Monitoring système#
Métriques système fondamentales#
Superviser un système Linux revient à mesurer en continu quatre grandes familles de ressources : le processeur, la mémoire, les entrées/sorties et le réseau. Chaque famille expose des métriques distinctes que le noyau agrège dans le pseudo-système de fichiers /proc.
CPU — les états de temps processeur#
Le noyau comptabilise le temps passé par chaque cœur dans plusieurs états, exprimés en jiffies (unité de temps interne) puis convertis en pourcentage :
État |
Signification |
|---|---|
user |
Temps passé à exécuter du code applicatif en espace utilisateur |
nice |
Temps passé pour des processus à priorité réduite (nice positif) |
system |
Temps passé dans le noyau (appels système, interruptions logicielles) |
iowait |
Temps d’attente d’opérations I/O disque (la CPU est inactive mais le système est bloqué) |
irq |
Gestion des interruptions matérielles |
softirq |
Interruptions logicielles (traitements réseau, timer) |
steal |
Temps « volé » par l’hyperviseur sur une machine virtuelle |
idle |
Temps réellement inactif |
Un iowait élevé (> 20 %) indique une saturation du sous-système disque. Un steal non nul signale une contention CPU sur l’hôte de virtualisation — un problème invisible depuis l’intérieur de la VM mais mesurable depuis /proc/stat.
Mémoire — RSS, VSZ, cache et buffers#
La comptabilité mémoire Linux distingue plusieurs notions souvent confondues :
VSZ (Virtual Set Size) : espace d’adressage virtuel réservé par le processus, inclut les bibliothèques partagées, les zones anonymes non encore allouées physiquement (lazy allocation). Toujours supérieur à RSS.
RSS (Resident Set Size) : pages réellement présentes en mémoire physique pour ce processus, hors swap.
Cache de page : mémoire utilisée par le noyau pour mettre en cache les blocs disque lus récemment. Libérée immédiatement si une application en a besoin — ne jamais interpréter ce chiffre comme « mémoire perdue ».
Buffers : mémoire tampon pour les métadonnées du système de fichiers (inodes, répertoires). Distincte du cache de page mais souvent agrégée avec lui dans les outils de monitoring.
La formule mémoire disponible = free + buffers + cache est celle qui importe pour évaluer la pression mémoire réelle. Le champ MemAvailable de /proc/meminfo l’estime directement.
I/O — débit, latence et queue depth#
Les métriques I/O clés sont :
r/s, w/s : opérations de lecture/écriture par seconde
rkB/s, wkB/s : débit en kilo-octets par seconde
await : temps moyen d’attente d’une opération I/O (queue + service), en millisecondes
%util : pourcentage de temps où le périphérique avait au moins une requête en cours (saturation si proche de 100 %)
avgqu-sz : taille moyenne de la file d’attente du périphérique
Réseau — paquets, débit et erreurs#
Les compteurs réseau exposés par /proc/net/dev comprennent pour chaque interface : octets reçus/envoyés, paquets, erreurs, collisions et paquets abandonnés. Une augmentation régulière des erreurs ou des drops indique une saturation de buffers ou un problème de pilote.
Outils temps réel#
top — l’outil universel#
top affiche la liste des processus actualisée toutes les 3 secondes par défaut. Les colonnes importantes :
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1234 www-data 20 0 512m 48m 12m S 4.7 0.6 0:23.11 nginx
PR : priorité noyau réelle (20 + NI pour les processus normaux)
NI : valeur nice (-20 à 19)
VIRT : VSZ, RES : RSS, SHR : pages partagées
S : état (R=running, S=sleeping, D=uninterruptible sleep, Z=zombie, T=stopped)
Raccourcis interactifs utiles : M (tri par mémoire), P (tri par CPU), k (envoyer un signal), r (renice), 1 (afficher chaque cœur), H (afficher les threads), W (sauvegarder la configuration).
htop et btop — alternatives enrichies#
htop ajoute une interface ncurses avec barres de progression, navigation à la souris, arborescence des processus (F5), filtrage (F4) et tri multi-colonnes (F6). Il permet aussi de tuer ou renommer un processus directement.
btop (anciennement bpytop) propose une visualisation graphique ASCII en temps réel de la CPU, mémoire, swap, réseau et disque dans un seul écran. Particulièrement lisible sur les terminaux haute résolution.
uptime et w#
uptime
14:32:07 up 42 days, 3:17, 2 users, load average: 0.85, 1.12, 1.04
La charge moyenne (load average) mesure le nombre moyen de processus en état R (running) ou D (uninterruptible sleep) sur 1, 5 et 15 minutes. Une valeur inférieure au nombre de cœurs logiques indique un système non saturé.
w
14:32:07 up 42 days, 3:17, 2 users, load average: 0.85, 1.12, 1.04
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
alice pts/0 192.168.1.10 14:10 0.00s 0.12s 0.02s w
bob pts/1 192.168.1.25 13:55 10:22 0.05s 0.05s vim /etc/nginx/nginx.conf
w combine la sortie d”uptime avec la liste des utilisateurs connectés et leur activité en cours.
vmstat et iostat#
vmstat — vue globale du système#
vmstat 2 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1240320 45612 2341200 0 0 14 28 312 645 8 2 89 1 0
0 0 0 1238912 45620 2342100 0 0 0 48 289 612 5 2 93 0 0
2 0 0 1237400 45628 2342500 0 0 0 16 445 890 18 4 78 0 0
Colonnes critiques :
Colonne |
Description |
|---|---|
r |
Processus en file d’attente d’exécution (runqueue) |
b |
Processus bloqués en uninterruptible sleep (I/O) |
swpd |
Mémoire swap utilisée (Ko) |
bi / bo |
Blocs lus/écrits depuis/vers le swap (blocs/s) |
si / so |
Pages swappées depuis/vers le disque (swap in/out) |
wa |
% CPU en iowait |
in |
Interruptions par seconde |
cs |
Context switches par seconde |
Un r > nb_cœurs persistant indique une saturation CPU. Un b > 0 persistant couplé à wa > 10 % signale un sous-système I/O saturé. Des valeurs si/so non nulles révèlent du swapping actif — situation à éviter en production.
iostat — métriques I/O par périphérique#
iostat -xz 2 3
Device r/s w/s rkB/s wkB/s await r_await w_await %util
sda 12.4 38.7 496.0 1548.0 2.14 1.82 2.28 18.4
nvme0n1 45.2 120.3 1808.0 4812.0 0.38 0.31 0.41 8.7
L’option -x affiche les statistiques étendues, -z masque les périphériques sans activité. Un await > 20 ms pour un SSD signale un problème sérieux (normalement < 1 ms). Pour un disque rotatif, des valeurs jusqu’à 10 ms sont acceptables en charge mixte.
sar et sysstat#
sysstat est une suite d’outils de collecte et d’analyse historique des performances. Elle comprend sar, sadc (collecteur), sadf (formateur), pidstat, cifsiostat et nfsiostat.
Activation de la collecte#
# Debian/Ubuntu
apt install sysstat
# Activer la collecte
sed -i 's/ENABLED="false"/ENABLED="true"/' /etc/default/sysstat
systemctl enable --now sysstat
Le daemon sadc collecte les données toutes les 10 minutes (configurable dans /etc/cron.d/sysstat) et les archive dans /var/log/sysstat/sa<JJ>.
Commandes sar essentielles#
# Utilisation CPU sur les dernières 24h
sar -u
# Utilisation mémoire
sar -r
# Statistiques I/O par périphérique
sar -d -p
# Trafic réseau
sar -n DEV
# Données d'hier
sar -u -f /var/log/sysstat/sa$(date -d yesterday +%d)
# Plage horaire spécifique
sar -u --start 08:00:00 --end 18:00:00
# sar -u 1 5
Linux 6.1.0 (serveur) 2026-03-24 _x86_64_ (8 CPU)
14:35:01 CPU %user %nice %system %iowait %steal %idle
14:35:02 all 8.37 0.00 2.14 0.50 0.00 89.00
14:35:03 all 12.45 0.00 3.27 0.25 0.00 84.03
Archives sysstat
Les archives binaires /var/log/sysstat/saXX sont lisibles avec sadf -d saXX -- -u pour obtenir un format CSV, ou sadf -j saXX -- -u pour du JSON. Cela facilite l’intégration dans des pipelines d’analyse.
Lecture de /proc#
Le répertoire /proc est un système de fichiers virtuel exposant l’état interne du noyau sous forme de fichiers texte. C’est la source primaire de toutes les métriques système — tous les outils (top, vmstat, sar) ne font que le lire.
/proc/meminfo#
cat /proc/meminfo | head -20
MemTotal: 16384000 kB
MemFree: 1240320 kB
MemAvailable: 5120000 kB
Buffers: 45612 kB
Cached: 2341200 kB
SwapCached: 0 kB
Active: 4512000 kB
Inactive: 2100000 kB
SwapTotal: 4194304 kB
SwapFree: 4194304 kB
Dirty: 1024 kB
Writeback: 0 kB
AnonPages: 3200000 kB
Mapped: 512000 kB
Shmem: 200000 kB
/proc/stat — calcul manuel du % CPU#
import time
def lire_cpu_stat():
with open("/proc/stat") as f:
ligne = f.readline()
vals = list(map(int, ligne.split()[1:]))
idle = vals[3] + vals[4] # idle + iowait
total = sum(vals)
return total, idle
t1, i1 = lire_cpu_stat()
time.sleep(0.5)
t2, i2 = lire_cpu_stat()
delta_total = t2 - t1
delta_idle = i2 - i1
cpu_pct = 100.0 * (1 - delta_idle / delta_total) if delta_total > 0 else 0.0
print(f"Utilisation CPU (calcul /proc/stat) : {cpu_pct:.1f} %")
print(f" delta_total={delta_total} jiffies, delta_idle={delta_idle} jiffies")
Utilisation CPU (calcul /proc/stat) : 5.8 %
delta_total=400 jiffies, delta_idle=377 jiffies
/proc/diskstats et /proc/net/dev#
cat /proc/diskstats | grep -v " 0 0 0 0 0 0 0 0 0 0 0"
259 0 nvme0n1 45231 1204 2305482 12340 120345 48203 6712044 234567 0 180234 247890
Les 11 champs par périphérique correspondent aux compteurs définis dans la documentation du noyau (Documentation/admin-guide/iostats.txt) : lectures complétées, lectures fusionnées, secteurs lus, temps de lecture (ms), et les équivalents pour les écritures.
psutil Python#
psutil (Process and System UTILities) est la bibliothèque Python de référence pour accéder aux métriques système de façon portable. Elle lit /proc sous Linux mais fonctionne également sur macOS et Windows.
Utilisation CPU par cœur#
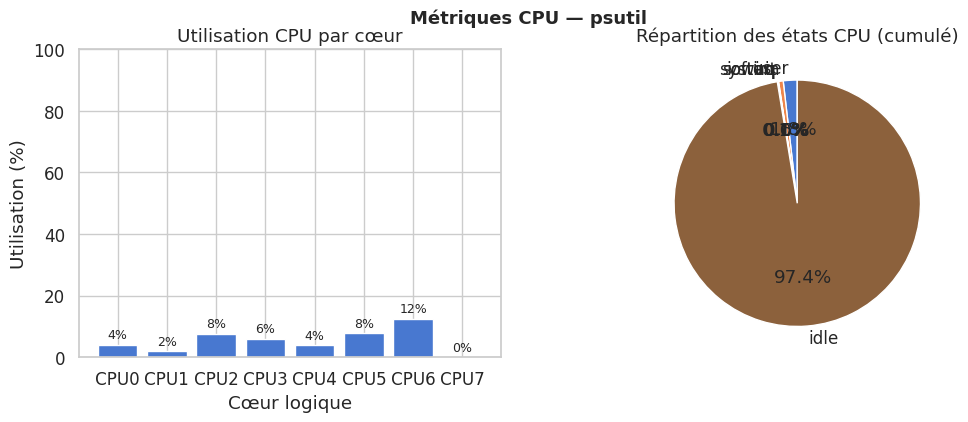
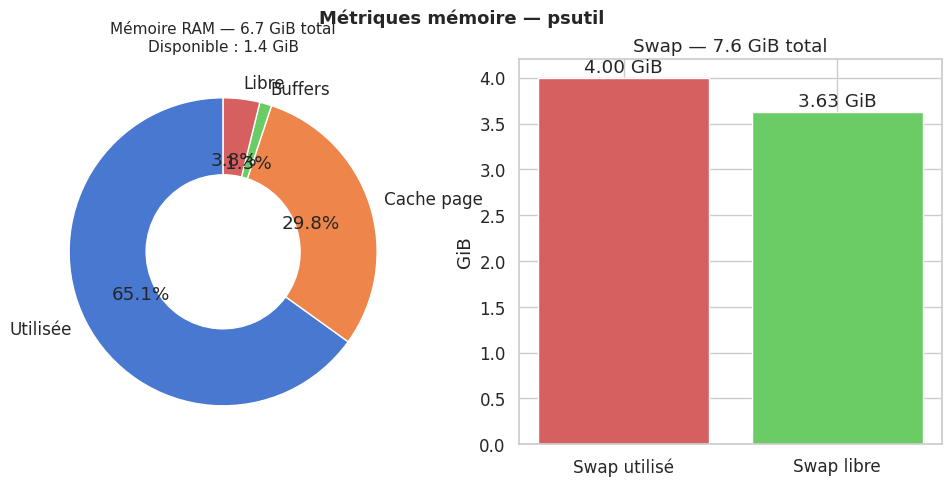
Mémoire — donut chart#
I/O disque#
io = psutil.disk_io_counters(perdisk=True)
lignes = []
for nom, c in io.items():
lignes.append({
"Périphérique" : nom,
"Lectures" : c.read_count,
"Écritures" : c.write_count,
"Lu (MiB)" : round(c.read_bytes / 1024**2, 1),
"Écrit (MiB)" : round(c.write_bytes / 1024**2, 1),
"Tps lecture (s)" : round(c.read_time / 1000, 2),
"Tps écriture (s)": round(c.write_time / 1000, 2),
})
df_io = pd.DataFrame(lignes)
print("=== Métriques I/O disque ===")
print(df_io.to_string(index=False))
=== Métriques I/O disque ===
Périphérique Lectures Écritures Lu (MiB) Écrit (MiB) Tps lecture (s) Tps écriture (s)
sda 3819022 2481126 45595.2 67133.5 1423.26 4425.33
sda1 2561 2 25.8 0.0 0.90 0.00
sda2 1941346 344373 10256.7 18312.0 658.64 1753.15
sda3 696316 162198 15704.9 7064.0 310.62 265.65
sda4 1177265 1974544 19579.5 41757.5 452.50 2406.51
sda5 1311 8 25.3 0.0 0.51 0.01
sdb 11316 160 92.9 0.1 9.78 0.32
sdb1 1038 0 21.9 0.0 1.16 0.00
sdb2 7878 160 19.4 0.1 4.21 0.32
sdb3 2296 0 50.3 0.0 4.26 0.00
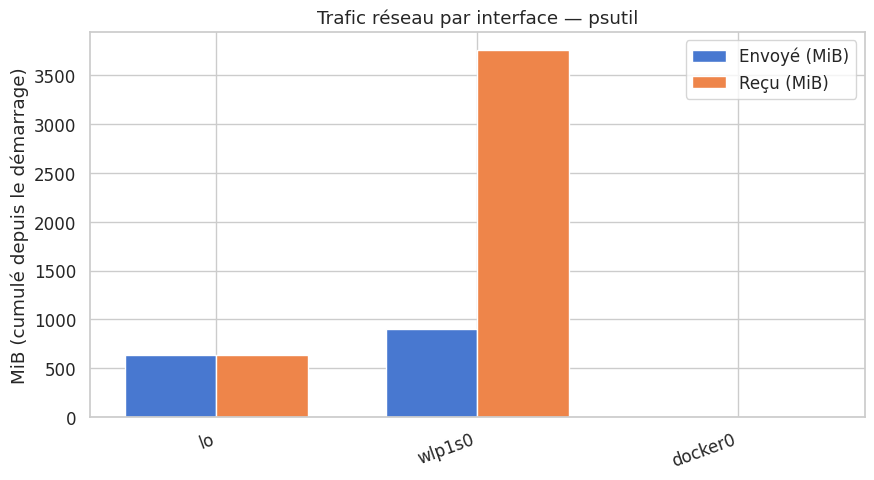
Trafic réseau par interface#
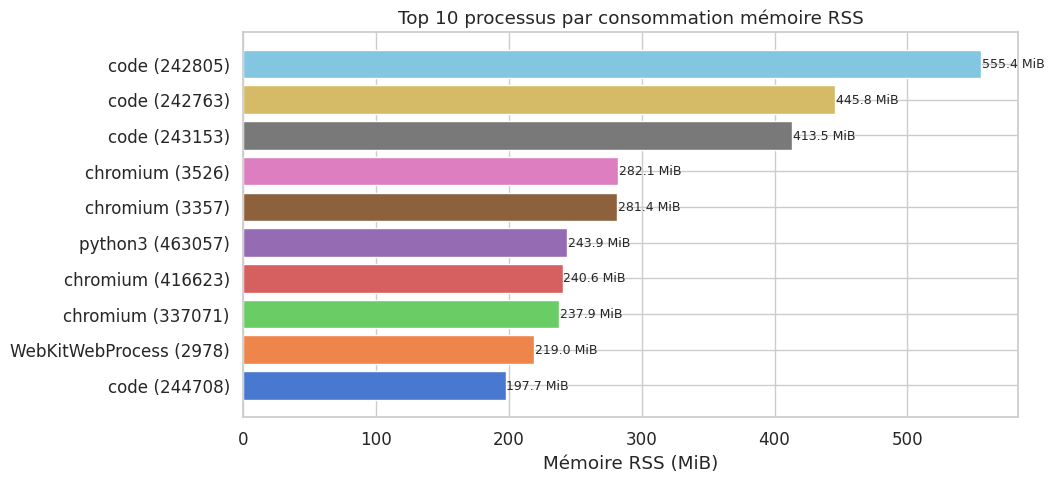
Top 10 processus par mémoire RSS#
Alertes et seuils#
Script bash de surveillance#
Un script de monitoring minimaliste peut être planifié via cron ou exécuté en démon :
#!/bin/bash
# /usr/local/bin/check_resources.sh
SEUIL_CPU=80
SEUIL_MEM=90
SEUIL_DISK=85
DESTINATAIRE="admin@example.com"
# CPU utilisation (moyenne sur 1 mesure vmstat)
CPU_IDLE=$(vmstat 1 2 | tail -1 | awk '{print $15}')
CPU_USED=$((100 - CPU_IDLE))
# Mémoire
MEM_POURCENT=$(free | awk '/Mem:/ {printf "%.0f", ($3/$2)*100}')
# Disque racine
DISK_POURCENT=$(df -h / | awk 'NR==2 {print $5}' | tr -d '%')
alerte() {
local SUJET="$1"
local CORPS="$2"
echo "$CORPS" | mail -s "[ALERTE] $SUJET" "$DESTINATAIRE"
logger -t monitoring "[ALERTE] $SUJET"
}
[ "$CPU_USED" -gt "$SEUIL_CPU" ] && alerte "CPU élevé" "CPU: ${CPU_USED}%"
[ "$MEM_POURCENT" -gt "$SEUIL_MEM" ] && alerte "Mémoire" "RAM: ${MEM_POURCENT}%"
[ "$DISK_POURCENT" -gt "$SEUIL_DISK" ] && alerte "Disque /" "Disque: ${DISK_POURCENT}%"
Intégration avec systemd OnFailure#
Pour qu’un service envoie une alerte en cas d’échec :
# /etc/systemd/system/mon-app.service
[Unit]
Description=Mon application
OnFailure=alerter-failure@%n.service
[Service]
ExecStart=/opt/mon-app/start.sh
Restart=on-failure
RestartSec=10s
# /etc/systemd/system/alerter-failure@.service
[Unit]
Description=Notification d'échec pour %i
[Service]
Type=oneshot
ExecStart=/usr/local/bin/notify-failure.sh %i
Seuils et faux positifs
Des seuils trop bas génèrent des alertes intempestives qui finissent par être ignorées (fatigue d’alerte). Calibrer les seuils sur l’historique sar de la semaine précédente : utiliser le 95e percentile + 20 % comme point de départ, puis affiner selon le profil de charge de l’application.
Prometheus et Grafana#
Architecture#
Prometheus est un système de monitoring open source basé sur un modèle de collecte par pull : le serveur Prometheus interroge périodiquement des exporters qui exposent des métriques au format texte sur un endpoint HTTP (/metrics).
┌─────────────────┐ scrape ┌────────────────┐
│ Serveur cible │ ←────────────────── │ Prometheus │
│ node_exporter │ /metrics HTTP │ (serveur) │
│ :9100 │ └───────┬────────┘
└─────────────────┘ │ PromQL queries
┌──────▼──────┐
│ Grafana │
│ (dashboards)│
└─────────────┘
node_exporter#
node_exporter est l’exporter officiel Prometheus pour les métriques système Linux. Il expose plus de 700 métriques nativement :
# Installation
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/\
node_exporter-1.7.0.linux-amd64.tar.gz
tar xf node_exporter-1.7.0.linux-amd64.tar.gz
mv node_exporter-1.7.0.linux-amd64/node_exporter /usr/local/bin/
# Service systemd
systemctl enable --now node_exporter
# Vérification
curl -s http://localhost:9100/metrics | grep "^node_cpu_seconds"
node_cpu_seconds_total{cpu="0",mode="idle"} 12345.67
node_cpu_seconds_total{cpu="0",mode="iowait"} 45.12
node_cpu_seconds_total{cpu="0",mode="system"} 234.89
node_cpu_seconds_total{cpu="0",mode="user"} 1023.45
Requêtes PromQL essentielles#
# % CPU utilisé (sur 5 minutes glissantes)
100 - (avg by(instance)(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
# Mémoire disponible en GiB
node_memory_MemAvailable_bytes / 1024^3
# Trafic réseau entrant par interface
rate(node_network_receive_bytes_total[5m]) * 8
Rétention et haute disponibilité
Prometheus stocke ses données localement par défaut (15 jours). Pour une rétention longue durée, intégrer Thanos ou Cortex pour le stockage objet distribué. Grafana se connecte à Prometheus comme datasource et propose des dashboards communautaires prêts à l’emploi (ID 1860 : « Node Exporter Full »).
Résumé#
Le monitoring système repose sur la lecture cohérente de métriques issues de /proc, exposées et historisées par des outils spécialisés. La progression naturelle va des outils interactifs (top, htop) pour le diagnostic immédiat, aux outils d’agrégation temporelle (sar, vmstat) pour l’analyse de tendance, jusqu’aux plateformes de monitoring continues (Prometheus/Grafana) pour la supervision à l’échelle.
Points à retenir :
iowait et saturation disque (
%util,avgqu-sz) sont les indicateurs I/O les plus critiques.La mémoire disponible (
MemAvailable) est plus pertinente que la mémoire libre brute.Le steal CPU est invisible aux outils classiques mais mesurable depuis
/proc/stat— crucial en environnement virtualisé.psutiloffre un accès Python idiomatique à toutes ces métriques, adapté à l’automatisation et aux rapports.Les alertes doivent être calibrées sur l’historique réel pour éviter la fatigue d’alerte.
Prometheus + Grafana représentent la solution standard pour la supervision continue de parcs de serveurs.
Outil |
Usage principal |
Granularité |
|---|---|---|
|
Diagnostic interactif immédiat |
Temps réel |
|
Vue agrégée CPU/mémoire/I/O |
Intervalle configurable |
|
Historique sur 24h+ |
10 min (configurable) |
|
Intégration Python/automatisation |
À la demande |
Prometheus |
Supervision continue multi-hôtes |
15s (configurable) |