RAID et sauvegarde#
Concepts RAID#
Le RAID (Redundant Array of Independent Disks) désigne un ensemble de techniques permettant de combiner plusieurs disques physiques en une unité logique unique. L’objectif est double et souvent contradictoire : augmenter les performances d’entrées/sorties ou accroître la fiabilité par redondance — rarement les deux simultanément sans coût supplémentaire.
Redondance vs performance#
La redondance consiste à stocker les mêmes données sur plusieurs disques de sorte qu’une panne d’un ou plusieurs disques ne provoque aucune perte de données. Le prix à payer est une capacité utile réduite.
La performance, au contraire, tire parti du parallélisme des disques. En distribuant les lectures et écritures sur plusieurs unités simultanément, on peut multiplier le débit par le nombre de disques. Cette approche n’apporte aucune protection contre les pannes.
Les IOPS (Input/Output Operations Per Second) constituent la métrique principale pour évaluer les performances d’un array RAID. En lecture, la plupart des niveaux RAID permettent de paralléliser les accès. En écriture, les niveaux avec parité introduisent une pénalité due au calcul et à l’écriture de la parité.
IOPS et débit
Les IOPS mesurent le nombre d’opérations indépendantes par seconde, pertinent pour les charges de travail aléatoires (bases de données, journaux). Le débit séquentiel (Mo/s) est plus pertinent pour les transferts de gros fichiers. Les deux métriques sont indépendantes et un RAID peut exceller sur l’une sans améliorer l’autre.
RAID matériel vs RAID logiciel#
Le RAID matériel repose sur un contrôleur dédié (carte RAID) qui présente au système d’exploitation une unité logique unique. Le processeur principal est déchargé du calcul de parité, et la carte dispose généralement d’un cache protégé par batterie de secours. L’inconvénient est le coût élevé et la dépendance au fabricant : un contrôleur défaillant peut rendre les données inaccessibles même si tous les disques sont intacts.
Le RAID logiciel délègue la gestion au noyau du système d’exploitation. Sous Linux, mdadm implémente tous les niveaux RAID courants directement dans le noyau. Les avantages sont la portabilité (un array peut être déplacé sur n’importe quelle machine Linux), la transparence et l’absence de coût matériel. La charge CPU reste négligeable sur les systèmes modernes, même pour le calcul de parité RAID 5/6.
Faux RAID (BIOS RAID / RAID hybride)
Les chipsets de cartes mères proposent souvent un « RAID » configurable dans le BIOS. Il s’agit en réalité d’un RAID logiciel piloté par un pilote propriétaire. Sous Linux, cette fonctionnalité est généralement problématique : les données peuvent devenir inaccessibles lors d’une réinstallation ou d’un changement de distribution. Préférez mdadm pour une solution robuste et portable.
Niveaux RAID#
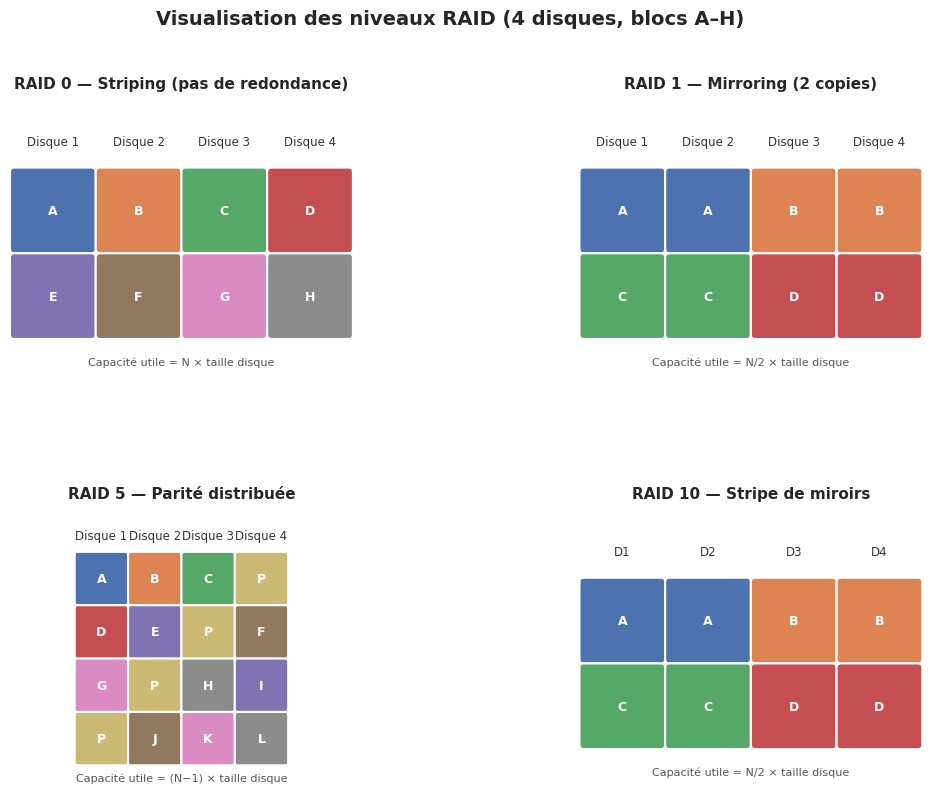
RAID 0 — Striping#
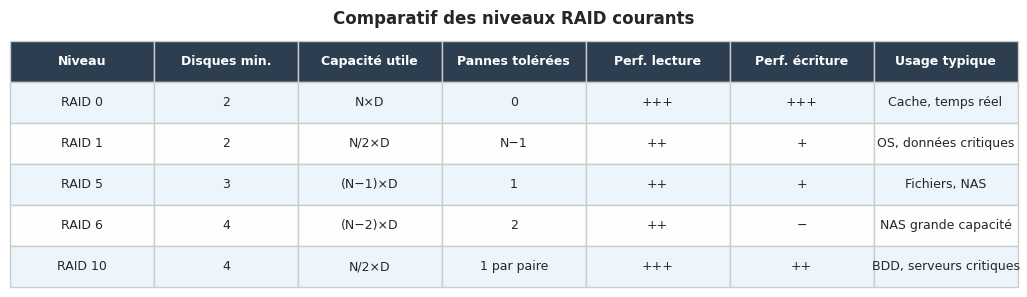
Le RAID 0 distribue les données en blocs alternés sur tous les disques. Il n’y a aucune redondance : la perte d’un seul disque détruit l’intégralité des données. En contrepartie, les débits séquentiels sont théoriquement multipliés par le nombre de disques. Le RAID 0 est réservé aux contextes où la performance prime et où les données sont facilement reconstituables (caches, données éphémères).
RAID 1 — Mirroring#
Le RAID 1 maintient une copie identique des données sur chaque disque du groupe. Avec deux disques, la capacité utile est divisée par deux. Les performances en lecture peuvent être améliorées par la lecture en parallèle sur les deux disques. Le RAID 1 tolère la panne de N-1 disques si tous les disques survivants contiennent les mêmes données.
RAID 5 — Parité distribuée#
Le RAID 5 répartit les données et la parité sur tous les disques du groupe (minimum 3 disques). La parité est calculée par XOR entre les blocs de données du même rang. La capacité utile est (N-1) × taille d'un disque. Le RAID 5 tolère la panne d’un seul disque. La reconstruction après remplacement met la charge du contrôleur à son maximum pendant plusieurs heures ou jours sur des grands volumes.
Risque de double panne lors de la reconstruction
La reconstruction RAID 5 soumet les disques restants à une charge maximale prolongée. Sur des disques de grande capacité (8 To et plus), le risque de panne d’un second disque pendant la reconstruction est significatif. Pour les volumes critiques, RAID 6 ou RAID 10 sont préférables.
RAID 6 — Double parité#
Le RAID 6 utilise deux blocs de parité indépendants par bande, permettant de tolérer la panne simultanée de deux disques. Il requiert au minimum 4 disques et la capacité utile est (N-2) × taille d'un disque. La pénalité en écriture est plus élevée qu’en RAID 5. Il est aujourd’hui le standard pour les NAS de grande capacité.
RAID 10 — Stripe de miroirs#
Le RAID 10 (ou RAID 1+0) combine le mirroring et le striping : les disques sont regroupés par paires en miroirs, et les paires sont stripées. Il requiert un minimum de 4 disques. La capacité utile est de 50 %. Les performances en lecture et en écriture sont excellentes, et il tolère plusieurs pannes simultanées à condition qu’elles ne touchent pas les deux disques d’une même paire.
Tableau comparatif#
mdadm — RAID logiciel Linux#
mdadm (multiple device admin) est l’outil de référence pour la gestion du RAID logiciel sous Linux. Il crée et administre des périphériques md (multiple device) qui apparaissent comme /dev/md0, /dev/md1, etc.
Création d’un array#
# Création d'un RAID 5 avec 3 disques
mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb /dev/sdc /dev/sdd
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
# Création d'un RAID 1 avec disque de rechange (spare)
mdadm --create /dev/md1 --level=1 --raid-devices=2 \
--spare-devices=1 /dev/sde /dev/sdf /dev/sdg
Après la création, le noyau synchronise immédiatement les disques en arrière-plan. L’array est utilisable pendant cette synchronisation initiale (dite « resync »), mais ses performances sont dégradées.
Surveillance avec /proc/mdstat#
cat /proc/mdstat
Personalities : [raid1] [raid5] [raid6]
md0 : active raid5 sdd[2] sdc[1] sdb[0]
2929886208 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
md1 : active raid1 sdf[1] sde[0]
976773168 blocks super 1.2 [2/2] [UU]
spare: sdg[2]
Le champ [UUU] indique l’état de chaque disque : U (Up, opérationnel) ou _ (défaillant ou absent). mdadm --detail /dev/md0 fournit des informations plus complètes, notamment l’UUID de l’array, l’état de la reconstruction et les informations par disque.
Reconstruction après panne#
# Simulation de la défaillance d'un disque
mdadm /dev/md0 --fail /dev/sdb
# Retrait du disque défaillant
mdadm /dev/md0 --remove /dev/sdb
# Ajout du disque de remplacement
mdadm /dev/md0 --add /dev/sdh
mdadm: added /dev/sdh
La reconstruction démarre automatiquement. Sa progression est visible dans /proc/mdstat avec une barre de progression et une estimation du temps restant.
# Surveillance de la reconstruction en temps réel
watch -n 2 cat /proc/mdstat
md0 : active raid5 sdh[3] sdd[2] sdc[1]
2929886208 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[=========>...........] recovery = 47.3% (692813824/1464943104) finish=68.2min speed=188645K/sec
Persistance avec mdadm.conf#
Pour que les arrays soient automatiquement assemblés au démarrage, leur configuration doit être enregistrée dans /etc/mdadm/mdadm.conf.
# Génération automatique de la configuration
mdadm --detail --scan >> /etc/mdadm/mdadm.conf
# Mise à jour de l'initramfs pour le démarrage
update-initramfs -u
Vérifier mdadm.conf après modification
Après toute modification de /etc/mdadm/mdadm.conf, reconstruire l’initramfs est indispensable. Sans cette étape, le système peut ne pas assembler les arrays au démarrage, rendant potentiellement le système inaccessible si la partition racine est sur un array RAID.
# Contenu typique de /etc/mdadm/mdadm.conf
ARRAY /dev/md0 metadata=1.2 name=serveur:0 UUID=b4a95e7c:8f3d1a20:44c9e2b1:7f8d3c11
ARRAY /dev/md1 metadata=1.2 name=serveur:1 UUID=3d8f2c10:aa91b445:1c3e9f72:8b2d40e5
Stratégie de sauvegarde#
La règle 3-2-1#
La règle 3-2-1 est le standard minimal de toute politique de sauvegarde sérieuse :
3 copies des données (l’original + 2 sauvegardes)
2 types de supports différents (disque interne, NAS, bande, cloud…)
1 copie hors site (résistance aux sinistres physiques : incendie, inondation, vol)
Le RAID n’est pas une sauvegarde
Un array RAID protège contre la défaillance matérielle de disques, mais pas contre la suppression accidentelle, la corruption logicielle, les ransomwares ou les erreurs humaines. Ces événements se propagent instantanément sur tous les disques d’un RAID. Le RAID améliore la disponibilité ; la sauvegarde protège les données.
RTO et RPO#
Deux métriques définissent les objectifs d’une stratégie de sauvegarde :
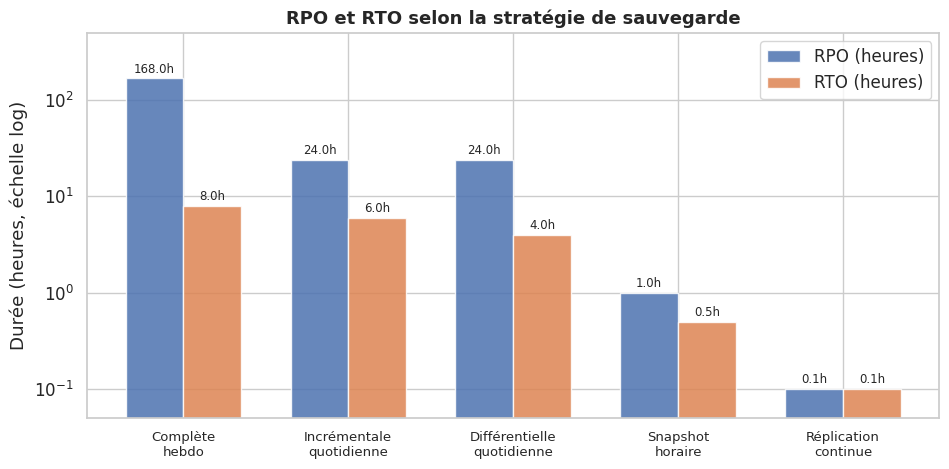
RPO (Recovery Point Objective) : perte de données maximale acceptable, exprimée en temps. Un RPO de 24h signifie qu’on accepte de perdre jusqu’à 24h de données. Il détermine la fréquence des sauvegardes.
RTO (Recovery Time Objective) : durée maximale acceptable pour restaurer le service après un incident. Un RTO de 4h signifie que le système doit être opérationnel en moins de 4 heures. Il détermine les procédures et outils de restauration.
Types de sauvegarde#
Sauvegarde complète : copie intégrale de toutes les données sélectionnées. Elle est autonome (aucun autre fichier n’est nécessaire pour la restauration) mais coûteuse en espace et en temps.
Sauvegarde incrémentale : copie uniquement les données modifiées depuis la dernière sauvegarde (complète ou incrémentale). Rapide à créer, elle nécessite la sauvegarde complète et toute la chaîne des incrémentales pour une restauration complète.
Sauvegarde différentielle : copie les données modifiées depuis la dernière sauvegarde complète. Elle croît en taille au fil du temps mais ne nécessite que deux éléments pour la restauration : la complète et la dernière différentielle.
rsync — synchronisation de fichiers#
rsync est l’outil de synchronisation incrémentale par excellence sous Linux. Son algorithme de delta transfer identifie les blocs modifiés et ne transfère que les différences, économisant temps et bande passante.
Options essentielles#
# Synchronisation locale avec archivage
rsync -avz /source/ /destination/
Option |
Signification |
|---|---|
|
Mode archive : récursif, préserve permissions, timestamps, liens symboliques, propriétaire |
|
Verbeux : affiche les fichiers transférés |
|
Compression à la volée (utile sur réseau lent) |
|
Supprime dans la destination les fichiers absents de la source |
|
Simule sans modifier (indispensable pour valider avant exécution) |
|
Affiche la progression fichier par fichier |
|
Exclut des fichiers ou répertoires selon un motif |
Synchronisation distante#
rsync utilise SSH comme transport par défaut pour les transferts distants. La syntaxe est similaire à SCP mais bien plus efficace pour les synchronisations répétées.
# Sauvegarde vers un serveur distant
rsync -avz --delete /data/ user@backup-server:/mnt/backups/data/
# Restauration depuis le serveur distant
rsync -avz user@backup-server:/mnt/backups/data/ /data/
# Avec une clé SSH spécifique et un port non-standard
rsync -avz -e "ssh -i /root/.ssh/backup_key -p 2222" \
/data/ user@backup-server:/mnt/backups/data/
Sauvegardes incrémentales avec –link-dest#
L’option --link-dest permet de créer des sauvegardes complètes apparentes sans dupliquer les fichiers inchangés grâce aux liens durs (hard links). Chaque répertoire de sauvegarde contient l’intégralité des fichiers, mais seuls les fichiers modifiés occupent réellement de l’espace supplémentaire.
# Structure de sauvegarde quotidienne avec hard links
TODAY=$(date +%Y-%m-%d)
YESTERDAY=$(date -d "yesterday" +%Y-%m-%d)
BACKUP_ROOT=/mnt/backups
rsync -avz --delete \
--link-dest="${BACKUP_ROOT}/${YESTERDAY}" \
/data/ "${BACKUP_ROOT}/${TODAY}/"
Cette technique permet de naviguer dans n’importe quelle sauvegarde comme s’il s’agissait d’une sauvegarde complète, tout en ne stockant réellement que les différences.
Attention à l’ordre source/destination
Avec rsync, la présence ou l’absence du slash final sur le chemin source change le comportement : /source/ synchronise le contenu du répertoire, /source synchronise le répertoire lui-même dans la destination. Cette distinction est source d’erreurs fréquentes.
tar et compression#
tar (Tape ARchiver) reste l’outil fondamental de création d’archives sous Linux. Combiné à différents algorithmes de compression, il offre un spectre large entre vitesse et taux de compression.
Syntaxe de base#
# Création d'une archive compressée gzip
tar -czf archive.tar.gz /répertoire/
# Extraction
tar -xzf archive.tar.gz -C /destination/
# Listage du contenu sans extraction
tar -tzf archive.tar.gz | head -20
Le premier argument après le tiret détermine l’opération : c (create), x (extract), t (list). Les options de compression les plus courantes sont z (gzip), j (bzip2), J (xz), et --zstd (zstd).
Comparaison des algorithmes de compression#
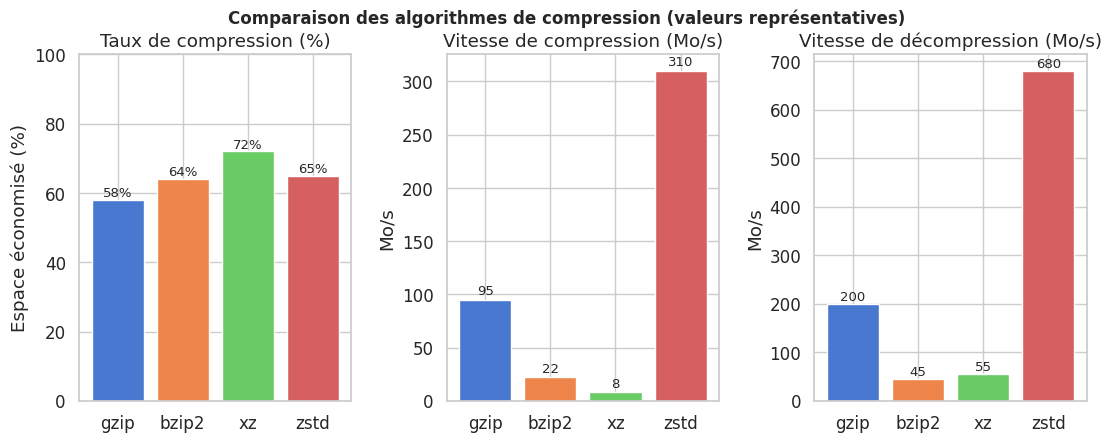
gzip reste le meilleur compromis pour un usage général : rapide, universellement disponible, intégré nativement dans tar. bzip2 offre un meilleur taux de compression au prix d’une vitesse considérablement réduite. xz optimise le taux de compression au détriment de la vitesse (utile pour les archives de distribution). zstd (Zstandard, développé par Facebook) offre le meilleur rapport vitesse/compression et est aujourd’hui le choix recommandé pour les nouvelles infrastructures.
# Sauvegarde tar avec exclusions et vérification
tar --zstd -cf /mnt/backups/home_$(date +%Y%m%d).tar.zst \
--exclude='/home/*/.cache' \
--exclude='/home/*/Downloads' \
/home/
# Vérification de l'intégrité de l'archive
tar --zstd -tf /mnt/backups/home_20240315.tar.zst > /dev/null && echo "Archive OK"
Snapshots comme outil de backup#
Un snapshot (instantané) capture l’état d’un volume à un instant précis. Contrairement à une copie traditionnelle, la création est quasi-instantanée grâce aux mécanismes Copy-on-Write (CoW).
LVM snapshots#
LVM crée des snapshots en enregistrant uniquement les blocs modifiés depuis la création du snapshot (mécanisme CoW). Le snapshot initial n’occupe aucun espace supplémentaire et grossit au fur et à mesure que les données du volume source sont modifiées.
# Création d'un snapshot LVM de 10 Go
lvcreate -L10G -s -n data_snap /dev/vg_data/data
# Montage du snapshot pour sauvegarde
mount -o ro /dev/vg_data/data_snap /mnt/snapshot
# Sauvegarde du snapshot vers un serveur distant
rsync -avz /mnt/snapshot/ user@backup:/mnt/backups/data_$(date +%Y%m%d)/
# Démontage et suppression du snapshot
umount /mnt/snapshot
lvremove -f /dev/vg_data/data_snap
Dimensionner correctement le snapshot
La taille allouée au snapshot doit être suffisante pour absorber toutes les écritures sur le volume source pendant la durée de la sauvegarde. Si le snapshot sature, il est automatiquement invalidé et la sauvegarde est compromise. En pratique, allouer 10 à 20% de la taille du volume source pour un snapshot de courte durée.
Btrfs snapshots#
Le système de fichiers Btrfs intègre nativement les snapshots au niveau du système de fichiers, sans nécessiter LVM. Les snapshots Btrfs sont des sous-volumes CoW et peuvent être en lecture-écriture (utile pour les restaurations).
# Création d'un snapshot en lecture seule
btrfs subvolume snapshot -r /data /data_snapshots/snap_$(date +%Y%m%d)
# Liste des snapshots
btrfs subvolume list /data
# Restauration : recréer le volume principal depuis un snapshot
btrfs subvolume snapshot /data_snapshots/snap_20240315 /data_restored
# Envoi d'un snapshot vers un autre serveur (stream binaire)
btrfs send /data_snapshots/snap_20240315 | \
ssh backup-server "btrfs receive /mnt/backups/"
btrfs send/receive est particulièrement efficace pour la réplication : seuls les blocs modifiés depuis le dernier snapshot commun sont transmis.
Cohérence applicative#
Un snapshot pris sur un système actif peut capturer des données dans un état incohérent (transactions en cours, caches non écrits). Pour garantir la cohérence applicative :
# PostgreSQL : flush et verrouillage du WAL avant snapshot
psql -c "SELECT pg_start_backup('snap_backup');"
lvcreate -L10G -s -n pgdata_snap /dev/vg_db/pgdata
psql -c "SELECT pg_stop_backup();"
# MySQL : flush des tables avec verrou de lecture
mysql -e "FLUSH TABLES WITH READ LOCK;"
lvcreate -L5G -s -n mysql_snap /dev/vg_db/mysql
mysql -e "UNLOCK TABLES;"
Outils avancés#
BorgBackup — déduplication et chiffrement#
BorgBackup (borg) est un outil de sauvegarde moderne qui combine déduplication, compression et chiffrement. La déduplication opère au niveau des chunks (blocs de données variables) : deux fichiers identiques ou deux versions proches d’un même fichier ne stockent qu’une seule copie des blocs communs.
# Initialisation d'un dépôt chiffré
borg init --encryption=repokey /mnt/backups/borg_repo
# Création d'une archive
borg create --compression lz4 --stats \
/mnt/backups/borg_repo::backup-{now:%Y-%m-%d} \
/home /etc /var/www
------------------------------------------------------------------------------
Archive name: backup-2024-03-15
Archive fingerprint: 8f3d1a20aa91b445...
Time (start): Fri, 2024-03-15 02:00:01
Time (end): Fri, 2024-03-15 02:04:33
Original size Compressed size Deduplicated size
This archive: 45.23 GB 38.11 GB 1.23 GB
All archives: 678.41 GB 572.03 GB 52.87 GB
La ligne « Deduplicated size » révèle la puissance de l’outil : 45 Go de données représentent seulement 1.23 Go de données réellement nouvelles dans le dépôt.
# Politique de rétention automatique
borg prune --keep-daily=7 --keep-weekly=4 --keep-monthly=6 \
/mnt/backups/borg_repo
# Vérification de l'intégrité du dépôt
borg check /mnt/backups/borg_repo
# Montage d'une archive pour navigation
borg mount /mnt/backups/borg_repo::backup-2024-03-15 /mnt/restore
ls /mnt/restore/home/
borg umount /mnt/restore
Restic — portabilité et simplicité#
Restic est un outil de sauvegarde moderne écrit en Go. Il se distingue par sa portabilité (un seul binaire statique), son support natif de nombreux backends de stockage (local, SFTP, S3, Azure, GCS, Backblaze B2…) et son chiffrement systématique de toutes les sauvegardes.
# Initialisation d'un dépôt S3
restic -r s3:s3.amazonaws.com/mon-bucket/backups init
# Sauvegarde
restic -r s3:s3.amazonaws.com/mon-bucket/backups backup /home /etc
# Liste des snapshots
restic -r s3:s3.amazonaws.com/mon-bucket/backups snapshots
# Restauration d'un snapshot
restic -r s3:s3.amazonaws.com/mon-bucket/backups \
restore latest --target /mnt/restore
Restic opère également par déduplication de chunks et chiffre systématiquement les données avant tout transfert. Le dépôt ne contient que des blocs chiffrés : même l’administrateur du backend de stockage ne peut pas lire les données.
Borg vs Restic
BorgBackup offre de meilleures performances sur les dépôts locaux ou SSH et une déduplication plus efficace. Restic excelle pour les sauvegardes vers des backends cloud (S3, B2) et sa portabilité multi-plateforme. Les deux chiffrent les données ; Restic chiffre le dépôt entier (métadonnées comprises) par défaut.
Test de restauration#
Pourquoi tester est critique#
Une sauvegarde non testée est une sauvegarde dont la fiabilité est inconnue. Les statistiques industrielles sont sans appel : une proportion significative des sauvegardes non testées échouent à la restauration, pour des raisons aussi variées que la corruption silencieuse de données, l’obsolescence des procédures ou la perte du mot de passe de chiffrement.
La découverte de l’échec d’une sauvegarde au moment d’un incident est une situation catastrophique. Un test de restauration régulier transforme cette découverte en aléa prévisible et gérable.
Types de tests de restauration#
Test de lisibilité : vérification que les fichiers d’archive peuvent être lus et que les checksums correspondent. Rapide mais insuffisant.
# Vérification tar
tar -tzf backup.tar.gz > /dev/null && echo "Lisible"
# Vérification borg
borg check --verify-data /mnt/backups/borg_repo
# Vérification restic
restic -r /mnt/backups/restic_repo check --read-data
Test de restauration partielle : restauration d’un sous-ensemble de fichiers dans un répertoire temporaire et vérification de l’intégrité.
# Restauration d'un fichier spécifique depuis borg
borg extract /mnt/backups/borg_repo::backup-2024-03-15 \
home/utilisateur/documents/fichier_critique.pdf \
--destination /tmp/test_restore/
diff /home/utilisateur/documents/fichier_critique.pdf \
/tmp/test_restore/home/utilisateur/documents/fichier_critique.pdf
Test de restauration complète : restauration intégrale sur un environnement isolé (machine virtuelle, environnement de staging) avec validation applicative. C’est le seul test qui garantit réellement la capacité de reprise.
Politique de rétention et calendrier#
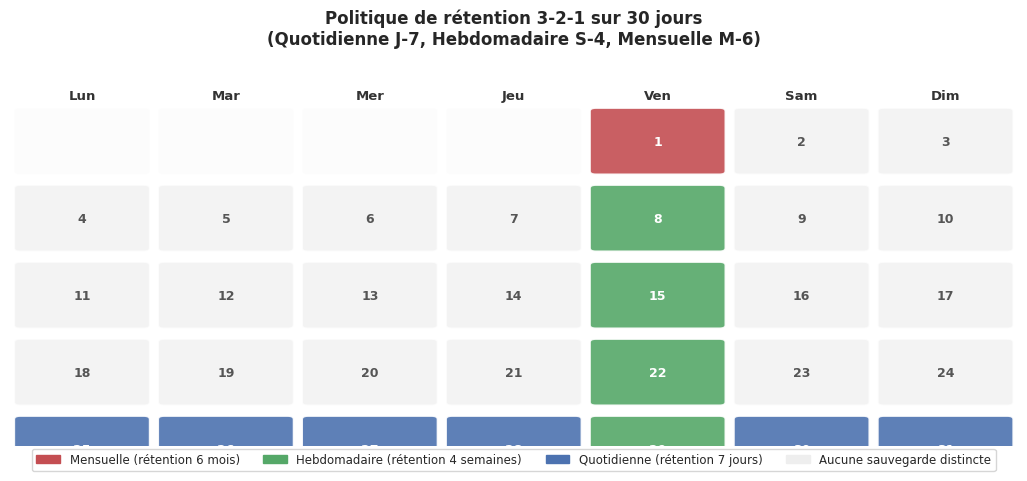
Automatisation et alertes#
# Script de sauvegarde borg avec notification en cas d'échec
#!/bin/bash
set -euo pipefail
REPO="/mnt/backups/borg_repo"
LOG="/var/log/backup.log"
{
echo "=== Backup démarré : $(date) ==="
borg create --compression lz4 --stats \
"${REPO}::backup-$(date +%Y-%m-%d_%H%M%S)" \
/home /etc /var/www
borg prune --keep-daily=7 --keep-weekly=4 --keep-monthly=6 "${REPO}"
echo "=== Backup terminé avec succès : $(date) ==="
} >> "${LOG}" 2>&1 || {
echo "ÉCHEC de la sauvegarde le $(date)" | \
mail -s "[ALERTE] Échec backup" admin@domaine.fr
exit 1
}
Automatisation avec systemd timer
Préférez les systemd timers aux cron jobs pour les sauvegardes critiques : ils offrent un meilleur suivi des erreurs (journalctl -u backup.timer), une gestion de la persistance (exécution différée si la machine était éteinte au moment prévu) et une intégration native aux alertes système.
Résumé#
Ce chapitre couvre l’ensemble des techniques de protection des données, de la redondance matérielle à la sauvegarde hors site.
RAID et redondance
Le RAID logiciel sous Linux (mdadm) offre une protection contre les défaillances disques sans coût matériel supplémentaire. Le choix du niveau dépend du compromis entre capacité, performance et tolérance aux pannes : RAID 1 pour la simplicité, RAID 5 pour le ratio capacité/protection sur les systèmes peu critiques, RAID 6 ou RAID 10 pour les charges de production sensibles.
Stratégie de sauvegarde
La règle 3-2-1 constitue le plancher minimal de toute politique sérieuse. Les métriques RPO et RTO permettent de dimensionner la fréquence des sauvegardes et les procédures de restauration en fonction des exigences métier.
Outils
Besoin |
Outil recommandé |
|---|---|
Synchronisation incrémentale |
|
Archives compressées |
|
Snapshots cohérents |
LVM snapshot / Btrfs |
Sauvegarde déduplicatée locale |
BorgBackup |
Sauvegarde cloud chiffrée |
Restic |
Points critiques
Un RAID n’est pas une sauvegarde et ne protège pas contre la corruption logique.
Dimensionner correctement les snapshots LVM pour éviter leur invalidation pendant la sauvegarde.
Tester la restauration régulièrement sur un environnement isolé — c’est la seule manière de valider réellement une politique de sauvegarde.
Stocker les clés de chiffrement séparément des données sauvegardées : une clé perdue rend les sauvegardes inutilisables.
Automatiser les sauvegardes et les tests, et surveiller leurs résultats avec des alertes.