Bonnes pratiques et production#
Vous avez maintenant une vision complète de Docker et Kubernetes. Ce dernier chapitre synthétise les bonnes pratiques qui distinguent une application « qui tourne » d’une application « prête pour la production ». Du Dockerfile au cluster multi-zones, en passant par le sizing des ressources, les probes et la gestion des coûts.
Checklist Dockerfile de production#

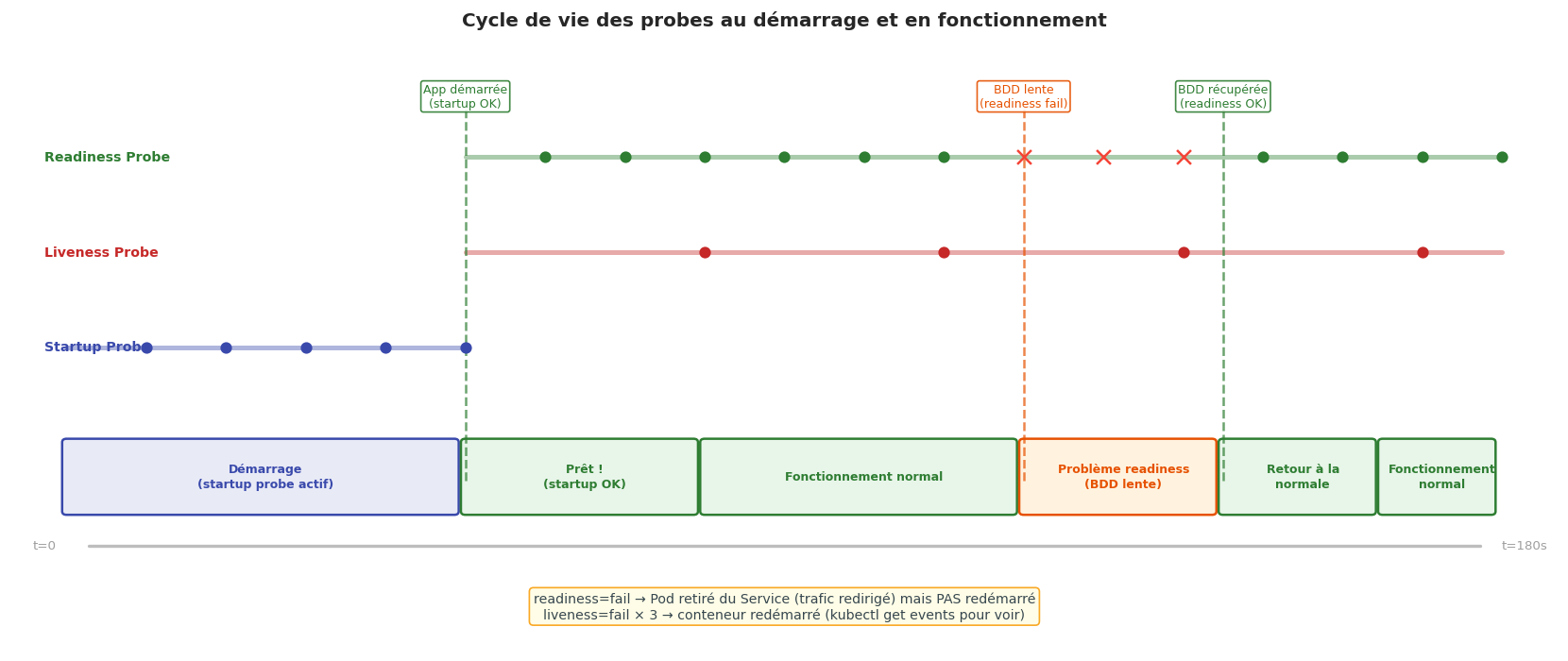
Les probes en détail : liveness, readiness, startup#
Les trois types de probes répondent à des questions différentes et ont des conséquences différentes en cas d’échec.
Probe |
Question |
Action si échec |
Quand configurer |
|---|---|---|---|
liveness |
« Mon app est-elle encore vivante ? » |
Redémarrer le conteneur |
Toujours |
readiness |
« Mon app est-elle prête à recevoir du trafic ? » |
Retirer du Service (load balancer) |
Toujours |
startup |
« Mon app a-t-elle fini de démarrer ? » |
Bloquer liveness et readiness |
Apps lentes au démarrage |
# Exemple complet des 3 probes
spec:
containers:
- name: app
image: mon-app:1.0
# Startup Probe : protège les apps lentes au démarrage
# liveness et readiness sont DÉSACTIVÉES tant que startup n'est pas OK
startupProbe:
httpGet:
path: /startup
port: 8080
failureThreshold: 30 # 30 × 10s = 5 minutes max pour démarrer
periodSeconds: 10
# Si échec après 30 tentatives → conteneur redémarré
# Liveness Probe : détecte les deadlocks, états corrompus
livenessProbe:
httpGet:
path: /healthz # Réponse simple (200 OK)
port: 8080
initialDelaySeconds: 0 # Attendu que startupProbe réussisse
periodSeconds: 30
failureThreshold: 3 # 3 échecs consécutifs → restart
timeoutSeconds: 5
# Readiness Probe : détecte quand l'app n'est pas prête
# (ex: base de données non connectée, cache non chargé)
readinessProbe:
httpGet:
path: /ready # Vérifications plus complètes
port: 8080
initialDelaySeconds: 0
periodSeconds: 10 # Plus fréquent que liveness
failureThreshold: 3
successThreshold: 1 # 1 succès suffit pour revenir dans le LB
timeoutSeconds: 3
Endpoints /healthz vs /ready — que vérifier ?
/healthz(liveness) : vérification légère — « le processus répond-il ? » Un 200 OK simple suffit. Ne pas vérifier les dépendances externes ici (sinon un problème de BDD redémarre tous vos Pods en boucle !)./ready(readiness) : vérification des dépendances — « puis-je traiter des requêtes ? » Vérifier la connexion à la BDD, au cache, la disponibilité des fichiers de config…
Resource sizing : méthode pour estimer requests et limits#
L’un des problèmes les plus courants en production est le mauvais sizing des ressources : trop peu (OOM, throttling), trop (gaspillage de coûts).
Méthode recommandée#
Déployer en mode BestEffort (sans requests ni limits) pendant quelques heures en staging
Observer via
kubectl top podsou PrometheusAppliquer VPA en mode Off : il recommande des valeurs basées sur l’utilisation réelle
Configurer
requests= P95 d’utilisation normale,limits= 2× ou 3× les requestsActiver HPA pour absorber les pics
# Observer l'utilisation des ressources
kubectl top pods -n production
# NAME CPU(cores) MEMORY(bytes)
# api-7d4f9-x8k2 83m 145Mi
# api-7d4f9-p3l1 91m 158Mi
# api-7d4f9-nh2v 78m 142Mi
# VPA recommandation (après quelques heures d'observation)
kubectl describe vpa mon-api-vpa
# Target CPU : 250m (recommandé comme requests)
# Target Mem : 200Mi
# Règle empirique :
# requests.cpu = utilisation P95 en conditions normales
# limits.cpu = 2× à 4× les requests (burst toléré)
# requests.mem = utilisation P99 (la mémoire ne se throttle pas, elle OOM-kill)
# limits.mem = 1.2× à 1.5× requests (marge, mais pas trop pour éviter OOM loop)
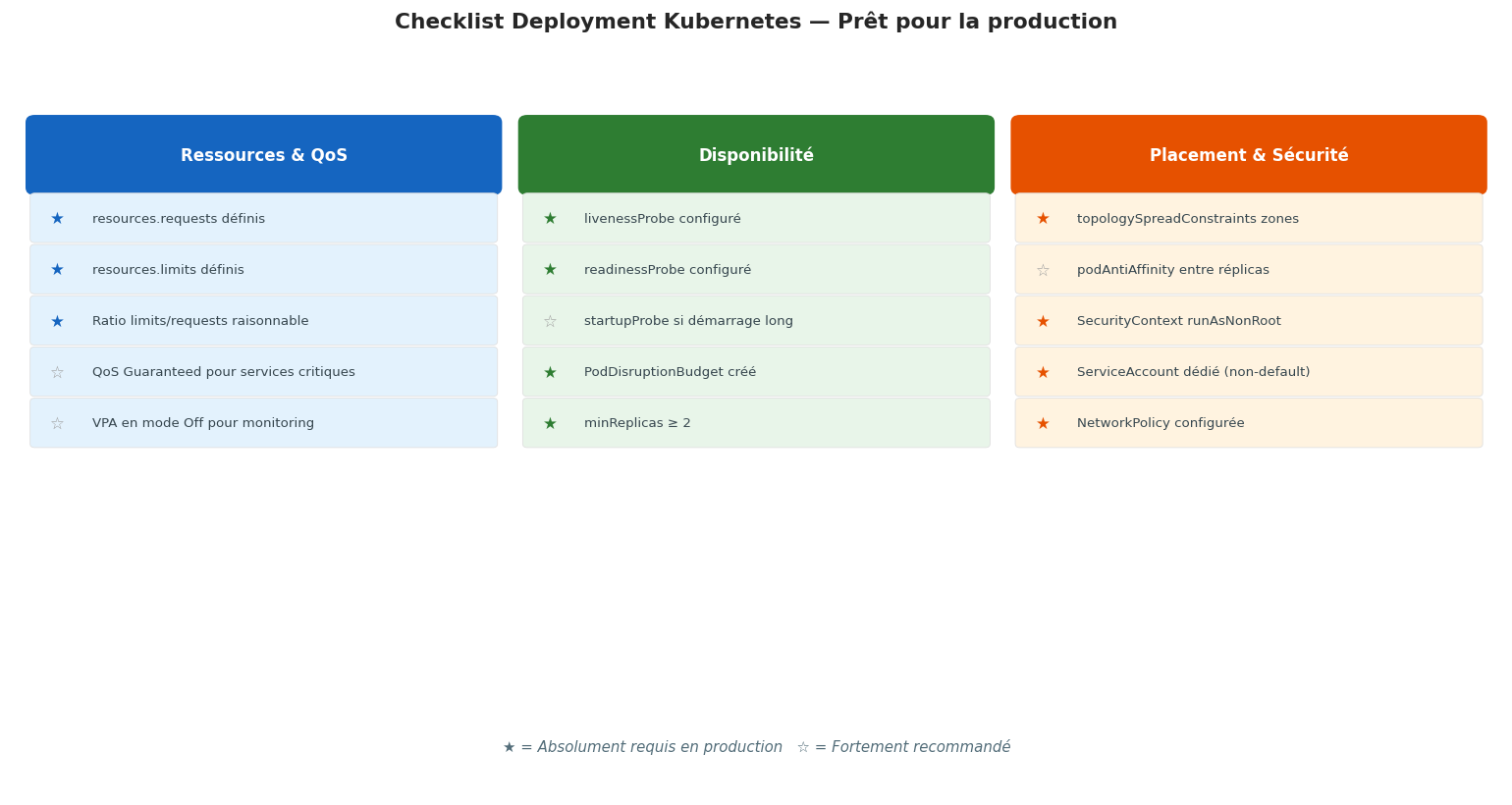
Checklist Pod/Deployment de production#
Gestion des configurations : l’approche 12-Factor#
La règle d’or de l’application 12-factor pour la configuration : séparer strictement la configuration du code.
# Ce qui va dans le code : comportement de l'application
# Ce qui va dans la config : tout ce qui change entre les environnements
# ConfigMap — pour les configurations non-sensibles
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
APP_ENV: "production"
LOG_LEVEL: "info"
MAX_WORKERS: "8"
CACHE_TTL: "300"
---
# Secret — pour les données sensibles
apiVersion: v1
kind: Secret
metadata:
name: app-secrets
type: Opaque
stringData: # stringData : Kubernetes encode en base64 automatiquement
DATABASE_URL: "postgresql://user:password@postgres:5432/appdb"
JWT_SECRET: "..."
API_KEY: "..."
# Utilisation dans le Deployment
spec:
containers:
- name: app
# Injecter tout le ConfigMap comme variables d'environnement
envFrom:
- configMapRef:
name: app-config
- secretRef:
name: app-secrets
# Ou sélectivement
env:
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: app-config
key: LOG_LEVEL
Vérificateur de conformité d’un Deployment#
from dataclasses import dataclass, field
from typing import List, Dict, Optional
@dataclass
class Critere:
nom: str
description: str
critique: bool # True = requis, False = recommandé
points: int
@dataclass
class ResultatAudit:
critere: Critere
reussi: bool
detail: str = ""
@property
def points_obtenus(self) -> int:
return self.critere.points if self.reussi else 0
class VerificateurDeployment:
"""
Vérificateur de conformité d'un manifeste Deployment Kubernetes.
Calcule un score de maturité de 0 à 100.
"""
CRITERES = [
# Ressources
Critere("resources-requests", "resources.requests définis pour CPU et mémoire", True, 8),
Critere("resources-limits", "resources.limits définis pour CPU et mémoire", True, 8),
# Probes
Critere("liveness-probe", "livenessProbe configuré", True, 7),
Critere("readiness-probe", "readinessProbe configuré", True, 7),
Critere("startup-probe", "startupProbe configuré", False, 3),
# Sécurité
Critere("non-root", "securityContext.runAsNonRoot = true", True, 8),
Critere("no-privilege-esc", "allowPrivilegeEscalation = false", True, 7),
Critere("readonly-fs", "readOnlyRootFilesystem = true", False, 5),
Critere("drop-caps", "capabilities.drop = ALL", False, 5),
Critere("service-account", "ServiceAccount dédié (pas default)", False, 4),
# Disponibilité
Critere("min-replicas", "replicas >= 2", True, 7),
Critere("topology-spread", "topologySpreadConstraints défini", False, 5),
Critere("image-tag", "Version d'image épinglée (pas :latest)", True, 6),
# Configuration
Critere("no-inline-secrets", "Pas de secrets en clair dans env", True, 8),
Critere("labels", "Labels app, version, environment présents", False, 3),
Critere("rolling-update", "Stratégie RollingUpdate configurée", False, 4),
Critere("pdb", "PodDisruptionBudget associé (à vérifier sep.)", False, 5),
]
def verifier(self, manifeste: dict) -> List[ResultatAudit]:
resultats = []
spec = manifeste.get("spec", {})
template = spec.get("template", {})
pod_spec = template.get("spec", {})
containers = pod_spec.get("containers", [])
metadata = manifeste.get("metadata", {})
labels = metadata.get("labels", {})
# resources
has_requests = all(c.get("resources", {}).get("requests") for c in containers)
has_limits = all(c.get("resources", {}).get("limits") for c in containers)
resultats.append(ResultatAudit(self._get("resources-requests"), has_requests,
"Tous les conteneurs ont des requests" if has_requests else
"Au moins un conteneur sans resources.requests"))
resultats.append(ResultatAudit(self._get("resources-limits"), has_limits))
# probes
has_liveness = all(c.get("livenessProbe") for c in containers)
has_readiness = all(c.get("readinessProbe") for c in containers)
has_startup = any(c.get("startupProbe") for c in containers)
resultats.append(ResultatAudit(self._get("liveness-probe"), has_liveness))
resultats.append(ResultatAudit(self._get("readiness-probe"), has_readiness))
resultats.append(ResultatAudit(self._get("startup-probe"), has_startup))
# sécurité
pod_ctx = pod_spec.get("securityContext", {})
non_root = pod_ctx.get("runAsNonRoot", False)
resultats.append(ResultatAudit(self._get("non-root"), non_root))
no_priv = all(c.get("securityContext", {}).get("allowPrivilegeEscalation") is False
for c in containers)
resultats.append(ResultatAudit(self._get("no-privilege-esc"), no_priv))
readonly = all(c.get("securityContext", {}).get("readOnlyRootFilesystem", False)
for c in containers)
resultats.append(ResultatAudit(self._get("readonly-fs"), readonly))
drop_all = all(c.get("securityContext", {}).get("capabilities", {}).get("drop") == ["ALL"]
for c in containers)
resultats.append(ResultatAudit(self._get("drop-caps"), drop_all))
sa = pod_spec.get("serviceAccountName", "default")
resultats.append(ResultatAudit(self._get("service-account"),
sa != "default" and sa != "",
f"ServiceAccount : {sa}"))
# disponibilité
replicas = spec.get("replicas", 1)
resultats.append(ResultatAudit(self._get("min-replicas"), replicas >= 2,
f"replicas = {replicas}"))
has_topology = bool(pod_spec.get("topologySpreadConstraints"))
resultats.append(ResultatAudit(self._get("topology-spread"), has_topology))
# image tag
not_latest = all(not c.get("image", ":latest").endswith(":latest") and
":" in c.get("image", "")
for c in containers)
resultats.append(ResultatAudit(self._get("image-tag"), not_latest))
# secrets en clair
no_inline_secrets = True
for c in containers:
for env in c.get("env", []):
name_lower = env.get("name", "").lower()
if any(kw in name_lower for kw in ["password", "secret", "token", "key", "api"]):
if "value" in env:
no_inline_secrets = False
break
resultats.append(ResultatAudit(self._get("no-inline-secrets"), no_inline_secrets))
# labels
required_labels = {"app", "version", "environment"}
has_labels = required_labels.issubset(set(labels.keys()))
resultats.append(ResultatAudit(self._get("labels"), has_labels))
# rolling update
strategy = spec.get("strategy", {})
has_rolling = strategy.get("type") == "RollingUpdate"
resultats.append(ResultatAudit(self._get("rolling-update"), has_rolling))
# PDB : ne peut pas être vérifié dans le manifeste Deployment seul
resultats.append(ResultatAudit(self._get("pdb"), False,
"À vérifier séparément (objet PodDisruptionBudget)"))
return resultats
def _get(self, nom: str) -> Critere:
return next(c for c in self.CRITERES if c.nom == nom)
def score(self, resultats: List[ResultatAudit]) -> dict:
max_points = sum(c.points for c in self.CRITERES)
obtenus = sum(r.points_obtenus for r in resultats)
critiques_rates = [r for r in resultats if r.critere.critique and not r.reussi]
return {
"score": obtenus,
"max": max_points,
"pct": obtenus / max_points * 100,
"critiques_rates": critiques_rates,
"niveau": "Prêt pour la production" if obtenus / max_points >= 0.85
else ("Presque prêt" if obtenus / max_points >= 0.65
else ("En développement" if obtenus / max_points >= 0.40
else "Prototype")),
}
def rapport(self, nom: str, resultats: List[ResultatAudit]):
sc = self.score(resultats)
print(f"\n{'='*65}")
print(f"Audit Deployment : {nom}")
print(f"Score : {sc['score']}/{sc['max']} ({sc['pct']:.0f}%) — {sc['niveau']}")
print(f"{'='*65}")
if sc["critiques_rates"]:
print(f"\n❌ CRITÈRES OBLIGATOIRES MANQUANTS ({len(sc['critiques_rates'])}) :")
for r in sc["critiques_rates"]:
detail = f" — {r.detail}" if r.detail else ""
print(f" ✗ {r.critere.description}{detail}")
non_critiques_rates = [r for r in resultats if not r.critere.critique and not r.reussi]
if non_critiques_rates:
print(f"\n⚠ RECOMMANDATIONS NON APPLIQUÉES ({len(non_critiques_rates)}) :")
for r in non_critiques_rates:
print(f" ! {r.critere.description}")
ok_list = [r for r in resultats if r.reussi]
print(f"\n✅ CONTRÔLES RÉUSSIS ({len(ok_list)}) :")
for r in ok_list[:5]: # Afficher les 5 premiers
print(f" ✓ {r.critere.description}")
if len(ok_list) > 5:
print(f" ... et {len(ok_list) - 5} autres")
verificateur = VerificateurDeployment()
# Deployment en production bien configuré
deployment_prod = {
"metadata": {"labels": {"app": "mon-api", "version": "2.1.0", "environment": "production"}},
"spec": {
"replicas": 3,
"strategy": {"type": "RollingUpdate"},
"template": {
"spec": {
"serviceAccountName": "api-service-account",
"securityContext": {"runAsNonRoot": True, "runAsUser": 1000},
"topologySpreadConstraints": [{"maxSkew": 1}],
"containers": [{
"name": "api",
"image": "mon-api:2.1.0",
"resources": {
"requests": {"cpu": "200m", "memory": "256Mi"},
"limits": {"cpu": "500m", "memory": "512Mi"},
},
"livenessProbe": {"httpGet": {"path": "/healthz", "port": 8080}},
"readinessProbe": {"httpGet": {"path": "/ready", "port": 8080}},
"startupProbe": {"httpGet": {"path": "/startup", "port": 8080}},
"env": [
{"name": "DB_URL", "valueFrom": {"secretKeyRef": {"name": "db", "key": "url"}}},
],
"securityContext": {
"allowPrivilegeEscalation": False,
"readOnlyRootFilesystem": True,
"capabilities": {"drop": ["ALL"]},
},
}]
}
}
}
}
# Deployment de développement (peu configuré)
deployment_dev = {
"metadata": {"labels": {"app": "mon-api"}},
"spec": {
"replicas": 1,
"template": {
"spec": {
"containers": [{
"name": "api",
"image": "mon-api:latest", # latest !
"env": [
{"name": "API_PASSWORD", "value": "secret123"}, # en clair !
],
}]
}
}
}
}
res_prod = verificateur.verifier(deployment_prod)
verificateur.rapport("deployment-production.yaml", res_prod)
res_dev = verificateur.verifier(deployment_dev)
verificateur.rapport("deployment-dev.yaml", res_dev)
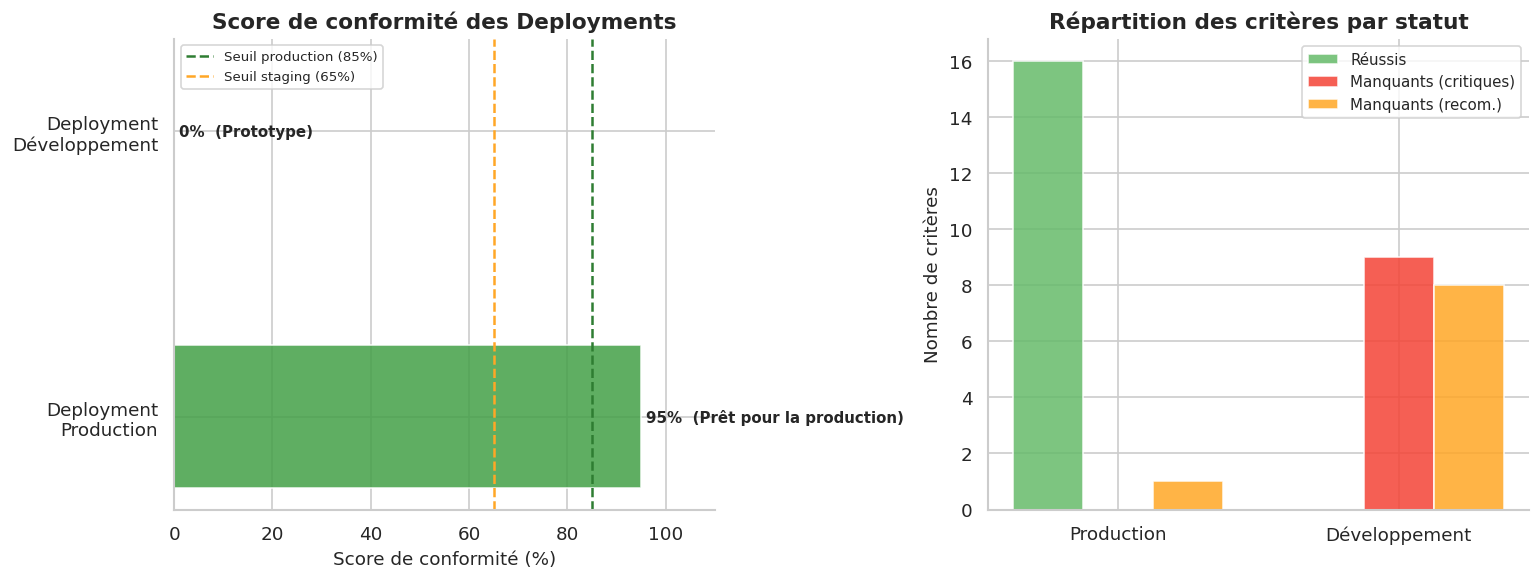
=================================================================
Audit Deployment : deployment-production.yaml
Score : 95/100 (95%) — Prêt pour la production
=================================================================
⚠ RECOMMANDATIONS NON APPLIQUÉES (1) :
! PodDisruptionBudget associé (à vérifier sep.)
✅ CONTRÔLES RÉUSSIS (16) :
✓ resources.requests définis pour CPU et mémoire
✓ resources.limits définis pour CPU et mémoire
✓ livenessProbe configuré
✓ readinessProbe configuré
✓ startupProbe configuré
... et 11 autres
=================================================================
Audit Deployment : deployment-dev.yaml
Score : 0/100 (0%) — Prototype
=================================================================
❌ CRITÈRES OBLIGATOIRES MANQUANTS (9) :
✗ resources.requests définis pour CPU et mémoire — Au moins un conteneur sans resources.requests
✗ resources.limits définis pour CPU et mémoire
✗ livenessProbe configuré
✗ readinessProbe configuré
✗ securityContext.runAsNonRoot = true
✗ allowPrivilegeEscalation = false
✗ replicas >= 2 — replicas = 1
✗ Version d'image épinglée (pas :latest)
✗ Pas de secrets en clair dans env
⚠ RECOMMANDATIONS NON APPLIQUÉES (8) :
! startupProbe configuré
! readOnlyRootFilesystem = true
! capabilities.drop = ALL
! ServiceAccount dédié (pas default)
! topologySpreadConstraints défini
! Labels app, version, environment présents
! Stratégie RollingUpdate configurée
! PodDisruptionBudget associé (à vérifier sep.)
✅ CONTRÔLES RÉUSSIS (0) :
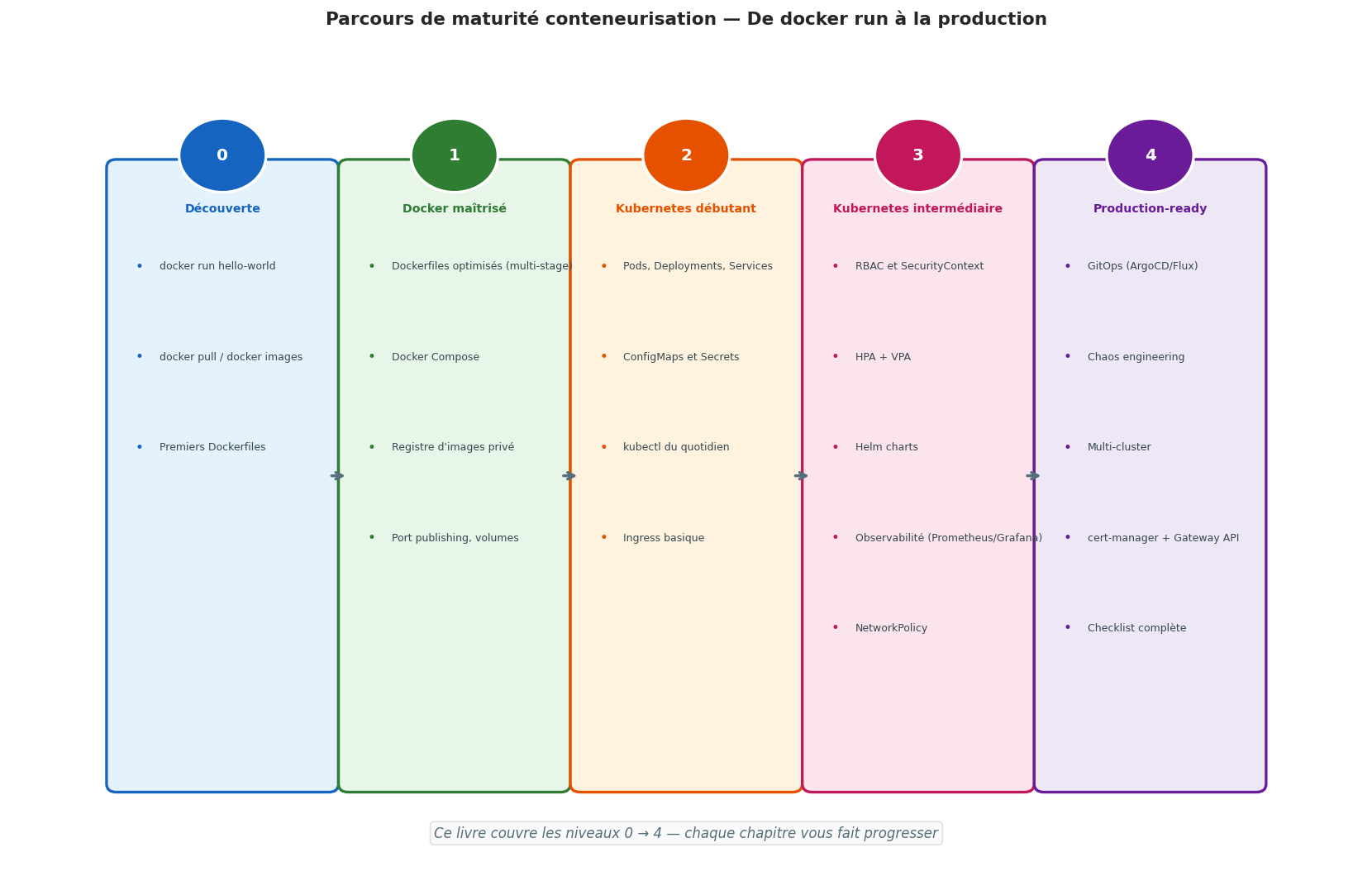
Récapitulatif visuel : de docker run à la production Kubernetes#
Coûts Kubernetes : optimisation#
Kubernetes peut rapidement devenir coûteux si les ressources ne sont pas bien dimensionnées. Quelques stratégies d’optimisation :
Réduire les coûts :
Spot / Preemptible instances : 60-80% moins cher pour les workloads tolerant aux interruptions (batch, CI)
Quotas de namespace :
ResourceQuotapour limiter la consommation par équipeVPA : éviter le sur-dimensionnement des containers
KEDA scale-to-zero : certains workloads peuvent descendre à 0 Pods hors heures de travail
Node consolidation :
kubectl-node-cleanupou Karpenter pour consolider les Pods sur moins de nœuds
# ResourceQuota — limiter les ressources d'un namespace
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-equipe-alpha
namespace: equipe-alpha
spec:
hard:
requests.cpu: "10" # 10 CPU au total pour le namespace
requests.memory: 20Gi
limits.cpu: "20"
limits.memory: 40Gi
pods: "50" # Max 50 Pods
services: "10"
persistentvolumeclaims: "20"
Mise à jour du cluster : stratégies#
Mettre à jour Kubernetes lui-même est une opération délicate qui nécessite de la préparation.
# Stratégie 1 : Rolling upgrade (in-place)
# 1. Mettre à jour le control plane (un nœud à la fois si HA)
# 2. Mettre à jour les nœuds workers un par un (drain → upgrade → uncordon)
# Drain d'un nœud (évacuer les Pods)
kubectl drain node-1 --ignore-daemonsets --delete-emptydir-data
# Mettre à jour le nœud (OS + kubelet + kubectl)
# ...
kubectl uncordon node-1 # Remettre le nœud en service
# Stratégie 2 : Blue/Green cluster (recommandée pour les mises à jour majeures)
# 1. Créer un nouveau cluster (version N+1)
# 2. Migrer les applications progressivement (canary via DNS/load balancer)
# 3. Basculer le trafic à 100% sur le nouveau cluster
# 4. Supprimer l'ancien cluster
Points clés à retenir — Récapitulatif du livre#
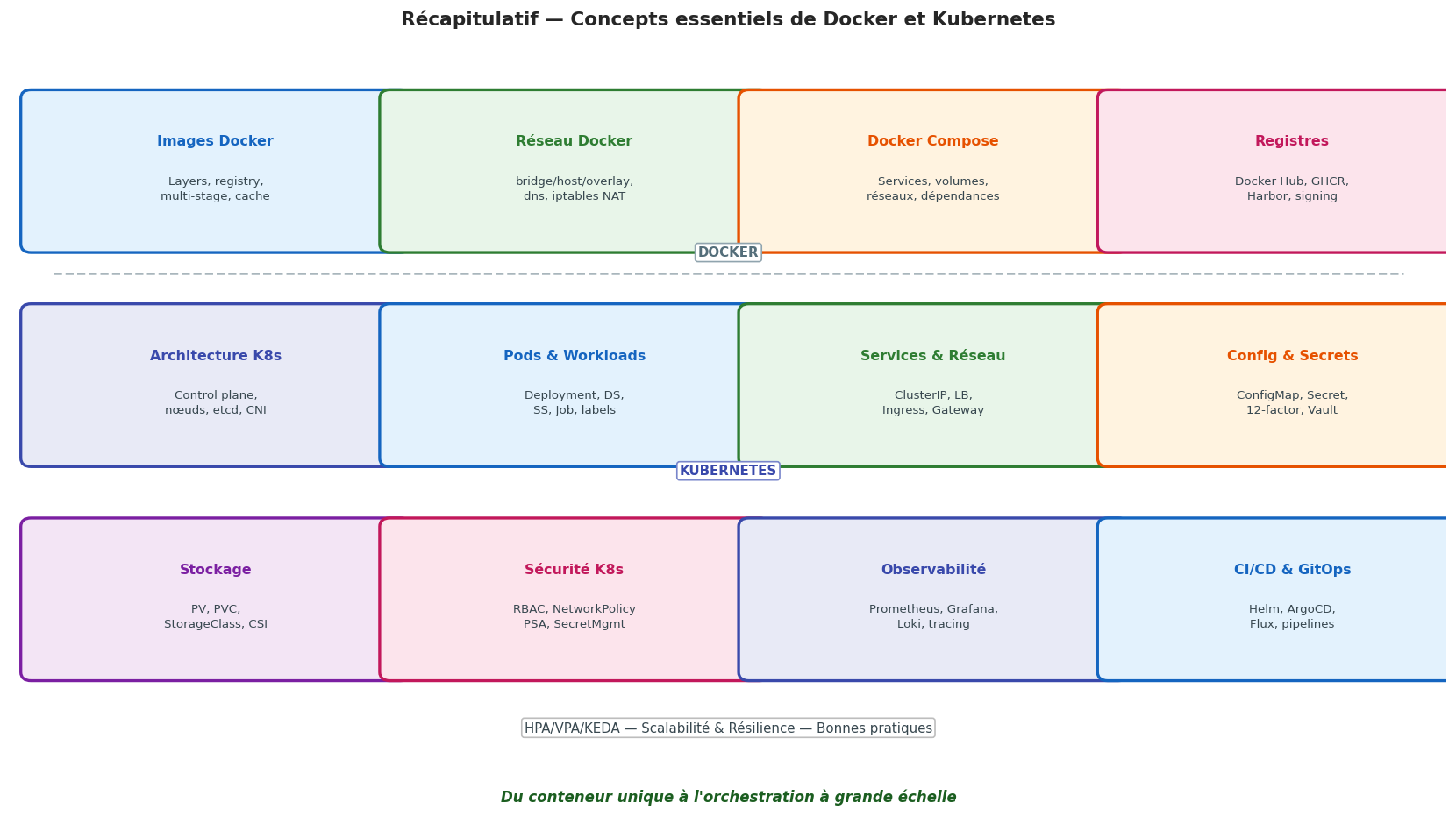
Points clés à retenir#
La checklist Dockerfile : image minimale, multi-stage, utilisateur non-root, HEALTHCHECK, .dockerignore, pas de secrets dans ENV
La checklist Deployment : resources requests+limits, liveness+readiness probes, replicas≥2, SecurityContext, PDB, topologySpreadConstraints
Le sizing des ressources se fait empiriquement : observer d’abord (VPA mode Off), puis configurer —
requests.cpu= P95,requests.mem= P99Les trois probes ont des rôles distincts : liveness redémarre, readiness retire du LB, startup protège le démarrage lent
La séparation config/code (12-factor) est fondamentale : ConfigMaps pour la config, Secrets pour les données sensibles
Optimiser les coûts : spot instances pour les workloads non-critiques, ResourceQuota par namespace, VPA pour éviter le sur-dimensionnement
La mise à jour du cluster : rolling upgrade pour les mises à jour mineures, blue/green cluster pour les mises à jour majeures
La maturité conteneurisation est un chemin progressif : commencer par maîtriser Docker, puis progresser vers K8s, puis vers GitOps et la production complète