Chapitre 3 — Pensée systèmes#
L’architecture logicielle ne se pratique pas en assemblant des composants isolés. Elle consiste à raisonner sur des systèmes — des ensembles d’éléments en interaction, dont le comportement collectif ne peut pas être déduit de l’examen des parties prises séparément. Ce chapitre introduit les outils conceptuels et mathématiques qui permettent de raisonner rigoureusement sur la complexité des systèmes distribués.
Complexité accidentelle vs complexité essentielle#
Fred Brooks a introduit cette distinction dans son essai fondateur « No Silver Bullet » (1986). Elle reste l’une des analyses les plus pertinentes de la discipline, quarante ans après.
La complexité essentielle est inhérente au problème à résoudre. Elle ne peut pas être éliminée sans changer la nature du problème. Un système de trading haute fréquence est essentiellement complexe : la concurrence, la gestion des ordres partiels, les règles de matching — ces complexités reflètent la réalité du domaine financier. On ne peut pas les supprimer par de meilleures technologies.
La complexité accidentelle est introduite par les outils, les langages, les processus et les choix architecturaux. Elle est la complexité que les développeurs s’infligent à eux-mêmes. Brooks arguait que l’essentiel des gains de productivité réalisables viendrait de la réduction de la complexité accidentelle — ce qui explique l’impact des langages de haut niveau, des environnements intégrés, et de la virtualisation.
Dans les systèmes modernes, les sources de complexité accidentelle sont bien documentées :
Configuration : des dizaines de fichiers de configuration, des variables d’environnement non documentées, des secrets dispersés dans différents systèmes. La complexité de configuration d’une application cloud-native dépasse souvent celle du code applicatif lui-même.
Cohérence distribuée : quand les données sont répliquées entre plusieurs nœuds pour des raisons de disponibilité ou de performance, les développeurs doivent raisonner sur des états partiellement cohérents. Cette complexité est accidentelle dans le sens où elle est introduite par les choix architecturaux de distribution.
Orchestration des services : dans une architecture microservices, la coordination entre services (sagas, orchestration, chorégraphie) introduit une complexité qui n’existe pas dans un monolithe. Cette complexité est un trade-off délibéré, pas une nécessité absolue.
Observabilité insuffisante : un système dont le comportement interne n’est pas observable force ses opérateurs à raisonner sur un système partiellement opaque. La complexité de débogage qui en résulte est accidentelle.
L’objectif de l’architecte
Un bon architecte maximise sa compréhension de la complexité essentielle et minimise la complexité accidentelle introduite. Toute complexité accidentelle doit se justifier par un bénéfice concret et mesurable. « C’est la façon moderne de faire » n’est pas une justification.
Loi de Conway — exemples réels et inverse Conway maneuver#
La loi de Conway (1967) : « Les organisations qui conçoivent des systèmes sont contraintes de produire des designs qui sont des copies de leur structure de communication. »
Cette loi n’est pas une observation cynique — c’est un mécanisme causal. Les équipes qui ne se parlent pas produisent des interfaces bien définies entre leurs systèmes (pour réduire la coordination nécessaire). Les équipes qui collaborent étroitement produisent des systèmes fortement couplés. Le schéma de communication détermine le schéma d’interface.
Exemples réels :
Amazon, à ses débuts, avait des équipes organisées par couches techniques (frontend, backend, base de données). L’architecture reflétait cette organisation : une application monolithique à trois couches. Quand Amazon a réorganisé ses équipes en « two-pizza teams » autonomes autour de capacités métier, l’architecture microservices est devenue naturelle. La décision architecturale et la décision organisationnelle sont indissociables.
Netflix a documenté ce phénomène dans ses retours d’expérience : la migration vers les microservices et la réorganisation des équipes ont avancé en parallèle et de façon codépendante.
Dans les grandes banques, les systèmes legacy reflètent souvent la structure organisationnelle des années 1980-1990 : une application par département (trading, settlement, risk), avec des interfaces batch entre elles.
L’inverse Conway maneuver consiste à inverser délibérément la relation causale. Plutôt que de laisser l’organisation dicter l’architecture, on conçoit d’abord l’architecture souhaitée, puis on organise les équipes de façon à ce que leur structure de communication produise naturellement cette architecture.
Les Team Topologies (Skelton & Pais, 2019) formalisent ce concept avec quatre types d’équipes :
Stream-aligned teams : alignées sur un flux de valeur métier, propriétaires d’un ou plusieurs services
Enabling teams : facilitent l’adoption de nouvelles pratiques ou technologies
Complicated-subsystem teams : propriétaires d’un composant spécialisé à haute complexité cognitive
Platform teams : fournissent une plateforme interne qui réduit la charge cognitive des stream-aligned teams
Et trois modes d’interaction :
Collaboration : deux équipes travaillent ensemble pendant une période limitée
X-as-a-Service : une équipe consomme les services d’une autre via une interface bien définie
Facilitating : une équipe aide une autre à acquérir de nouvelles capacités
Conway dans la pratique
Avant de proposer une refonte architecturale, posez la question : est-ce que l’organisation actuelle peut maintenir et faire évoluer cette architecture ? Une architecture microservices maintenue par une seule équipe de trois personnes introduit de la complexité accidentelle sans bénéfice réel.
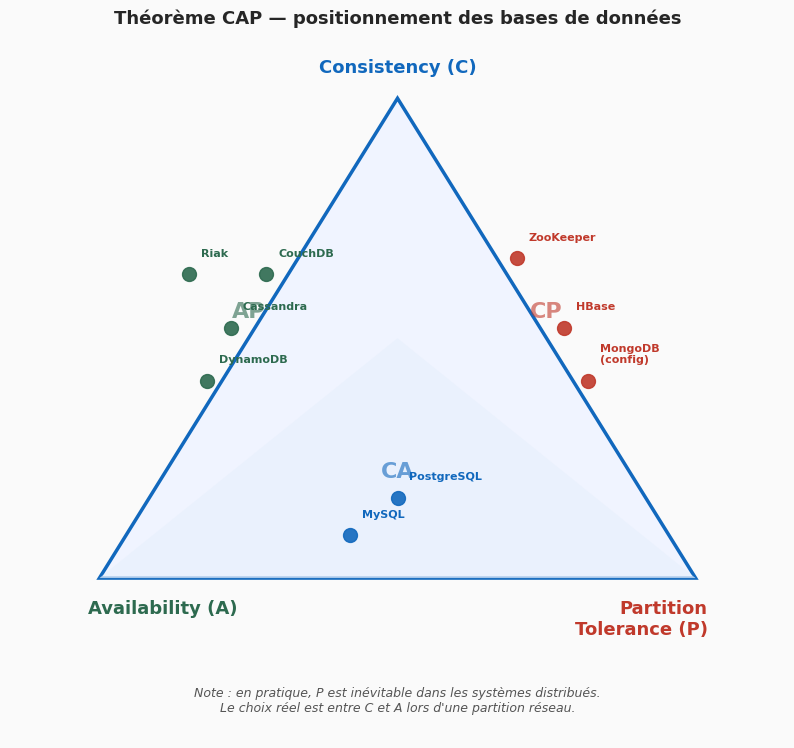
Théorème CAP — consistency, availability, partition tolerance#
Le théorème CAP, formulé par Eric Brewer en 2000 et prouvé formellement par Gilbert et Lynch en 2002, établit qu’un système distribué ne peut garantir simultanément que deux des trois propriétés suivantes :
Consistency (C) : tous les nœuds voient les mêmes données au même moment. Après une écriture, toute lecture retourne la valeur la plus récente.
Availability (A) : le système répond à toute requête, même en cas de défaillance de nœuds. Chaque requête reçoit une réponse (pas nécessairement la plus récente).
Partition tolerance (P) : le système continue à fonctionner malgré la perte de messages entre nœuds (partition réseau). Cette propriété est inévitable dans tout système distribué sur un réseau non fiable.
La conséquence pratique est directe : puisque les partitions réseau sont inévitables dans les systèmes distribués (câbles qui se coupent, nœuds qui redémarrent, datacenter inaccessible), le choix réel est entre C et A lors d’une partition.
Systèmes CP : préfèrent la cohérence à la disponibilité lors d’une partition. Si un nœud ne peut pas garantir une réponse cohérente, il rejette la requête. Exemples : HBase, MongoDB (en mode « majority read concern »), Zookeeper. Cas d’usage typique : coordination distribuée, stockage de configuration.
Systèmes AP : préfèrent la disponibilité à la cohérence lors d’une partition. Les nœuds continuent à répondre avec potentiellement des données périmées. La cohérence est éventuellement rétablie (eventual consistency). Exemples : Cassandra, DynamoDB, CouchDB. Cas d’usage typique : paniers e-commerce, compteurs de vues, profils utilisateur.
Systèmes CA : garantissent cohérence et disponibilité en l’absence de partition. En pratique, tout système distribué sur un réseau non fiable doit tolérer les partitions, donc les systèmes CA sont des bases de données relationnelles traditionnelles fonctionnant sur un seul nœud ou dans un réseau fiable contrôlé. Exemples : PostgreSQL standalone, MySQL standalone.
Au-delà de CAP : PACELC
Le modèle PACELC (Daniel Abadi, 2012) affine CAP en ajoutant le compromis latence/cohérence même en l’absence de partition. Un système peut être CP en cas de partition, mais toujours choisir entre latence faible (réponse sans consensus) et cohérence forte (consensus synchrone) en fonctionnement normal. DynamoDB est PA/EL : disponible en cas de partition, faible latence en fonctionnement normal.
Loi d’Amdahl — limites du parallélisme#
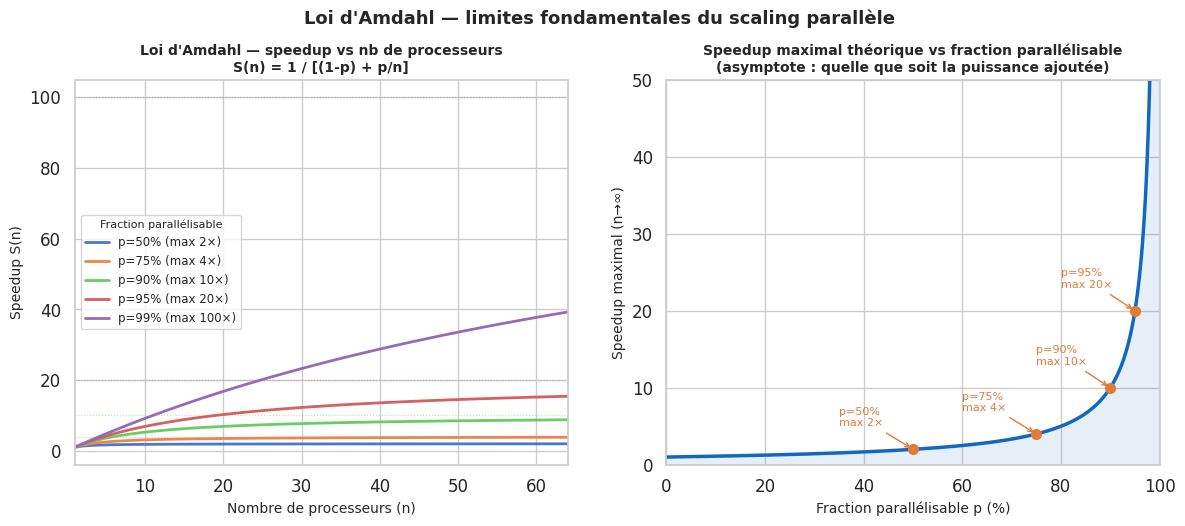
La loi d’Amdahl (1967) quantifie le gain maximal atteignable en parallélisant une fraction d’un programme. Elle est une démonstration mathématique des limites fondamentales du scaling.
Soit p la fraction du programme qui peut être parallélisée (0 ≤ p ≤ 1). Le speedup maximal avec n processeurs est :
Quand n → ∞ (nombre infini de processeurs), le speedup tend vers 1 / (1-p). Si 20% du programme est séquentiel (p = 0.8), le speedup maximal est 5×, quelle que soit la puissance de calcul ajoutée.
La loi d’Amdahl s’applique directement aux architectures distribuées :
La fraction séquentielle inclut tout ce qui ne peut pas être distribué : le consensus distribué (Paxos, Raft), les transactions globales, les opérations qui nécessitent un état global cohérent.
Un système dont 10% des opérations nécessitent une coordination globale ne peut pas scaler au-delà de 10×, peu importe le nombre de nœuds ajoutés.
Le goulot d’étranglement est souvent subtil : un service de log centralisé, une base de données de session partagée, un seul nœud de coordination dans un cluster.
La loi de Gustafson (1988) nuance Amdahl en observant que pour les problèmes parallèles, la taille du problème augmente généralement avec le nombre de processeurs. Si on maintient le temps de calcul constant en augmentant la taille du problème avec le nombre de processeurs, le speedup est : S(n) = n - (1-p)(n-1). Gustafson s’applique aux simulations scientifiques et au Big Data ; Amdahl s’applique aux contraintes de latence des systèmes transactionnels.
Loi de Little revisitée — queues et saturation#
La loi de Little (N = λ × W), abordée au chapitre 2 en termes de dimensionnement, prend une dimension plus riche quand on l’applique aux architectures de systèmes réels.
Application aux microservices : chaque service est une file d’attente. Si un service de paiement traite 50 requêtes par seconde et que le temps de traitement moyen est de 100ms, il y a en permanence 5 requêtes en cours de traitement. Si la charge monte à 100 req/s et que le temps de traitement monte à 300ms (à cause de la contention sur la base de données), il y a maintenant 30 requêtes en vol — le pool de threads est saturé.
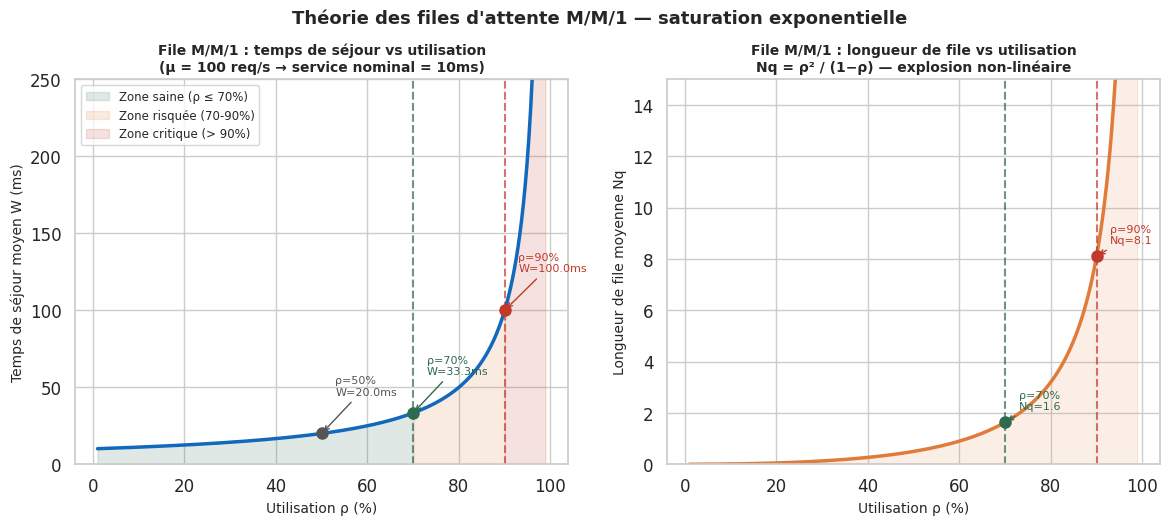
La saturation survient quand l’utilisation ρ approche 1. Dans ce régime, les temps de réponse explosent de façon non linéaire (cf. file M/M/1). Un service à 95% d’utilisation n’a quasiment plus de marge pour absorber les pics.
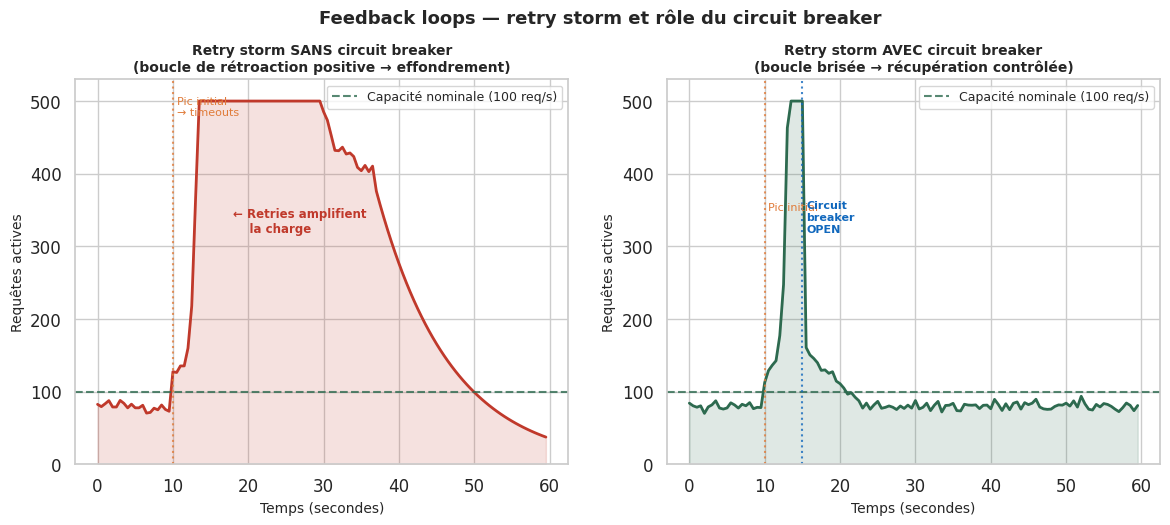
Circuit breaker et back-pressure : les systèmes bien conçus ne laissent pas la saturation se propager. Le pattern Circuit Breaker détecte la saturation d’un service aval et arrête d’envoyer des requêtes avant d’atteindre le timeout. La back-pressure (rétrécissement) signale aux clients de ralentir leur rythme d’envoi quand la capacité est atteinte. Ces patterns transforment une cascade de défaillances en dégradation contrôlée.
La règle des 70%
En pratique, les architectes dimensionnent les systèmes pour fonctionner à 70% d’utilisation maximale. Cette marge de 30% absorbe les pics, les requêtes de retry, et les opérations en arrière-plan. Un système continuellement à 90% est une bombe à retardement.
Feedback loops — boucles positives, négatives et défaillances en cascade#
La théorie des systèmes distingue deux types de boucles de rétroaction. Comprendre leur rôle dans les systèmes distribués permet d’anticiper des comportements émergents souvent surprenants.
Les boucles négatives sont stabilisantes. Elles ramènent le système vers un état d’équilibre. Le thermostat est l’exemple classique : la température monte → le système de refroidissement s’active → la température descend. Dans un cluster Kubernetes, le controller replanifie un pod tombé (boucle de réconciliation) — c’est une boucle négative. Les systèmes stables sont dominés par des boucles négatives.
Les boucles positives sont amplificatrices. Elles amplifient un état initial, qu’il soit favorable ou défavorable. Le « cache warming » illustre la version favorable : un cache froid génère de nombreux cache misses qui alimentent la base de données → la base de données se réchauffe le cache → le taux de hit augmente → la charge sur la base diminue → les performances s’améliorent. Cette boucle s’auto-renforce jusqu’à l’équilibre.
La retry storm illustre la version catastrophique. Un service devient lent sous charge → les clients atteignent leur timeout et retentent → le nombre de requêtes actives double → le service se dégrade encore plus → encore plus de timeouts et de retries → effondrement total. La boucle positive amplifie la dégradation initiale jusqu’à la saturation complète.
Les cascading failures (défaillances en cascade) combinent plusieurs mécanismes. Dans une architecture microservices, si le service A appelle B qui appelle C, et que C sature, alors B accumule des threads bloqués en attente de C, puis A accumule des threads bloqués en attente de B. La défaillance de C se propage vers A, qui peut à son tour surcharger ses clients.
Les contre-mesures architecturales incluent :
Timeout courts avec retry exponentiel et jitter (délai aléatoire pour éviter les pics synchronisés)
Circuit breaker (Hystrix, Resilience4j) : coupe les appels vers un service dégradé
Bulkhead : isolation des pools de threads par service appelé, pour éviter qu’un service lent épuise les ressources partagées
Rate limiting côté serveur : rejette explicitement les requêtes au-delà d’un seuil
Propriétés émergentes#
Les propriétés émergentes sont des comportements du système que les composants individuels n’ont pas. Elles sont le cœur de la pensée systèmes.
Un neurone individuel n’a pas de conscience. Pourtant, leur interaction dans un réseau neural produit la cognition. Une fourmi individuelle ne planifie pas la construction d’une fourmilière. Pourtant, la colonie produit des structures d’une complexité architecturale remarquable.
Dans les systèmes distribués, les propriétés émergentes sont souvent découvertes à la mise en production, parfois douloureusement.
La cohérence éventuelle est une propriété émergente des systèmes AP. Aucun nœud individuel ne garantit la cohérence — chaque nœud répond localement. Pourtant, à travers des protocoles de propagation (gossip, anti-entropy), le système converge vers un état cohérent. Le délai de convergence dépend des paramètres du réseau et du trafic, pas d’une horloge centrale.
Le thundering herd (troupeau tonnerreux) est une propriété émergente défavorable. Quand un cache expire ou qu’un service redémarre, de nombreux clients envoient simultanément la même requête. Chacun agit rationnellement, mais l’effet collectif est une avalanche de requêtes identiques. Les solutions incluent le cache stampede protection (mutex sur la reconstruction du cache) et le TTL jitter (expiration aléatoire plutôt que synchronisée).
La latence de queue des microservices : dans une chaîne de 10 services avec chacun un p99 de 50ms, le p99 de bout en bout n’est pas 500ms mais peut atteindre plusieurs secondes. Les queues de latence se composent de façon non triviale : si chaque service est au p99 indépendamment, la probabilité que tous soient au p99 simultanément est faible, mais la distribution de latence totale a une queue beaucoup plus lourde que la somme des moyennes.
Théorie des files d’attente — M/M/1#
La notation de Kendall (A/S/c) décrit un système de file d’attente par trois paramètres :
A: distribution des arrivées (M = markovien = exponentiel, D = déterministe)S: distribution des temps de servicec: nombre de serveurs
Le modèle M/M/1 — arrivées poissonniennes, service exponentiel, un seul serveur — est le cas de base. Malgré ses simplifications, il capture les comportements qualitatifs essentiels.
Pour un taux d’arrivée λ, un taux de service μ, et une utilisation ρ = λ/μ (ρ < 1 pour la stabilité) :
Nombre moyen de clients dans le système :
N = ρ / (1 - ρ)Temps de séjour moyen :
W = 1 / (μ(1 - ρ))Temps d’attente moyen en queue :
Wq = ρ / (μ(1 - ρ))
La relation W = 1 / (μ(1-ρ)) illustre parfaitement la saturation non linéaire. Quand ρ → 1, W → ∞. La dégradation n’est pas linéaire : passer de ρ = 0.5 à ρ = 0.9 multiplie le temps de séjour par un facteur 9.
M/M/c pour les pools de threads
Un pool de threads est un système M/M/c où c est le nombre de threads. Pour le même ρ, un système M/M/c a un temps d’attente en queue très inférieur à c systèmes M/M/1 indépendants. C’est pourquoi les connexions poolées (pool de connexions base de données, pool de threads HTTP) sont toujours plus performantes que les connexions dédiées par requête.
Visualisations#
Triangle CAP — positionnement des systèmes connus#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(10, 9))
ax.set_xlim(-0.15, 1.15)
ax.set_ylim(-0.25, 1.05)
ax.axis('off')
ax.set_facecolor('#fafafa')
fig.patch.set_facecolor('#fafafa')
# Triangle CAP
vertices = np.array([[0.5, 0.95], [0.0, 0.05], [1.0, 0.05]])
triangle = plt.Polygon(vertices, fill=True, facecolor='#f0f4ff',
edgecolor='#1168BD', linewidth=2.5, zorder=1)
ax.add_patch(triangle)
# Sommets labels
ax.text(0.5, 0.99, "Consistency (C)", ha='center', va='bottom',
fontsize=13, fontweight='bold', color='#1168BD')
ax.text(-0.02, 0.01, "Availability (A)", ha='left', va='top',
fontsize=13, fontweight='bold', color='#2d6a4f')
ax.text(1.02, 0.01, "Partition\nTolerance (P)", ha='right', va='top',
fontsize=13, fontweight='bold', color='#c0392b')
# Zones colorées dans les 3 régions
# Zone CP (haut-droit)
cp_zone = plt.Polygon([[0.5, 0.95], [1.0, 0.05], [0.75, 0.5]],
facecolor='#fde8e8', alpha=0.7, edgecolor='none', zorder=2)
ax.add_patch(cp_zone)
# Zone AP (haut-gauche)
ap_zone = plt.Polygon([[0.5, 0.95], [0.0, 0.05], [0.25, 0.5]],
facecolor='#e8f8ee', alpha=0.7, edgecolor='none', zorder=2)
ax.add_patch(ap_zone)
# Zone CA (bas)
ca_zone = plt.Polygon([[0.0, 0.05], [1.0, 0.05], [0.5, 0.5]],
facecolor='#e8f0fd', alpha=0.7, edgecolor='none', zorder=2)
ax.add_patch(ca_zone)
# Labels des zones
ax.text(0.75, 0.55, "CP", fontsize=16, fontweight='bold', color='#c0392b',
ha='center', va='center', alpha=0.6, zorder=3)
ax.text(0.25, 0.55, "AP", fontsize=16, fontweight='bold', color='#2d6a4f',
ha='center', va='center', alpha=0.6, zorder=3)
ax.text(0.5, 0.25, "CA", fontsize=16, fontweight='bold', color='#1168BD',
ha='center', va='center', alpha=0.6, zorder=3)
# Systèmes positionnés
systems = {
"HBase": (0.78, 0.52, "CP"),
"ZooKeeper": (0.70, 0.65, "CP"),
"MongoDB\n(config)": (0.82, 0.42, "CP"),
"Cassandra": (0.22, 0.52, "AP"),
"DynamoDB": (0.18, 0.42, "AP"),
"CouchDB": (0.28, 0.62, "AP"),
"Riak": (0.15, 0.62, "AP"),
"PostgreSQL": (0.50, 0.20, "CA"),
"MySQL": (0.42, 0.13, "CA"),
}
zone_colors = {"CP": "#c0392b", "AP": "#2d6a4f", "CA": "#1168BD"}
for name, (x, y, zone) in systems.items():
color = zone_colors[zone]
ax.plot(x, y, 'o', color=color, markersize=10, zorder=5, alpha=0.9)
ax.text(x + 0.02, y + 0.03, name, fontsize=8, color=color,
fontweight='bold', zorder=6, va='bottom')
ax.text(0.5, -0.18,
"Note : en pratique, P est inévitable dans les systèmes distribués.\n"
"Le choix réel est entre C et A lors d'une partition réseau.",
ha='center', va='center', fontsize=9, color='#555555', style='italic')
ax.set_title("Théorème CAP — positionnement des bases de données",
fontsize=13, fontweight='bold', pad=15)
plt.savefig("cap_triangle.png", dpi=120, bbox_inches='tight')
plt.show()
Loi d’Amdahl — speedup et limites du parallélisme#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
n_processors = np.arange(1, 65)
parallel_fractions = [0.5, 0.75, 0.9, 0.95, 0.99]
colors = sns.color_palette("muted", len(parallel_fractions))
# --- Courbe 1 : speedup vs nombre de processeurs ---
for p, color in zip(parallel_fractions, colors):
speedup = 1 / ((1 - p) + p / n_processors)
max_speedup = 1 / (1 - p)
axes[0].plot(n_processors, speedup, linewidth=2, color=color,
label=f"p={int(p*100)}% (max {max_speedup:.0f}×)")
# Ligne asymptotique
axes[0].axhline(max_speedup, color=color, linewidth=0.8,
linestyle=':', alpha=0.5)
axes[0].set_xlabel("Nombre de processeurs (n)", fontsize=10)
axes[0].set_ylabel("Speedup S(n)", fontsize=10)
axes[0].set_title("Loi d'Amdahl — speedup vs nb de processeurs\n"
"S(n) = 1 / [(1-p) + p/n]", fontsize=10, fontweight='bold')
axes[0].legend(fontsize=8.5, title="Fraction parallélisable", title_fontsize=8)
axes[0].set_xlim(1, 64)
# --- Courbe 2 : speedup maximal vs fraction parallélisable ---
p_range = np.linspace(0.0, 0.999, 500)
max_speedup_range = 1 / (1 - p_range)
axes[1].plot(p_range * 100, max_speedup_range, color='#1168BD', linewidth=2.5)
axes[1].fill_between(p_range * 100, max_speedup_range, alpha=0.1, color='#1168BD')
# Annotations pour quelques valeurs
annotations = [(50, "p=50%\nmax 2×"), (75, "p=75%\nmax 4×"),
(90, "p=90%\nmax 10×"), (95, "p=95%\nmax 20×")]
for p_pct, label in annotations:
p = p_pct / 100
sp = 1 / (1 - p)
if sp < 45:
axes[1].plot(p_pct, sp, 'o', color='#e07b39', markersize=7, zorder=5)
axes[1].annotate(label, xy=(p_pct, sp),
xytext=(p_pct - 15, sp + 3),
fontsize=8, color='#e07b39',
arrowprops=dict(arrowstyle='->', color='#e07b39', lw=1.0))
axes[1].set_xlabel("Fraction parallélisable p (%)", fontsize=10)
axes[1].set_ylabel("Speedup maximal (n→∞)", fontsize=10)
axes[1].set_title("Speedup maximal théorique vs fraction parallélisable\n"
"(asymptote : quelle que soit la puissance ajoutée)", fontsize=10, fontweight='bold')
axes[1].set_ylim(0, 50)
axes[1].set_xlim(0, 100)
fig.suptitle("Loi d'Amdahl — limites fondamentales du scaling parallèle",
fontsize=13, fontweight='bold', y=1.02)
plt.savefig("amdahl.png", dpi=120, bbox_inches='tight')
plt.show()
File M/M/1 — temps de réponse vs utilisation#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Paramètres
mu = 100 # taux de service : 100 requêtes/seconde
rho_range = np.linspace(0.01, 0.99, 500)
# Temps de séjour W = 1 / (mu * (1 - rho))
W = 1 / (mu * (1 - rho_range)) * 1000 # en ms
# Longueur de file Nq = rho^2 / (1 - rho)
Nq = rho_range**2 / (1 - rho_range)
# --- Courbe 1 : W vs rho ---
axes[0].plot(rho_range * 100, W, color='#1168BD', linewidth=2.5)
axes[0].fill_between(rho_range[rho_range <= 0.7] * 100,
W[rho_range <= 0.7], alpha=0.15, color='#2d6a4f', label='Zone saine (ρ ≤ 70%)')
axes[0].fill_between(rho_range[(rho_range > 0.7) & (rho_range <= 0.9)] * 100,
W[(rho_range > 0.7) & (rho_range <= 0.9)],
alpha=0.15, color='#e07b39', label='Zone risquée (70-90%)')
axes[0].fill_between(rho_range[rho_range > 0.9] * 100,
W[rho_range > 0.9], alpha=0.15, color='#c0392b', label='Zone critique (> 90%)')
axes[0].axvline(70, color='#2d6a4f', linewidth=1.5, linestyle='--', alpha=0.7)
axes[0].axvline(90, color='#c0392b', linewidth=1.5, linestyle='--', alpha=0.7)
w_at_50 = 1 / (mu * 0.5) * 1000
w_at_70 = 1 / (mu * 0.3) * 1000
w_at_90 = 1 / (mu * 0.1) * 1000
for rho_pct, w_val, color in [(50, w_at_50, '#555555'), (70, w_at_70, '#2d6a4f'), (90, w_at_90, '#c0392b')]:
axes[0].plot(rho_pct, w_val, 'o', color=color, markersize=8, zorder=5)
axes[0].annotate(f'ρ={rho_pct}%\nW={w_val:.1f}ms',
xy=(rho_pct, w_val),
xytext=(rho_pct + 3, w_val + 25),
fontsize=8, color=color,
arrowprops=dict(arrowstyle='->', color=color, lw=1.0))
axes[0].set_xlabel("Utilisation ρ (%)", fontsize=10)
axes[0].set_ylabel("Temps de séjour moyen W (ms)", fontsize=10)
axes[0].set_title(f"File M/M/1 : temps de séjour vs utilisation\n(μ = {mu} req/s → service nominal = 10ms)", fontsize=10, fontweight='bold')
axes[0].set_ylim(0, 250)
axes[0].legend(fontsize=8.5)
# --- Courbe 2 : longueur de file vs rho ---
axes[1].plot(rho_range * 100, Nq, color='#e07b39', linewidth=2.5)
axes[1].fill_between(rho_range * 100, Nq, alpha=0.12, color='#e07b39')
axes[1].axvline(70, color='#2d6a4f', linewidth=1.5, linestyle='--', alpha=0.7)
axes[1].axvline(90, color='#c0392b', linewidth=1.5, linestyle='--', alpha=0.7)
nq_70 = 0.7**2 / 0.3
nq_90 = 0.9**2 / 0.1
for rho_pct, nq_val, color in [(70, nq_70, '#2d6a4f'), (90, nq_90, '#c0392b')]:
axes[1].plot(rho_pct, nq_val, 'o', color=color, markersize=8, zorder=5)
axes[1].annotate(f'ρ={rho_pct}%\nNq={nq_val:.1f}',
xy=(rho_pct, nq_val),
xytext=(rho_pct + 3, nq_val + 0.5),
fontsize=8, color=color,
arrowprops=dict(arrowstyle='->', color=color, lw=1.0))
axes[1].set_xlabel("Utilisation ρ (%)", fontsize=10)
axes[1].set_ylabel("Longueur de file moyenne Nq", fontsize=10)
axes[1].set_title("File M/M/1 : longueur de file vs utilisation\n"
"Nq = ρ² / (1−ρ) — explosion non-linéaire", fontsize=10, fontweight='bold')
axes[1].set_ylim(0, 15)
fig.suptitle("Théorie des files d'attente M/M/1 — saturation exponentielle",
fontsize=13, fontweight='bold', y=1.02)
plt.savefig("mm1_queue.png", dpi=120, bbox_inches='tight')
plt.show()
Simulation d’une retry storm#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
time = np.arange(0, 60, 0.5) # 60 secondes, pas de 0.5s
# Simulation d'une retry storm
# t < 10 : fonctionnement normal
# t = 10 : pic de charge initial → service commence à dégrader
# t > 10 : les timeouts génèrent des retries → charge s'amplifie
# t > 30 (avec circuit breaker) : charge revient à la normale
def simulate_storm(time, circuit_breaker=False):
requests = np.zeros(len(time))
service_capacity = 100 # req/s nominal
for i, t in enumerate(time):
if t < 10:
# Fonctionnement normal
requests[i] = 80 + np.random.normal(0, 5)
elif t < 12:
# Pic initial
requests[i] = 120 + (t - 10) * 15 + np.random.normal(0, 5)
elif t < 30:
if circuit_breaker and t > 15:
# Circuit breaker s'active à t=15
factor = max(0, 1 - (t - 15) / 8)
requests[i] = 80 * factor + 80 + np.random.normal(0, 3)
else:
# Retries amplifient la charge : boucle positive
prev_load = requests[i-1] if i > 0 else 100
overload_factor = max(0, prev_load / service_capacity - 1)
retry_amplification = 1 + overload_factor * 0.6
requests[i] = requests[i-1] * retry_amplification + np.random.normal(0, 8)
requests[i] = min(requests[i], 500) # cap physique
else:
if circuit_breaker:
requests[i] = 80 + np.random.normal(0, 5)
else:
# Effondrement : service down, les clients continuent à retry
if requests[i-1] > 400:
requests[i] = requests[i-1] * 0.98 + np.random.normal(0, 10)
else:
requests[i] = max(20, requests[i-1] * 0.95)
return np.clip(requests, 0, 520)
storm_no_cb = simulate_storm(time, circuit_breaker=False)
storm_with_cb = simulate_storm(time, circuit_breaker=True)
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# --- Sans circuit breaker ---
axes[0].fill_between(time, storm_no_cb, alpha=0.15, color='#c0392b')
axes[0].plot(time, storm_no_cb, color='#c0392b', linewidth=2)
axes[0].axhline(100, color='#2d6a4f', linewidth=1.5, linestyle='--', alpha=0.8,
label='Capacité nominale (100 req/s)')
axes[0].axvline(10, color='#e07b39', linewidth=1.5, linestyle=':', alpha=0.8)
axes[0].text(10.5, 480, 'Pic initial\n→ timeouts', fontsize=8, color='#e07b39')
axes[0].text(18, 320, '← Retries amplifient\n la charge', fontsize=8.5,
color='#c0392b', fontweight='bold')
axes[0].set_xlabel("Temps (secondes)", fontsize=10)
axes[0].set_ylabel("Requêtes actives", fontsize=10)
axes[0].set_title("Retry storm SANS circuit breaker\n(boucle de rétroaction positive → effondrement)", fontsize=10, fontweight='bold')
axes[0].legend(fontsize=9)
axes[0].set_ylim(0, 530)
# --- Avec circuit breaker ---
axes[1].fill_between(time, storm_with_cb, alpha=0.15, color='#2d6a4f')
axes[1].plot(time, storm_with_cb, color='#2d6a4f', linewidth=2)
axes[1].axhline(100, color='#2d6a4f', linewidth=1.5, linestyle='--', alpha=0.8,
label='Capacité nominale (100 req/s)')
axes[1].axvline(10, color='#e07b39', linewidth=1.5, linestyle=':', alpha=0.8)
axes[1].axvline(15, color='#1168BD', linewidth=1.5, linestyle=':', alpha=0.8)
axes[1].text(10.5, 350, 'Pic initial', fontsize=8, color='#e07b39')
axes[1].text(15.5, 320, 'Circuit\nbreaker\nOPEN', fontsize=8, color='#1168BD', fontweight='bold')
axes[1].set_xlabel("Temps (secondes)", fontsize=10)
axes[1].set_ylabel("Requêtes actives", fontsize=10)
axes[1].set_title("Retry storm AVEC circuit breaker\n(boucle brisée → récupération contrôlée)", fontsize=10, fontweight='bold')
axes[1].legend(fontsize=9)
axes[1].set_ylim(0, 530)
fig.suptitle("Feedback loops — retry storm et rôle du circuit breaker",
fontsize=13, fontweight='bold', y=1.02)
plt.savefig("retry_storm.png", dpi=120, bbox_inches='tight')
plt.show()
Résumé#
La pensée systèmes dote l’architecte d’un cadre conceptuel pour raisonner sur des comportements qui ne peuvent pas être déduits de l’analyse des composants en isolation.
Complexité accidentelle vs essentielle : distinguer ces deux formes de complexité est le premier geste de l’architecte. Toute complexité accidentelle doit être justifiée par un bénéfice concret et mesurable.
Loi de Conway : l’organisation et l’architecture sont codépendantes. L’inverse Conway maneuver et les Team Topologies fournissent un cadre pour aligner les deux consciemment.
Théorème CAP : les systèmes distribués ne peuvent garantir simultanément cohérence, disponibilité et tolérance aux partitions. En pratique, P étant inévitable, le choix est entre CP (cohérence, aux dépens de la disponibilité sous partition) et AP (disponibilité, avec cohérence éventuelle). PACELC affine ce modèle pour le cas sans partition.
Loi d’Amdahl : la fraction séquentielle d’un programme plafonne définitivement le gain obtenu par parallélisation. Identifier et réduire cette fraction est le levier principal du scaling.
Loi de Little : N = λ × W connecte concurrence, débit et latence. La saturation (ρ → 1) produit une dégradation exponentielle de la latence. Dimensionner à 70% d’utilisation maximale n’est pas du conservatisme — c’est de la physique.
Feedback loops : les boucles positives amplifient les perturbations. Les retry storms, thundering herds et cascading failures sont des boucles positives. Les circuit breakers, timeouts avec jitter et back-pressure les brisent avant l’effondrement.
Propriétés émergentes : la cohérence éventuelle, le thundering herd, et la composition des queues de latence sont des propriétés qui n’existent pas au niveau des composants individuels — elles émergent des interactions.
Files d’attente M/M/1 : le modèle analytique de base qui explique la saturation non linéaire. W = 1/(μ(1-ρ)) — comprendre cette formule permet de dimensionner, d’identifier les goulots d’étranglement, et de justifier les décisions de scaling.
Points clés à retenir
La complexité accidentelle doit être activement combattue — la complexité essentielle ne peut pas l’être
La loi de Conway est un mécanisme causal : concevoir l’organisation et l’architecture ensemble
CAP : en système distribué, choisir entre CP (cohérence forte) et AP (disponibilité + cohérence éventuelle)
Amdahl : la fraction séquentielle plafonne le scaling — identifier ce goulot est la priorité
La saturation M/M/1 est exponentielle : 90% d’utilisation ≠ 10% de marge — c’est un gouffre
Les boucles de rétroaction positives (retry storms) doivent être brisées architecturalement avant d’atteindre la production