Scalabilité et résilience#
Un des atouts majeurs de Kubernetes est sa capacité à adapter automatiquement les ressources à la charge et à maintenir la disponibilité en cas de défaillance. Ce chapitre couvre les mécanismes d’autoscaling (HPA, VPA, KEDA), la résilience (PDB, topologie, affinité) et l’ingénierie du chaos.
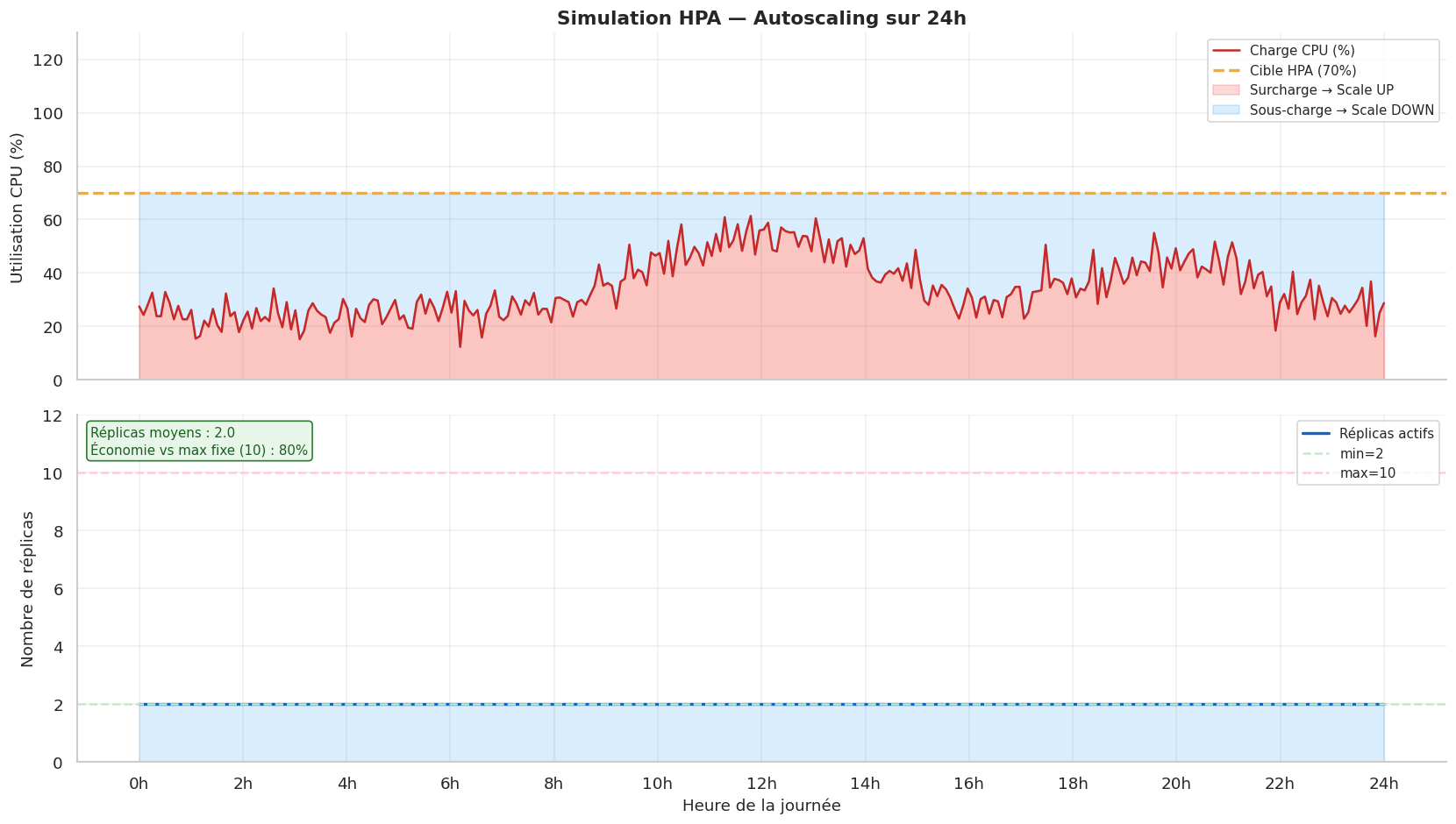
HPA : Horizontal Pod Autoscaler#
Le Horizontal Pod Autoscaler ajuste automatiquement le nombre de réplicas d’un Deployment (ou StatefulSet) en fonction des métriques observées.
Configuration du HPA#
# hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: mon-api-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mon-api
minReplicas: 2 # Jamais en dessous de 2 (haute disponibilité)
maxReplicas: 20 # Jamais au-dessus de 20 (contrôle des coûts)
metrics:
# Scaling basé sur l'utilisation CPU
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # Cible : 70% du CPU request
# Scaling basé sur la mémoire
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
behavior:
# Cooldown avant de réduire (éviter les oscillations)
scaleDown:
stabilizationWindowSeconds: 300 # Attendre 5 min avant de scale down
policies:
- type: Pods
value: 1 # Retirer au plus 1 Pod par fenêtre
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 0 # Scale up immédiat
policies:
- type: Percent
value: 100 # Doubler au maximum par fenêtre
periodSeconds: 15
Algorithme de scaling HPA#
L’algorithme HPA utilise la formule suivante pour calculer le nombre de réplicas désiré :
réplicas_désirés = ceil(réplicas_actuels × (métrique_actuelle / métrique_cible))
import math
def algorithme_hpa(replicas_actuels: int, metrique_actuelle: float,
metrique_cible: float, min_replicas: int,
max_replicas: int) -> int:
"""
Simule l'algorithme de calcul du HPA Kubernetes.
Retourne le nombre de réplicas désiré.
"""
ratio = metrique_actuelle / metrique_cible
replicas_desires = math.ceil(replicas_actuels * ratio)
# Appliquer les bornes min/max
return max(min_replicas, min(max_replicas, replicas_desires))
print("Simulation de l'algorithme HPA")
print("=" * 60)
print(f"Configuration : CPU cible = 70%, min=2, max=20")
print()
print(f"{'CPU actuel':<15} {'Réplicas actuels':<20} {'Réplicas désirés':<20} {'Action'}")
print("-" * 65)
scenarios = [
(35, 5), (50, 5), (65, 5), (70, 5), (85, 5), (95, 5), (110, 5),
(140, 10), (30, 10), (20, 8), (15, 4),
]
resultats = []
for cpu_actuel, replicas_actuels in scenarios:
replicas_desires = algorithme_hpa(replicas_actuels, cpu_actuel, 70, 2, 20)
ratio = cpu_actuel / 70
if replicas_desires > replicas_actuels:
action = f"↑ Scale UP : +{replicas_desires - replicas_actuels}"
elif replicas_desires < replicas_actuels:
action = f"↓ Scale DOWN : -{replicas_actuels - replicas_desires}"
else:
action = "= Stable"
print(f" {cpu_actuel}%{'':<12} {replicas_actuels:<20} {replicas_desires:<20} {action}")
resultats.append((cpu_actuel, replicas_actuels, replicas_desires))
Simulation de l'algorithme HPA
============================================================
Configuration : CPU cible = 70%, min=2, max=20
CPU actuel Réplicas actuels Réplicas désirés Action
-----------------------------------------------------------------
35% 5 3 ↓ Scale DOWN : -2
50% 5 4 ↓ Scale DOWN : -1
65% 5 5 = Stable
70% 5 5 = Stable
85% 5 7 ↑ Scale UP : +2
95% 5 7 ↑ Scale UP : +2
110% 5 8 ↑ Scale UP : +3
140% 10 20 ↑ Scale UP : +10
30% 10 5 ↓ Scale DOWN : -5
20% 8 3 ↓ Scale DOWN : -5
15% 4 2 ↓ Scale DOWN : -2
VPA : Vertical Pod Autoscaler#
Le Vertical Pod Autoscaler recommande (ou applique) les bons requests et limits pour les conteneurs, basés sur l’utilisation réelle.
# vpa.yaml
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: mon-api-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: mon-api
updatePolicy:
updateMode: "Off" # Off = recommandations seulement (ne touche pas aux Pods)
# "Initial" = applique au démarrage des Pods
# "Auto" = redémarre les Pods pour appliquer les changements
# "Off" = recommandations uniquement → idéal pour démarrer avec VPA
resourcePolicy:
containerPolicies:
- containerName: "*"
minAllowed:
cpu: "50m"
memory: "64Mi"
maxAllowed:
cpu: "2"
memory: "2Gi"
# Voir les recommandations VPA
kubectl describe vpa mon-api-vpa
# Résultat :
# Recommendation:
# Container Recommendations:
# Container Name: app
# Lower Bound: cpu: 50m, memory: 128Mi
# Target: cpu: 250m, memory: 512Mi ← recommandation principale
# Upper Bound: cpu: 1, memory: 1Gi
HPA + VPA : compatibilité
Ne pas utiliser HPA (basé CPU) et VPA (mode Auto) ensemble sur le même Deployment — ils entrent en conflit. La bonne pratique est :
VPA en mode
Offpour des recommandations de sizing initialHPA pour le scaling horizontal en production
Ou KEDA (événementiel) qui peut compléter les deux
KEDA : scaling basé sur les événements#
KEDA (Kubernetes Event-Driven Autoscaling) permet de scaler des Deployments basé sur des métriques externes : longueur d’une file de messages, lag Kafka, requêtes HTTP en attente…
# keda-scaledobject.yaml — Scaler selon la longueur d'une file RabbitMQ
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: worker-scaler
spec:
scaleTargetRef:
name: worker-deployment
minReplicaCount: 0 # Peut descendre à 0 ! (scale to zero)
maxReplicaCount: 50
triggers:
- type: rabbitmq
metadata:
queueName: "taches-a-traiter"
mode: QueueLength
value: "10" # 1 réplica pour 10 messages en attente
host: amqp://rabbitmq.production.svc:5672/
# Trigger basé sur le cron (en plus de la file)
- type: cron
metadata:
timezone: Europe/Paris
start: "0 8 * * 1-5" # Lundi-vendredi 8h : pré-chauffer
end: "0 20 * * 1-5"
desiredReplicas: "3"
Cluster Autoscaler : ajouter des nœuds automatiquement#
Le Cluster Autoscaler surveille les Pods en état Pending (aucun nœud disponible pour les placer) et ajoute automatiquement des nœuds via l’API du cloud provider.
# Installer le Cluster Autoscaler (exemple GKE)
# Les fournisseurs cloud ont des intégrations natives :
# GKE : Node Auto-provisioning intégré
# EKS : Cluster Autoscaler ou Karpenter
# AKS : Cluster Autoscaler intégré
# Annoter le node group pour l'autoscaling
kubectl annotate nodegroup mon-node-group \
cluster-autoscaler.kubernetes.io/node-template/label/node-type=general
# Vérifier les décisions du Cluster Autoscaler
kubectl logs -n kube-system -l app=cluster-autoscaler --tail=50
PodDisruptionBudget : disponibilité pendant les maintenances#
Un PodDisruptionBudget (PDB) garantit qu’un certain nombre minimum de Pods reste disponible lors des disruptions volontaires (mise à jour de nœud, drain pour maintenance…).
# pdb.yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mon-api-pdb
spec:
# Option 1 : nombre minimum de Pods disponibles
minAvailable: 2
# Option 2 : nombre maximum de Pods indisponibles
# maxUnavailable: 1
selector:
matchLabels:
app: mon-api
# Lors d'un drain de nœud, le PDB est respecté
kubectl drain node-1 --ignore-daemonsets
# Si le PDB l'empêche, kubectl drain attend que les conditions soient réunies
Quand le PDB est-il utile ?
Le PDB protège contre les disruptions volontaires (maintenance, mise à jour K8s, redimensionnement du cluster), pas contre les pannes matérielles. Configurez un PDB pour tout service qui ne doit pas descendre à 0 réplica pendant les opérations de maintenance.
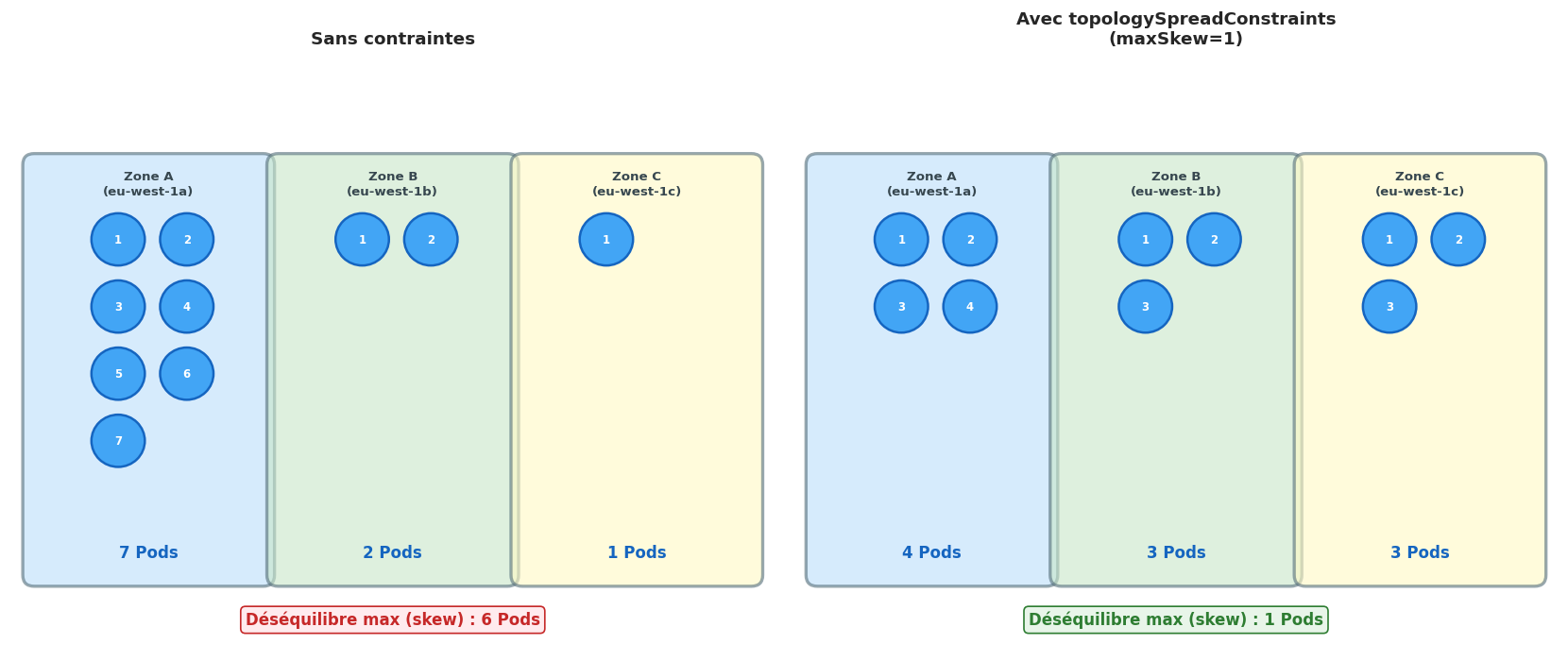
topologySpreadConstraints : distribution géographique#
Les topologySpreadConstraints permettent de distribuer les Pods de manière équilibrée sur des zones de disponibilité ou des nœuds.
# deployment avec spread contraints
spec:
template:
spec:
topologySpreadConstraints:
# Distribuer sur les zones de disponibilité
- maxSkew: 1 # Différence max de 1 Pod entre zones
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule # Refuser si non satisfait
labelSelector:
matchLabels:
app: mon-api
# Distribuer aussi entre les nœuds
- maxSkew: 2
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway # Essayer mais ne pas bloquer
labelSelector:
matchLabels:
app: mon-api
Affinity et anti-affinity#
Les règles d”affinity et d”anti-affinity contrôlent plus finement le placement des Pods.
spec:
affinity:
# Anti-affinity : éviter que deux Pods de la même app soient sur le même nœud
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # Règle dure (obligatoire)
- labelSelector:
matchLabels:
app: mon-api
topologyKey: kubernetes.io/hostname
# Affinity nœud : préférer les nœuds avec des SSDs
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution: # Règle souple (préférence)
- weight: 80
preference:
matchExpressions:
- key: storage-type
operator: In
values: ["ssd"]
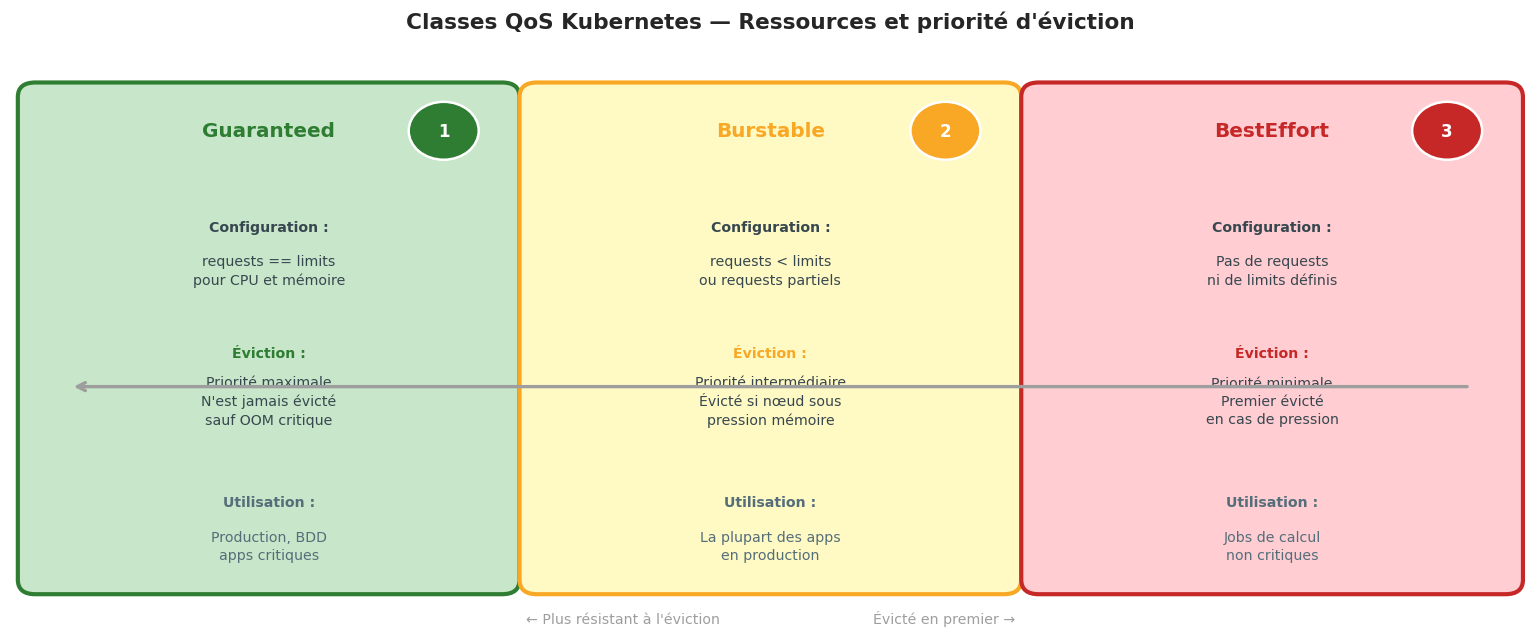
QoS Classes : garanties de ressources#
Kubernetes classe les Pods en trois catégories de Qualité de Service selon leurs requests et limits.
Chaos Engineering : tester la résilience#
L”ingénierie du chaos consiste à introduire volontairement des défaillances pour vérifier que le système reste résilient.
Principe de Chaos Engineering
« Identifier les faiblesses du système avant qu’une panne réelle ne les révèle. »
Processus :
Définir l’état stable (métriques nominales : latence P99, taux d’erreur…)
Formuler une hypothèse (« Si je tue 30% des Pods, le service reste disponible »)
Injecter la défaillance en production ou staging
Observer si l’hypothèse est vérifiée
Corriger si non
Outils de chaos engineering pour Kubernetes :
# Chaos Mesh — injection de pannes dans K8s
kubectl apply -f https://mirrors.chaos-mesh.org/v2.6.1/install.yaml
# Exemple : tuer des Pods aléatoirement (comme Netflix Chaos Monkey)
# podcast-kill.yaml
# chaos-pod-kill.yaml
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: kill-api-pods
spec:
action: pod-kill
mode: one # Tuer 1 Pod aléatoire parmi le sélecteur
selector:
namespaces: ["production"]
labelSelectors:
app: mon-api
scheduler:
cron: "@every 10m" # Toutes les 10 minutes
# chaos-network-latency.yaml — Injecter de la latence réseau
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: latence-api-db
spec:
action: delay
mode: all
selector:
labelSelectors:
app: mon-api
delay:
latency: "200ms" # Ajouter 200ms de latence
correlation: "50"
jitter: "50ms"
direction: to
target:
selector:
labelSelectors:
app: postgres
duration: "5m"
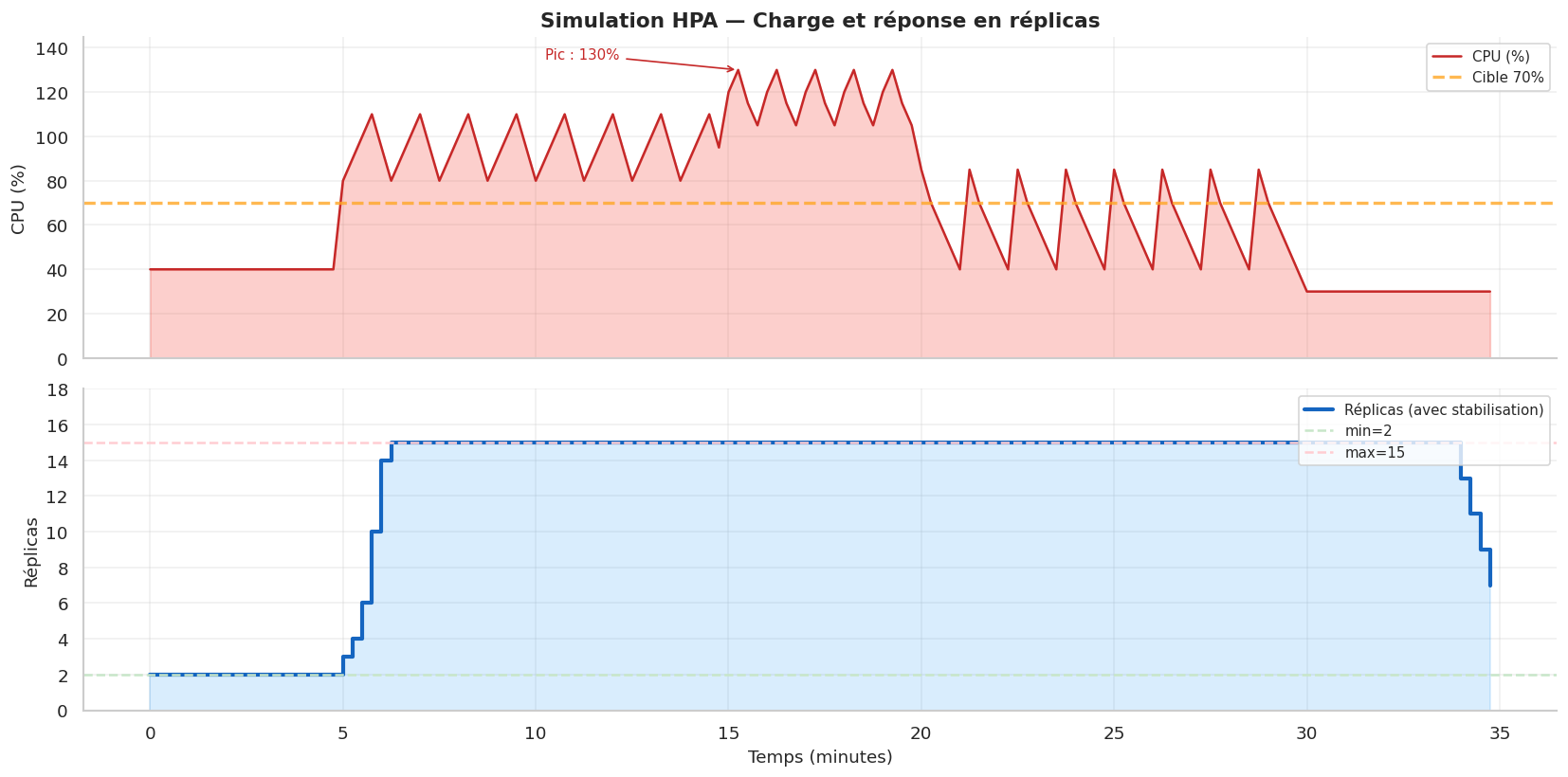
Simulation Python : algorithme HPA et simulation de chaos#
import random
import math
from dataclasses import dataclass, field
from typing import List, Tuple
@dataclass
class SimulateurHPA:
"""Simulation complète d'un HPA avec stabilisation et cooldown."""
nom: str
min_replicas: int
max_replicas: int
cible_cpu: float # Cible en % (ex: 70)
stabilisation_scale_down: int # Secondes de cooldown avant scale down
tick_secondes: int = 15 # Intervalle de réévaluation
def simuler(self, charges: List[float]) -> Tuple[List[float], List[int]]:
"""
Simule le comportement du HPA sur une série de charges CPU.
Retourne (charges, réplicas_par_tick).
"""
replicas = self.min_replicas
historique_replicas = []
fenetre_stabilisation = [] # Historique pour le cooldown
for charge in charges:
# Calcul du nombre désiré
desires = math.ceil(replicas * (charge / self.cible_cpu))
desires = max(self.min_replicas, min(self.max_replicas, desires))
# Stabilisation au scale down : prendre le max sur la fenêtre
fenetre_stabilisation.append(desires)
ticks_stabilisation = self.stabilisation_scale_down // self.tick_secondes
if len(fenetre_stabilisation) > ticks_stabilisation:
fenetre_stabilisation.pop(0)
if desires < replicas:
# Scale down : utiliser le max de la fenêtre (conservateur)
desires = max(fenetre_stabilisation)
# Scale up : immédiat
replicas = desires
historique_replicas.append(replicas)
return charges, historique_replicas
@dataclass
class SimulateurChaos:
"""Simulation de l'impact du chaos engineering sur un service."""
def simuler_pod_kill(self, n_replicas: int, n_tues: int) -> dict:
"""Simule le kill de n_tues Pods et le retour à l'état normal."""
disponibles = n_replicas - n_tues
taux_disponibilite = disponibles / n_replicas * 100
# Temps de récupération estimé (création d'un nouveau Pod)
temps_recovery_s = 30 + random.randint(5, 20) # 30-50s typique
return {
"replicas_avant": n_replicas,
"pods_tues": n_tues,
"disponibles_pendant_chaos": disponibles,
"taux_disponibilite": taux_disponibilite,
"temps_recovery_s": temps_recovery_s,
"impact_service": "MAJEUR" if taux_disponibilite < 50
else ("MODÉRÉ" if taux_disponibilite < 80 else "FAIBLE"),
}
def simuler_latence_reseau(self, latence_ajoutee_ms: float,
latence_baseline_ms: float,
timeout_ms: float) -> dict:
"""Simule l'impact d'une injection de latence réseau."""
latence_totale = latence_baseline_ms + latence_ajoutee_ms
taux_timeout = max(0, (latence_totale - timeout_ms * 0.8) / timeout_ms) * 100
return {
"latence_baseline": f"{latence_baseline_ms}ms",
"latence_ajoutee": f"+{latence_ajoutee_ms}ms",
"latence_totale": f"{latence_totale}ms",
"timeout_config": f"{timeout_ms}ms",
"taux_timeout_estime": f"{min(100, taux_timeout):.1f}%",
"recommandation": "Augmenter le timeout ou optimiser les requêtes DB"
if taux_timeout > 10 else "Système résilient à cette latence",
}
# Test HPA
hpa_sim = SimulateurHPA(
nom="api-hpa",
min_replicas=2,
max_replicas=15,
cible_cpu=70,
stabilisation_scale_down=300, # 5 minutes
tick_secondes=15,
)
# Charges simulées (288 ticks = 72 minutes à 15s/tick)
charges_test = (
[40] * 20 + # Charge normale
[80, 90, 100, 110, 95] * 8 + # Montée en charge
[120, 130, 115, 105] * 5 + # Pic
[85, 70, 60, 50, 40] * 8 + # Redescente
[30] * 20 # Calme
)
charges, replicas = hpa_sim.simuler(charges_test)
# Tests chaos
chaos = SimulateurChaos()
print("=" * 55)
print("Simulation de Chaos Engineering")
print("=" * 55)
for n_replicas, n_tues in [(5, 1), (5, 2), (5, 3), (10, 3), (2, 1)]:
res = chaos.simuler_pod_kill(n_replicas, n_tues)
print(f"\n Kill {n_tues}/{n_replicas} Pods :")
print(f" Disponibilité : {res['taux_disponibilite']:.0f}% — Impact : {res['impact_service']}")
print(f" Recovery estimé : {res['temps_recovery_s']}s")
print("\n--- Injection de latence ---")
for latence in [50, 150, 300, 500]:
res = chaos.simuler_latence_reseau(latence, 20, 500)
print(f" +{latence}ms : latence totale {res['latence_totale']}, "
f"timeout estimé : {res['taux_timeout_estime']}")
if float(res["taux_timeout_estime"].rstrip("%")) > 10:
print(f" → {res['recommandation']}")
=======================================================
Simulation de Chaos Engineering
=======================================================
Kill 1/5 Pods :
Disponibilité : 80% — Impact : FAIBLE
Recovery estimé : 38s
Kill 2/5 Pods :
Disponibilité : 60% — Impact : MODÉRÉ
Recovery estimé : 35s
Kill 3/5 Pods :
Disponibilité : 40% — Impact : MAJEUR
Recovery estimé : 43s
Kill 3/10 Pods :
Disponibilité : 70% — Impact : MODÉRÉ
Recovery estimé : 42s
Kill 1/2 Pods :
Disponibilité : 50% — Impact : MODÉRÉ
Recovery estimé : 42s
--- Injection de latence ---
+50ms : latence totale 70ms, timeout estimé : 0.0%
+150ms : latence totale 170ms, timeout estimé : 0.0%
+300ms : latence totale 320ms, timeout estimé : 0.0%
+500ms : latence totale 520ms, timeout estimé : 24.0%
→ Augmenter le timeout ou optimiser les requêtes DB
Points clés à retenir#
Le HPA scale horizontalement (nombre de Pods) en fonction de métriques (CPU, mémoire, custom) avec
stabilizationWindowSecondspour éviter les oscillationsLe VPA recommande les bons
requests/limits— commencer en modeOffpour observer, avant de passer en modeInitialouAutoKEDA permet le scale-to-zero et le scaling basé sur des métriques externes (queues, Kafka, cron) que HPA ne supporte pas nativement
Le PodDisruptionBudget garantit qu’un minimum de Pods reste disponible pendant les maintenances volontaires
topologySpreadConstraints distribue les Pods équitablement sur les zones de disponibilité — essentiel pour la résilience multi-zone
Les classes QoS (Guaranteed/Burstable/BestEffort) déterminent l’ordre d’éviction en cas de pression mémoire — utiliser Guaranteed pour les services critiques
L”ingénierie du chaos (Chaos Mesh, Litmus) permet de valider la résilience avant qu’une vraie panne ne le fasse