17. Scalabilité#
La scalabilité désigne la capacité d’un système à maintenir ses performances lorsque la charge augmente. C’est une propriété qui se conçoit dès les premières décisions architecturales — elle ne s’ajoute pas après coup sans coûts importants.
Scaling vertical vs horizontal#
Le scaling vertical (scale-up) consiste à augmenter les ressources d’une seule machine : plus de CPU, plus de RAM, des disques plus rapides. C’est simple à mettre en œuvre — il n’y a pas de code à modifier — mais ses limites sont dures. Au-delà d’un certain seuil, le matériel n’existe tout simplement pas, et le rapport coût/performance se dégrade fortement. Une machine à 64 cœurs coûte bien plus du double d’une machine à 32 cœurs.
Le scaling horizontal (scale-out) consiste à ajouter des instances identiques derrière un load balancer. L’élasticité est quasi infinie : on peut passer de 2 à 200 instances en quelques minutes sur le cloud. Le coût suit une courbe linéaire. Mais cette approche impose une contrainte architecturale fondamentale : les instances doivent être stateless.
Pourquoi stateless est obligatoire pour scale-out#
Si chaque instance stocke l’état de la session utilisateur localement (en mémoire), une requête routée vers une autre instance ne trouvera pas cet état. Deux solutions existent : les sticky sessions (l’utilisateur est toujours routé vers la même instance) ou l’externalisation de l’état. Les sticky sessions sont une solution de contournement fragile — elles empêchent la distribution uniforme de la charge et compliquent les déploiements. L’externalisation vers Redis ou un service équivalent est la bonne pratique.
Limites du scaling vertical
Sur les grands clouds (AWS, GCP, Azure), les instances les plus puissantes peuvent coûter plusieurs milliers d’euros par mois. Au-delà, les instances n’existent plus. Le scaling vertical a un plafond physique absolu.
Stateless vs stateful#
Un service stateless traite chaque requête de manière indépendante, sans mémoire des requêtes précédentes. Toute l’information nécessaire au traitement est dans la requête elle-même (ou récupérée depuis un store partagé). Les services REST bien conçus sont stateless.
Un service stateful maintient un état entre les requêtes. C’est parfois inévitable (bases de données, brokers de messages) mais doit rester confiné à des composants dédiés.
JWT comme mécanisme stateless#
Les JSON Web Tokens encodent les informations de session directement dans un token signé. Le serveur n’a pas besoin de stocker quoi que ce soit — il vérifie la signature et lit les claims. C’est l’incarnation du stateless pour l’authentification.
Inconvénient : la révocation est difficile. Un JWT valide reste valide jusqu’à expiration, même si l’utilisateur s’est déconnecté. Des solutions existent (liste noire en Redis, tokens à courte durée de vie + refresh tokens) mais ajoutent de la complexité.
Externalisation de l’état avec Redis#
Redis est le choix standard pour externaliser l’état : sessions, caches, files de travail légères, verrous distribués. Sa latence en mémoire (< 1 ms) le rend adapté au chemin critique des requêtes HTTP.
Sticky sessions : un anti-pattern à éviter
Les sticky sessions semblent résoudre le problème stateful/stateless mais créent de nouveaux problèmes : impossibilité de déployer sans interruption pour certains utilisateurs, déséquilibre de charge si certains utilisateurs sont très actifs, complexité du load balancer.
Sharding et partitionnement#
Quand une base de données devient trop grande pour une seule machine, le sharding distribue les données sur plusieurs nœuds. Chaque shard contient un sous-ensemble des données.
Hash sharding#
La clé de partition est hashée pour déterminer le shard. Distribution uniforme garantie, mais les requêtes par plage sont impossibles (les données d’une plage sont éparpillées sur tous les shards).
Range sharding#
Les données sont réparties par plage de valeurs (A-M sur le shard 1, N-Z sur le shard 2). Les requêtes par plage sont efficaces, mais les hotspots sont un risque réel : si toutes les nouvelles données ont des clés dans la même plage (timestamps, IDs auto-incrémentés), un seul shard reçoit toute la charge.
Consistent hashing#
Le consistent hashing place les nœuds et les clés sur un anneau circulaire. Quand un nœud est ajouté ou retiré, seules les clés du voisin immédiat sont redistribuées — pas la totalité des données. C’est la propriété clé pour les systèmes dynamiques où les nœuds arrivent et partent.
Hotspots : le piège du range sharding
Dans un système de logs avec un timestamp comme clé de shard, tous les nouveaux logs vont sur le dernier shard. Ce shard devient un hotspot pendant que les autres restent inactifs. Solution : préfixer la clé avec un hash ou utiliser des clés composites.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import hashlib
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
def hash_key(key, modulus=2**16):
"""Hash une clé sur l'anneau [0, modulus)."""
h = int(hashlib.md5(str(key).encode()).hexdigest(), 16)
return h % modulus
def consistent_hash_ring(nodes, virtual_nodes=3, ring_size=2**16):
"""Construit un anneau de consistent hashing."""
ring = {}
sorted_keys = []
for node in nodes:
for v in range(virtual_nodes):
vnode_key = f"{node}#{v}"
pos = hash_key(vnode_key, ring_size)
ring[pos] = node
sorted_keys.append(pos)
sorted_keys.sort()
return ring, sorted_keys
def assign_key(key, ring, sorted_keys, ring_size=2**16):
"""Assigne une clé au nœud suivant sur l'anneau."""
pos = hash_key(key, ring_size)
for sk in sorted_keys:
if pos <= sk:
return ring[sk]
return ring[sorted_keys[0]]
# Simulation
nodes = ["Node-A", "Node-B", "Node-C", "Node-D"]
ring, sorted_keys = consistent_hash_ring(nodes, virtual_nodes=5)
# Distribuer 1000 clés
n_keys = 1000
assignments = {}
for i in range(n_keys):
node = assign_key(f"key_{i}", ring, sorted_keys)
assignments[node] = assignments.get(node, 0) + 1
# Visualisation de l'anneau
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Anneau circulaire
ax = axes[0]
ax.set_aspect('equal')
theta = np.linspace(0, 2 * np.pi, 500)
ax.plot(np.cos(theta), np.sin(theta), 'k-', linewidth=1.5, alpha=0.3)
colors = sns.color_palette("muted", len(nodes))
node_colors = {n: colors[i] for i, n in enumerate(nodes)}
ring_size = 2**16
for pos, node in ring.items():
angle = (pos / ring_size) * 2 * np.pi
x, y = np.cos(angle), np.sin(angle)
ax.plot(x, y, 'o', color=node_colors[node], markersize=10, zorder=5)
# Légende
handles = [mpatches.Patch(color=node_colors[n], label=n) for n in nodes]
ax.legend(handles=handles, loc='upper right', fontsize=9)
ax.set_title("Anneau de consistent hashing\n(nœuds virtuels)", fontsize=12)
ax.set_xlim(-1.4, 1.4)
ax.set_ylim(-1.4, 1.4)
ax.axis('off')
# Distribution
ax2 = axes[1]
node_names = list(assignments.keys())
counts = [assignments[n] for n in node_names]
bars = ax2.bar(node_names, counts, color=[node_colors[n] for n in node_names], edgecolor='white', linewidth=1.5)
ax2.axhline(n_keys / len(nodes), color='red', linestyle='--', linewidth=1.5, label=f'Distribution idéale ({n_keys//len(nodes)})')
ax2.set_ylabel("Nombre de clés assignées")
ax2.set_title(f"Distribution de {n_keys} clés\nsur {len(nodes)} nœuds", fontsize=12)
ax2.legend()
for bar, count in zip(bars, counts):
ax2.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 5,
str(count), ha='center', va='bottom', fontweight='bold')
plt.suptitle("Consistent Hashing — Simulation", fontsize=14, fontweight='bold', y=1.02)
plt.savefig("consistent_hashing.png", dpi=100, bbox_inches='tight')
plt.show()
print(f"\nDistribution : {assignments}")
print(f"Écart-type : {np.std(list(assignments.values())):.1f} clés")
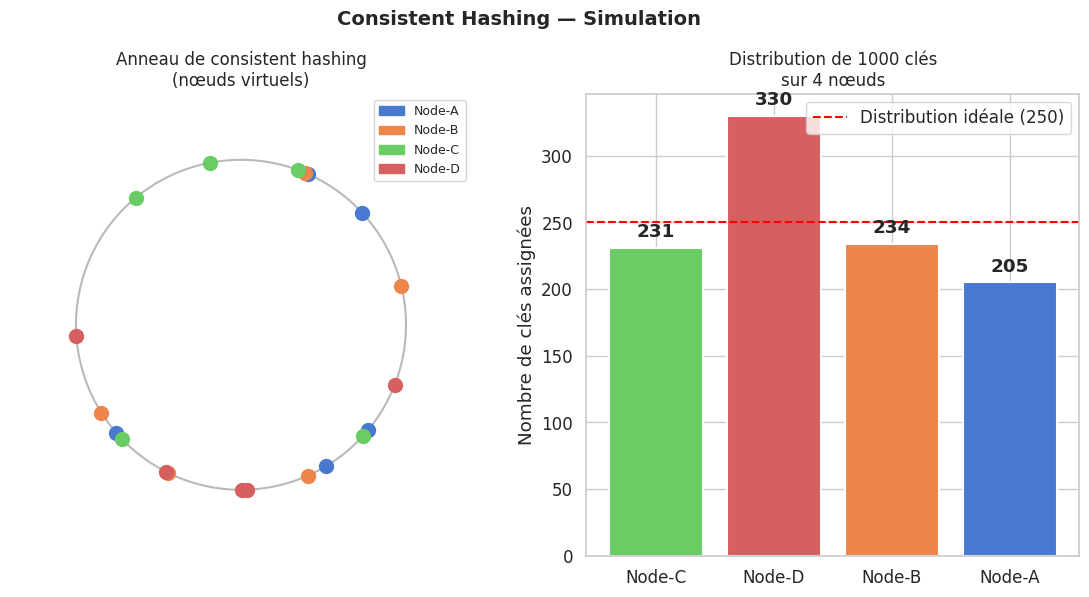
Distribution : {'Node-C': 231, 'Node-D': 330, 'Node-B': 234, 'Node-A': 205}
Écart-type : 47.5 clés
Load balancing#
Le load balancer distribue les requêtes entrantes sur un pool d’instances. C’est le point d’entrée de l’architecture horizontale.
Algorithmes de distribution#
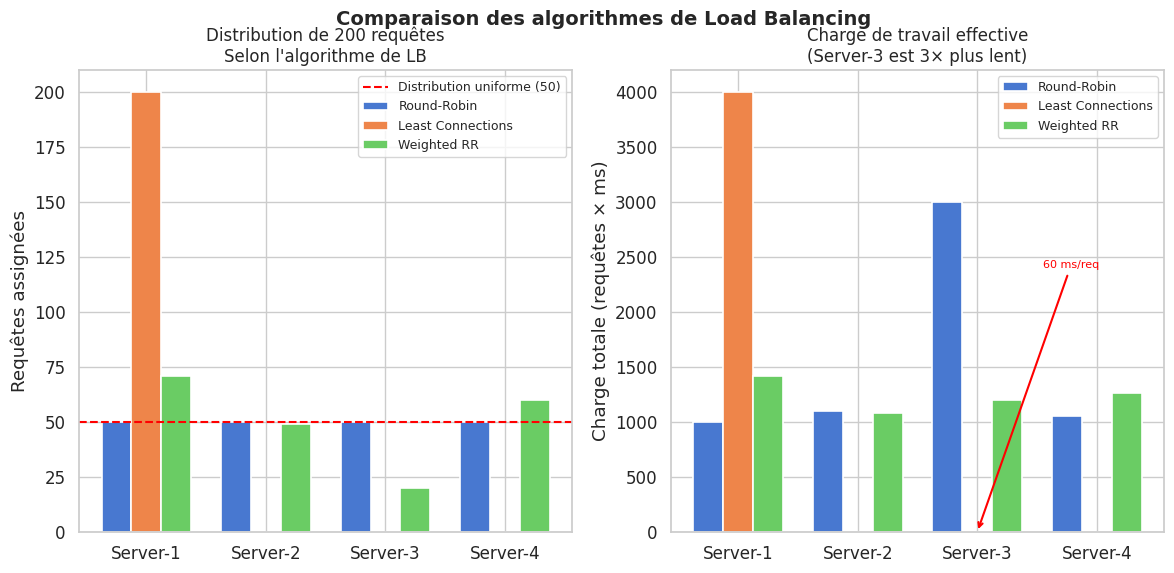
Round-robin : les requêtes sont distribuées tour à tour. Simple, mais ignore la charge réelle de chaque instance — une instance lente accumule les connexions.
Least connections : la requête est envoyée à l’instance qui a le moins de connexions actives. Plus adapté aux traitements de durées variables.
Consistent hashing : les requêtes avec la même clé (IP, user ID) vont toujours sur la même instance. Utile pour maximiser les caches locaux des instances.
L4 vs L7#
Un load balancer L4 (couche transport) distribue les paquets TCP/UDP sans inspecter le contenu. Très rapide, mais peu de contrôle.
Un load balancer L7 (couche application) comprend HTTP/HTTPS. Il peut router selon l’URL, les headers, le contenu. Il peut faire de la terminaison TLS, de la compression, de la mise en cache. HAProxy et Nginx opèrent en L7.
Health checks#
Le load balancer sonde régulièrement chaque instance (HTTP GET /health). Une instance qui ne répond plus est retirée du pool automatiquement. C’est le mécanisme de base de la tolérance aux pannes au niveau du routage.
Health check superficiel vs profond
Un health check qui répond toujours 200 est inutile. Un bon health check vérifie la connectivité à la base de données, aux dépendances critiques, et répond 503 si quelque chose est dégradé — permettant au load balancer de retirer l’instance du pool.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import random
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
random.seed(42)
np.random.seed(42)
n_requests = 200
n_servers = 4
server_names = [f"Server-{i+1}" for i in range(n_servers)]
# Simulation des durées de traitement (Server-3 est plus lent)
base_times = [20, 22, 60, 21] # ms moyens par serveur
def simulate_algorithms(n_req, n_srv, base_t):
"""Simule 3 algorithmes de load balancing."""
results = {}
# Round-robin
rr_counts = [0] * n_srv
for i in range(n_req):
srv = i % n_srv
rr_counts[srv] += 1
results['Round-Robin'] = rr_counts
# Least connections (simulé dynamiquement)
lc_counts = [0] * n_srv
active_conns = [0] * n_srv
for i in range(n_req):
srv = active_conns.index(min(active_conns))
lc_counts[srv] += 1
active_conns[srv] += 1
# Libère des connexions aléatoirement selon la vitesse du serveur
for s in range(n_srv):
release_prob = 1 / (base_t[s] / min(base_t))
if active_conns[s] > 0 and random.random() < release_prob:
active_conns[s] -= 1
results['Least Connections'] = lc_counts
# Weighted round-robin (poids inversement proportionnels au temps de traitement)
weights = [1/t for t in base_t]
total_w = sum(weights)
probs = [w/total_w for w in weights]
wrr_counts = [0] * n_srv
for i in range(n_req):
srv = np.random.choice(n_srv, p=probs)
wrr_counts[srv] += 1
results['Weighted RR'] = wrr_counts
return results
results = simulate_algorithms(n_requests, n_servers, base_times)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Barplot comparaison
ax1 = axes[0]
x = np.arange(n_servers)
width = 0.25
colors = sns.color_palette("muted", 3)
algos = list(results.keys())
for idx, (algo, counts) in enumerate(results.items()):
bars = ax1.bar(x + idx * width, counts, width, label=algo,
color=colors[idx], edgecolor='white', linewidth=1.2)
ax1.axhline(n_requests / n_servers, color='red', linestyle='--',
linewidth=1.5, label=f'Distribution uniforme ({n_requests//n_servers})')
ax1.set_xticks(x + width)
ax1.set_xticklabels(server_names)
ax1.set_ylabel("Requêtes assignées")
ax1.set_title(f"Distribution de {n_requests} requêtes\nSelon l'algorithme de LB", fontsize=12)
ax1.legend(fontsize=9)
# Charge pondérée (requêtes × temps de traitement)
ax2 = axes[1]
for idx, (algo, counts) in enumerate(results.items()):
work_ms = [c * t for c, t in zip(counts, base_times)]
ax2.bar(x + idx * width, work_ms, width, label=algo,
color=colors[idx], edgecolor='white', linewidth=1.2)
ax2.set_xticks(x + width)
ax2.set_xticklabels(server_names)
ax2.set_ylabel("Charge totale (requêtes × ms)")
ax2.set_title("Charge de travail effective\n(Server-3 est 3× plus lent)", fontsize=12)
ax2.legend(fontsize=9)
# Annotation du serveur lent
ax2.annotate(f'60 ms/req', xy=(2 + width, 0), xytext=(2.8, max([c*60 for c in [results[a][2] for a in algos]])*0.8),
fontsize=8, color='red',
arrowprops=dict(arrowstyle='->', color='red', lw=1.5))
plt.suptitle("Comparaison des algorithmes de Load Balancing", fontsize=14, fontweight='bold')
plt.savefig("load_balancing.png", dpi=100, bbox_inches='tight')
plt.show()
Loi d’Amdahl revisitée#
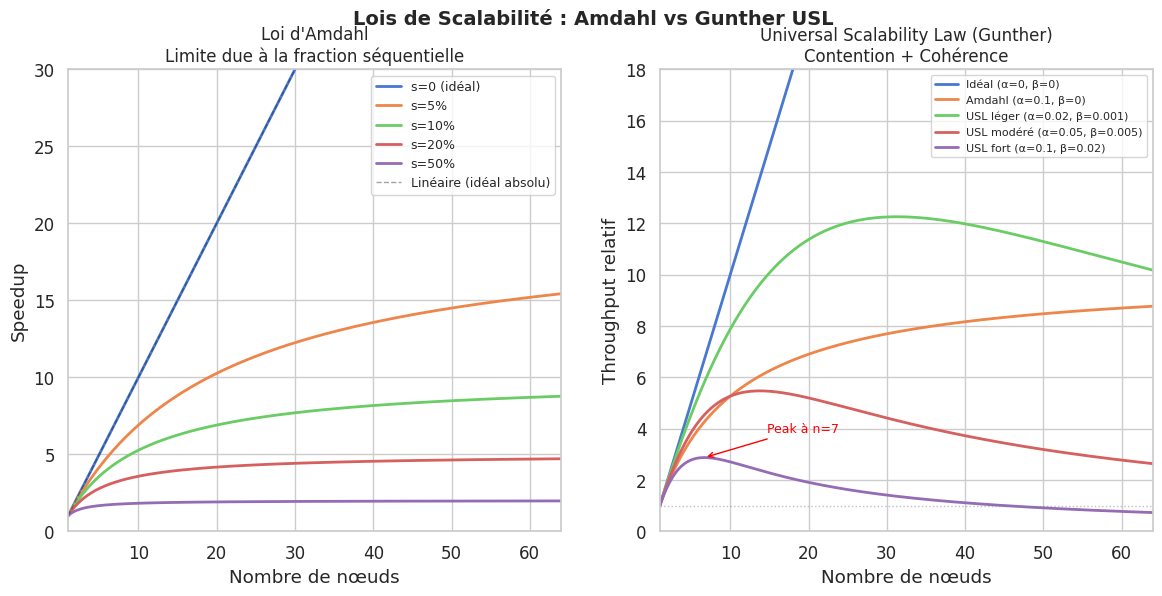
La loi d’Amdahl modélise la limite théorique du speedup obtenu en parallélisant une tâche dont une fraction s est intrinsèquement séquentielle :
Quand n → ∞, S → 1/s. Si 10 % du code est séquentiel, le speedup maximal est 10×, quelles que soient les ressources ajoutées.
La fraction séquentielle englobe plus que le code : la coordination entre processus, les verrous, les points de synchronisation, les accès à des ressources partagées. Dans les systèmes distribués, la latence réseau est une composante séquentielle incompressible.
Mesurer la fraction parallélisable
Pour mesurer s empiriquement : faire tourner le système sur 1 nœud, puis 2, 4, 8… La fraction séquentielle se calcule par régression sur la courbe de speedup observée. Si le speedup plafonne à 5× avec 20 nœuds, s ≈ 0.20.
Loi de Gunther (Universal Scalability Law)#
La USL étend Amdahl en ajoutant deux termes :
α (contention) : coût de la sérialisation, comme Amdahl — chaque nœud attend les ressources partagées.
β (coherency) : coût de la cohérence des données entre nœuds. Ce terme est quadratique : il croît avec n², ce qui peut faire décroître le throughput quand on ajoute des nœuds.
La USL prédit un phénomène contre-intuitif : au-delà d’un certain nombre de nœuds, les performances se dégradent. C’est ce qu’on observe dans les bases de données distribuées fortement consistantes.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
def amdahl(n, s):
"""Speedup selon Amdahl."""
return 1 / (s + (1 - s) / n)
def usl(n, alpha, beta):
"""Throughput relatif selon la Universal Scalability Law."""
return n / (1 + alpha * (n - 1) + beta * n * (n - 1))
n = np.linspace(1, 64, 500)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Amdahl
ax1 = axes[0]
for s, label in [(0.0, 's=0 (idéal)'), (0.05, 's=5%'), (0.10, 's=10%'),
(0.20, 's=20%'), (0.50, 's=50%')]:
speedup = amdahl(n, s)
ax1.plot(n, speedup, linewidth=2, label=label)
ax1.plot(n, n, 'k--', linewidth=1, alpha=0.4, label='Linéaire (idéal absolu)')
ax1.set_xlabel("Nombre de nœuds")
ax1.set_ylabel("Speedup")
ax1.set_title("Loi d'Amdahl\nLimite due à la fraction séquentielle", fontsize=12)
ax1.legend(fontsize=9)
ax1.set_xlim(1, 64)
ax1.set_ylim(0, 30)
# USL
ax2 = axes[1]
configs = [
(0.0, 0.0, 'Idéal (α=0, β=0)'),
(0.1, 0.0, 'Amdahl (α=0.1, β=0)'),
(0.02, 0.001, 'USL léger (α=0.02, β=0.001)'),
(0.05, 0.005, 'USL modéré (α=0.05, β=0.005)'),
(0.1, 0.02, 'USL fort (α=0.1, β=0.02)'),
]
for alpha, beta, label in configs:
throughput = usl(n, alpha, beta)
ax2.plot(n, throughput, linewidth=2, label=label)
ax2.axhline(1, color='gray', linestyle=':', linewidth=1, alpha=0.5)
ax2.set_xlabel("Nombre de nœuds")
ax2.set_ylabel("Throughput relatif")
ax2.set_title("Universal Scalability Law (Gunther)\nContention + Cohérence", fontsize=12)
ax2.legend(fontsize=8)
ax2.set_xlim(1, 64)
ax2.set_ylim(0, 18)
# Annoter la dégradation
alpha_demo, beta_demo = 0.1, 0.02
tp = usl(n, alpha_demo, beta_demo)
peak_idx = np.argmax(tp)
ax2.annotate(f'Peak à n={n[peak_idx]:.0f}',
xy=(n[peak_idx], tp[peak_idx]),
xytext=(n[peak_idx]+8, tp[peak_idx]+1),
fontsize=9, color='red',
arrowprops=dict(arrowstyle='->', color='red'))
plt.suptitle("Lois de Scalabilité : Amdahl vs Gunther USL", fontsize=14, fontweight='bold')
plt.savefig("scalabilite_lois.png", dpi=100, bbox_inches='tight')
plt.show()
CQRS pour la scalabilité#
CQRS (Command Query Responsibility Segregation) sépare les modèles de lecture et d’écriture. Cette séparation ouvre des possibilités de scalabilité asymétrique : dans la plupart des applications, les lectures sont 10 à 100 fois plus fréquentes que les écritures.
Côté lecture : des read replicas de la base de données servent les requêtes. On peut en ajouter autant que nécessaire. Les projections dénormalisées optimisent chaque vue pour sa requête spécifique — pas de JOIN, pas de calcul à la volée.
Côté écriture : un seul nœud maître (ou un cluster) gère les commands. Le volume est structurellement plus faible.
La contrepartie est l”eventual consistency : un write arrivé sur le maître met quelques millisecondes à se propager sur les replicas. Les lectures immédiatement après une écriture peuvent retourner une valeur légèrement obsolète. C’est acceptable pour la plupart des cas d’usage (feed social, catalogue produit) mais inadmissible pour d’autres (solde bancaire, stock).
Eventual consistency : accepter l’incertitude
L’eventual consistency ne signifie pas que les données seront fausses — elle signifie qu’elles seront cohérentes après un délai borné. Dans un système correctement configuré, ce délai est de quelques millisecondes à quelques secondes selon la géographie.
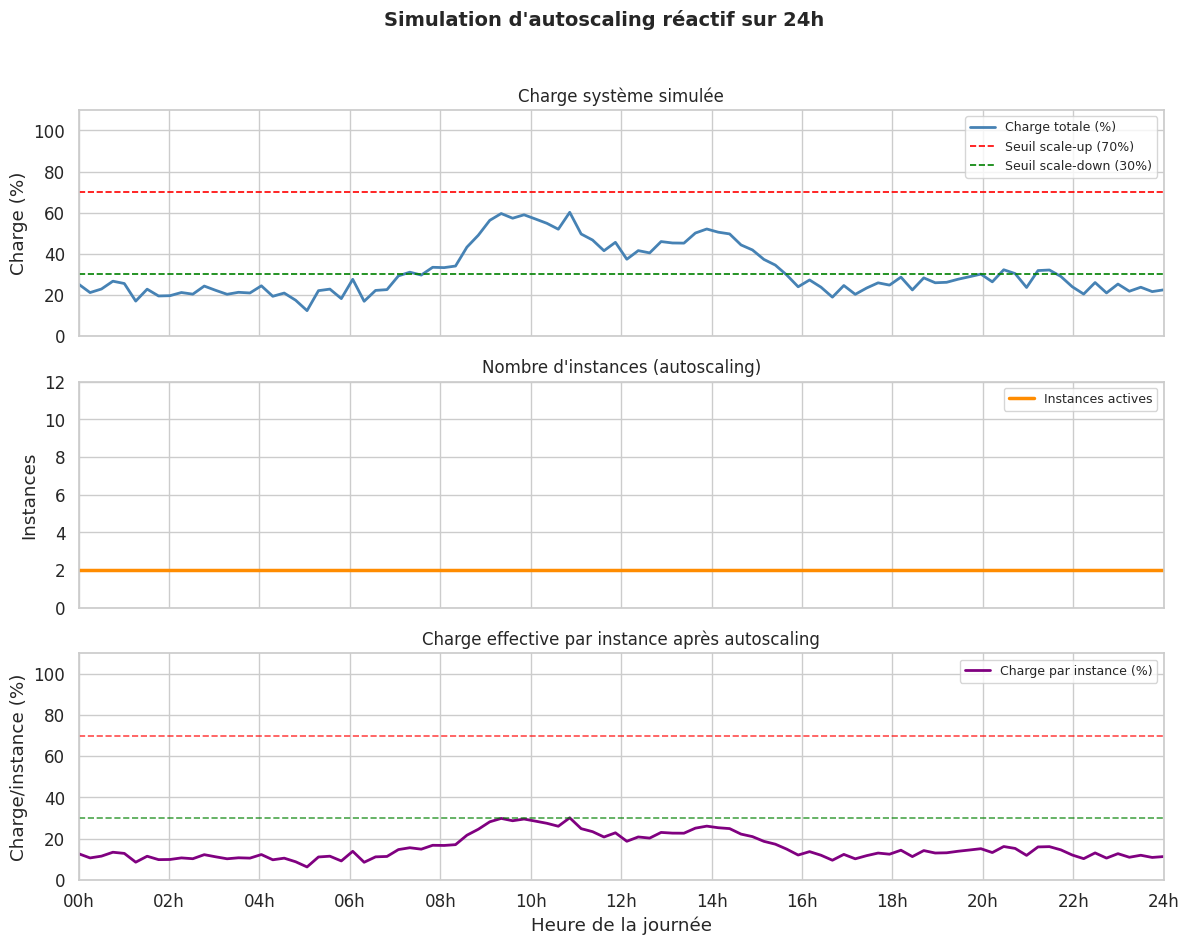
Autoscaling#
L’autoscaling ajuste automatiquement le nombre d’instances selon la charge. Il est devenu standard sur tous les clouds.
Métriques déclenchantes#
Les métriques les plus courantes : CPU moyen, mémoire, nombre de requêtes par seconde, profondeur d’une queue. Attention à choisir la bonne métrique : l’autoscaling sur le CPU peut être trompeur (un service I/O-bound peut être surchargé avec un CPU à 10 %).
Cooldown#
Après un scale-out ou scale-in, une période de cooldown empêche les décisions oscillantes. Sans cooldown, le système peut scaler-out, puis scaler-in immédiatement, puis scaler-out à nouveau dans une boucle instable.
Predictive scaling#
Au lieu de réagir à la charge, le predictive scaling anticipe les pics en analysant les patterns historiques. Si chaque mardi matin à 9h la charge triple, les instances sont déjà présentes avant le pic.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(0)
# Simulation d'une journée de trafic (96 pas de 15 min)
time_steps = 96
t = np.linspace(0, 24, time_steps)
# Charge simulée : deux pics (matin et midi)
load_base = (
20 + 40 * np.exp(-((t - 10)**2) / 4)
+ 30 * np.exp(-((t - 14)**2) / 3)
+ 10 * np.exp(-((t - 20)**2) / 5)
+ np.random.normal(0, 3, time_steps)
)
load_base = np.clip(load_base, 5, 100)
# Seuils autoscaling
scale_up_threshold = 70 # % CPU
scale_down_threshold = 30 # % CPU
min_instances = 2
max_instances = 10
cooldown = 4 # pas de 15 min = 1h de cooldown
# Simulation autoscaling
instances = [min_instances] * time_steps
current_instances = min_instances
last_scale_time = -cooldown - 1
for i in range(1, time_steps):
load_per_instance = load_base[i] / current_instances
in_cooldown = (i - last_scale_time) < cooldown
if not in_cooldown:
if load_per_instance > scale_up_threshold and current_instances < max_instances:
needed = int(np.ceil(load_base[i] / scale_up_threshold))
current_instances = min(needed, max_instances)
last_scale_time = i
elif load_per_instance < scale_down_threshold and current_instances > min_instances:
needed = max(int(np.ceil(load_base[i] / scale_up_threshold)), min_instances)
current_instances = needed
last_scale_time = i
instances[i] = current_instances
effective_load = load_base / np.array(instances)
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
ax1 = axes[0]
ax1.plot(t, load_base, color='steelblue', linewidth=2, label='Charge totale (%)')
ax1.axhline(scale_up_threshold, color='red', linestyle='--', linewidth=1.2,
label=f'Seuil scale-up ({scale_up_threshold}%)')
ax1.axhline(scale_down_threshold, color='green', linestyle='--', linewidth=1.2,
label=f'Seuil scale-down ({scale_down_threshold}%)')
ax1.set_ylabel("Charge (%)")
ax1.set_title("Charge système simulée", fontsize=12)
ax1.legend(fontsize=9)
ax1.set_ylim(0, 110)
ax2 = axes[1]
ax2.step(t, instances, color='darkorange', linewidth=2.5, where='post', label='Instances actives')
ax2.fill_between(t, min_instances, instances, alpha=0.3, color='darkorange', step='post')
ax2.set_ylabel("Instances")
ax2.set_title("Nombre d'instances (autoscaling)", fontsize=12)
ax2.set_ylim(0, max_instances + 2)
ax2.legend(fontsize=9)
ax3 = axes[2]
ax3.plot(t, effective_load, color='purple', linewidth=2, label='Charge par instance (%)')
ax3.axhline(scale_up_threshold, color='red', linestyle='--', linewidth=1.2, alpha=0.7)
ax3.axhline(scale_down_threshold, color='green', linestyle='--', linewidth=1.2, alpha=0.7)
ax3.set_xlabel("Heure de la journée")
ax3.set_ylabel("Charge/instance (%)")
ax3.set_title("Charge effective par instance après autoscaling", fontsize=12)
ax3.legend(fontsize=9)
ax3.set_ylim(0, 110)
ax3.set_xlim(0, 24)
ax3.set_xticks(range(0, 25, 2))
ax3.set_xticklabels([f"{h:02d}h" for h in range(0, 25, 2)])
plt.suptitle("Simulation d'autoscaling réactif sur 24h", fontsize=14, fontweight='bold')
plt.savefig("autoscaling.png", dpi=100, bbox_inches='tight')
plt.show()
Résumé#
La scalabilité est une discipline qui commence par l’architecture, pas par l’infrastructure.
Technique |
Bénéfice |
Prérequis |
|---|---|---|
Scaling horizontal |
Élasticité quasi-infinie |
Services stateless |
Consistent hashing |
Redistribution minimale |
Clé de partition pertinente |
CQRS + read replicas |
Scalabilité asymétrique lectures/écritures |
Eventual consistency acceptable |
Autoscaling |
Coût proportionnel à l’usage |
Métriques fiables, cooldown configuré |
USL |
Prédire le plafond de scalabilité |
Mesurer α et β sur des benchmarks réels |
Règles pratiques :
Rendre les services stateless avant de scaler horizontalement — c’est non négociable.
Le consistent hashing minimise les redistributions lors des changements de topologie.
La loi de Gunther prédit la dégradation : mesurer α et β tôt pour connaître les limites avant de les atteindre.
L’autoscaling réactif seul ne suffit pas — anticiper les pics prévisibles avec du predictive scaling.
CQRS est un levier architectural puissant dès que les lectures sont 10× plus fréquentes que les écritures.