Virtualisation et conteneurs#
Types de virtualisation#
Hyperviseur de type 1 et type 2#
La virtualisation consiste à faire fonctionner plusieurs systèmes d’exploitation sur un même matériel physique en isolant chacun dans une machine virtuelle (VM). L’élément central est l”hyperviseur, le logiciel qui arbitre l’accès aux ressources.
Type 1 — bare metal : l’hyperviseur s’exécute directement sur le matériel, sans système d’exploitation hôte intermédiaire. Les performances sont optimales car la couche intermédiaire est minimale. Exemples : KVM (Linux), VMware ESXi, Microsoft Hyper-V, Xen.
Type 2 — hosted : l’hyperviseur tourne comme une application sur un système d’exploitation hôte. Plus simple à installer, il convient au développement et aux tests. Les performances sont inférieures en raison de la double couche d’indirection. Exemples : VirtualBox, VMware Workstation, Parallels.
KVM : type 1 ou type 2 ?
KVM (Kernel-based Virtual Machine) est considéré comme de type 1 : le module noyau kvm.ko
transforme le noyau Linux lui-même en hyperviseur. Linux joue simultanément le rôle du système
hôte et de l’hyperviseur, ce qui lui confère d’excellentes performances.
Para-virtualisation#
La para-virtualisation est une technique dans laquelle le système d’exploitation invité est modifié pour communiquer directement avec l’hyperviseur via une interface optimisée (API hypercall), plutôt que d’émuler du matériel réel. Les pilotes para-virtualisés virtio (réseau, disque, mémoire) utilisent ce mécanisme sous KVM pour atteindre des performances proches du bare metal.
Virtualisation matérielle — Intel VT-x et AMD-V#
Les processeurs modernes intègrent des extensions dédiées à la virtualisation :
Intel VT-x (Virtualization Technology for IA-32/64) : jeu d’instructions VMX.
AMD-V (AMD Virtualization, aussi appelé SVM) : équivalent AMD.
Ces extensions permettent à l’hyperviseur de faire tourner le code invité directement sur le processeur physique en mode protégé, sans émulation logicielle des instructions privilégiées.
# Vérifier la présence des extensions de virtualisation
grep -c 'vmx\|svm' /proc/cpuinfo
# vmx = Intel VT-x, svm = AMD-V
# Une valeur > 0 confirme le support matériel
KVM/libvirt#
Architecture en couches#
KVM seul ne suffit pas pour créer des VMs complètes : il fournit l’isolation mémoire et l’accélération CPU mais délègue l’émulation des périphériques (disque, réseau, USB) à QEMU.
La pile complète est la suivante :
Couche |
Rôle |
|---|---|
KVM |
Module noyau, accélération matérielle, isolation mémoire |
QEMU |
Émulation des périphériques, amorçage des VMs |
libvirt |
API d’abstraction unifiée (gestion des VMs, réseaux, pools) |
virsh / virt-manager |
Interfaces CLI et graphique pour libvirt |
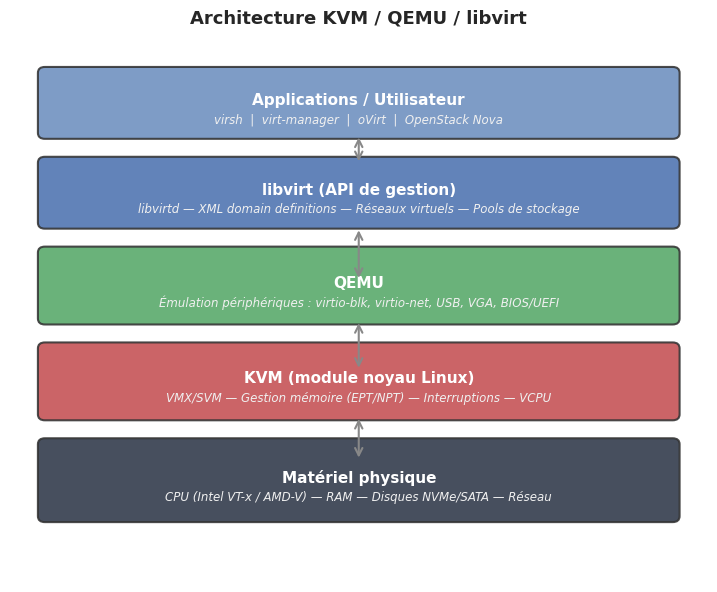
virsh — commandes essentielles#
# Lister les VMs actives
virsh list
# Lister toutes les VMs (y compris arrêtées)
virsh list --all
# Démarrer une VM
virsh start debian12
# Arrêt propre (ACPI)
virsh shutdown debian12
# Forcer l'arrêt (équivalent d'un coupe-courant)
virsh destroy debian12
# Accéder à la console série de la VM
virsh console debian12
# Voir l'utilisation CPU/RAM en temps réel
virsh domstats debian12 --vcpu --balloon
Gestion des VMs#
virt-install#
# Créer une VM Debian 12 en mode texte
virt-install \
--name debian12 \
--ram 2048 \
--vcpus 2 \
--disk path=/var/lib/libvirt/images/debian12.qcow2,size=20,format=qcow2 \
--os-variant debian12 \
--cdrom /var/lib/libvirt/boot/debian-12-netinst.iso \
--network network=default \
--graphics none \
--console pty,target_type=serial
Formats d’image disque#
Format |
Description |
Cas d’usage |
|---|---|---|
qcow2 |
QEMU Copy-On-Write v2, snapshots, compression, chiffrement |
Production KVM |
raw |
Image brute octet par octet, performances maximales |
Benchmarks, migration |
vmdk |
Format VMware |
Interopérabilité VMware |
vhd/vhdx |
Format Hyper-V |
Migration Windows |
# Convertir une image raw en qcow2
qemu-img convert -f raw -O qcow2 debian.raw debian.qcow2
# Inspecter une image
qemu-img info debian12.qcow2
Snapshots et clonage#
# Créer un snapshot
virsh snapshot-create-as debian12 avant-upgrade \
--description "Avant mise à jour majeure" --atomic
# Lister les snapshots
virsh snapshot-list debian12
# Revenir à un snapshot
virsh snapshot-revert debian12 avant-upgrade
# Cloner une VM arrêtée
virt-clone --original debian12 --name debian12-clone \
--file /var/lib/libvirt/images/debian12-clone.qcow2
Migration#
La migration à chaud (live migration) déplace une VM d’un hyperviseur à l’autre sans l’arrêter. Elle nécessite un stockage partagé (NFS, Ceph, iSCSI) ou une migration avec copie mémoire complète.
# Migration vers un autre hôte KVM (stockage partagé)
virsh migrate --live debian12 qemu+ssh://kvm02.example.com/system
Réseau KVM#
Modes réseau#
# Lister les réseaux virtuels
virsh net-list --all
# Décrire un réseau
virsh net-dumpxml default
Mode |
Description |
Usage |
|---|---|---|
NAT |
Les VMs accèdent à Internet via la table NAT de l’hôte |
Développement |
Bridge |
La VM est attachée directement au réseau physique |
Production |
macvtap |
Interface virtuelle directe sur la NIC physique |
Performance |
Isolated |
Réseau privé sans accès à l’hôte |
Tests isolés |
Bridge Linux#
# Créer un bridge sur l'hôte (NetworkManager)
nmcli connection add type bridge con-name br0 ifname br0
nmcli connection add type bridge-slave con-name br0-eth0 \
ifname eth0 master br0
nmcli connection up br0
# Attacher une VM existante au bridge
virsh attach-interface debian12 bridge br0 --model virtio --live --config
LXC/LXD#
Conteneurs système vs conteneurs applicatifs#
LXC (Linux Containers) crée des conteneurs système : chaque conteneur dispose d’un processus init, une arborescence complète, et se comporte comme un serveur Linux léger. C’est à mi-chemin entre la VM (isolation forte) et Docker (conteneur applicatif mono-processus).
LXD est un démon de gestion construit sur LXC, avec une API REST, un CLI lxc, des profils et
des snapshots. Il est maintenu par Canonical.
# Lancer un conteneur Ubuntu
lxc launch ubuntu:22.04 mon-conteneur
# Lister les conteneurs
lxc list
# Exécuter une commande dans le conteneur
lxc exec mon-conteneur -- bash
# Arrêter et supprimer
lxc stop mon-conteneur
lxc delete mon-conteneur
Profils et snapshots#
# Créer un profil limité en ressources
lxc profile create petit
lxc profile edit petit # édite config YAML
# Appliquer un profil
lxc launch ubuntu:22.04 app1 --profile default --profile petit
# Snapshot
lxc snapshot mon-conteneur snap0
lxc restore mon-conteneur snap0
Namespaces et cgroups#
Namespaces Linux#
Les namespaces sont le mécanisme noyau qui isole les ressources entre processus. Chaque conteneur (LXC ou Docker) dispose de ses propres namespaces :
Namespace |
Isolation |
|---|---|
pid |
Arbre des processus (le conteneur voit son propre PID 1) |
net |
Interfaces réseau, tables de routage, ports |
mnt |
Points de montage et arborescence de fichiers |
uts |
Nom d’hôte et nom de domaine |
ipc |
File de messages, sémaphores, mémoire partagée |
user |
UIDs/GIDs (user namespaces — rootless containers) |
cgroup |
Vue isolée de la hiérarchie cgroups |
time |
Horloge système isolée (noyau ≥ 5.6) |
cgroups v2#
Les cgroups (control groups) limitent et comptabilisent l’utilisation des ressources :
# Voir la hiérarchie cgroups d'un conteneur Docker
cat /sys/fs/cgroup/system.slice/docker-<id>.scope/cpu.max
# Vérifier les limites d'une VM KVM via libvirt
virsh schedinfo debian12
# Appliquer une limite CPU à une VM
virsh schedinfo debian12 --set vcpu_quota=50000
cgroups v1 vs v2
La version 2 des cgroups (unifiée) est activée par défaut dans les noyaux récents (≥ 4.5) et adoptée par défaut dans Debian 11, Ubuntu 22.04, Fedora 31+. Elle simplifie la hiérarchie (une seule arborescence au lieu de plusieurs sous-systèmes séparés) et améliore le support des user namespaces pour les conteneurs sans privilège.
VM vs conteneur#
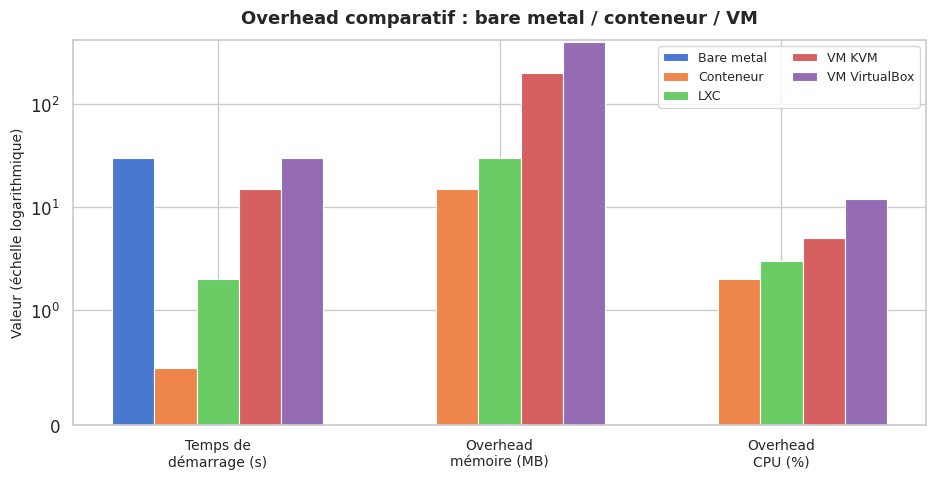
Tableau de synthèse#
Critère |
VM (KVM) |
LXC/LXD |
Docker |
|---|---|---|---|
Isolation |
Forte (hyperviseur) |
Moyenne (namespaces) |
Moyenne (namespaces) |
OS invité |
Kernel indépendant |
Kernel partagé |
Kernel partagé |
Démarrage |
10-30 s |
1-3 s |
< 1 s |
Overhead |
Élevé (RAM/CPU) |
Faible |
Très faible |
Snapshot |
Oui (qcow2) |
Oui |
Oui (layers) |
Réseau |
Bridge/NAT/SR-IOV |
Profils réseau |
Docker network |
Cas d’usage |
Multi-OS, isolation forte |
Environnements légers |
Microservices |
Pont vers Docker#
Pourquoi Docker a simplifié le workflow#
LXC existait avant Docker (2008 vs 2013). Docker n’a pas inventé les namespaces ni les cgroups. Sa révolution a été l”expérience développeur :
Image portable : une image Docker contient l’application et toutes ses dépendances. Elle tourne identiquement en développement, CI et production.
Dockerfile déclaratif :
FROM debian:12puis des étapes reproductibles.Registre central (Docker Hub, GitHub Container Registry) : partager une image se résume à
docker push/docker pull.Ecosystème : Docker Compose, Docker Swarm, puis Kubernetes ont standardisé l’orchestration des conteneurs.
Aujourd’hui, le moteur bas niveau d’exécution (containerd, CRI-O) n’utilise plus nécessairement Docker mais repose toujours sur les mêmes primitives : namespaces pour l’isolation et cgroups pour la limitation des ressources.
Docker et Kubernetes
Ce livre se concentre sur l’administration système Linux. L’écosystème Docker et l’orchestration Kubernetes font l’objet d’un volume dédié de cette série. Les concepts de namespaces et cgroups présentés ici constituent les fondations directes de ces outils.
Pont vers Docker (suite)#
Sécurité des conteneurs sans privilège (rootless)#
L’une des évolutions importantes de Docker et Podman est la possibilité de faire tourner des
conteneurs sans les droits root sur l’hôte, grâce aux user namespaces. L’utilisateur
uid=1000 à l’intérieur du conteneur est mappé sur un UID non-privilégié sur l’hôte.
# Vérifier le support user namespaces
sysctl kernel.unprivileged_userns_clone # doit valoir 1
# Lancer un conteneur Docker en rootless
dockerd-rootless-setuptool.sh install
docker run --rm -it ubuntu:22.04 bash
# Podman (rootless natif)
podman run --rm -it ubuntu:22.04 bash
# Podman avec LXC — conteneur rootless
lxc launch ubuntu:22.04 app --config security.nesting=true
Comparaison des runtimes de conteneurs#
Runtime |
Standard |
Rootless |
Cas d’usage |
|---|---|---|---|
Docker |
OCI |
Oui (expérimental) |
Développement, CI/CD |
Podman |
OCI |
Oui (natif) |
Production RHEL/Fedora |
containerd |
OCI |
Partiel |
Nœuds Kubernetes |
CRI-O |
CRI/OCI |
Partiel |
Kubernetes (intégration directe) |
LXC/LXD |
Propre |
Oui |
Conteneurs système |
Réseau entre conteneurs et VMs#
En environnement hybride, VMs KVM et conteneurs Docker coexistent sur le même hôte. La communication se fait via des bridges Linux et des réseaux overlay.
# Connecter un conteneur Docker au bridge KVM "default" (NAT)
docker network create --driver bridge \
--subnet 192.168.122.0/24 \
--gateway 192.168.122.1 \
kvm-bridge
docker run --network kvm-bridge monimage
Isolation et performance
Pour les charges de travail nécessitant une isolation maximale (multi-locataire, PCI-DSS, données sensibles), les VMs KVM restent la solution de référence. Pour les applications cloud-native stateless, les conteneurs offrent une densité et une agilité supérieures. En pratique, les deux coexistent dans la majorité des environnements de production modernes.
Outils de surveillance des VMs et conteneurs#
# Surveiller les VMs KVM en temps réel
virt-top
# Statistiques détaillées d'une VM
virsh domstats debian12 --all
# Ressources consommées par les conteneurs LXD
lxc info --resources mon-conteneur
# Voir les namespaces d'un processus conteneurisé
ls -la /proc/$(pgrep nginx | head -1)/ns/
Résumé#
La virtualisation et les conteneurs partagent les mêmes primitives noyau (namespaces, cgroups) mais offrent des compromis différents :
VM KVM |
LXC/LXD |
Docker |
|
|---|---|---|---|
Isolation |
Maximale |
Bonne |
Bonne |
Performance |
Bonne |
Excellente |
Excellente |
Flexibilité OS |
Totale |
Linux seulement |
Linux seulement |
Cas idéal |
Multi-OS, sécurité stricte |
Environnements légers |
Microservices |
La pile KVM + libvirt reste la référence pour héberger des VMs sur Linux en production. LXD convient aux environnements de développement et aux services simples. Docker et Kubernetes dominent le déploiement applicatif moderne.
Prochaine étape
Le chapitre 21 aborde l’automatisation et la maintenance : mises à jour non-surveillées, surveillance de l’intégrité, sauvegardes automatisées avec BorgBackup, et runbooks opérationnels.