Performance et tuning#
Méthodologie de diagnostic — méthode USE#
Avant de toucher à un seul paramètre noyau, il faut mesurer. La méthode USE (Utilization, Saturation, Errors), formalisée par Brendan Gregg, fournit un cadre systématique applicable à chaque ressource physique :
Ressource |
Utilisation |
Saturation |
Erreurs |
|---|---|---|---|
CPU |
|
Load avg > nb_cœurs, runqueue |
|
Mémoire |
|
Swap actif (si/so vmstat), OOM killer |
Erreurs ECC mémoire |
Disque |
|
|
|
Réseau |
|
Drops ( |
Erreurs de trame |
L’application systématique de la méthode USE évite le cargo-cult tuning : modifier des paramètres sans mesure préalable conduit presque toujours à des régressions non anticipées.
Charge moyenne — interprétation correcte#
La charge moyenne (load average) mesure le nombre moyen de processus en état R (runnable) ou D (uninterruptible sleep I/O). Elle est souvent mal interprétée :
load average: 3.20, 2.95, 2.81
1 min 5 min 15 min
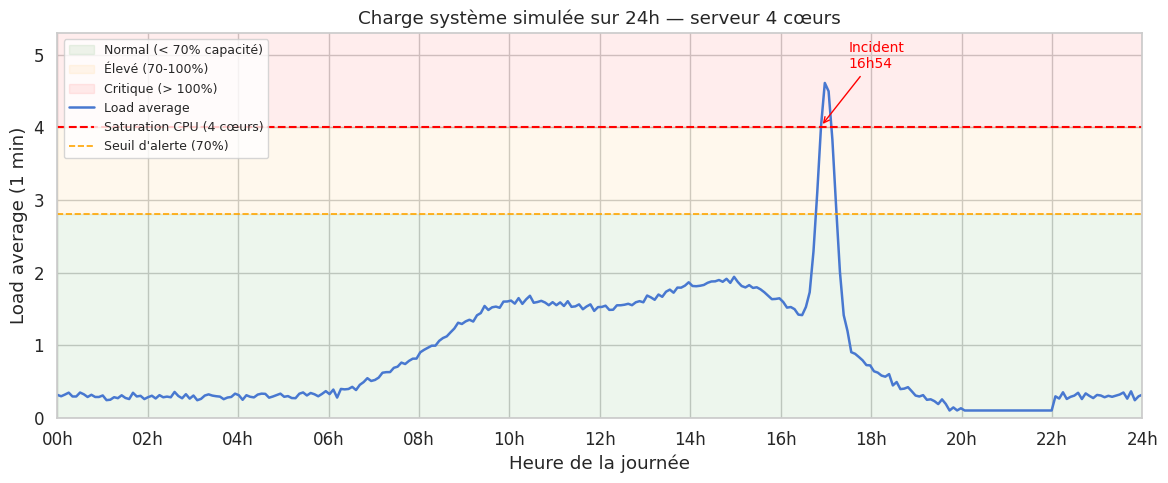
Sur un système à 4 cœurs : charge 3.2 à 1 min → 80 % de saturation, acceptable
Sur un système à 2 cœurs : charge 3.2 → saturation à 160 %, files d’attente
La tendance temporelle est aussi informative que la valeur absolue : une charge montant de 0.5 à 4.0 sur 15 minutes signale un problème émergent.
iowait dans le load average
Les processus en état D (uninterruptible I/O wait) contribuent au load average mais n’utilisent pas la CPU. Un load average élevé avec une CPU idle à 70 % et iowait à 25 % indique une saturation I/O, pas une saturation CPU — deux problèmes très différents avec des solutions différentes.
Profiling CPU#
perf stat — compteurs matériels#
perf stat interroge les Performance Monitoring Counters (PMC) du processeur, exposés par le noyau via le sous-système perf_events :
perf stat -e cycles,instructions,cache-misses,branch-misses ./mon-programme
Performance counter stats for './mon-programme':
2,345,678,901 cycles # 3.42 GHz
1,890,234,567 instructions # 0.81 insn per cycle
45,234,100 cache-misses # 2.45% of all cache refs
3,456,789 branch-misses # 1.23% of all branches
0.686321123 seconds time elapsed
Un ratio instructions per cycle (IPC) < 1 indique des bulles de pipeline fréquentes, souvent dues à des cache-misses. Un taux de branch-misses > 5 % indique des prédictions de branchement défaillantes.
perf record/report — profiling par échantillonnage#
# Enregistrer un profil CPU pendant 30 secondes
perf record -g -F 1000 -p $(pgrep mon-app) -- sleep 30
# Analyser le profil
perf report --sort=symbol,dso
-g capture les call stacks, -F 1000 échantillonne à 1000 Hz. Le rapport montre les fonctions consommant le plus de cycles CPU, avec leur call graph complet.
Flamegraphs — visualisation des call stacks#
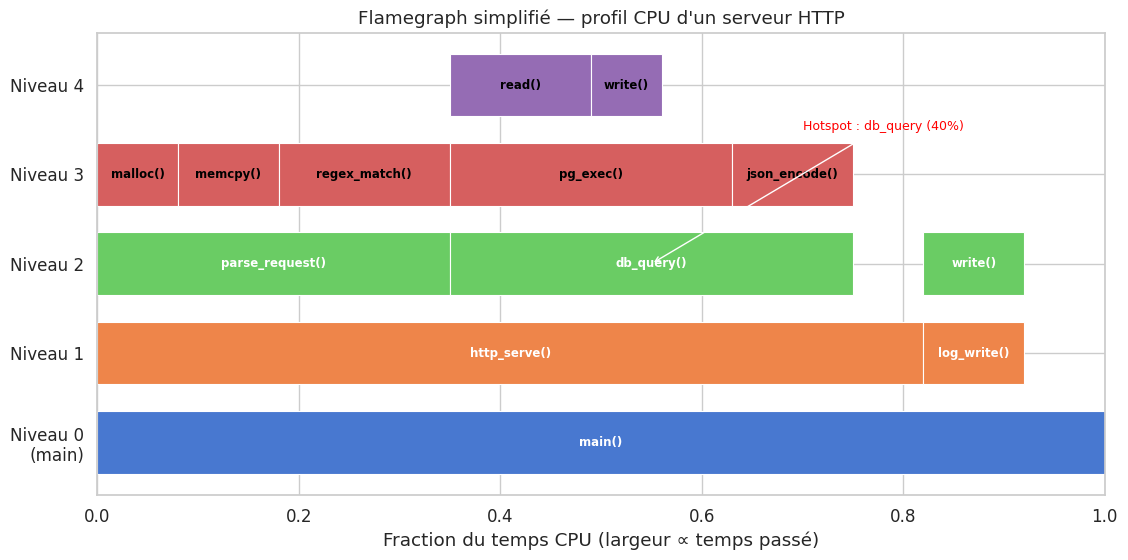
Un flamegraph représente les call stacks de manière hiérarchique : la largeur de chaque bloc est proportionnelle au temps CPU passé dans cette fonction. Les fonctions les plus larges en haut de la flamme sont les hotspots à optimiser.
# Avec les scripts de Brendan Gregg
perf record -F 99 -ag -- sleep 30
perf script | stackcollapse-perf.pl | flamegraph.pl > flamegraph.svg
strace et ltrace — traçage des appels système#
# Tracer les appels système d'un processus
strace -c -p 1234
# Résumé statistique
strace -c ./mon-programme 2>&1 | head -20
% time seconds usecs/call calls errors syscall
45.23 0.001234 12 100 read
23.11 0.000631 6 105 write
15.44 0.000421 421 1 execve
8.90 0.000243 4 60 mmap
ltrace fait de même pour les appels aux bibliothèques dynamiques (libssl, libc…).
I/O et stockage#
iotop — processus et I/O#
# Afficher les processus avec le plus d'I/O en temps réel
iotop -o -d 2
# Mode non-interactif pour la journalisation
iotop -b -o -n 5 -d 2
Total DISK READ: 12.34 M/s | Total DISK WRITE: 45.67 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
1234 be/4 mysql 10.23 M/s 2.34 M/s 0.00 % 78.23 % mysqld
5678 be/4 www 0.00 B/s 43.33 M/s 0.00 % 12.45 % php-fpm
Schedulers I/O — choisir selon le workload#
Le noyau Linux propose plusieurs ordonnanceurs d’I/O pour la file de requêtes des blocs :
Scheduler |
Description |
Workload adapté |
|---|---|---|
mq-deadline |
Garantit des délais maximaux, faible latence |
SSD, bases de données OLTP |
kyber |
Faible overhead, optimisé multi-queue NVMe |
NVMe haute performance |
bfq (Budget Fair Queueing) |
Équité entre processus, latence interactive |
Desktop, médias, HDD |
none |
Pas d’ordonnancement (FIFO) |
Hyperviseurs (l’hôte ordonnance) |
# Voir le scheduler actuel
cat /sys/block/sda/queue/scheduler
# Changer le scheduler
echo "mq-deadline" > /sys/block/nvme0n1/queue/scheduler
# Persistant via udev
cat /etc/udev/rules.d/60-scheduler.rules
# ACTION=="add|change", KERNEL=="nvme[0-9]*", ATTR{queue/scheduler}="kyber"
fio — benchmark I/O#
# Test de lecture séquentielle
fio --name=lecture_seq --filename=/tmp/test.fio \
--rw=read --bs=1M --size=2G --numjobs=1 --runtime=30 \
--ioengine=libaio --direct=1 --iodepth=32
# Test d'écriture aléatoire (4K)
fio --name=ecriture_rand --filename=/tmp/test.fio \
--rw=randwrite --bs=4K --size=1G --numjobs=4 --runtime=30 \
--ioengine=libaio --direct=1 --iodepth=64 --group_reporting
READ: bw=1241MiB/s (1301MB/s), io=2048MiB, run=1650msec
iops : min=1200, max=1280, avg=1241.34
lat (msec) : min=0.82, max=2.34, avg=0.97
Réseau — diagnostic et tuning#
ss — états TCP et buffers#
ss remplace netstat avec de meilleures performances (il lit directement les sockets du noyau via Netlink au lieu de /proc/net/tcp) :
# Toutes les sockets TCP établies avec informations étendues
ss -tipn
# Sockets en écoute avec les buffers
ss -tlnp
# Statistiques par état TCP
ss -s
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 10.0.0.1:443 203.0.113.5:52341 users:(("nginx",pid=1234))
cubic wscale:7,7 rto:204 rtt:3.421/1.2 ato:40 mss:1448 rcvmss:1448 advmss:1448
cwnd:10 bytes_acked:45234 bytes_received:1234 segs_out:456 segs_in:234
Les champs Recv-Q et Send-Q non nuls sur les sockets en écoute signalent que l’application ne consomme pas les connexions assez vite — un backlog saturé.
tcpdump — capture de paquets#
# Capturer le trafic HTTP sur eth0
tcpdump -i eth0 -w /tmp/capture.pcap port 80 or port 443
# Filtre BPF avancé : uniquement les SYN (nouvelles connexions)
tcpdump -i any 'tcp[tcpflags] & tcp-syn != 0 and tcp[tcpflags] & tcp-ack == 0'
# Afficher le contenu HTTP
tcpdump -i eth0 -A -s 0 port 80 | grep -E "Host:|GET |POST "
ethtool — configuration de l’interface#
# Voir les offloads actifs
ethtool -k eth0 | grep -E "scatter-gather|tcp-segmentation|generic-segmentation"
# Désactiver le GRO (Generic Receive Offload) — utile pour analyser des paquets
ethtool -K eth0 gro off
# Statistiques du pilote réseau
ethtool -S eth0 | grep -E "rx_missed|tx_dropped|rx_errors"
iperf3 — mesure de bande passante#
# Serveur
iperf3 -s
# Client — test TCP bidirectionnel sur 30 secondes
iperf3 -c 192.168.1.100 -t 30 --bidir
# Test UDP (mesure du jitter)
iperf3 -c 192.168.1.100 -u -b 100M
Mémoire — pages, NUMA et OOM killer#
Transparent HugePages (THP)#
Par défaut, Linux alloue la mémoire par pages de 4 KiB. Les Transparent HugePages (THP) regroupent 512 pages consécutives en une seule page de 2 MiB, réduisant la pression sur le TLB (Translation Lookaside Buffer).
# Voir l'état THP
cat /sys/kernel/mm/transparent_hugepage/enabled
# [always] madvise never
# Désactiver pour les bases de données (Oracle, MongoDB recommandent never)
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo never > /sys/kernel/mm/transparent_hugepage/defrag
THP et bases de données
Oracle, MongoDB, Redis et plusieurs autres bases de données recommandent de désactiver THP. Le compactage de mémoire déclenché par THP introduit des latences imprévisibles (pauses de 100ms+) incompatibles avec les SLAs OLTP. Pour les applications analytiques en mémoire (Spark, Hadoop), THP peut au contraire améliorer les performances.
NUMA — Non-Uniform Memory Access#
Sur les serveurs multi-sockets, chaque processeur a accès rapide à sa propre banque mémoire (NUMA node local) et accès plus lent à celle des autres processeurs :
# Voir la topologie NUMA
numactl --hardware
# Lier un processus à un nœud NUMA
numactl --cpunodebind=0 --membind=0 ./mon-app
# Statistiques NUMA
numastat -m
Un processus qui alloue de la mémoire sur un nœud NUMA distant peut subir des latences mémoire 2 à 3 fois supérieures.
OOM Killer — score et configuration#
Quand la mémoire physique est épuisée, le noyau active l”OOM Killer qui sélectionne et tue le processus avec le score le plus élevé :
# Voir le score OOM d'un processus
cat /proc/$(pgrep mon-app)/oom_score
# Protéger un processus critique (score ajustement -1000 = jamais tuer)
echo -1000 > /proc/$(pgrep sshd)/oom_score_adj
# Forcer le kill d'un processus par l'OOM (score +1000)
echo 1000 > /proc/$(pgrep gros-process)/oom_score_adj
# OOM killer dans les logs
dmesg | grep -i "oom\|killed process"
journalctl -k | grep "Out of memory"
[1234567.890] Out of memory: Kill process 4567 (java) score 892 or sacrifice child
[1234567.891] Killed process 4567 (java) total-vm:4096000kB, anon-rss:3800000kB
vm.swappiness#
# Valeur actuelle (défaut : 60)
sysctl vm.swappiness
# Réduire le swap pour les serveurs (10 = utiliser swap uniquement en dernier recours)
sysctl -w vm.swappiness=10
# Persistant
echo "vm.swappiness=10" >> /etc/sysctl.d/99-performance.conf
Tuning noyau — paramètres sysctl#
Paramètres réseau critiques#
# /etc/sysctl.d/99-network-tuning.conf
# Buffers TCP : [min défaut max] en octets
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 65536 16777216
# Backlog des sockets en écoute (SYN queue)
net.ipv4.tcp_max_syn_backlog = 8192
# File d'attente des connexions entrantes (SOMAXCONN)
net.core.somaxconn = 65535
# Réutilisation des sockets TIME_WAIT (serveurs à fort trafic)
net.ipv4.tcp_tw_reuse = 1
# Protection SYN flood
net.ipv4.tcp_syncookies = 1
# Nombre de ports éphémères disponibles
net.ipv4.ip_local_port_range = 1024 65535
Paramètres I/O et VM#
# Taille de la fenêtre de lecture anticipée (Ko) — adapté aux lectures séquentielles
blockdev --setra 4096 /dev/sda
# Via sysfs (persistant avec udev)
echo 4096 > /sys/block/sda/queue/read_ahead_kb
# Ratio de pages sales avant flush (défaut : 20%)
sysctl -w vm.dirty_ratio=15
# Ratio déclenchant le flush en arrière-plan (défaut : 10%)
sysctl -w vm.dirty_background_ratio=5
Appliquer les changements sysctl
sysctl -p /etc/sysctl.d/99-performance.conf applique immédiatement un fichier de configuration sans redémarrage. Pour valider sans appliquer, utiliser sysctl -n <paramètre> pour lire la valeur actuelle.
Courbe de charge simulée sur 24h#
Flamegraph simplifié#
Mémoire — parse de /proc/meminfo#
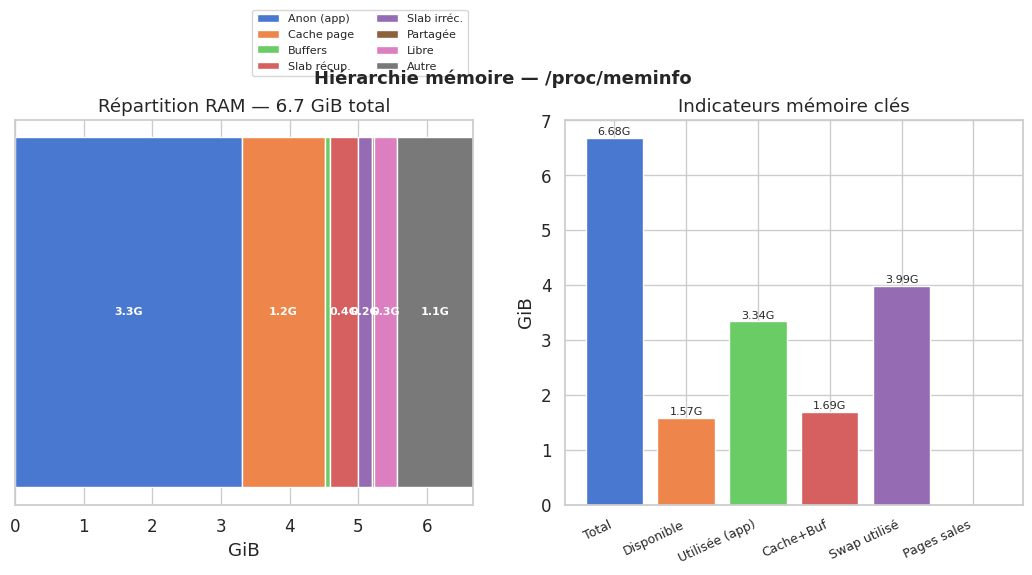
MemAvailable : 1.57 GiB | Swap utilisé : 3.99 GiB
Modélisation — Little’s Law et schedulers I/O#
Little’s Law pour le dimensionnement#
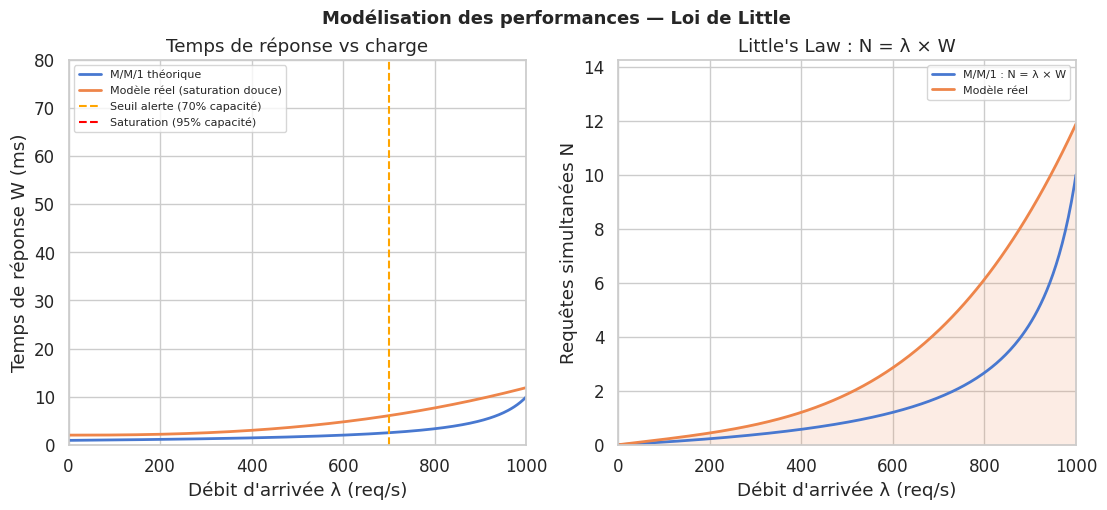
La loi de Little est un résultat fondamental de la théorie des files d’attente :
N = λ × W
N : nombre moyen de requêtes dans le système (en cours de traitement + en attente)
λ : débit d’arrivée (requêtes par seconde)
W : temps moyen de séjour dans le système (traitement + attente)
Comparaison des schedulers I/O#
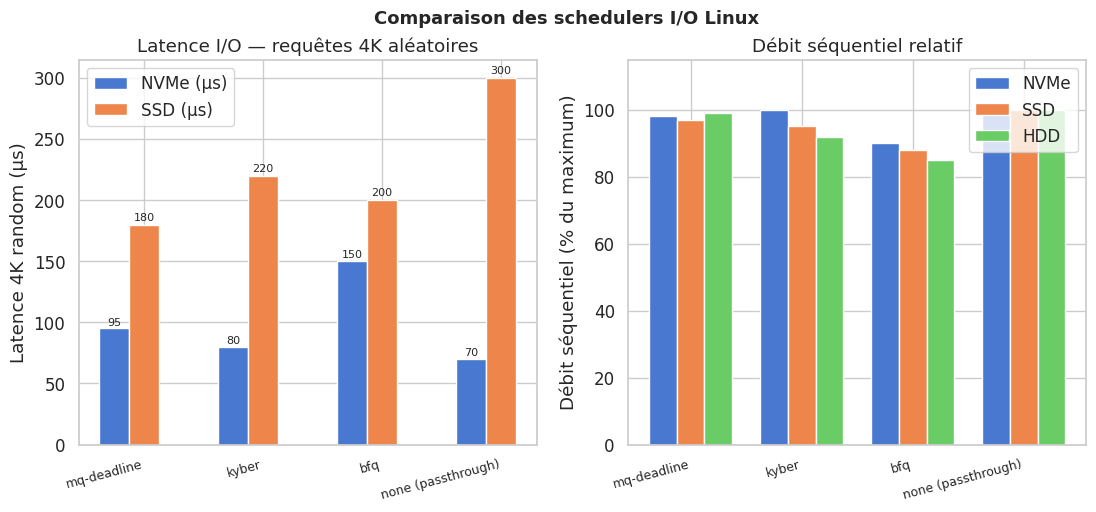
Scheduler Latence NVMe (µs) Latence SSD (µs) Latence HDD (µs) Workload optimal
mq-deadline 95 180 8000 OLTP, bases de données
kyber 80 220 12000 NVMe haute performance
bfq 150 200 5500 Desktop, usage mixte
none (passthrough) 70 300 15000 VM (délégation à l'hôte)
Profiling applicatif et benchmarking#
/usr/bin/time -v — profil d’exécution complet#
/usr/bin/time -v ./mon-programme argument1
Command being timed: "./mon-programme argument1"
User time (seconds): 4.23
System time (seconds): 0.18
Percent of CPU this job got: 98%
Elapsed (wall clock) time: 4.52
Maximum resident set size (kbytes): 524288
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 12345
Voluntary context switches: 234
Involuntary context switches: 89
File system inputs: 0
File system outputs: 8192
Les major page faults (> 0) indiquent que le programme a dû charger des pages depuis le disque — un signe que son working set dépasse la RAM disponible.
cProfile Python vs profiling système#
# Profiler un script Python avec cProfile
python3 -m cProfile -s cumulative mon_script.py | head -20
# Avec sortie vers fichier pour analyse avec snakeviz
python3 -m cProfile -o profile.pstats mon_script.py
snakeviz profile.pstats
La différence entre cProfile (profiling au niveau Python, bytecode) et perf (profiling noyau, instructions machine) est fondamentale : cProfile ne voit pas le temps passé dans les extensions C (numpy, lxml, cryptographie) tandis que perf peut capturer le profil complet incluant les bibliothèques natives.
sysbench et stress-ng — benchmarking#
# Benchmark CPU (calcul de nombres premiers)
sysbench cpu --cpu-max-prime=20000 --threads=4 run
# Benchmark mémoire (débit de lecture/écriture)
sysbench memory --memory-block-size=1K --memory-total-size=10G run
# Benchmark I/O
sysbench fileio --file-total-size=2G prepare
sysbench fileio --file-total-size=2G --file-test-mode=rndrw --threads=4 run
sysbench fileio --file-total-size=2G cleanup
# stress-ng : générer une charge contrôlée pour tester la stabilité
stress-ng --cpu 4 --vm 2 --vm-bytes 1G --io 2 --timeout 60s --metrics
Protocole de mesure rigoureux#
Éviter les pièges de mesure
Répétitions : effectuer au minimum 5 à 10 mesures et utiliser la médiane (pas la moyenne) pour éliminer les valeurs aberrantes liées à des interruptions système.
Isolation : désactiver le scaling de fréquence CPU (cpupower frequency-set -g performance), s’assurer qu’aucun autre workload intensif ne tourne en parallèle, vider les caches disque (echo 3 > /proc/sys/vm/drop_caches) avant les benchmarks I/O.
Warmup : inclure une phase d’échauffement (1-2 itérations non mesurées) pour que les caches TLB, CPU et disque soient dans un état stable représentatif des conditions de production.
Réplicabilité : noter l’état complet du système (version noyau, paramètres sysctl, schedulers, topologie NUMA, gouverneur CPU) pour que les résultats puissent être reproduits.
Résumé#
Le tuning Linux est une discipline empirique : chaque optimisation doit être précédée d’une mesure, suivie d’une validation, et documentée. La méthode USE fournit le cadre systématique pour éviter de se concentrer sur la mauvaise ressource.
Points à retenir :
La méthode USE (Utilisation/Saturation/Erreurs) s’applique à chaque ressource physique et évite le diagnostic par intuition.
perf est l’outil de référence pour le profiling CPU à bas niveau ; les flamegraphs rendent les résultats lisibles par tous.
Les schedulers I/O doivent être sélectionnés selon le type de stockage et le profil de charge :
mq-deadlinepour les bases de données,bfqpour les usages interactifs.Les paramètres sysctl réseau (
tcp_rmem/wmem,somaxconn) sont les plus impactants sur des serveurs à fort trafic HTTP.THP améliore les performances analytiques mais dégrade les bases de données transactionnelles — configurer explicitement selon le workload.
La loi de Little (N = λ × W) permet de dimensionner correctement les ressources sans sur-provisionner.
Tout benchmark sans protocole rigoureux (répétitions, isolation, warmup) produit des résultats non reproductibles et donc inexploitables.
Axe de tuning |
Outil de mesure |
Levier principal |
|---|---|---|
CPU |
|
Affinité, priorité nice/RT |
Mémoire |
|
swappiness, NUMA binding, THP |
I/O disque |
|
Scheduler I/O, read_ahead, direct I/O |
Réseau |
|
tcp_rmem/wmem, somaxconn, offloads |
Applicatif |
|
Algorithmes, pool de connexions |