Conteneurs et virtualisation#
Avant d’écrire une seule commande Docker, prenons le temps de comprendre pourquoi les conteneurs existent. Le problème qu’ils résolvent est vieux comme l’informatique : comment garantir qu’un programme qui fonctionne sur la machine du développeur fonctionnera aussi sur le serveur de production, sur la machine d’un collègue, ou dans six mois sur une nouvelle infrastructure ?
L’analogie du conteneur maritime#
En 1956, un transporteur américain nommé Malcolm McLean a révolutionné le commerce mondial avec une idée simple : standardiser les boîtes dans lesquelles on transporte les marchandises. Avant lui, chaque navire avait ses propres caisses, ses propres palettes, ses propres systèmes d’arrimage. Charger un bateau prenait des jours ; les dommages et pertes étaient fréquents.
Avec le conteneur maritime normalisé (20 pieds, 40 pieds), tout change. Une boîte de café du Brésil peut voyager par camion jusqu’au port de Santos, être chargée sans manipulation sur un porte-conteneurs, traverser l’Atlantique, être déchargée au Havre par une grue identique, repartir par train vers Paris — sans que personne n’ouvre la boîte, sans reconditionner quoi que ce soit.
Note
Le conteneur maritime repose sur trois propriétés fondamentales :
Standardisation : toutes les boîtes ont les mêmes dimensions et coins de fixation.
Portabilité : la même boîte fonctionne sur tous les camions, trains et navires compatibles.
Isolation : le contenu de la boîte n’interagit pas avec celui des boîtes voisines.
Le conteneur logiciel reprend exactement ces trois propriétés. Un conteneur Docker empaquette une application et toutes ses dépendances (bibliothèques, fichiers de configuration, variables d’environnement) dans une unité standardisée. Cette unité tourne identiquement sur votre laptop Linux, sur un Mac avec Docker Desktop, sur un serveur cloud, sur un Raspberry Pi. Le runtime Docker (équivalent de la grue portuaire) sait comment démarrer n’importe quel conteneur sans connaître son contenu.
Le problème de l’environnement#
Imaginez cette situation classique : vous développez une application Python qui utilise la bibliothèque cryptography version 41. Sur votre machine, tout fonctionne. Vous envoyez le code à un collègue — il a cryptography version 38 installée globalement et obtient des erreurs d’incompatibilité. Vous déployez sur le serveur de production — le serveur tourne sous Ubuntu 20.04 avec Python 3.8 alors que vous avez Python 3.12. L’application plante pour des raisons qui n’ont rien à voir avec votre code.
Ce problème porte un nom dans le jargon : le syndrome du « ça marche sur ma machine » (works on my machine). Les conteneurs l’éliminent en empaquetant non seulement votre code, mais aussi Python 3.12, cryptography 41, et chaque fichier système dont l’application a besoin.
Machines virtuelles : la première solution#
Avant Docker, la solution standard à ce problème était la machine virtuelle (VM). Une VM émule un ordinateur complet : processeur, mémoire, disque, carte réseau. Un logiciel appelé hyperviseur (VMware, VirtualBox, KVM, Hyper-V) s’exécute sur la machine physique (hôte) et crée des machines virtuelles (invitées).
Chaque VM contient :
Un noyau (kernel) complet de système d’exploitation (Linux, Windows…)
Des pilotes (drivers) pour le matériel virtualisé
Tous les services système (systemd, sshd, cron…)
Votre application et ses dépendances
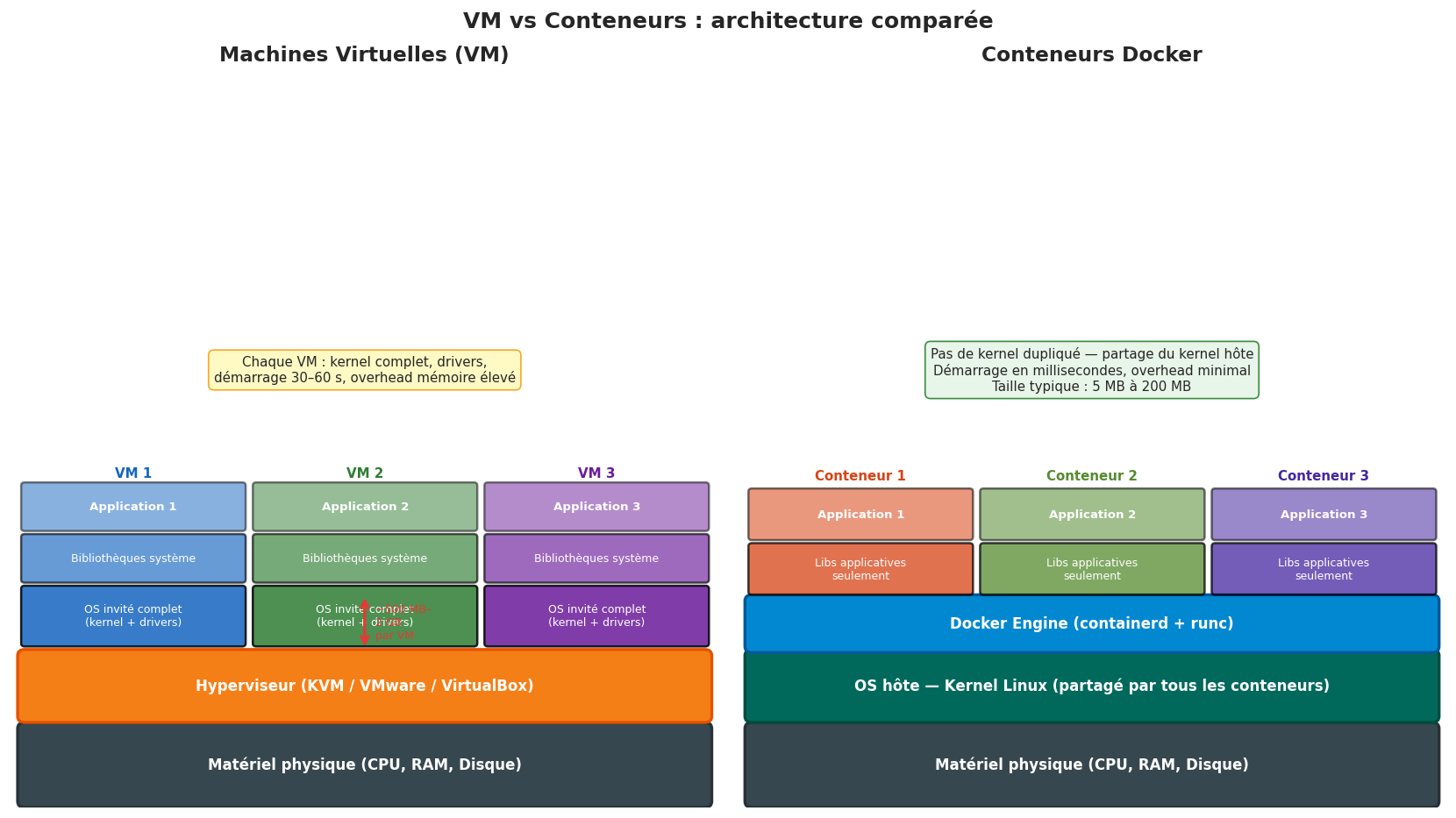
La différence fondamentale est dans la couche de partage. Les VMs dupliquent intégralement le système d’exploitation : chaque VM embarque son propre kernel Linux (ou Windows) complet, ses propres pilotes, ses propres processus système. C’est robuste et offre une isolation forte, mais c’est lourd :
Une VM Ubuntu minimale pèse 800 MB à 2 GB
Elle prend 30 à 60 secondes pour démarrer
Elle consomme de la RAM même lorsqu’elle est inactive (le kernel et les services système tournent en permanence)
Les conteneurs partagent le kernel du système hôte. Il n’y a qu’un seul kernel Linux actif sur la machine ; les conteneurs utilisent ses fonctionnalités via des appels système normaux. En contrepartie, un conteneur Docker ne peut tourner que sur un hôte Linux (ou sur Windows avec un kernel Linux fourni par Docker Desktop, ou sur macOS via une VM Linux légère cachée derrière Docker Desktop).
Technologies Linux sous-jacentes#
Docker n’a pas inventé la magie — il a assemblé de façon élégante des primitives Linux qui existaient déjà. Ces primitives sont les namespaces et les cgroups.
Namespaces : l’isolation#
Un namespace est un mécanisme kernel qui crée une vue partielle et isolée d’une ressource système. Quand un processus vit dans un namespace, il ne voit qu’une portion du système, distincte de ce que voient les autres processus.
Linux propose six namespaces utilisés par Docker :

Namespace PID. Chaque conteneur possède son propre espace de numérotation des processus. À l’intérieur d’un conteneur, le premier processus lancé a toujours le PID 1 — comme si c’était l’init du système. Depuis l’hôte, ce même processus a un PID différent (par exemple 4237). L’isolation est complète : un processus dans le conteneur ne peut pas voir les processus des autres conteneurs ou de l’hôte.
Namespace NET. Chaque conteneur dispose d’une pile réseau entièrement isolée : sa propre interface eth0, sa propre adresse IP, sa propre table de routage, ses propres règles iptables. Deux conteneurs peuvent chacun écouter sur le port 80 sans conflit car ils ont des interfaces réseau distinctes.
Namespace MNT. Chaque conteneur a son propre arbre de fichiers. Ce que le conteneur voit comme / n’est pas le / de l’hôte, mais un système de fichiers construit à partir des couches de l’image Docker (nous verrons cela en détail au chapitre suivant).
Namespace UTS. Chaque conteneur peut avoir son propre hostname. Si vous faites hostname dans un conteneur nommé web-server, vous obtiendrez le nom du conteneur, pas celui de la machine hôte.
Namespace IPC. Isole les mécanismes de communication inter-processus : files de messages POSIX, sémaphores, mémoire partagée. Les processus dans un conteneur ne peuvent pas accéder à la mémoire partagée des processus d’un autre conteneur.
Namespace USER. Permet de mapper les UIDs/GIDs du conteneur vers des UIDs différents sur l’hôte. Avec les user namespaces, le processus qui se croit root (UID 0) dans le conteneur peut en réalité être un utilisateur sans privilèges (UID 65534) sur l’hôte — renforçant considérablement la sécurité.
cgroups : le contrôle des ressources#
Si les namespaces s’occupent de l”isolation (qui voit quoi), les cgroups (control groups) s’occupent du rationnement (qui consomme combien). Les cgroups permettent de limiter, mesurer et prioriser l’utilisation des ressources système par des groupes de processus.
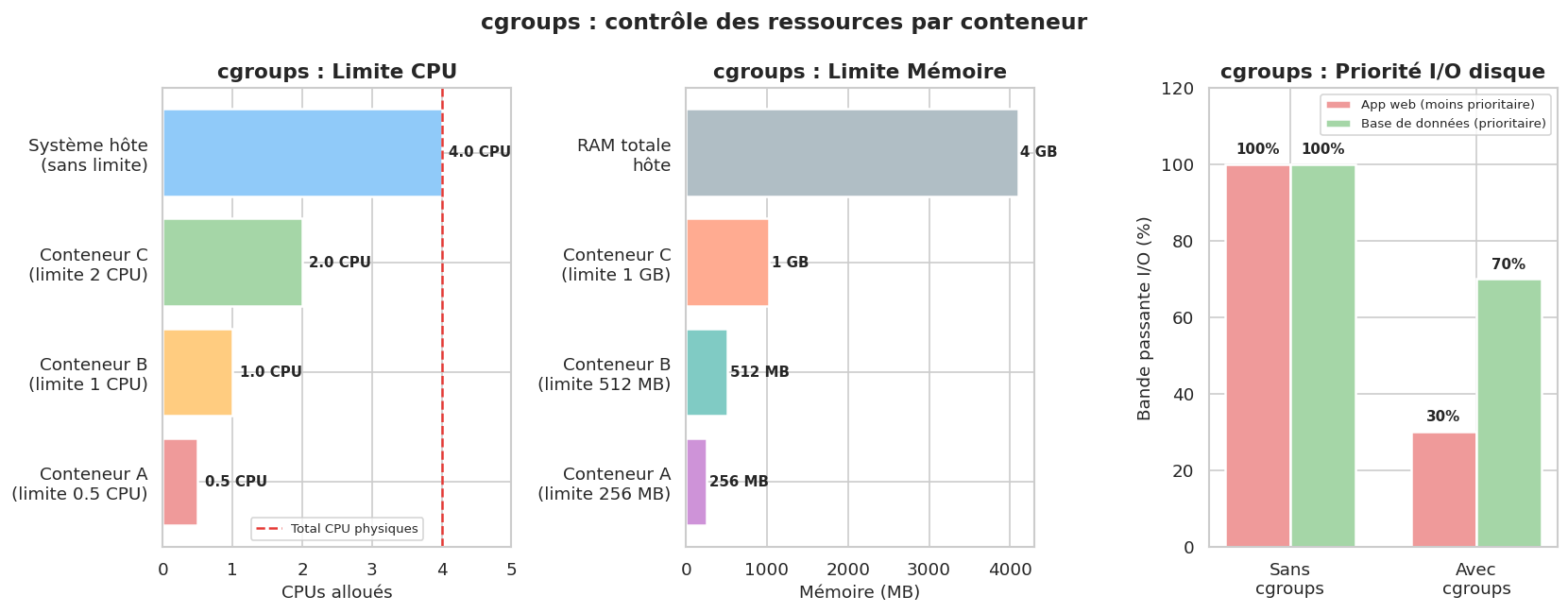
Sans cgroups, n’importe quel conteneur pourrait consommer toute la RAM ou tout le CPU de la machine et affamer les autres. Avec les cgroups, on peut définir :
--memory=512m: le conteneur ne peut pas utiliser plus de 512 MB de RAM--cpus=0.5: le conteneur est limité à la moitié d’un cœur CPU--blkio-weight=300: priorité d’accès disque réduite
Union filesystems et OverlayFS#
La troisième brique technologique fondamentale est l”union filesystem. Imaginez que vous disposez de plusieurs disques transparents (des calques) que vous pouvez empiler : le disque du dessus masque ce qui est en dessous, mais si un calque inférieur contient un fichier absent du calque supérieur, ce fichier est visible à travers. C’est exactement le principe d’OverlayFS.
Une image Docker est composée de couches (layers) en lecture seule, empilées. Quand vous lancez un conteneur, Docker ajoute au sommet une couche en lecture-écriture (la couche conteneur). Toutes les modifications (nouveaux fichiers, modifications, suppressions) vont dans cette couche supérieure. Les couches inférieures (l’image) restent intactes et peuvent être partagées entre plusieurs conteneurs.
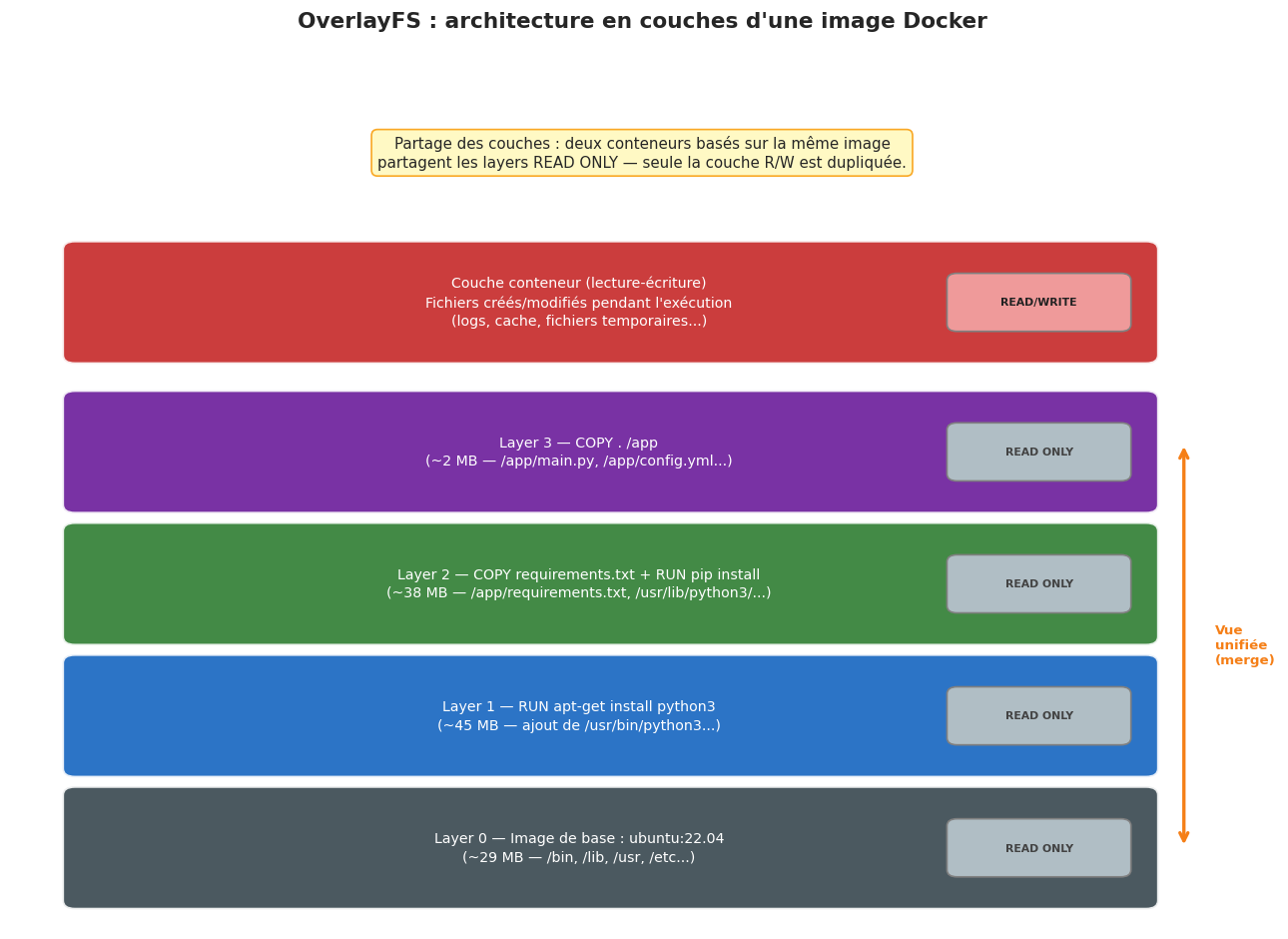
Ce mécanisme apporte plusieurs avantages :
Partage de couches : cent conteneurs basés sur
ubuntu:22.04ne stockent pas cent fois l’image de base — elle est présente une seule fois sur le disque.Rapidité : créer un nouveau conteneur revient à ajouter une couche vide vierge, ce qui est quasi-instantané.
Immuabilité : les modifications dans un conteneur n’affectent jamais l’image sous-jacente.
Histoire : de chroot à containerd#
La conteneurisation n’est pas apparue du jour au lendemain. C’est le résultat de quarante ans d’évolution progressive des mécanismes d’isolation.
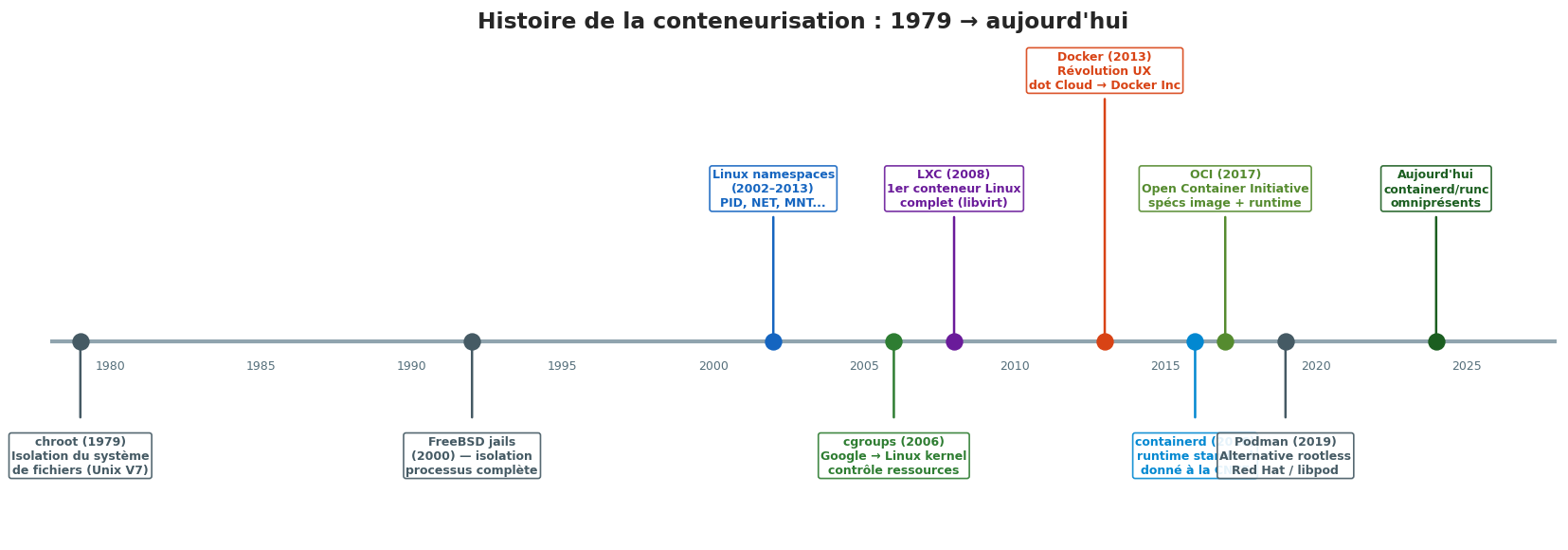
1979 — chroot. La primitive d’isolation la plus ancienne est chroot (change root), introduite dans Unix Version 7. Elle permet de changer le répertoire racine apparent d’un processus : le programme croit que / est en réalité /jails/monapp/. L’isolation est partielle (pas de namespaces réseau ou PID), mais c’est le concept fondateur.
2000 — FreeBSD Jails. FreeBSD introduit les « jails » : une isolation bien plus complète incluant le réseau, les processus et le système de fichiers. C’est le premier vrai système de conteneurisation, mais limité à FreeBSD.
2002–2013 — Linux namespaces. Le kernel Linux intègre progressivement les namespaces : mount (2002), UTS et IPC (2006), PID et réseau (2008), user (2013). Les briques sont en place.
2006 — cgroups. Des ingénieurs de Google (Paul Menage et Rohit Seth) développent les process containers, renommés cgroups et intégrés au kernel Linux 2.6.24 en 2008.
2008 — LXC. Linux Containers (LXC) combine namespaces et cgroups pour offrir le premier système de conteneurs complet sur Linux standard. C’est robuste mais complexe à utiliser.
2013 — Docker. Solomon Hykes présente Docker lors de la PyCon 2013. La révolution n’est pas technique — les briques existaient — mais ergonomique : un Dockerfile simple, une commande docker run, un registre d’images public (Docker Hub). Docker démocratise la conteneurisation.
2016–2017 — Standardisation. Docker fait don de containerd (son runtime interne) à la CNCF. L”OCI (Open Container Initiative) est fondée pour standardiser le format des images et le comportement des runtimes.
2019 — Podman. Red Hat lance Podman, une alternative à Docker sans daemon central et sans nécessité d’être root sur la machine hôte (rootless). Podman est compatible avec les commandes Docker mais architecturalement différent.
OCI : le standard ouvert#
L’OCI (Open Container Initiative), fondée en 2015 sous l’égide de la Linux Foundation, a défini deux spécifications cruciales :
Image Spec. Définit le format d’une image de conteneur : une liste de layers (tarballs), un manifest JSON décrivant les couches et leurs digests SHA256, et une configuration JSON spécifiant la commande à lancer, les variables d’environnement, etc. N’importe quel outil (Docker, Podman, Buildah, Kaniko) qui produit une image conforme peut être exécuté par n’importe quel runtime conforme.
Runtime Spec. Définit le comportement d’un runtime : comment créer un conteneur à partir d’un bundle OCI (une image extraite), quels namespaces et cgroups configurer, quels hooks exécuter. runc est l’implémentation de référence, écrite en Go.
Podman : l’alternative rootless
Podman (Pod Manager) remplace Docker commande par commande (alias docker=podman fonctionne), mais sans daemon central. Chaque podman run lance directement un processus conmon qui gère le conteneur. L’avantage majeur est le mode rootless : un utilisateur normal peut créer et gérer des conteneurs sans jamais toucher à root, ce qui est un gain de sécurité significatif sur les serveurs partagés. Podman est particulièrement populaire dans les environnements Red Hat/Fedora/CentOS.
Simulation Python : namespaces et isolation#
Pour rendre concrets ces mécanismes, voici une simulation Python qui illustre comment les namespaces isolent les processus — sans avoir besoin de Docker.
import os
import json
# Simulation du concept de namespace PID
# En réalité, les vrais namespaces nécessitent des appels système privilégiés
# Ici on simule la VISION qu'ont les processus de leur environnement
class SimNamespacePID:
"""Simule l'isolation des PIDs dans un namespace conteneur."""
def __init__(self, nom: str):
self.nom = nom
self._processus: list[dict] = []
self._prochain_pid_interne = 1 # Le conteneur commence à PID 1
def ajouter_processus(self, nom_proc: str, pid_hote: int):
"""Enregistre un processus avec son PID hôte et son PID interne."""
pid_interne = self._prochain_pid_interne
self._prochain_pid_interne += 1
self._processus.append({
"nom": nom_proc,
"pid_hote": pid_hote,
"pid_interne": pid_interne,
})
def vue_interne(self) -> list[dict]:
"""Ce que le conteneur voit (PID internes)."""
return [{"PID": p["pid_interne"], "processus": p["nom"]}
for p in self._processus]
def vue_hote(self) -> list[dict]:
"""Ce que l'hôte voit (PID réels)."""
return [{"PID hôte": p["pid_hote"], "PID conteneur": p["pid_interne"],
"conteneur": self.nom, "processus": p["nom"]}
for p in self._processus]
# Créons deux conteneurs simulés
c1 = SimNamespacePID("web-app")
c1.ajouter_processus("nginx (PID 1)", pid_hote=4213)
c1.ajouter_processus("nginx worker", pid_hote=4214)
c1.ajouter_processus("nginx worker", pid_hote=4215)
c2 = SimNamespacePID("database")
c2.ajouter_processus("postgres (PID 1)", pid_hote=4320)
c2.ajouter_processus("postgres worker", pid_hote=4321)
print("=" * 55)
print("VUE depuis l'intérieur du conteneur 'web-app'")
print("=" * 55)
for proc in c1.vue_interne():
print(f" PID {proc['PID']:3d} {proc['processus']}")
print()
print("=" * 55)
print("VUE depuis l'intérieur du conteneur 'database'")
print("=" * 55)
for proc in c2.vue_interne():
print(f" PID {proc['PID']:3d} {proc['processus']}")
print()
print("=" * 55)
print("VUE depuis l'hôte (tous les conteneurs)")
print("=" * 55)
tous = c1.vue_hote() + c2.vue_hote()
for proc in tous:
print(f" PID hôte {proc['PID hôte']} "
f"[{proc['conteneur']}:PID {proc['PID conteneur']}] "
f"{proc['processus']}")
=======================================================
VUE depuis l'intérieur du conteneur 'web-app'
=======================================================
PID 1 nginx (PID 1)
PID 2 nginx worker
PID 3 nginx worker
=======================================================
VUE depuis l'intérieur du conteneur 'database'
=======================================================
PID 1 postgres (PID 1)
PID 2 postgres worker
=======================================================
VUE depuis l'hôte (tous les conteneurs)
=======================================================
PID hôte 4213 [web-app:PID 1] nginx (PID 1)
PID hôte 4214 [web-app:PID 2] nginx worker
PID hôte 4215 [web-app:PID 3] nginx worker
PID hôte 4320 [database:PID 1] postgres (PID 1)
PID hôte 4321 [database:PID 2] postgres worker
# Simulation des cgroups : répartition des ressources
class SimCgroup:
"""Simule un cgroup avec limites CPU et mémoire."""
def __init__(self, nom: str, cpu_limit: float, mem_limit_mb: int):
self.nom = nom
self.cpu_limit = cpu_limit # en nombre de CPUs
self.mem_limit_mb = mem_limit_mb
self.cpu_actuel = 0.0
self.mem_actuelle_mb = 0
def utiliser(self, cpu: float, mem_mb: int) -> dict:
"""Tente d'allouer des ressources. Retourne le résultat."""
cpu_ok = cpu <= self.cpu_limit
mem_ok = mem_mb <= self.mem_limit_mb
if cpu_ok:
self.cpu_actuel = cpu
if mem_ok:
self.mem_actuelle_mb = mem_mb
return {
"conteneur": self.nom,
"cpu_demandé": cpu,
"cpu_accordé": min(cpu, self.cpu_limit),
"cpu_throttled": not cpu_ok,
"mem_demandée_mb": mem_mb,
"mem_accordée_mb": min(mem_mb, self.mem_limit_mb),
"mem_oom_killed": not mem_ok,
}
conteneurs_cg = [
SimCgroup("web-api", cpu_limit=0.5, mem_limit_mb=256),
SimCgroup("worker", cpu_limit=1.0, mem_limit_mb=512),
SimCgroup("database", cpu_limit=2.0, mem_limit_mb=2048),
]
# Scénario : une charge normale puis une surcharge
scenarios = [
(0.3, 200, "Charge normale"),
(0.8, 300, "Pic de charge (CPU throttlé)"),
(0.4, 600, "Fuite mémoire (OOM Kill simulé)"),
]
print(f"{'Conteneur':<12} {'Scénario':<30} {'CPU':>8} {'Mem':>10} {'Throttle':>10} {'OOM':>6}")
print("-" * 82)
for sg_cpu, sg_mem, sg_label in scenarios:
for cg in conteneurs_cg:
r = cg.utiliser(sg_cpu, sg_mem)
throttle = "OUI ⚠" if r["cpu_throttled"] else "non"
oom = "OUI ⚠" if r["mem_oom_killed"] else "non"
print(f"{cg.nom:<12} {sg_label:<30} "
f"{r['cpu_accordé']:>6.1f}/{cg.cpu_limit:.1f}"
f" {r['mem_accordée_mb']:>4}MB/{cg.mem_limit_mb}MB"
f" {throttle:>8} {oom:>4}")
print()
Conteneur Scénario CPU Mem Throttle OOM
----------------------------------------------------------------------------------
web-api Charge normale 0.3/0.5 200MB/256MB non non
worker Charge normale 0.3/1.0 200MB/512MB non non
database Charge normale 0.3/2.0 200MB/2048MB non non
web-api Pic de charge (CPU throttlé) 0.5/0.5 256MB/256MB OUI ⚠ OUI ⚠
worker Pic de charge (CPU throttlé) 0.8/1.0 300MB/512MB non non
database Pic de charge (CPU throttlé) 0.8/2.0 300MB/2048MB non non
web-api Fuite mémoire (OOM Kill simulé) 0.4/0.5 256MB/256MB non OUI ⚠
worker Fuite mémoire (OOM Kill simulé) 0.4/1.0 512MB/512MB non OUI ⚠
database Fuite mémoire (OOM Kill simulé) 0.4/2.0 600MB/2048MB non non
Bilan : pourquoi les conteneurs ont gagné#
Les conteneurs ont conquis l’industrie pour des raisons très concrètes.
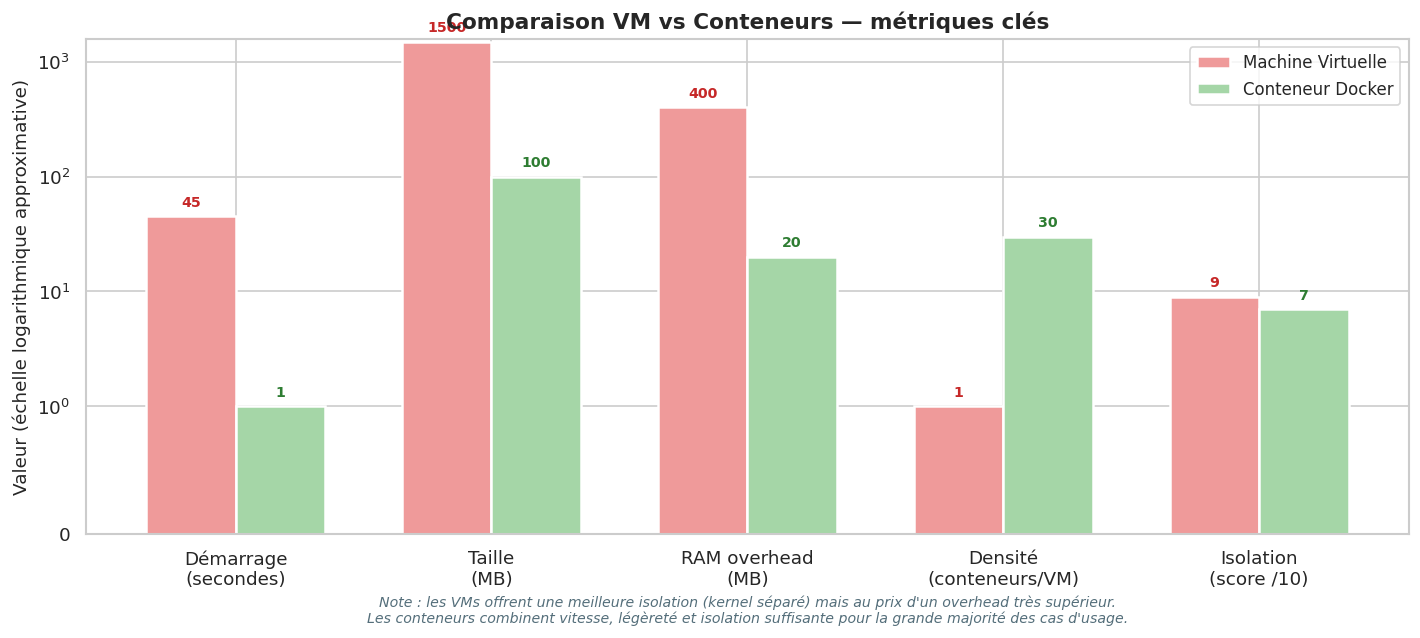
Les conteneurs ne remplacent pas toujours les VMs. Pour des charges de travail nécessitant une isolation totale du kernel (environnements multi-tenants hostiles, machines Windows sur hôte Linux), les VMs restent la référence. En pratique, les deux coexistent : on fait tourner des VMs dans le cloud (une VM par client), et des conteneurs à l’intérieur de ces VMs (plusieurs services par VM).
Résumé#
Un conteneur est un processus Linux isolé grâce aux namespaces (isolation) et aux cgroups (limitation des ressources), avec son propre système de fichiers construit par OverlayFS.
Les VMs offrent une isolation plus forte (kernel séparé) mais sont plus lourdes (secondes de démarrage, centaines de MB de RAM).
Docker n’a pas inventé les conteneurs mais les a rendus accessibles grâce à une UX révolutionnaire et Docker Hub.
Le standard OCI garantit l’interopérabilité entre outils (Docker, Podman, Buildah) et runtimes (containerd, crun, youki).
Podman est une alternative rootless populaire, compatible avec l’écosystème Docker.
Dans le prochain chapitre, nous entrons dans le concret : les images Docker, leur structure en couches, le Dockerfile et le processus de build.