05 — Architecture monolithique#
Le monolithe n’est pas un gros mot#
Dans le vocabulaire courant de l’industrie, « monolithe » est souvent prononcé avec une nuance péjorative, comme si tout système déployé en une seule unité était nécessairement vieux, mal conçu et voué à l’échec. Cette réputation est injuste et, surtout, contre-productive pour les équipes qui cherchent à choisir une architecture adaptée à leur contexte.
Un monolithe est une application dont tous les composants fonctionnels sont déployés ensemble, au sein d’un même processus. Cette définition est neutre. Elle décrit une propriété de déploiement, pas un niveau de qualité.
Les forces réelles du monolithe#
Simplicité opérationnelle. Déployer une application, c’est déployer un artefact. Rollback signifie revenir à la version précédente de cet artefact. Il n’y a pas de choreographie entre dix services pour garantir la cohérence d’un déploiement.
Cohérence transactionnelle native. Dans un monolithe, une transaction de base de données peut englober plusieurs modules fonctionnels sans protocole distribué. Si une commande e-commerce crée une ligne dans orders, décrémente le stock dans inventory et génère une notification dans notifications, tout cela peut tenir dans une seule transaction ACID. L’atomicité est gratuite.
Appels de fonction, pas d’appels réseau. La communication entre composants est un appel de méthode en mémoire, avec une latence de quelques nanosecondes et une fiabilité de 100 % (pas de timeout réseau, pas de retry à gérer). Le débogage est trivial : une stack trace complète, un debugger qui traverse tous les modules.
Outillage mature. Les outils de profiling, de monitoring, de débogage sont tous conçus pour des processus uniques. Ils fonctionnent parfaitement sur un monolithe, sans adapter son infrastructure d’observabilité à des appels distribués.
Refactoring sans friction inter-services. Renommer une interface, déplacer une responsabilité, extraire un concept — dans un monolithe, le compilateur ou le linter valide tout cela en une passe. Pas besoin de versionner une API publique et de gérer des clients qui en dépendent.
Le « mauvais monolithe » n’est pas un argument contre le monolithe
Les critiques du monolithe décrivent souvent un monolithe non structuré : du code spaghetti où tout dépend de tout, sans modules clairs, sans séparation des responsabilités. Ce problème de structure est indépendant du choix de déploiement. Un microservice mal conçu souffre des mêmes maux, avec en prime la complexité distribuée.
Structuration en couches#
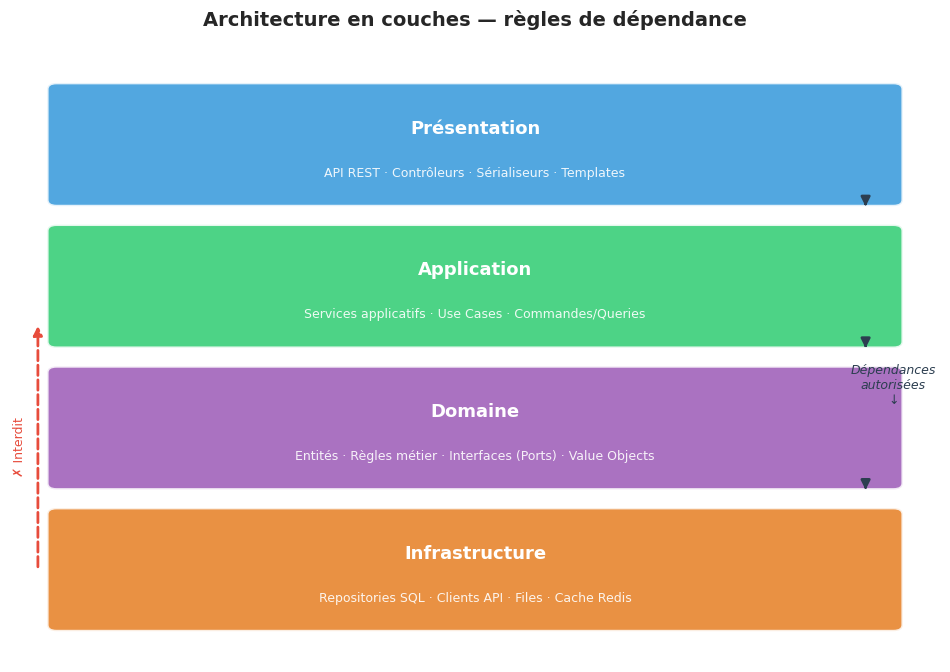
Un monolithe bien conçu n’est pas un bloc de code homogène. Il est organisé en couches (layers), chacune avec une responsabilité précise et des règles de dépendance strictes.
Le modèle classique de la Layered Architecture définit quatre couches :
Couche |
Responsabilité |
Exemples |
|---|---|---|
Présentation |
Interface utilisateur, API HTTP |
Contrôleurs Flask/Django, templates HTML, sérialiseurs REST |
Application |
Orchestration des cas d’usage |
Services applicatifs, use cases, commandes/queries |
Domaine |
Règles métier, entités |
|
Infrastructure |
Accès aux ressources externes |
Repositories BDD, clients API externes, envoi d’emails |
La règle fondamentale est simple : les dépendances ne vont que vers le bas (ou vers l’intérieur, selon la représentation). La couche domaine ne connaît pas la couche infrastructure. La couche application orchestre mais ne présente pas.
Structure Python d’un monolithe e-commerce#
# Arborescence d'un monolithe e-commerce structuré en couches
ecommerce/
├── presentation/
│ ├── api/
│ │ ├── orders.py # POST /orders, GET /orders/{id}
│ │ ├── products.py # GET /products, GET /products/{id}
│ │ └── customers.py
│ └── schemas/
│ ├── order_schema.py # Sérialisation/validation HTTP
│ └── product_schema.py
│
├── application/
│ ├── order_service.py # place_order(), cancel_order()
│ ├── inventory_service.py # reserve_stock(), release_stock()
│ └── notification_service.py
│
├── domain/
│ ├── order.py # class Order, OrderItem, OrderStatus
│ ├── product.py # class Product, Price, Stock
│ ├── customer.py # class Customer, Address
│ └── exceptions.py # InsufficientStockError, OrderNotFoundError
│
└── infrastructure/
├── repositories/
│ ├── order_repository.py # SQL via SQLAlchemy
│ └── product_repository.py
├── external/
│ ├── payment_gateway.py # Appel Stripe
│ └── email_client.py # Appel SendGrid
└── database.py # Session SQLAlchemy, migrations
# domain/order.py — La couche domaine ne connaît rien de la BDD ni du web
from dataclasses import dataclass, field
from enum import Enum
from datetime import datetime
from typing import List
class OrderStatus(Enum):
PENDING = "pending"
CONFIRMED = "confirmed"
SHIPPED = "shipped"
CANCELLED = "cancelled"
@dataclass
class OrderItem:
product_id: str
quantity: int
unit_price: float
@property
def subtotal(self) -> float:
return self.quantity * self.unit_price
@dataclass
class Order:
id: str
customer_id: str
items: List[OrderItem] = field(default_factory=list)
status: OrderStatus = OrderStatus.PENDING
created_at: datetime = field(default_factory=datetime.utcnow)
@property
def total(self) -> float:
return sum(item.subtotal for item in self.items)
def confirm(self) -> None:
if self.status != OrderStatus.PENDING:
raise ValueError(f"Impossible de confirmer une commande en état {self.status}")
self.status = OrderStatus.CONFIRMED
def cancel(self) -> None:
if self.status == OrderStatus.SHIPPED:
raise ValueError("Impossible d'annuler une commande expédiée")
self.status = OrderStatus.CANCELLED
# application/order_service.py — Orchestration du cas d'usage
class OrderService:
def __init__(self, order_repo, inventory_service, notification_service):
self.order_repo = order_repo
self.inventory = inventory_service
self.notifier = notification_service
def place_order(self, customer_id: str, items: list) -> Order:
# 1. Créer l'entité domaine
order = Order(id=generate_id(), customer_id=customer_id,
items=[OrderItem(**i) for i in items])
# 2. Vérifier et réserver le stock (même transaction)
for item in order.items:
self.inventory.reserve(item.product_id, item.quantity)
# 3. Confirmer et persister
order.confirm()
self.order_repo.save(order)
# 4. Notifier (peut échouer sans rollback de la commande)
self.notifier.send_confirmation(order)
return order
Couplage dans un monolithe#
La structuration en couches est une convention. Sans discipline, le couplage rampant détruit cette structure.
Les imports circulaires#
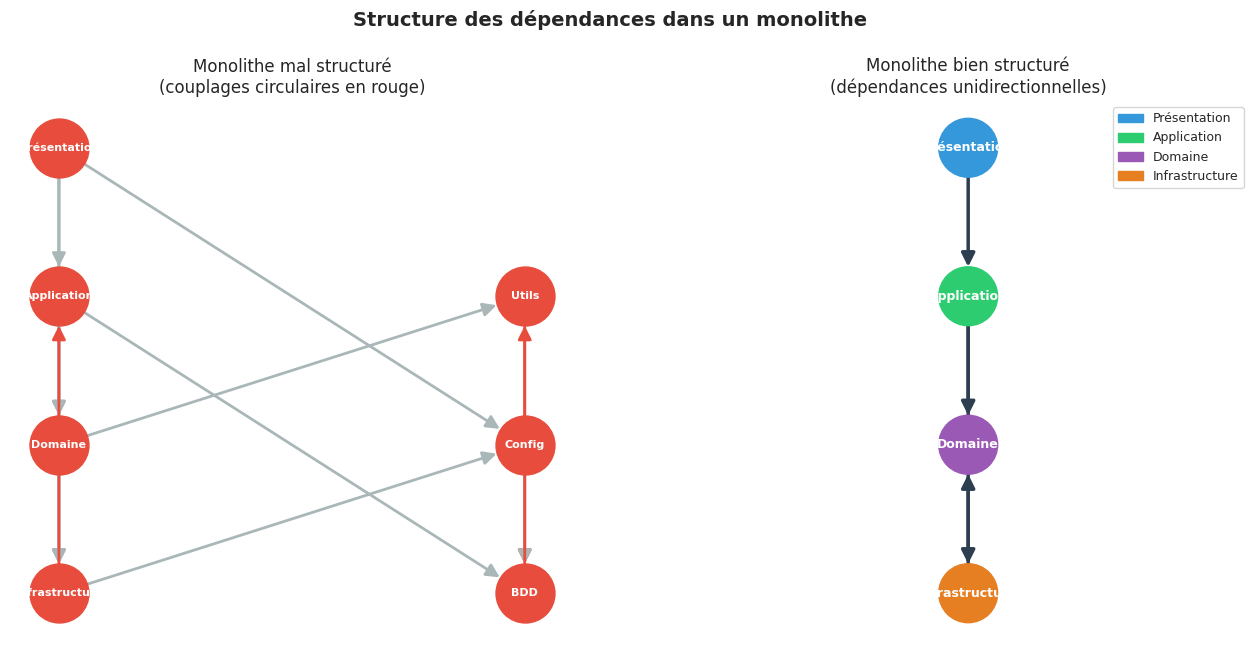
Le symptôme le plus visible d’un monolithe dégradé est le couplage circulaire : le module A importe B, qui importe C, qui importe A. Python lève une ImportError dans les cas évidents, mais les cycles indirects passent inaperçus et créent une base de code où aucun module ne peut être compris indépendamment.
# Couplage circulaire — à éviter absolument
# domain/order.py
from infrastructure.repositories import ProductRepository # INTERDIT : domaine → infra
# infrastructure/order_repository.py
from application.order_service import OrderService # INTERDIT : infra → application
Dépendances transverses#
Un autre anti-pattern fréquent : les God modules, des modules utilitaires importés par toutes les couches (logger, config, helpers), qui créent des couplages transitifs difficiles à démêler.
Stratégies de prévention#
Linting des dépendances : outils comme
import-linter(Python) permettent de définir des règles de contrats sur les imports autorisés entre modules.Dependency Inversion Principle : la couche application définit des interfaces (protocoles Python), l’infrastructure les implémente. La couche haute ne dépend jamais de la couche basse directement.
Revues de code focalisées sur les imports : un import vers une couche « interdite » doit déclencher un commentaire de revue systématique.
Monolithe modulaire#
Entre le monolithe non structuré et les microservices, il existe une option souvent sous-estimée : le monolithe modulaire.
L’idée est d’organiser le monolithe en modules à frontières explicites, chacun exposant une API interne publique bien définie, et masquant ses détails d’implémentation. Deux modules ne s’appellent jamais directement dans leurs entrailles ; ils passent par l’interface publique de l’autre.
Module avec interface publique explicite#
# Module "orders" — seul ce qui est dans __init__.py est public
orders/
├── __init__.py # API publique : place_order, get_order, cancel_order
├── _domain.py # Privé : Order, OrderItem (underscore = interne)
├── _repository.py # Privé : OrderRepository
├── _service.py # Privé : OrderService
└── _schemas.py # Privé : sérialisation
# orders/__init__.py
from ._service import OrderService as _svc
def place_order(customer_id: str, items: list) -> dict:
"""Point d'entrée public du module orders."""
return _svc().place_order(customer_id, items)
def get_order(order_id: str) -> dict:
return _svc().get_order(order_id)
def cancel_order(order_id: str) -> None:
_svc().cancel_order(order_id)
# Le module inventory appelle orders via son interface publique
# inventory/_service.py
import orders # API publique seulement — JAMAIS orders._domain ou orders._repository
class InventoryService:
def process_shipped_order(self, order_id: str) -> None:
order = orders.get_order(order_id) # Via l'interface publique
self._update_stock(order)
Feature flags pour le déploiement progressif#
Les feature flags permettent d’activer ou désactiver des modules entiers sans redéploiement, ce qui donne une flexibilité proche des microservices tout en gardant la simplicité du monolithe.
Le monolithe modulaire comme étape intermédiaire
Si votre équipe envisage de migrer vers les microservices, commencer par un monolithe modulaire bien structuré est souvent la meilleure stratégie. Les modules à frontières nettes deviennent naturellement les candidats à l’extraction en services indépendants. Vous découpez du code bien compris, pas du spaghetti.
Déploiement et scaling d’un monolithe#
Processus unique, scaling horizontal#
Un monolithe se déploie comme un processus unique (ou plusieurs instances du même processus). Le scaling horizontal consiste à lancer plusieurs instances derrière un load balancer. Cette approche fonctionne très bien pour la plupart des charges de travail.
Internet → Load Balancer
├── Instance 1 (monolithe) → Base de données partagée
├── Instance 2 (monolithe) →
└── Instance 3 (monolithe) →
Sessions sticky et état partagé#
Le seul vrai défi du scaling horizontal d’un monolithe est la gestion de l”état partagé. Si les sessions utilisateur sont stockées en mémoire d’une instance, les requêtes suivantes doivent aller vers la même instance (session sticky, ou sticky sessions).
La solution propre : stocker les sessions dans un store partagé (Redis, base de données), ce qui rend le monolithe stateless et permet un load balancing libre.
Granularité du scaling#
Le scaling horizontal d’un monolithe scale toutes les fonctionnalités ensemble. Si seule la fonctionnalité de recherche est sous forte charge, on scale quand même le module de facturation. C’est un vrai désavantage — mais il faut relativiser : le coût d’une sur-allocation de ressources est souvent bien inférieur à la complexité opérationnelle des microservices.
Quand le monolithe souffre#
Un monolithe bien structuré peut servir des millions d’utilisateurs. Mais certains symptômes signalent qu’il approche de ses limites.
Symptômes organisationnels#
Peur du déploiement. Quand l’équipe hésite à déployer parce que « on ne sait jamais ce que ça va casser », c’est un signe d’un couplage excessif et d’une couverture de tests insuffisante — pas nécessairement un argument pour les microservices.
Équipes bloquées. Quand cinq équipes travaillent sur le même dépôt et se marchent dessus (conflits de merge constants, casse des tests des uns par les autres), la monorepo atteint ses limites organisationnelles.
Temps de build et de test prohibitifs. Si le pipeline CI prend 45 minutes pour valider un changement d’une ligne, la productivité s’effondre.
Symptômes techniques#
Impossibilité de déployer des composants indépendamment. Si l’équipe de recommandation veut déployer 10 fois par jour mais est bloquée par le cycle de release global de la semaine, le modèle de déploiement monolithique crée une friction réelle.
Besoins technologiques divergents. Le moteur de machine learning a besoin de Python avec des librairies spécifiques, le service de traitement temps réel veut du Go ou du Rust. Dans un monolithe, tout doit cohabiter dans le même runtime.
Base de données saturée. Le monolithe partage une seule base de données. Quand les besoins de performance des différentes fonctionnalités divergent (lecture intensive vs écriture intensive vs analytique), une seule BDD devient un goulot d’étranglement difficile à résoudre sans découpage.
Le bon diagnostic avant la chirurgie
Avant de décider de « microserviciser » un monolithe qui souffre, diagnostiquez précisément le problème. La plupart des symptômes ci-dessus ont des solutions qui ne nécessitent pas de distribuer l’application : améliorer les tests, structurer le code en modules, optimiser la base de données, adopter une meilleure organisation d’équipes.
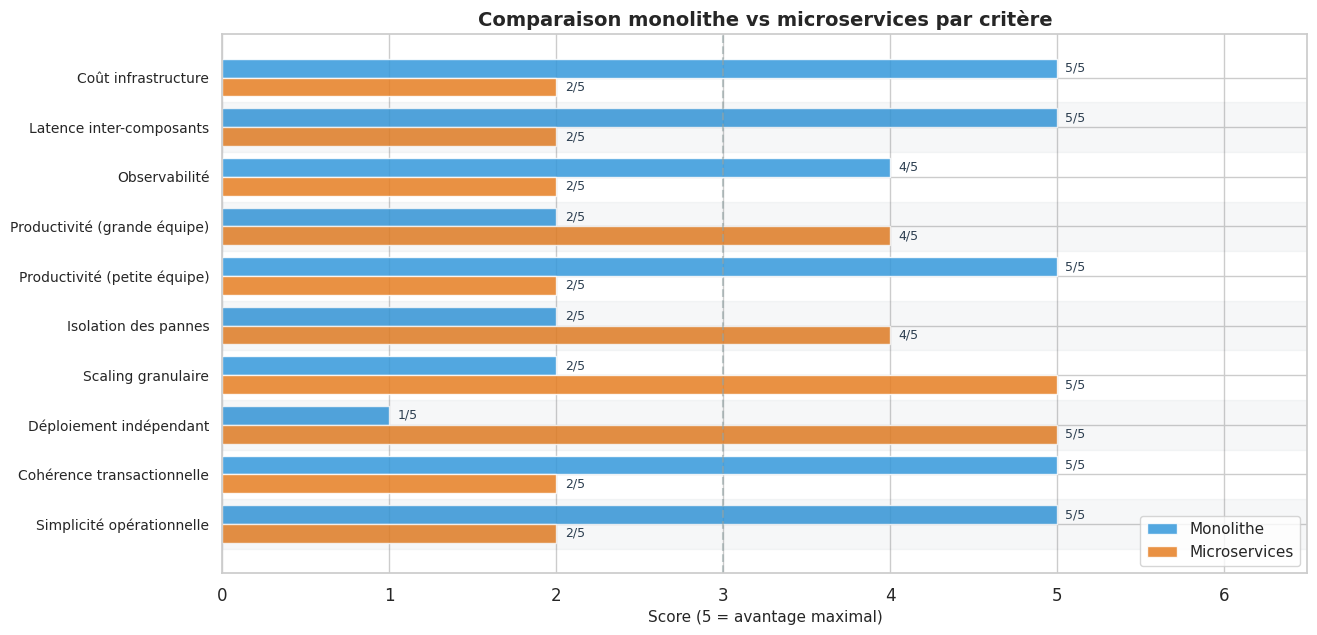
Monolithe vs microservices — faux dilemme, vrai spectre#
Le débat monolithe vs microservices est souvent présenté comme un choix binaire. Ce n’est pas le cas. Il existe un spectre continu d’options architecturales.
Option |
Description |
Cas d’usage |
|---|---|---|
Monolithe non structuré |
Tout dans tout, pas de séparation |
Prototypes jetables |
Monolithe structuré en couches |
Séparation couches, cohérence déploiement |
PME, startups en croissance |
Monolithe modulaire |
Modules à frontières nettes, même déploiement |
Grandes équipes, avant migration |
Macro-services |
3-10 services, granularité large |
Domains bien identifiés |
Microservices |
Des dizaines à centaines de services |
Scale organisationnel élevé |
Serverless |
Fonctions, facturation à l’usage |
Charges variables, event-driven |
La loi de Conway n’est pas neutre
« Les organisations conçoivent des systèmes qui copient leurs structures de communication. » (Melvin Conway, 1967). Si vous avez 3 développeurs, une architecture microservices est une charge opérationnelle disproportionnée. Si vous avez 500 développeurs en 40 équipes, un monolithe est un goulot organisationnel. L’architecture suit la taille et la structure de l’organisation.
Visualisations#
Graphe de dépendances : monolithe bien structuré vs mal structuré#
import networkx as nx
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# --- Monolithe mal structuré (couplage circulaire) ---
G_bad = nx.DiGraph()
nodes_bad = ["Présentation", "Application", "Domaine", "Infrastructure",
"Utils", "Config", "BDD"]
G_bad.add_nodes_from(nodes_bad)
# Dépendances chaotiques (circulaires, transverses)
bad_edges = [
("Présentation", "Application"), ("Présentation", "Domaine"),
("Présentation", "Infrastructure"), ("Application", "Domaine"),
("Application", "Infrastructure"), ("Domaine", "Infrastructure"),
("Domaine", "Utils"), ("Infrastructure", "Application"), # cycle!
("Utils", "BDD"), ("Config", "BDD"), ("BDD", "Utils"), # cycle!
("Présentation", "Config"), ("Infrastructure", "Config"),
("Application", "BDD"),
]
G_bad.add_edges_from(bad_edges)
pos_bad = {
"Présentation": (0, 3), "Application": (0, 2), "Domaine": (0, 1),
"Infrastructure": (0, 0), "Utils": (2, 2), "Config": (2, 1), "BDD": (2, 0)
}
edge_colors_bad = []
cycle_edges = {("Infrastructure", "Application"), ("BDD", "Utils"), ("Utils", "BDD")}
for e in G_bad.edges():
edge_colors_bad.append("#e74c3c" if e in cycle_edges else "#aab7b8")
nx.draw_networkx(G_bad, pos_bad, ax=axes[0],
node_color="#e74c3c", node_size=1800,
font_size=8, font_color="white", font_weight="bold",
edge_color=edge_colors_bad, width=2,
arrows=True, arrowsize=20)
axes[0].set_title("Monolithe mal structuré\n(couplages circulaires en rouge)", fontsize=12)
axes[0].axis("off")
# --- Monolithe bien structuré (dépendances unidirectionnelles) ---
G_good = nx.DiGraph()
layers = {
"Présentation": (1, 3),
"Application": (1, 2),
"Domaine": (1, 1),
"Infrastructure": (1, 0),
}
G_good.add_nodes_from(layers.keys())
good_edges = [
("Présentation", "Application"),
("Application", "Domaine"),
("Infrastructure", "Domaine"), # Infrastructure dépend du domaine (ports)
("Application", "Infrastructure"), # via interface/port
]
G_good.add_edges_from(good_edges)
layer_colors = {
"Présentation": "#3498db",
"Application": "#2ecc71",
"Domaine": "#9b59b6",
"Infrastructure": "#e67e22",
}
node_colors_good = [layer_colors[n] for n in G_good.nodes()]
nx.draw_networkx(G_good, layers, ax=axes[1],
node_color=node_colors_good, node_size=1800,
font_size=9, font_color="white", font_weight="bold",
edge_color="#2c3e50", width=2.5,
arrows=True, arrowsize=20)
legend_patches = [mpatches.Patch(color=c, label=n) for n, c in layer_colors.items()]
axes[1].legend(handles=legend_patches, loc="upper right", fontsize=9)
axes[1].set_title("Monolithe bien structuré\n(dépendances unidirectionnelles)", fontsize=12)
axes[1].axis("off")
plt.suptitle("Structure des dépendances dans un monolithe", fontsize=14, fontweight="bold", y=1.01)
plt.savefig("_static/05_dependances_monolithe.png", dpi=150, bbox_inches="tight")
plt.show()
Simulation du temps de build selon le couplage#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Axe 1 : temps de build vs nombre de modules couplés
modules = np.arange(5, 55, 5)
# Monolithe bien structuré : build incrémental possible (quasi-linéaire)
build_structuré = 2 + 0.8 * modules
# Monolithe mal couplé : toute modification rebâtit tout (exponentiel)
build_couplé = 2 * np.exp(0.07 * modules)
axes[0].plot(modules, build_structuré, "o-", color="#2ecc71", linewidth=2.5,
markersize=7, label="Monolithe modulaire")
axes[0].plot(modules, build_couplé, "s-", color="#e74c3c", linewidth=2.5,
markersize=7, label="Monolithe non structuré")
axes[0].set_xlabel("Nombre de modules", fontsize=11)
axes[0].set_ylabel("Temps de build (minutes)", fontsize=11)
axes[0].set_title("Temps de build selon la structure", fontsize=12)
axes[0].legend(fontsize=10)
axes[0].set_xlim(5, 50)
axes[0].set_ylim(0, 80)
# Axe 2 : impact d'un changement — modules affectés selon le couplage
couplage = np.linspace(0, 1, 50)
modules_affectés_haut = 30 * couplage ** 0.5
modules_affectés_bas = 3 + 5 * couplage
zones_y = np.linspace(0, 30, 100)
axes[1].fill_betweenx(zones_y, 0, 0.3, alpha=0.08, color="#2ecc71", label="Zone saine")
axes[1].fill_betweenx(zones_y, 0.7, 1.0, alpha=0.08, color="#e74c3c", label="Zone dangereuse")
axes[1].plot(couplage, modules_affectés_haut, "-", color="#e74c3c", linewidth=2.5,
label="Couplage fort")
axes[1].plot(couplage, modules_affectés_bas, "-", color="#2ecc71", linewidth=2.5,
label="Couplage faible")
axes[1].set_xlabel("Degré de couplage (0 = indépendant, 1 = tout couplé)", fontsize=11)
axes[1].set_ylabel("Modules affectés par un changement", fontsize=11)
axes[1].set_title("Propagation d'un changement selon le couplage", fontsize=12)
axes[1].legend(fontsize=10)
plt.suptitle("Impact du couplage sur la maintenabilité", fontsize=14, fontweight="bold")
plt.savefig("_static/05_couplage_build.png", dpi=150, bbox_inches="tight")
plt.show()
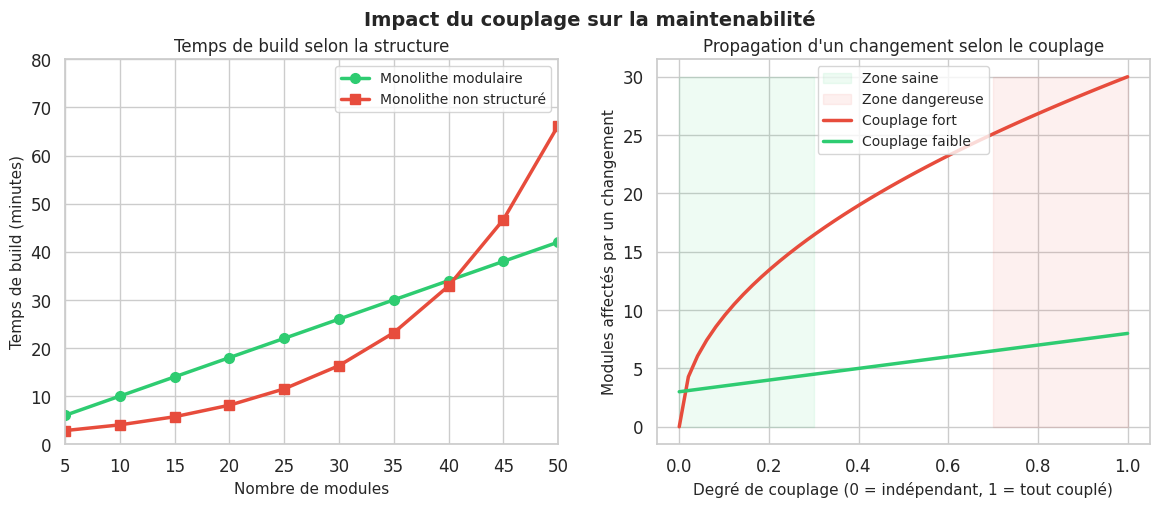
Diagramme en couches annoté#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(12, 8))
ax.set_xlim(0, 10)
ax.set_ylim(0, 10)
layers_data = [
{"y": 7.5, "h": 1.8, "color": "#3498db", "label": "Présentation",
"sublabel": "API REST · Contrôleurs · Sérialiseurs · Templates"},
{"y": 5.2, "h": 1.8, "color": "#2ecc71", "label": "Application",
"sublabel": "Services applicatifs · Use Cases · Commandes/Queries"},
{"y": 2.9, "h": 1.8, "color": "#9b59b6", "label": "Domaine",
"sublabel": "Entités · Règles métier · Interfaces (Ports) · Value Objects"},
{"y": 0.6, "h": 1.8, "color": "#e67e22", "label": "Infrastructure",
"sublabel": "Repositories SQL · Clients API · Files · Cache Redis"},
]
for layer in layers_data:
rect = mpatches.FancyBboxPatch(
(0.5, layer["y"]), 9, layer["h"],
boxstyle="round,pad=0.1",
linewidth=2, edgecolor="white",
facecolor=layer["color"], alpha=0.85
)
ax.add_patch(rect)
ax.text(5, layer["y"] + layer["h"] * 0.65, layer["label"],
ha="center", va="center", fontsize=13, fontweight="bold", color="white")
ax.text(5, layer["y"] + layer["h"] * 0.25, layer["sublabel"],
ha="center", va="center", fontsize=9, color="white", alpha=0.9)
# Flèches de dépendance (sens autorisé : haut → bas)
arrow_props = dict(arrowstyle="-|>", color="#2c3e50", lw=2)
for y_start in [7.5, 5.2, 2.9]:
ax.annotate("", xy=(9.2, y_start - 0.15), xytext=(9.2, y_start),
arrowprops=arrow_props)
ax.text(9.5, 4.5, "Dépendances\nautorisées\n↓", ha="center", va="center",
fontsize=9, color="#2c3e50", fontstyle="italic")
# Flèche interdite (remontant)
ax.annotate("", xy=(0.3, 5.5), xytext=(0.3, 1.5),
arrowprops=dict(arrowstyle="-|>", color="#e74c3c", lw=2, linestyle="dashed"))
ax.text(0.1, 3.5, "✗ Interdit", ha="center", va="center", fontsize=9,
color="#e74c3c", rotation=90)
ax.set_title("Architecture en couches — règles de dépendance", fontsize=14, fontweight="bold", pad=15)
ax.axis("off")
plt.savefig("_static/05_couches_annotees.png", dpi=150, bbox_inches="tight")
plt.show()
Comparaison monolithe vs microservices#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
critères = [
"Simplicité opérationnelle",
"Cohérence transactionnelle",
"Déploiement indépendant",
"Scaling granulaire",
"Isolation des pannes",
"Productivité (petite équipe)",
"Productivité (grande équipe)",
"Observabilité",
"Latence inter-composants",
"Coût infrastructure",
]
# Score sur 5 (5 = avantage maximal pour ce style)
scores_monolithe = [5, 5, 1, 2, 2, 5, 2, 4, 5, 5]
scores_micro = [2, 2, 5, 5, 4, 2, 4, 2, 2, 2]
x = np.arange(len(critères))
width = 0.38
fig, ax = plt.subplots(figsize=(14, 7))
bars1 = ax.barh(x + width/2, scores_monolithe, width, label="Monolithe",
color="#3498db", alpha=0.85)
bars2 = ax.barh(x - width/2, scores_micro, width, label="Microservices",
color="#e67e22", alpha=0.85)
# Annotations
for bar in bars1:
ax.text(bar.get_width() + 0.05, bar.get_y() + bar.get_height()/2,
f"{int(bar.get_width())}/5", va="center", ha="left", fontsize=9, color="#2c3e50")
for bar in bars2:
ax.text(bar.get_width() + 0.05, bar.get_y() + bar.get_height()/2,
f"{int(bar.get_width())}/5", va="center", ha="left", fontsize=9, color="#2c3e50")
ax.set_yticks(x)
ax.set_yticklabels(critères, fontsize=10)
ax.set_xlabel("Score (5 = avantage maximal)", fontsize=11)
ax.set_xlim(0, 6.5)
ax.set_title("Comparaison monolithe vs microservices par critère", fontsize=14, fontweight="bold")
ax.legend(fontsize=11, loc="lower right")
ax.axvline(x=3, color="#95a5a6", linestyle="--", alpha=0.6, label="Seuil neutre")
for i in range(len(critères)):
if i % 2 == 0:
ax.axhspan(i - 0.5, i + 0.5, alpha=0.04, color="#2c3e50")
plt.savefig("_static/05_comparaison_monolithe_micro.png", dpi=150, bbox_inches="tight")
plt.show()
Résumé#
Le monolithe est un style architectural légitime, productif et souvent optimal pour la majorité des projets et des équipes. Sa mauvaise réputation vient d’une confusion entre « monolithe » (propriété de déploiement) et « code non structuré » (propriété de qualité).
Points clés à retenir :
Un monolithe bien structuré en couches offre simplicité opérationnelle, cohérence transactionnelle et déploiement atomique que les architectures distribuées ne peuvent égaler sans complexité supplémentaire.
La règle de dépendance entre couches (présentation → application → domaine ← infrastructure) est la discipline fondamentale à maintenir. Les imports circulaires sont le signe d’une dégradation.
Le monolithe modulaire — modules à interfaces publiques explicites déployés ensemble — est souvent le meilleur compromis entre la rigueur du monolithe et la flexibilité des microservices. C’est aussi une excellente étape de transition.
Le scaling horizontal d’un monolithe fonctionne très bien pour la plupart des charges ; la granularité fine du scaling des microservices ne justifie son coût qu’au-delà d’un certain seuil de charge et d’organisation.
Les symptômes qui signalent les limites du monolithe (temps de build, peur du déploiement, équipes bloquées) sont des signaux organisationnels autant que techniques. Diagnostiquer précisément avant de migrer.
Le choix monolithe vs microservices est un spectre, pas une décision binaire. La loi de Conway suggère d’aligner l’architecture sur la structure de l’organisation, pas l’inverse.
Principe de Martin Fowler
« Ne commencez pas avec les microservices. Commencez avec un monolithe bien conçu, identifiez les frontières réelles de votre domaine, puis extrayez des services seulement quand vous avez une raison concrète de le faire. » — Martin Fowler, Microservices (2014)