Docker en production — Logs, ressources et sécurité#
Logging : capturer ce qui se passe dans vos conteneurs#
En production, comprendre ce qui se passe dans vos conteneurs est vital. Docker fournit un système de log drivers qui capture la sortie standard (stdout/stderr) de chaque conteneur.
Les drivers de logs disponibles#
Driver |
Description |
Cas d’usage |
|---|---|---|
|
Fichiers JSON locaux (défaut) |
Dev, petits déploiements |
|
Format binaire compressé, plus performant |
Alternative à json-file |
|
Envoie vers syslog/rsyslog |
Systèmes Linux classiques |
|
Intégration systemd journald |
Hôtes avec systemd |
|
Envoie vers Fluentd/Fluentbit |
ELK Stack, agrégation centralisée |
|
Amazon CloudWatch Logs |
Déploiements AWS |
|
Google Cloud Logging |
Déploiements GCP |
|
Splunk HTTP Event Collector |
Entreprises avec Splunk |
|
Désactive les logs |
Conteneurs très verbeux sans besoin de logs |
Configuration des logs#
# Configurer le driver globalement dans /etc/docker/daemon.json
# {
# "log-driver": "json-file",
# "log-opts": {
# "max-size": "10m",
# "max-file": "3",
# "compress": "true"
# }
# }
# Configurer pour un conteneur spécifique
docker run \
--log-driver json-file \
--log-opt max-size=10m \
--log-opt max-file=3 \
--log-opt compress=true \
myapp:latest
# Avec Fluentd (centralisé)
docker run \
--log-driver fluentd \
--log-opt fluentd-address=localhost:24224 \
--log-opt tag="app.{{.Name}}" \
myapp:latest
Dans un compose.yml :
services:
app:
image: myapp:latest
logging:
driver: json-file
options:
max-size: "10m"
max-file: "5"
compress: "true"
labels: "service,version" # Ajouter des labels aux logs
12-Factor App : logs comme flux
La bonne pratique (issue du manifeste 12-Factor) : vos applications ne doivent jamais gérer les fichiers de logs elles-mêmes. Elles écrivent sur stdout/stderr, et c’est l’infrastructure (Docker, systemd, Kubernetes) qui se charge de collecter, router et stocker les logs. Cela rend le code plus simple et le déploiement plus flexible.
Simulation : analyse de logs JSON#
# Simulation de logs JSON Docker (format json-file driver)
import io
def generate_fake_logs(n: int = 50) -> list[dict]:
"""Génère des logs réalistes pour une application Flask."""
methods = ["GET", "POST", "PUT", "DELETE"]
paths = ["/api/users", "/api/orders", "/health", "/api/products",
"/api/search", "/static/app.js", "/api/auth/login"]
status_codes = [200, 200, 200, 200, 201, 204, 400, 404, 500, 503]
levels = ["INFO", "INFO", "INFO", "WARNING", "ERROR"]
base_time = datetime(2026, 3, 21, 10, 0, 0, tzinfo=timezone.utc)
logs = []
for i in range(n):
t = base_time + timedelta(seconds=i * 2 + random.randint(0, 3))
method = random.choice(methods)
path = random.choice(paths)
status = random.choice(status_codes)
duration_ms = random.randint(5, 800) if status < 500 else random.randint(200, 3000)
level = "ERROR" if status >= 500 else ("WARNING" if status >= 400 else "INFO")
log_entry = {
"log": json.dumps({
"timestamp": t.isoformat(),
"level": level,
"method": method,
"path": path,
"status": status,
"duration_ms": duration_ms,
"request_id": f"req-{i:04d}",
"message": f"{method} {path} → {status} ({duration_ms}ms)"
}) + "\n",
"stream": "stderr" if level == "ERROR" else "stdout",
"time": t.isoformat()
}
logs.append(log_entry)
return logs
def analyze_logs(logs: list[dict]) -> pd.DataFrame:
"""Parse et analyse les logs JSON."""
records = []
for entry in logs:
try:
inner = json.loads(entry["log"].strip())
records.append(inner)
except (json.JSONDecodeError, KeyError):
continue
return pd.DataFrame(records)
logs = generate_fake_logs(100)
df = analyze_logs(logs)
# Statistiques
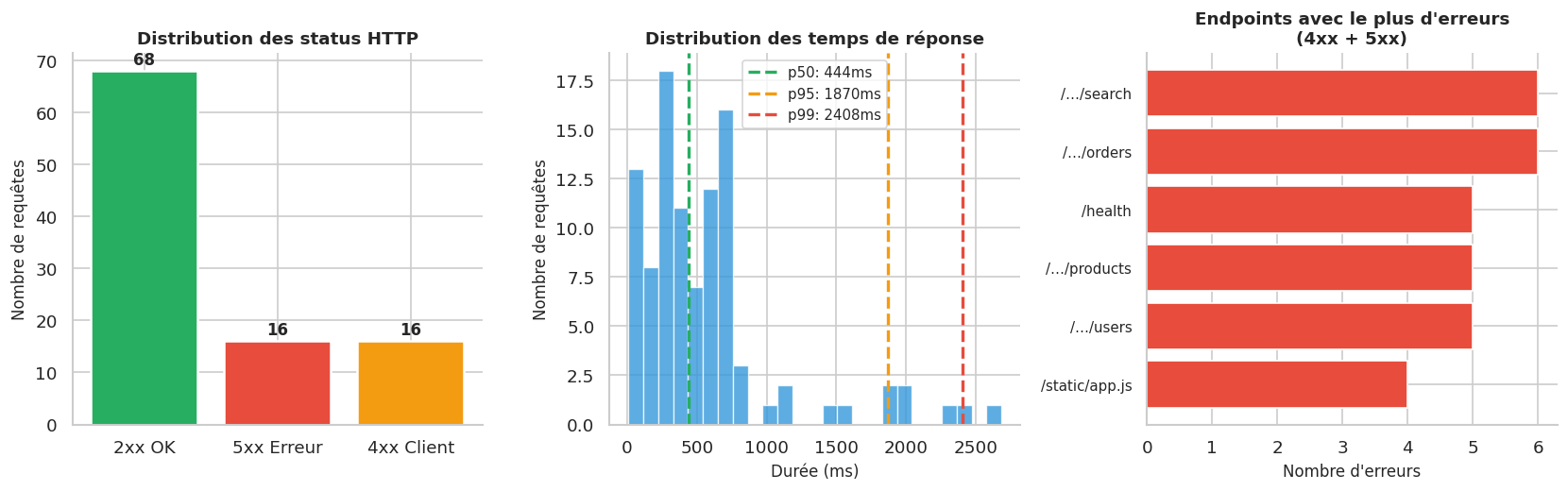
print("Analyse des logs de production")
print("=" * 45)
print(f"Total requêtes : {len(df)}")
print(f"Période : {df['timestamp'].min()[:19]} → {df['timestamp'].max()[:19]}")
print()
status_counts = df["status"].value_counts().sort_index()
print("Distribution des status HTTP :")
for status, count in status_counts.items():
cat = "✅" if status < 400 else ("⚠️ " if status < 500 else "❌")
bar = "█" * count
print(f" {cat} {status} {count:3d} {bar}")
print()
p50 = df["duration_ms"].quantile(0.50)
p95 = df["duration_ms"].quantile(0.95)
p99 = df["duration_ms"].quantile(0.99)
print(f"Temps de réponse (ms) :")
print(f" Médiane (p50) : {p50:.0f}ms")
print(f" p95 : {p95:.0f}ms")
print(f" p99 : {p99:.0f}ms")
print()
errors = df[df["level"] == "ERROR"]
print(f"Erreurs (5xx) : {len(errors)}")
if not errors.empty:
for _, row in errors.head(3).iterrows():
print(f" [{row['timestamp'][11:19]}] {row['method']} {row['path']} → {row['status']} ({row['duration_ms']}ms)")
Analyse des logs de production
=============================================
Total requêtes : 100
Période : 2026-03-21T10:00:00 → 2026-03-21T10:03:18
Distribution des status HTTP :
✅ 200 46 ██████████████████████████████████████████████
✅ 201 10 ██████████
✅ 204 12 ████████████
⚠️ 400 6 ██████
⚠️ 404 10 ██████████
❌ 500 10 ██████████
❌ 503 6 ██████
Temps de réponse (ms) :
Médiane (p50) : 444ms
p95 : 1870ms
p99 : 2408ms
Erreurs (5xx) : 16
[10:00:07] POST /api/search → 503 (308ms)
[10:00:35] DELETE /health → 500 (1099ms)
[10:01:09] GET /api/auth/login → 500 (715ms)
fig, axes = plt.subplots(1, 3, figsize=(14, 4.5))
# --- Distribution des status ---
ax1 = axes[0]
df["status_cat"] = df["status"].apply(
lambda s: "2xx OK" if s < 300 else ("3xx Redirect" if s < 400 else ("4xx Client" if s < 500 else "5xx Erreur")))
cat_counts = df["status_cat"].value_counts()
colors_status = {"2xx OK": "#27ae60", "3xx Redirect": "#3498db",
"4xx Client": "#f39c12", "5xx Erreur": "#e74c3c"}
bars = ax1.bar(cat_counts.index, cat_counts.values,
color=[colors_status.get(c, "#aaa") for c in cat_counts.index],
edgecolor="white", linewidth=1.5)
ax1.set_title("Distribution des status HTTP", fontsize=11, fontweight="bold")
ax1.set_ylabel("Nombre de requêtes", fontsize=10)
ax1.set_xlabel("")
for bar, val in zip(bars, cat_counts.values):
ax1.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
str(val), ha="center", va="bottom", fontsize=10, fontweight="bold")
# --- Durée des réponses (histogramme) ---
ax2 = axes[1]
ax2.hist(df["duration_ms"], bins=25, color="#3498db", edgecolor="white", linewidth=0.8, alpha=0.8)
for q, label, color in [(p50, "p50", "#27ae60"), (p95, "p95", "#f39c12"), (p99, "p99", "#e74c3c")]:
ax2.axvline(q, color=color, lw=2, ls="--", label=f"{label}: {q:.0f}ms")
ax2.set_title("Distribution des temps de réponse", fontsize=11, fontweight="bold")
ax2.set_xlabel("Durée (ms)", fontsize=10)
ax2.set_ylabel("Nombre de requêtes", fontsize=10)
ax2.legend(fontsize=9)
# --- Top endpoints par erreurs ---
ax3 = axes[2]
error_by_path = df[df["status"] >= 400].groupby("path")["status"].count().sort_values(ascending=True).tail(6)
colors_endpoints = ["#e74c3c" if p > 2 else "#f39c12" for p in error_by_path.values]
ax3.barh(range(len(error_by_path)), error_by_path.values,
color=colors_endpoints, edgecolor="white", linewidth=1)
ax3.set_yticks(range(len(error_by_path)))
ax3.set_yticklabels([p.replace("/api/", "/…/") for p in error_by_path.index], fontsize=9)
ax3.set_title("Endpoints avec le plus d'erreurs\n(4xx + 5xx)", fontsize=11, fontweight="bold")
ax3.set_xlabel("Nombre d'erreurs", fontsize=10)
plt.tight_layout()
plt.show()
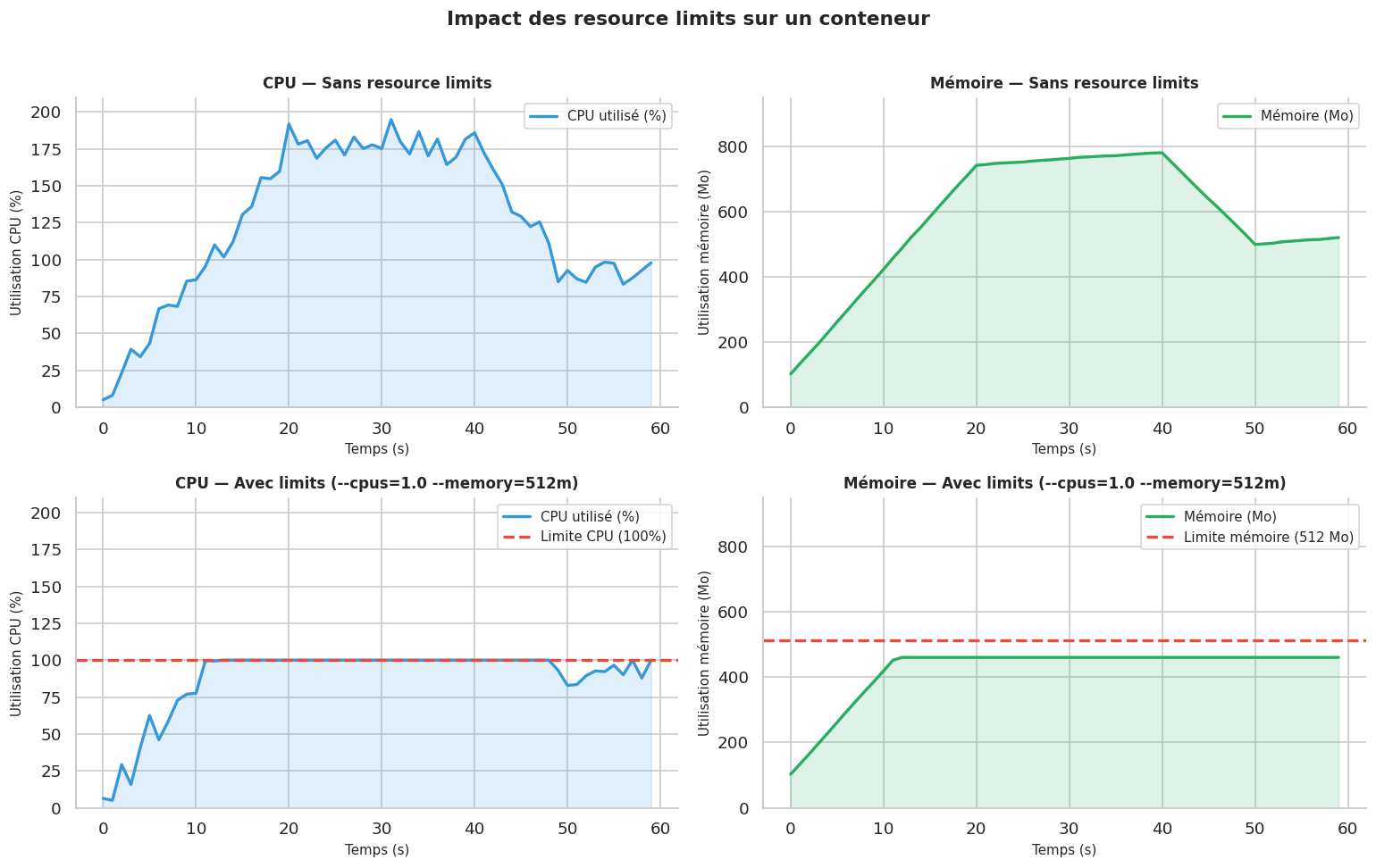
Resource limits : contrôler CPU et mémoire#
Sans limites, un conteneur peut consommer toutes les ressources d’un hôte et affamer les autres. Les limites de ressources sont obligatoires en production :
# Limiter la mémoire à 512 Mo et le CPU à 1 cœur
docker run \
--memory 512m \
--memory-swap 512m \ # = --memory → pas de swap
--cpus 1.0 \
myapp:latest
# Limiter avec CPU shares (poids relatif)
docker run \
--memory 256m \
--cpu-shares 512 \ # 512 = moitié d'un core (défaut : 1024)
myapp:latest
# Voir les ressources consommées
docker stats
docker stats --no-stream # Snapshot unique
Dans un compose.yml :
services:
app:
image: myapp:latest
deploy:
resources:
limits:
cpus: "1.0"
memory: 512M
reservations: # Ressources garanties
cpus: "0.25"
memory: 128M
Cgroups v2
Les limites Docker s’appuient sur les control groups (cgroups) du noyau Linux. Cgroups v2 (disponible sur les distributions modernes) offre une meilleure isolation et de nouvelles métriques. Docker utilise automatiquement cgroups v2 quand disponible. Vérification : docker info | grep "Cgroup Version".
Simulation : impact des resource limits#
# Simulation de métriques conteneur dans le temps
# Scénario : conteneur avec et sans limits, soumis à une charge progressive
def simulate_metrics(n_points: int = 60, memory_limit_mb: float = None,
cpu_limit: float = None, label: str = "") -> pd.DataFrame:
"""Simule l'utilisation CPU/mémoire d'un conteneur sous charge."""
t = np.arange(n_points)
# Charge croissante puis plateau
load_profile = np.where(t < 20, t / 20,
np.where(t < 40, 1.0,
np.where(t < 50, 1.0 - (t - 40) / 20, 0.5)))
# CPU : suit la charge avec bruit
cpu_raw = load_profile * 180 + np.random.normal(0, 8, n_points)
cpu_raw = np.clip(cpu_raw, 5, 200)
cpu = np.clip(cpu_raw, 0, (cpu_limit * 100) if cpu_limit else 200)
# Mémoire : croît progressivement (fuites légères + données en cache)
mem_raw = 100 + load_profile * 600 + np.cumsum(np.random.normal(2, 1, n_points))
mem = np.clip(mem_raw, 80, (memory_limit_mb * 0.9) if memory_limit_mb else 900)
# OOM si mémoire atteint 100% de la limite
oom_events = []
if memory_limit_mb:
for i in range(n_points):
if mem[i] >= memory_limit_mb * 0.98:
oom_events.append(i)
mem[i:] = np.maximum(80, mem[i:] - memory_limit_mb * 0.3)
return pd.DataFrame({
"t": t, "cpu": cpu, "mem": mem,
"label": label,
"cpu_limit": cpu_limit * 100 if cpu_limit else None,
"mem_limit": memory_limit_mb,
"oom": [i in oom_events for i in range(n_points)]
})
df_no_limit = simulate_metrics(label="Sans limite")
df_limited = simulate_metrics(memory_limit_mb=512, cpu_limit=1.0, label="Avec limits (1CPU, 512Mo)")
fig, axes = plt.subplots(2, 2, figsize=(13, 8))
fig.suptitle("Impact des resource limits sur un conteneur", fontsize=13, fontweight="bold", y=1.01)
for ax_row, (df_m, title) in enumerate([(df_no_limit, "Sans resource limits"),
(df_limited, "Avec limits (--cpus=1.0 --memory=512m)")]):
ax_cpu = axes[ax_row][0]
ax_mem = axes[ax_row][1]
# CPU
ax_cpu.plot(df_m["t"], df_m["cpu"], color="#3498db", lw=2, label="CPU utilisé (%)")
ax_cpu.fill_between(df_m["t"], df_m["cpu"], alpha=0.15, color="#3498db")
if df_m["cpu_limit"].iloc[0]:
ax_cpu.axhline(df_m["cpu_limit"].iloc[0], color="#e74c3c", ls="--", lw=2,
label=f"Limite CPU ({df_m['cpu_limit'].iloc[0]:.0f}%)")
ax_cpu.set_title(f"CPU — {title}", fontsize=10, fontweight="bold")
ax_cpu.set_ylabel("Utilisation CPU (%)", fontsize=9)
ax_cpu.set_xlabel("Temps (s)", fontsize=9)
ax_cpu.legend(fontsize=9)
ax_cpu.set_ylim(0, 210)
# Mémoire
ax_mem.plot(df_m["t"], df_m["mem"], color="#27ae60", lw=2, label="Mémoire (Mo)")
ax_mem.fill_between(df_m["t"], df_m["mem"], alpha=0.15, color="#27ae60")
if df_m["mem_limit"].iloc[0]:
ax_mem.axhline(df_m["mem_limit"].iloc[0], color="#e74c3c", ls="--", lw=2,
label=f"Limite mémoire ({df_m['mem_limit'].iloc[0]:.0f} Mo)")
# Marquer OOM
oom_points = df_m[df_m["oom"]]
if not oom_points.empty:
ax_mem.scatter(oom_points["t"], oom_points["mem"], color="#c0392b", s=80,
zorder=5, marker="X", label="OOM Kill !")
ax_mem.set_title(f"Mémoire — {title}", fontsize=10, fontweight="bold")
ax_mem.set_ylabel("Utilisation mémoire (Mo)", fontsize=9)
ax_mem.set_xlabel("Temps (s)", fontsize=9)
ax_mem.legend(fontsize=9)
ax_mem.set_ylim(0, 950)
plt.tight_layout()
plt.show()
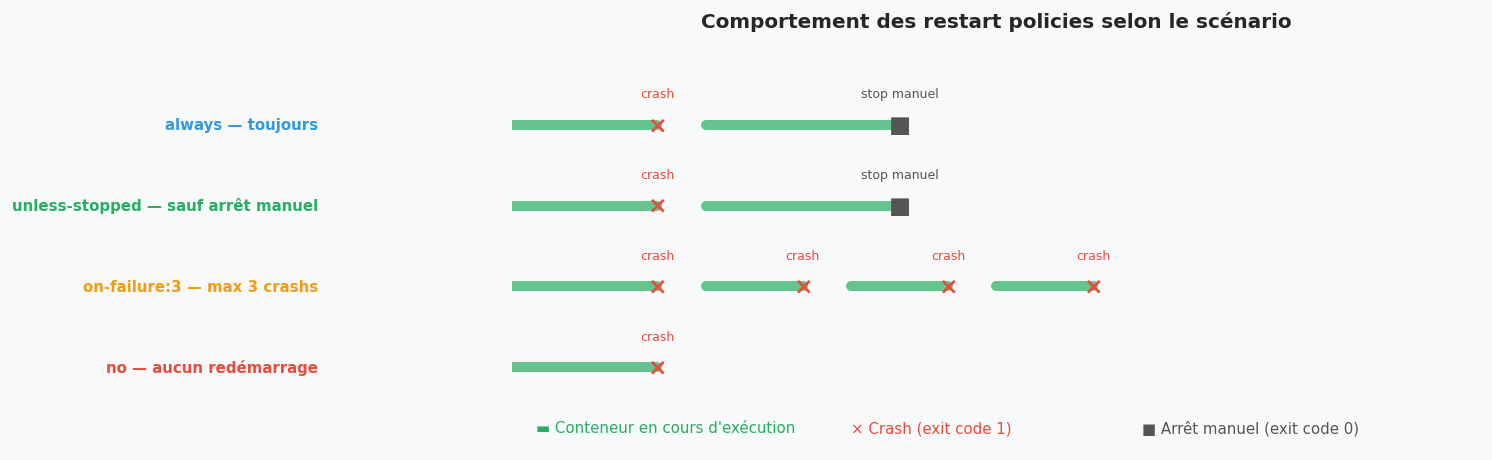
Restart policies : que faire quand un conteneur plante ?#
# no (défaut) : ne redémarre jamais automatiquement
docker run --restart no myapp
# always : redémarre toujours, même si arrêté manuellement
# (redémarre aussi au démarrage du daemon Docker)
docker run --restart always myapp
# on-failure : redémarre seulement si exit code non-zéro
# avec un maximum de 5 tentatives
docker run --restart on-failure:5 myapp
# unless-stopped : comme always, SAUF si arrêté manuellement
# (recommandé pour la plupart des services)
docker run --restart unless-stopped myapp
fig, ax = plt.subplots(figsize=(13, 4))
ax.set_xlim(0, 20)
ax.set_ylim(-0.5, 4.5)
ax.axis("off")
ax.set_facecolor("#f8f9fa")
fig.patch.set_facecolor("#f8f9fa")
ax.set_title("Comportement des restart policies selon le scénario", fontsize=12, fontweight="bold", pad=10)
policies = ["no", "on-failure:3", "unless-stopped", "always"]
scenarios = [
# (temps, événement, exit_code)
[(0, "start", 0), (3, "crash", 1), (4, None, None), (10, "stop manuel", 0)],
[(0, "start", 0), (3, "crash", 1), (4, "restart", 0), (6, "crash", 1), (7, "restart", 0), (9, "crash", 1), (10, "restart", 0), (12, "crash", 1), (13, "stop", 0)],
[(0, "start", 0), (3, "crash", 1), (4, "restart", 0), (8, "stop manuel", 0)],
[(0, "start", 0), (3, "crash", 1), (4, "restart", 0), (8, "stop manuel", 0), (9, "restart", 0)],
]
y_labels_colors = [("#e74c3c", "no — aucun redémarrage"),
("#f39c12", "on-failure:3 — max 3 crashs"),
("#27ae60", "unless-stopped — sauf arrêt manuel"),
("#3498db", "always — toujours")]
for i, (policy, events, (color, label)) in enumerate(zip(policies, scenarios, y_labels_colors)):
y = i + 0.5
ax.text(-0.2, y, label, ha="right", va="center", fontsize=9, color=color, fontweight="bold",
transform=ax.get_yaxis_transform())
running_start = None
for j, (t, evt, code) in enumerate(events):
if evt in ("start", "restart"):
running_start = t
elif evt in ("crash", "stop", "stop manuel") and running_start is not None:
# Ligne verte = conteneur en cours
ax.plot([running_start, t], [y, y], color="#27ae60", lw=6, solid_capstyle="round", alpha=0.7)
# Marque de fin
marker = "×" if "crash" in str(evt) else "■"
mcolor = "#e74c3c" if "crash" in str(evt) else "#555"
ax.text(t, y, marker, ha="center", va="center", fontsize=14, color=mcolor, fontweight="bold")
ax.text(t, y + 0.3, evt, ha="center", va="bottom", fontsize=7.5, color=mcolor)
running_start = None
elif evt is None and running_start is not None:
ax.plot([running_start, 8], [y, y], color="#27ae60", lw=6, solid_capstyle="round", alpha=0.7)
ax.text(8.5, y, "…", ha="left", va="center", fontsize=14, color="#999")
# Légende
ax.text(0.5, -0.25, "▬ Conteneur en cours d'exécution", ha="left", va="center",
fontsize=9, color="#27ae60")
ax.text(7, -0.25, "× Crash (exit code 1)", ha="left", va="center", fontsize=9, color="#e74c3c")
ax.text(13, -0.25, "■ Arrêt manuel (exit code 0)", ha="left", va="center", fontsize=9, color="#555")
plt.tight_layout()
plt.show()
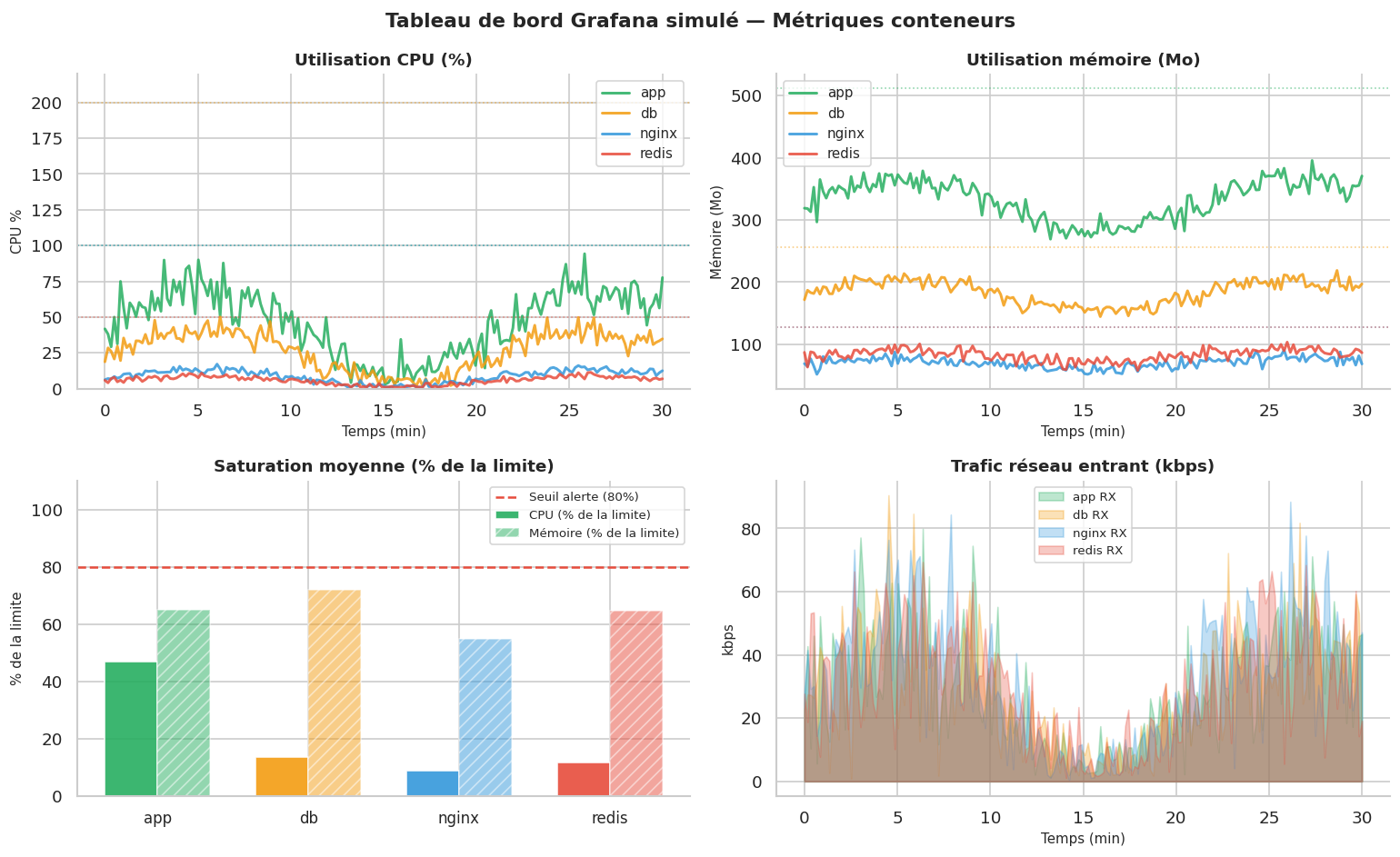
Monitoring : cAdvisor, Prometheus et Grafana#
En production, vous avez besoin de métriques : combien de CPU, de mémoire, de réseau chaque conteneur consomme. La stack classique est :
Conteneurs
↓
cAdvisor (collecte les métriques de chaque conteneur)
↓
Prometheus (agrège et stocke les métriques avec TSDB)
↓
Grafana (dashboards de visualisation)
# compose.yml — Stack de monitoring
services:
cadvisor:
image: gcr.io/cadvisor/cadvisor:v0.47.0
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8080:8080"
restart: unless-stopped
prometheus:
image: prom/prometheus:v2.48.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
- promdata:/prometheus
ports:
- "9090:9090"
restart: unless-stopped
grafana:
image: grafana/grafana:10.2.0
volumes:
- grafana-data:/var/lib/grafana
ports:
- "3000:3000"
environment:
GF_SECURITY_ADMIN_PASSWORD: ${GRAFANA_PASSWORD}
restart: unless-stopped
depends_on:
- prometheus
volumes:
promdata:
grafana-data:
# Simulation de métriques multi-conteneurs (style cAdvisor/Prometheus)
import math
def simulate_container_metrics(containers: list[dict], duration_min: int = 30) -> pd.DataFrame:
"""Simule des métriques pour plusieurs conteneurs."""
records = []
times = np.linspace(0, duration_min, duration_min * 6) # toutes les 10s
for container in containers:
name = container["name"]
base_cpu = container["base_cpu"]
base_mem = container["base_mem"]
cpu_limit = container.get("cpu_limit", 200)
mem_limit = container.get("mem_limit", 1024)
for t in times:
# Pattern de charge avec variation circadienne simulée
load = (0.5 + 0.4 * math.sin(t * 0.3) +
0.1 * np.random.normal())
load = max(0.05, min(1.0, load))
cpu = min(base_cpu * load * (1 + np.random.normal(0, 0.08)), cpu_limit)
mem = min(base_mem * (0.7 + 0.3 * load) + np.random.normal(0, 5), mem_limit)
records.append({
"container": name,
"time_min": t,
"cpu_pct": max(1, cpu),
"mem_mb": max(20, mem),
"cpu_limit": cpu_limit,
"mem_limit": mem_limit,
"net_rx_kbps": abs(np.random.normal(50, 20) * load),
"net_tx_kbps": abs(np.random.normal(30, 15) * load),
})
return pd.DataFrame(records)
containers_config = [
{"name": "nginx", "base_cpu": 15, "base_mem": 80, "cpu_limit": 100, "mem_limit": 128},
{"name": "app", "base_cpu": 80, "base_mem": 380, "cpu_limit": 100, "mem_limit": 512},
{"name": "db", "base_cpu": 45, "base_mem": 210, "cpu_limit": 200, "mem_limit": 256},
{"name": "redis", "base_cpu": 10, "base_mem": 95, "cpu_limit": 50, "mem_limit": 128},
]
metrics_df = simulate_container_metrics(containers_config)
fig, axes = plt.subplots(2, 2, figsize=(13, 8))
fig.suptitle("Tableau de bord Grafana simulé — Métriques conteneurs", fontsize=13, fontweight="bold")
container_colors = {"nginx": "#3498db", "app": "#27ae60", "db": "#f39c12", "redis": "#e74c3c"}
# --- CPU ---
ax_cpu = axes[0][0]
for cname, group in metrics_df.groupby("container"):
ax_cpu.plot(group["time_min"], group["cpu_pct"], label=cname,
color=container_colors[cname], lw=1.8, alpha=0.85)
limit = group["cpu_limit"].iloc[0]
ax_cpu.axhline(limit, color=container_colors[cname], ls=":", lw=1, alpha=0.5)
ax_cpu.set_title("Utilisation CPU (%)", fontsize=11, fontweight="bold")
ax_cpu.set_xlabel("Temps (min)", fontsize=9)
ax_cpu.set_ylabel("CPU %", fontsize=9)
ax_cpu.legend(fontsize=9)
ax_cpu.set_ylim(0, 220)
# --- Mémoire ---
ax_mem = axes[0][1]
for cname, group in metrics_df.groupby("container"):
ax_mem.plot(group["time_min"], group["mem_mb"], label=cname,
color=container_colors[cname], lw=1.8, alpha=0.85)
limit = group["mem_limit"].iloc[0]
ax_mem.axhline(limit, color=container_colors[cname], ls=":", lw=1, alpha=0.5)
ax_mem.set_title("Utilisation mémoire (Mo)", fontsize=11, fontweight="bold")
ax_mem.set_xlabel("Temps (min)", fontsize=9)
ax_mem.set_ylabel("Mémoire (Mo)", fontsize=9)
ax_mem.legend(fontsize=9)
# --- Usage moyen par conteneur (barres groupées) ---
ax_avg = axes[1][0]
summary = metrics_df.groupby("container").agg(
cpu_avg=("cpu_pct", "mean"),
cpu_limit=("cpu_limit", "first"),
mem_avg=("mem_mb", "mean"),
mem_limit=("mem_limit", "first"),
).reset_index()
x = np.arange(len(summary))
w = 0.35
bars_cpu = ax_avg.bar(x - w/2, summary["cpu_avg"] / summary["cpu_limit"] * 100,
width=w, label="CPU (% de la limite)",
color=[container_colors[c] for c in summary["container"]],
edgecolor="white", alpha=0.9)
bars_mem = ax_avg.bar(x + w/2, summary["mem_avg"] / summary["mem_limit"] * 100,
width=w, label="Mémoire (% de la limite)",
color=[container_colors[c] for c in summary["container"]],
edgecolor="white", alpha=0.5, hatch="///")
ax_avg.set_xticks(x)
ax_avg.set_xticklabels(summary["container"], fontsize=10)
ax_avg.axhline(80, color="#e74c3c", ls="--", lw=1.5, label="Seuil alerte (80%)")
ax_avg.set_title("Saturation moyenne (% de la limite)", fontsize=11, fontweight="bold")
ax_avg.set_ylabel("% de la limite", fontsize=9)
ax_avg.legend(fontsize=8)
ax_avg.set_ylim(0, 110)
# --- Réseau ---
ax_net = axes[1][1]
t_sample = metrics_df[metrics_df["container"] == "app"]["time_min"].values
for cname, group in metrics_df.groupby("container"):
ax_net.fill_between(group["time_min"], group["net_rx_kbps"],
alpha=0.3, color=container_colors[cname], label=f"{cname} RX")
ax_net.set_title("Trafic réseau entrant (kbps)", fontsize=11, fontweight="bold")
ax_net.set_xlabel("Temps (min)", fontsize=9)
ax_net.set_ylabel("kbps", fontsize=9)
ax_net.legend(fontsize=8)
plt.tight_layout()
plt.show()
Sécurité runtime : réduire la surface d’attaque#
Capabilities Linux#
# Supprimer TOUTES les capabilities, n'ajouter que celles nécessaires
docker run \
--cap-drop ALL \
--cap-add NET_BIND_SERVICE \ # Autoriser les ports < 1024
--read-only \ # Système de fichiers en lecture seule
--tmpfs /tmp:size=64m \ # /tmp en RAM (pour les fichiers temporaires)
--user 1000:1000 \ # Utilisateur non-root
--security-opt no-new-privileges \ # Interdit l'élévation de privilèges
myapp:latest
AppArmor et Seccomp#
# Profil seccomp personnalisé (bloque les syscalls inutiles)
docker run \
--security-opt seccomp=/etc/docker/seccomp-profiles/myapp.json \
myapp:latest
# Profil AppArmor
docker run \
--security-opt apparmor=docker-default \
myapp:latest
Le danger du Docker socket#
Danger : le socket Docker
Monter le socket Docker (/var/run/docker.sock) dans un conteneur donne à ce conteneur un accès root sur l’hôte entier. C’est une faille de sécurité majeure. Si vous avez besoin d’accès Docker dans un conteneur (CI/CD, outils de déploiement), utilisez :
Rootless Docker : le daemon Docker tourne sans root
Docker socket proxy (
tecnativa/docker-socket-proxy) : proxy qui filtre les API DockerKaniko ou Buildah : build d’images sans démon Docker
Backup de volumes : protéger les données#
# Pattern 1 : Conteneur sidecar pour sauvegarder un volume
docker run --rm \
--volumes-from my-postgres-container \ # Accès aux volumes du conteneur source
-v $(pwd)/backups:/backup \ # Dossier local pour les sauvegardes
postgres:16 \
pg_dump -U postgres mydb > /backup/mydb-$(date +%Y%m%d).sql
# Pattern 2 : Snapshot d'un volume nommé
docker run --rm \
-v pgdata:/data:ro \ # Volume source en lecture seule
-v $(pwd)/backups:/backup \
alpine \
tar czf /backup/pgdata-$(date +%Y%m%d).tar.gz -C /data .
# Pattern 3 : Restauration depuis un backup
docker run --rm \
-v pgdata:/data \
-v $(pwd)/backups:/backup:ro \
alpine \
tar xzf /backup/pgdata-20260321.tar.gz -C /data
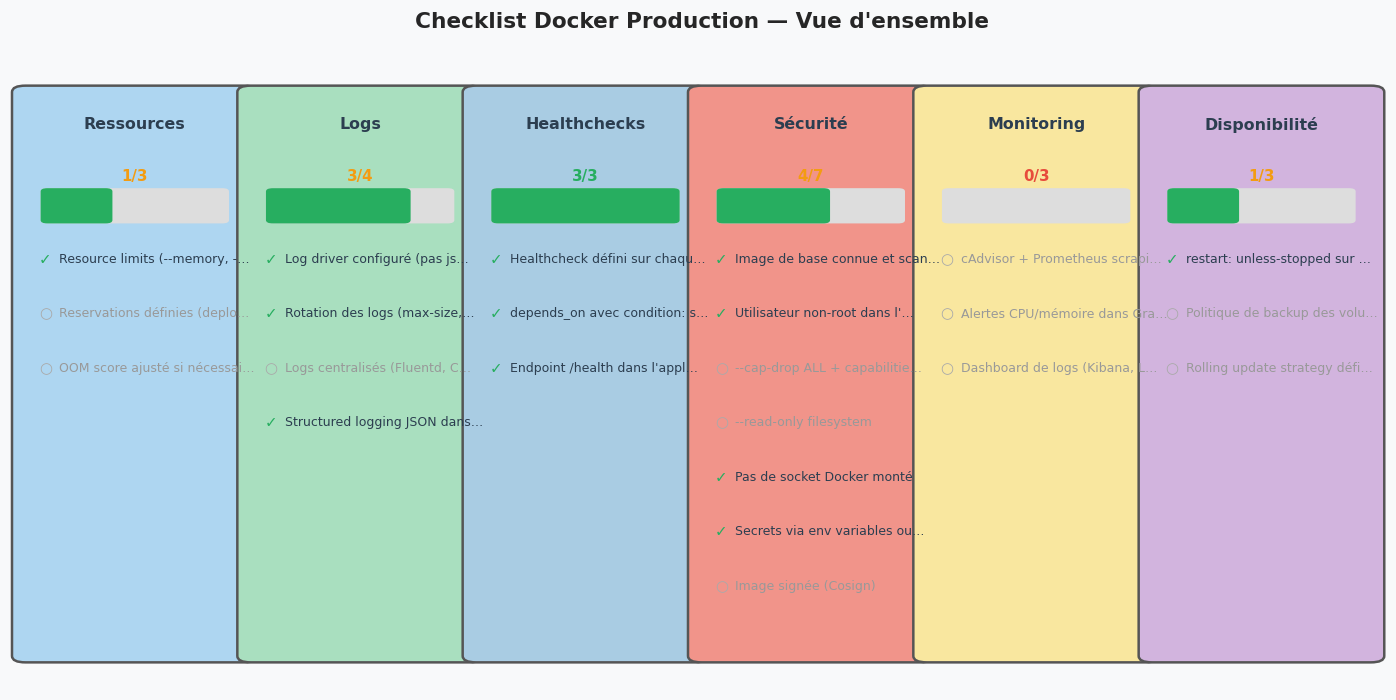
Checklist production Docker#
checklist = [
("Ressources", [
("Resource limits (--memory, --cpus)", True),
("Reservations définies (deploy.resources.reservations)", False),
("OOM score ajusté si nécessaire", False),
]),
("Logs", [
("Log driver configuré (pas json-file sans rotation)", True),
("Rotation des logs (max-size, max-file)", True),
("Logs centralisés (Fluentd, CloudWatch…)", False),
("Structured logging JSON dans l'application", True),
]),
("Healthchecks", [
("Healthcheck défini sur chaque service", True),
("depends_on avec condition: service_healthy", True),
("Endpoint /health dans l'application", True),
]),
("Sécurité", [
("Image de base connue et scannée (Trivy)", True),
("Utilisateur non-root dans l'image", True),
("--cap-drop ALL + capabilities minimales", False),
("--read-only filesystem", False),
("Pas de socket Docker monté", True),
("Secrets via env variables ou Docker secrets (pas en dur)", True),
("Image signée (Cosign)", False),
]),
("Monitoring", [
("cAdvisor + Prometheus scraping", False),
("Alertes CPU/mémoire dans Grafana", False),
("Dashboard de logs (Kibana, Loki)", False),
]),
("Disponibilité", [
("restart: unless-stopped sur tous les services", True),
("Politique de backup des volumes", False),
("Rolling update strategy définie", False),
]),
]
# Résumé
total = sum(len(items) for _, items in checklist)
done = sum(1 for _, items in checklist for _, checked in items if checked)
print(f"Checklist production Docker")
print(f"{'=' * 50}")
print(f"Score : {done}/{total} ({100*done//total}%)")
print()
for category, items in checklist:
count_done = sum(1 for _, c in items if c)
print(f"\n {category} ({count_done}/{len(items)})")
for item, checked in items:
icon = "✅" if checked else "☐"
print(f" {icon} {item}")
Checklist production Docker
==================================================
Score : 12/23 (52%)
Ressources (1/3)
✅ Resource limits (--memory, --cpus)
☐ Reservations définies (deploy.resources.reservations)
☐ OOM score ajusté si nécessaire
Logs (3/4)
✅ Log driver configuré (pas json-file sans rotation)
✅ Rotation des logs (max-size, max-file)
☐ Logs centralisés (Fluentd, CloudWatch…)
✅ Structured logging JSON dans l'application
Healthchecks (3/3)
✅ Healthcheck défini sur chaque service
✅ depends_on avec condition: service_healthy
✅ Endpoint /health dans l'application
Sécurité (4/7)
✅ Image de base connue et scannée (Trivy)
✅ Utilisateur non-root dans l'image
☐ --cap-drop ALL + capabilities minimales
☐ --read-only filesystem
✅ Pas de socket Docker monté
✅ Secrets via env variables ou Docker secrets (pas en dur)
☐ Image signée (Cosign)
Monitoring (0/3)
☐ cAdvisor + Prometheus scraping
☐ Alertes CPU/mémoire dans Grafana
☐ Dashboard de logs (Kibana, Loki)
Disponibilité (1/3)
✅ restart: unless-stopped sur tous les services
☐ Politique de backup des volumes
☐ Rolling update strategy définie
# Visualisation de la checklist
fig, ax = plt.subplots(figsize=(12, 6))
ax.set_facecolor("#f8f9fa")
fig.patch.set_facecolor("#f8f9fa")
ax.axis("off")
ax.set_title("Checklist Docker Production — Vue d'ensemble", fontsize=13, fontweight="bold", pad=12)
cat_colors = {
"Ressources": "#aed6f1",
"Logs": "#a9dfbf",
"Healthchecks": "#a9cce3",
"Sécurité": "#f1948a",
"Monitoring": "#f9e79f",
"Disponibilité": "#d2b4de",
}
x_start = 0.0
x_gap = 0.005
cat_width = 1.0 / len(checklist) - x_gap
for i, (category, items) in enumerate(checklist):
x = i * (cat_width + x_gap)
n = len(items)
done_c = sum(1 for _, c in items if c)
color = cat_colors.get(category, "#ddd")
# Boîte catégorie
box = FancyBboxPatch((x, 0.05), cat_width, 0.88,
boxstyle="round,pad=0.01",
facecolor=color, edgecolor="#555", linewidth=1.5,
transform=ax.transAxes, clip_on=False)
ax.add_patch(box)
ax.text(x + cat_width/2, 0.88, category,
ha="center", va="center", fontsize=9.5, fontweight="bold", color="#2c3e50",
transform=ax.transAxes)
ax.text(x + cat_width/2, 0.80, f"{done_c}/{n}",
ha="center", va="center", fontsize=9,
color="#27ae60" if done_c == n else ("#f39c12" if done_c >= n//2 else "#e74c3c"),
fontweight="bold", transform=ax.transAxes)
# Barre de progression
prog_w = cat_width * 0.8
prog_x = x + cat_width * 0.1
ax.add_patch(FancyBboxPatch((prog_x, 0.73), prog_w, 0.045,
boxstyle="round,pad=0.005",
facecolor="#ddd", edgecolor="none",
transform=ax.transAxes, clip_on=False))
if done_c > 0:
ax.add_patch(FancyBboxPatch((prog_x, 0.73), prog_w * done_c/n, 0.045,
boxstyle="round,pad=0.005",
facecolor="#27ae60", edgecolor="none",
transform=ax.transAxes, clip_on=False))
# Items
for j, (item, checked) in enumerate(items):
y = 0.67 - j * 0.085
icon = "✓" if checked else "○"
icon_color = "#27ae60" if checked else "#aaa"
text_color = "#2c3e50" if checked else "#999"
ax.text(x + 0.01, y, icon, ha="left", va="center", fontsize=9,
color=icon_color, fontweight="bold", transform=ax.transAxes)
short_item = item[:28] + "…" if len(item) > 28 else item
ax.text(x + 0.025, y, short_item, ha="left", va="center", fontsize=7.5,
color=text_color, transform=ax.transAxes)
plt.tight_layout()
plt.show()
Points clés à retenir#
Résumé du chapitre
Docker en production, les 6 règles d’or :
Logs : écrivez sur stdout/stderr, configurez la rotation, centralisez avec Fluentd ou un driver cloud
Resource limits : toujours définir
--memoryet--cpuspour protéger l’hôteRestart policy :
unless-stoppedpour les services,nopour les jobs one-shotSécurité :
--cap-drop ALL, utilisateur non-root, filesystem en lecture seule, jamais le socket DockerMonitoring : cAdvisor → Prometheus → Grafana est la stack standard open-source
Backups : les volumes ne sont pas sauvegardés automatiquement — définissez une stratégie
Le principe fondamental : un conteneur doit être éphémère et stateless. Les données persistent dans des volumes, pas dans le conteneur.