21. Architecture cloud-native#
Une application cloud-native est conçue pour exploiter les propriétés des plateformes cloud modernes : élasticité, automatisation, observabilité, résilience. Ce n’est pas juste une application déployée dans le cloud — c’est une application qui tire parti de sa nature distribuée et dynamique.
Les 12 facteurs (12-factor app)#
Formulés par Adam Wiggins (Heroku) en 2011, les 12 facteurs restent la référence pour concevoir des applications portables, scalables et maintenables dans des environnements cloud.
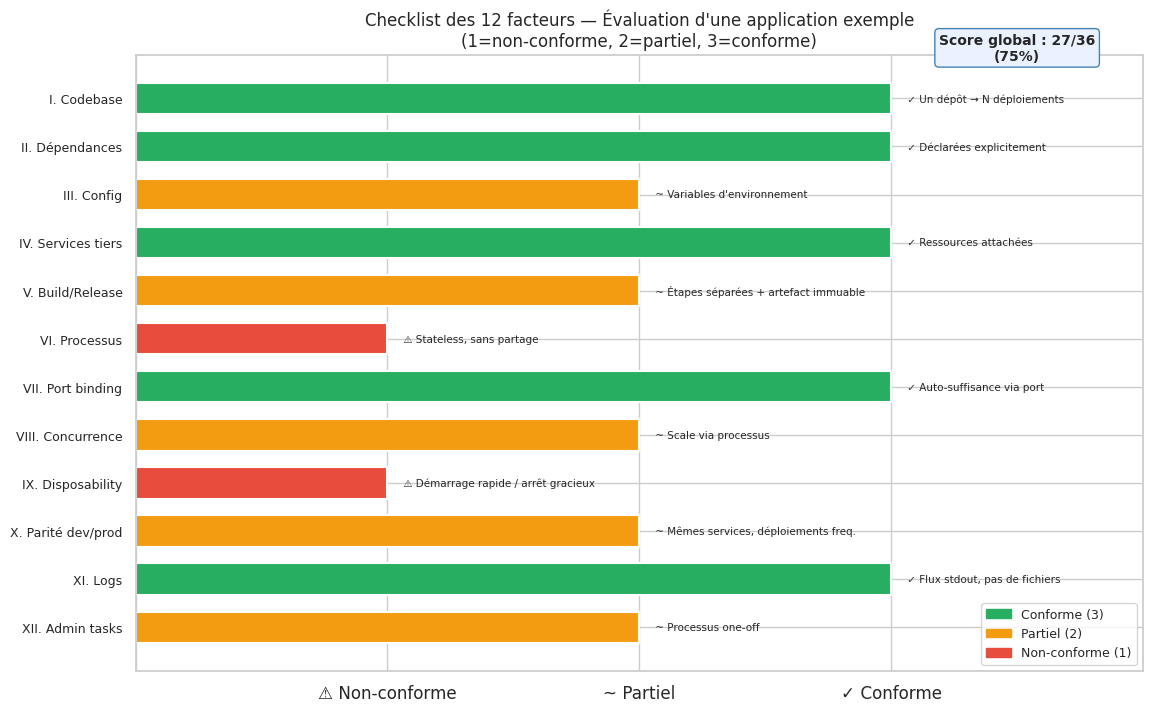
I. Codebase — Un dépôt git, plusieurs déploiements. Pas de branches par environnement.
II. Dépendances — Déclarées explicitement (requirements.txt, package.json, Gemfile). Jamais de dépendances implicites au système.
III. Configuration — Dans l’environnement (variables d’env), jamais dans le code. La configuration est tout ce qui varie entre les déploiements (URLs de DB, clés API, feature flags).
IV. Services tiers — Traités comme des ressources attachées. La DB, Redis, le broker de messages sont des ressources interchangeables — changer de fournisseur ne nécessite que de modifier la configuration.
V. Build, release, run — Trois étapes strictement séparées. Le build produit un artefact immuable. La release combine l’artefact avec la configuration. Le run exécute la release.
VI. Processus — Stateless et sans partage. L’état persiste dans les services tiers (DB, cache). Les processus peuvent démarrer et s’arrêter à tout moment.
VII. Binding de port — L’application expose ses services via un port. Elle est auto-suffisante — pas besoin d’un serveur d’application externe.
VIII. Concurrence — Scaler via le modèle de processus. Chaque type de travail est un type de processus (web, worker, scheduler).
IX. Disposability — Démarrage rapide, arrêt gracieux. Les processus peuvent être démarrés ou tués à tout moment. Le SIGTERM déclenche un arrêt propre (finir les requêtes en cours, fermer les connexions).
X. Parité dev/prod — Réduire au maximum les écarts entre développement et production. Mêmes services tiers (pas de SQLite en dev / PostgreSQL en prod), mêmes versions, déploiements fréquents.
XI. Logs — Traités comme des flux d’événements. L’application écrit sur stdout. L’infrastructure collecte et route les logs.
XII. Processus d’administration — Tâches admin exécutées en processus one-off dans le même environnement. Les migrations de DB, les consoles REPL, les scripts de maintenance tournent dans le même contexte que l’application.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Checklist 12 facteurs avec score de conformité (exemple)
factors = [
("I. Codebase", "Un dépôt → N déploiements", 3, '#27ae60'),
("II. Dépendances", "Déclarées explicitement", 3, '#27ae60'),
("III. Config", "Variables d'environnement", 2, '#f39c12'),
("IV. Services tiers","Ressources attachées", 3, '#27ae60'),
("V. Build/Release", "Étapes séparées + artefact immuable", 2, '#f39c12'),
("VI. Processus", "Stateless, sans partage", 1, '#e74c3c'),
("VII. Port binding", "Auto-suffisance via port", 3, '#27ae60'),
("VIII. Concurrence", "Scale via processus", 2, '#f39c12'),
("IX. Disposability", "Démarrage rapide / arrêt gracieux", 1, '#e74c3c'),
("X. Parité dev/prod","Mêmes services, déploiements freq.", 2, '#f39c12'),
("XI. Logs", "Flux stdout, pas de fichiers", 3, '#27ae60'),
("XII. Admin tasks", "Processus one-off", 2, '#f39c12'),
]
labels = [f[0] for f in factors]
descriptions = [f[1] for f in factors]
scores = [f[2] for f in factors]
colors = [f[3] for f in factors]
fig, ax = plt.subplots(figsize=(13, 8))
y_pos = np.arange(len(factors))
bars = ax.barh(y_pos, scores, color=colors, edgecolor='white', linewidth=1.5, height=0.65)
ax.set_yticks(y_pos)
ax.set_yticklabels(labels, fontsize=9)
ax.set_xlim(0, 4)
ax.set_xticks([0, 1, 2, 3])
ax.set_xticklabels(['', '⚠ Non-conforme', '~ Partiel', '✓ Conforme'])
ax.set_title("Checklist des 12 facteurs — Évaluation d'une application exemple\n"
"(1=non-conforme, 2=partiel, 3=conforme)", fontsize=12)
for bar, desc, score in zip(bars, descriptions, scores):
label = ['', '⚠', '~', '✓'][score]
ax.text(score + 0.05, bar.get_y() + bar.get_height()/2,
f' {label} {desc}', va='center', fontsize=7.5)
# Score global
total = sum(scores)
max_score = 3 * len(factors)
ax.text(3.5, -0.8, f'Score global : {total}/{max_score}\n({total/max_score*100:.0f}%)',
ha='center', fontsize=10, fontweight='bold',
bbox=dict(boxstyle='round', facecolor='#eaf2ff', edgecolor='steelblue'))
legend_elements = [
mpatches.Patch(color='#27ae60', label='Conforme (3)'),
mpatches.Patch(color='#f39c12', label='Partiel (2)'),
mpatches.Patch(color='#e74c3c', label='Non-conforme (1)'),
]
ax.legend(handles=legend_elements, loc='lower right', fontsize=9)
ax.invert_yaxis()
plt.savefig("12factors.png", dpi=100, bbox_inches='tight')
plt.show()
Conteneurs et immutabilité#
Un conteneur Docker empaquette l’application avec toutes ses dépendances dans une image immuable. Cette image est construite une fois et déployée identiquement en développement, test et production. L’immutabilité élimine le problème « ça marche sur ma machine ».
Images immutables#
Une image de production ne doit jamais être modifiée après build. Toute modification (correction de bug, mise à jour de configuration) passe par un nouveau build → nouvelle image → nouveau déploiement. C’est la garantie que ce qui a été testé est exactement ce qui est déployé.
Configuration externe#
La configuration (URLs, clés, feature flags) est injectée au runtime via des variables d’environnement ou des secrets managers — jamais baked dans l’image. La même image tourne en staging avec une base de données de test et en production avec la vraie base.
Conteneurs éphémères#
Les conteneurs sont conçus pour être tués et recréés à tout moment. Kubernetes peut tuer un pod et en recréer un nouveau en quelques secondes. L’application ne doit pas supposer que son système de fichiers persiste entre deux démarrages.
« Build once, deploy many »
L’immutabilité des images garantit que le même artefact traverse tous les environnements. Si l’image est validée en staging, c’est exactement la même image — même hash SHA256 — qui est déployée en production.
Service mesh#
Un service mesh est une couche d’infrastructure qui gère les communications entre microservices, de manière transparente pour le code applicatif.
Sidecar proxy#
Chaque instance d’un service est accompagnée d’un proxy léger (Envoy dans Istio, linkerd-proxy dans Linkerd) déployé en sidecar. Tout le trafic entrant et sortant passe par ce proxy. Le code applicatif ne sait pas que le proxy existe.
Fonctionnalités offertes#
mTLS automatique : les sidecars établissent automatiquement des connexions chiffrées et mutuellement authentifiées entre services. Le code applicatif ne gère pas de certificats.
Observabilité : les sidecars collectent métriques (latence, taux d’erreur, trafic), traces distribuées, et logs de connexion — sans modifier le code applicatif.
Traffic management : canary deployments, circuit breaking, retries, timeouts — configurés via des ressources Kubernetes, pas dans le code.
Complexité du service mesh
Un service mesh ajoute une complexité opérationnelle non négligeable. Istio est réputé difficile à opérer. Pour une équipe petite ou un système avec peu de services, les bénéfices peuvent ne pas justifier le coût. Linkerd est une alternative plus simple.
Serverless#
Le serverless (FaaS — Function as a Service) pousse la gestion de l’infrastructure à l’extrême : le développeur déploie du code, la plateforme gère tout le reste (instances, scaling, OS, runtime).
Avantages#
Scaling à zéro : si la fonction n’est pas appelée, aucune instance ne tourne, aucun coût n’est engagé. Le scaling est automatique, de 0 à des milliers d’instances en secondes.
Coût à l’usage : on paie uniquement le temps d’exécution effectif, à la milliseconde. Pour des workloads irréguliers, le serverless est souvent 10-100× moins cher que des instances fixes.
Simplification opérationnelle : pas de serveurs à gérer, pas de patches OS, pas de dimensionnement de flotte.
Limites#
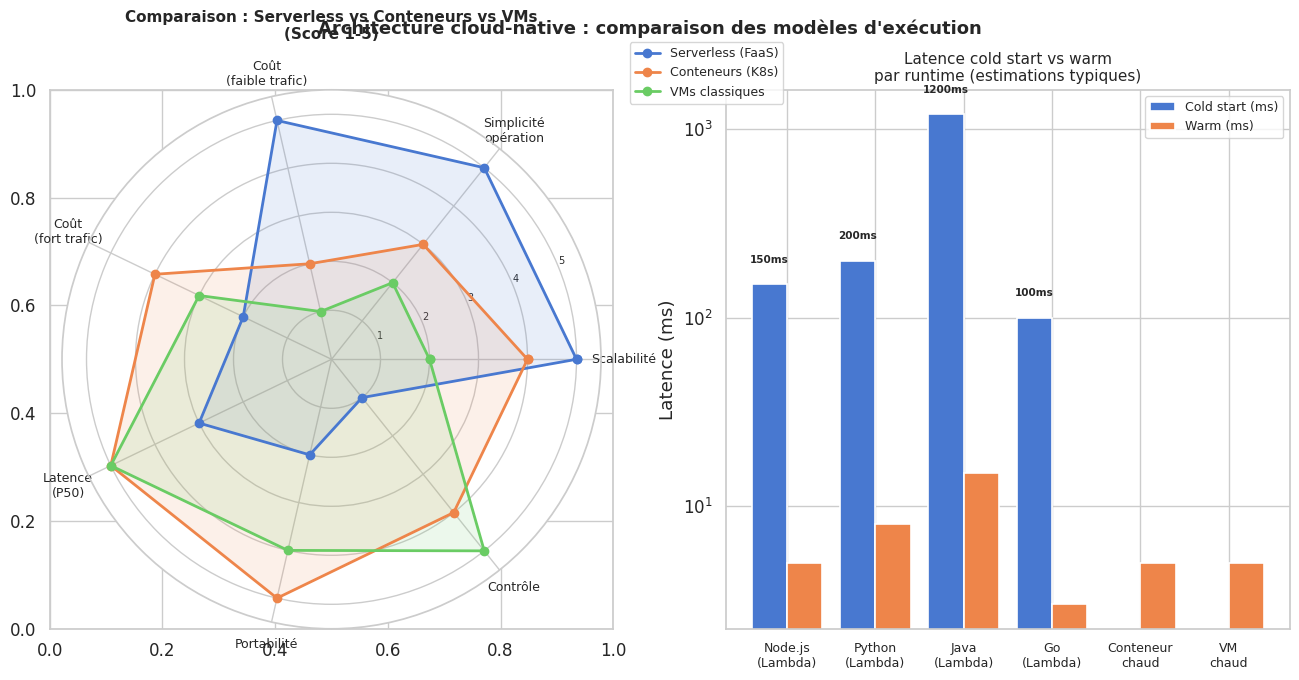
Cold start : la première invocation d’une fonction après inactivité déclenche un cold start — le runtime doit être initialisé. Latence de 100ms à plusieurs secondes selon le runtime et la taille du déploiement.
Durée maximale : les fonctions ont une durée d’exécution maximale (15 minutes sur Lambda). Les traitements longs nécessitent d’autres approches.
Vendor lock-in : les APIs des FaaS sont propriétaires. Migrer de Lambda à Cloud Functions est non trivial.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
# Simulation des latences : serverless (cold start) vs conteneur chaud
n_requests = 1000
# Serverless : majorité de requêtes chaudes (fast), quelques cold starts
cold_start_prob = 0.05 # 5% de cold starts
serverless_latencies = np.where(
np.random.random(n_requests) < cold_start_prob,
np.random.normal(800, 200, n_requests), # cold start : ~800ms
np.random.normal(45, 15, n_requests) # warm : ~45ms
)
serverless_latencies = np.clip(serverless_latencies, 1, 2000)
# Conteneur chaud : distribution plus étroite, pas de cold start
container_latencies = np.random.normal(35, 10, n_requests)
container_latencies = np.clip(container_latencies, 5, 200)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
colors = sns.color_palette("muted", 3)
# Histogrammes
ax1 = axes[0]
ax1.hist(serverless_latencies, bins=60, alpha=0.7, color=colors[0],
label='Serverless (Lambda)', edgecolor='white', density=True)
ax1.hist(container_latencies, bins=60, alpha=0.7, color=colors[1],
label='Conteneur chaud', edgecolor='white', density=True)
ax1.axvline(np.percentile(serverless_latencies, 99), color=colors[0],
linestyle='--', linewidth=2, label=f'P99 Lambda: {np.percentile(serverless_latencies, 99):.0f}ms')
ax1.axvline(np.percentile(container_latencies, 99), color=colors[1],
linestyle='--', linewidth=2, label=f'P99 Container: {np.percentile(container_latencies, 99):.0f}ms')
ax1.set_xlabel("Latence (ms)")
ax1.set_ylabel("Densité")
ax1.set_title("Distribution des latences\nServerless vs Conteneur chaud", fontsize=12)
ax1.legend(fontsize=9)
ax1.set_xlim(0, 300)
# Modélisation du coût cloud selon le trafic
ax2 = axes[1]
traffic = np.linspace(0, 1_000_000, 1000) # requêtes/mois
# Serverless : ~$0.20 per million requests + $0.0000166667 per GB-second
avg_duration_ms = 100 # ms
memory_gb = 0.128 # 128MB
price_per_million_req = 0.20
price_per_gb_second = 0.0000166667
cost_serverless = (
traffic / 1_000_000 * price_per_million_req
+ traffic * (avg_duration_ms / 1000) * memory_gb * price_per_gb_second
)
# Instance fixe : ~$30/mois pour une petite instance (t3.small)
cost_instance_1 = np.full_like(traffic, 30)
# Avec autoscaling : jusqu'à 3 instances
cost_instances_auto = np.where(
traffic < 100_000, 30,
np.where(traffic < 500_000, 60, 90)
)
ax2.plot(traffic / 1000, cost_serverless, color=colors[0], linewidth=2.5,
label='Serverless (Lambda)')
ax2.plot(traffic / 1000, cost_instance_1, color=colors[1], linewidth=2.5,
linestyle='--', label='1 instance fixe (t3.small)')
ax2.plot(traffic / 1000, cost_instances_auto, color=colors[2], linewidth=2.5,
linestyle=':', label='Auto-scaling (1-3 instances)')
# Point de croisement serverless vs instance fixe
crossover_idx = np.argmin(np.abs(cost_serverless - cost_instance_1))
ax2.axvline(traffic[crossover_idx] / 1000, color='red', linestyle=':', linewidth=1.5, alpha=0.6)
ax2.annotate(f'Break-even\n~{traffic[crossover_idx]/1000:.0f}K req/mois',
xy=(traffic[crossover_idx]/1000, cost_instance_1[0]),
xytext=(traffic[crossover_idx]/1000 + 100, cost_instance_1[0] + 15),
fontsize=8, color='red',
arrowprops=dict(arrowstyle='->', color='red'))
ax2.set_xlabel("Trafic (milliers de requêtes/mois)")
ax2.set_ylabel("Coût estimé (USD/mois)")
ax2.set_title("Modélisation du coût cloud\nServerless vs instances fixes", fontsize=12)
ax2.legend(fontsize=9)
ax2.set_ylim(0, 100)
plt.suptitle("Serverless : latences et modèle économique", fontsize=13, fontweight='bold')
plt.savefig("serverless_analysis.png", dpi=100, bbox_inches='tight')
plt.show()
print(f"Serverless — P50: {np.percentile(serverless_latencies, 50):.0f}ms | "
f"P95: {np.percentile(serverless_latencies, 95):.0f}ms | "
f"P99: {np.percentile(serverless_latencies, 99):.0f}ms")
print(f"Conteneur — P50: {np.percentile(container_latencies, 50):.0f}ms | "
f"P95: {np.percentile(container_latencies, 95):.0f}ms | "
f"P99: {np.percentile(container_latencies, 99):.0f}ms")
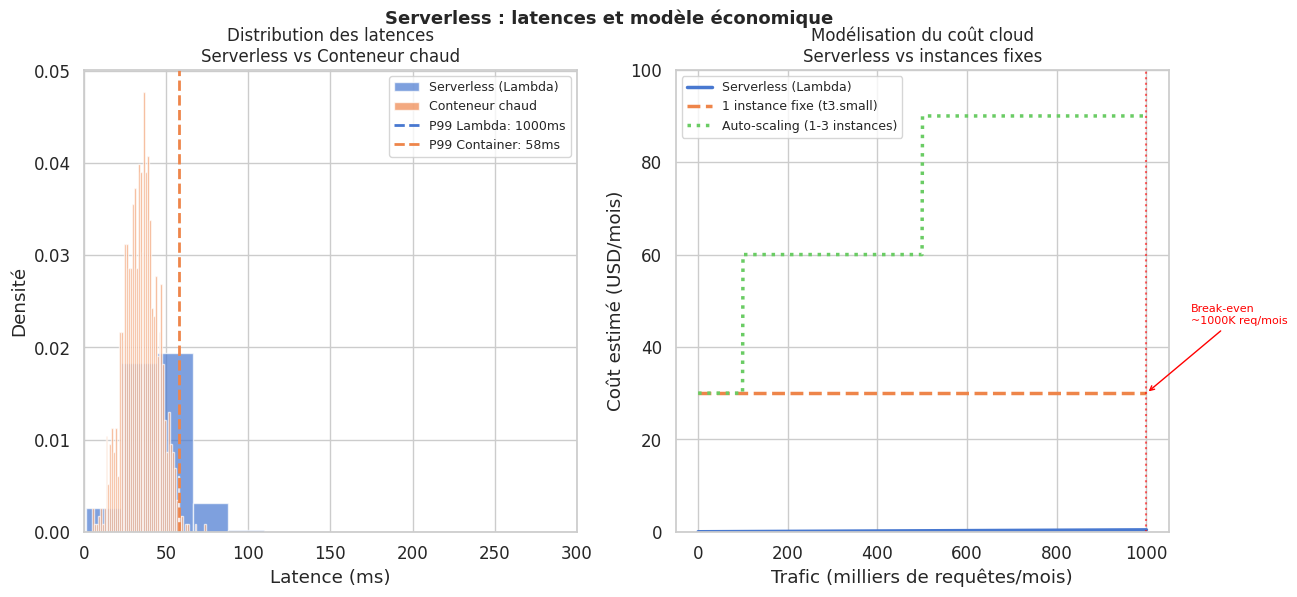
Serverless — P50: 46ms | P95: 499ms | P99: 1000ms
Conteneur — P50: 35ms | P95: 52ms | P99: 58ms
Observabilité#
L’observabilité est la capacité à comprendre l’état interne d’un système à partir de ses sorties externes. Dans un système distribué où des centaines de services interagissent, c’est une propriété de survie.
Les trois piliers#
Logs structurés (JSON) : les logs textuels sont illisibles à l’échelle. Les logs JSON sont indexables, filtrables, agrégables. Chaque log contient : timestamp ISO 8601, niveau, message, trace_id, span_id, service, et les champs pertinents au contexte.
Métriques (OpenMetrics/Prometheus) : séries temporelles numériques — counters (requêtes totales), gauges (connexions actives), histogrammes (distribution des latences). Prometheus scrappe les métriques exposées par les services. Grafana les visualise.
Traces distribuées (OpenTelemetry) : une requête qui traverse 5 services génère 5 spans liés par un trace_id. La trace reconstruit le chemin complet et identifie quel service a ajouté de la latence.
Corrélation#
La puissance de l’observabilité vient de la corrélation entre les trois piliers. Une alerte sur une métrique (latence P99 > 1s) permet de trouver les logs correspondants (filtrés par trace_id), qui renvoient aux traces détaillées montrant exactement où la latence est introduite.
SLI de performance
Les SLI (Service Level Indicators) définissent les métriques utilisées pour mesurer la fiabilité. Pour un service web : taux d’erreur (5xx / total), latence P99, disponibilité. Ces métriques alimentent les SLO et l’error budget.
GitOps#
GitOps est une pratique où git est la source de vérité unique pour l’infrastructure et la configuration applicative. L’état désiré du système (manifestes Kubernetes, configuration Helm, variables d’environnement) est dans git. Un opérateur (ArgoCD, Flux) synchronise en continu l’état réel avec l’état désiré.
Principes#
Déclaratif : décrire l’état désiré, pas les étapes pour y arriver. Un manifeste Kubernetes déclare « je veux 3 replicas de ce pod » — Kubernetes se charge de créer ou supprimer des pods pour atteindre cet état.
Versionné : tout changement d’infrastructure passe par un commit git. Rollback = git revert. Audit trail = git log.
Réconciliation continue : si quelqu’un modifie manuellement un objet Kubernetes, l’opérateur le détecte et le ramène à l’état décrit dans git.
ArgoCD et Flux#
ArgoCD et Flux sont les deux outils dominants. ArgoCD offre une interface visuelle qui montre l’état de synchronisation de chaque application. Flux est plus orienté CLI et GitOps strict. Les deux peuvent déclencher des déploiements sur push git ou sur un nouveau tag d’image Docker.
FinOps#
Le FinOps (Financial Operations) traite le coût cloud comme une métrique architecturale de première classe, au même titre que la latence ou la disponibilité.
Coût comme contrainte architecturale#
Une architecture qui coûte 10× plus cher qu’une alternative équivalente est une mauvaise architecture. Les décisions d’architecture ont un impact direct sur la facture cloud : choix du type d’instance, stockage objet vs bloc, transferts de données inter-régions, rétention des logs.
Right-sizing#
Sur-dimensionner les instances « pour être sûr » est une erreur fréquente. Le right-sizing consiste à analyser l’utilisation réelle (CPU, mémoire, IOPS) et à choisir l’instance adaptée. AWS Compute Optimizer, GCP Recommender fournissent des recommandations automatiques.
Reserved vs Spot#
On-demand : prix plein, flexibilité maximale. Reserved instances : engagement sur 1 ou 3 ans, réduction de 30-60%. Adapté aux workloads stables et prévisibles. Spot/Preemptible : instances surplus vendues avec 70-90% de réduction, mais peuvent être reprises avec un préavis de 2 minutes. Adapté aux workloads batch, fault-tolerant, stateless.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Radar : Serverless vs Conteneurs vs VMs
categories = ['Scalabilité', 'Simplicité\nopération', 'Coût\n(faible trafic)',
'Coût\n(fort trafic)', 'Latence\n(P50)', 'Portabilité', 'Contrôle']
n_cat = len(categories)
angles = np.linspace(0, 2 * np.pi, n_cat, endpoint=False).tolist()
angles += angles[:1] # fermer le polygone
scores = {
'Serverless (FaaS)': [5, 5, 5, 2, 3, 2, 1],
'Conteneurs (K8s)': [4, 3, 2, 4, 5, 5, 4],
'VMs classiques': [2, 2, 1, 3, 5, 4, 5],
}
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# Radar
ax = axes[0]
ax = plt.subplot(121, polar=True)
colors = sns.color_palette("muted", 3)
for (label, vals), color in zip(scores.items(), colors):
vals_plot = vals + vals[:1]
ax.plot(angles, vals_plot, 'o-', linewidth=2, color=color, label=label)
ax.fill(angles, vals_plot, alpha=0.12, color=color)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=9)
ax.set_ylim(0, 5.5)
ax.set_yticks([1, 2, 3, 4, 5])
ax.set_yticklabels(['1', '2', '3', '4', '5'], fontsize=7)
ax.set_title("Comparaison : Serverless vs Conteneurs vs VMs\n(Score 1-5)", fontsize=11,
pad=15, fontweight='bold')
ax.legend(loc='upper right', bbox_to_anchor=(1.35, 1.1), fontsize=9)
# Comparaison coût cold start (barplot)
ax2 = axes[1]
runtimes = ['Node.js\n(Lambda)', 'Python\n(Lambda)', 'Java\n(Lambda)',
'Go\n(Lambda)', 'Conteneur\nchaud', 'VM\nchaud']
cold_start_ms = [150, 200, 1200, 100, 0, 0]
warm_ms = [5, 8, 15, 3, 5, 5]
x = np.arange(len(runtimes))
width = 0.4
colors2 = sns.color_palette("muted", 2)
bars1 = ax2.bar(x - width/2, cold_start_ms, width, label='Cold start (ms)',
color=colors2[0], edgecolor='white', linewidth=1.2)
bars2 = ax2.bar(x + width/2, warm_ms, width, label='Warm (ms)',
color=colors2[1], edgecolor='white', linewidth=1.2)
ax2.set_xticks(x)
ax2.set_xticklabels(runtimes, fontsize=9)
ax2.set_ylabel("Latence (ms)")
ax2.set_title("Latence cold start vs warm\npar runtime (estimations typiques)", fontsize=11)
ax2.legend(fontsize=9)
ax2.set_yscale('log')
for bar, val in zip(bars1, cold_start_ms):
if val > 0:
ax2.text(bar.get_x() + bar.get_width()/2, bar.get_height() * 1.3,
f'{val}ms', ha='center', fontsize=7.5, fontweight='bold')
plt.suptitle("Architecture cloud-native : comparaison des modèles d'exécution",
fontsize=13, fontweight='bold')
plt.savefig("cloud_native_comparison.png", dpi=100, bbox_inches='tight')
plt.show()
Résumé#
L’architecture cloud-native est une philosophie autant qu’un ensemble de technologies.
Pratique |
Bénéfice principal |
Prérequis |
|---|---|---|
12-factor app |
Portabilité, scalabilité |
Discipline de code |
Conteneurs immuables |
Reproductibilité |
Pipeline CI/CD |
Service mesh |
mTLS automatique, observabilité |
Complexité opérationnelle |
Serverless |
Scaling à zéro, coût à l’usage |
Workloads courts et stateless |
Observabilité (logs/metrics/traces) |
Debuggabilité en production |
Instrumentation |
GitOps |
Audit trail, rollback trivial |
Culture git-centric |
FinOps |
Coût maîtrisé |
Accès aux métriques de coût |
Règles pratiques :
Commencer par les 12 facteurs : c’est le socle. Un service non-conforme aux facteurs III (config), VI (stateless) et IX (disposability) ne peut pas être cloud-native.
L’observabilité s’instrumente dès le début — l’ajouter après coup dans un système complexe est extrêmement difficile.
Serverless n’est pas une solution universelle : évaluer les P99 (cold start) avant d’adopter pour des workloads latence-sensitifs.
GitOps nécessite de la discipline dans les équipes — toute modification manuelle en dehors de git crée une divergence.
FinOps n’est pas une phase finale : intégrer les coûts dans les décisions d’architecture dès la conception.