Observabilité#
Pourquoi « observer » un système ?#
Imaginez que vous conduisez une voiture les yeux bandés. Vous savez que vous roulez, mais vous ignorez la vitesse, le niveau d’essence, la température du moteur. Un incident surviendra, et vous ne le verrez pas venir.
Un système en production sans observabilité, c’est exactement ça. L’observabilité est la capacité à comprendre l’état interne d’un système à partir de ses sorties externes. Plus précisément, c’est la propriété d’un système qui permet de répondre à des questions arbitraires sans avoir à y accéder directement.
Observabilité vs Monitoring
Le monitoring consiste à surveiller des indicateurs connus à l’avance (ex. : « alerter si CPU > 80% »). On sait ce qu’on cherche.
L”observabilité permet d’explorer des comportements inconnus (ex. : « pourquoi cette requête précise est-elle lente pour cet utilisateur spécifique ? »). On peut poser des questions qu’on n’avait pas anticipées.
En pratique, un système observable est aussi bien monitoré — mais l’inverse n’est pas vrai.
Les trois piliers de l’observabilité#
L’industrie a convergé vers trois types de données complémentaires, souvent appelés les « trois piliers » :

Les trois piliers sont complémentaires : les métriques alertent,
les logs expliquent, les traces localisent.
Ces trois piliers fonctionnent en synergie. Quand une alerte métrique se déclenche (CPU élevé), on consulte les logs pour comprendre ce qui s’est passé, puis on suit une trace pour identifier quel service est responsable.
Métriques Kubernetes#
Les couches de métriques#
Dans un cluster Kubernetes, les métriques proviennent de plusieurs couches :

Format d’exposition Prometheus#
Prometheus utilise un format texte simple. Chaque application expose un endpoint /metrics :
# HELP http_requests_total Nombre total de requêtes HTTP
# TYPE http_requests_total counter
http_requests_total{method="GET",status="200"} 1234
http_requests_total{method="POST",status="500"} 7
# HELP process_cpu_seconds_total CPU consommé en secondes
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 23.45
# HELP http_request_duration_seconds Durée des requêtes
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.1"} 800
http_request_duration_seconds_bucket{le="0.5"} 1100
http_request_duration_seconds_bucket{le="1.0"} 1200
http_request_duration_seconds_bucket{le="+Inf"} 1234
http_request_duration_seconds_sum 156.3
http_request_duration_seconds_count 1234
Les types de métriques Prometheus#
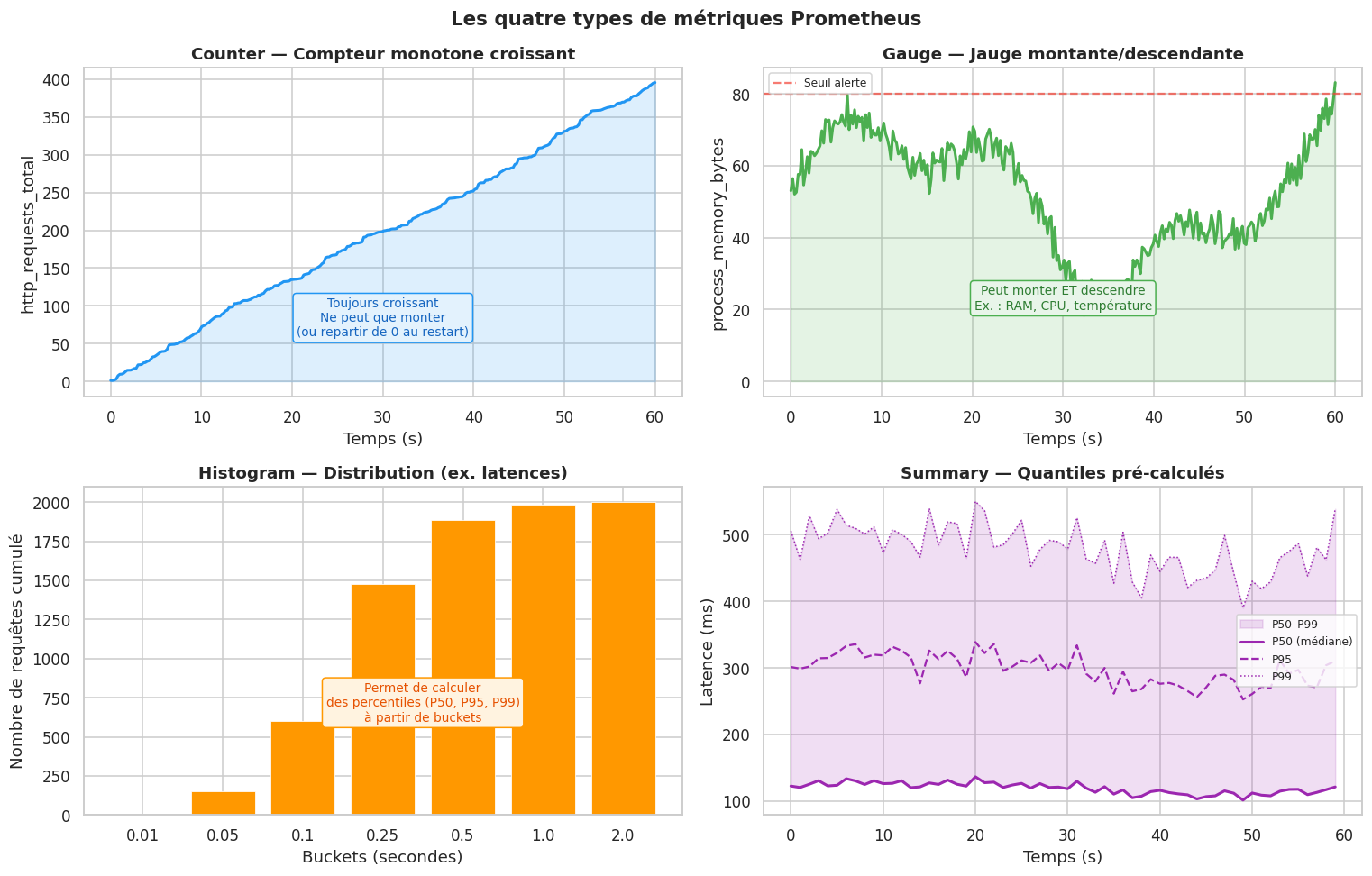
Prometheus : architecture et PromQL#
Architecture de scraping#
Prometheus fonctionne en mode pull : c’est lui qui va chercher les métriques sur chaque cible, à intervalles réguliers (par défaut toutes les 15 secondes).
# prometheus.yml — configuration de scraping
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- job_name: 'node-exporter'
static_configs:
- targets: ['node-exporter:9100']
- job_name: 'kube-state-metrics'
static_configs:
- targets: ['kube-state-metrics:8080']
PromQL — requêtes essentielles#
PromQL (Prometheus Query Language) permet d’interroger les séries temporelles :
# Taux de requêtes HTTP (par seconde sur 5 minutes)
rate(http_requests_total[5m])
# Taux d'erreurs (ratio)
rate(http_requests_total{status=~"5.."}[5m])
/
rate(http_requests_total[5m])
# P95 des latences
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))
# CPU utilisé par pod
sum(rate(container_cpu_usage_seconds_total[5m])) by (pod)
# Mémoire disponible sur les nœuds
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100
# Pods en état non-running
kube_pod_status_phase{phase!="Running",phase!="Succeeded"} == 1
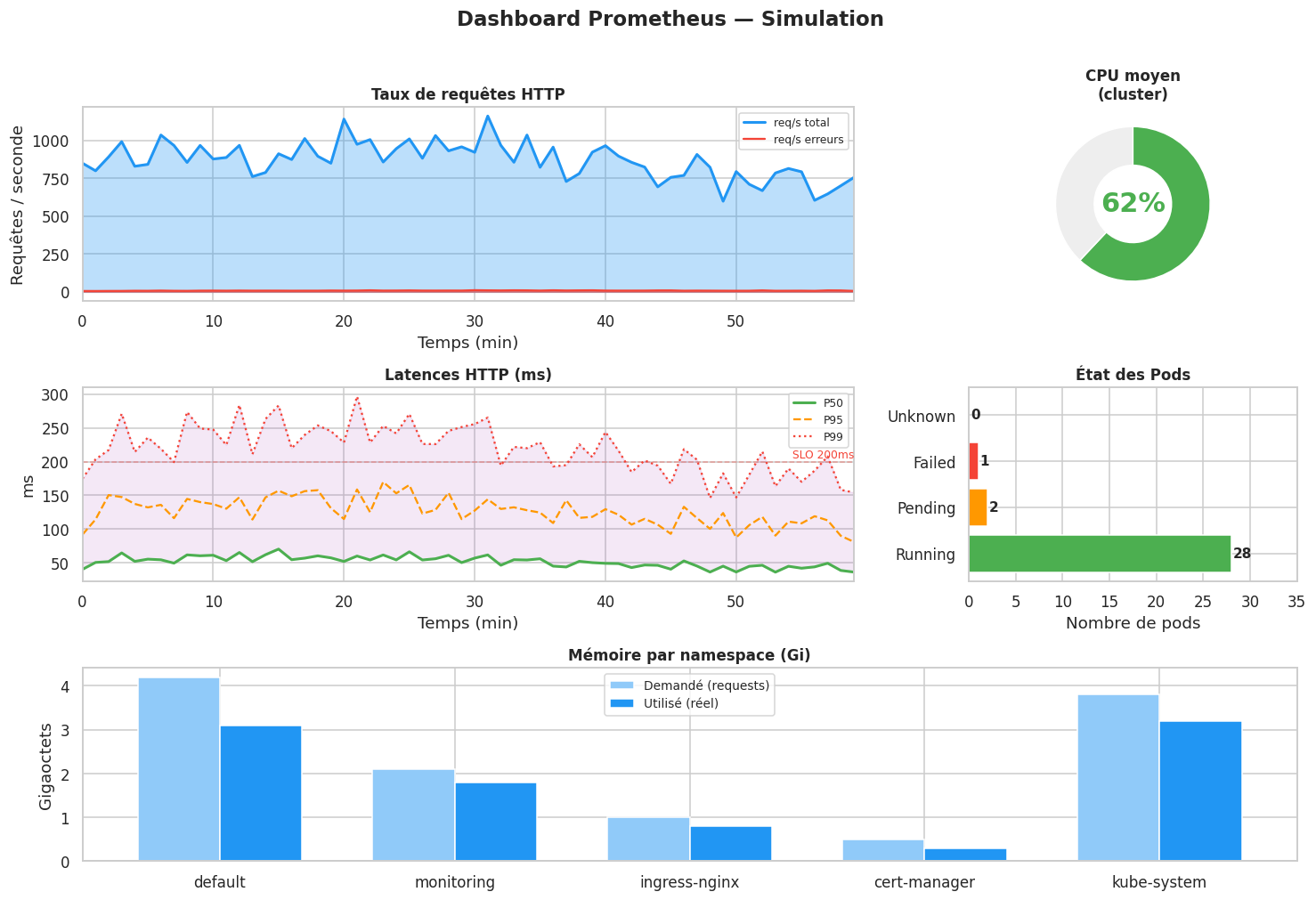
Alerting avec Prometheus#
Prometheus permet de définir des règles d’alerte en PromQL :
# alerting-rules.yml
groups:
- name: kubernetes-applications
rules:
- alert: HighErrorRate
expr: |
rate(http_requests_total{status=~"5.."}[5m])
/ rate(http_requests_total[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "Taux d'erreurs élevé sur {{ $labels.service }}"
description: "{{ $value | humanizePercentage }} d'erreurs 5xx depuis 2 min"
- alert: PodCrashLooping
expr: rate(kube_pod_container_status_restarts_total[15m]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.pod }} en crash loop"
Grafana : visualisation des métriques#
Grafana est l’outil de visualisation de référence. Il se connecte à Prometheus (et à d’autres sources) pour afficher des dashboards interactifs.
# Installation via Helm
helm repo add grafana https://grafana.github.io/helm-charts
helm install grafana grafana/grafana \
--namespace monitoring \
--set adminPassword='MonMotDePasse' \
--set datasources."datasources\.yaml".apiVersion=1 \
--set datasources."datasources\.yaml".datasources[0].name=Prometheus \
--set datasources."datasources\.yaml".datasources[0].type=prometheus \
--set datasources."datasources\.yaml".datasources[0].url=http://prometheus-server
# Port-forward pour accéder à Grafana
kubectl port-forward svc/grafana 3000:80 -n monitoring
Les panels Grafana supportent différents types de visualisation : graphes temporels, jauges, heatmaps, tableaux, stat panels. On peut importer des dashboards communautaires depuis grafana.com/dashboards (ex. : dashboard 315 pour Kubernetes).
Logs : centralisation et analyse#
Logs dans Kubernetes#
Par convention, les conteneurs écrivent leurs logs sur stdout et stderr. Kubernetes capture ces flux et les rend accessibles via kubectl logs :
# Logs d'un pod
kubectl logs monpod
# Logs en temps réel (follow)
kubectl logs -f monpod
# Logs d'un conteneur spécifique dans un pod multi-conteneur
kubectl logs monpod -c mon-conteneur
# Logs des 100 dernières lignes
kubectl logs monpod --tail=100
# Logs depuis 1 heure
kubectl logs monpod --since=1h
# Logs d'un déploiement entier (tous les pods)
kubectl logs deployment/mon-deploiement --all-pods
Architecture de centralisation des logs#
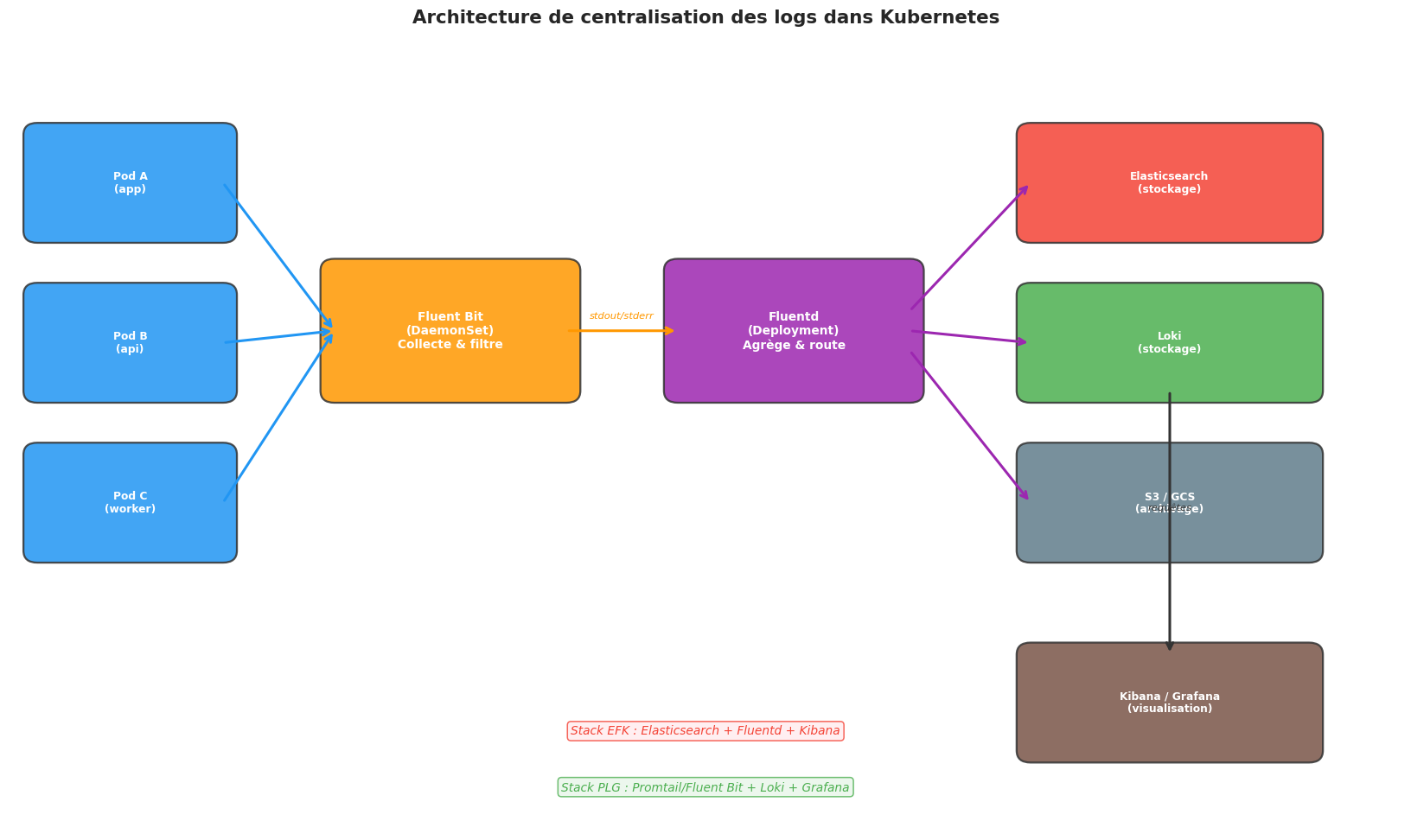
Loki vs EFK#
Loki (de Grafana Labs) est souvent préféré aujourd’hui pour sa simplicité et son coût réduit. Contrairement à Elasticsearch qui indexe le contenu des logs, Loki n’indexe que les labels (metadata). La recherche full-text est plus lente, mais le stockage est bien moins coûteux.
# Requête LogQL (langage Loki, similaire à PromQL)
# Logs d'erreur du namespace "production"
{namespace="production"} |= "ERROR"
# Comptage des erreurs par service
sum by (app) (count_over_time({namespace="production"} |= "ERROR" [5m]))
# Extraction de champs structurés
{app="api"} | json | status_code >= 500
Traces distribuées#
Le problème des microservices#
Dans une architecture monolithique, quand une requête est lente, on regarde le stack trace. Dans une architecture de microservices, une requête peut traverser 10 services différents. Comment savoir lequel est responsable du ralentissement ?
Les traces distribuées répondent à ce problème en suivant une requête de bout en bout à travers tous les services.
Concepts OpenTelemetry#
OpenTelemetry (OTel) est le standard ouvert d’instrumentation. Il définit :
Trace : le parcours complet d’une requête, avec un
trace_iduniqueSpan : une unité de travail (appel HTTP, requête DB, etc.) avec durée et attributs
Context propagation : transmission du
trace_identre services (via headers HTTP)
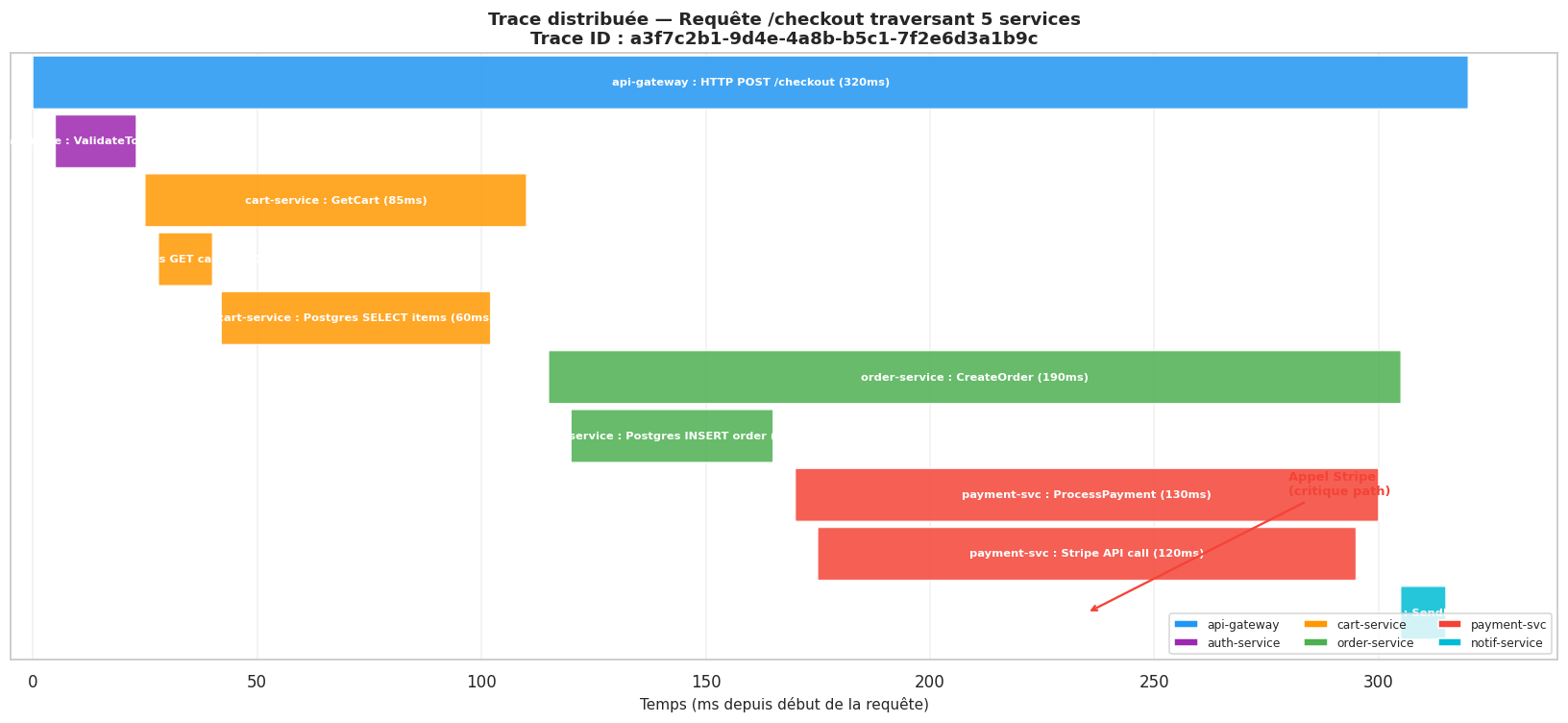
Durée totale de la trace : 320ms
Span le plus lent : payment-svc/Stripe API call (120ms)
Nombre de services impliqués : 6
Jaeger : visualisation des traces#
Jaeger est l’outil open-source standard pour visualiser les traces (créé par Uber, maintenant CNCF) :
# Installation de Jaeger via Helm
helm repo add jaegertracing https://jaegertracing.github.io/helm-charts
helm install jaeger jaegertracing/jaeger \
--namespace monitoring \
--set provisionDataStore.cassandra=false \
--set allInOne.enabled=true \
--set storage.type=memory
# Port-forward pour accéder à l'UI
kubectl port-forward svc/jaeger-query 16686:16686 -n monitoring
Pour instrumenter une application Python :
# Instrumentation OpenTelemetry (illustratif)
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
provider = TracerProvider()
exporter = OTLPSpanExporter(endpoint="http://jaeger-collector:4317")
provider.add_span_processor(BatchSpanProcessor(exporter))
trace.set_tracer_provider(provider)
tracer = trace.get_tracer("mon-service")
def traiter_commande(commande_id):
with tracer.start_as_current_span("traiter-commande") as span:
span.set_attribute("commande.id", commande_id)
result = appeler_base_de_donnees(commande_id)
return result
kube-state-metrics#
kube-state-metrics écoute l’API Kubernetes et expose l’état des objets K8s sous forme de métriques Prometheus. C’est différent de cAdvisor (qui mesure la consommation de ressources des conteneurs) :
# Métriques clés de kube-state-metrics
kube_pod_status_phase{phase="Pending"} # Pods en attente
kube_deployment_status_replicas_unavailable # Replicas non disponibles
kube_node_status_condition{condition="Ready"} # État des nœuds
kube_job_status_failed # Jobs échoués
kube_persistentvolumeclaim_status_phase # État des PVC
kube_horizontalpodautoscaler_status_current_replicas # Replicas HPA actuels
SLI / SLO / SLA#
Ces termes définissent les objectifs de fiabilité d’un service :
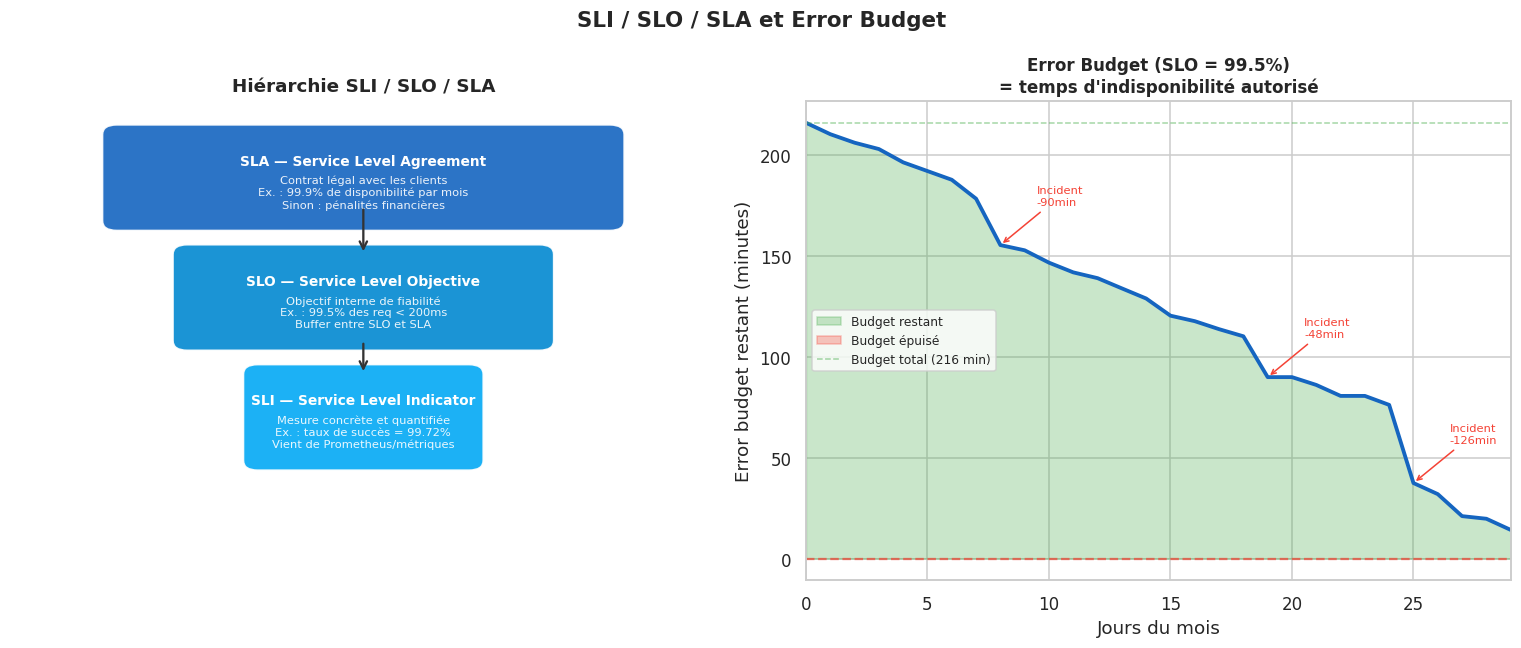
SLO cible : 99.5% de disponibilité
Error budget mensuel : 216 minutes (3.6h)
Budget consommé ce mois : 202 minutes
Budget restant : 14 minutes
Simulation complète : métriques et SLO#
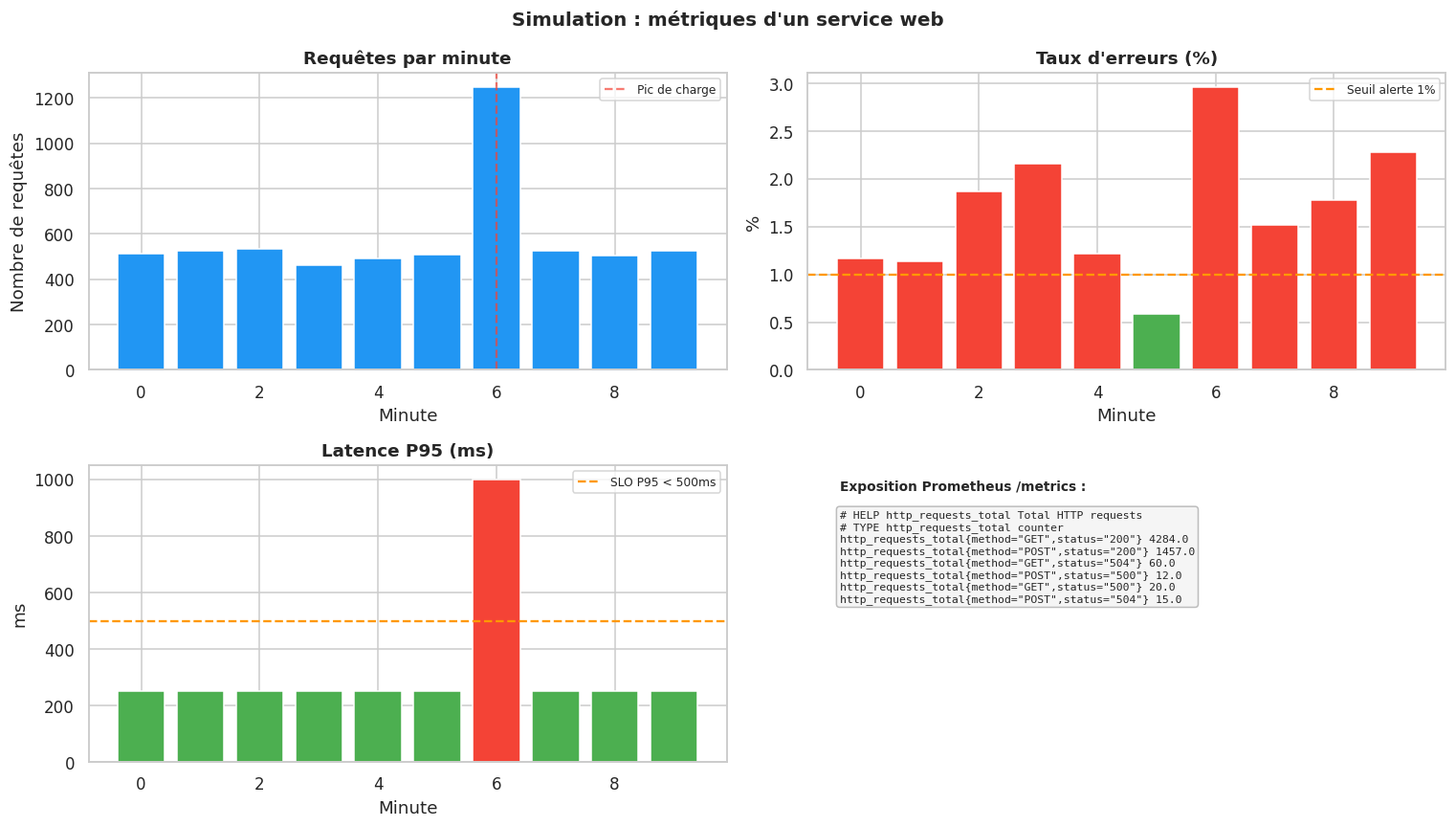
Bilan de la simulation :
Requêtes totales : 5848
Erreurs totales : 106 (1.81%)
Minutes avec SLO violé (P95 > 500ms) : 1
Architecture d’observabilité complète#
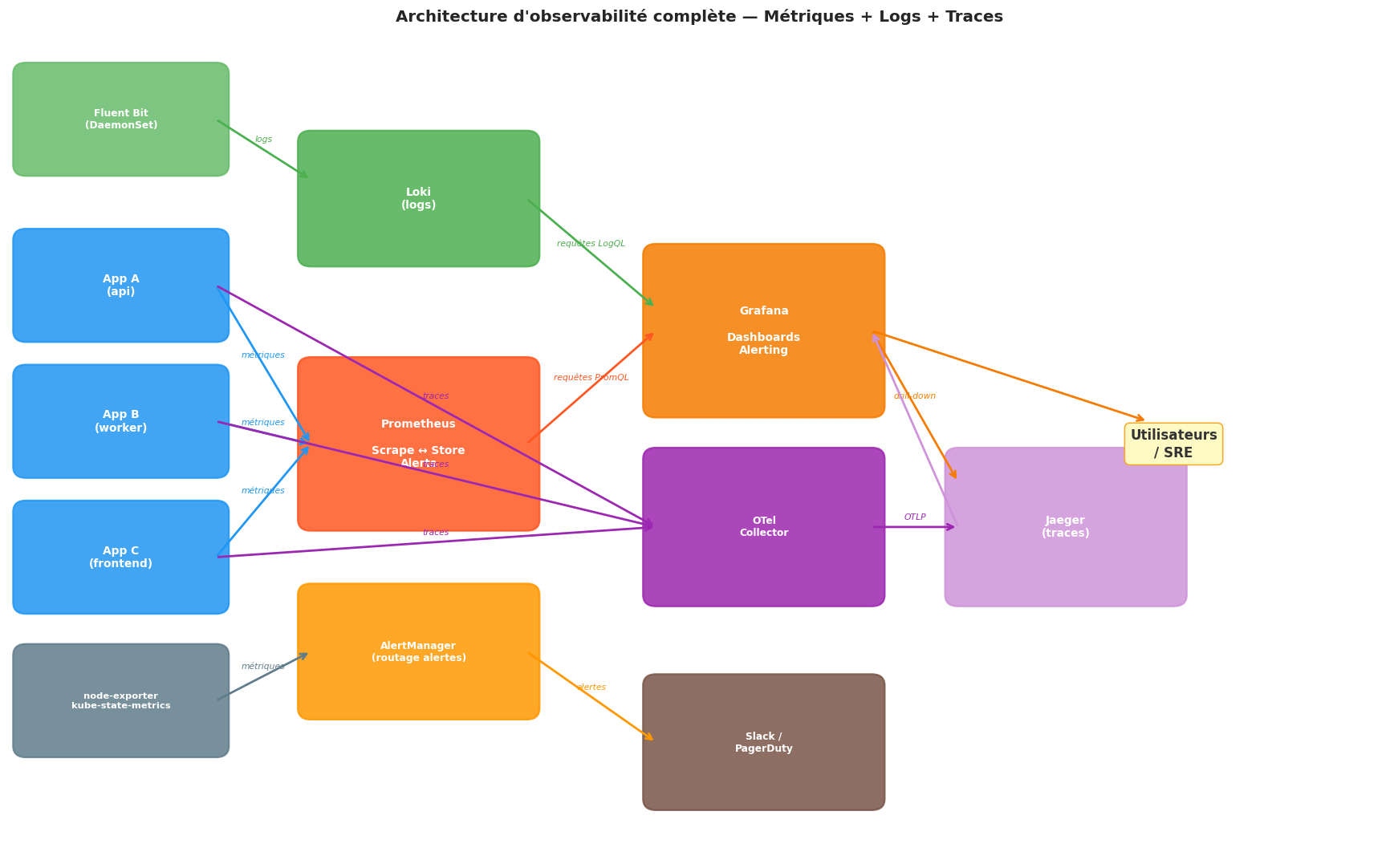
Récapitulatif#
Ce qu’il faut retenir
Les trois piliers : métriques (alerter), logs (expliquer), traces (localiser). Les trois sont complémentaires.
Prometheus scrape les métriques toutes les 15s. PromQL permet des requêtes puissantes. AlertManager achemine les alertes.
Grafana visualise les métriques, logs (via Loki) et traces (via Jaeger) dans des dashboards unifiés.
kube-state-metrics expose l’état des objets Kubernetes (pods pending, déploiements, etc.).
OpenTelemetry est le standard d’instrumentation pour les traces. Jaeger les visualise.
SLO (objectif) > SLI (mesure) > SLA (contrat). L’error budget est le temps d’indisponibilité autorisé avant de violer le SLO.
Un système bien observable permet de diagnostiquer des problèmes qu’on n’avait pas anticipés.