19. Performance et caching#
La performance est une fonctionnalité. Un système correct mais lent est un système qui perd des utilisateurs et de l’argent. Mais la performance ne s’améliore pas au hasard — elle se mesure, se localise, et se corrige avec des techniques ciblées. Le caching est l’outil le plus puissant du répertoire, et aussi le plus risqué si mal utilisé.
Niveaux de cache#
Les caches existent à tous les niveaux de la hiérarchie matérielle et logicielle. Comprendre leurs caractéristiques permet de choisir le bon niveau d’intervention.
Hiérarchie matérielle#
L1 cache (par cœur CPU) : 32-64 KB, latence ~1 ns. Géré automatiquement par le processeur, invisible au développeur.
L2 cache (par cœur ou partagé) : 256 KB - 1 MB, latence ~5 ns.
L3 cache (partagé entre cœurs) : 4-64 MB, latence ~30 ns.
RAM : quelques GB à TB, latence ~100 ns (accès aléatoire).
SSD NVMe : latence ~100 µs (100 000 ns).
HDD : latence ~10 ms (10 000 000 ns).
Réseau local : latence ~100 µs à 1 ms.
CDN edge : latence variable, 1-50 ms selon la géographie.
Localité des données#
Les CPU exploitent la localité temporelle (une donnée récemment accédée le sera probablement à nouveau) et la localité spatiale (les données voisines en mémoire sont probablement accédées ensemble). Écrire du code cache-friendly — parcourir des tableaux en ordre, éviter les listes chaînées — peut multiplier les performances par 10.
Les ordres de grandeur à retenir
La RAM est ~100× plus lente que le cache L1. Le SSD est ~1000× plus lent que la RAM. Le réseau est ~10 000× plus lent que la RAM. Ces ratios justifient l’effort architectural d’éviter les accès aux niveaux bas.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Latences typiques (nanosecondes)
cache_levels = {
'L1 cache\n(32 KB)': 1,
'L2 cache\n(256 KB)': 5,
'L3 cache\n(8 MB)': 30,
'RAM\n(32 GB)': 100,
'SSD NVMe\n(local)': 100_000,
'HDD\n(local)': 10_000_000,
'Réseau LAN\n(1 Gbit)': 200_000,
'CDN\n(edge)': 5_000_000,
}
names = list(cache_levels.keys())
latencies_ns = list(cache_levels.values())
latencies_us = [v / 1000 for v in latencies_ns]
colors = sns.color_palette("muted", len(names))
fig, ax = plt.subplots(figsize=(12, 7))
bars = ax.barh(names, latencies_ns, color=colors, edgecolor='white', linewidth=1.2)
ax.set_xscale('log')
ax.set_xlabel("Latence (nanosecondes) — échelle logarithmique")
ax.set_title("Hiérarchie des caches : latences typiques\n(chaque graduation = ×10)", fontsize=13)
for bar, val in zip(bars, latencies_ns):
if val < 1000:
label = f"{val} ns"
elif val < 1_000_000:
label = f"{val/1000:.0f} µs"
else:
label = f"{val/1_000_000:.0f} ms"
ax.text(bar.get_width() * 1.5, bar.get_y() + bar.get_height()/2,
label, va='center', fontsize=9, fontweight='bold')
ax.set_xlim(0.5, latencies_ns[-1] * 20)
plt.savefig("cache_hierarchy.png", dpi=100, bbox_inches='tight')
plt.show()
# Ratio par rapport au L1
print("Ratios de latence par rapport au L1 :")
l1 = latencies_ns[0]
for name, lat in cache_levels.items():
print(f" {name.replace(chr(10), ' '):<25} : {lat/l1:>10.0f}× plus lent que L1")
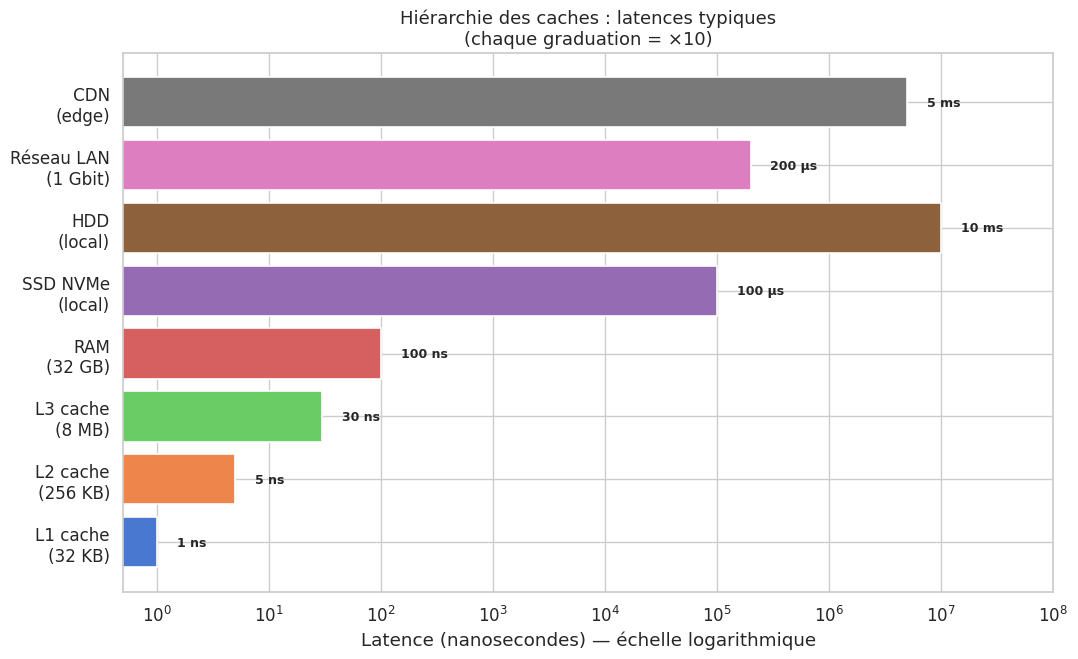
Ratios de latence par rapport au L1 :
L1 cache (32 KB) : 1× plus lent que L1
L2 cache (256 KB) : 5× plus lent que L1
L3 cache (8 MB) : 30× plus lent que L1
RAM (32 GB) : 100× plus lent que L1
SSD NVMe (local) : 100000× plus lent que L1
HDD (local) : 10000000× plus lent que L1
Réseau LAN (1 Gbit) : 200000× plus lent que L1
CDN (edge) : 5000000× plus lent que L1
Stratégies de cache#
Cache-aside (Lazy Loading)#
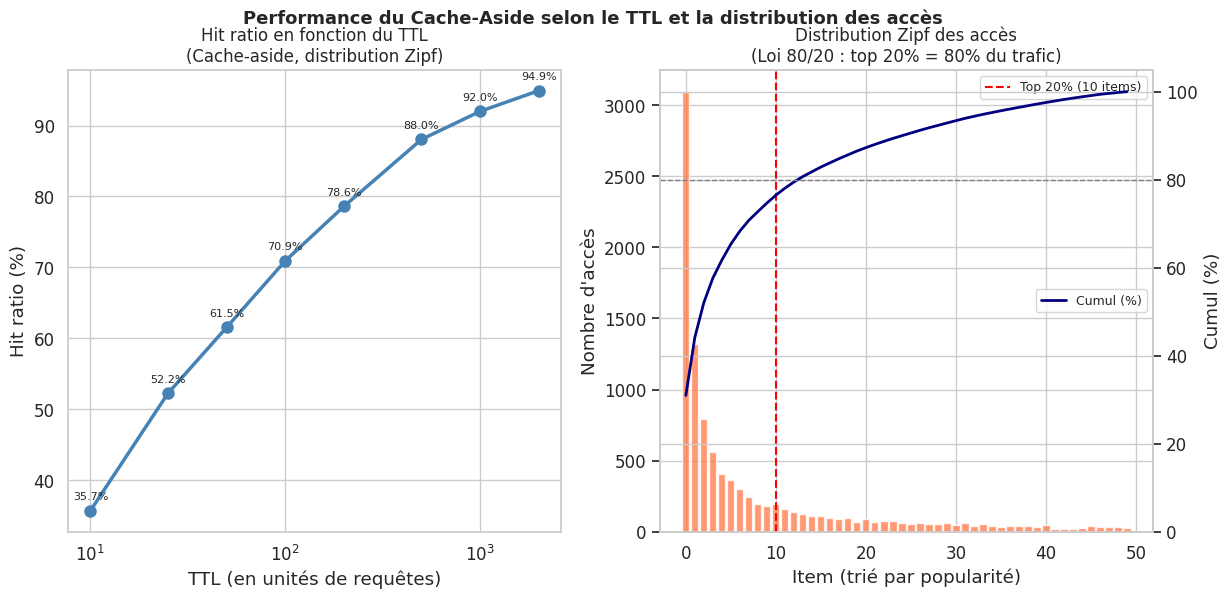
L’application est responsable de la gestion du cache. Lors d’une lecture : chercher dans le cache, en cas de miss charger depuis la DB et peupler le cache, retourner la donnée. Lors d’une écriture : écrire en DB, invalider ou mettre à jour le cache.
Avantage : le cache ne contient que les données réellement demandées. Inconvénient : la première requête après un miss subit la latence complète.
Read-through#
Le cache intercepte les lectures et charge depuis la DB en cas de miss, de manière transparente pour l’application. L’application ne parle qu’au cache. Simplifie le code applicatif, mais le cache devient un point de défaillance.
Write-through#
Toute écriture passe par le cache, qui écrit synchroniquement en DB. Le cache est toujours cohérent avec la DB. Inconvénient : la latence d’écriture est celle de la DB, pas du cache.
Write-behind (Write-back)#
L’écriture est faite dans le cache uniquement, qui écrit en DB de manière asynchrone par batch. Latences d’écriture très faibles, mais risque de perte de données si le cache tombe avant la synchronisation.
Choisir la bonne stratégie
Cache-aside est le choix par défaut : simple, explicite, pas de couplage fort au cache. Write-through pour les données critiques où la cohérence est non négociable. Write-behind uniquement si les performances d’écriture sont critiques et la perte de quelques écritures acceptable.
Invalidation#
Phil Karlton : « There are only two hard things in Computer Science: cache invalidation and naming things. »
L’invalidation est effectivement l’un des problèmes les plus difficiles du cache. Trois approches principales :
TTL (Time-To-Live) : chaque entrée expire après une durée fixe. Simple à implémenter, mais brutal : une entrée peut expirer alors qu’elle est toujours valide, ou rester en cache alors qu’elle est périmée.
Event-based invalidation : quand une donnée est modifiée en DB, un événement est émis, et les entrées de cache correspondantes sont invalidées. Plus précis, mais requiert une infrastructure d’événements et une logique de mapping données → clés de cache.
Cache tags : chaque entrée de cache est taguée avec les entités qu’elle contient. Quand une entité est modifiée, toutes les entrées portant son tag sont invalidées. Utilisé par les CDN comme Fastly et Varnish.
Cache distribué#
Redis vs Memcached#
Redis : structures de données riches (strings, lists, sets, sorted sets, hashes), persistence optionnelle, pub/sub, scripting Lua, clustering natif. Choix par défaut pour les nouveaux projets.
Memcached : plus simple, multi-threaded natif sur un seul nœud, meilleur raw throughput sur les workloads purement key-value avec de gros objets. Moins de fonctionnalités.
Partitionnement et consistance#
Un cluster Redis en mode cluster shard les données sur plusieurs nœuds avec consistent hashing. La consistance est éventuelle lors des réélections de maître. Pour les cas nécessitant une forte consistance, Redis Cluster n’est pas approprié.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
def simulate_cache_aside(n_requests, ttl_steps, n_unique_items=100):
"""
Simule un cache-aside avec TTL variable.
Retourne le hit ratio et l'âge moyen des entrées au moment du hit.
"""
cache = {} # {item_id: (valeur, timestamp)}
hits = 0
misses = 0
# Distribution Zipf pour simuler l'accès réel (80/20)
zipf_weights = 1 / (np.arange(1, n_unique_items + 1) ** 1.2)
zipf_weights /= zipf_weights.sum()
for t in range(n_requests):
item_id = np.random.choice(n_unique_items, p=zipf_weights)
if item_id in cache:
_, cached_at = cache[item_id]
if t - cached_at < ttl_steps:
hits += 1
continue # hit
else:
del cache[item_id]
# Miss : charger depuis DB et mettre en cache
misses += 1
cache[item_id] = (f"data_{item_id}", t)
return hits / n_requests
# Test avec différents TTL
n_requests = 5000
ttls = [10, 25, 50, 100, 200, 500, 1000, 2000]
hit_ratios = [simulate_cache_aside(n_requests, ttl) for ttl in ttls]
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Courbe hit ratio vs TTL
ax1 = axes[0]
ax1.plot(ttls, [r * 100 for r in hit_ratios], 'o-', color='steelblue',
linewidth=2.5, markersize=8)
ax1.set_xlabel("TTL (en unités de requêtes)")
ax1.set_ylabel("Hit ratio (%)")
ax1.set_title("Hit ratio en fonction du TTL\n(Cache-aside, distribution Zipf)", fontsize=12)
ax1.set_xscale('log')
for ttl, ratio in zip(ttls, hit_ratios):
ax1.annotate(f"{ratio*100:.1f}%", xy=(ttl, ratio*100),
xytext=(0, 8), textcoords='offset points',
ha='center', fontsize=8)
# Distribution des accès (Zipf)
ax2 = axes[1]
n_unique = 50
zipf_weights = 1 / (np.arange(1, n_unique + 1) ** 1.2)
zipf_weights /= zipf_weights.sum()
sample = np.random.choice(n_unique, size=10000, p=zipf_weights)
counts = np.bincount(sample, minlength=n_unique)
bars = ax2.bar(range(n_unique), counts, color='coral', alpha=0.8, edgecolor='white')
cumul = np.cumsum(np.sort(counts)[::-1])
ax2_twin = ax2.twinx()
ax2_twin.plot(range(n_unique), cumul / cumul[-1] * 100, color='navy',
linewidth=2, label='Cumul (%)')
ax2_twin.set_ylabel("Cumul (%)")
ax2_twin.axhline(80, color='gray', linestyle='--', linewidth=1)
ax2_twin.set_ylim(0, 105)
ax2.set_xlabel("Item (trié par popularité)")
ax2.set_ylabel("Nombre d'accès")
ax2.set_title("Distribution Zipf des accès\n(Loi 80/20 : top 20% = 80% du trafic)", fontsize=12)
ax2_twin.legend(loc='center right', fontsize=9)
# Annoter 80/20
top_20_pct = int(n_unique * 0.2)
ax2.axvline(top_20_pct, color='red', linestyle='--', linewidth=1.5,
label=f'Top 20% ({top_20_pct} items)')
ax2.legend(fontsize=9)
plt.suptitle("Performance du Cache-Aside selon le TTL et la distribution des accès",
fontsize=13, fontweight='bold')
plt.savefig("cache_aside.png", dpi=100, bbox_inches='tight')
plt.show()
CDN#
Un CDN (Content Delivery Network) est un réseau de caches distribués géographiquement. Les requêtes sont routées vers le nœud le plus proche de l’utilisateur, réduisant la latence et déchargeant l’origine.
Cache-Control headers#
Le navigateur et les CDN respectent les directives HTTP Cache-Control :
max-age=3600: mettre en cache pendant 1 heure.s-maxage=86400: durée spécifique pour les caches partagés (CDN), différente demax-age.no-cache: toujours revalider avec l’origine avant de servir.no-store: ne jamais mettre en cache (données sensibles).stale-while-revalidate=60: servir depuis le cache (même expiré) pendant 60s pendant la revalidation.
Stratégies par type de contenu#
Assets statiques versionnés (main.a3f2b.js) : max-age=31536000, immutable. Ces fichiers ne changent jamais — si le contenu change, l’URL change.
Pages HTML : no-cache ou max-age=0 — toujours revalider, les pages changent souvent.
API JSON : selon la sensibilité et la fraîcheur requise, de no-store à max-age=60.
Images : max-age=86400 à max-age=2592000 selon la fréquence de mise à jour.
Optimisation de base de données#
Le problème N+1#
Le problème N+1 est l’une des causes les plus fréquentes de mauvaise performance dans les applications avec ORM. Pour afficher une liste de 100 articles avec leurs auteurs :
Une requête pour charger les 100 articles.
Pour chaque article : une requête pour charger l’auteur → 100 requêtes supplémentaires.
Total : 101 requêtes au lieu de 1. L”eager loading (JOIN ou SELECT IN) résout le problème en une ou deux requêtes.
Index et query plan#
Un index mal choisi (ou absent) force un sequential scan sur toute la table. Sur 10 millions de lignes, la différence entre un index scan et un sequential scan est de l’ordre de 1000×.
Commande indispensable : EXPLAIN ANALYZE (PostgreSQL) ou EXPLAIN (MySQL) pour voir ce que fait réellement la base de données.
Connection pooling
Établir une connexion à PostgreSQL coûte ~3-10 ms. Avec 1000 requêtes/seconde, cela représente 3-10 secondes de travail pur en établissement de connexions. PgBouncer ou HikariCP maintiennent un pool de connexions réutilisables, divisant ce coût par 100.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(10)
def simulate_n_plus_1(n_items, db_latency_ms=2, network_overhead_ms=0.5):
"""Simule le problème N+1 vs eager loading."""
# N+1 : 1 requête pour les items + N requêtes pour les relations
n_queries_naive = 1 + n_items
time_naive = n_queries_naive * (db_latency_ms + network_overhead_ms)
# Eager loading : 2 requêtes (items + toutes les relations en une fois)
n_queries_eager = 2
time_eager = n_queries_eager * (db_latency_ms + network_overhead_ms) + n_items * 0.01 # parsing
return n_queries_naive, time_naive, n_queries_eager, time_eager
item_counts = [10, 50, 100, 250, 500, 1000]
results = [simulate_n_plus_1(n) for n in item_counts]
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
colors = sns.color_palette("muted", 2)
ax1 = axes[0]
naive_queries = [r[0] for r in results]
eager_queries = [r[2] for r in results]
x = np.arange(len(item_counts))
width = 0.35
ax1.bar(x - width/2, naive_queries, width, label='N+1 (naïf)', color=colors[0],
edgecolor='white', linewidth=1.2)
ax1.bar(x + width/2, eager_queries, width, label='Eager loading', color=colors[1],
edgecolor='white', linewidth=1.2)
ax1.set_xticks(x)
ax1.set_xticklabels([str(n) for n in item_counts])
ax1.set_xlabel("Nombre d'items chargés")
ax1.set_ylabel("Nombre de requêtes SQL")
ax1.set_title("Problème N+1 vs Eager Loading\nNombre de requêtes", fontsize=12)
ax1.legend(fontsize=10)
ax1.set_yscale('log')
ax2 = axes[1]
naive_times = [r[1] for r in results]
eager_times = [r[3] for r in results]
ax2.plot(item_counts, naive_times, 'o-', color=colors[0], linewidth=2.5,
markersize=8, label='N+1 (naïf)')
ax2.plot(item_counts, eager_times, 's-', color=colors[1], linewidth=2.5,
markersize=8, label='Eager loading')
ax2.set_xlabel("Nombre d'items chargés")
ax2.set_ylabel("Temps de réponse (ms)")
ax2.set_title("Problème N+1 vs Eager Loading\nTemps de réponse", fontsize=12)
ax2.legend(fontsize=10)
# Annoter le ratio à 1000 items
ratio = naive_times[-1] / eager_times[-1]
ax2.annotate(f'Ratio : {ratio:.0f}×\nplus lent', xy=(1000, naive_times[-1]),
xytext=(700, naive_times[-1] * 0.7),
fontsize=9, color='red',
arrowprops=dict(arrowstyle='->', color='red'))
plt.suptitle("Impact du problème N+1 sur les performances\n(latence DB = 2ms/requête)",
fontsize=13, fontweight='bold')
plt.savefig("n_plus_1.png", dpi=100, bbox_inches='tight')
plt.show()
for n, r in zip(item_counts, results):
print(f"N={n:4d} items : N+1={r[0]:4d} req / {r[1]:7.1f}ms | Eager={r[2]} req / {r[3]:5.1f}ms | Ratio={r[1]/r[3]:.0f}×")
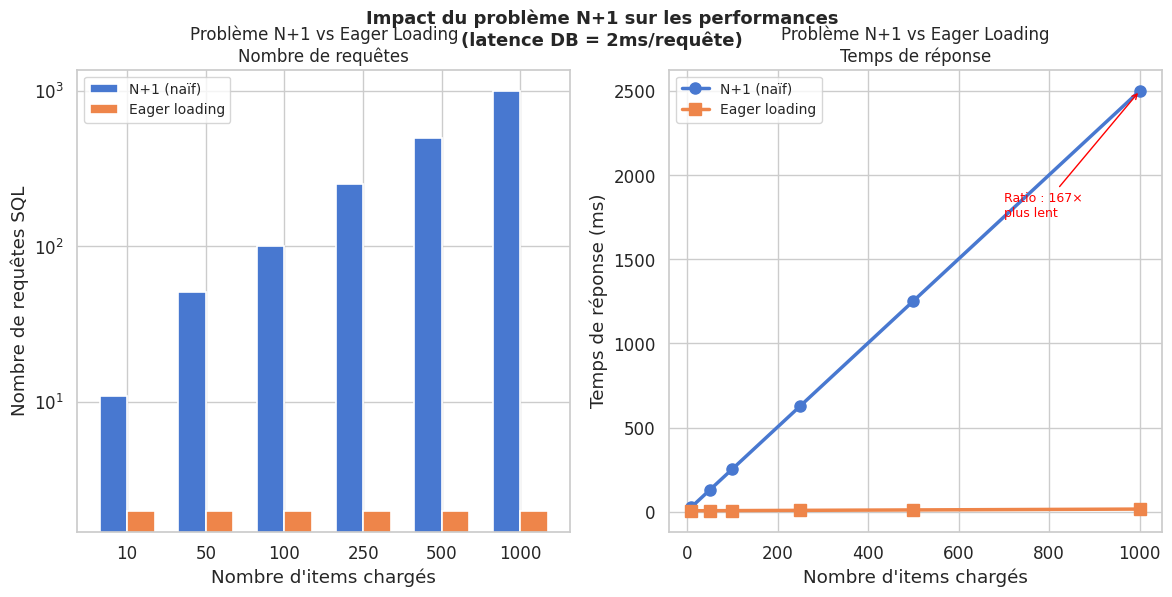
N= 10 items : N+1= 11 req / 27.5ms | Eager=2 req / 5.1ms | Ratio=5×
N= 50 items : N+1= 51 req / 127.5ms | Eager=2 req / 5.5ms | Ratio=23×
N= 100 items : N+1= 101 req / 252.5ms | Eager=2 req / 6.0ms | Ratio=42×
N= 250 items : N+1= 251 req / 627.5ms | Eager=2 req / 7.5ms | Ratio=84×
N= 500 items : N+1= 501 req / 1252.5ms | Eager=2 req / 10.0ms | Ratio=125×
N=1000 items : N+1=1001 req / 2502.5ms | Eager=2 req / 15.0ms | Ratio=167×
Profiling et mesure#
« Measure, don’t guess »#
L’optimisation prématurée est la source de tous les maux (Knuth). Mais la contre-mesure n’est pas l’absence d’optimisation — c’est la mesure avant d’optimiser. Profiler le code pour trouver les vrais goulots d’étranglement, qui sont presque toujours dans des endroits inattendus.
Flamegraphs#
Un flamegraph visualise l’arbre d’appels du programme avec la largeur proportionnelle au temps CPU passé. Les plateaux larges en haut de la flamme sont les cibles d’optimisation.
APM (Application Performance Monitoring)#
Les solutions APM (Datadog, New Relic, Dynatrace, Elastic APM) instrumentent automatiquement les frameworks et capturent les traces distribuées, les requêtes SQL lentes, les exceptions. Elles permettent de passer de « le service est lent » à « la requête SQL sur la table orders sans index prend 4 secondes ».
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(5)
# Modélisation hit ratio vs taille de cache (Loi de Zipf)
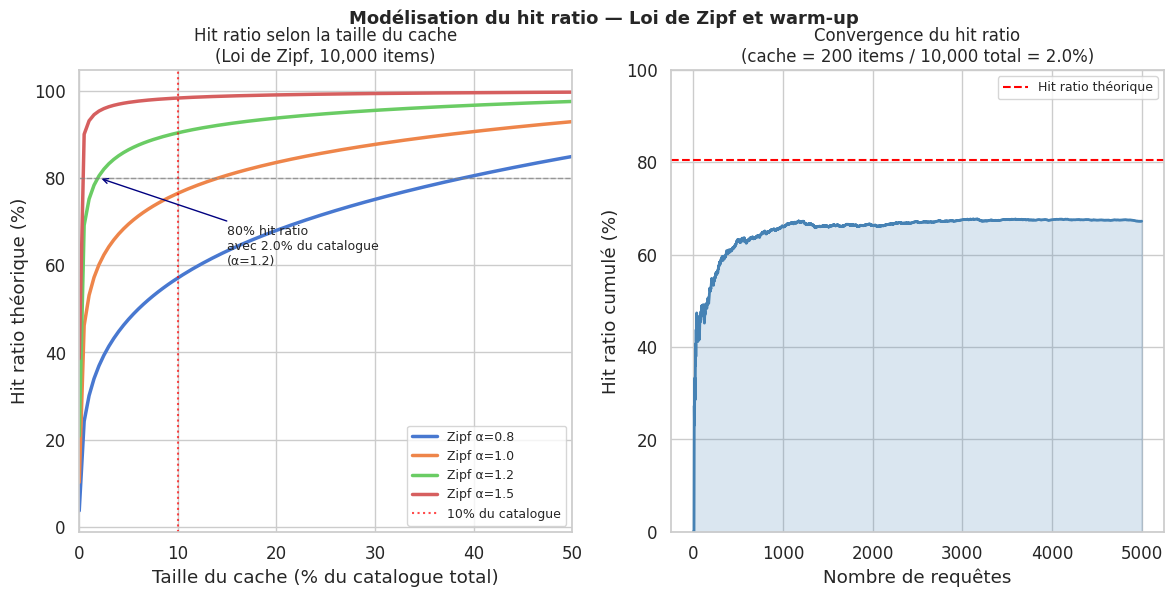
def hit_ratio_zipf(cache_size, n_items, n_requests=10000, alpha=1.2):
"""Calcule le hit ratio pour une taille de cache donnée avec accès Zipf."""
zipf_weights = 1 / (np.arange(1, n_items + 1) ** alpha)
zipf_weights /= zipf_weights.sum()
# Les cache_size items les plus populaires couvrent hit_ratio du trafic
top_k_coverage = zipf_weights[:cache_size].sum()
return top_k_coverage
n_items = 10000
cache_sizes = np.arange(1, n_items + 1, 50)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
ax1 = axes[0]
colors_alpha = sns.color_palette("muted", 4)
for alpha, color in zip([0.8, 1.0, 1.2, 1.5], colors_alpha):
ratios = [hit_ratio_zipf(cs, n_items, alpha=alpha) for cs in cache_sizes]
ax1.plot(cache_sizes / n_items * 100, [r * 100 for r in ratios],
linewidth=2.5, label=f'Zipf α={alpha}', color=color)
ax1.axhline(80, color='gray', linestyle='--', linewidth=1, alpha=0.7)
ax1.axvline(10, color='red', linestyle=':', linewidth=1.5, alpha=0.7, label='10% du catalogue')
ax1.set_xlabel("Taille du cache (% du catalogue total)")
ax1.set_ylabel("Hit ratio théorique (%)")
ax1.set_title(f"Hit ratio selon la taille du cache\n(Loi de Zipf, {n_items:,} items)", fontsize=12)
ax1.legend(fontsize=9)
ax1.set_xlim(0, 50)
# Pour α=1.2, montrer le "knee" de la courbe
alpha_demo = 1.2
ratios_demo = [hit_ratio_zipf(cs, n_items, alpha=alpha_demo) for cs in cache_sizes]
knee_idx = next(i for i, r in enumerate(ratios_demo) if r >= 0.80)
ax1.annotate(f'80% hit ratio\navec {cache_sizes[knee_idx]/n_items*100:.1f}% du catalogue\n(α=1.2)',
xy=(cache_sizes[knee_idx]/n_items*100, 80),
xytext=(15, 60), fontsize=9,
arrowprops=dict(arrowstyle='->', color='navy'))
# Simulation temporelle hit ratio avec warm-up
ax2 = axes[1]
n_req = 5000
cache_capacity = 200 # 2% du catalogue
cache = {}
hit_rates_rolling = []
window_size = 100
hits_total = 0
for req_idx in range(1, n_req + 1):
zipf_w = 1 / (np.arange(1, n_items + 1) ** 1.2)
zipf_w /= zipf_w.sum()
item = np.random.choice(n_items, p=zipf_w)
if item in cache:
hits_total += 1
else:
if len(cache) >= cache_capacity:
# LRU simplifié : retirer un élément aléatoire (approximation)
remove = next(iter(cache))
del cache[remove]
cache[item] = req_idx
if req_idx >= window_size:
# Recalcul sur fenêtre glissante
pass
hit_rates_rolling.append(hits_total / req_idx)
ax2.plot(range(1, n_req + 1), [r * 100 for r in hit_rates_rolling],
color='steelblue', linewidth=2)
ax2.axhline(ratios_demo[next(i for i, cs in enumerate(cache_sizes) if cs >= cache_capacity)] * 100,
color='red', linestyle='--', linewidth=1.5, label='Hit ratio théorique')
ax2.fill_between(range(1, n_req + 1), [r * 100 for r in hit_rates_rolling], alpha=0.2, color='steelblue')
ax2.set_xlabel("Nombre de requêtes")
ax2.set_ylabel("Hit ratio cumulé (%)")
ax2.set_title(f"Convergence du hit ratio\n(cache = {cache_capacity} items / {n_items:,} total = {cache_capacity/n_items*100:.1f}%)", fontsize=12)
ax2.legend(fontsize=9)
ax2.set_ylim(0, 100)
plt.suptitle("Modélisation du hit ratio — Loi de Zipf et warm-up", fontsize=13, fontweight='bold')
plt.savefig("hit_ratio_zipf.png", dpi=100, bbox_inches='tight')
plt.show()
Résumé#
La performance est un travail de hiérarchisation : identifier le vrai goulot d’étranglement avant d’agir.
Technique |
Gain potentiel |
Risque |
|---|---|---|
Cache-aside + TTL |
10-100× sur les lectures répétées |
Staleness, invalidation incomplète |
CDN pour assets statiques |
Latence réseau ÷ 10-50 |
Gestion des purges |
Correction N+1 |
100-1000× sur les requêtes DB |
Refactoring ORM |
Connection pooling |
Latence d’établissement ÷ 100 |
Épuisement du pool |
Index manquant |
Requête ÷ 1000× |
Surcoût en écriture |
Write-behind cache |
Latence écriture ÷ 10-50 |
Risque de perte de données |
Règles pratiques :
Mesurer d’abord : profiler avant d’optimiser. Les goulots sont rarement là où on les attend.
Le problème N+1 est la première chose à corriger dans toute application avec ORM.
Cache-aside avec distribution Zipf : mettre en cache 10% des items les plus populaires couvre souvent 80% du trafic.
Les TTL trop courts neutralisent le bénéfice du cache. Les TTL trop longs créent de la staleness.
Un index manquant sur une colonne filtrée ou jointe sur une grande table est toujours une priorité.