Chapitre 18 — API-first et workflow de design#
L’approche code-first consiste à implémenter un service, puis à générer la documentation API depuis le code. L’approche API-first inverse la démarche : le contrat de l’API est conçu, révisé et validé avant qu’une seule ligne d’implémentation soit écrite. Ce renversement change profondément la manière de collaborer et de livrer.
API-first — le contrat comme source de vérité#
Dans l’approche code-first, la spécification OpenAPI est une conséquence du code. Elle décrit ce que le code fait — y compris ses imperfections. Les équipes qui consomment l’API attendent que l’implémentation soit prête pour commencer leur propre développement.
Dans l’approche API-first :
Le contrat (fichier OpenAPI) est écrit avant le code
Il est soumis à review comme un pull request de code
Un mock server permet aux consommateurs de développer en parallèle
L’implémentation doit satisfaire le contrat, pas l’inverse
Des tests de conformité vérifient que l’implémentation correspond au contrat
Avantages#
Mocking précoce : dès que le contrat est approuvé, une équipe frontend ou un consommateur tiers peut démarrer son intégration contre un mock. Les équipes travaillent en parallèle.
Review de design : le contrat peut être relu par des pairs techniques, des architectes, des équipes sécurité — avant que le code soit écrit. Il est beaucoup moins coûteux de corriger une décision de design à ce stade.
Documentation = livrable : la spec OpenAPI n’est pas une documentation annexe générée en fin de sprint. Elle est le livrable principal du travail de design.
Parallélisation : backend et frontend avancent simultanément. La dépendance séquentielle est brisée.
Code-first vs API-first
L’approche code-first (FastAPI, Spring, NestJS avec génération de spec) reste valide pour les APIs internes sans consommateurs externes et pour les équipes petites où le coût de coordination est faible. L’API-first apporte le plus de valeur quand plusieurs équipes consomment l’API, quand des clients externes sont impliqués, ou quand la stabilité du contrat est critique.
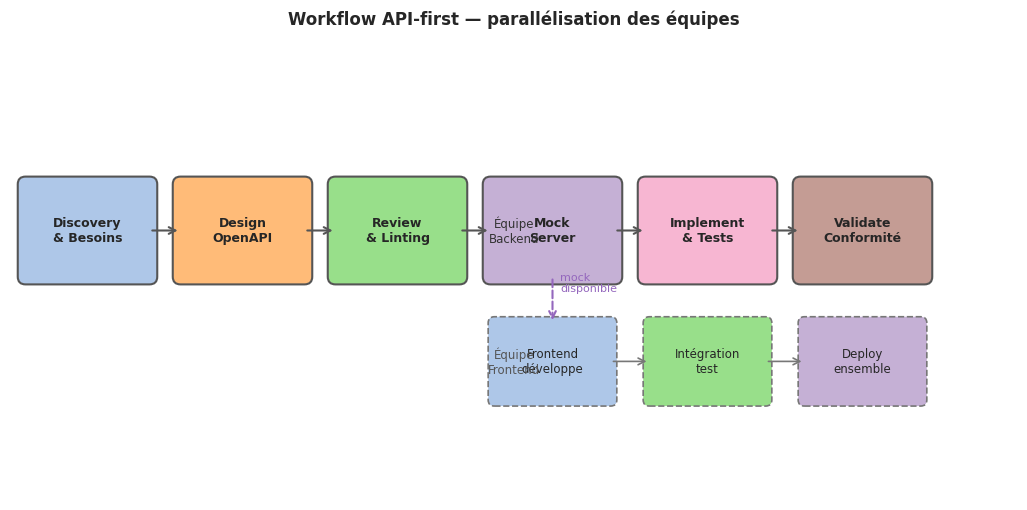
Workflow de design#
Le workflow API-first suit six étapes itératives.
Étape 1 — Discovery#
Avant d’écrire la spec, comprendre les besoins :
Quelles opérations métier l’API doit-elle exposer ?
Qui sont les consommateurs ? Quels langages, quels frameworks ?
Quelles contraintes existent (performance, sécurité, régulation) ?
Quelles APIs existantes peut-on réutiliser ou étendre ?
Outils : event storming, domain modeling, interviews des équipes consommatrices.
Étape 2 — Design#
Rédiger le fichier OpenAPI. Suivre le style guide de l’organisation. Pour chaque ressource :
Choisir les noms de ressources (substantifs, pluriels, snake_case)
Définir les opérations (CRUD ou opérations métier)
Spécifier les schémas de requête et de réponse
Documenter les codes d’erreur
Définir la pagination, le filtrage, le tri
Étape 3 — Review#
Soumettre le fichier OpenAPI en pull request. La review couvre :
Cohérence avec le style guide (linting Spectral)
Sécurité (authentification, autorisation, validation des entrées)
Breaking changes (si l’API existait déjà)
Expérience développeur (nommage clair, exemples présents)
Étape 4 — Mock#
Déployer un mock server depuis la spec validée. Les consommateurs peuvent commencer à développer immédiatement.
# Prism (Stoplight) — mock server depuis une spec OpenAPI
npx @stoplight/prism-cli mock openapi.yaml
# Le mock répond avec les exemples définis dans la spec
curl http://localhost:4010/api/v2/users/42
# → {"id": 42, "name": "Alice Dupont", ...}
Étape 5 — Implement#
L’équipe backend implémente le service en ayant le contrat comme référence. Le code ne génère pas la spec — il doit satisfaire la spec existante.
Étape 6 — Validate#
Des tests de conformité vérifient que l’implémentation correspond au contrat :
# Dredd — tests de conformité OpenAPI → serveur réel
dredd openapi.yaml http://localhost:8000
# Schemathesis — fuzzing basé sur la spec OpenAPI
schemathesis run openapi.yaml --url http://localhost:8000
Mock servers#
Un mock server simule le comportement de l’API à partir de la spec OpenAPI, sans implémentation réelle.
Prism — validation et mock#
Prism (Stoplight) est l’outil de référence. Il opère en deux modes :
Mode mock : retourne les exemples définis dans la spec, ou génère des réponses aléatoires conformes aux schémas.
Mode proxy + validation : relaie les requêtes vers un vrai serveur et valide que les requêtes/réponses sont conformes à la spec. Idéal pour les tests d’intégration.
# Dans la spec OpenAPI, définir des exemples de réponse
paths:
/users/{userId}:
get:
responses:
"200":
content:
application/json:
schema:
$ref: "#/components/schemas/User"
examples:
alice:
summary: "Utilisateur standard"
value:
id: 42
name: "Alice Dupont"
email: "alice@example.com"
created_at: "2024-01-15T10:30:00Z"
Wiremock#
Wiremock est un mock server Java plus puissant que Prism pour les cas d’usage avancés : simulation de latence, injection d’erreurs, scénarios avec état.
{
"request": {
"method": "POST",
"url": "/api/v2/orders"
},
"response": {
"status": 201,
"jsonBody": {"id": "ord-123", "status": "pending"},
"fixedDelayMilliseconds": 150
}
}
Utilité pour le développement frontend#
Le frontend peut développer l’intégration API avant que le backend soit prêt. Le mock server permet :
Tests d’interface avec des données réalistes
Test des cas d’erreur (le vrai serveur est rarement en erreur en dev)
Développement offline
Tests E2E reproductibles
API style guides et linting avec Spectral#
Un style guide API est un ensemble de règles qui définissent comment les APIs de l’organisation doivent être conçues. Il garantit la cohérence entre équipes et réduit le coût d’apprentissage pour les consommateurs.
Règles typiques d’un style guide#
Nommage :
Ressources en snake_case, plurielles (
/users, pas/userni/User)Champs JSON en snake_case (
created_at, pascreatedAt)Pas d’abréviations non standard (
customer_id, pascust_id)
Versioning :
URI versioning obligatoire (
/api/v{n}/)Version dans
info.versionau format SemVer
Pagination :
Cursor-based sur les grandes collections
Paramètres standards :
limit,cursorEnveloppe standard :
{"data": [...], "next_cursor": "..."}
Erreurs :
Format RFC 7807 Problem Details obligatoire
Champ
error_codemachine-lisible obligatoire
Spectral — linting OpenAPI#
Spectral est un linter pour les specs OpenAPI. Il vérifie les règles du style guide automatiquement, en CI comme localement.
# .spectral.yaml — règles custom
extends: ["spectral:oas"]
rules:
# Vérifier que tous les endpoints ont une description
operation-description:
description: "Chaque opération doit avoir une description"
severity: warn
given: "$.paths[*][*]"
then:
field: description
function: truthy
# Vérifier le nommage snake_case des paramètres
parameter-snake-case:
description: "Les paramètres doivent être en snake_case"
severity: error
given: "$.paths[*][*].parameters[*].name"
then:
function: pattern
functionOptions:
match: "^[a-z][a-z0-9_]*$"
# Vérifier que les réponses 2xx ont des exemples
response-examples-required:
description: "Les réponses 2xx doivent avoir des exemples"
severity: warn
given: "$.paths[*][*].responses[?(@property >= '200' && @property < '300')]"
then:
field: content.application/json.examples
function: truthy
# Lancer Spectral en CI
spectral lint openapi.yaml --ruleset .spectral.yaml
# Sortie :
# ✖ 3 problems (1 error, 2 warnings) found.
# [1:1] error: parameter-snake-case: "userId" should be "user_id"
Design review#
La design review d’une API est l’équivalent de la code review — mais en amont. Elle doit être structurée pour être efficace.
Checklist de review#
Ressources et nommage :
Les noms de ressources sont-ils cohérents avec le domaine métier ?
La hiérarchie des ressources est-elle logique (pas plus de 2 niveaux) ?
Les noms respectent-ils le style guide (snake_case, pluriels) ?
Opérations HTTP :
Les verbes HTTP sont-ils utilisés correctement (GET = lecture idempotente, POST = création) ?
Les opérations destructives sont-elles idempotentes (DELETE
/users/42= idempotent) ?Les codes de retour sont-ils appropriés (201 pour création, 204 pour suppression) ?
Sécurité :
Chaque endpoint a-t-il un schéma d’authentification défini ?
Les permissions sont-elles documentées (scopes OAuth) ?
Les données sensibles sont-elles exclues des réponses par défaut ?
Évolutivité :
Les champs optionnels ont-ils des valeurs par défaut documentées ?
Les enums sont-ils documentés comme extensibles ?
La pagination est-elle cursor-based (scalable) ?
ADR pour les décisions API#
Les Architecture Decision Records (ADR) documentent les décisions importantes et leur contexte. Pour les APIs, un ADR est utile quand :
On choisit un pattern non standard (pourquoi
POST /actions/cancelplutôt quePATCH /orders/{id}?)On décide d’une exception au style guide
On choisit entre deux patterns également valides
## ADR-042 : Endpoint d'annulation de commande
**Décision :** POST /orders/{id}/cancel plutôt que PATCH /orders/{id}
**Contexte :** L'annulation déclenche une série d'effets (remboursement, notification,
libération de stock). Ce n'est pas une simple modification de champ.
**Alternatives considérées :**
- PATCH /orders/{id} avec {"status": "cancelled"} — trop générique, ne capture
pas la sémantique de l'annulation
- DELETE /orders/{id} — sémantique incorrecte (la commande n'est pas supprimée)
**Conséquences :** Exception documentée dans le style guide section "Actions métier".
Collaboration — API portal et onboarding#
L’API-first n’est pas seulement un processus technique — c’est aussi un processus de collaboration avec les consommateurs.
API portal#
Un API portal est un portail documentaire qui centralise toutes les APIs de l’organisation. Fonctionnalités clés :
Documentation interactive (Swagger UI, Redoc)
Sandbox pour tester les APIs avec ses propres credentials
Gestion des clés API et OAuth apps
Métriques d’utilisation par consommateur
Changelog et annonces de déprécation
Outils : Stoplight Platform, Readme.io, Backstage (Spotify), Kong DevPortal.
Onboarding des consommateurs#
Un bon onboarding réduit le temps entre « je découvre l’API » et « j’ai mon premier appel réussi » (time to first call). Éléments essentiels :
Quickstart : en 5 minutes, obtenir un token et faire le premier appel
SDK officiels dans les langages principaux des consommateurs
Exemples runnable dans la documentation (notebooks, code sandbox)
Environnement sandbox avec des données de test réalistes
Sandbox#
Un environnement sandbox est une instance isolée de l’API avec :
Données fictives réinitialisées périodiquement
Paiements simulés (pas de vrais débits)
Rate limits plus permissifs
Logs accessibles au développeur pour le débogage
Coût de l’onboarding
Le coût d’onboarding d’un nouveau consommateur est souvent 10× le coût d’un appel API. Investir dans la documentation, les exemples et le sandbox est un multiplicateur de valeur : chaque consommateur activé représente un revenu ou un gain de productivité.
API changelog#
Un changelog bien tenu est un outil de communication critique pour les consommateurs.
Format keepachangelog#
# Changelog
## [Unreleased]
## [2.1.0] — 2024-12-01
### Added
- GET /users/{id}/activity — historique d'activité paginé
- Paramètre `include_deleted` sur GET /users
### Changed
- GET /orders — limite par défaut passée de 20 à 50
### Deprecated
- GET /v1/reports — sera retiré le 2025-06-30. Utiliser GET /v2/reports.
## [2.0.0] — 2024-09-15
### BREAKING CHANGES
- GET /users/{id} : champ `fullname` supprimé (utilisez `first_name` + `last_name`)
- POST /users : champ `phone` désormais obligatoire
Génération depuis les commits conventionnels#
Les commits conventionnels (Conventional Commits) permettent de générer le changelog automatiquement :
feat(users): add GET /users/{id}/activity endpoint
fix(orders): correct pagination cursor encoding
feat(reports)!: BREAKING CHANGE — remove v1 reports endpoint
Des outils comme release-please (Google) ou semantic-release lisent l’historique git et génèrent le changelog + le tag de version.
Communication aux consommateurs#
Chaque release MINOR ou MAJOR devrait déclencher :
Mise à jour du changelog dans le portail
Email/Slack aux équipes consommatrices enregistrées
Headers
Deprecation+Sunsetsur les endpoints impactésPage de migration pour les breaking changes
Cellules exécutables#
Linter OpenAPI minimaliste#
import json
import re
def lint_openapi_schema(spec: dict) -> list[dict]:
"""
Linter minimaliste qui vérifie un sous-ensemble de règles de style guide.
Retourne une liste d'issues avec severity, rule, location, message.
"""
issues = []
def issue(severity, rule, location, message):
issues.append({"severity": severity, "rule": rule, "location": location, "message": message})
# Règle 1 : info.version doit être SemVer
version = spec.get("info", {}).get("version", "")
if not re.match(r"^\d+\.\d+\.\d+", version):
issue("error", "semver-version", "info.version",
f"La version '{version}' n'est pas au format SemVer (MAJOR.MINOR.PATCH)")
# Règle 2 : Chaque opération doit avoir une description
for path, path_item in spec.get("paths", {}).items():
for method in ["get", "post", "put", "patch", "delete"]:
op = path_item.get(method)
if op is None:
continue
location = f"paths.{path}.{method}"
if not op.get("description") and not op.get("summary"):
issue("warning", "operation-description", location,
"L'opération n'a ni description ni summary")
# Règle 3 : Tags obligatoires
if not op.get("tags"):
issue("warning", "operation-tags", location,
"L'opération n'a pas de tags (nécessaire pour l'organisation de la doc)")
# Règle 4 : operationId obligatoire
if not op.get("operationId"):
issue("error", "operation-id", location,
"operationId manquant (nécessaire pour les SDK générés)")
# Règle 5 : Paramètres en snake_case
for param in op.get("parameters", []):
name = param.get("name", "")
if not re.match(r"^[a-z][a-z0-9_]*$", name):
issue("error", "snake-case-params", f"{location}.parameters.{name}",
f"Le paramètre '{name}' n'est pas en snake_case")
# Règle 6 : Paths commençant par /api/v{n}/
for path in spec.get("paths", {}):
if not re.match(r"^/api/v\d+/", path):
issue("warning", "api-versioned-path", f"paths.{path}",
f"Le chemin '{path}' devrait commencer par /api/v{{n}}/")
return issues
# Spec de test (intentionnellement imparfaite)
spec = {
"openapi": "3.1.0",
"info": {
"title": "User API",
"version": "2.1" # ← non SemVer
},
"paths": {
"/api/v2/users": {
"get": {
"summary": "Liste des utilisateurs",
"operationId": "listUsers",
"tags": ["users"],
"parameters": [
{"name": "pageSize", "in": "query", "schema": {"type": "integer"}}, # ← camelCase
{"name": "cursor", "in": "query", "schema": {"type": "string"}},
],
"responses": {"200": {"description": "OK"}}
},
"post": {
# ← pas de description, pas de tags, pas d'operationId
"responses": {"201": {"description": "Created"}}
}
},
"/reports": { # ← pas versionné
"get": {
"operationId": "getReports",
"summary": "Reports",
"tags": ["reports"],
"responses": {"200": {"description": "OK"}}
}
}
}
}
issues = lint_openapi_schema(spec)
errors = [i for i in issues if i["severity"] == "error"]
warnings = [i for i in issues if i["severity"] == "warning"]
print(f"=== Résultats du linting ===")
print(f"Erreurs : {len(errors)}")
print(f"Warnings : {len(warnings)}")
print()
for iss in sorted(issues, key=lambda x: (x["severity"] != "error", x["location"])):
icon = "✖" if iss["severity"] == "error" else "⚠"
print(f"{icon} [{iss['rule']}] {iss['location']}")
print(f" → {iss['message']}")
=== Résultats du linting ===
Erreurs : 3
Warnings : 3
✖ [semver-version] info.version
→ La version '2.1' n'est pas au format SemVer (MAJOR.MINOR.PATCH)
✖ [snake-case-params] paths./api/v2/users.get.parameters.pageSize
→ Le paramètre 'pageSize' n'est pas en snake_case
✖ [operation-id] paths./api/v2/users.post
→ operationId manquant (nécessaire pour les SDK générés)
⚠ [operation-description] paths./api/v2/users.post
→ L'opération n'a ni description ni summary
⚠ [operation-tags] paths./api/v2/users.post
→ L'opération n'a pas de tags (nécessaire pour l'organisation de la doc)
⚠ [api-versioned-path] paths./reports
→ Le chemin '/reports' devrait commencer par /api/v{n}/
Visualisation du workflow API-first#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", font_scale=1.0)
fig, ax = plt.subplots(figsize=(13, 6))
ax.set_xlim(0, 13)
ax.set_ylim(0, 6)
ax.axis("off")
steps = [
(1, 3.5, "Discovery\n& Besoins", "#aec7e8"),
(3, 3.5, "Design\nOpenAPI", "#ffbb78"),
(5, 3.5, "Review\n& Linting", "#98df8a"),
(7, 3.5, "Mock\nServer", "#c5b0d5"),
(9, 3.5, "Implement\n& Tests", "#f7b6d2"),
(11, 3.5, "Validate\nConformité", "#c49c94"),
]
for x, y, label, color in steps:
rect = mpatches.FancyBboxPatch(
(x - 0.8, y - 0.6), 1.6, 1.2,
boxstyle="round,pad=0.1",
facecolor=color, edgecolor="#555555", linewidth=1.5
)
ax.add_patch(rect)
ax.text(x, y, label, ha="center", va="center", fontsize=9, fontweight="bold")
# Flèches entre étapes
for i in range(len(steps) - 1):
x1 = steps[i][0] + 0.8
x2 = steps[i + 1][0] - 0.8
y_mid = 3.5
ax.annotate("", xy=(x2, y_mid), xytext=(x1, y_mid),
arrowprops=dict(arrowstyle="->", color="#555555", lw=1.5))
# Piste parallèle : frontend développe en parallèle du mock
parallel_steps = [
(7, 1.8, "Frontend\ndéveloppe", "#aec7e8"),
(9, 1.8, "Intégration\ntest", "#98df8a"),
(11, 1.8, "Deploy\nensemble", "#c5b0d5"),
]
for x, y, label, color in parallel_steps:
rect = mpatches.FancyBboxPatch(
(x - 0.75, y - 0.5), 1.5, 1.0,
boxstyle="round,pad=0.08",
facecolor=color, edgecolor="#777777", linewidth=1.2, linestyle="--"
)
ax.add_patch(rect)
ax.text(x, y, label, ha="center", va="center", fontsize=8.5)
for i in range(len(parallel_steps) - 1):
x1 = parallel_steps[i][0] + 0.75
x2 = parallel_steps[i + 1][0] - 0.75
ax.annotate("", xy=(x2, 1.8), xytext=(x1, 1.8),
arrowprops=dict(arrowstyle="->", color="#777777", lw=1.2))
# Flèche du Mock → Frontend
ax.annotate("", xy=(7, 1.8 + 0.5), xytext=(7, 3.5 - 0.6),
arrowprops=dict(arrowstyle="->", color="#9467bd", lw=1.5, linestyle="dashed"))
ax.text(7.1, 2.7, "mock\ndisponible", fontsize=8, color="#9467bd")
ax.text(6.5, 3.5, "Équipe\nBackend", fontsize=8.5, ha="center", va="center",
color="#333333")
ax.text(6.5, 1.8, "Équipe\nFrontend", fontsize=8.5, ha="center", va="center",
color="#555555")
ax.set_title("Workflow API-first — parallélisation des équipes", fontsize=12, fontweight="bold", pad=10)
plt.show()
Checklist de design review#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", font_scale=0.9)
categories = {
"Ressources &\nNommage": [
"Noms en snake_case pluriels",
"Hiérarchie ≤ 2 niveaux",
"Cohérence avec le domaine métier",
"Pas d'abréviations non standard",
],
"Opérations\nHTTP": [
"Verbes HTTP corrects",
"Idempotence respectée",
"Codes de retour appropriés",
"Pagination définie",
],
"Sécurité": [
"Auth définie sur chaque endpoint",
"Scopes OAuth documentés",
"Données sensibles masquées",
"Rate limiting spécifié",
],
"Évolutivité": [
"Champs optionnels avec défauts",
"Enums documentés extensibles",
"additionalProperties: true (réponses)",
"Versioning défini",
],
"Documentation": [
"Tous les endpoints décrits",
"Exemples dans la spec",
"Erreurs documentées (RFC 7807)",
"operationId présent",
],
}
colors = {
"Ressources &\nNommage": "#aec7e8",
"Opérations\nHTTP": "#98df8a",
"Sécurité": "#ff9896",
"Évolutivité": "#ffbb78",
"Documentation": "#c5b0d5",
}
fig, ax = plt.subplots(figsize=(13, 7))
ax.axis("off")
col_width = 2.4
row_height = 0.55
x_start = 0.2
for col_idx, (category, items) in enumerate(categories.items()):
x = x_start + col_idx * (col_width + 0.15)
color = colors[category]
# En-tête
header = mpatches.FancyBboxPatch(
(x, 5.5), col_width, 0.7,
boxstyle="round,pad=0.05",
facecolor=color, edgecolor="#555555", linewidth=1.2
)
ax.add_patch(header)
ax.text(x + col_width / 2, 5.85, category, ha="center", va="center",
fontsize=9, fontweight="bold")
# Items
for row_idx, item in enumerate(items):
y = 5.5 - (row_idx + 1) * (row_height + 0.08)
cell = mpatches.FancyBboxPatch(
(x, y), col_width, row_height,
boxstyle="round,pad=0.04",
facecolor=color, alpha=0.3, edgecolor="#aaaaaa", linewidth=0.8
)
ax.add_patch(cell)
ax.text(x + 0.2, y + row_height / 2, "☐", fontsize=10, va="center")
ax.text(x + 0.45, y + row_height / 2, item, fontsize=8, va="center")
ax.set_xlim(0, 13)
ax.set_ylim(2.8, 6.5)
ax.set_title("Checklist de design review API", fontsize=12, fontweight="bold", pad=8)
plt.show()

Changelog depuis les commits conventionnels#
import re
from datetime import date
# Commits conventionnels simulés (format: type(scope): message)
commits = [
("feat(users)", "add GET /users/{id}/activity endpoint"),
("feat(users)", "add include_deleted parameter on GET /users"),
("fix(orders)", "correct pagination cursor encoding for unicode names"),
("fix(auth)", "fix token refresh race condition"),
("feat(reports)!", "BREAKING CHANGE: remove v1 reports endpoint, use v2"),
("feat(products)", "add GET /products/search endpoint"),
("fix(products)", "fix price rounding to 2 decimals"),
("chore(ci)", "update Spectral to 6.11.0"),
("docs(auth)", "add OAuth2 flow examples in OpenAPI spec"),
("feat(orders)!", "BREAKING CHANGE: field 'total' renamed to 'total_amount'"),
("fix(users)", "fix email validation regex rejecting + in local part"),
("feat(webhooks)", "add webhook signature verification"),
("perf(products)", "add DB index on products.sku — 10x faster lookup"),
]
# Regex pour parser les commits conventionnels
PATTERN = re.compile(
r"^(?P<type>[a-z]+)"
r"(?:\((?P<scope>[^)]+)\))?(?P<breaking>!)?"
r":\s*(?P<message>.+)$"
)
def parse_commit(raw_type: str, raw_message: str) -> dict | None:
full = f"{raw_type}: {raw_message}"
m = PATTERN.match(full)
if not m:
return None
return {
"type": m.group("type"),
"scope": m.group("scope"),
"breaking": bool(m.group("breaking")),
"message": m.group("message"),
}
def determine_bump(parsed_commits: list[dict]) -> str:
if any(c["breaking"] or c["message"].startswith("BREAKING CHANGE") for c in parsed_commits):
return "MAJOR"
if any(c["type"] in ("feat",) for c in parsed_commits):
return "MINOR"
return "PATCH"
def generate_changelog(commits_raw: list[tuple], current_version: str) -> str:
parsed = [parse_commit(t, m) for t, m in commits_raw if parse_commit(t, m)]
bump = determine_bump(parsed)
major, minor, patch = map(int, current_version.split("."))
if bump == "MAJOR":
major += 1; minor = 0; patch = 0
elif bump == "MINOR":
minor += 1; patch = 0
else:
patch += 1
new_version = f"{major}.{minor}.{patch}"
sections = {"BREAKING CHANGES": [], "Added": [], "Fixed": [], "Changed": [], "Performance": []}
for c in parsed:
msg = f"- {c['scope'] + ': ' if c['scope'] else ''}{c['message']}"
if c["breaking"] or c["message"].startswith("BREAKING CHANGE"):
sections["BREAKING CHANGES"].append(msg)
elif c["type"] == "feat":
sections["Added"].append(msg)
elif c["type"] == "fix":
sections["Fixed"].append(msg)
elif c["type"] == "perf":
sections["Performance"].append(msg)
changelog = f"## [{new_version}] — {date.today().isoformat()}\n\n"
changelog += f"**Bump type : {bump}** (version précédente : {current_version})\n\n"
for section, items in sections.items():
if items:
changelog += f"### {section}\n"
changelog += "\n".join(items) + "\n\n"
return changelog.strip(), new_version
changelog_text, new_version = generate_changelog(commits, current_version="2.3.1")
print(f"Nouvelle version : {new_version}\n")
print(changelog_text)
Nouvelle version : 3.0.0
## [3.0.0] — 2026-03-26
**Bump type : MAJOR** (version précédente : 2.3.1)
### BREAKING CHANGES
- reports: BREAKING CHANGE: remove v1 reports endpoint, use v2
- orders: BREAKING CHANGE: field 'total' renamed to 'total_amount'
### Added
- users: add GET /users/{id}/activity endpoint
- users: add include_deleted parameter on GET /users
- products: add GET /products/search endpoint
- webhooks: add webhook signature verification
### Fixed
- orders: correct pagination cursor encoding for unicode names
- auth: fix token refresh race condition
- products: fix price rounding to 2 decimals
- users: fix email validation regex rejecting + in local part
### Performance
- products: add DB index on products.sku — 10x faster lookup
Résumé#
L’approche API-first repositionne le contrat OpenAPI comme le livrable principal du travail de design, avant toute implémentation. Les bénéfices sont concrets : les équipes frontend et backend travaillent en parallèle via un mock server, les décisions de design sont prises collectivement lors d’une review structurée, et les breaking changes sont détectés avant la production.
Les points clés :
Le workflow API-first suit six étapes : discovery → design → review → mock → implement → validate. La validate (tests de conformité Dredd, Schemathesis) garantit que l’implémentation ne dérive pas du contrat.
Spectral automatise l’application du style guide en CI. Les règles custom permettent d’encoder des conventions spécifiques à l’organisation (snake_case, pagination cursor-based, RFC 7807).
Un mock server (Prism) permet aux consommateurs de démarrer leur intégration dès l’approbation de la spec — parfois des semaines avant que le backend soit prêt.
La design review est plus efficace avec une checklist structurée par catégorie : ressources, HTTP, sécurité, évolutivité, documentation.
Le changelog en format keepachangelog avec génération depuis les commits conventionnels réduit la friction de communication avec les consommateurs.