08 — Microservices#
Définition et principes#
Le terme « microservices » a été popularisé par James Lewis et Martin Fowler dans un article de 2014. Il décrit une approche de développement logiciel où une application est structurée comme un ensemble de petits services, chacun :
Responsable d’une seule capacité métier (Single Responsibility Principle à l’échelle service)
Déployable indépendamment des autres services
Propriété d’une seule équipe, de la conception au déploiement en production
Communiquant via des interfaces légères (généralement HTTP/REST ou messages asynchrones)
Ayant sa propre base de données (ou son propre espace de données isolé)
Ces caractéristiques ne sont pas des règles universellement respectées — elles constituent un idéal vers lequel les architectures microservices tendent.
Ce que les microservices ne sont pas#
Ce n’est pas une question de taille : « micro » est trompeur. Un microservice n’est pas défini par le nombre de lignes de code. Il est défini par la délimitation de sa responsabilité.
Ce n’est pas un monolithe distribué : si tous vos services partagent la même base de données ou ne peuvent pas être déployés indépendamment, vous avez un monolithe distribué — le pire des deux mondes.
Ce n’est pas la solution par défaut : les microservices sont une réponse à des problèmes de scale organisationnel et technique. Ils introduisent une complexité distribuée réelle qu’il faut être prêt à gérer.
Décomposition par domaine#
La question la plus posée en pratique est : « Comment décider de la taille d’un microservice ? »
La réponse la plus rigoureuse vient du Domain-Driven Design (DDD) : le Bounded Context est la frontière naturelle d’un microservice.
Un Bounded Context est un périmètre au sein duquel un modèle de domaine est cohérent et non ambigu. Dans un système e-commerce, « Commande » n’a pas le même sens dans le contexte des ventes (statut, articles, client) que dans le contexte de la logistique (colis, adresse de livraison, transporteur) ou de la comptabilité (ligne de facture, TVA).
La règle de Sam Newman#
Sam Newman, auteur de Building Microservices, propose une heuristique simple : un microservice doit pouvoir être entièrement réécrit en deux semaines par une petite équipe. Ce n’est pas une règle absolue mais un garde-fou contre les services trop grands.
Anti-patterns de décomposition#
Mauvaise décomposition (par couche technique) :
- service-base-de-données
- service-logique-métier
- service-interface-utilisateur
→ Tout changement fonctionnel touche trois services → déploiement coordonné → monolithe distribué
Bonne décomposition (par capacité métier) :
- service-commandes
- service-inventaire
- service-paiements
- service-notifications
→ Une feature de notification n'impacte que service-notifications → déploiement indépendant
Commencez large, découpez ensuite
Il est plus facile de découper un service trop grand en deux que de fusionner deux services trop petits. Si vous n’êtes pas certain des frontières, commencez avec des services plus grands (macro-services) et découpez quand vous observez des frictions réelles : conflits de déploiement, dépendances excessives entre équipes.
Communication synchrone#
REST et HTTP#
La communication synchrone la plus courante entre microservices est REST sur HTTP. Un service A fait une requête HTTP vers le service B et attend la réponse.
# Communication synchrone entre service commandes et service inventaire
import httpx # Client HTTP asynchrone recommandé
class InventoryClient:
"""Client HTTP pour le service inventaire."""
def __init__(self, base_url: str):
self.base_url = base_url
async def check_availability(self, product_id: str, quantity: int) -> bool:
async with httpx.AsyncClient() as client:
try:
response = await client.get(
f"{self.base_url}/products/{product_id}/availability",
params={"quantity": quantity},
timeout=2.0 # Timeout impératif — le service peut être lent ou tombé
)
response.raise_for_status()
return response.json()["available"]
except httpx.TimeoutException:
# Décision : fallback pessimiste ou optimiste ?
raise ServiceUnavailableError("Inventaire inaccessible")
except httpx.HTTPStatusError as e:
if e.response.status_code == 404:
return False # Produit inexistant
raise
gRPC#
Pour les communications internes à haute performance, gRPC (Google Remote Procedure Call) est une alternative sérieuse. Il utilise Protocol Buffers pour la sérialisation (binaire, ~3-10x plus compact que JSON) et HTTP/2 pour le transport (multiplexage, streaming bidirectionnel).
// inventory.proto — contrat formel du service
syntax = "proto3";
service InventoryService {
rpc CheckAvailability (AvailabilityRequest) returns (AvailabilityResponse);
rpc WatchStock (ProductId) returns (stream StockUpdate); // Streaming serveur
}
message AvailabilityRequest {
string product_id = 1;
int32 quantity = 2;
}
message AvailabilityResponse {
bool available = 1;
int32 stock_remaining = 2;
}
Service discovery et load balancing côté client#
Dans un environnement de microservices dynamique (Kubernetes, ECS), les services ne sont pas à des adresses IP fixes. Le service discovery permet à un service de localiser les instances disponibles d’un autre service.
Discovery côté serveur : un load balancer (nginx, HAProxy, AWS ALB) résout le nom vers une instance. Le client appelle simplement
http://inventory-service/.Discovery côté client : le client interroge un registre de services (Consul, Eureka, DNS Kubernetes) et choisit lui-même l’instance à appeler (Ribbon dans Netflix OSS).
Communication asynchrone#
Pour les cas d’usage où l’appelant n’a pas besoin d’une réponse immédiate, la communication asynchrone via message broker offre un découplage bien plus fort.
Patterns pub/sub#
# Pattern Publisher — service commandes publie un événement
class OrderService:
def __init__(self, event_bus):
self.event_bus = event_bus
def place_order(self, command):
order = self._create_order(command)
# Publier l'événement — le service commandes ne sait pas qui s'y intéresse
self.event_bus.publish("orders.placed", {
"order_id": order.id,
"customer_id": order.customer_id,
"items": [{"product_id": i.product_id, "qty": i.quantity}
for i in order.items],
"total": order.total,
"timestamp": order.created_at.isoformat(),
})
return order
# Pattern Subscriber — service notifications s'abonne à l'événement
class NotificationConsumer:
def handle_order_placed(self, event: dict) -> None:
customer_id = event["customer_id"]
order_id = event["order_id"]
total = event["total"]
self._send_email(customer_id, f"Commande {order_id} confirmée — Total : {total}€")
# Pattern Subscriber — service inventaire s'abonne au même événement
class InventoryConsumer:
def handle_order_placed(self, event: dict) -> None:
for item in event["items"]:
self._decrement_stock(item["product_id"], item["qty"])
At-least-once delivery#
Les message brokers garantissent généralement une livraison at-least-once : un message sera livré au moins une fois, mais potentiellement plusieurs fois en cas de retry. Les consommateurs doivent être idempotents — traiter le même message deux fois ne doit pas avoir d’effet supplémentaire.
class InventoryConsumer:
def handle_order_placed(self, event: dict) -> None:
order_id = event["order_id"]
# Vérifier si cet événement a déjà été traité (idempotence)
if self._already_processed(order_id):
return # Ignorer le doublon silencieusement
for item in event["items"]:
self._decrement_stock(item["product_id"], item["qty"])
self._mark_as_processed(order_id)
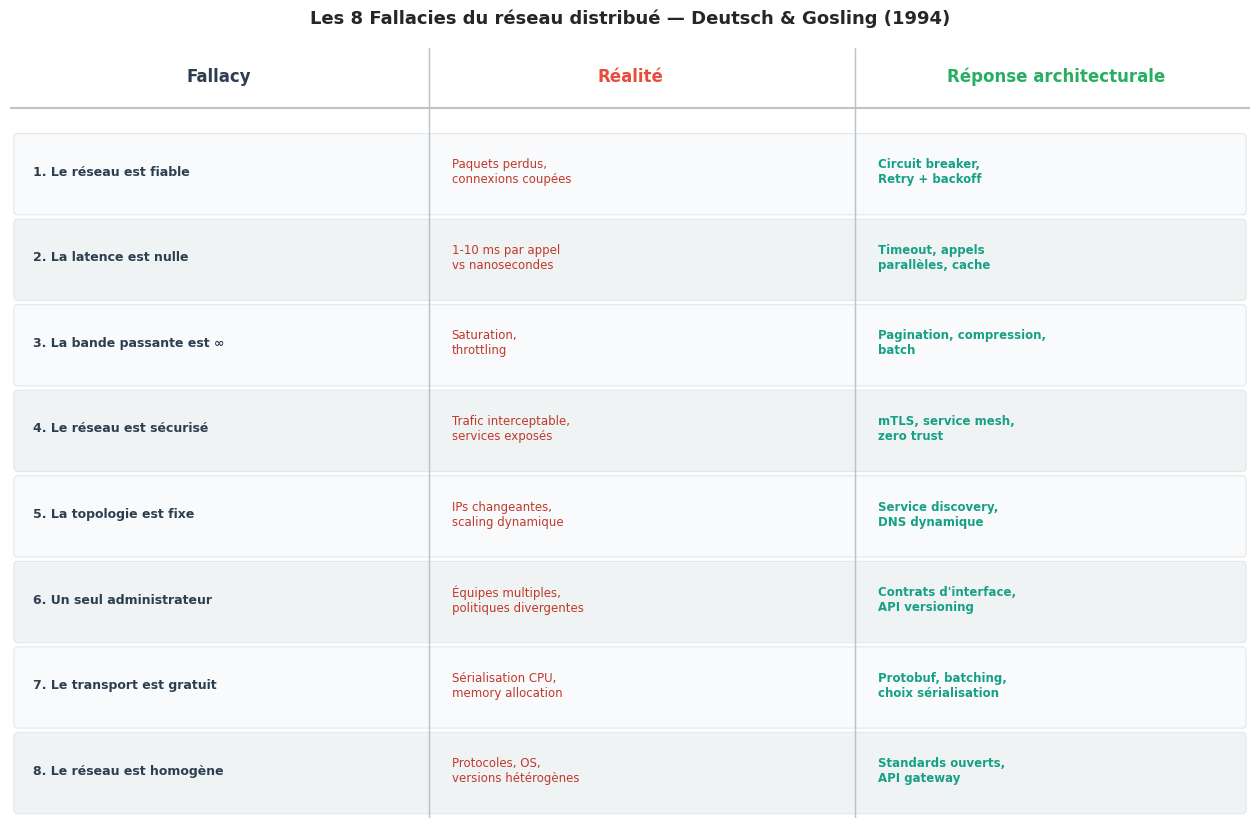
Les 8 fallacies du réseau distribué#
En 1994, Peter Deutsch (puis James Gosling) a formulé les 8 fallacies du réseau distribué — huit suppositions fausses que les développeurs font inconsciemment quand ils passent d’une architecture monolithique à une architecture distribuée.
# |
Fallacy |
Réalité |
Conséquence si ignorée |
|---|---|---|---|
1 |
Le réseau est fiable |
Paquets perdus, connexions coupées |
Services qui ne répondent pas, timeouts silencieux |
2 |
La latence est nulle |
Appels réseau ≈ 1-10 ms (vs ns en mémoire) |
Dégradation des performances imprévue |
3 |
La bande passante est infinie |
Limite réelle, saturation possible |
Backlogs, throttling |
4 |
Le réseau est sécurisé |
Trafic interceptable, services exposés |
Failles de sécurité |
5 |
La topologie ne change pas |
Services redéployés, IPs changent |
Routing cassé si addresses hardcodées |
6 |
Il n’y a qu’un seul administrateur |
Équipes multiples, politiques divergentes |
Configurations incompatibles |
7 |
Le coût de transport est nul |
Sérialisation/désérialisation coûtent cher |
CPU gaspillé sur le marshaling |
8 |
Le réseau est homogène |
Protocoles, versions, OS hétérogènes |
Problèmes d’interopérabilité |
Ces fallacies sont des pièges de conception
Chaque fallacy se traduit en exigence concrète : retry avec backoff exponentiel, circuit breaker, timeouts sur tous les appels, TLS mutuel pour l’authentification inter-services, service discovery dynamique, tracing distribué. Concevoir des microservices sans ces mécanismes revient à construire sur des fondations fragiles.
Challenges opérationnels#
Déploiement indépendant et versioning d’API#
L’un des principaux avantages des microservices est le déploiement indépendant. Mais cela exige de gérer les versions d’API entre services.
Stratégies :
Versioning dans l’URL :
/v1/orders,/v2/orders— simple mais prolifère vite.Versioning dans les headers :
Accept: application/vnd.api+json;version=2— plus propre mais moins visible.Consumer-Driven Contract Testing (Pact) : les consommateurs définissent leurs attentes, les producteurs les valident. Permet de déployer en confiance sans tests d’intégration massifs.
La règle d’or : backward compatibility. Un service doit accepter les requêtes des anciennes versions de ses clients pendant une période de transition.
Distributed tracing et observabilité#
Dans un monolithe, une stack trace suffit pour diagnostiquer un bug. Dans les microservices, une requête utilisateur peut traverser 10 services. Le distributed tracing permet de suivre une requête de bout en bout.
# Propagation du contexte de tracing (OpenTelemetry)
from opentelemetry import trace
from opentelemetry.propagate import inject, extract
tracer = trace.get_tracer("orders-service")
async def place_order(request):
# Extraction du contexte de tracing de la requête entrante
ctx = extract(request.headers)
with tracer.start_as_current_span("place_order", context=ctx) as span:
span.set_attribute("order.customer_id", request.customer_id)
span.set_attribute("order.item_count", len(request.items))
# Propagation vers les services appelés
headers = {}
inject(headers)
inventory_response = await inventory_client.check(
request.items,
headers=headers # Trace ID propagé
)
Consistency distribuée#
La fin des transactions ACID distribuées#
Dans un monolithe avec une seule base de données, une transaction ACID garantit l’atomicité de toutes les opérations. Dans les microservices, chaque service a sa propre BDD : il n’y a pas de transaction distribuée gratuite.
Le théorème CAP (Brewer, 2000) formule le trade-off fondamental : dans un système distribué, on ne peut garantir simultanément que deux des trois propriétés — Consistency, Availability, Partition tolerance.
Eventual consistency#
La réponse pratique est l”eventual consistency : le système sera éventuellement cohérent, même si à un instant T des vues incohérentes peuvent exister. Le service commandes peut confirmer une commande avant que le service inventaire ait décrémenté le stock — mais in fine, après traitement du message, les deux seront cohérents.
Saga pattern (aperçu)#
Le Saga pattern est la réponse architecturale aux transactions longues distribuées. Une saga est une séquence d”transactions locales, chacune publiée comme un événement. En cas d’échec, des transactions compensatoires (annulation) sont déclenchées.
Saga "passer une commande" :
1. OrderService.createOrder() → publie OrderCreated
2. InventoryService.reserveStock() → publie StockReserved (ou StockFailed)
3. PaymentService.chargePayment() → publie PaymentDone (ou PaymentFailed)
4. ShippingService.scheduleShipment() → publie ShipmentScheduled
En cas d'échec à l'étape 3 :
← ShippingService : rien (pas encore exécuté)
← PaymentService : compensation → refundPayment()
← InventoryService: compensation → releaseStock()
← OrderService : compensation → cancelOrder()
Quand ne pas faire des microservices#
Premature decomposition#
Le risque le plus fréquent est de découper trop tôt, avant que les frontières du domaine soient bien comprises. Si les frontières changent, chaque refactoring implique des modifications coordonnées sur plusieurs services, avec des impacts sur les API, les schémas de messages, les déploiements.
Indice de maturité nécessaire :
Les domaines métier sont bien délimités et stables.
Les équipes ont une organisation claire et des responsabilités non ambiguës.
L’infrastructure (Kubernetes, CI/CD, observabilité) est en place.
L’équipe a de l’expérience en systèmes distribués.
Le monolithe distribué#
Si vous déployez tous vos services ensemble parce qu’ils partagent une base de données ou parce que modifier l’un casse les autres — vous avez un monolithe distribué. Vous payez tous les coûts des systèmes distribués sans en tirer les bénéfices.
Le test de Martin Fowler
« Pouvez-vous déployer un seul service en production sans coordonner avec les équipes d’autres services ? » Si la réponse est non, vous n’avez pas de microservices — vous avez une architecture distribuée couplée. La première chose à corriger n’est pas l’architecture technique, c’est le couplage contractuel entre services.
Visualisations#
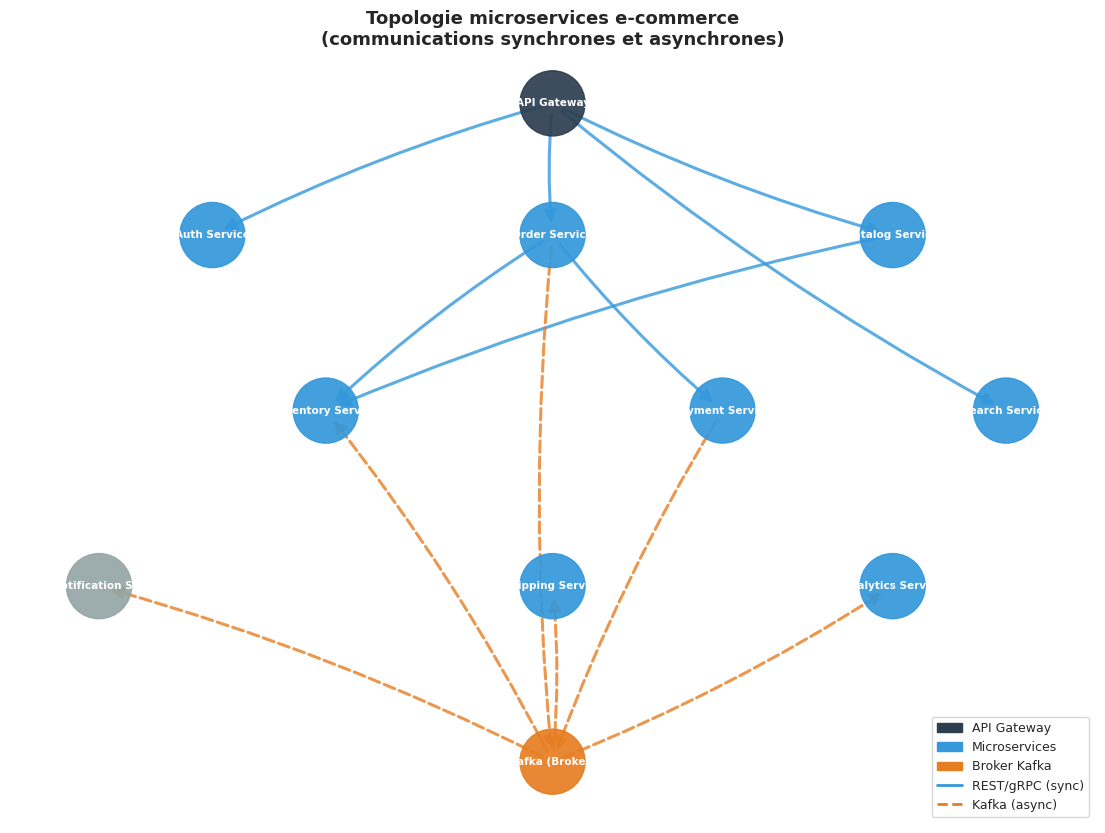
Graphe de topologie microservices#
import networkx as nx
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(14, 10))
G = nx.DiGraph()
services = {
"API Gateway": (5, 9),
"Auth Service": (2, 7.5),
"Order Service": (5, 7.5),
"Catalog Service": (8, 7.5),
"Inventory Service": (3, 5.5),
"Payment Service": (6.5, 5.5),
"Notification Svc": (1, 3.5),
"Shipping Service": (5, 3.5),
"Search Service": (9, 5.5),
"Analytics Service": (8, 3.5),
"Kafka (Broker)": (5, 1.5),
}
for service, pos in services.items():
G.add_node(service, pos=pos)
# Connexions synchrones (REST/gRPC)
sync_edges = [
("API Gateway", "Auth Service"),
("API Gateway", "Order Service"),
("API Gateway", "Catalog Service"),
("API Gateway", "Search Service"),
("Order Service", "Inventory Service"),
("Order Service", "Payment Service"),
("Catalog Service", "Inventory Service"),
]
# Connexions asynchrones (via Kafka)
async_edges = [
("Order Service", "Kafka (Broker)"),
("Payment Service", "Kafka (Broker)"),
("Kafka (Broker)", "Notification Svc"),
("Kafka (Broker)", "Shipping Service"),
("Kafka (Broker)", "Analytics Service"),
("Kafka (Broker)", "Inventory Service"),
]
G.add_edges_from(sync_edges)
G.add_edges_from(async_edges)
pos = nx.get_node_attributes(G, "pos")
# Couleurs des nœuds
def node_color(name):
if name == "API Gateway": return "#2c3e50"
if name == "Kafka (Broker)": return "#e67e22"
if "Service" in name: return "#3498db"
return "#95a5a6"
node_colors = [node_color(n) for n in G.nodes()]
# Dessin des arêtes par type
nx.draw_networkx_edges(G, pos, edgelist=sync_edges, ax=ax,
edge_color="#3498db", width=2.2,
arrowsize=18, alpha=0.8,
connectionstyle="arc3,rad=0.05")
nx.draw_networkx_edges(G, pos, edgelist=async_edges, ax=ax,
edge_color="#e67e22", width=2.2,
arrowsize=18, alpha=0.8, style="dashed",
connectionstyle="arc3,rad=0.05")
nx.draw_networkx_nodes(G, pos, ax=ax,
node_color=node_colors, node_size=2200, alpha=0.92)
nx.draw_networkx_labels(G, pos, ax=ax,
font_size=7.5, font_color="white", font_weight="bold")
legend_patches = [
mpatches.Patch(color="#2c3e50", label="API Gateway"),
mpatches.Patch(color="#3498db", label="Microservices"),
mpatches.Patch(color="#e67e22", label="Broker Kafka"),
plt.Line2D([0], [0], color="#3498db", lw=2, label="REST/gRPC (sync)"),
plt.Line2D([0], [0], color="#e67e22", lw=2, linestyle="dashed", label="Kafka (async)"),
]
ax.legend(handles=legend_patches, loc="lower right", fontsize=9)
ax.set_title("Topologie microservices e-commerce\n(communications synchrones et asynchrones)",
fontsize=13, fontweight="bold")
ax.axis("off")
plt.savefig("_static/08_topologie_microservices.png", dpi=150, bbox_inches="tight")
plt.show()
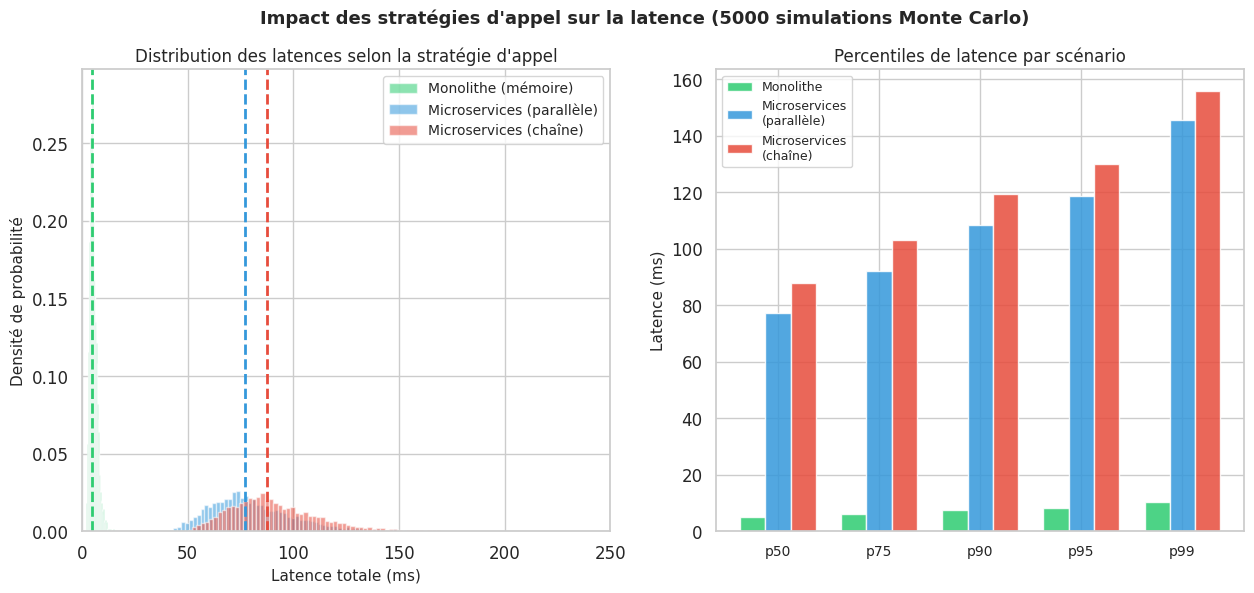
Simulation latence : appels en chaîne vs parallèles#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
rng = np.random.default_rng(42)
n_simulations = 5000
# Latences individuelles des services (distribution log-normale)
def service_latency(mean_ms, sigma=0.4, n=n_simulations):
return rng.lognormal(np.log(mean_ms) - sigma**2/2, sigma, n)
# Service latencies (en ms)
l_auth = service_latency(8)
l_catalog = service_latency(12)
l_inventory= service_latency(15)
l_payment = service_latency(45)
l_shipping = service_latency(10)
# Cas 1 : appels en chaîne (séquentiel) — somme des latences
latence_chaine = l_auth + l_catalog + l_inventory + l_payment + l_shipping
# Cas 2 : appels parallèles optimisés
# auth → puis catalog + inventory en parallèle → payment → shipping
latence_parallel = l_auth + np.maximum(l_catalog, l_inventory) + l_payment + l_shipping
# Cas 3 : monolithe (référence) — tout en mémoire
latence_monolithe = rng.lognormal(np.log(5), 0.3, n_simulations)
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
# Distribution des latences
for data, label, color in [
(latence_monolithe, "Monolithe (mémoire)", "#2ecc71"),
(latence_parallel, "Microservices (parallèle)", "#3498db"),
(latence_chaine, "Microservices (chaîne)", "#e74c3c"),
]:
axes[0].hist(data, bins=80, alpha=0.55, label=label, color=color, density=True)
axes[0].axvline(np.median(data), color=color, linestyle="--", linewidth=2)
axes[0].set_xlabel("Latence totale (ms)", fontsize=11)
axes[0].set_ylabel("Densité de probabilité", fontsize=11)
axes[0].set_title("Distribution des latences selon la stratégie d'appel", fontsize=12)
axes[0].set_xlim(0, 250)
axes[0].legend(fontsize=10)
# Percentiles
percentiles = [50, 75, 90, 95, 99]
scenarios = {
"Monolithe": latence_monolithe,
"Microservices\n(parallèle)": latence_parallel,
"Microservices\n(chaîne)": latence_chaine,
}
colors_bar = ["#2ecc71", "#3498db", "#e74c3c"]
x = np.arange(len(percentiles))
width = 0.25
for i, (scenario, data) in enumerate(scenarios.items()):
vals = [np.percentile(data, p) for p in percentiles]
bars = axes[1].bar(x + i*width, vals, width, label=scenario,
color=colors_bar[i], alpha=0.85)
axes[1].set_xticks(x + width)
axes[1].set_xticklabels([f"p{p}" for p in percentiles], fontsize=10)
axes[1].set_ylabel("Latence (ms)", fontsize=11)
axes[1].set_title("Percentiles de latence par scénario", fontsize=12)
axes[1].legend(fontsize=9)
# Stats résumées
for i, (label, data) in enumerate([(l, d) for l, d in
[("Monolithe", latence_monolithe), ("Parallel", latence_parallel), ("Chaîne", latence_chaine)]]):
print(f"{label:20} | p50={np.percentile(data,50):5.0f}ms | "
f"p95={np.percentile(data,95):5.0f}ms | p99={np.percentile(data,99):5.0f}ms")
plt.suptitle("Impact des stratégies d'appel sur la latence (5000 simulations Monte Carlo)",
fontsize=13, fontweight="bold")
plt.savefig("_static/08_latence.png", dpi=150, bbox_inches="tight")
plt.show()
Monolithe | p50= 5ms | p95= 8ms | p99= 10ms
Parallel | p50= 77ms | p95= 119ms | p99= 146ms
Chaîne | p50= 88ms | p95= 130ms | p99= 156ms
Visualisation des 8 fallacies#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fallacies = [
("1. Le réseau est fiable", "Paquets perdus,\nconnexions coupées", "Circuit breaker,\nRetry + backoff"),
("2. La latence est nulle", "1-10 ms par appel\nvs nanosecondes", "Timeout, appels\nparallèles, cache"),
("3. La bande passante est ∞", "Saturation,\nthrottling", "Pagination, compression,\nbatch"),
("4. Le réseau est sécurisé", "Trafic interceptable,\nservices exposés", "mTLS, service mesh,\nzero trust"),
("5. La topologie est fixe", "IPs changeantes,\nscaling dynamique", "Service discovery,\nDNS dynamique"),
("6. Un seul administrateur", "Équipes multiples,\npolitiques divergentes","Contrats d'interface,\nAPI versioning"),
("7. Le transport est gratuit", "Sérialisation CPU,\nmemory allocation", "Protobuf, batching,\nchoix sérialisation"),
("8. Le réseau est homogène", "Protocoles, OS,\nversions hétérogènes", "Standards ouverts,\nAPI gateway"),
]
fig, ax = plt.subplots(figsize=(16, 10))
ax.set_xlim(0, 16)
ax.set_ylim(-0.5, len(fallacies) + 0.5)
ax.axis("off")
# En-têtes
headers = ["Fallacy", "Réalité", "Réponse architecturale"]
header_x = [0.2, 5.5, 11.0]
header_colors = ["#2c3e50", "#e74c3c", "#27ae60"]
for hx, header, hcolor in zip(header_x, headers, header_colors):
ax.text(hx + 2.5, len(fallacies) + 0.1, header,
fontsize=12, fontweight="bold", color=hcolor, ha="center")
ax.axhline(len(fallacies) - 0.2, color="#bdc3c7", linewidth=1.5)
for i, (fallacy, réalité, réponse) in enumerate(fallacies):
y = len(fallacies) - 1 - i
bg_color = "#f8f9fa" if i % 2 == 0 else "#ecf0f1"
bg = mpatches.FancyBboxPatch((0.1, y - 0.4), 15.8, 0.85,
boxstyle="round,pad=0.05",
facecolor=bg_color, edgecolor="#dee2e6",
linewidth=0.8, alpha=0.8)
ax.add_patch(bg)
ax.text(0.3, y + 0.05, fallacy,
fontsize=9, fontweight="bold", color="#2c3e50", va="center")
ax.text(5.7, y + 0.05, réalité,
fontsize=8.5, color="#c0392b", va="center")
ax.text(11.2, y + 0.05, réponse,
fontsize=8.5, color="#16a085", va="center", fontweight="bold")
# Séparateurs verticaux
ax.axvline(5.4, color="#bdc3c7", linewidth=0.8, ymin=0, ymax=1, alpha=0.5)
ax.axvline(10.9, color="#bdc3c7", linewidth=0.8, ymin=0, ymax=1, alpha=0.5)
ax.set_title("Les 8 Fallacies du réseau distribué — Deutsch & Gosling (1994)",
fontsize=13, fontweight="bold", y=1.02)
plt.savefig("_static/08_fallacies.png", dpi=150, bbox_inches="tight")
plt.show()
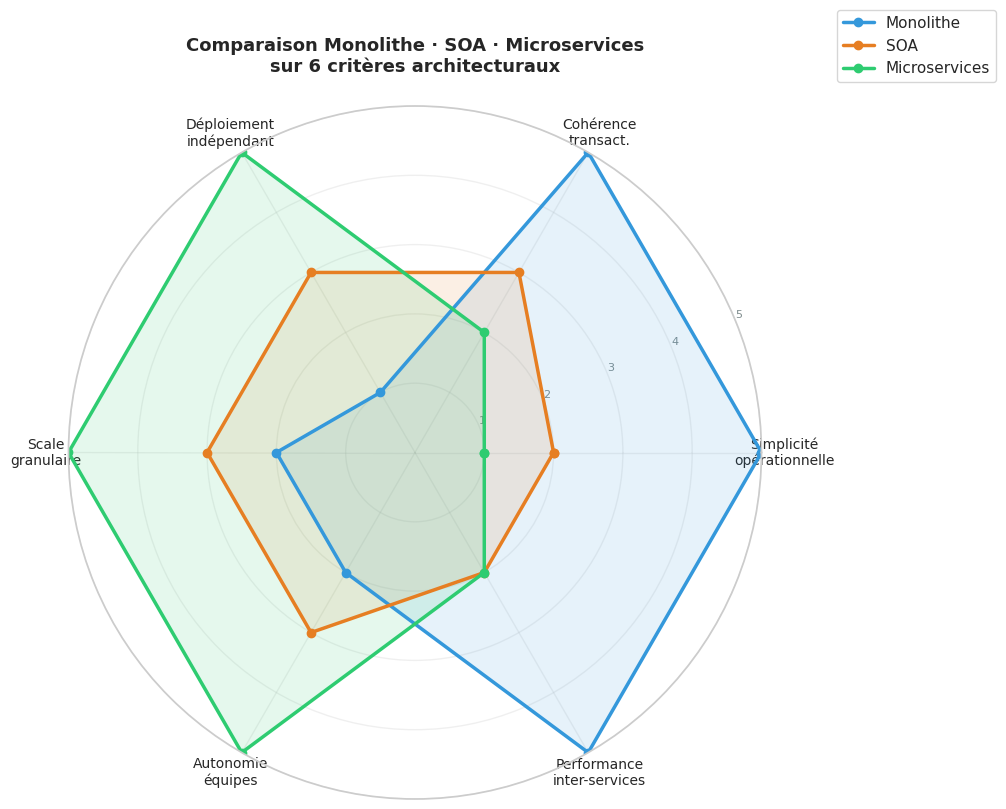
Radar : comparaison monolithe / SOA / microservices#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
critères = [
"Simplicité\nopérationnelle",
"Cohérence\ntransact.",
"Déploiement\nindépendant",
"Scale\ngranulaire",
"Autonomie\néquipes",
"Performance\ninter-services",
]
monolithe = [5, 5, 1, 2, 2, 5]
soa = [2, 3, 3, 3, 3, 2]
microservices = [1, 2, 5, 5, 5, 2]
N = len(critères)
angles = [n / float(N) * 2 * np.pi for n in range(N)]
angles += angles[:1]
fig, ax = plt.subplots(figsize=(9, 9), subplot_kw=dict(polar=True))
def plot_radar(ax, values, label, color):
vals = values + values[:1]
ax.plot(angles, vals, "o-", linewidth=2.5, color=color, label=label)
ax.fill(angles, vals, alpha=0.12, color=color)
plot_radar(ax, monolithe, "Monolithe", "#3498db")
plot_radar(ax, soa, "SOA", "#e67e22")
plot_radar(ax, microservices, "Microservices", "#2ecc71")
ax.set_xticks(angles[:-1])
ax.set_xticklabels(critères, fontsize=10)
ax.set_ylim(0, 5)
ax.set_yticks([1, 2, 3, 4, 5])
ax.set_yticklabels(["1", "2", "3", "4", "5"], fontsize=8, color="#7f8c8d")
ax.grid(True, alpha=0.3)
ax.legend(loc="upper right", bbox_to_anchor=(1.35, 1.15), fontsize=11)
ax.set_title("Comparaison Monolithe · SOA · Microservices\nsur 6 critères architecturaux",
fontsize=13, fontweight="bold", pad=25)
plt.savefig("_static/08_radar.png", dpi=150, bbox_inches="tight")
plt.show()
Résumé#
Les microservices représentent une réponse architecturale au problème du scale organisationnel : comment permettre à de nombreuses équipes de travailler et déployer indépendamment sur un système complexe ? Ils apportent une solution réelle mais introduisent une complexité distribuée substantielle.
Points clés :
Un microservice est défini par sa responsabilité (une capacité métier) et son déploiement indépendant, pas par sa taille en lignes de code. Le Bounded Context du DDD est la frontière naturelle.
La communication synchrone (REST, gRPC) est simple à raisonner mais crée un couplage temporel — si le service appelé est indisponible, l’appelant l’est aussi. Timeouts, circuit breakers et retries sont impératifs.
La communication asynchrone (Kafka, RabbitMQ) découple temporellement les services mais exige de gérer l’idempotence, l’ordering des messages et la gestion des erreurs différemment.
Les 8 fallacies du réseau distribué sont un rappel que les microservices vivent dans un monde où le réseau est hostile. Chaque fallacy se traduit en exigence de conception concrète.
La consistency distribuée ne peut pas s’appuyer sur des transactions ACID. L’eventual consistency et le Saga pattern sont les réponses architecturales, avec leurs propres complexités de débogage.
Les microservices ne sont pas la solution par défaut. Ils se justifient quand l’organisation a la maturité (équipes produit autonomes, infrastructure DevOps, DDD), pas avant.
Le monolithe distribué — services couplés déployés ensemble — est le pire des deux mondes. Le vrai test est : peut-on déployer un service sans coordonner avec les autres ?
La règle des deux pizzas
Jeff Bezos a popularisé la règle : une équipe ne doit pas être trop grande pour être nourrie avec deux pizzas (5-8 personnes). Chaque microservice doit idéalement être la propriété d’une telle équipe, qui en est responsable de bout en bout. Cette règle organisationnelle est aussi importante que les choix techniques.