminé.
README serveur automatisé#
# /etc/update-motd.d/10-readme (Debian/Ubuntu)
#!/bin/bash
echo "=== SERVEUR : $(hostname) ==="
echo "Rôle : Proxy inverse Nginx + Certbot"
echo "Contact : infra@example.com"
echo "Wiki : https://wiki.example.com/serveurs/$(hostname)"
echo "Dernière mise à jour infra : $(stat -c %y /etc/nginx/nginx.conf | cut -d' ' -f1)"
Gestion des changements#
Change management#
En production, tout changement doit être planifié, communiqué et réversible. Les étapes minimales d’un processus de changement :
Demande de changement (RFC) : description, motivation, impact estimé, plan de rollback.
Revue : validation par un pair ou un responsable.
Fenêtre de maintenance : plage horaire à faible trafic, communiquée aux parties prenantes.
Exécution : avec un observateur si l’impact est élevé.
Vérification : tests fonctionnels post-changement.
Documentation : mise à jour du wiki et du changelog.
Fenêtres de maintenance#
# Notifier les utilisateurs via /etc/motd
echo "MAINTENANCE PLANIFIÉE : dimanche 17/03 02h00-04h00 UTC" \
>> /etc/motd
# Supprimer après la maintenance
truncate -s 0 /etc/motd
Rollback#
Chaque changement doit avoir un plan de rollback défini avant l’exécution.
Configuration nginx :
cp /etc/nginx/nginx.conf{,.bak}avant toute modification.Paquets :
apt-mark hold <paquet>pour geler une version.Noyau : garder l’entrée GRUB précédente, tester avec
reboot+ surveillance.
Git pour /etc#
# Initialiser un dépôt git dans /etc
cd /etc
git init
git add .
git commit -m "État initial du serveur web01"
# Ou utiliser etckeeper (automatise les commits avant apt)
apt install etckeeper
etckeeper init
etckeeper crée automatiquement un commit avant chaque opération apt install ou apt upgrade, permettant de retrouver exactement quel paquet a modifié quel fichier de
configuration.
Post-mortems#
Culture blameless#
Le post-mortem blameless (sans blâme) est une pratique née chez Google et Etsy. Son principe : les incidents sont des opportunités d’apprentissage, pas des occasions de punir. Lorsque les ingénieurs craignent d’être punis, ils cachent les incidents et n’apprennent pas collectivement.
Un post-mortem blameless part du principe que :
Les personnes impliquées ont pris les meilleures décisions possibles avec les informations disponibles à ce moment.
L’objectif est de comprendre les causes systémiques, pas de trouver un coupable.
Les actions correctives visent le système (monitoring, documentation, automatisation), pas l’individu.
Format standard d’un post-mortem#
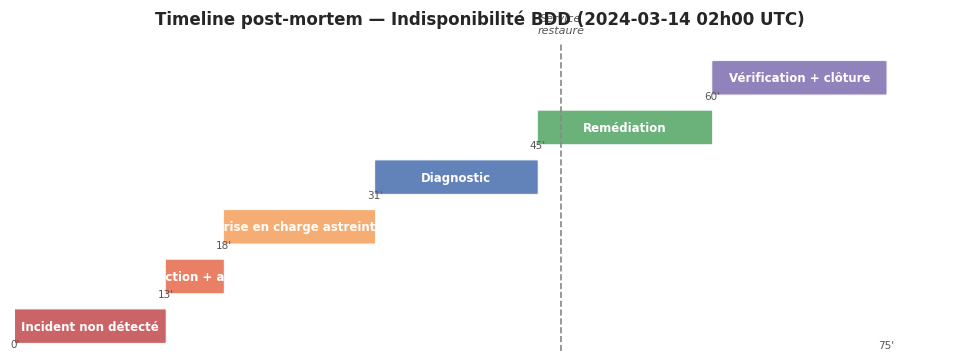
# Post-mortem : Indisponibilité base de données (2024-03-14)
## Impact
- Durée : 47 minutes (02h13 — 03h00 UTC)
- Utilisateurs affectés : ~12 000 (toutes les requêtes écritures en échec)
- Revenus estimés : 2 400 €
## Chronologie
- 02h13 — Alerte Prometheus : `pg_up == 0`
- 02h18 — Ingéniaire d'astreinte contacté
- 02h31 — Diagnostic : disque root plein (inode exhausted)
- 02h45 — Libération d'espace (/var/log, pg_log)
- 03h00 — Service restauré, confirmation monitoring
## Causes racines
1. Rotation des logs PostgreSQL non configurée (pg_log non limité)
2. Alerte espace disque seuil 95 % — trop tardif (atteint en 10 min après 90 %)
## Actions correctives
- [ ] Configurer `log_rotation_age = 1d` et `log_rotation_size = 100MB` (J+2)
- [ ] Abaisser le seuil d'alerte disque à 80 % (J+1)
- [ ] Ajouter monitoring des inodes (J+3)
- [ ] Runbook disque plein dans le wiki (J+5)
Gestion des secrets#
Ne jamais committer de secrets#
La première règle de la sécurité des secrets est absolue : aucun secret (mot de passe, clé API, certificat privé, token) ne doit être commité dans un dépôt git, même privé.
# Détecter les secrets avant un commit (outil git-secrets ou trufflehog)
apt install trufflehog
trufflehog git file://. --since-commit HEAD
# Configurer un hook pre-commit
cat > .git/hooks/pre-commit << 'EOF'
#!/bin/bash
if git diff --cached --name-only | xargs grep -lE \
'password\s*=|api_key\s*=|secret\s*=|token\s*=' 2>/dev/null; then
echo "ERREUR : secret potentiel détecté dans les fichiers stagés"
exit 1
fi
EOF
chmod +x .git/hooks/pre-commit
Rotation des secrets#
Tous les secrets doivent être rotés régulièrement :
Mots de passe : rotation tous les 90 jours minimum, immédiate en cas de départ d’un collaborateur avec accès.
Clés SSH : au moins une fois par an, immédiatement si un poste est compromis.
Tokens API : à chaque départ ou en cas d’exposition accidentelle.
Clés de chiffrement : selon la politique de sécurité, avec procédure de re-chiffrement des données.
HashiCorp Vault — bases#
Vault est un gestionnaire de secrets centralisé. Il expose une API REST, gère les politiques d’accès et l’audit.
# Démarrer Vault en mode dev (tests uniquement)
vault server -dev
# Stocker un secret
vault kv put secret/db/prod password=MonMotDePasse
# Lire un secret
vault kv get secret/db/prod
# Générer un mot de passe dynamique PostgreSQL (lease 1h)
vault read database/creds/readonly
pass — gestionnaire de secrets local#
# Initialiser avec une clé GPG
pass init "admin@example.com"
# Stocker un secret
pass insert infra/db/prod/password
# Lire
pass infra/db/prod/password
# Synchroniser avec git
pass git init
pass git push
Sauvegarde et restauration#
Tester régulièrement#
Une sauvegarde non testée n’est pas une sauvegarde. La seule façon de savoir qu’une sauvegarde fonctionne est de la restaurer effectivement sur un environnement de test.
Règle 3-2-1
3 copies des données, sur 2 supports différents, dont 1 hors site. Exemple : données en production + sauvegarde BorgBackup locale + réplication sur serveur distant (ou stockage objet S3/Backblaze B2).
RTO et RPO#
RPO (Recovery Point Objective) : perte de données maximale acceptable. Une sauvegarde quotidienne implique un RPO de 24h.
RTO (Recovery Time Objective) : durée maximale acceptable d’indisponibilité. Un RTO de 4h exige une procédure de restauration testée et documentée.
Ces deux métriques doivent être définies avec les parties prenantes métier, pas unilatéralement par l’équipe technique.
Simulation d’incident de restauration#
# Procédure de restauration BorgBackup (à tester mensuellement)
# 1. Lister les archives disponibles
borg list user@backup-server:/mnt/borg/prod
# 2. Monter une archive pour inspection
borg mount user@backup-server:/mnt/borg/prod::prod-2024-03-14 /mnt/restore
# 3. Vérifier l'intégrité d'un fichier critique
diff /etc/nginx/nginx.conf /mnt/restore/etc/nginx/nginx.conf
# 4. Restaurer sélectivement
borg extract user@backup-server:/mnt/borg/prod::prod-2024-03-14 \
var/lib/postgresql/data
# 5. Démonter
borg umount /mnt/restore
Sécurité opérationnelle#
Comptes de service#
Chaque service applicatif doit tourner sous un compte dédié sans shell et sans droits superflus :
useradd --system --no-create-home --shell /usr/sbin/nologin appservice
# ou avec home applicatif
useradd --system --home-dir /opt/app --shell /usr/sbin/nologin appservice
Rotation des clés SSH#
# Générer une nouvelle paire de clés Ed25519
ssh-keygen -t ed25519 -C "admin@example.com-$(date +%Y)" \
-f ~/.ssh/id_ed25519_2024
# Déployer la nouvelle clé sur tous les serveurs (via Ansible)
ansible all -m authorized_key -a \
"user=ansible key='{{ lookup('file', '~/.ssh/id_ed25519_2024.pub') }}'"
# Après validation, retirer l'ancienne clé
ansible all -m authorized_key -a \
"user=ansible key='{{ lookup('file', '~/.ssh/id_ed25519_old.pub') }}' state=absent"
Audit des accès#
# Dernières connexions SSH
last -n 20
# Connexions échouées (brute force)
journalctl -u sshd | grep "Failed password" | tail -20
# Comptes avec accès sudo
getent group sudo
grep -v '^#' /etc/sudoers /etc/sudoers.d/* 2>/dev/null
# Ports ouverts actuels vs attendus
ss -tlnp
Journalisation centralisée#
Les journaux locaux peuvent être effacés par un attaquant. En production, centraliser les logs sur un serveur syslog distant dès que possible :
# /etc/systemd/journald.conf
[Journal]
ForwardToSyslog=yes
# /etc/rsyslog.d/50-remote.conf
*.* @siem.example.com:514 # UDP (non fiable)
*.* @@siem.example.com:514 # TCP (fiable)
Infrastructure as Code#
Git pour les configurations#
Versionner /etc avec etckeeper ou un dépôt Ansible/Terraform constitue une source de vérité
unique. Chaque changement devient un commit avec auteur, date et message.
Peer review des changements infra#
Un changement d’infrastructure qui passe par une pull request bénéficie du regard d’un pair avant d’être appliqué. Cette pratique, venue du développement logiciel, est aussi précieuse pour l’infra :
Détection d’erreurs avant la production.
Partage de connaissance entre membres de l’équipe.
Traçabilité des décisions (pourquoi ce changement, à quelle date, validé par qui).
CI/CD pour l’infra#
# .gitlab-ci.yml — pipeline Ansible simplifié
stages: [lint, test, deploy]
ansible-lint:
stage: lint
image: pipelinecomponents/ansible-lint
script: ansible-lint site.yml
molecule-test:
stage: test
script:
- pip install molecule molecule-docker
- molecule test -s default
deploy-prod:
stage: deploy
when: manual
only: [main]
script:
- ansible-playbook -i inventaire/prod site.yml
Veille et amélioration continue#
Suivi des CVE#
Une CVE (Common Vulnerabilities and Exposures) est un identifiant public pour une vulnérabilité de sécurité. Les administrateurs système doivent surveiller les CVE affectant leurs logiciels.
# apt-listchanges affiche les changelogs lors des mises à jour
apt install apt-listchanges
# Lister les CVE corrigées dans la dernière mise à jour OpenSSH
apt changelog openssh-server | grep CVE
# Flux RSS CVE Ubuntu
# https://ubuntu.com/security/cves/rss.xml
# Outil Debian pour auditer les paquets vulnérables
apt install debsecan
debsecan --suite bookworm --only-fixed
Ressources de veille#
CERT-FR (cert.ssi.gouv.fr) : alertes et bulletins en français.
NVD (nvd.nist.gov) : base nationale américaine, API REST.
oss-security (mailing list) : divulgations avant correctif (full disclosure).
RHEL/CentOS Errata : liste des correctifs par version.
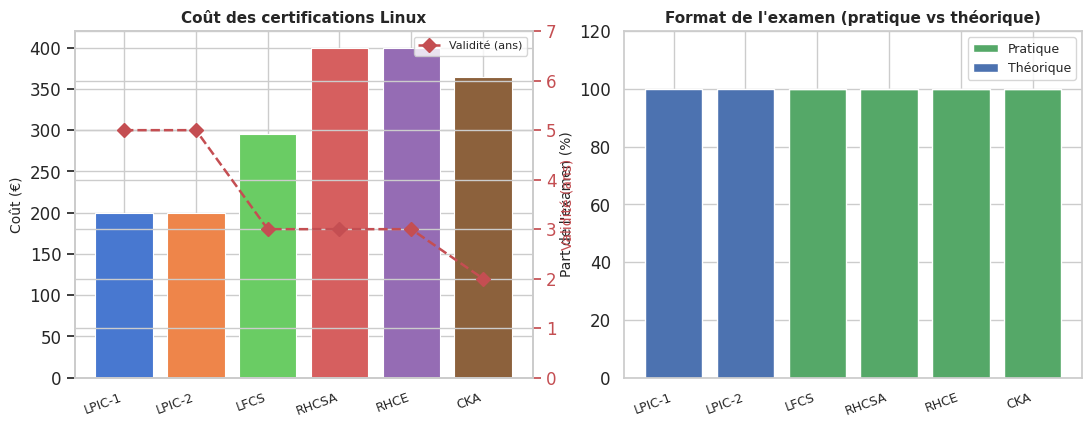
Certifications Linux#
Résumé du parcours#
De Bash à l’administration avancée#
Ce livre a couvert l’ensemble du spectre de l’administration système Linux :
Partie |
Chapitres |
Thème |
|---|---|---|
I |
1–4 |
Fondations : boot, noyau, utilisateurs, systemd |
II |
5–8 |
Stockage : disques, LVM, RAID, sauvegardes |
III |
9–12 |
Réseau : configuration, pare-feu, SSH, services |
IV |
13–15 |
Sécurité : permissions, durcissement, cryptographie |
V |
16–18 |
Observabilité : monitoring, logs, performance |
VI |
19–22 |
Pratiques : Ansible, virtualisation, automatisation, ops |
Prochaines étapes#
L’administration système Linux est un domaine en évolution permanente. Les axes d’approfondissement naturels après ce livre sont :
CI/CD et DevOps
GitLab CI / GitHub Actions pour l’automatisation des déploiements.
Terraform et Pulumi pour le provisionnement d’infrastructure cloud.
ArgoCD et Flux pour le GitOps appliqué à Kubernetes.
Sécurité avancée
Analyse forensique Linux :
auditd,osquery, SIEM.Pentest d’infrastructure : outils défensifs (Lynis, OpenVAS).
Gestion des secrets à l’échelle : HashiCorp Vault en cluster.
Observabilité
La suite Prometheus + Grafana + Loki + Tempo (métriques, logs, traces).
OpenTelemetry pour l’instrumentation des applications.
Conteneurs et orchestration
Docker en profondeur : réseaux, volumes, multi-stage builds.
Kubernetes : pods, deployments, services, ingress, RBAC.
Sécurité des conteneurs : Falco, OPA/Gatekeeper, Trivy.
Conseil final
L’expertise opérationnelle s’acquiert en production, pas seulement en formation. Mettre en place un homelab, contribuer à des projets open source, passer des certifications pratiques (RHCSA, LFCS, CKA) — chacune de ces pratiques consolide les réflexes que les livres ne peuvent qu’amorcer. La meilleure façon d’apprendre à diagnostiquer une panne est d’avoir déjà résolu des pannes.
Résumé#
Les bonnes pratiques ops ne sont pas un ensemble de règles rigides mais une culture :
Pratique |
Valeur apportée |
|---|---|
Documentation |
Résilience collective, réduction du bus factor |
Change management |
Réversibilité, traçabilité, communication |
Post-mortems blameless |
Apprentissage systémique, confiance dans l’équipe |
Gestion des secrets |
Réduction de la surface d’attaque |
Tests de restauration |
Confiance réelle dans les sauvegardes |
Infrastructure as Code |
Reproductibilité, revue de code, audit |
Veille CVE |
Réactivité face aux vulnérabilités |
Un administrateur système efficace n’est pas celui qui connaît le plus de commandes, mais celui qui construit des systèmes fiables, observables, documentés et réparables — par lui-même et par son équipe.