11 — Services et réseau Kubernetes#
Le problème des IPs éphémères#
Imaginons un Pod comme un locataire d’appartement. À chaque fois qu’il déménage (redémarrage, mise à jour, crash), il reçoit une nouvelle adresse IP. Si d’autres Pods communiquaient directement avec cette IP, ils perdraient le contact à chaque redémarrage.
C’est exactement le problème que résout le Service Kubernetes.
Analogie : la boîte postale
Un Service, c’est comme une boîte postale à adresse fixe. Peu importe combien de fois le destinataire déménage (les Pods changent d’IP), le courrier arrive toujours à la bonne boîte. C’est le Service qui fait le tri et achemine vers les Pods actifs.
Le Service Kubernetes#
Un Service est une abstraction stable qui définit :
Un sélecteur de labels : quels Pods sont ciblés
Une ClusterIP virtuelle : adresse stable, inchangée tant que le Service existe
Des ports : mapping port du Service → port du Pod
apiVersion: v1
kind: Service
metadata:
name: mon-app
namespace: production
spec:
selector:
app: mon-app # Sélectionne les Pods avec ce label
version: stable
ports:
- name: http
port: 80 # Port du Service (stable)
targetPort: 8080 # Port du Pod (conteneur)
protocol: TCP
type: ClusterIP
kube-proxy : le routeur de Kubernetes#
Sur chaque nœud tourne un composant essentiel : kube-proxy. Son rôle est de programmer les règles réseau pour que le trafic vers une ClusterIP soit redirigé vers l’un des Pods réels.
Comment fonctionne kube-proxy ?
kube-proxy surveille l’API Server. Dès qu’un Service est créé ou modifié, il met à jour les règles du noyau Linux (iptables ou IPVS) sur le nœud. Le trafic ne passe jamais « par » kube-proxy en production — ce composant ne fait que configurer les règles, le noyau fait le routage directement.
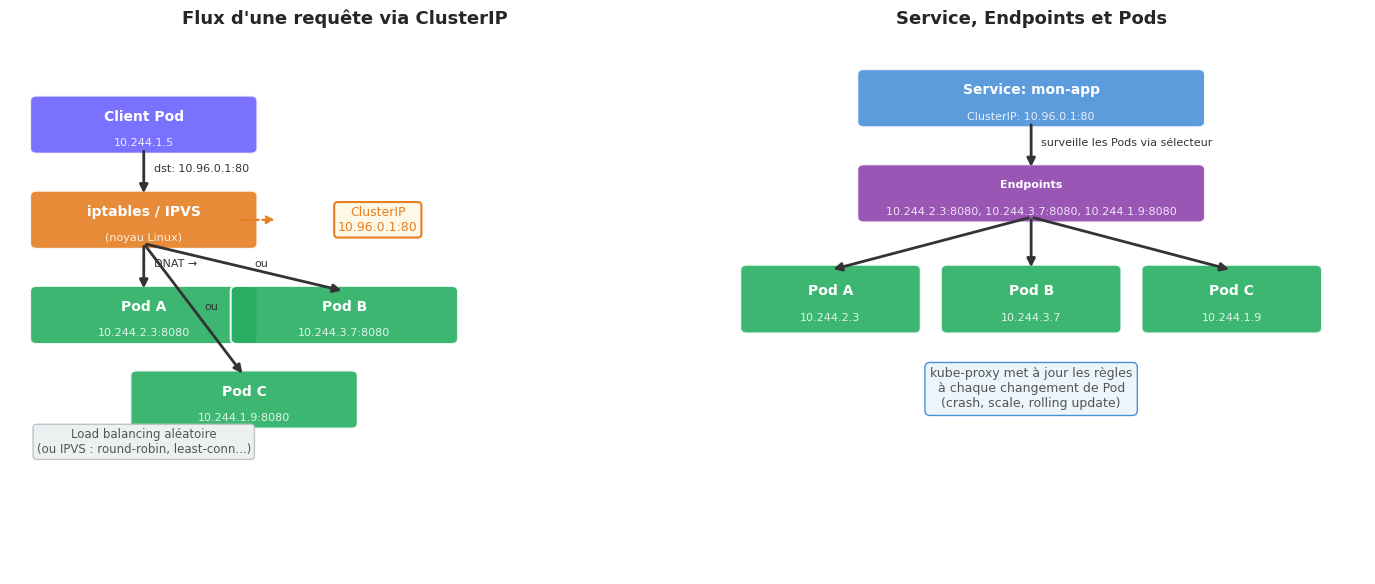
Les quatre types de Services#
Kubernetes propose quatre saveurs de Service, adaptées à des cas d’usage différents.
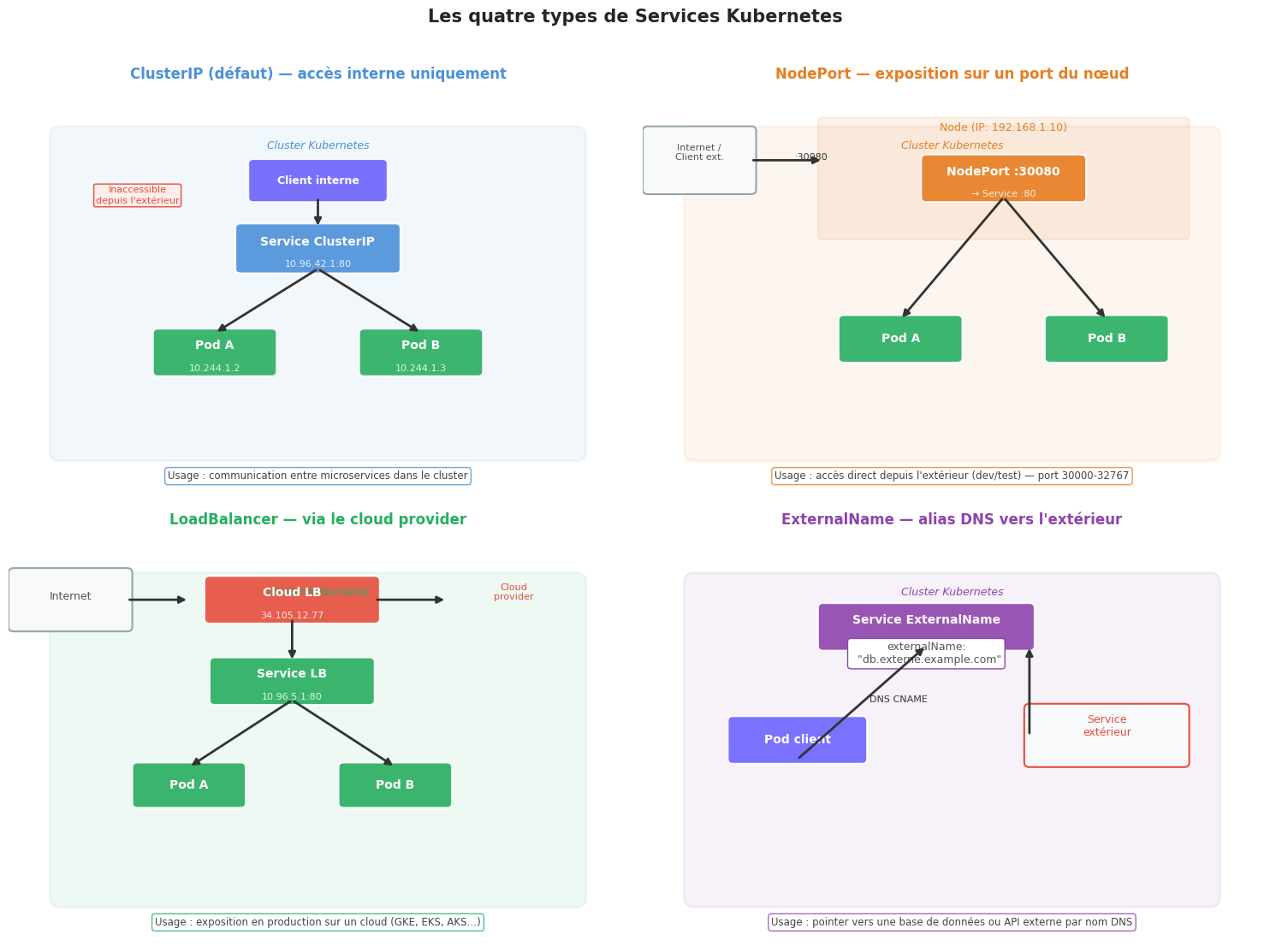
Comparatif des types de Services#
Type |
Accès |
ClusterIP ? |
Cas d’usage |
|---|---|---|---|
ClusterIP |
Interne uniquement |
Oui (virtuelle) |
Communication inter-services |
NodePort |
NodeIP:30000-32767 |
Oui + NodePort |
Dev/test, accès direct |
LoadBalancer |
IP publique via cloud |
Oui + NodePort + LB |
Production sur cloud |
ExternalName |
DNS CNAME |
Non |
Alias vers services externes |
DNS Kubernetes : CoreDNS#
Kubernetes embarque un serveur DNS interne : CoreDNS. Il permet de joindre un Service par nom plutôt que par IP.
Le format complet d’un nom DNS de Service est :
<nom-service>.<namespace>.svc.cluster.local
Par exemple, mon-app.production.svc.cluster.local résout vers la ClusterIP du Service mon-app dans le namespace production.
Raccourcis DNS
Depuis le même namespace, on peut utiliser juste mon-app (sans suffixe). Depuis un autre namespace, il faut au minimum mon-app.production. Le suffixe complet .svc.cluster.local est toujours valide quel que soit le contexte.
# Tester la résolution DNS depuis un Pod
kubectl run -it --rm dns-test --image=busybox --restart=Never -- nslookup mon-app.production
# Résultat attendu :
# Server: 10.96.0.10 (CoreDNS)
# Address: 10.96.0.10:53
# Name: mon-app.production.svc.cluster.local
# Address: 10.96.42.1
Endpoints et EndpointSlices#
Quand un Service est créé avec un sélecteur, Kubernetes crée automatiquement un objet Endpoints qui liste les IPs et ports des Pods correspondants.
# Voir les Endpoints d'un Service
kubectl get endpoints mon-app -n production
# NAME ENDPOINTS AGE
# mon-app 10.244.1.2:8080,10.244.2.5:8080,10.244.3.1:8080 5d
Pour les clusters de grande taille, les EndpointSlices (depuis K8s 1.21) découpent les Endpoints en tranches de 100 entrées maximum pour améliorer les performances.
# Exemple d'EndpointSlice (géré automatiquement par K8s)
apiVersion: discovery.k8s.io/v1
kind: EndpointSlice
metadata:
name: mon-app-abc12
labels:
kubernetes.io/service-name: mon-app
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 8080
endpoints:
- addresses: ["10.244.1.2"]
conditions:
ready: true
nodeName: node-1
- addresses: ["10.244.2.5"]
conditions:
ready: true
nodeName: node-2
kube-proxy : trois modes de fonctionnement#
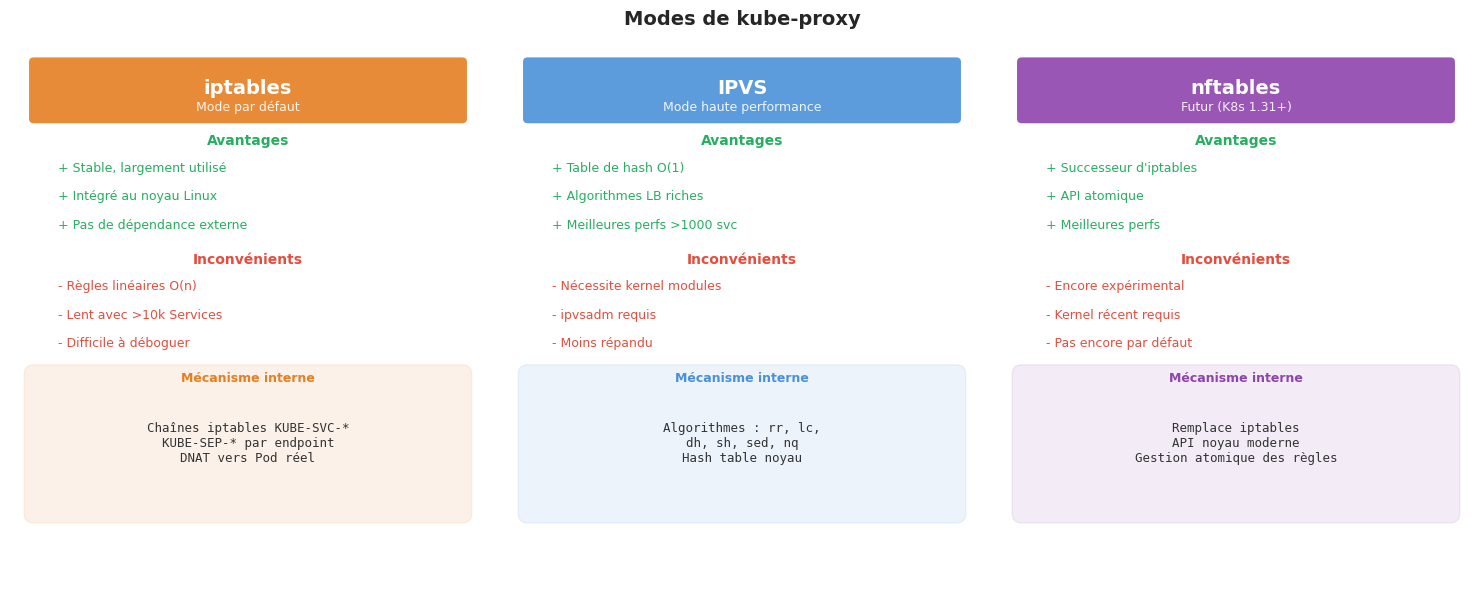
Simulation d’un load balancer kube-proxy (iptables)#
Pour comprendre comment kube-proxy programme les règles iptables, simulons en Python le processus de sélection d’un endpoint.
import random
import hashlib
import json
from collections import defaultdict
# Simulation des règles iptables générées par kube-proxy
# pour un Service avec 3 Pods
class KubeProxySimulator:
"""Simule les règles iptables de kube-proxy pour un Service."""
def __init__(self, service_name, cluster_ip, port):
self.service_name = service_name
self.cluster_ip = cluster_ip
self.port = port
self.endpoints = []
self.rules = {} # Simule les chaînes iptables KUBE-SVC-*
self._stats = defaultdict(int)
def add_endpoint(self, pod_name, pod_ip, pod_port):
"""Ajoute un endpoint (Pod prêt à recevoir du trafic)."""
self.endpoints.append({
"pod": pod_name,
"ip": pod_ip,
"port": pod_port,
})
self._build_iptables_rules()
def remove_endpoint(self, pod_name):
"""Retire un endpoint (Pod crashé ou en cours d'arrêt)."""
self.endpoints = [e for e in self.endpoints if e["pod"] != pod_name]
self._build_iptables_rules()
def _build_iptables_rules(self):
"""
Reconstruit les règles iptables.
iptables utilise une probabilité 1/n pour chaque endpoint :
- 1er endpoint : probabilité 1/3
- 2ème endpoint : probabilité 1/2 (des 2/3 restants)
- 3ème endpoint : probabilité 1/1 (le reste)
"""
n = len(self.endpoints)
if n == 0:
self.rules = {}
return
rules = []
for i, ep in enumerate(self.endpoints):
# Règle KUBE-SEP-* (Service EndPoint)
sep_name = f"KUBE-SEP-{hashlib.md5(ep['ip'].encode()).hexdigest()[:8].upper()}"
remaining = n - i
probability = round(1.0 / remaining, 4)
rules.append({
"chain": f"KUBE-SVC-{self.service_name[:8].upper()}",
"sep_chain": sep_name,
"probability": probability,
"dnat_target": f"{ep['ip']}:{ep['port']}",
"pod": ep["pod"],
})
self.rules = {
"service_chain": f"KUBE-SVC-{self.service_name[:8].upper()}",
"cluster_ip": f"{self.cluster_ip}:{self.port}",
"endpoints": rules,
}
def route_packet(self, src_ip="10.244.0.1"):
"""Simule le routage d'un paquet via les règles iptables."""
if not self.endpoints:
return None, "REJECT — aucun endpoint disponible"
# Sélection probabiliste (comme iptables statistic --mode random)
n = len(self.endpoints)
selected = None
for i, ep in enumerate(self.endpoints):
remaining = n - i
prob = 1.0 / remaining
if random.random() < prob:
selected = ep
break
if not selected:
selected = self.endpoints[-1]
self._stats[selected["pod"]] += 1
return selected, f"DNAT {self.cluster_ip}:{self.port} → {selected['ip']}:{selected['port']}"
def print_rules(self):
"""Affiche les règles iptables simulées."""
if not self.rules:
print("Aucune règle (pas d'endpoint)")
return
print(f"\n{'='*60}")
print(f"Chaîne : {self.rules['service_chain']}")
print(f"ClusterIP : {self.rules['cluster_ip']}")
print(f"{'='*60}")
for rule in self.rules["endpoints"]:
print(f" -A {rule['chain']} -m statistic --mode random "
f"--probability {rule['probability']:.4f} "
f"-j {rule['sep_chain']}")
print(f" → DNAT vers {rule['dnat_target']} ({rule['pod']})")
print(f"{'='*60}\n")
# Création du simulateur
sim = KubeProxySimulator("mon-app", "10.96.0.1", 80)
# Ajout des Pods initiaux
sim.add_endpoint("pod-a", "10.244.1.2", 8080)
sim.add_endpoint("pod-b", "10.244.2.5", 8080)
sim.add_endpoint("pod-c", "10.244.3.1", 8080)
print("=== Règles iptables générées par kube-proxy ===")
sim.print_rules()
# Simulation de 300 requêtes
print("Simulation de 300 requêtes...")
for _ in range(300):
sim.route_packet()
print("Distribution du trafic :")
total = sum(sim._stats.values())
for pod, count in sorted(sim._stats.items()):
pct = count / total * 100
bar = "█" * int(pct / 2)
print(f" {pod:10s}: {count:4d} ({pct:.1f}%) {bar}")
# Simulation d'un crash de pod-b
print("\n--- Pod-b crash ! Mise à jour des règles... ---")
sim.remove_endpoint("pod-b")
sim.print_rules()
print("Simulation de 100 requêtes supplémentaires (sans pod-b)...")
sim._stats.clear()
for _ in range(100):
sim.route_packet()
print("Distribution après crash de pod-b :")
total = sum(sim._stats.values())
for pod, count in sorted(sim._stats.items()):
pct = count / total * 100
bar = "█" * int(pct / 2)
print(f" {pod:10s}: {count:4d} ({pct:.1f}%) {bar}")
=== Règles iptables générées par kube-proxy ===
============================================================
Chaîne : KUBE-SVC-MON-APP
ClusterIP : 10.96.0.1:80
============================================================
-A KUBE-SVC-MON-APP -m statistic --mode random --probability 0.3333 -j KUBE-SEP-1BF1E500
→ DNAT vers 10.244.1.2:8080 (pod-a)
-A KUBE-SVC-MON-APP -m statistic --mode random --probability 0.5000 -j KUBE-SEP-56E5AAE2
→ DNAT vers 10.244.2.5:8080 (pod-b)
-A KUBE-SVC-MON-APP -m statistic --mode random --probability 1.0000 -j KUBE-SEP-9594E920
→ DNAT vers 10.244.3.1:8080 (pod-c)
============================================================
Simulation de 300 requêtes...
Distribution du trafic :
pod-a : 104 (34.7%) █████████████████
pod-b : 88 (29.3%) ██████████████
pod-c : 108 (36.0%) ██████████████████
--- Pod-b crash ! Mise à jour des règles... ---
============================================================
Chaîne : KUBE-SVC-MON-APP
ClusterIP : 10.96.0.1:80
============================================================
-A KUBE-SVC-MON-APP -m statistic --mode random --probability 0.5000 -j KUBE-SEP-1BF1E500
→ DNAT vers 10.244.1.2:8080 (pod-a)
-A KUBE-SVC-MON-APP -m statistic --mode random --probability 1.0000 -j KUBE-SEP-9594E920
→ DNAT vers 10.244.3.1:8080 (pod-c)
============================================================
Simulation de 100 requêtes supplémentaires (sans pod-b)...
Distribution après crash de pod-b :
pod-a : 48 (48.0%) ████████████████████████
pod-c : 52 (52.0%) ██████████████████████████
Calcul du hash IPVS#
En mode IPVS, kube-proxy utilise des tables de hash pour une sélection O(1) des endpoints.
import hashlib
import struct
def ipvs_hash_key(src_ip: str, dst_ip: str, dst_port: int, protocol: int = 6) -> int:
"""
Simule le calcul de clé de hash IPVS pour le load balancing.
En mode 'sh' (Source Hash), le même client va toujours
vers le même serveur (session persistence).
"""
# Conversion IP → entier 32 bits
def ip_to_int(ip):
parts = [int(p) for p in ip.split('.')]
return (parts[0] << 24) | (parts[1] << 16) | (parts[2] << 8) | parts[3]
src_int = ip_to_int(src_ip)
dst_int = ip_to_int(dst_ip)
# Clé combinée (simplifié par rapport à l'implémentation réelle)
key_bytes = struct.pack(">IIIH", src_int, dst_int, 0, dst_port)
hash_val = int(hashlib.md5(key_bytes).hexdigest(), 16)
return hash_val
# Test : 5 clients, 3 serveurs
clients = [f"10.244.{i}.{j}" for i in range(1, 3) for j in range(1, 4)]
servers = [
{"name": "pod-a", "ip": "10.244.10.1"},
{"name": "pod-b", "ip": "10.244.10.2"},
{"name": "pod-c", "ip": "10.244.10.3"},
]
print("Mode IPVS 'sh' (Source Hash) — persistance de session :")
print(f"{'Client IP':<18} {'Hash (mod 3)':<15} {'Serveur sélectionné'}")
print("-" * 55)
assignments = {}
for client in clients:
h = ipvs_hash_key(client, "10.96.0.1", 80)
server_idx = h % len(servers)
server = servers[server_idx]
assignments[client] = server["name"]
print(f" {client:<16} {h % 1000:>8} mod 3 = {server_idx} → {server['name']} ({server['ip']})")
print("\nLe même client va TOUJOURS vers le même Pod (session persistence).")
print("Utile pour : paniers e-commerce, sessions authentifiées, WebSockets.")
Mode IPVS 'sh' (Source Hash) — persistance de session :
Client IP Hash (mod 3) Serveur sélectionné
-------------------------------------------------------
10.244.1.1 807 mod 3 = 0 → pod-a (10.244.10.1)
10.244.1.2 628 mod 3 = 1 → pod-b (10.244.10.2)
10.244.1.3 603 mod 3 = 0 → pod-a (10.244.10.1)
10.244.2.1 675 mod 3 = 1 → pod-b (10.244.10.2)
10.244.2.2 294 mod 3 = 0 → pod-a (10.244.10.1)
10.244.2.3 800 mod 3 = 0 → pod-a (10.244.10.1)
Le même client va TOUJOURS vers le même Pod (session persistence).
Utile pour : paniers e-commerce, sessions authentifiées, WebSockets.
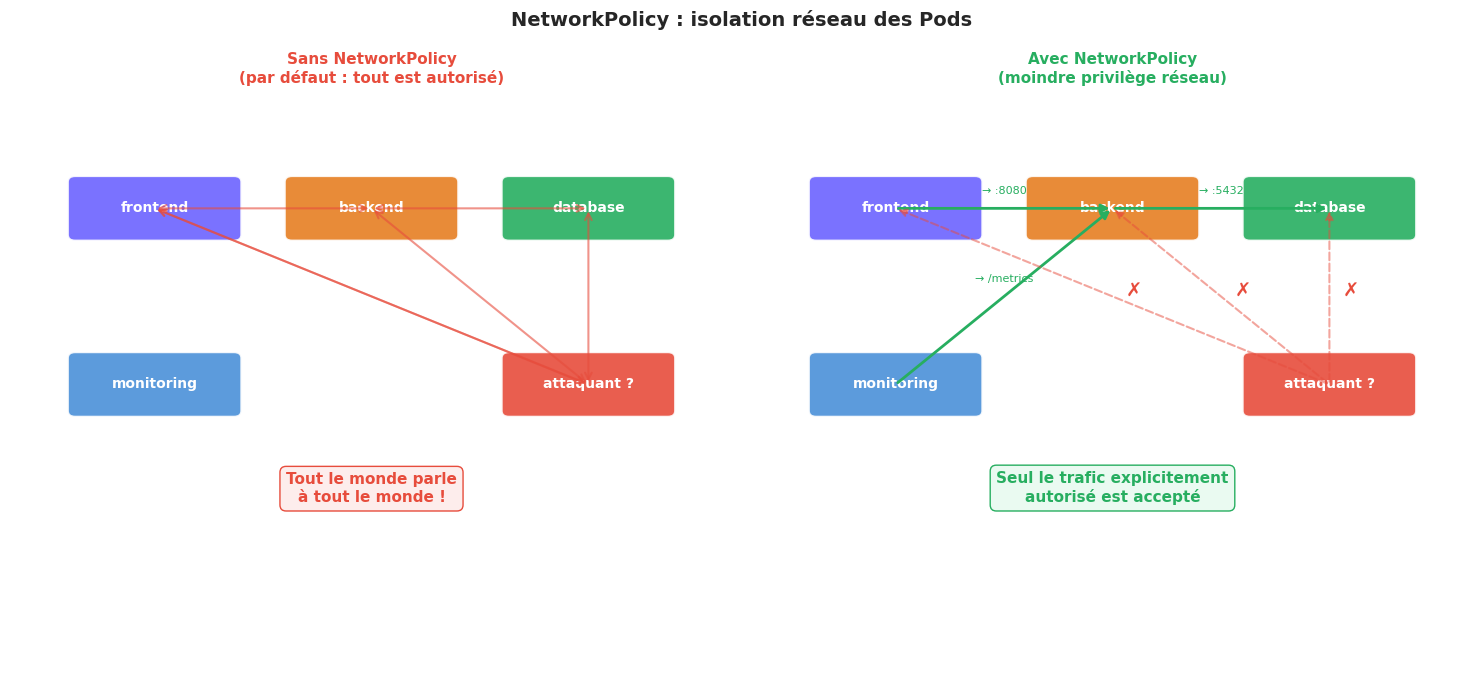
NetworkPolicy : isolation réseau entre Pods#
Par défaut, tous les Pods dans un cluster Kubernetes peuvent communiquer entre eux. C’est pratique au démarrage, mais dangereux en production. Les NetworkPolicy permettent de définir des règles de pare-feu au niveau Pod.
NetworkPolicy nécessite un CNI compatible
Les NetworkPolicy ne fonctionnent que si le plugin CNI installé les supporte. Flannel (simple overlay) ne supporte PAS les NetworkPolicy. Calico, Cilium, Weave Net, et Antrea les supportent.
# Politique : le Pod "backend" n'accepte du trafic entrant
# que depuis les Pods "frontend" du même namespace
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: backend-ingress
namespace: production
spec:
podSelector:
matchLabels:
app: backend # Politique appliquée à ces Pods
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: frontend # Autorise depuis les Pods frontend
ports:
- protocol: TCP
port: 8080
egress:
- to:
- namespaceSelector:
matchLabels:
name: monitoring # Autorise vers le namespace monitoring
ports:
- protocol: TCP
port: 9090
- to: [] # DNS interne (CoreDNS)
ports:
- protocol: UDP
port: 53
CNI Plugins : le réseau sous-jacent#
Le réseau dans Kubernetes repose sur un standard : CNI (Container Network Interface). Chaque cluster doit avoir un plugin CNI installé pour que les Pods obtiennent des adresses IP et puissent communiquer.

Service Mesh : quand les Services ne suffisent plus#
Un service mesh est une couche d’infrastructure qui gère la communication entre microservices de façon transparente, sans modifier le code applicatif.
Analogie : le service mesh comme un réseau téléphonique d’entreprise
Sans service mesh : chaque développeur doit coder lui-même la gestion des timeouts, les retries, le chiffrement TLS, les métriques… C’est comme si chaque employé devait construire son propre téléphone.
Avec un service mesh (Istio, Linkerd) : un proxy sidecar (Envoy) est injecté dans chaque Pod. Il intercepte tout le trafic et gère automatiquement le mTLS, le circuit breaking, le tracing distribué — comme un standard téléphonique d’entreprise.
Les fonctionnalités apportées par un service mesh :
Fonctionnalité |
Sans service mesh |
Avec service mesh |
|---|---|---|
Chiffrement TLS |
Codé dans l’app |
mTLS automatique |
Retries / timeouts |
Codé dans l’app |
Politique déclarative |
Circuit breaker |
Bibliothèque (Hystrix…) |
Proxy transparent |
Tracing distribué |
Instrumentation manuelle |
Automatique (Zipkin, Jaeger) |
Canary deployment |
Logique complexe |
Règle de routage simple |
# Installation d'Istio (exemple)
istioctl install --set profile=demo
# Activation de l'injection automatique du sidecar sur un namespace
kubectl label namespace production istio-injection=enabled
# Après cette étape, chaque Pod créé dans 'production'
# aura automatiquement un conteneur 'istio-proxy' (Envoy)
kubectl get pods -n production
# NAME READY STATUS RESTARTS
# mon-app-5d4f7b-x9j2k 2/2 Running 0
# ^-- 2 conteneurs : l'app + le proxy Envoy
Récapitulatif#

Dans ce chapitre, nous avons vu comment Kubernetes résout le problème des IPs éphémères avec l’abstraction Service, comment kube-proxy programme les règles réseau sur chaque nœud, et comment les NetworkPolicy permettent d’isoler les workloads. Le chapitre suivant aborde la gestion de la configuration et des secrets.