18. Résilience et tolérance aux pannes#
La résilience n’est pas l’absence de pannes — c’est la capacité d’un système à continuer de fonctionner, de manière dégradée si nécessaire, malgré les défaillances inévitables de ses composants. Les systèmes distribués tombent en panne de façon partielle, inattendue et souvent subtile. L’architecte résilient conçoit pour ce monde-là.
Failure modes#
Panne partielle vs panne totale#
Une panne totale est paradoxalement simple : le service est indisponible, les clients reçoivent une erreur claire, les équipes sont alertées. Une panne partielle est beaucoup plus dangereuse : certaines requêtes réussissent, d’autres échouent silencieusement ou lentement, les données peuvent être partiellement écrites.
Les pannes les plus redoutées dans les systèmes distribués sont les pannes lentes : un service qui répond mais met 30 secondes au lieu de 100 ms. Ses appelants accumulent des connexions en attente, épuisent leurs pools de threads, et tombent en cascade.
Dégradation gracieuse#
Un système résilient se dégrade gracieusement : quand un service secondaire est indisponible, les fonctionnalités principales continuent. Un moteur de recommandations en panne ne doit pas empêcher d’afficher le catalogue produit. Cette propriété s’appelle aussi le graceful degradation.
Fail fast vs fail safe#
Fail fast : détecter l’erreur le plus tôt possible et la signaler immédiatement. Ne pas attendre un timeout de 30 secondes pour décider qu’un service est mort.
Fail safe : en cas de défaillance, adopter un comportement par défaut sûr — renvoyer un résultat en cache, une liste vide, une réponse statique. La distinction est contextuelle : fail fast pour les dépendances critiques, fail safe pour les fonctionnalités secondaires.
La panne lente : l’ennemi silencieux
Un service qui répond en 30 secondes est souvent plus dangereux qu’un service mort. Ses appelants restent bloqués, consomment des ressources, et propagent la lenteur à toute la chaîne. Les timeouts sont la défense primaire contre ce scénario.
Retry et backoff#
Le retry naïf et le thundering herd#
Quand un service échoue, la réaction naturelle est de réessayer. Mais si 1000 clients réessaient tous simultanément à la seconde suivante, ils créent un thundering herd : une avalanche de requêtes qui surcharge un service déjà fragilisé et l’empêche de se rétablir.
Backoff exponentiel#
La solution standard : espacer les retries exponentiellement. Après le 1er échec, attendre 1s. Après le 2ème, 2s. Après le 3ème, 4s. La charge agrégée sur le service en difficulté diminue et lui laisse le temps de se rétablir.
Jitter#
Même avec un backoff exponentiel, si tous les clients ont démarré en même temps (au redémarrage d’un service), ils retenteont tous en même temps. Le jitter ajoute une composante aléatoire :
Cela étale les retries dans le temps et évite les synchronisations accidentelles.
Idempotence obligatoire#
Un retry implique qu’une requête peut être exécutée plusieurs fois. Le service cible doit être idempotent : exécuter la même requête deux fois produit le même résultat que l’exécuter une fois. Pour les opérations d’écriture, cela se réalise via des clés d’idempotence : le client envoie un identifiant unique de requête, le serveur déduplique.
Idempotence et HTTP
GET, PUT et DELETE sont idempotents par définition HTTP. POST ne l’est pas. Pour rendre un POST idempotent, utiliser un header Idempotency-Key (pattern adopté par Stripe, Stripe notamment) : le serveur stocke la réponse associée à cette clé et la renvoie directement si la clé est connue.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import random
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
random.seed(42)
np.random.seed(42)
def naive_retry(n_clients, max_retries=5, failure_prob=0.7):
"""Retry naïf : tous les clients réessaient immédiatement."""
timeline = {}
for client_id in range(n_clients):
t = 0
for attempt in range(max_retries):
ts = round(t, 2)
timeline[ts] = timeline.get(ts, 0) + 1
if random.random() > failure_prob:
break
t += 0.1 # retry quasi-immédiat
return timeline
def exp_backoff_retry(n_clients, max_retries=5, base=1.0, failure_prob=0.7):
"""Retry avec backoff exponentiel."""
timeline = {}
for client_id in range(n_clients):
t = random.uniform(0, 0.1) # léger étalement initial
for attempt in range(max_retries):
ts = round(t, 1)
timeline[ts] = timeline.get(ts, 0) + 1
if random.random() > failure_prob:
break
t += base * (2 ** attempt)
return timeline
def jitter_backoff_retry(n_clients, max_retries=5, base=1.0, failure_prob=0.7):
"""Retry avec backoff exponentiel + jitter."""
timeline = {}
for client_id in range(n_clients):
t = random.uniform(0, 0.1)
for attempt in range(max_retries):
ts = round(t, 1)
timeline[ts] = timeline.get(ts, 0) + 1
if random.random() > failure_prob:
break
max_delay = base * (2 ** attempt)
t += random.uniform(0, max_delay)
return timeline
n_clients = 200
t_naive = naive_retry(n_clients)
t_exp = exp_backoff_retry(n_clients)
t_jitter = jitter_backoff_retry(n_clients)
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=False)
def plot_timeline(ax, timeline, title, color, max_t=None):
if not timeline:
return
if max_t is None:
max_t = max(timeline.keys()) + 1
times = sorted(timeline.keys())
counts = [timeline[t] for t in times]
ax.bar(times, counts, width=0.08 if max_t < 5 else max_t/100,
color=color, alpha=0.8, edgecolor='white')
ax.set_ylabel("Requêtes simultanées")
ax.set_title(title, fontsize=12)
ax.set_xlim(0, max_t)
colors = sns.color_palette("muted", 3)
plot_timeline(axes[0], t_naive, "Retry naïf — thundering herd", colors[0], max_t=3)
plot_timeline(axes[1], t_exp, "Backoff exponentiel", colors[1], max_t=35)
plot_timeline(axes[2], t_jitter, "Backoff exponentiel + jitter", colors[2], max_t=35)
for ax in axes:
ax.set_xlabel("Temps (secondes)")
# Pic max annoté
max_naive = max(t_naive.values()) if t_naive else 0
axes[0].annotate(f'Pic : {max_naive} req/s', xy=(0.1, max_naive),
xytext=(0.5, max_naive * 0.85), fontsize=10, color='red',
arrowprops=dict(arrowstyle='->', color='red'))
plt.suptitle(f"Stratégies de retry — {n_clients} clients, p(échec)=70%",
fontsize=14, fontweight='bold')
plt.savefig("retry_strategies.png", dpi=100, bbox_inches='tight')
plt.show()
print(f"Pic naïf : {max(t_naive.values())} req simultanées")
print(f"Pic backoff : {max(t_exp.values())} req simultanées")
print(f"Pic jitter : {max(t_jitter.values())} req simultanées")
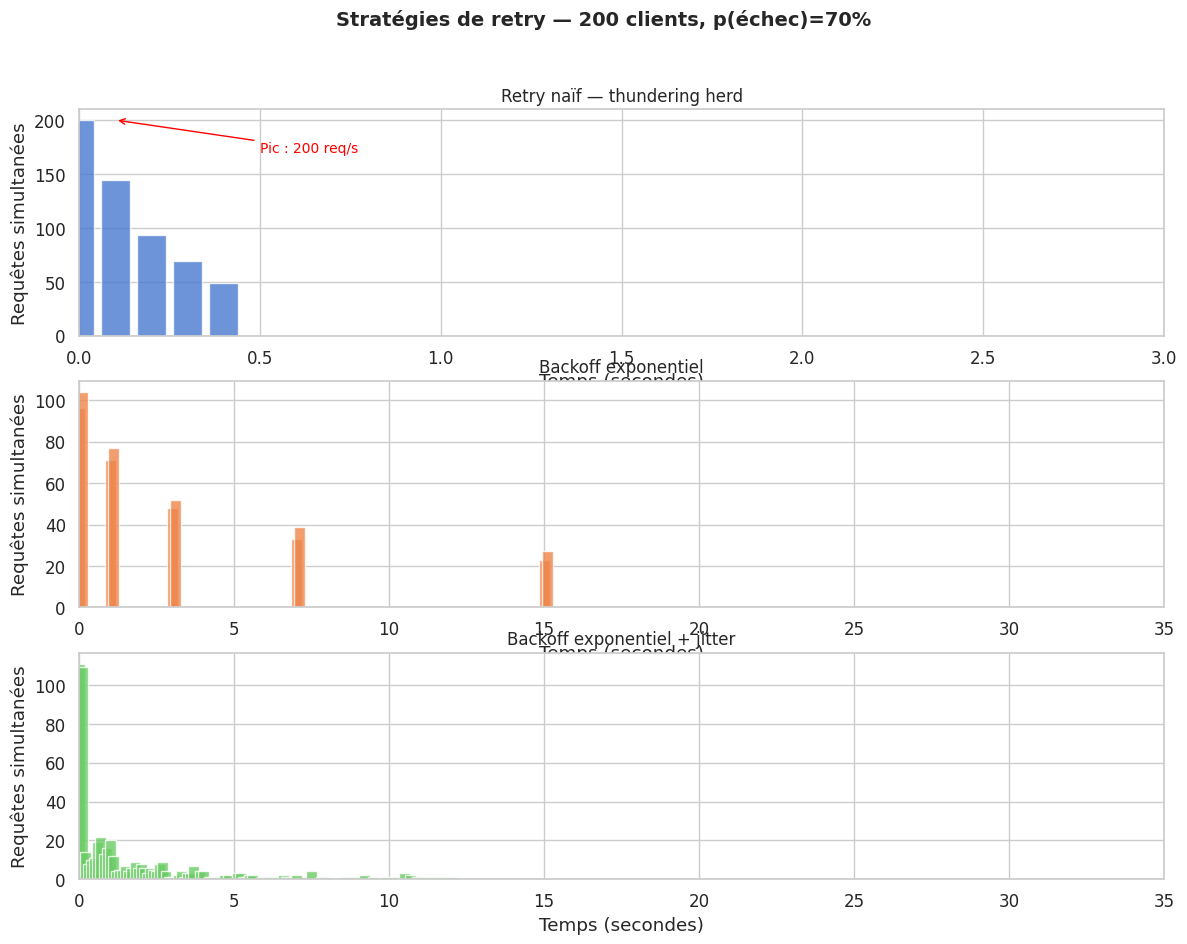
Pic naïf : 200 req simultanées
Pic backoff : 104 req simultanées
Pic jitter : 111 req simultanées
Circuit Breaker#
Le circuit breaker, popularisé par Michael Nygard dans Release It!, protège un service des appels vers une dépendance défaillante. Comme un disjoncteur électrique, il coupe le circuit avant que la surcharge ne cause des dommages.
États et transitions#
Closed (normal) : les requêtes passent. Les erreurs sont comptées.
Open (déclenché) : les requêtes sont bloquées immédiatement, sans appeler la dépendance. Une erreur rapide est renvoyée. Après un délai, le circuit passe en Half-Open.
Half-Open (sonde) : quelques requêtes tests sont autorisées. Si elles réussissent, le circuit se referme. Si elles échouent, il reste ouvert.
Configuration#
Threshold : nombre ou pourcentage d’erreurs déclenchant l’ouverture (ex : 50% d’erreurs sur les 20 dernières secondes).
Timeout : durée pendant laquelle le circuit reste ouvert avant de passer en half-open.
Half-open probe count : nombre de requêtes test autorisées en half-open.
Fail fast avec le Circuit Breaker
Quand le circuit est ouvert, l’appelant reçoit une erreur en moins d’une milliseconde au lieu d’attendre un timeout de 30 secondes. Cette réponse rapide libère les ressources (threads, connexions) et empêche la propagation de la lenteur en cascade.
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import random
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
random.seed(7)
class CircuitBreaker:
CLOSED, OPEN, HALF_OPEN = 'closed', 'open', 'half_open'
def __init__(self, threshold=5, timeout=10, probe=3):
self.state = self.CLOSED
self.failure_count = 0
self.success_count = 0
self.threshold = threshold
self.timeout = timeout
self.probe = probe
self.open_since = 0
self.probe_count = 0
def call(self, success, t):
if self.state == self.CLOSED:
if success:
self.failure_count = 0
return True, 'success'
else:
self.failure_count += 1
if self.failure_count >= self.threshold:
self.state = self.OPEN
self.open_since = t
return False, 'failure'
elif self.state == self.OPEN:
if t - self.open_since >= self.timeout:
self.state = self.HALF_OPEN
self.probe_count = 0
self.success_count = 0
return False, 'probing'
return False, 'blocked'
elif self.state == self.HALF_OPEN:
self.probe_count += 1
if success:
self.success_count += 1
if self.probe_count >= self.probe:
if self.success_count >= self.probe:
self.state = self.CLOSED
self.failure_count = 0
else:
self.state = self.OPEN
self.open_since = t
return success, 'probe'
# Simulation : service défaillant de t=20 à t=60, puis rétablissement
n_steps = 120
cb = CircuitBreaker(threshold=5, timeout=15, probe=3)
states = []
outcomes = []
requests_blocked = []
for t in range(n_steps):
# Probabilité de succès selon l'état du service backend
if 20 <= t < 60:
p_success = 0.05 # service en panne
elif 60 <= t < 70:
p_success = 0.6 # rétablissement progressif
else:
p_success = 0.95 # service sain
success = random.random() < p_success
_, outcome = cb.call(success, t)
states.append(cb.state)
outcomes.append(outcome)
requests_blocked.append(outcome == 'blocked')
# Visualisation
state_colors = {'closed': '#2ecc71', 'open': '#e74c3c', 'half_open': '#f39c12'}
state_numeric = {'closed': 0, 'open': 2, 'half_open': 1}
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
# État du circuit breaker
ax1 = axes[0]
state_vals = [state_numeric[s] for s in states]
color_list = [state_colors[s] for s in states]
for i in range(len(states) - 1):
ax1.fill_between([i, i+1], [state_vals[i]]*2, [state_vals[i+1]]*2,
color=color_list[i], alpha=0.7)
ax1.plot(range(n_steps), state_vals, 'k-', linewidth=0.5, alpha=0.3)
ax1.set_yticks([0, 1, 2])
ax1.set_yticklabels(['Closed', 'Half-Open', 'Open'])
ax1.set_title("État du Circuit Breaker", fontsize=12)
# Légende états
handles = [mpatches.Patch(color=c, label=s.title()) for s, c in state_colors.items()]
ax1.legend(handles=handles, loc='upper right', fontsize=9)
# Taux d'erreur du service backend
ax2 = axes[1]
window = 5
error_rate = []
for i in range(n_steps):
start = max(0, i - window)
window_outcomes = outcomes[start:i+1]
failures = sum(1 for o in window_outcomes if o == 'failure')
total_real = sum(1 for o in window_outcomes if o in ('success', 'failure'))
rate = failures / total_real if total_real > 0 else 0
error_rate.append(rate * 100)
ax2.plot(range(n_steps), error_rate, color='steelblue', linewidth=2)
ax2.axhline(50, color='red', linestyle='--', linewidth=1.2, label='Seuil 50%')
ax2.fill_between(range(20, 60), 0, 100, alpha=0.1, color='red', label='Service en panne')
ax2.set_ylabel("Taux d'erreur (%)")
ax2.set_title("Taux d'erreur observé (fenêtre glissante)", fontsize=12)
ax2.set_ylim(0, 110)
ax2.legend(fontsize=9)
# Requêtes bloquées vs passées
ax3 = axes[2]
cumul_blocked = np.cumsum(requests_blocked)
cumul_passed = np.cumsum([not b for b in requests_blocked])
ax3.plot(range(n_steps), cumul_passed, color='green', linewidth=2, label='Requêtes passées (cumulées)')
ax3.plot(range(n_steps), cumul_blocked, color='red', linewidth=2, label='Requêtes bloquées (cumulées)')
ax3.set_xlabel("Temps (unités)")
ax3.set_ylabel("Requêtes (cumulées)")
ax3.set_title("Impact du Circuit Breaker : requêtes bloquées vs passées", fontsize=12)
ax3.legend(fontsize=9)
plt.suptitle("Simulation Circuit Breaker — Panne de t=20 à t=60", fontsize=14, fontweight='bold')
plt.savefig("circuit_breaker.png", dpi=100, bbox_inches='tight')
plt.show()
print(f"Total requêtes bloquées : {sum(requests_blocked)}")
print(f"Total requêtes passées : {n_steps - sum(requests_blocked)}")
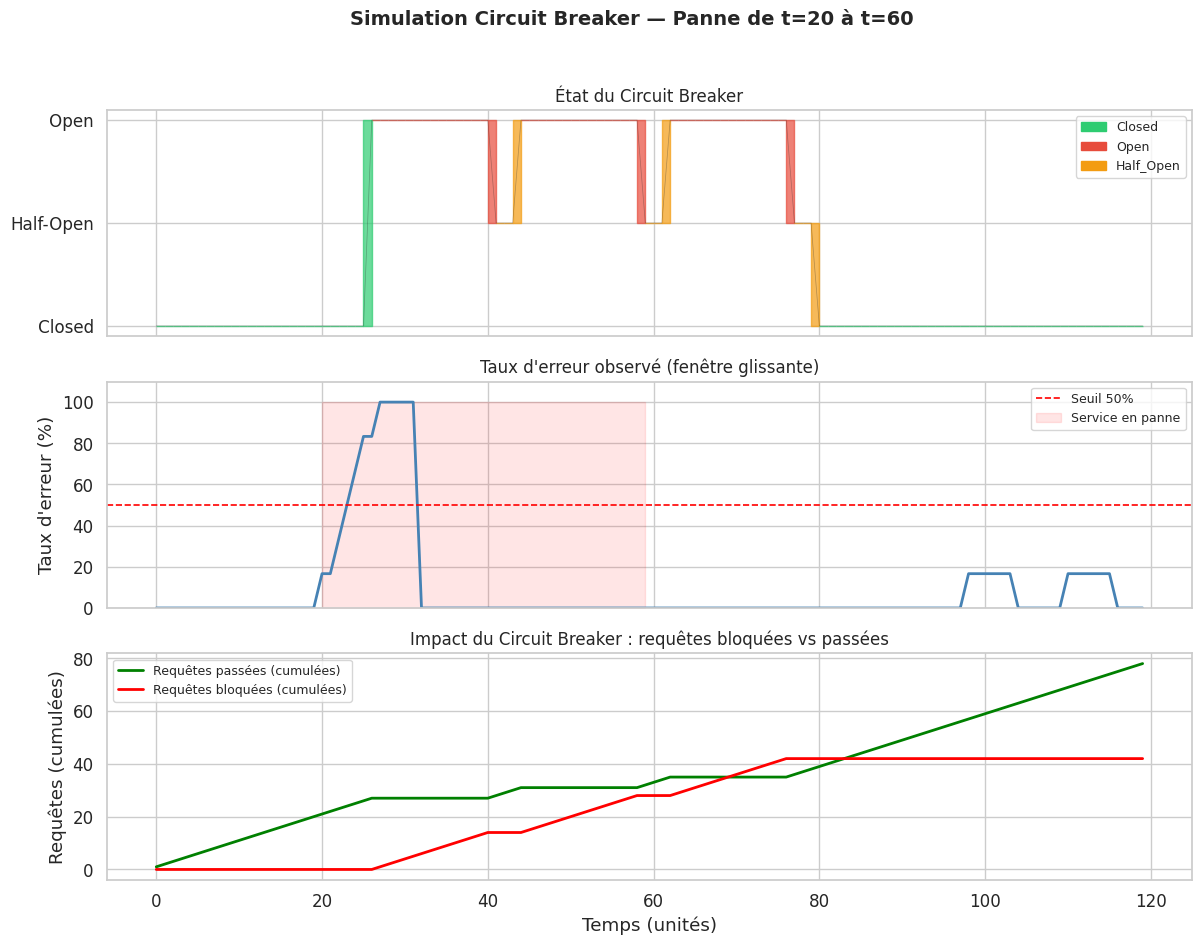
Total requêtes bloquées : 42
Total requêtes passées : 78
Bulkhead#
Le pattern Bulkhead (cloison étanche) isole les ressources entre les différents utilisateurs d’un système pour éviter qu’une défaillance dans une partie ne propage ses effets à d’autres.
Un pool de threads partagé signifie qu’un service lent peut consommer tous les threads disponibles, bloquant les autres services. Avec le Bulkhead, chaque service ou tenant a son propre pool limité. Si le pool du service A est saturé, les requêtes vers le service B ne sont pas affectées.
En pratique : pools de connexions séparés par service, queues dédiées par tenant, instances séparées pour les clients premium.
Isolation par tenant
Dans une architecture SaaS multi-tenant, un tenant très actif (ou malveillant) ne doit pas dégrader le service des autres. Les Bulkheads permettent d’appliquer des quotas physiques par tenant, pas seulement des quotas logiques.
Timeout#
Un timeout absent sur un appel réseau est une bombe à retardement. Sans timeout, un thread peut rester bloqué indéfiniment en attente d’une réponse qui ne viendra jamais.
Hiérarchie des timeouts#
Dans un système avec des appels imbriqués (A → B → C → D), les timeouts doivent être hiérarchiques : le timeout de A doit être plus long que celui de B, qui doit être plus long que celui de C. Sinon, le timeout du niveau supérieur peut déclencher alors que le niveau inférieur est encore en train de traiter — créant des work orphelins.
Règle pratique#
Timeout de connexion (établir la connexion) < Timeout de lecture (attendre la réponse). Le timeout de connexion est typiquement court (1-5 secondes). Le timeout de lecture dépend du SLA du service appelé.
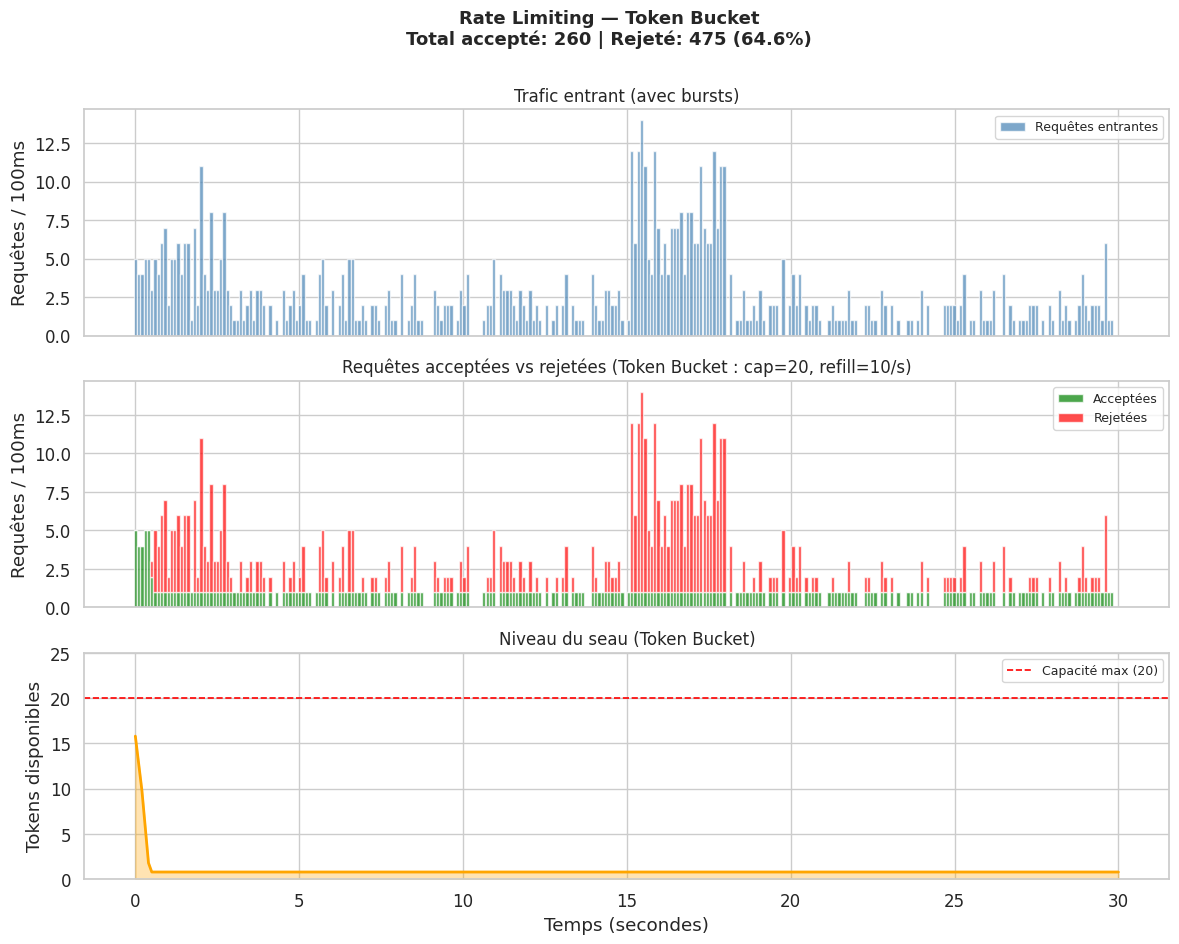
Rate Limiting#
Le rate limiting protège un service de la surcharge, qu’elle soit due à un client abusif, un bug, ou une attaque. Il garantit que le service reste disponible pour tous les clients légitimes.
Token bucket#
Un seau contient des tokens qui se rechargent à un débit constant (ex : 100 tokens/seconde). Chaque requête consomme un token. Si le seau est vide, la requête est rejetée. Ce modèle tolère les bursts courts : si le seau est plein, un client peut envoyer 100 requêtes d’un coup.
Leaky bucket#
Les requêtes entrent dans un seau qui se vide à débit constant. Si le seau est plein, les nouvelles requêtes sont rejetées. Ce modèle lisse le trafic sortant — adapté pour protéger un backend qui ne peut pas absorber les bursts.
Sliding window#
Une fenêtre temporelle glissante compte les requêtes sur la dernière période (ex : 1000 requêtes par minute). Plus précis que les fenêtres fixes qui créent un effet de double-burst en fin/début de fenêtre.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(42)
class TokenBucket:
def __init__(self, capacity, refill_rate):
self.capacity = capacity
self.tokens = capacity
self.refill_rate = refill_rate # tokens/seconde
def consume(self, dt, n_tokens=1):
"""Essaie de consommer n_tokens après dt secondes."""
self.tokens = min(self.capacity, self.tokens + self.refill_rate * dt)
if self.tokens >= n_tokens:
self.tokens -= n_tokens
return True # accepté
return False # rejeté
# Simulation : trafic avec burst
dt = 0.1 # pas de temps 100ms
duration = 30 # secondes
n_steps = int(duration / dt)
# Génération du trafic : burst au début et à t=15s
requests_per_step = np.zeros(n_steps)
for i in range(n_steps):
t = i * dt
if t < 3:
requests_per_step[i] = np.random.poisson(5) # burst initial
elif 15 < t < 18:
requests_per_step[i] = np.random.poisson(8) # burst milieu
else:
requests_per_step[i] = np.random.poisson(1.5) # trafic normal
# Token bucket : capacity=20, refill=10/s
tb = TokenBucket(capacity=20, refill_rate=10)
accepted = np.zeros(n_steps)
rejected = np.zeros(n_steps)
tokens_over_time = np.zeros(n_steps)
for i in range(n_steps):
n_req = int(requests_per_step[i])
for _ in range(n_req):
if tb.consume(dt / max(n_req, 1)):
accepted[i] += 1
else:
rejected[i] += 1
tokens_over_time[i] = tb.tokens
time = np.linspace(0, duration, n_steps)
fig, axes = plt.subplots(3, 1, figsize=(14, 10), sharex=True)
ax1 = axes[0]
ax1.bar(time, requests_per_step, width=dt, color='steelblue', alpha=0.7, label='Requêtes entrantes')
ax1.set_ylabel("Requêtes / 100ms")
ax1.set_title("Trafic entrant (avec bursts)", fontsize=12)
ax1.legend(fontsize=9)
ax2 = axes[1]
ax2.bar(time, accepted, width=dt, color='green', alpha=0.7, label='Acceptées')
ax2.bar(time, rejected, width=dt, bottom=accepted, color='red', alpha=0.7, label='Rejetées')
ax2.set_ylabel("Requêtes / 100ms")
ax2.set_title("Requêtes acceptées vs rejetées (Token Bucket : cap=20, refill=10/s)", fontsize=12)
ax2.legend(fontsize=9)
ax3 = axes[2]
ax3.plot(time, tokens_over_time, color='orange', linewidth=2)
ax3.axhline(20, color='red', linestyle='--', linewidth=1.2, label='Capacité max (20)')
ax3.fill_between(time, 0, tokens_over_time, alpha=0.3, color='orange')
ax3.set_xlabel("Temps (secondes)")
ax3.set_ylabel("Tokens disponibles")
ax3.set_title("Niveau du seau (Token Bucket)", fontsize=12)
ax3.legend(fontsize=9)
ax3.set_ylim(0, 25)
plt.suptitle(f"Rate Limiting — Token Bucket\n"
f"Total accepté: {accepted.sum():.0f} | Rejeté: {rejected.sum():.0f} "
f"({100*rejected.sum()/(accepted.sum()+rejected.sum()):.1f}%)",
fontsize=13, fontweight='bold')
plt.savefig("rate_limiting.png", dpi=100, bbox_inches='tight')
plt.show()
Chaos Engineering#
Le chaos engineering est la pratique de provoquer délibérément des pannes en production pour vérifier que le système les tolère. La phrase clé de Netflix, qui a popularisé la discipline avec Chaos Monkey : « Si nous n’échouons pas intentionnellement, nous échouerons de façon non intentionnelle. »
Principes fondamentaux#
Former une hypothèse : définir à l’avance ce que le système est censé faire lors de la panne (ex : « si le service de recommandations tombe, le catalogue s’affiche quand même en moins de 500ms »).
Minimiser le blast radius : commencer par des pannes en environnement de staging, sur un faible pourcentage du trafic.
Automatiser : les expériences de chaos doivent être reproductibles et faire partie du pipeline CI/CD.
Gamedays : sessions planifiées où l’équipe s’entraîne à répondre aux incidents simulés.
Chaos Monkey et ses successeurs
Netflix a ouvert Chaos Monkey, qui tue aléatoirement des instances en production. La suite Simian Army inclut Latency Monkey (injecte des délais), Conformity Monkey (vérifie les bonnes pratiques), et Chaos Gorilla (simule la perte d’une zone de disponibilité entière).
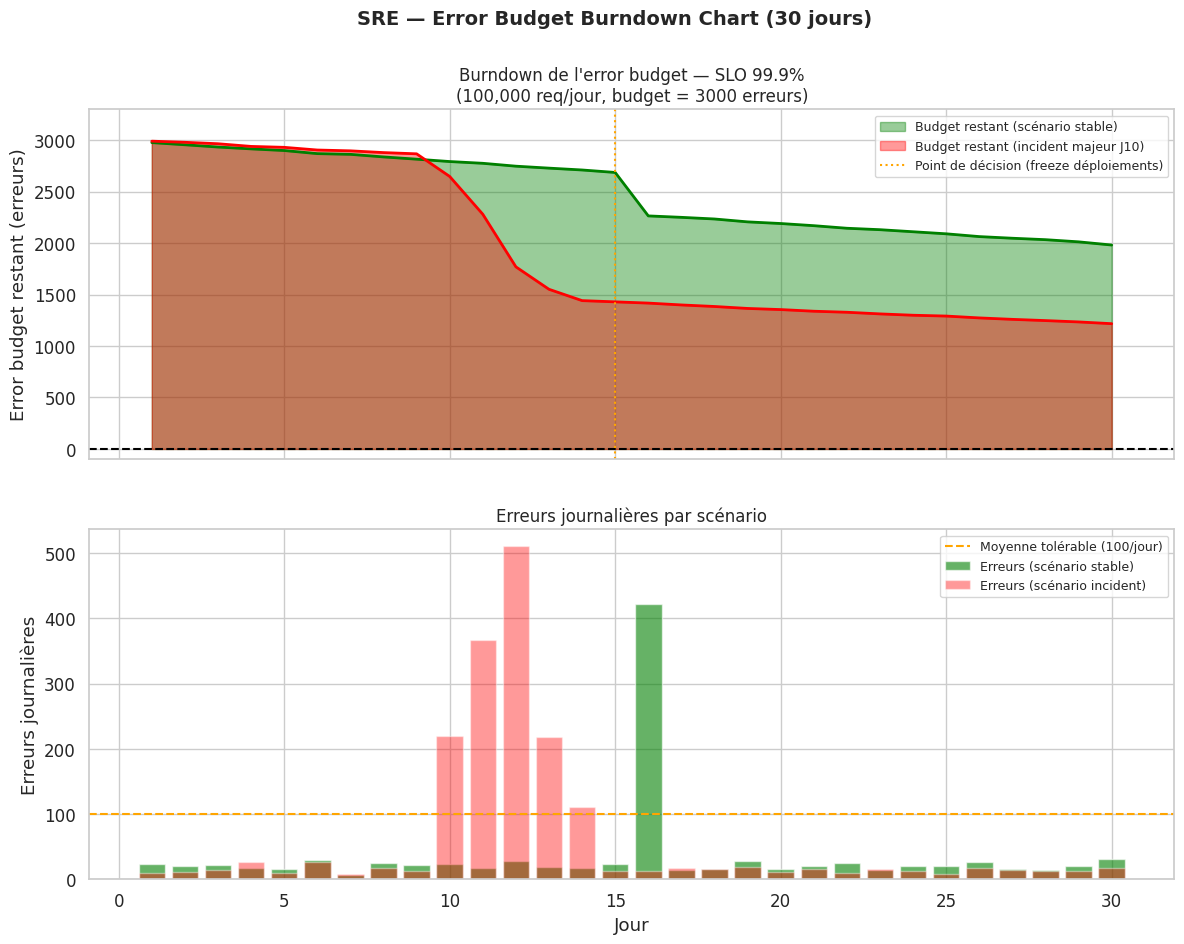
SRE et error budget#
Le Site Reliability Engineering, formalisé par Google, apporte un cadre quantitatif à la fiabilité.
SLO et error budget#
Un SLO (Service Level Objective) est un objectif mesurable : « 99.9% des requêtes en moins de 200ms ». L”error budget est la quantité de défaillances tolérée : avec un SLO à 99.9%, on dispose de 0.1% du temps pour les incidents — environ 8.7 heures par an.
Tant que l’error budget n’est pas épuisé, l’équipe peut déployer des nouvelles fonctionnalités, prendre des risques. Quand l’error budget est épuisé, le focus passe à la fiabilité : plus de déploiements risqués, travail sur la résilience.
Toil#
Le toil est le travail manuel, répétitif et sans valeur ajoutée à long terme : redémarrer manuellement un service, répondre à des alertes qui ne nécessitent pas d’action humaine. Les SRE visent à maintenir le toil sous 50% de leur temps de travail.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
np.random.seed(13)
# Simulation d'un error budget sur 30 jours
# SLO: 99.9% (0.1% d'erreurs tolérées)
slo = 0.999
days = 30
requests_per_day = 100_000
error_budget_total = (1 - slo) * requests_per_day * days # erreurs tolérées au total
print(f"Error budget total sur {days} jours : {error_budget_total:.0f} erreurs")
# Simulation de 2 scénarios
# Scénario 1 : équipe qui consomme lentement le budget
errors_slow = np.random.poisson(20, days) + np.where(np.arange(days) == 15, 400, 0)
# Scénario 2 : incident majeur à J10 qui épuise le budget
errors_fast = np.random.poisson(15, days).copy()
errors_fast[9:14] += np.array([200, 350, 500, 200, 100]) # incident
cumul_slow = np.cumsum(errors_slow)
cumul_fast = np.cumsum(errors_fast)
budget_line = np.linspace(error_budget_total, error_budget_total, days)
remaining_slow = np.maximum(0, error_budget_total - cumul_slow)
remaining_fast = np.maximum(0, error_budget_total - cumul_fast)
fig, axes = plt.subplots(2, 1, figsize=(14, 10), sharex=True)
day_range = np.arange(1, days + 1)
ax1 = axes[0]
ax1.fill_between(day_range, remaining_slow, alpha=0.4, color='green', label='Budget restant (scénario stable)')
ax1.fill_between(day_range, remaining_fast, alpha=0.4, color='red', label='Budget restant (incident majeur J10)')
ax1.plot(day_range, remaining_slow, color='green', linewidth=2)
ax1.plot(day_range, remaining_fast, color='red', linewidth=2)
ax1.axhline(0, color='black', linewidth=1.5, linestyle='--')
ax1.axvline(15, color='orange', linewidth=1.5, linestyle=':', label='Point de décision (freeze déploiements)')
ax1.set_ylabel("Error budget restant (erreurs)")
ax1.set_title(f"Burndown de l'error budget — SLO {slo*100}%\n({requests_per_day:,} req/jour, budget = {error_budget_total:.0f} erreurs)", fontsize=12)
ax1.legend(fontsize=9)
ax1.set_ylim(-100, error_budget_total * 1.1)
# Annoter l'épuisement
exhaustion_day = next((i+1 for i, r in enumerate(remaining_fast) if r == 0), None)
if exhaustion_day:
ax1.annotate(f'Budget épuisé\nà J{exhaustion_day}',
xy=(exhaustion_day, 0),
xytext=(exhaustion_day + 3, error_budget_total * 0.3),
fontsize=9, color='red',
arrowprops=dict(arrowstyle='->', color='red'))
ax2 = axes[1]
ax2.bar(day_range, errors_slow, color='green', alpha=0.6, label='Erreurs (scénario stable)')
ax2.bar(day_range, errors_fast, color='red', alpha=0.4, label='Erreurs (scénario incident)')
ax2.axhline(error_budget_total / days, color='orange', linestyle='--',
linewidth=1.5, label=f'Moyenne tolérable ({error_budget_total/days:.0f}/jour)')
ax2.set_xlabel("Jour")
ax2.set_ylabel("Erreurs journalières")
ax2.set_title("Erreurs journalières par scénario", fontsize=12)
ax2.legend(fontsize=9)
plt.suptitle(f"SRE — Error Budget Burndown Chart ({days} jours)", fontsize=14, fontweight='bold')
plt.savefig("error_budget.png", dpi=100, bbox_inches='tight')
plt.show()
Error budget total sur 30 jours : 3000 erreurs
Résumé#
La résilience est une propriété systémique qui s’obtient par la combinaison de plusieurs patterns — aucun n’est suffisant seul.
Pattern |
Problème résolu |
Contrepartie |
|---|---|---|
Retry + jitter |
Erreurs transitoires |
Idempotence obligatoire |
Circuit Breaker |
Propagation des pannes |
Complexité d’état, configuration |
Bulkhead |
Isolation des défaillances |
Ressources supplémentaires |
Timeout |
Pannes lentes |
Calibration délicate |
Rate Limiting |
Surcharge, abus |
Expérience dégradée pour les clients légitimes |
Chaos Engineering |
Confiance dans la résilience |
Courage organisationnel |
Error Budget |
Équilibre fiabilité/vélocité |
Culture data-driven requise |
Règles pratiques :
Tout appel réseau doit avoir un timeout. Sans exception.
Le jitter est non négociable dès qu’il y a plusieurs clients qui reessaient.
Le Circuit Breaker protège le service appelé, pas seulement l’appelant.
Commencer le chaos engineering en staging avant la production.
L’error budget transforme la fiabilité en conversation de produit, pas seulement technique.