Chapitre 2 — Qualités architecturales#
Les qualités architecturales sont les propriétés d’un système qui ne décrivent pas ce qu’il fait, mais comment bien il le fait. Elles déterminent la différence entre un système qui fonctionne et un système sur lequel on peut compter. Ce chapitre examine les huit qualités les plus décisives, leurs métriques, et les tensions qu’elles créent entre elles.
Disponibilité — SLA, SLO, SLI et les « nines »#
La disponibilité est la fraction de temps pendant laquelle un système est opérationnel et accessible. Elle est exprimée en pourcentage sur une période de référence (généralement un an ou un mois).
Trois concepts structurent la gestion de la disponibilité dans les systèmes modernes :
SLI — Service Level Indicator : une mesure quantitative de la qualité du service. Exemples : taux de succès des requêtes HTTP, latence au percentile 99, taux d’erreur. C’est la donnée brute.
SLO — Service Level Objective : l’objectif interne de l’équipe sur un SLI. « 99,9% des requêtes doivent aboutir en moins de 200ms. » Le SLO est la cible que l’équipe s’engage à atteindre.
SLA — Service Level Agreement : le contrat formalisé avec les clients ou partenaires. Le SLA inclut les pénalités en cas de non-respect. En pratique, le SLO est toujours plus exigeant que le SLA, pour garder une marge.
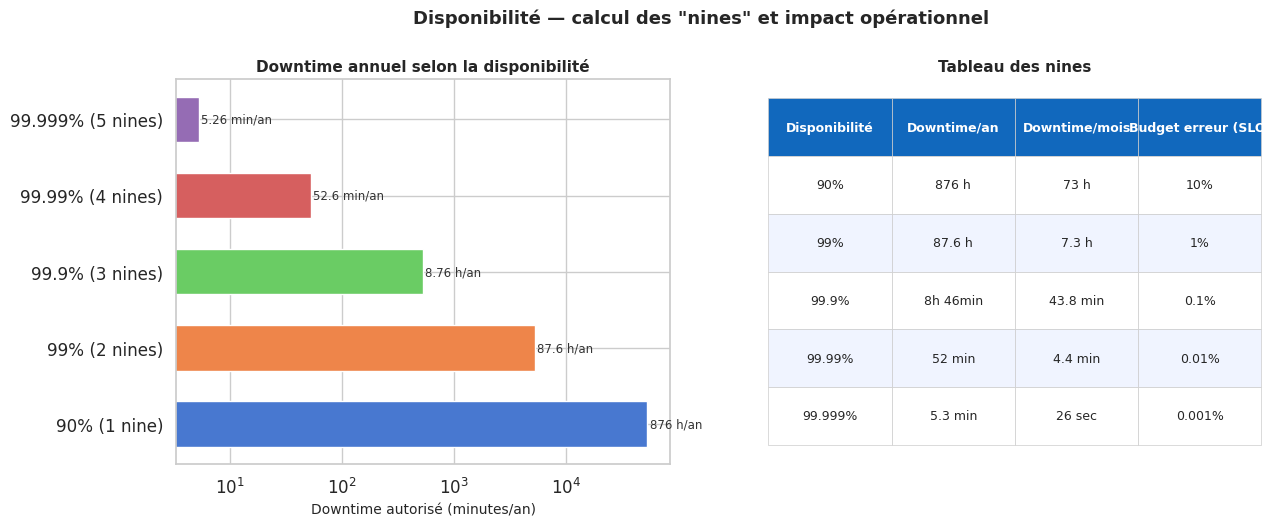
La disponibilité se mesure en « nines » : 99% est « deux nines », 99,9% est « trois nines », 99,99% est « quatre nines ». La progression est trompeuse — chaque nine supplémentaire réduit le downtime autorisé d’un ordre de grandeur.
Le budget d’erreur
Google SRE a popularisé le concept de « error budget » : si le SLO est de 99,9%, le budget d’erreur est 0,1% du temps, soit environ 8,7 heures par an. Ce budget peut être « dépensé » en déploiements risqués, en expérimentations. S’il est épuisé, les déploiements sont gelés jusqu’à la fin de la période. Cette approche transforme la disponibilité en ressource partagée entre les équipes de développement et d’exploitation.
MTTF et MTTR : Mean Time To Failure et Mean Time To Repair sont deux métriques complémentaires. La disponibilité réelle se calcule : Disponibilité = MTTF / (MTTF + MTTR). Pour atteindre 99,99%, il faut soit des composants très fiables (MTTF élevé), soit une capacité de rétablissement très rapide (MTTR faible), soit les deux.
La redondance est le mécanisme principal pour augmenter la disponibilité système. En série, la disponibilité se multiplie (deux composants à 99% en série donnent 98,01%). En parallèle avec basculement, la disponibilité s’améliore : deux composants à 99% en parallèle actif-passif donnent 99,99%.
Scalabilité — horizontale, verticale, élasticité#
La scalabilité est la capacité d’un système à maintenir ses attributs de performance sous une charge croissante. On distingue deux axes.
Scalabilité verticale (scale up) : augmenter les ressources d’une machine existante — plus de CPU, plus de RAM, disques plus rapides. Simple à mettre en œuvre, elle atteint rapidement ses limites physiques et financières. Un seul serveur, aussi puissant soit-il, reste un point de défaillance unique.
Scalabilité horizontale (scale out) : ajouter des instances supplémentaires derrière un répartiteur de charge. Théoriquement illimitée, elle exige que l’application soit conçue pour être stateless ou que l’état soit externalisé (base de données partagée, cache distribué). C’est l’approche dominante dans les architectures cloud.
L’élasticité est la capacité d’un système à s’adapter dynamiquement à la charge — scale out sous charge, scale in quand la charge diminue. L’élasticité nécessite une scalabilité horizontale et une automatisation du provisionnement. AWS Auto Scaling et Kubernetes Horizontal Pod Autoscaler sont des implémentations courantes.
Scalabilité ≠ performance
La scalabilité et la performance sont des attributs distincts. Un système lent peut être scalable (la latence reste constante même sous charge élevée, si on ajoute des ressources). Un système rapide peut ne pas être scalable (la latence dégrade sous charge). L’objectif est d’avoir les deux : une performance acceptable à faible charge, et une scalabilité qui maintient cette performance sous charge croissante.
La scalabilité a des limites fondamentales. La loi d’Amdahl (chapitre 3) montre que la fraction séquentielle d’un programme plafonne le gain obtenu en parallélisant. Pour les systèmes distribués, la loi de Little lie la charge, la concurrence et la latence — augmenter la charge au-delà d’un seuil critique dégrade la latence de façon non linéaire.
Maintenabilité — couplage, cohésion, métriques#
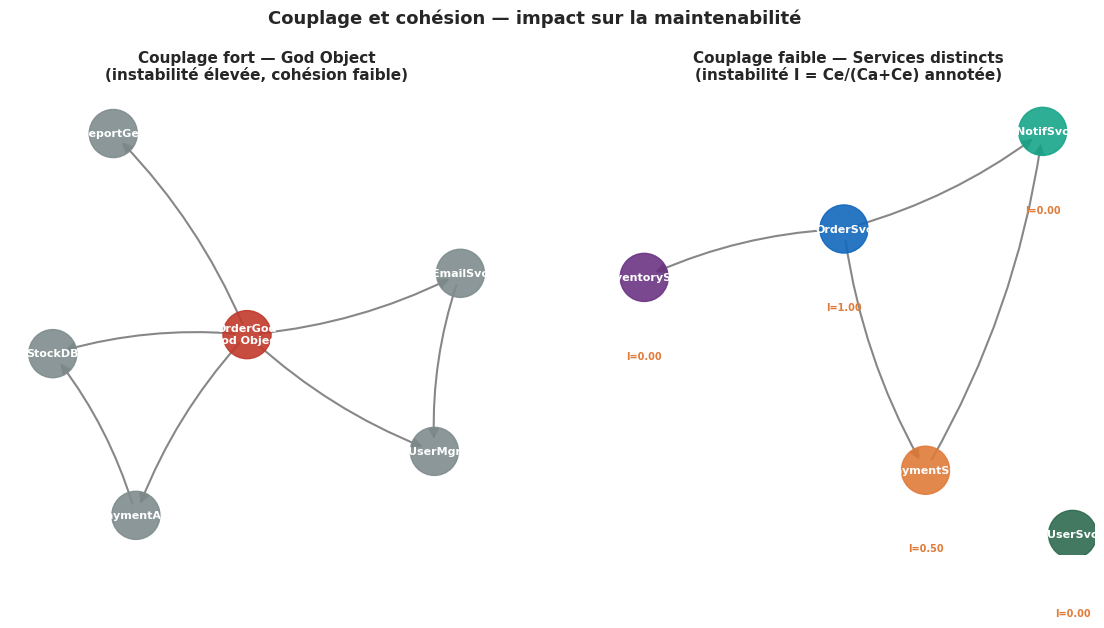
La maintenabilité est la facilité avec laquelle un système peut être modifié, corrigé et amélioré. Elle est directement liée à deux propriétés du code : le couplage et la cohésion.
La cohésion mesure le degré auquel les éléments d’un module ont une raison d’être ensemble. Une classe qui gère l’authentification, la sérialisation JSON et l’envoi d’emails a une cohésion faible. Une classe qui ne gère que l’authentification a une cohésion élevée. Le principe de responsabilité unique (SRP) formalise cet objectif.
Le couplage mesure le degré d’interdépendance entre modules. Un couplage fort signifie qu’une modification dans un module nécessite des modifications dans plusieurs autres. Le couplage afférent (Ca) compte le nombre de modules qui dépendent d’un module donné. Le couplage efférent (Ce) compte le nombre de modules dont dépend un module. L’instabilité se calcule : I = Ce / (Ca + Ce). Une valeur proche de 0 indique un module stable (peu de dépendances sortantes, beaucoup de dépendances entrantes). Une valeur proche de 1 indique un module instable.
La complexité cyclomatique (McCabe) mesure le nombre de chemins indépendants dans un programme. Elle se calcule comme V(G) = E - N + 2P sur le graphe de contrôle de flux, où E est le nombre d’arêtes, N le nombre de nœuds, et P le nombre de composantes connexes. En pratique : chaque if, while, for, case ajoute 1 à la complexité. Une valeur supérieure à 10 par fonction est un signal d’alarme.
La dette technique est la métaphore de Ward Cunningham pour désigner le coût différé d’une conception non optimale. Comme une dette financière, elle génère des intérêts : plus on attend, plus le coût de remboursement augmente. Les outils SonarQube, CodeClimate ou CodeScene quantifient cette dette en jours-hommes estimés.
Principe de l’abstraction stable
Robert Martin (Uncle Bob) formule la règle d’abstractivité stable : les modules stables (instabilité faible) doivent être abstraits. Les modules instables (instabilité élevée) peuvent être concrets. Un module stable et concret est rigide — difficile à modifier sans impacter ses dépendants. La zone idéale sur le graphe Abstractivité/Instabilité est la « main séquence » : A + I ≈ 1.
Testabilité — architecture testable et pyramide de tests#
La testabilité est la facilité avec laquelle un système peut être testé. Ce n’est pas une propriété du code de test, c’est une propriété de l’architecture. Un système difficile à tester l’est généralement parce qu’il est mal conçu.
Les obstacles à la testabilité sont récurrents :
Dépendances sur des ressources externes (base de données, services tiers, système de fichiers)
État global mutable partagé entre composants
Constructeurs qui font trop de travail
Couplage fort entre couches
L’injection de dépendances est le mécanisme architectural de base qui rend un système testable. En passant les dépendances en paramètre plutôt qu’en les instanciant dans le composant, on permet leur substitution par des doublures de test.
La pyramide de tests (Mike Cohn) décrit la distribution idéale des tests :
Tests unitaires (base) : nombreux, rapides, isolés. Testent une unité de logique.
Tests d’intégration (milieu) : moins nombreux, testent l’interaction entre composants ou avec des ressources réelles.
Tests de bout en bout (sommet) : peu nombreux, lents, testent les scénarios utilisateurs complets.
La pyramide est inversée dans de nombreux projets (beaucoup de tests E2E, peu de tests unitaires), ce qui produit des suites de tests lentes, fragiles et difficiles à maintenir.
Les test doubles (Meszaros) désignent les objets qui remplacent des dépendances réelles dans les tests :
Stub : retourne des valeurs prédéfinies
Mock : vérifie que certaines interactions ont eu lieu
Fake : implémentation simplifiée mais fonctionnelle (ex. base de données en mémoire)
Spy : enregistre les appels pour vérification ultérieure
Testabilité et hexagonale
L’architecture hexagonale (Ports & Adapters, chapitre 6) est conçue pour maximiser la testabilité. Le domaine métier n’a aucune dépendance sur l’infrastructure — il peut être testé unitairement sans base de données ni réseau. Les adaptateurs (implémentations des ports) sont testés séparément en intégration.
Sécurité — CIA, surface d’attaque, moindre privilège#
La sécurité en architecture logicielle s’organise autour de trois propriétés fondamentales, connues sous le trigramme CIA :
Confidentialité : seules les entités autorisées accèdent aux données. Mécanismes : chiffrement au repos et en transit, contrôle d’accès basé sur les rôles (RBAC), authentification forte.
Intégrité : les données ne peuvent pas être modifiées sans autorisation et toute modification est détectable. Mécanismes : signatures numériques, checksums, journaux d’audit immuables.
Disponibilité : le système reste accessible aux entités autorisées malgré des tentatives d’attaque. Les attaques DDoS ciblent spécifiquement cette propriété.
La surface d’attaque est l’ensemble des points d’entrée par lesquels un attaquant peut interagir avec le système. Réduire la surface d’attaque est un objectif architectural fondamental : chaque API exposée, chaque port ouvert, chaque dépendance tierce est un vecteur d’attaque potentiel.
Le principe du moindre privilège stipule que tout composant, utilisateur ou processus ne doit avoir que les droits strictement nécessaires à sa fonction. Un service de lecture de catalogue ne doit pas avoir les droits d’écriture en base. Un microservice de notification ne doit pas avoir accès aux données financières.
La défense en profondeur (defense in depth) consiste à empiler plusieurs couches de sécurité indépendantes, de façon qu’une défaillance sur une couche ne compromette pas le système entier. WAF, pare-feu applicatif, authentification, autorisation, chiffrement, détection d’anomalies — chaque couche assume que les précédentes ont été franchies.
Shift-left security
La sécurité ajoutée après coup (en production) est systématiquement plus coûteuse et moins efficace que la sécurité intégrée dès la conception. Le modèle de menaces (threat modeling) — identifier les acteurs malveillants, les vecteurs d’attaque et les contre-mesures — doit faire partie des activités de conception architecturale, pas de l’audit final.
Performance — latence, throughput, percentiles, loi de Little#
La performance se décline selon deux axes orthogonaux et souvent confondus :
La latence est le temps de traitement d’une requête individuelle — de l’envoi de la requête à la réception de la réponse. Elle intéresse l’utilisateur final qui attend un résultat.
Le throughput (débit) est le nombre de requêtes traitées par unité de temps — requêtes par seconde, transactions par heure. Il intéresse la capacité système à absorber la charge.
La confusion entre les deux conduit à des erreurs d’optimisation fréquentes. Un système peut avoir un throughput élevé avec une latence élevée (traitements par batch) ou une latence faible avec un throughput modeste.
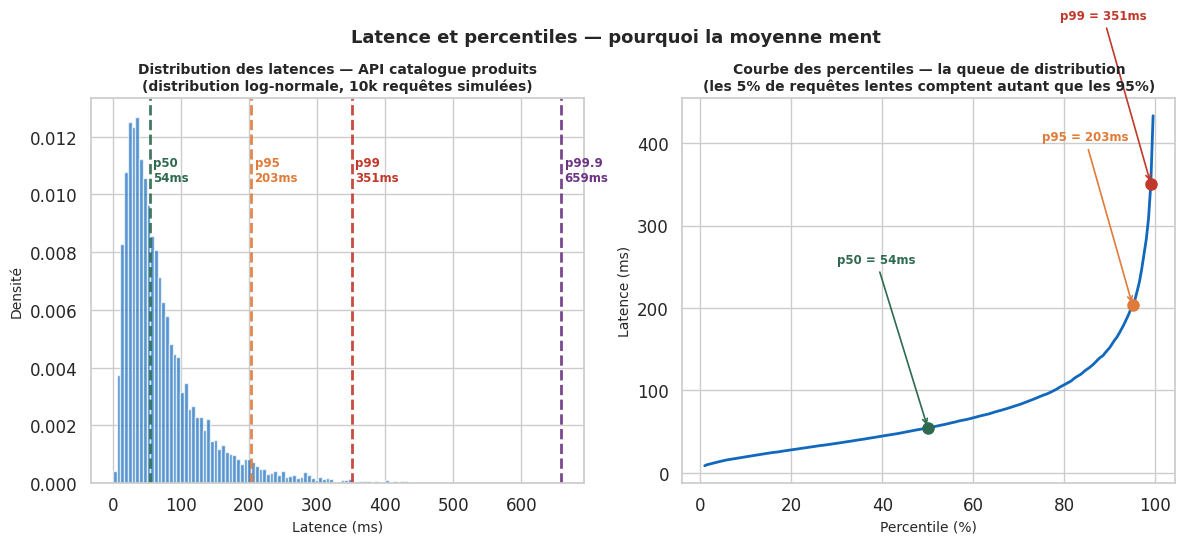
Les percentiles sont la façon correcte de mesurer la latence. La moyenne est trompeuse car elle masque la queue de distribution. Si 1% des requêtes prennent 10 secondes, la moyenne peut sembler raisonnable pendant que 1 utilisateur sur 100 a une expérience catastrophique.
p50 (médiane) : 50% des requêtes sont traitées en dessous de cette valeur
p95 : 95% des requêtes sont en dessous — la référence courante pour les SLO
p99 : 99% des requêtes sont en dessous — les « tail latencies »
p99.9 : le « long tail » — critique pour les systèmes à haute fréquence
Amazon a montré que 100ms de latence supplémentaire réduit les ventes de 1%. Cette corrélation entre performance et revenu justifie économiquement les investissements architecturaux en performance.
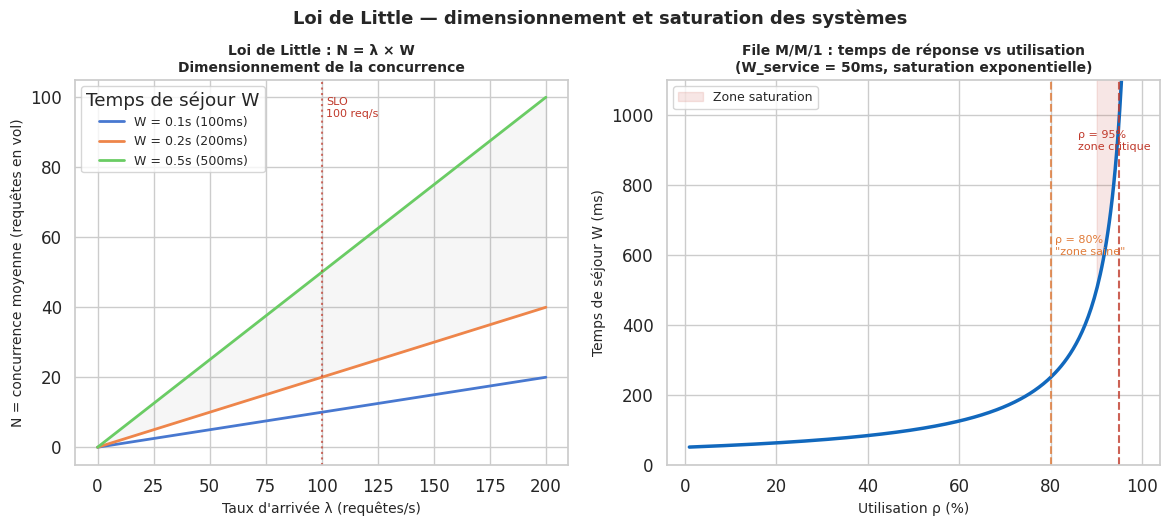
La loi de Little (N = λ × W) relie trois grandeurs fondamentales d’un système de file d’attente :
N: nombre moyen de requêtes dans le système (en cours de traitement + en attente)λ(lambda) : taux d’arrivée des requêtes (requêtes/seconde)W: temps de séjour moyen d’une requête dans le système (secondie)
Si λ = 100 req/s et W = 0,2s, alors il y a en permanence N = 20 requêtes dans le système. Pour réduire le temps de réponse, on peut soit réduire le taux d’arrivée (rare), soit réduire le temps de traitement (optimisation), soit augmenter la capacité de traitement parallèle (scaling).
Observabilité — logs, métriques, traces#
L’observabilité est la capacité à comprendre l’état interne d’un système à partir de ses sorties externes. Elle répond à la question : « Que se passe-t-il dans ce système en ce moment, et pourquoi ? »
Le monitoring traditionnel répond à des questions connues à l’avance : « Le service est-il up ? », « Le CPU est-il au-dessus de 80% ? ». L’observabilité permet de répondre à des questions non anticipées : « Pourquoi les requêtes d’un sous-ensemble d’utilisateurs sont-elles lentes uniquement en soirée sur cette région géographique ? »
Les trois piliers de l’observabilité sont complémentaires et non substituables :
Les logs sont des enregistrements d’événements discrets, horodatés. Ils permettent le débogage post-mortem. Leurs limites : volume élevé, coût de stockage, difficulté d’agrégation en système distribué. Les formats structurés (JSON) facilitent l’indexation et la recherche.
Les métriques sont des mesures numériques agrégées dans le temps : compteurs, jauges, histogrammes. Elles permettent la visualisation de tendances, l’alerting, et le capacity planning. Prometheus et son modèle de scraping sont le standard de facto en environnement cloud-native.
Les traces distribuées reconstituent le parcours d’une requête à travers les différents services d’une architecture distribuée. Chaque service propage un identifiant de trace (trace ID) et crée des spans pour chaque opération. OpenTelemetry standardise l’instrumentation. Jaeger, Zipkin et AWS X-Ray sont des backends courants.
Les quatre signaux d’or (Google SRE)
Google SRE a identifié quatre métriques à monitorer en priorité : la latence (temps de réponse), le trafic (volume de requêtes), les erreurs (taux d’échec) et la saturation (utilisation des ressources). Ces quatre signaux couvrent la grande majorité des incidents de production. Toute stack d’observabilité devrait les exposer nativement.
Compromis — ATAM et la nature des trade-offs#
La conclusion de ce chapitre est que les attributs de qualité sont fondamentalement en tension. Il n’existe pas d’architecture qui maximise simultanément tous les attributs. Chaque décision architecturale est un compromis.
Quelques tensions classiques :
Disponibilité vs cohérence : le théorème CAP (chapitre 3) formalise cette tension dans les systèmes distribués. Augmenter la disponibilité via la réplication introduit des fenêtres d’incohérence.
Performance vs sécurité : chiffrer les données au repos et en transit ajoute une latence de quelques millisecondes. Le TLS handshake a un coût. Les validations de sécurité sont des opérations supplémentaires.
Maintenabilité vs performance : une abstraction supplémentaire (interface, inversion de dépendance) facilite la testabilité et la maintenabilité, mais ajoute une indirection qui peut dégrader légèrement la performance.
Scalabilité vs consistance : les architectures event-driven qui facilitent le scale-out introduisent de la cohérence éventuelle, ce qui complique le raisonnement sur l’état du système.
ATAM — Architecture Tradeoff Analysis Method est une méthode formelle d’évaluation architecturale développée par le SEI (Software Engineering Institute). Elle consiste à :
Collecter les scénarios de qualité prioritaires des parties prenantes
Identifier les décisions architecturales qui impactent ces scénarios
Analyser les points de sensibilité (une décision qui impacte fortement un attribut)
Analyser les trade-offs (une décision qui améliore un attribut et dégrade un autre)
Identifier les risques (combinaisons de décisions et scénarios à risque élevé)
L’ATAM n’est pas un processus qu’on applique dans sa totalité à chaque projet. C’est un cadre conceptuel dont on peut extraire des outils partiels — notamment la formalisation des trade-offs — qui s’appliquent à des évaluations architecturales de toute taille.
Visualisations#
Disponibilité et calcul des « nines »#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
import pandas as pd
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
nines = {
"90% (1 nine)": 90.0,
"99% (2 nines)": 99.0,
"99.9% (3 nines)": 99.9,
"99.99% (4 nines)":99.99,
"99.999% (5 nines)":99.999,
}
heures_an = 8760
downtimes = {label: (1 - v/100) * heures_an * 60 for label, v in nines.items()}
downtime_str = {
"90% (1 nine)": "876 h/an",
"99% (2 nines)": "87.6 h/an",
"99.9% (3 nines)": "8.76 h/an",
"99.99% (4 nines)":"52.6 min/an",
"99.999% (5 nines)":"5.26 min/an",
}
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Barplot downtime en minutes
labels = list(downtimes.keys())
values = list(downtimes.values())
colors = sns.color_palette("muted", len(labels))
bars = axes[0].barh(labels, values, color=colors, edgecolor='white', height=0.6)
axes[0].set_xlabel("Downtime autorisé (minutes/an)", fontsize=10)
axes[0].set_title("Downtime annuel selon la disponibilité", fontsize=11, fontweight='bold')
axes[0].set_xscale('log')
for bar, (label, ds) in zip(bars, downtime_str.items()):
axes[0].text(bar.get_width() * 1.05, bar.get_y() + bar.get_height() / 2,
ds, va='center', ha='left', fontsize=8.5, color='#333333')
# Tableau récapitulatif
table_data = [
["Disponibilité", "Downtime/an", "Downtime/mois", "Budget erreur (SLO)"],
["90%", "876 h", "73 h", "10%"],
["99%", "87.6 h", "7.3 h", "1%"],
["99.9%", "8h 46min", "43.8 min", "0.1%"],
["99.99%", "52 min", "4.4 min", "0.01%"],
["99.999%","5.3 min", "26 sec", "0.001%"],
]
axes[1].axis('off')
table = axes[1].table(
cellText=table_data[1:],
colLabels=table_data[0],
cellLoc='center',
loc='center',
bbox=[0, 0.05, 1, 0.9]
)
table.auto_set_font_size(False)
table.set_fontsize(9)
header_color = '#1168BD'
row_colors = ['#f0f4ff', '#ffffff']
for (row, col), cell in table.get_celld().items():
if row == 0:
cell.set_facecolor(header_color)
cell.set_text_props(color='white', fontweight='bold')
else:
cell.set_facecolor(row_colors[row % 2])
cell.set_edgecolor('#cccccc')
cell.set_linewidth(0.5)
axes[1].set_title("Tableau des nines", fontsize=11, fontweight='bold')
fig.suptitle("Disponibilité — calcul des \"nines\" et impact opérationnel",
fontsize=13, fontweight='bold', y=1.02)
plt.savefig("disponibilite_nines.png", dpi=120, bbox_inches='tight')
plt.show()
Couplage et cohésion — graphe de dépendances#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import networkx as nx
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
def draw_dep_graph(ax, nodes, edges, title, node_colors, metrics=None):
G = nx.DiGraph()
G.add_nodes_from(nodes)
G.add_edges_from(edges)
pos = nx.spring_layout(G, seed=42, k=1.5)
nx.draw_networkx_nodes(G, pos, ax=ax, node_color=node_colors,
node_size=1200, alpha=0.9)
nx.draw_networkx_labels(G, pos, ax=ax, font_size=8,
font_color='white', font_weight='bold')
nx.draw_networkx_edges(G, pos, ax=ax, edge_color='#555555',
width=1.5, alpha=0.7, arrows=True,
arrowsize=15, connectionstyle='arc3,rad=0.1')
if metrics:
for node, (ca, ce) in metrics.items():
i = ce / (ca + ce) if (ca + ce) > 0 else 0
x, y = pos[node]
ax.text(x, y - 0.18, f"I={i:.2f}", ha='center', va='top',
fontsize=7, color='#e07b39', fontweight='bold')
ax.set_title(title, fontsize=11, fontweight='bold', pad=10)
ax.axis('off')
# Cas 1 : couplage fort, cohésion faible (God Object)
nodes1 = ["OrderGod\n(God Object)", "UserMgr", "PaymentAPI", "StockDB", "EmailSvc", "ReportGen"]
edges1 = [
("OrderGod\n(God Object)", "UserMgr"),
("OrderGod\n(God Object)", "PaymentAPI"),
("OrderGod\n(God Object)", "StockDB"),
("OrderGod\n(God Object)", "EmailSvc"),
("OrderGod\n(God Object)", "ReportGen"),
("PaymentAPI", "StockDB"),
("EmailSvc", "UserMgr"),
]
colors1 = ['#c0392b'] + ['#7f8c8d'] * 5
draw_dep_graph(axes[0], nodes1, edges1,
"Couplage fort — God Object\n(instabilité élevée, cohésion faible)",
colors1)
# Cas 2 : couplage faible, cohésion forte (services distincts)
nodes2 = ["OrderSvc", "UserSvc", "PaymentSvc", "InventorySvc", "NotifSvc"]
edges2 = [
("OrderSvc", "PaymentSvc"),
("OrderSvc", "InventorySvc"),
("OrderSvc", "NotifSvc"),
("PaymentSvc", "NotifSvc"),
]
metrics2 = {
"OrderSvc": (0, 3),
"UserSvc": (0, 0),
"PaymentSvc": (1, 1),
"InventorySvc": (1, 0),
"NotifSvc": (2, 0),
}
colors2 = ['#1168BD', '#2d6a4f', '#e07b39', '#6c3483', '#17a589']
draw_dep_graph(axes[1], nodes2, edges2,
"Couplage faible — Services distincts\n(instabilité I = Ce/(Ca+Ce) annotée)",
colors2, metrics=metrics2)
fig.suptitle("Couplage et cohésion — impact sur la maintenabilité",
fontsize=13, fontweight='bold', y=1.02)
plt.savefig("couplage_cohesion.png", dpi=120, bbox_inches='tight')
plt.show()
Distribution de latence et percentiles#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
from scipy import stats
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
# Simulation d'une distribution log-normale de latences (en ms)
# Paramètres réalistes pour une API REST
mu_log = 4.0 # ~ exp(4) = 54ms médiane
sigma_log = 0.8
n_samples = 10000
latencies = np.random.lognormal(mu_log, sigma_log, n_samples)
p50 = np.percentile(latencies, 50)
p95 = np.percentile(latencies, 95)
p99 = np.percentile(latencies, 99)
p999 = np.percentile(latencies, 99.9)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Histogramme avec percentiles annotés
x_max = np.percentile(latencies, 99.5)
bins = np.linspace(0, x_max, 80)
n, bins_out, patches = axes[0].hist(latencies[latencies <= x_max], bins=bins,
color='#1168BD', alpha=0.7, edgecolor='white',
density=True)
percentiles = [(p50, '#2d6a4f', 'p50'), (p95, '#e07b39', 'p95'),
(p99, '#c0392b', 'p99'), (p999, '#6c3483', 'p99.9')]
for p_val, color, label in percentiles:
axes[0].axvline(p_val, color=color, linewidth=2, linestyle='--', alpha=0.9)
axes[0].text(p_val + 5, axes[0].get_ylim()[1] * 0.85, f'{label}\n{p_val:.0f}ms',
color=color, fontsize=8.5, fontweight='bold', va='top')
axes[0].set_xlabel("Latence (ms)", fontsize=10)
axes[0].set_ylabel("Densité", fontsize=10)
axes[0].set_title("Distribution des latences — API catalogue produits\n"
"(distribution log-normale, 10k requêtes simulées)", fontsize=10, fontweight='bold')
# Courbe percentile cumulée
percentile_range = np.arange(1, 100, 0.5)
pct_values = np.percentile(latencies, percentile_range)
axes[1].plot(percentile_range, pct_values, color='#1168BD', linewidth=2)
for p_pct, p_val, color, label in [(50, p50, '#2d6a4f', 'p50'),
(95, p95, '#e07b39', 'p95'),
(99, p99, '#c0392b', 'p99')]:
axes[1].plot(p_pct, p_val, 'o', color=color, markersize=8, zorder=5)
axes[1].annotate(f'{label} = {p_val:.0f}ms',
xy=(p_pct, p_val),
xytext=(p_pct - 20, p_val + 200),
fontsize=8.5, color=color, fontweight='bold',
arrowprops=dict(arrowstyle='->', color=color, lw=1.2))
axes[1].set_xlabel("Percentile (%)", fontsize=10)
axes[1].set_ylabel("Latence (ms)", fontsize=10)
axes[1].set_title("Courbe des percentiles — la queue de distribution\n"
"(les 5% de requêtes lentes comptent autant que les 95%)", fontsize=10, fontweight='bold')
fig.suptitle("Latence et percentiles — pourquoi la moyenne ment",
fontsize=13, fontweight='bold', y=1.02)
plt.savefig("latence_percentiles.png", dpi=120, bbox_inches='tight')
plt.show()
Loi de Little — dimensionnement système#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# --- Courbe 1 : N = lambda * W, fixer W, varier lambda ---
W_values = [0.1, 0.2, 0.5] # temps de séjour en secondes
lambda_range = np.linspace(0, 200, 300) # requêtes/seconde
colors = sns.color_palette("muted", 3)
for W, color in zip(W_values, colors):
N = lambda_range * W
axes[0].plot(lambda_range, N, linewidth=2, color=color, label=f"W = {W}s ({W*1000:.0f}ms)")
axes[0].set_xlabel("Taux d'arrivée λ (requêtes/s)", fontsize=10)
axes[0].set_ylabel("N = concurrence moyenne (requêtes en vol)", fontsize=10)
axes[0].set_title("Loi de Little : N = λ × W\nDimensionnement de la concurrence", fontsize=10, fontweight='bold')
axes[0].legend(fontsize=9, title="Temps de séjour W")
axes[0].fill_between(lambda_range, lambda_range * 0.2, lambda_range * 0.5,
alpha=0.07, color='grey', label='Zone opérationnelle')
axes[0].axvline(100, color='#c0392b', linewidth=1.5, linestyle=':', alpha=0.7)
axes[0].text(102, axes[0].get_ylim()[1] * 0.9, 'SLO\n100 req/s', fontsize=8, color='#c0392b')
# --- Courbe 2 : W vs utilisation ρ (M/M/1 simplifiée) ---
# W = W_service / (1 - ρ) pour une file M/M/1
rho = np.linspace(0.01, 0.99, 300)
W_service = 0.05 # 50ms de temps de service
W_system = W_service / (1 - rho)
axes[1].plot(rho * 100, W_system * 1000, color='#1168BD', linewidth=2.5)
axes[1].axvline(80, color='#e07b39', linewidth=1.5, linestyle='--', alpha=0.8)
axes[1].axvline(95, color='#c0392b', linewidth=1.5, linestyle='--', alpha=0.8)
axes[1].text(81, 600, 'ρ = 80%\n"zone saine"', fontsize=8, color='#e07b39')
axes[1].text(86, 900, 'ρ = 95%\nzone critique', fontsize=8, color='#c0392b')
axes[1].set_xlabel("Utilisation ρ (%)", fontsize=10)
axes[1].set_ylabel("Temps de séjour W (ms)", fontsize=10)
axes[1].set_title(f"File M/M/1 : temps de réponse vs utilisation\n(W_service = {W_service*1000:.0f}ms, saturation exponentielle)", fontsize=10, fontweight='bold')
axes[1].set_ylim(0, 1100)
# Zone de danger
axes[1].fill_between(rho[rho >= 0.90] * 100, W_system[rho >= 0.90] * 1000,
1100, alpha=0.12, color='#c0392b', label='Zone saturation')
axes[1].legend(fontsize=9)
fig.suptitle("Loi de Little — dimensionnement et saturation des systèmes",
fontsize=13, fontweight='bold', y=1.02)
plt.savefig("loi_little.png", dpi=120, bbox_inches='tight')
plt.show()
Résumé#
Les qualités architecturales ne sont pas des cases à cocher — elles sont le résultat de décisions de conception conscientes, mesurables, et en tension permanente.
Disponibilité : exprimée en « nines », mesurée via SLI/SLO/SLA. Chaque nine supplémentaire exige un investissement non linéaire en infrastructure et en processus opérationnels. Le budget d’erreur transforme la disponibilité en ressource partagée.
Scalabilité : horizontale (scale out) et verticale (scale up) ne sont pas équivalentes. L’élasticité est la scalabilité horizontale automatisée. La scalabilité a des limites fondamentales (Amdahl, cohérence distribuée) qu’aucune architecture ne peut abolir.
Maintenabilité : couplage faible et cohésion forte sont les deux principes cardinaux. La complexité cyclomatique, l’instabilité et l’abstractivité sont des métriques actionnables. La dette technique s’accumule silencieusement et doit être activement gérée.
Testabilité : c’est une propriété de l’architecture, pas du code de test. L’injection de dépendances et l’architecture hexagonale sont les mécanismes principaux. La pyramide de tests oriente la distribution optimale des tests.
Sécurité : CIA, surface d’attaque minimale, moindre privilège, défense en profondeur. La sécurité doit être conçue dès le départ (shift-left), pas ajoutée en fin de projet.
Performance : latence ≠ throughput. Les percentiles (p95, p99) sont la bonne unité de mesure. La loi de Little connecte taux d’arrivée, concurrence et latence dans un cadre mathématique rigoureux.
Observabilité : logs + métriques + traces distribuées. La différence avec le monitoring est qualitative — l’observabilité permet de répondre à des questions non anticipées.
Compromis : l’ATAM fournit un cadre pour identifier et formaliser les trade-offs entre attributs. Toute décision architecturale optimise un sous-ensemble de qualités au détriment d’autres.
Points clés à retenir
La disponibilité se mesure en « nines » et s’optimise par le MTTF, le MTTR et la redondance
Scalabilité horizontale + élasticité = cloud-native; elle exige des applications stateless
Couplage faible et cohésion forte sont mesurables (instabilité, complexité cyclomatique)
La latence se mesure en percentiles — la moyenne est une métrique trompeuse
L’observabilité (logs + métriques + traces) est différente qualitativement du monitoring
Tout compromis entre attributs de qualité doit être documenté explicitement dans les ADR