09 — Architecture événementielle#
Événements, commandes et requêtes#
Avant d’aborder l’architecture événementielle, il faut distinguer trois types fondamentaux de messages qui circulent dans un système.
Requête (Query)#
Une requête est une demande d’information. Elle ne modifie pas l’état du système et attend une réponse.
GET /orders/42 → {id: 42, status: "confirmed", total: 150.00}
Commande (Command)#
Une commande est une instruction adressée à un système. Elle exprime une intention de modification : « fais ceci ». Elle peut être acceptée ou rejetée.
PlaceOrder {customer_id: "C1", items: [...]}
CancelOrder {order_id: "42", reason: "customer_request"}
Une commande est adressée à un destinataire précis. Si elle échoue, l’émetteur le sait.
Événement (Event)#
Un événement est un fait passé : quelque chose s’est produit dans le système. Il est nommé au passé et est immuable — ce qui est arrivé est arrivé.
OrderPlaced {order_id: "42", customer_id: "C1", items: [...], timestamp: "..."}
PaymentFailed {order_id: "42", reason: "insufficient_funds", timestamp: "..."}
StockDepleted {product_id: "P7", warehouse: "WH-Paris", timestamp: "..."}
Un événement est public — le producteur publie ce qui s’est passé et ne sait pas qui va l’écouter ni combien. C’est la différence fondamentale avec une commande.
« Tell, don’t ask »#
Le principe tell, don’t ask est le fondement de la pensée événementielle. Au lieu de demander à un service son état pour décider quoi faire (ask), on lui dit ce qu’il s’est passé (tell) et il réagit de manière autonome.
# Approche "ask" (couplage fort)
stock = inventory_service.get_stock(product_id)
if stock < threshold:
notification_service.alert_reorder(product_id)
# Approche "tell" (événement, couplage faible)
# Quand le stock tombe sous le seuil, l'inventaire publie :
event_bus.publish("inventory.stock_depleted", {
"product_id": product_id, "current_stock": 3, "threshold": 10
})
# Le service de notifications s'y abonne — l'inventaire ignore qui écoute
Event-Driven Architecture#
L”Event-Driven Architecture (EDA) est un style architectural où les composants communiquent principalement par la production et la consommation d’événements.
Trois topologies principales#
Simple event processing — traitement immédiat d’événements individuels. Un événement arrive, un consommateur réagit. Utilisé pour des intégrations simples, des notifications, des workflows linéaires.
Complex Event Processing (CEP) — détection de patterns dans des flux d’événements. Plusieurs événements sont corrélés dans le temps pour détecter des situations complexes : « un client a effectué plus de 5 transactions supérieures à 1000€ en moins de 10 minutes sur des IP différentes » → alerte fraude.
Event Sourcing — les événements sont la source de vérité du système, pas l’état courant. On ne stocke pas « le compte a un solde de 1500€ » mais « MoneyDeposited(500€) puis MoneyWithdrawn(200€) puis MoneyDeposited(1200€) ». L’état courant est reconstruit en rejouant les événements.
Producteurs et consommateurs#
Producteur Broker Consommateurs
─────────────────────────────────────────────────────────────────────
OrderService ──→ OrderPlaced ──→ [Topic: orders] ──→ InventoryService
──→ NotificationService
──→ AnalyticsService
──→ FraudDetectionService
Le broker (Kafka, RabbitMQ, EventBridge) découple producteurs et consommateurs dans le temps, dans l’espace et dans la synchronisation.
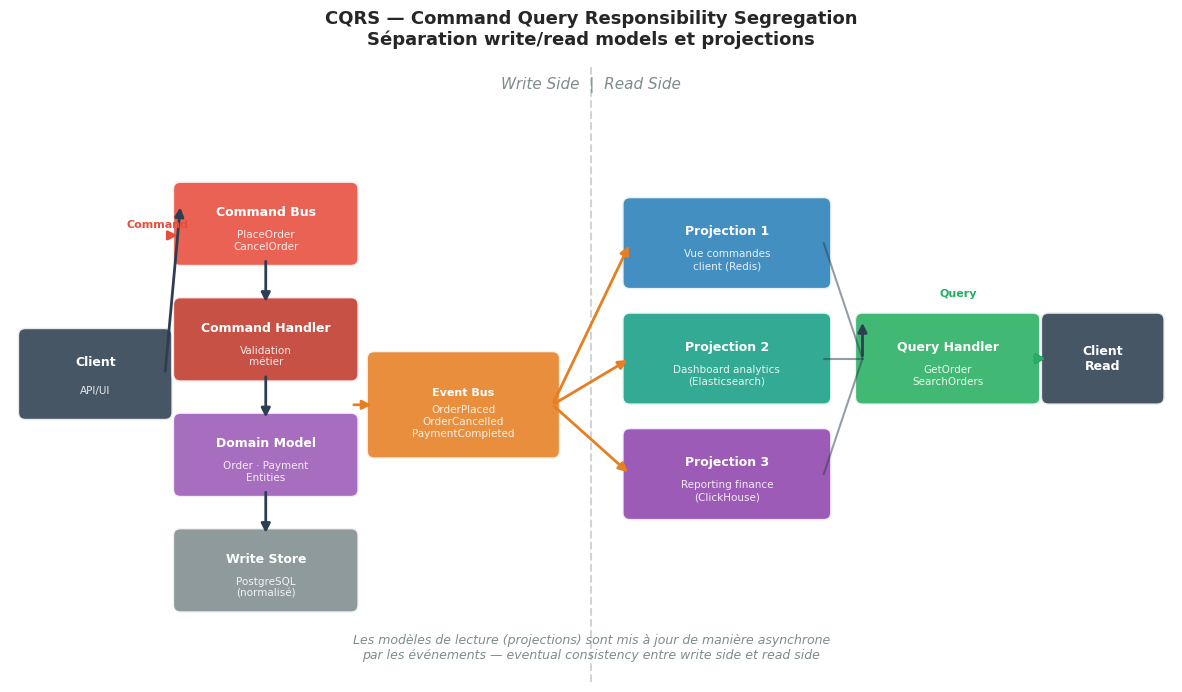
CQRS#
Command Query Responsibility Segregation (CQRS) est un pattern proposé par Greg Young qui sépare les modèles de lecture et d’écriture d’une application.
Le problème qu’il résout#
Dans un modèle CRUD traditionnel, le même objet domaine sert à la fois pour les écritures (avec toutes les règles de validation) et les lectures (avec toutes les projections nécessaires aux vues). Ces deux besoins ont des contraintes divergentes :
Écriture : cohérence forte, validation métier, transactions, tout ou rien.
Lecture : performance, dénormalisation, projections multiples, éventuellement incohérence temporaire acceptable.
La séparation write/read#
# Write side — modèle riche, validation, règles métier
class OrderCommandHandler:
def handle_place_order(self, cmd: PlaceOrderCommand) -> str:
order = Order.create(cmd.customer_id, cmd.items)
order.validate() # Règles métier
order.confirm()
self.repo.save(order) # Écriture transactionnelle
self.event_bus.publish(OrderPlaced(order))
return order.id
# Read side — projections dénormalisées, optimisées pour la lecture
class OrderReadModel:
"""Projection dénormalisée pour l'interface utilisateur."""
order_id: str
customer_name: str # Dénormalisé depuis le service client
items_summary: str # "3 articles (iPhone x1, AirPods x2)"
status_label: str # "En cours de livraison"
estimated_delivery: str
class OrderQueryHandler:
def get_order_details(self, order_id: str) -> OrderReadModel:
return self.read_db.query(OrderReadModel).filter_by(order_id=order_id).first()
def get_orders_for_customer(self, customer_id: str) -> list[OrderReadModel]:
return self.read_db.query(OrderReadModel)\
.filter_by(customer_id=customer_id)\
.order_by("created_at DESC").limit(20).all()
Projections#
Une projection est le mécanisme qui maintient le modèle de lecture à jour en réagissant aux événements du write side. Quand un OrderPlaced est publié, la projection OrderReadModel est mise à jour pour refléter la nouvelle commande.
CQRS n’implique pas Event Sourcing
CQRS et Event Sourcing sont souvent mentionnés ensemble mais sont indépendants. On peut avoir du CQRS avec des stores CRUD distincts (base de données relationnelle pour les écritures, Elasticsearch pour les lectures) sans Event Sourcing. Et on peut faire de l’Event Sourcing sans CQRS. Ils se combinent bien mais ne sont pas liés.
Event Sourcing#
L”Event Sourcing renverse la façon dont on pense la persistence. Au lieu de stocker l’état courant d’une entité (la dernière valeur), on stocke la séquence complète des événements qui ont conduit à cet état.
Exemple : compte bancaire#
# Event Sourcing — compte bancaire
# Ce qu'on stocke : la séquence d'événements
events = [
AccountOpened(account_id="ACC-1", owner="Alice", initial_balance=0),
MoneyDeposited(account_id="ACC-1", amount=1000, timestamp="2024-01-01"),
MoneyDeposited(account_id="ACC-1", amount=500, timestamp="2024-01-15"),
MoneyWithdrawn(account_id="ACC-1", amount=200, timestamp="2024-01-20"),
MoneyTransferred(account_id="ACC-1", to="ACC-2", amount=300, timestamp="2024-02-01"),
]
# L'état courant est reconstruit en rejouant les événements
def reconstruct_balance(events: list) -> float:
balance = 0
for event in events:
if isinstance(event, MoneyDeposited):
balance += event.amount
elif isinstance(event, MoneyWithdrawn):
balance -= event.amount
elif isinstance(event, MoneyTransferred):
balance -= event.amount
return balance # → 1000
Avantages de l’Event Sourcing#
Audit trail complet : chaque changement d’état est tracé avec son contexte. Idéal pour les systèmes financiers et réglementés.
Débogage temporel : on peut rejouer les événements jusqu’à n’importe quel point dans le temps pour comprendre l’état du système à cet instant.
Projections multiples : le même flux d’événements peut alimenter plusieurs modèles de lecture différents.
Intégration naturelle : les événements sont la source de vérité pour tous les autres services.
Snapshots#
Rejouer tous les événements depuis le début pour reconstruire l’état d’un compte actif depuis 10 ans devient prohibitif. Les snapshots sont une optimisation : périodiquement, l’état courant est capturé, et on ne rejoue les événements qu’à partir du dernier snapshot.
# Reconstruction avec snapshot
def reconstruct_with_snapshot(account_id: str, store) -> BankAccount:
snapshot = store.get_latest_snapshot(account_id)
if snapshot:
account = BankAccount.from_snapshot(snapshot)
events_since = store.get_events_after(account_id, snapshot.version)
else:
account = BankAccount(account_id)
events_since = store.get_all_events(account_id)
for event in events_since:
account.apply(event)
return account
Complexités de l’Event Sourcing#
L’Event Sourcing n’est pas une solution universelle
Event Sourcing introduit des complexités réelles :
Les requêtes simples (« donne-moi le solde courant ») deviennent plus complexes sans modèle de lecture séparé (→ CQRS).
L’évolution des schémas d’événements est délicate : les vieux événements doivent rester lisibles.
Le debugging est non intuitif pour les développeurs habitués au CRUD.
La gestion des snapshots est un mécanisme supplémentaire à maintenir.
Il se justifie principalement pour les domaines où l’historique des modifications a une valeur métier propre (finance, comptabilité, audit, conformité réglementaire).
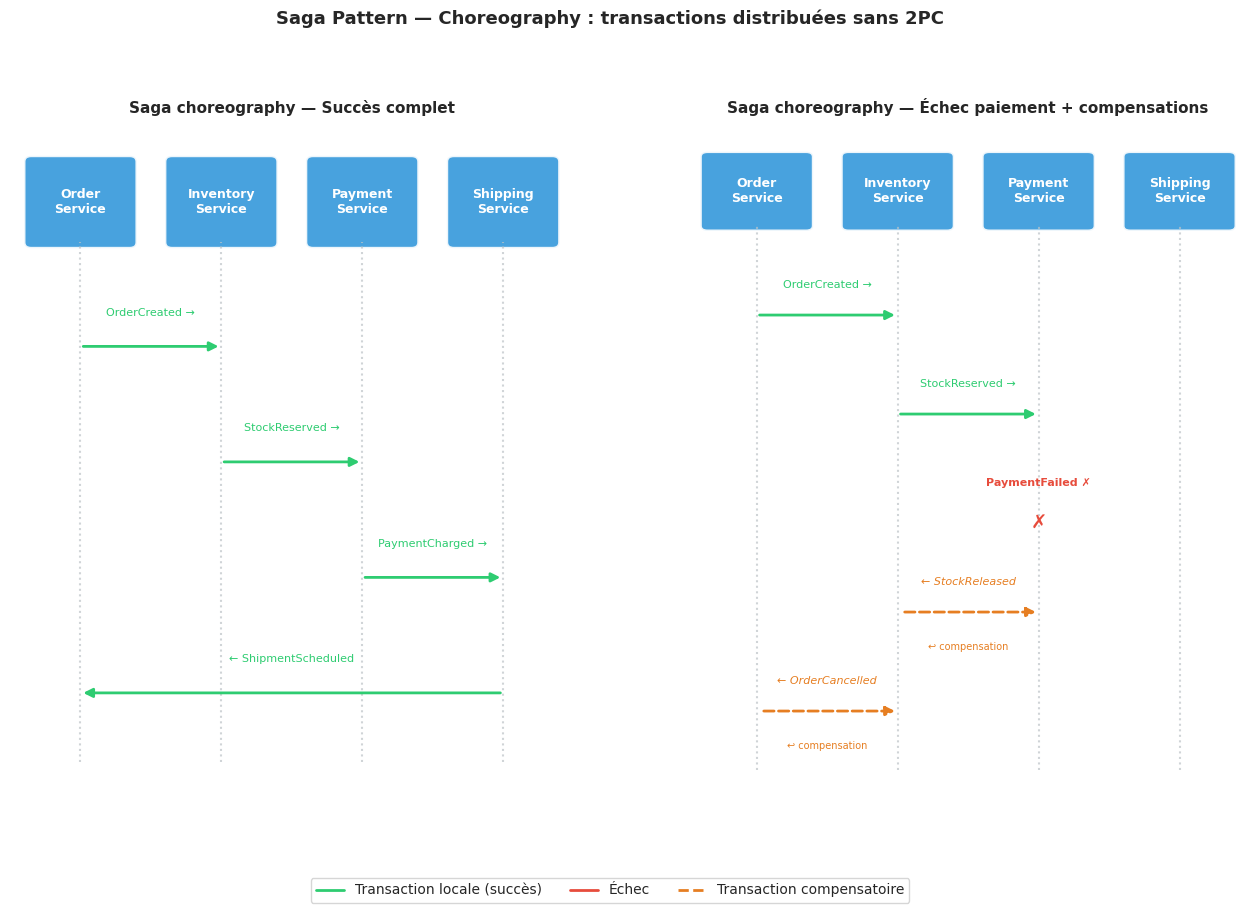
Saga pattern#
Le Saga pattern résout le problème des transactions longues distribuées : comment garantir la cohérence d’une opération qui s’étend sur plusieurs services, sans transaction ACID distribuée ?
Principe#
Une saga est une séquence de transactions locales. Chaque transaction locale met à jour les données d’un service et publie un événement (ou une commande) qui déclenche la transaction locale suivante. Si une étape échoue, des transactions compensatoires annulent les étapes précédentes.
Deux variantes : choreography vs orchestration#
Choreography — les services décident eux-mêmes quoi faire en réponse aux événements.
OrderService → publie OrderCreated
InventoryService reçoit OrderCreated → réserve le stock → publie StockReserved
PaymentService reçoit StockReserved → facture le client → publie PaymentCompleted
ShippingService reçoit PaymentCompleted → planifie livraison → publie ShipmentScheduled
Orchestration — un orchestrateur central coordonne les étapes.
SagaOrchestrator:
1. Appelle InventoryService.reserve()
2. Appelle PaymentService.charge()
3. Appelle ShippingService.schedule()
En cas d'échec à l'étape N, appelle les compensations des étapes 1..N-1
Aspect |
Choreography |
Orchestration |
|---|---|---|
Couplage |
Plus faible (événements) |
Plus fort (orchestrateur connaît tous les services) |
Lisibilité |
Difficile à suivre (logique dispersée) |
Plus facile (logique centralisée) |
Point de défaillance unique |
Non |
Oui (l’orchestrateur) |
Debugging |
Complexe (tracer les événements) |
Plus simple (état dans l’orchestrateur) |
Recommandé pour |
Sagas simples, équipes autonomes |
Sagas complexes, besoin de visibilité |
Message brokers#
Kafka — log partitionné#
Apache Kafka modélise les messages comme un log append-only partitionné. Ses caractéristiques clés :
Topics et partitions : un topic est divisé en partitions. Les messages d’une partition sont strictement ordonnés.
Consumer groups : plusieurs instances d’un service forment un groupe. Chaque partition est assignée à une seule instance du groupe, garantissant que chaque message est traité une fois par le groupe.
Retention configurable : Kafka ne supprime pas les messages après consommation (contrairement à une queue). Les messages sont conservés selon une politique de rétention (7 jours par défaut). Un nouveau service peut relire l’historique complet.
Haute performance : Kafka est conçu pour des millions de messages par seconde.
# Kafka — producteur (confluent-kafka)
from confluent_kafka import Producer
producer = Producer({"bootstrap.servers": "kafka:9092"})
def publish_order_placed(order):
producer.produce(
topic="orders.events",
key=order.id.encode(), # Partitionnement par order_id
value=json.dumps({
"event_type": "OrderPlaced",
"order_id": order.id,
"customer_id": order.customer_id,
"items": [...],
}).encode(),
callback=lambda err, msg: print(f"Erreur: {err}" if err else None)
)
producer.flush()
# Kafka — consommateur
from confluent_kafka import Consumer
consumer = Consumer({
"bootstrap.servers": "kafka:9092",
"group.id": "inventory-service",
"auto.offset.reset": "earliest",
})
consumer.subscribe(["orders.events"])
while True:
msg = consumer.poll(timeout=1.0)
if msg and not msg.error():
event = json.loads(msg.value())
if event["event_type"] == "OrderPlaced":
handle_order_placed(event)
consumer.commit(msg) # Commit manuel pour at-least-once
RabbitMQ — exchanges et queues#
RabbitMQ modélise la messagerie différemment : les producteurs publient vers des exchanges, qui routent les messages vers des queues selon des règles de binding.
Direct exchange : routage par routing key exacte (1:1 ou 1:N queues).
Fanout exchange : broadcast vers toutes les queues bindées (pub/sub).
Topic exchange : routage par pattern sur la routing key (
orders.#,*.failed).Headers exchange : routage selon les headers du message.
# RabbitMQ — échange topic (pika)
import pika, json
connection = pika.BlockingConnection(pika.ConnectionParameters("rabbitmq"))
channel = connection.channel()
# Déclaration de l'exchange et des queues
channel.exchange_declare("orders", exchange_type="topic", durable=True)
channel.queue_declare("inventory.orders", durable=True)
channel.queue_declare("notification.orders", durable=True)
channel.queue_bind("inventory.orders", "orders", routing_key="orders.*")
channel.queue_bind("notification.orders", "orders", routing_key="orders.*")
# Publication
channel.basic_publish(
exchange="orders",
routing_key="orders.placed",
body=json.dumps({"order_id": "42", "customer_id": "C1"}),
properties=pika.BasicProperties(delivery_mode=2) # Message persistant
)
Dimension |
Kafka |
RabbitMQ |
|---|---|---|
Modèle |
Log distribué partitionné |
Queue broker (AMQP) |
Rétention |
Configurable (jours/semaines) |
Jusqu’à consommation |
Débit |
Très élevé (millions/s) |
Élevé (centaines de milliers/s) |
Ordering |
Par partition |
Par queue (FIFO) |
Routing |
Consumers choisissent (offset) |
Exchange routes vers queues |
Replay |
Oui (rembobinage d’offset) |
Non (consommé = supprimé) |
Cas d’usage principal |
Event Sourcing, streaming, audit |
Workflows, tâches, RPC async |
Schémas et contrats d’événements#
L’évolution des schémas#
Les événements sont des interfaces publiques entre services. Modifier le schéma d’un événement sans coordination peut casser les consommateurs. La gestion de l’évolution des schémas est l’un des défis les moins visibles de l’architecture événementielle.
Deux types de compatibilité :
Backward compatible : les consommateurs anciens peuvent lire les nouveaux événements (ajout de champs optionnels).
Forward compatible : les nouveaux consommateurs peuvent lire les anciens événements (champs manquants ont des valeurs par défaut).
# Évolution de schéma — ajout rétrocompatible
# Version 1
{"event_type": "OrderPlaced", "order_id": "42", "customer_id": "C1"}
# Version 2 — backward compatible (nouveau champ optionnel)
{"event_type": "OrderPlaced", "order_id": "42", "customer_id": "C1",
"source_channel": "mobile_app"} # Nouveau champ — les consommateurs v1 l'ignorent
# Version 3 — BREAKING CHANGE (renommage de champ)
{"event_type": "OrderPlaced", "order_id": "42", "user_id": "C1"}
# ^ customer_id renommé en user_id — les consommateurs v1 et v2 sont cassés
Schema Registry#
Le Schema Registry (Confluent, Apicurio) est un service centralisé qui stocke les schémas des événements et valide la compatibilité des nouvelles versions avant publication.
# Avec Avro et Confluent Schema Registry
from confluent_kafka.avro import AvroProducer
from confluent_kafka import avro
order_schema = avro.loads("""{
"type": "record",
"name": "OrderPlaced",
"fields": [
{"name": "order_id", "type": "string"},
{"name": "customer_id", "type": "string"},
{"name": "total", "type": "double"},
{"name": "source", "type": ["null", "string"], "default": null}
]
}""")
producer = AvroProducer({
"bootstrap.servers": "kafka:9092",
"schema.registry.url": "http://schema-registry:8081"
}, default_value_schema=order_schema)
Pièges#
Ordering et partitionnement#
Kafka garantit l’ordre au sein d’une partition. Si les événements d’une même commande sont répartis sur plusieurs partitions, un consommateur peut les recevoir dans le mauvais ordre.
La solution : partitionner par clé métier (order_id, customer_id) pour que tous les événements d’une même entité soient dans la même partition.
Idempotence#
At-least-once delivery signifie que les consommateurs peuvent recevoir le même événement deux fois (en cas de retry après crash). Les consommateurs doivent être idempotents.
Stratégies : table de déduplication (stocker les event_id traités), opérations naturellement idempotentes (upsert SQL plutôt qu’insert).
Exactly-once#
La livraison exactly-once est le Saint-Graal de la messagerie distribuée. Kafka la supporte depuis la version 0.11 avec les transactions Kafka (idempotent producer + transactional consumer), mais elle a un coût en performance et en complexité. Pour la plupart des cas, at-least-once + idempotence est le compromis recommandé.
Debugging difficile#
Dans une architecture événementielle, suivre le fil d’une requête utilisateur à travers une chaîne d’événements asynchrones est difficile. Les outils essentiels :
Correlation ID : un identifiant unique propagé dans tous les événements d’une même opération.
Distributed tracing : OpenTelemetry propagé dans les headers des messages.
Event store consultable : pouvoir rejouer et inspecter les événements passés.
Le débogage asynchrone est une compétence à part entière
Dans un système synchrone, une erreur produit une exception avec une stack trace. Dans un système événementiel, une anomalie peut n’apparaître que des heures ou des jours après l’événement qui l’a causée, dans un service totalement différent. Investir dans l’observabilité (corrélation, tracing, dashboards de flux d’événements) avant de déployer en production.
Visualisations#
Simulation Event Sourcing — reconstruction d’état#
from dataclasses import dataclass, field
from typing import List, Optional
from datetime import datetime, timedelta
import random
# Définition des types d'événements
@dataclass
class Event:
account_id: str
event_type: str
timestamp: str
amount: Optional[float] = None
description: Optional[str] = None
version: int = 0
class EventStore:
"""Store d'événements en mémoire."""
def __init__(self):
self._events: List[Event] = []
def append(self, event: Event):
event.version = len(self._events) + 1
self._events.append(event)
def get_events(self, account_id: str, after_version: int = 0) -> List[Event]:
return [e for e in self._events
if e.account_id == account_id and e.version > after_version]
def get_all(self) -> List[Event]:
return list(self._events)
class BankAccount:
"""Entité domaine reconstruite depuis les événements."""
def __init__(self, account_id: str):
self.account_id = account_id
self.balance = 0.0
self.owner = ""
self.version = 0
self.is_active = False
self._event_history = []
def apply(self, event: Event):
"""Applique un événement à l'état courant."""
self.version = event.version
self._event_history.append(event)
if event.event_type == "AccountOpened":
self.is_active = True
self.owner = event.description
elif event.event_type == "MoneyDeposited":
self.balance += event.amount
elif event.event_type == "MoneyWithdrawn":
self.balance -= event.amount
elif event.event_type == "MoneyTransferred":
self.balance -= event.amount
elif event.event_type == "AccountClosed":
self.is_active = False
@classmethod
def reconstruct(cls, account_id: str, store: EventStore, at_version: int = None) -> "BankAccount":
"""Reconstruit l'état à partir des événements."""
account = cls(account_id)
events = store.get_events(account_id)
for event in events:
if at_version and event.version > at_version:
break
account.apply(event)
return account
# Génération d'un historique de compte simulé
store = EventStore()
account_id = "ACC-ALICE-001"
rng_sim = random.Random(42)
base_date = datetime(2024, 1, 1)
events_sequence = [
Event(account_id, "AccountOpened", "2024-01-01", description="Alice Martin"),
Event(account_id, "MoneyDeposited", "2024-01-05", amount=2000.0, description="Virement salaire"),
Event(account_id, "MoneyWithdrawn", "2024-01-08", amount=150.0, description="Retrait DAB"),
Event(account_id, "MoneyDeposited", "2024-01-15", amount=500.0, description="Remboursement"),
Event(account_id, "MoneyTransferred","2024-01-20", amount=300.0, description="Loyer"),
Event(account_id, "MoneyDeposited", "2024-02-05", amount=2000.0, description="Virement salaire"),
Event(account_id, "MoneyWithdrawn", "2024-02-10", amount=75.0, description="Abonnement Netflix"),
Event(account_id, "MoneyDeposited", "2024-02-14", amount=250.0, description="Freelance"),
Event(account_id, "MoneyWithdrawn", "2024-02-22", amount=400.0, description="Courses"),
Event(account_id, "MoneyDeposited", "2024-03-05", amount=2000.0, description="Virement salaire"),
]
for ev in events_sequence:
store.append(ev)
# Reconstruction à différents instants (time travel)
print("=" * 62)
print(" EVENT SOURCING — Reconstruction temporelle d'un compte")
print("=" * 62)
print(f"\n{'Version':<10} {'Événement':<22} {'Montant':>10} {'Solde':>10}")
print("-" * 62)
running_account = BankAccount(account_id)
for event in store.get_events(account_id):
running_account.apply(event)
amount_str = f"{event.amount:+.2f}€" if event.amount else "—"
print(f"v{running_account.version:<9} {event.event_type:<22} {amount_str:>10} {running_account.balance:>9.2f}€")
print("-" * 62)
print(f"\nÉtat courant (v{running_account.version}) : solde = {running_account.balance:.2f}€")
# Time travel — état à la version 5
past = BankAccount.reconstruct(account_id, store, at_version=5)
print(f"État à v5 (snapshot partiel) : solde = {past.balance:.2f}€")
print(f"\nTotal événements stockés : {len(store.get_all())}")
print("=" * 62)
==============================================================
EVENT SOURCING — Reconstruction temporelle d'un compte
==============================================================
Version Événement Montant Solde
--------------------------------------------------------------
v1 AccountOpened — 0.00€
v2 MoneyDeposited +2000.00€ 2000.00€
v3 MoneyWithdrawn +150.00€ 1850.00€
v4 MoneyDeposited +500.00€ 2350.00€
v5 MoneyTransferred +300.00€ 2050.00€
v6 MoneyDeposited +2000.00€ 4050.00€
v7 MoneyWithdrawn +75.00€ 3975.00€
v8 MoneyDeposited +250.00€ 4225.00€
v9 MoneyWithdrawn +400.00€ 3825.00€
v10 MoneyDeposited +2000.00€ 5825.00€
--------------------------------------------------------------
État courant (v10) : solde = 5825.00€
État à v5 (snapshot partiel) : solde = 2050.00€
Total événements stockés : 10
==============================================================
Diagramme CQRS#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(15, 8))
ax.set_xlim(0, 15)
ax.set_ylim(0, 8)
ax.axis("off")
def box(ax, x, y, w, h, label, sublabel="", color="#3498db", fontsize=9):
rect = mpatches.FancyBboxPatch((x, y), w, h,
boxstyle="round,pad=0.1",
facecolor=color, edgecolor="white",
linewidth=2, alpha=0.88)
ax.add_patch(rect)
ax.text(x + w/2, y + h/2 + (0.15 if sublabel else 0), label,
ha="center", va="center", fontsize=fontsize,
fontweight="bold", color="white")
if sublabel:
ax.text(x + w/2, y + h/2 - 0.22, sublabel,
ha="center", va="center", fontsize=7.5, color="white", alpha=0.88)
arrow = lambda ax, x1, y1, x2, y2, color="#2c3e50", label="", style="-|>": \
ax.annotate("", xy=(x2, y2), xytext=(x1, y1),
arrowprops=dict(arrowstyle=style, color=color, lw=2.0))
# Client
box(ax, 0.2, 3.5, 1.8, 1.0, "Client", "API/UI", "#2c3e50")
# Séparateur write/read
ax.axvline(7.5, color="#bdc3c7", linestyle="--", linewidth=1.5, alpha=0.7)
ax.text(7.5, 7.7, "Write Side | Read Side",
ha="center", fontsize=11, color="#7f8c8d", style="italic")
# Write side
box(ax, 2.2, 5.5, 2.2, 0.9, "Command Bus", "PlaceOrder\nCancelOrder", "#e74c3c")
box(ax, 2.2, 4.0, 2.2, 0.9, "Command Handler", "Validation\nmétier", "#c0392b")
box(ax, 2.2, 2.5, 2.2, 0.9, "Domain Model", "Order · Payment\nEntities", "#9b59b6")
box(ax, 2.2, 1.0, 2.2, 0.9, "Write Store", "PostgreSQL\n(normalisé)", "#7f8c8d")
# Événements
box(ax, 4.7, 3.0, 2.3, 1.2, "Event Bus", "OrderPlaced\nOrderCancelled\nPaymentCompleted",
"#e67e22", fontsize=8)
# Read side — projections multiples
box(ax, 8.0, 5.2, 2.5, 1.0, "Projection 1", "Vue commandes\nclient (Redis)", "#2980b9")
box(ax, 8.0, 3.7, 2.5, 1.0, "Projection 2", "Dashboard analytics\n(Elasticsearch)", "#16a085")
box(ax, 8.0, 2.2, 2.5, 1.0, "Projection 3", "Reporting finance\n(ClickHouse)", "#8e44ad")
box(ax, 11.0, 3.7, 2.2, 1.0, "Query Handler", "GetOrder\nSearchOrders", "#27ae60")
box(ax, 13.4, 3.7, 1.4, 1.0, "Client\nRead", "", "#2c3e50")
# Flèches write side
arrow(ax, 2.0, 4.0, 2.2, 6.2)
arrow(ax, 3.3, 5.5, 3.3, 4.9)
arrow(ax, 3.3, 4.0, 3.3, 3.4)
arrow(ax, 3.3, 2.5, 3.3, 1.9)
# Lien vers event bus
arrow(ax, 4.4, 3.6, 4.7, 3.6, color="#e67e22")
# Projections
for y_proj in [5.7, 4.2, 2.7]:
arrow(ax, 7.0, 3.6, 8.0, y_proj, color="#e67e22")
# Read side
for y_proj in [5.7, 4.2, 2.7]:
ax.plot([10.5, 11.0], [y_proj, 4.2], color="#2c3e50", lw=1.5,
linestyle="-", alpha=0.5)
arrow(ax, 11.0, 4.2, 11.0, 4.7)
arrow(ax, 13.2, 4.2, 13.4, 4.2)
arrow(ax, 2.0, 4.0, 2.0, 4.0)
# Label query
ax.annotate("", xy=(2.2, 5.8), xytext=(2.0, 5.8),
arrowprops=dict(arrowstyle="-|>", color="#e74c3c", lw=2))
ax.text(1.5, 5.9, "Command", fontsize=8, color="#e74c3c", fontweight="bold")
ax.annotate("", xy=(13.4, 4.2), xytext=(13.2, 4.2),
arrowprops=dict(arrowstyle="-|>", color="#27ae60", lw=2))
ax.text(12.0, 5.0, "Query", fontsize=8, color="#27ae60", fontweight="bold")
ax.text(7.5, 0.3, "Les modèles de lecture (projections) sont mis à jour de manière asynchrone\n"
"par les événements — eventual consistency entre write side et read side",
ha="center", fontsize=9, color="#7f8c8d", style="italic")
ax.set_title("CQRS — Command Query Responsibility Segregation\nSéparation write/read models et projections",
fontsize=13, fontweight="bold", pad=15)
plt.savefig("_static/09_cqrs.png", dpi=150, bbox_inches="tight")
plt.show()
Simulation Saga choreography#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Scénario 1 : succès complet
# Scénario 2 : échec paiement → compensation
fig, axes = plt.subplots(1, 2, figsize=(16, 9))
services = ["Order\nService", "Inventory\nService", "Payment\nService", "Shipping\nService"]
n_services = len(services)
def draw_saga(ax, title, steps, failure_step=None):
ax.set_xlim(-0.5, n_services - 0.5)
ax.set_ylim(-1, len(steps) + 1)
ax.axis("off")
# En-têtes services
for i, svc in enumerate(services):
color = "#3498db"
rect = mpatches.FancyBboxPatch((i - 0.35, len(steps)), 0.7, 0.7,
boxstyle="round,pad=0.05",
facecolor=color, edgecolor="white",
linewidth=2, alpha=0.9)
ax.add_patch(rect)
ax.text(i, len(steps) + 0.35, svc, ha="center", va="center",
fontsize=9, fontweight="bold", color="white")
# Ligne de vie
ax.plot([i, i], [-0.5, len(steps)], color="#bdc3c7",
linestyle=":", linewidth=1.5, alpha=0.7)
for step_idx, step in enumerate(steps):
y = len(steps) - 1 - step_idx
is_compensation = step.get("compensation", False)
is_failure = step.get("failure", False)
color = "#e74c3c" if is_failure else ("#e67e22" if is_compensation else "#2ecc71")
style = "dashed" if is_compensation else "solid"
head = "-|>" if not is_compensation else "<|-"
x_from = step["from"]
x_to = step["to"]
# Flèche
ax.annotate("", xy=(x_to, y + 0.1), xytext=(x_from, y + 0.1),
arrowprops=dict(arrowstyle=head, color=color,
lw=2.0, linestyle=style))
# Label de l'événement
x_mid = (x_from + x_to) / 2
ax.text(x_mid, y + 0.35, step["event"],
ha="center", va="bottom", fontsize=8,
color=color, fontweight="bold" if is_failure else "normal",
style="italic" if is_compensation else "normal")
# Icône résultat
if is_failure:
ax.text(x_to, y, "✗", ha="center", va="center",
fontsize=14, color="#e74c3c")
elif is_compensation:
ax.text((x_from + x_to)/2, y - 0.2, "↩ compensation",
ha="center", va="top", fontsize=7, color="#e67e22")
ax.set_title(title, fontsize=11, fontweight="bold", pad=10)
# Saga succès
steps_success = [
{"from": 0, "to": 1, "event": "OrderCreated →"},
{"from": 1, "to": 2, "event": "StockReserved →"},
{"from": 2, "to": 3, "event": "PaymentCharged →"},
{"from": 3, "to": 0, "event": "← ShipmentScheduled"},
]
draw_saga(axes[0], "Saga choreography — Succès complet", steps_success)
# Saga avec échec paiement et compensations
steps_failure = [
{"from": 0, "to": 1, "event": "OrderCreated →"},
{"from": 1, "to": 2, "event": "StockReserved →"},
{"from": 2, "to": 2, "event": "PaymentFailed ✗", "failure": True},
{"from": 2, "to": 1, "event": "← StockReleased", "compensation": True},
{"from": 1, "to": 0, "event": "← OrderCancelled", "compensation": True},
]
draw_saga(axes[1], "Saga choreography — Échec paiement + compensations", steps_failure)
# Légende commune
legend_patches = [
plt.Line2D([0], [0], color="#2ecc71", lw=2, label="Transaction locale (succès)"),
plt.Line2D([0], [0], color="#e74c3c", lw=2, label="Échec"),
plt.Line2D([0], [0], color="#e67e22", lw=2, linestyle="dashed", label="Transaction compensatoire"),
]
fig.legend(handles=legend_patches, loc="lower center", fontsize=10, ncol=3,
bbox_to_anchor=(0.5, 0.01))
plt.suptitle("Saga Pattern — Choreography : transactions distribuées sans 2PC",
fontsize=13, fontweight="bold", y=1.01)
plt.savefig("_static/09_saga.png", dpi=150, bbox_inches="tight")
plt.show()
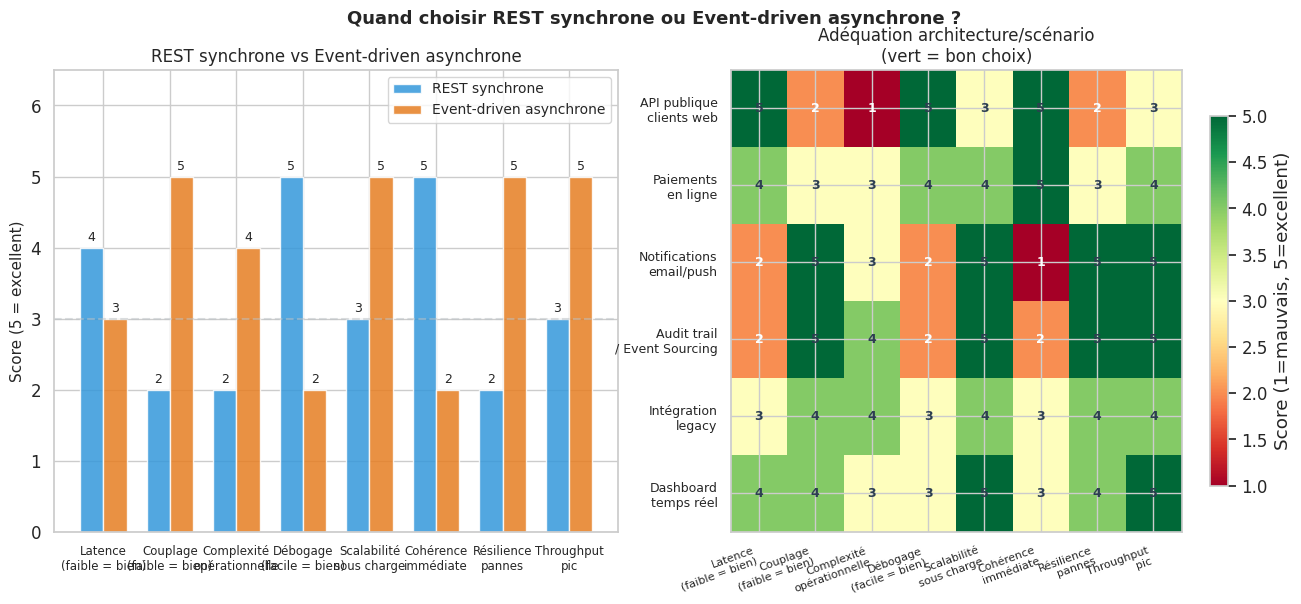
Comparaison REST sync vs event-driven async#
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
critères = [
"Latence\n(faible = bien)",
"Couplage\n(faible = bien)",
"Complexité\nopérationnelle",
"Débogage\n(facile = bien)",
"Scalabilité\nsous charge",
"Cohérence\nimmédiate",
"Résilience\npannes",
"Throughput\npic",
]
# Scores : 5 = excellent pour le critère
rest_sync = [4, 2, 2, 5, 3, 5, 2, 3]
event_async = [3, 5, 4, 2, 5, 2, 5, 5]
# Note : pour "couplage" et "latence", un score élevé = bon (faible couplage, faible latence)
# Adaptons les labels et la sémantique
x = np.arange(len(critères))
width = 0.35
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# Barplot comparatif
bars1 = axes[0].bar(x - width/2, rest_sync, width,
label="REST synchrone", color="#3498db", alpha=0.85)
bars2 = axes[0].bar(x + width/2, event_async, width,
label="Event-driven asynchrone", color="#e67e22", alpha=0.85)
for bar in bars1 + bars2:
axes[0].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.05,
f"{int(bar.get_height())}", ha="center", va="bottom", fontsize=9)
axes[0].set_xticks(x)
axes[0].set_xticklabels(critères, fontsize=8.5)
axes[0].set_ylabel("Score (5 = excellent)", fontsize=11)
axes[0].set_ylim(0, 6.5)
axes[0].set_title("REST synchrone vs Event-driven asynchrone", fontsize=12)
axes[0].legend(fontsize=10)
axes[0].axhline(3, color="#bdc3c7", linestyle="--", alpha=0.5)
# Heatmap des profils d'usage
scenarios = {
"API publique\nclients web": [5, 2, 1, 5, 3, 5, 2, 3],
"Paiements\nen ligne": [4, 3, 3, 4, 4, 5, 3, 4],
"Notifications\nemail/push": [2, 5, 3, 2, 5, 1, 5, 5],
"Audit trail\n/ Event Sourcing": [2, 5, 4, 2, 5, 2, 5, 5],
"Intégration\nlegacy": [3, 4, 4, 3, 4, 3, 4, 4],
"Dashboard\ntemps réel": [4, 4, 3, 3, 5, 3, 4, 5],
}
data = np.array(list(scenarios.values()))
im = axes[1].imshow(data, cmap="RdYlGn", aspect="auto", vmin=1, vmax=5)
axes[1].set_xticks(range(len(critères)))
axes[1].set_xticklabels(critères, fontsize=8, rotation=20, ha="right")
axes[1].set_yticks(range(len(scenarios)))
axes[1].set_yticklabels(list(scenarios.keys()), fontsize=9)
for i in range(data.shape[0]):
for j in range(data.shape[1]):
axes[1].text(j, i, str(data[i, j]),
ha="center", va="center", fontsize=9, fontweight="bold",
color="white" if data[i, j] < 3 else "#2c3e50")
plt.colorbar(im, ax=axes[1], shrink=0.8, label="Score (1=mauvais, 5=excellent)")
axes[1].set_title("Adéquation architecture/scénario\n(vert = bon choix)", fontsize=12)
plt.suptitle("Quand choisir REST synchrone ou Event-driven asynchrone ?",
fontsize=13, fontweight="bold")
plt.savefig("_static/09_rest_vs_events.png", dpi=150, bbox_inches="tight")
plt.show()
Résumé#
L’architecture événementielle représente un changement de paradigme : on cesse de penser en termes de requêtes/réponses pour penser en termes de faits qui se propagent dans le système. Ce paradigme est puissant pour les systèmes distribués à forte charge, mais il introduce une complexité opérationnelle et intellectuelle significative.
Points clés :
Distinguer événements (fait passé, immuable, public), commandes (instruction à un destinataire précis) et requêtes (demande d’information sans effet de bord) est la base conceptuelle de tout système événementiel.
L’Event-Driven Architecture découple producteurs et consommateurs dans le temps, l’espace et la synchronisation — au prix d’une complexité de débogage accrue.
CQRS sépare les modèles de lecture et d’écriture. Les projections maintiennent les modèles de lecture à jour via les événements. Il n’implique pas nécessairement Event Sourcing.
L’Event Sourcing stocke les événements comme source de vérité. Il offre un audit trail complet et le « time travel » mais complexifie les requêtes simples et l’évolution des schémas.
Le Saga pattern gère les transactions longues distribuées sans 2PC. La choreography offre moins de couplage ; l’orchestration offre plus de visibilité.
Kafka et RabbitMQ sont les brokers dominants avec des modèles distincts : log distribué rétentif (Kafka) vs queue broker AMQP (RabbitMQ). Le choix dépend du besoin de replay, du débit et du type de routing.
L’évolution des schémas d’événements doit être gérée explicitement (backward/forward compatibility, Schema Registry) — les événements sont des interfaces publiques.
Les pièges principaux (ordering, idempotence, exactly-once, debugging asynchrone) ont chacun des réponses architecturales connues. Les ignorer conduit à des systèmes fragiles et difficiles à opérer.
L’architecture événementielle comme investissement
Adopter une architecture événementielle est un investissement : en infrastructure (broker, schema registry, observabilité), en compétences (paradigme asynchrone, Event Sourcing) et en discipline (contracts d’événements, idempotence). Cet investissement est rentable pour les systèmes qui bénéficient du découplage fort, du replay d’événements ou de la scalabilité indépendante des producteurs et consommateurs. Pour un CRUD simple, c’est de la sur-ingénierie.