Analyse de logs#
Architecture de logging Linux#
Le protocole syslog (RFC 5424)#
Tous les systèmes Linux modernes s’appuient sur le protocole syslog pour structurer les événements système. Chaque message syslog porte deux attributs de classification :
Facility (source) : kern, user, mail, daemon, auth, syslog, lpr, news, uucp, cron, local0 à local7
Severity (niveau de priorité) :
Niveau |
Valeur |
Signification |
|---|---|---|
emerg |
0 |
Système inutilisable |
alert |
1 |
Action immédiate requise |
crit |
2 |
Condition critique |
err |
3 |
Erreur |
warning |
4 |
Avertissement |
notice |
5 |
Condition normale mais notable |
info |
6 |
Message informatif |
debug |
7 |
Messages de débogage |
La priorité numérique d’un message est facility × 8 + severity.
rsyslog et journald — deux mondes complémentaires#
rsyslog est le daemon syslog traditionnel. Il reçoit les messages via le socket Unix /dev/log, les filtre et les écrit dans des fichiers texte sous /var/log/. Il supporte des règles complexes, le forwarding réseau (UDP/TCP/TLS) et plusieurs formats de sortie.
journald (composant de systemd) collecte les messages de toutes les sources — noyau, services systemd, applications via l’API sd_journal — et les stocke dans un format binaire indexé sous /var/log/journal/. Ce format permet des requêtes structurées rapides que les fichiers texte ne permettent pas.
Les deux coexistent : journald peut retransmettre ses messages à rsyslog via /run/systemd/journal/syslog, permettant à rsyslog de continuer à écrire les fichiers classiques tout en bénéficiant de la collecte unifiée de journald.
Principaux fichiers /var/log/#
Fichier |
Contenu |
|---|---|
|
Messages syslog généraux (Debian/Ubuntu) |
|
Équivalent sur RHEL/CentOS |
|
Authentifications, sudo, PAM (Debian/Ubuntu) |
|
Équivalent sur RHEL/CentOS |
|
Messages du noyau |
|
Opérations APT/dpkg |
|
Accès et erreurs Nginx |
|
Journal binaire systemd |
journalctl avancé#
journalctl est l’interface de requête pour le journal systemd. Sa puissance réside dans sa capacité à filtrer sur des champs structurés plutôt que sur du texte brut.
Filtres temporels et par unité#
# Logs du service nginx depuis 2 heures
journalctl -u nginx.service --since "2 hours ago"
# Plage horaire précise
journalctl --since "2026-03-24 08:00:00" --until "2026-03-24 12:00:00"
# Niveau de priorité : erreurs et plus grave
journalctl -p err
# Combinaison : erreurs nginx d'aujourd'hui
journalctl -u nginx -p err --since today
Champs structurés#
# Filtrer sur le PID d'un processus
journalctl _PID=1234
# Filtrer sur l'unité systemd (champ interne)
journalctl _SYSTEMD_UNIT=sshd.service
# Tous les logs d'un UID donné
journalctl _UID=1000
# Logs du noyau (équivalent dmesg)
journalctl -k
Formats de sortie#
# Format JSON (une ligne par entrée) — pour le parsing
journalctl -u sshd --since "1 hour ago" --output=json | head -3
# Format court avec timestamp précis (microsecondes)
journalctl -u sshd --output=short-precise
# Afficher les curseurs (utile pour reprendre la lecture)
journalctl --show-cursor
# Suivre en temps réel
journalctl -f -u nginx
# Exemple de sortie JSON (extrait)
{"__REALTIME_TIMESTAMP":"1711270800123456","MESSAGE":"Accepted publickey for alice",
"_HOSTNAME":"srv01","_SYSTEMD_UNIT":"sshd.service","PRIORITY":"6"}
Curseurs — reprise de lecture#
Les curseurs journald permettent de reprendre la lecture exactement où on s’était arrêté, sans risquer de manquer ou de dupliquer des entrées :
# Sauvegarder le curseur courant
journalctl --show-cursor 2>&1 | tail -1 > /tmp/curseur_journal.txt
# Reprendre depuis ce curseur
journalctl --after-cursor="$(cat /tmp/curseur_journal.txt)"
Persistance du journal
Par défaut, sur certaines distributions, le journal n’est pas persisté entre les redémarrages (/run/log/journal/ est en RAM). Pour activer la persistance : mkdir -p /var/log/journal && systemd-tmpfiles --create --prefix /var/log/journal && systemctl restart systemd-journald.
rsyslog — configuration et filtrage#
Structure de /etc/rsyslog.conf#
# Modules d'entrée
module(load="imuxsock") # socket Unix /dev/log
module(load="imklog") # messages noyau via /proc/kmsg
module(load="imjournal") # depuis journald
# Règles : facility.severity action
auth,authpriv.* /var/log/auth.log
*.*;auth,authpriv.none /var/log/syslog
kern.* /var/log/kern.log
cron.* /var/log/cron.log
*.emerg :omusrmsg:* # broadcast tous utilisateurs
Templates — format de sortie personnalisé#
# Template JSON pour forwarding vers un SIEM
template(name="JsonFormat" type="list") {
constant(value="{")
property(name="timereported" dateFormat="rfc3339" format="jsonf")
constant(value=",")
property(name="hostname" format="jsonf")
constant(value=",")
property(name="syslogseverity-text" format="jsonf")
constant(value=",")
property(name="msg" format="jsonf")
constant(value="}\n")
}
*.* action(type="omfile" file="/var/log/all.json" template="JsonFormat")
Forwarding réseau vers un syslog distant#
# Forwarding TCP vers un collecteur central (port 514)
*.* action(type="omfwd"
target="192.168.1.100"
port="514"
protocol="tcp"
action.resumeRetryCount="100"
queue.type="linkedList"
queue.size="10000"
queue.filename="fwd_queue")
L’utilisation d’une file d’attente locale (queue) garantit qu’aucun message n’est perdu si le collecteur distant est temporairement indisponible.
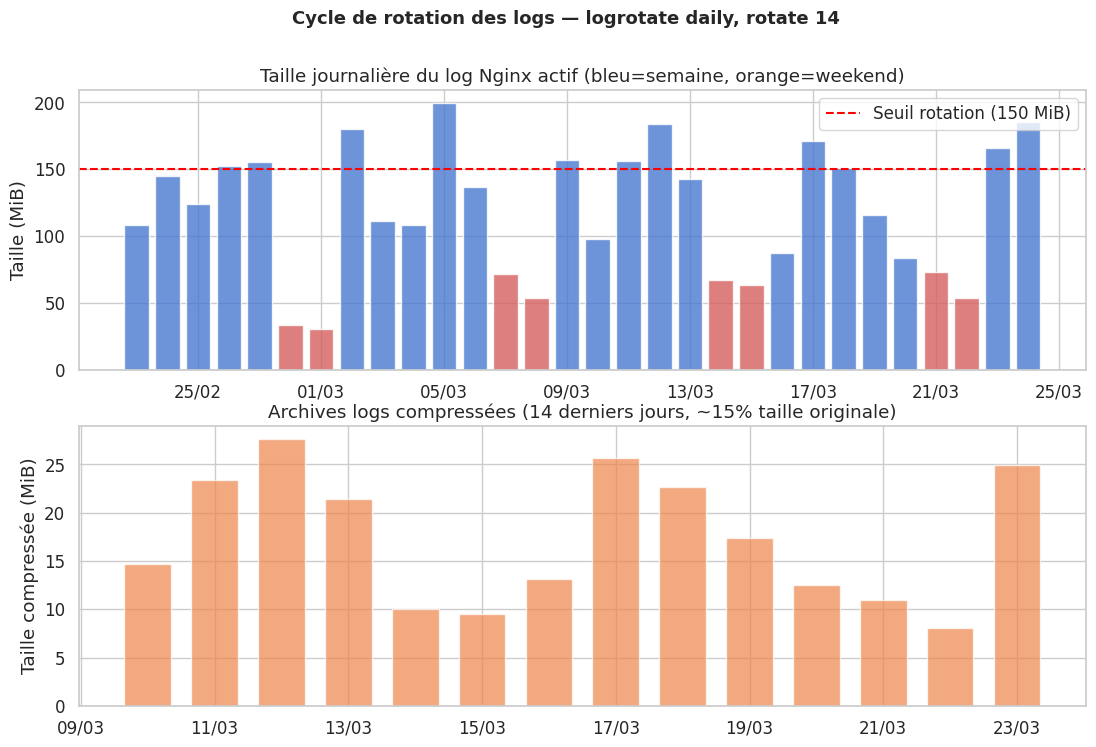
logrotate — rotation des fichiers de logs#
Sans rotation, les fichiers de logs grossissent indéfiniment jusqu’à saturer le disque. logrotate est le daemon chargé de les archiver et compresser périodiquement.
Configuration globale /etc/logrotate.conf#
# Rotation hebdomadaire par défaut
weekly
# Garder 4 semaines d'archives
rotate 4
# Compresser les archives
compress
# Ne pas lever d'erreur si le fichier est absent
missingok
# Ne pas tourner si le fichier est vide
notifempty
# Inclure les configurations des packages
include /etc/logrotate.d
Exemple /etc/logrotate.d/nginx#
/var/log/nginx/*.log {
daily
missingok
rotate 14
compress
delaycompress
notifempty
create 0640 www-data adm
sharedscripts
postrotate
if [ -f /run/nginx.pid ]; then
kill -USR1 $(cat /run/nginx.pid)
fi
endscript
}
Directives importantes :
Directive |
Effet |
|---|---|
|
Fréquence de rotation |
|
Rotation quand le fichier dépasse 100 MiB |
|
Garder N archives |
|
Compresser avec gzip |
|
Compresser l’archive précédente (pas la dernière) |
|
Script exécuté après rotation (ex : rechargement daemon) |
|
Copier puis vider le fichier original (pour les processus qui ne supportent pas SIGHUP) |
# Tester sans appliquer (-d = dry-run)
logrotate -d /etc/logrotate.d/nginx
# Forcer la rotation immédiatement
logrotate -f /etc/logrotate.d/nginx
delaycompress et les démons
delaycompress est nécessaire quand le daemon (Nginx, Apache) garde le fichier ouvert après rotation. Sans cette directive, le daemon écrirait dans le fichier compressé — résultant en un fichier corrompu et des logs perdus. La directive postrotate envoie SIGUSR1 à Nginx pour qu’il rouvre ses fichiers de log sur le nouveau fichier vide.
Analyse de logs Nginx — Combined Log Format#
Format Combined Log#
Le format par défaut de Nginx est le Combined Log Format :
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent"
Exemple :
203.0.113.42 - alice [24/Mar/2026:14:32:01 +0100] "GET /api/users HTTP/1.1" 200 1452 "https://example.com/" "Mozilla/5.0"
Génération de logs simulés et analyse#
import random
from datetime import datetime, timedelta
random.seed(42)
# --- Génération de données simulées ---
ips = [
"203.0.113.42", "198.51.100.7", "192.0.2.15",
"203.0.113.99", "198.51.100.33", "10.0.0.5",
"172.16.0.12", "203.0.113.42", "198.51.100.7",
"203.0.113.42",
]
urls = [
"/api/users", "/", "/static/app.js", "/api/orders",
"/login", "/api/products", "/admin", "/favicon.ico",
"/api/users/42", "/static/style.css",
]
codes = [200]*60 + [304]*15 + [404]*12 + [500]*5 + [301]*5 + [403]*3
agents = [
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36',
'curl/7.88.1',
'python-requests/2.31.0',
'Googlebot/2.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64)',
]
debut = datetime(2026, 3, 24, 0, 0, 0)
lignes_log = []
regex_pattern = (
r'(?P<ip>\S+) - (?P<user>\S+) \[(?P<time>[^\]]+)\] '
r'"(?P<method>\S+) (?P<url>\S+) \S+" '
r'(?P<status>\d+) (?P<bytes>\d+)'
)
for i in range(500):
ts = debut + timedelta(seconds=random.randint(0, 86399))
ip = random.choice(ips)
url = random.choice(urls)
code = random.choice(codes)
bytes_ = random.randint(200, 50000)
agent = random.choice(agents)
methode = "GET" if url != "/login" else random.choice(["GET", "POST"])
ligne = (f'{ip} - - [{ts.strftime("%d/%b/%Y:%H:%M:%S")} +0100] '
f'"{methode} {url} HTTP/1.1" {code} {bytes_} '
f'"-" "{agent}"')
lignes_log.append(ligne)
# --- Parsing ---
records = []
for ligne in lignes_log:
m = re.match(regex_pattern, ligne)
if m:
records.append({
"ip" : m.group("ip"),
"methode": m.group("method"),
"url" : m.group("url"),
"status" : int(m.group("status")),
"bytes" : int(m.group("bytes")),
"heure" : int(re.search(r':(\d{2}):', ligne).group(1))
if re.search(r':(\d{2}):', ligne) else 0,
})
df_nginx = pd.DataFrame(records)
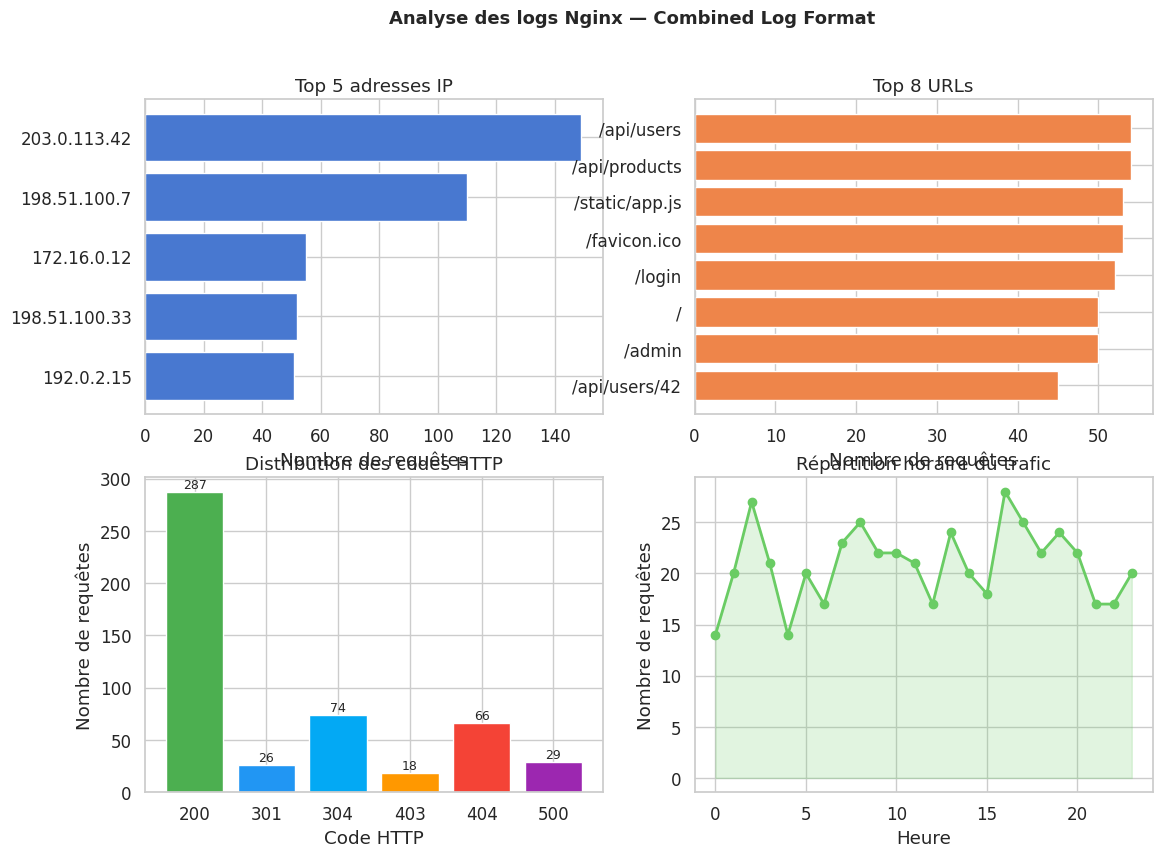
print(f"Lignes parsées : {len(df_nginx)}")
print(df_nginx["status"].value_counts().rename("Nombre de requêtes").rename_axis("Code HTTP"))
Lignes parsées : 500
Code HTTP
200 287
304 74
404 66
500 29
301 26
403 18
Name: Nombre de requêtes, dtype: int64
Analyse de logs SSH/auth#
Structure de /var/log/auth.log#
Mar 24 14:32:01 srv01 sshd[2341]: Accepted publickey for alice from 192.168.1.10 port 52341 ssh2
Mar 24 14:35:12 srv01 sshd[2342]: Failed password for root from 203.0.113.99 port 44231 ssh2
Mar 24 14:35:13 srv01 sshd[2342]: Failed password for root from 203.0.113.99 port 44231 ssh2
Mar 24 14:35:14 srv01 sshd[2342]: Failed password for invalid user admin from 203.0.113.99 port 44233 ssh2
import re
from collections import Counter
# Tentative de lecture du vrai fichier, sinon simulation
auth_lines = []
for chemin in ["/var/log/auth.log", "/var/log/secure"]:
if os.path.exists(chemin):
try:
with open(chemin, errors="replace") as f:
auth_lines = f.readlines()
if auth_lines:
print(f"Fichier réel lu : {chemin} ({len(auth_lines)} lignes)")
break
except PermissionError:
pass
if not auth_lines:
print("Fichier auth.log absent ou inaccessible — utilisation de données simulées")
random.seed(0)
ips_attaquants = ["203.0.113.99", "198.51.100.200", "192.0.2.88", "10.10.10.5"]
utilisateurs_cibles = ["root", "admin", "ubuntu", "oracle", "test", "pi"]
utilisateurs_legit = ["alice", "bob", "charlie"]
debut_sim = datetime(2026, 3, 24, 0, 0, 0)
for i in range(800):
ts = debut_sim + timedelta(seconds=random.randint(0, 86399))
ts_str = ts.strftime("%b %d %H:%M:%S")
if random.random() < 0.85:
ip = random.choice(ips_attaquants)
user = random.choice(utilisateurs_cibles)
pid = random.randint(2000, 9999)
auth_lines.append(
f"{ts_str} srv01 sshd[{pid}]: Failed password for {user} "
f"from {ip} port {random.randint(30000, 65535)} ssh2\n"
)
else:
ip = f"192.168.1.{random.randint(10, 50)}"
user = random.choice(utilisateurs_legit)
pid = random.randint(2000, 9999)
auth_lines.append(
f"{ts_str} srv01 sshd[{pid}]: Accepted publickey for {user} "
f"from {ip} port {random.randint(40000, 65535)} ssh2\n"
)
# Parsing
re_failed = re.compile(r"Failed password for (?:invalid user )?(\S+) from (\S+)")
re_accepted = re.compile(r"Accepted \S+ for (\S+) from (\S+)")
echecs = []
succes = []
for ligne in auth_lines:
m = re_failed.search(ligne)
if m:
echecs.append({"user": m.group(1), "ip": m.group(2)})
continue
m = re_accepted.search(ligne)
if m:
succes.append({"user": m.group(1), "ip": m.group(2)})
df_echecs = pd.DataFrame(echecs) if echecs else pd.DataFrame(columns=["user", "ip"])
df_succes = pd.DataFrame(succes) if succes else pd.DataFrame(columns=["user", "ip"])
print(f"\nTentatives échouées : {len(df_echecs)}")
print(f"Connexions réussies : {len(df_succes)}")
if not df_echecs.empty:
print("\nTop 5 IPs attaquantes :")
print(df_echecs["ip"].value_counts().head(5).to_string())
print("\nTop 5 comptes ciblés :")
print(df_echecs["user"].value_counts().head(5).to_string())
Fichier auth.log absent ou inaccessible — utilisation de données simulées
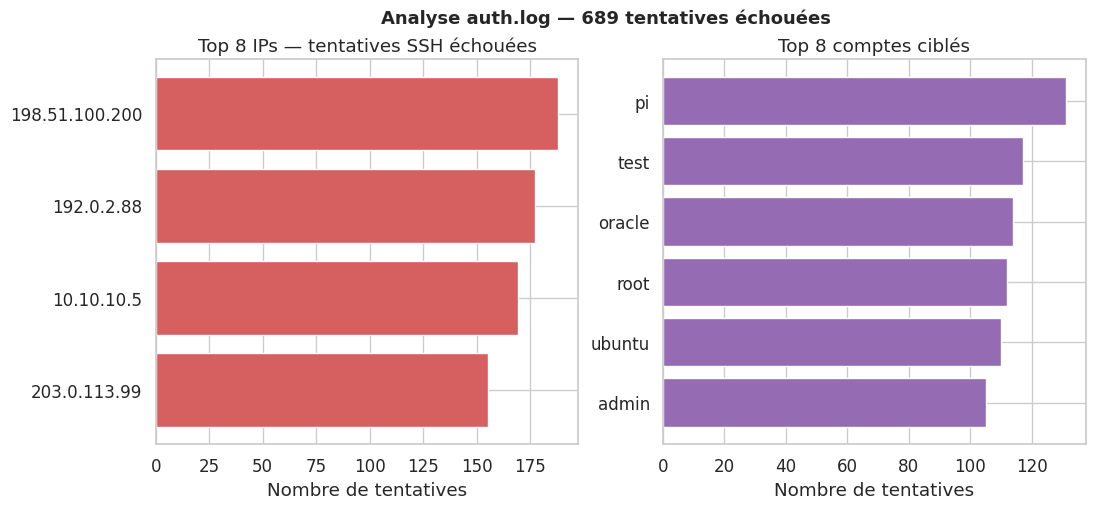
Tentatives échouées : 689
Connexions réussies : 111
Top 5 IPs attaquantes :
ip
198.51.100.200 188
192.0.2.88 177
10.10.10.5 169
203.0.113.99 155
Top 5 comptes ciblés :
user
pi 131
test 117
oracle 114
root 112
ubuntu 110
fail2ban — réponse automatique aux attaques
fail2ban surveille les logs d’authentification et bannit automatiquement les IPs dépassant un seuil de tentatives échouées via des règles iptables/nftables. Configuration de base : maxretry = 5 sur une fenêtre de findtime = 600s, bannissement de bantime = 3600s. Les tentatives SSH sont la première source de bruit dans auth.log sur tout serveur exposé à Internet.
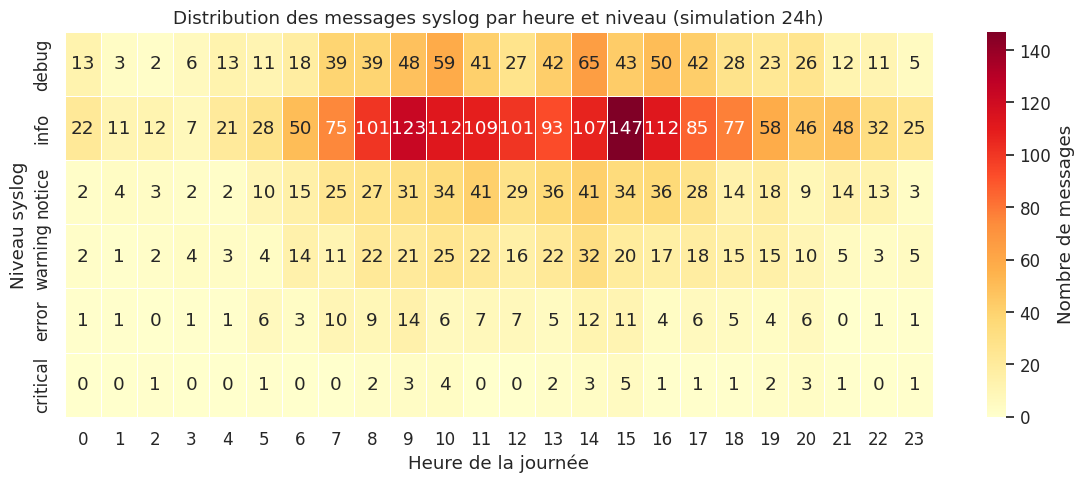
Heatmap des niveaux de logs par heure#
Centralisation — ELK Stack#
Architecture ELK#
La centralisation des logs est indispensable dès qu’un parc dépasse quelques serveurs. La pile ELK (Elastic Stack) est la référence :
┌─────────┐ ┌──────────┐ ┌─────────────┐ ┌──────────┐ ┌────────┐
│ Serveur │──▶│ Filebeat │──▶│ Logstash │──▶│Elasticsearch│──▶│Kibana │
│ (logs) │ │(collecte)│ │(parse/enrich)│ │ (stockage) │ │(viz) │
└─────────┘ └──────────┘ └─────────────┘ └──────────┘ └────────┘
Filebeat : agent léger installé sur chaque serveur, lit les fichiers de log et les envoie à Logstash ou directement à Elasticsearch
Logstash : pipeline de traitement (input → filter → output) avec des centaines de plugins. Permet le parsing (grok), l’enrichissement (GeoIP, DNS), la normalisation des champs
Elasticsearch : moteur de recherche et d’indexation distribué, stocke les documents JSON
Kibana : interface web de visualisation, dashboards, alertes (Watcher), Machine Learning
Configuration Filebeat minimale#
# /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
fields:
service: nginx
env: production
output.logstash:
hosts: ["logstash.interne:5044"]
Pipeline Logstash pour logs Nginx#
input {
beats { port => 5044 }
}
filter {
if [fields][service] == "nginx" {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
geoip { source => "clientip" }
date { match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] }
mutate { remove_field => ["message", "agent", "ecs"] }
}
}
output {
elasticsearch {
hosts => ["http://elasticsearch:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
Alertes sur logs#
tail -f et grep en pipeline#
# Surveiller les erreurs 500 en temps réel
tail -f /var/log/nginx/access.log | grep --line-buffered '" 500 '
# Compter les erreurs par minute
tail -f /var/log/nginx/access.log | \
awk '/HTTP\/[0-9.]+" [5][0-9]{2}/ {count++} NR%100==0 {print count " erreurs/100 lignes"; count=0}'
Script de surveillance avec webhook#
#!/bin/bash
# /usr/local/bin/watch_errors.sh
WEBHOOK="https://hooks.slack.com/services/XXX/YYY/ZZZ"
FICHIER="/var/log/nginx/error.log"
SEUIL=10
FENETRE=60 # secondes
while true; do
ERREURS=$(tail -n 200 "$FICHIER" | \
awk -v limite="$(date -d "-${FENETRE} seconds" +%s)" \
'BEGIN{c=0} {cmd="date -d \""$1" "$2"\" +%s 2>/dev/null"; cmd | getline ts; if(ts > limite) c++} END{print c}')
if [ "$ERREURS" -gt "$SEUIL" ]; then
MSG="⚠ ${ERREURS} erreurs Nginx dans les ${FENETRE}s sur $(hostname)"
curl -s -X POST -H 'Content-type: application/json' \
--data "{\"text\":\"${MSG}\"}" "$WEBHOOK"
fi
sleep 30
done
journalctl -f avec filtre par priorité#
# Suivre uniquement les erreurs et plus grave, en JSON
journalctl -f -p err --output=json | \
python3 -c "
import sys, json
for line in sys.stdin:
try:
d = json.loads(line)
print(f\"[{d.get('_HOSTNAME','?')}] {d.get('_SYSTEMD_UNIT','kernel')}: {d.get('MESSAGE','')}\")
except: pass
"
Visualisation de la rotation des logs#
Résumé#
L’analyse de logs en Linux mobilise deux familles d’outils : les outils de collecte/stockage (journald, rsyslog, logrotate) et les outils d’analyse (journalctl, grep/awk, Python, ELK). La maîtrise des deux est nécessaire pour diagnostiquer efficacement les incidents en production.
Points à retenir :
journald offre des requêtes structurées puissantes grâce aux champs indexés ; préférer
--output=jsonpour le parsing programmatique.rsyslog reste indispensable pour le forwarding réseau, la centralisation et l’intégration avec des SIEMs.
logrotate doit être configuré avant que les logs grossissent — le
postrotateetdelaycompresssont les directives les plus souvent oubliées.Le Combined Log Format de Nginx/Apache se parse facilement avec une regex standard ; l’analyse statistique des codes HTTP et des IPs détecte la majorité des incidents.
Les logs SSH dans
auth.logsont un indicateur direct de la surface d’attaque exposée — automatiser leur surveillance avec fail2ban.À l’échelle, la pile ELK (Filebeat + Logstash + Elasticsearch + Kibana) est la solution standard pour la centralisation et la corrélation multi-sources.
Outil |
Rôle |
Usage typique |
|---|---|---|
journald |
Collecte structurée systemd |
|
rsyslog |
Filtrage et forwarding |
Centralisation syslog réseau |
logrotate |
Archivage et compression |
Automatisation quotidienne |
Python/pandas |
Analyse statistique |
Rapports, détection d’anomalies |
ELK Stack |
Centralisation à l’échelle |
Parcs de > 10 serveurs |