Automatisation et maintenance#
Scripts d’administration#
Bonnes pratiques fondamentales#
Un script d’administration mal écrit est plus dangereux qu’une action manuelle : il peut répliquer une erreur à grande échelle en quelques secondes. Les conventions suivantes sont non-négociables en production.
En-tête de sécurité :
#!/usr/bin/env bash
set -euo pipefail
IFS=$'\n\t'
set -e: quitte immédiatement si une commande échoue.set -u: traite les variables non définies comme des erreurs.set -o pipefail: propage l’échec d’une commande dans un pipeline.IFS=$'\n\t': évite les surprises lors du découpage de chaînes avec des espaces.
Logging structuré#
#!/usr/bin/env bash
set -euo pipefail
readonly SCRIPT_NAME="$(basename "$0")"
readonly LOG_FILE="/var/log/admin/${SCRIPT_NAME%.sh}.log"
readonly TIMESTAMP="$(date +%Y-%m-%dT%H:%M:%S)"
log() {
local level="$1"; shift
printf '[%s] [%s] [%s] %s\n' \
"$TIMESTAMP" "$level" "$SCRIPT_NAME" "$*" | tee -a "$LOG_FILE"
}
log INFO "Démarrage du script"
log WARN "Espace disque inférieur à 20 %"
log ERROR "Echec de la sauvegarde — abandon"
Lockfiles — éviter les exécutions concurrentes#
readonly LOCK_FILE="/var/run/${SCRIPT_NAME%.sh}.pid"
acquire_lock() {
if [[ -f "$LOCK_FILE" ]]; then
local pid
pid="$(cat "$LOCK_FILE")"
if kill -0 "$pid" 2>/dev/null; then
log ERROR "Instance déjà en cours (PID $pid)"
exit 1
fi
fi
echo $$ > "$LOCK_FILE"
trap 'rm -f "$LOCK_FILE"' EXIT
}
acquire_lock
Notifications#
notify_slack() {
local message="$1"
curl -s -X POST "$SLACK_WEBHOOK_URL" \
-H 'Content-type: application/json' \
--data "{\"text\":\"[$HOSTNAME] $message\"}" > /dev/null
}
notify_email() {
local subject="$1" body="$2"
echo "$body" | mail -s "[$HOSTNAME] $subject" "$ADMIN_EMAIL"
}
Structure recommandée d’un script de production
En-tête
set -euo pipefailConstantes en
readonlyet variables d’environnementFonctions utilitaires :
log,acquire_lock,notifyVérification des prérequis (droits, espace disque, connectivité)
Logique principale dans des fonctions nommées
Appel de
main "$@"en fin de fichier
Mises à jour automatiques#
unattended-upgrades (Debian/Ubuntu)#
# Installation
apt install unattended-upgrades apt-listchanges
# Configuration principale
cat /etc/apt/apt.conf.d/50unattended-upgrades
// /etc/apt/apt.conf.d/50unattended-upgrades
Unattended-Upgrade::Allowed-Origins {
"${distro_id}:${distro_codename}-security";
// Décommenter pour les mises à jour non-sécurité :
// "${distro_id}:${distro_codename}-updates";
};
Unattended-Upgrade::AutoFixInterruptedDpkg "true";
Unattended-Upgrade::MinimalSteps "true";
Unattended-Upgrade::Remove-Unused-Dependencies "true";
Unattended-Upgrade::Automatic-Reboot "false";
Unattended-Upgrade::Mail "admin@example.com";
# Activer l'exécution automatique
cat /etc/apt/apt.conf.d/20auto-upgrades
// APT::Periodic::Update-Package-Lists "1";
// APT::Periodic::Unattended-Upgrade "1";
# Tester sans appliquer
unattended-upgrades --dry-run --debug
dnf-automatic (RHEL/Fedora/AlmaLinux)#
dnf install dnf-automatic
# Configuration
cat /etc/dnf/automatic.conf
# [commands]
# apply_updates = yes
# upgrade_type = security
systemctl enable --now dnf-automatic.timer
Stratégies de mise à jour#
Redémarrage automatique
Activer Automatic-Reboot "true" redémarre le serveur en pleine nuit si un noyau ou glibc est
mis à jour. En production, préférer une alerte email et planifier les redémarrages dans une
fenêtre de maintenance.
La stratégie recommandée en production est la mise à jour des correctifs de sécurité
uniquement via unattended-upgrades, et les mises à jour majeures lors d’une fenêtre de
maintenance planifiée, après tests en environnement de staging.
Surveillance de l’intégrité#
AIDE — Advanced Intrusion Detection Environment#
AIDE crée une base de référence des hachages et attributs de tous les fichiers critiques. Lors de chaque contrôle, il compare l’état actuel à la référence et signale toute modification.
# Installation
apt install aide
# Initialisation de la base de référence
aideinit
# Génère /var/lib/aide/aide.db.new — le renommer en .db
mv /var/lib/aide/aide.db.new /var/lib/aide/aide.db
# Lancer une vérification
aide --check
# Exemple de sortie (modification détectée)
# File: /etc/passwd
# Mtime : 2024-01-10 08:12:34 | 2024-01-15 22:43:01
# SHA256 : abc123... | def456...
# Mettre à jour la base après un changement légitime
aide --update && mv /var/lib/aide/aide.db.new /var/lib/aide/aide.db
Intégration avec systemd timer#
# /etc/systemd/system/aide-check.service
[Unit]
Description=Vérification d'intégrité AIDE
[Service]
Type=oneshot
ExecStart=/usr/bin/aide --check
ExecStartPost=/usr/bin/aide --update
StandardOutput=journal
# /etc/systemd/system/aide-check.timer
[Unit]
Description=Vérification AIDE quotidienne
[Timer]
OnCalendar=*-*-* 03:00:00
Persistent=true
[Install]
WantedBy=timers.target
Checksums manuels#
# Créer une empreinte d'un binaire sensible
sha256sum /usr/bin/sudo > /root/checksums_critiques.sha256
# Vérifier ultérieurement
sha256sum --check /root/checksums_critiques.sha256
Gestion des certificats#
Renouvellement automatique Let’s Encrypt#
# Installer Certbot
apt install certbot python3-certbot-nginx
# Obtenir un certificat
certbot --nginx -d mondomaine.fr -d www.mondomaine.fr
# Le timer systemd de Certbot est créé automatiquement
systemctl status certbot.timer
# Simuler un renouvellement
certbot renew --dry-run
Alerte d’expiration personnalisée#
#!/usr/bin/env bash
# /usr/local/bin/check_certs.sh
set -euo pipefail
DOMAINS=("mondomaine.fr" "api.mondomaine.fr")
SEUIL_JOURS=30
for domain in "${DOMAINS[@]}"; do
expiry=$(echo | openssl s_client -connect "${domain}:443" -servername "$domain" 2>/dev/null \
| openssl x509 -noout -enddate 2>/dev/null \
| cut -d= -f2)
expiry_epoch=$(date -d "$expiry" +%s)
now_epoch=$(date +%s)
jours_restants=$(( (expiry_epoch - now_epoch) / 86400 ))
if (( jours_restants < SEUIL_JOURS )); then
echo "ALERTE : certificat $domain expire dans $jours_restants jours ($expiry)"
fi
done
Sauvegardes automatisées#
BorgBackup + systemd timer#
BorgBackup est un outil de sauvegarde incrémentielle avec déduplication, compression et chiffrement intégrés.
# Installation
apt install borgbackup
# Initialiser le dépôt distant
borg init --encryption=repokey user@backup-server:/mnt/borg/mon-serveur
# Sauvegarder
borg create \
--compression lz4 \
--exclude '/var/cache' \
--exclude '/tmp' \
user@backup-server:/mnt/borg/mon-serveur::{hostname}-{now:%Y-%m-%d} \
/etc /home /var/www /var/lib/postgresql
# Lister les archives
borg list user@backup-server:/mnt/borg/mon-serveur
# Restaurer une archive
borg extract user@backup-server:/mnt/borg/mon-serveur::mon-serveur-2024-01-15 \
etc/nginx/nginx.conf
# Nettoyer les anciennes archives
borg prune \
--keep-daily 7 \
--keep-weekly 4 \
--keep-monthly 6 \
user@backup-server:/mnt/borg/mon-serveur
Timer systemd pour les sauvegardes#
# /etc/systemd/system/borg-backup.service
[Unit]
Description=Sauvegarde Borg
After=network-online.target
[Service]
Type=oneshot
User=root
EnvironmentFile=/etc/borg/env
ExecStart=/usr/local/bin/backup.sh
ExecStartPost=/usr/local/bin/check_backup.sh
StandardOutput=journal
OnFailure=notify-backup-failure@%n.service
# /etc/systemd/system/borg-backup.timer
[Unit]
Description=Sauvegarde Borg quotidienne
[Timer]
OnCalendar=*-*-* 02:00:00
RandomizedDelaySec=900
Persistent=true
[Install]
WantedBy=timers.target
Nettoyage automatique#
Journaux anciens#
# Limiter la taille totale des journaux systemd
journalctl --vacuum-size=500M
# Supprimer les journaux de plus de 30 jours
journalctl --vacuum-time=30d
# Configuration permanente dans /etc/systemd/journald.conf
[Journal]
SystemMaxUse=500M
MaxRetentionSec=1month
Paquets orphelins et cache APT#
# Supprimer les paquets orphelins (Debian/Ubuntu)
apt autoremove --purge
# Nettoyer le cache des paquets téléchargés
apt clean # supprime tout
apt autoclean # supprime uniquement les versions obsolètes
# Identifier les gros paquets installés
dpkg-query -W -f='${Installed-Size}\t${Package}\n' | sort -rn | head -20
Nettoyage de /tmp et fichiers temporaires#
# systemd-tmpfiles gère /tmp et /var/tmp automatiquement
# Configuration dans /etc/tmpfiles.d/
cat /usr/lib/tmpfiles.d/tmp.conf
# Forcer un nettoyage immédiat
systemd-tmpfiles --clean
# Nettoyage personnalisé : fichiers > 7 jours dans /tmp
find /tmp -type f -mtime +7 -delete
Surveillance des ressources#
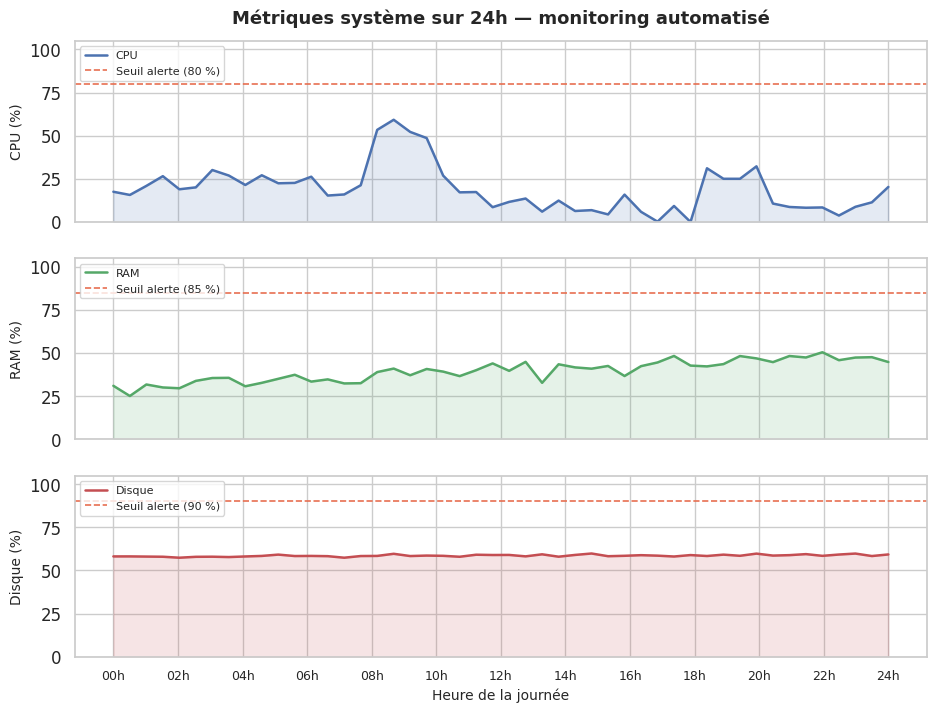
Script Python de monitoring avec alertes#
#!/usr/bin/env python3
"""Monitoring système minimal avec alertes webhook."""
import json
import os
import subprocess
import urllib.request
from dataclasses import dataclass
from datetime import datetime
SLACK_WEBHOOK = os.environ.get("SLACK_WEBHOOK", "")
SEUILS = {"cpu_percent": 80, "ram_percent": 85, "disk_percent": 90}
@dataclass
class Metrique:
nom: str
valeur: float
unite: str
seuil: float
@property
def en_alerte(self) -> bool:
return self.valeur >= self.seuil
def lire_cpu() -> float:
"""Lecture du CPU via /proc/stat sur 1 seconde."""
import time
def lire_stat():
with open("/proc/stat") as f:
ligne = f.readline().split()
return int(ligne[1]), sum(int(v) for v in ligne[1:])
idle1, total1 = lire_stat()
time.sleep(1)
idle2, total2 = lire_stat()
return round(100 * (1 - (idle2 - idle1) / (total2 - total1)), 1)
def lire_ram() -> float:
info = {}
with open("/proc/meminfo") as f:
for ligne in f:
k, v = ligne.split(":")
info[k.strip()] = int(v.split()[0])
total = info["MemTotal"]
disponible = info["MemAvailable"]
return round(100 * (1 - disponible / total), 1)
def envoyer_alerte(metriques: list[Metrique]) -> None:
if not SLACK_WEBHOOK:
return
alertes = [m for m in metriques if m.en_alerte]
if not alertes:
return
texte = f":warning: *Alerte monitoring* `{os.uname().nodename}`\n"
for m in alertes:
texte += f" • {m.nom}: {m.valeur}{m.unite} (seuil {m.seuil}{m.unite})\n"
data = json.dumps({"text": texte}).encode()
req = urllib.request.Request(SLACK_WEBHOOK, data=data,
headers={"Content-Type": "application/json"})
urllib.request.urlopen(req, timeout=5)
if __name__ == "__main__":
ts = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
metriques = [
Metrique("CPU", lire_cpu(), "%", SEUILS["cpu_percent"]),
Metrique("RAM", lire_ram(), "%", SEUILS["ram_percent"]),
]
for m in metriques:
etat = "ALERTE" if m.en_alerte else "OK"
print(f"[{ts}] [{etat}] {m.nom}: {m.valeur}{m.unite}")
envoyer_alerte(metriques)
Runbooks#
Définition et structure#
Un runbook est une procédure documentée et actionnable pour répondre à un événement opérationnel. Il peut s’agir d’une procédure de reprise après panne, d’ajout d’un nœud, ou de réponse à une alerte.
Un bon runbook contient :
Contexte : quel système, quelle alerte déclenchée, quelle criticité.
Diagnostic : commandes à exécuter pour confirmer le problème.
Actions de remédiation : étapes numérotées et précises.
Vérification : comment confirmer que le problème est résolu.
Escalade : qui contacter si la procédure échoue.
Exemple — reprise après disque plein#
# Runbook : Espace disque critique (>95 %)
## Déclencheur
Alerte Prometheus/Nagios : `node_filesystem_avail_bytes` < 5 %
## Diagnostic
```bash
df -h # Identifier la partition concernée
du -sh /var/log/* | sort -rh | head -10 # Top 10 répertoires
journalctl --disk-usage # Taille des journaux systemd
Remédiation immédiate#
journalctl --vacuum-size=200M # Libérer espace journaux
apt clean # Vider cache APT
find /tmp -mtime +3 -delete # Purger fichiers temporaires anciens
Remédiation durable#
Identifier la source de croissance (logs applicatifs non rotatifs ?)
Configurer logrotate pour l’application concernée
Étendre le volume LVM si nécessaire (voir Runbook LVM-extend)
Vérification#
df -h # Confirmer espace libéré > seuil
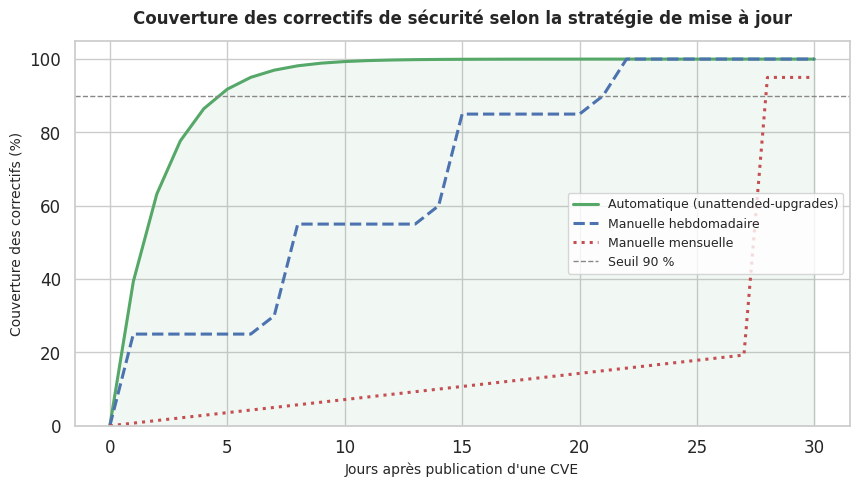
Résumé#
L’automatisation de la maintenance réduit la charge cognitive de l’administrateur et rend les opérations répétables. Les piliers sont :
Domaine |
Outil clé |
Fréquence |
|---|---|---|
Mises à jour sécurité |
|
Quotidienne |
Sauvegardes |
BorgBackup + systemd timer |
Quotidienne |
Intégrité fichiers |
AIDE |
Quotidienne |
Certificats TLS |
Certbot timer |
2× par jour |
Nettoyage journaux |
|
Hebdomadaire |
Monitoring |
Script Python / Prometheus |
Continu |
Un bon script de maintenance est idempotent, journalisé, notifiant et protégé par un lockfile. Les runbooks transforment l’expérience informelle de l’équipe en procédures partagées et testables.
Prochaine étape
Le dernier chapitre synthétise les bonnes pratiques opérationnelles : documentation, gestion des changements, post-mortems blameless, sécurité des secrets, et pistes d’approfondissement (CI/CD pour l’infra, certifications, veille CVE).