Chapitre 13 — BFF — Backend for Frontend#
Le pattern BFF (Backend for Frontend) est une stratégie architecturale qui consiste à créer un backend dédié pour chaque type de client. Plutôt qu’une API générique que tous les clients consomment de la même façon, chaque BFF est taillé sur mesure pour les besoins spécifiques de son client. Ce chapitre décrit le problème que résout ce pattern, son implémentation, ses variantes, et ses limites.
Problème résolu#
Over-fetching et under-fetching#
Une API REST générique expose des ressources complètes. Un client web qui affiche la fiche complète d’un utilisateur peut utiliser la totalité des champs retournés. Un client mobile qui n’affiche que l’avatar et le nom reçoit la même réponse volumineuse mais ignore 90% des données — c’est l”over-fetching. La bande passante est gaspillée et la batterie du mobile sollicitée inutilement.
L”under-fetching est le problème inverse : la ressource retournée ne contient pas suffisamment d’information pour construire l’écran, ce qui oblige le client à enchaîner plusieurs appels. Pour afficher un fil d’actualité, le client récupère d’abord la liste des posts, puis pour chaque post récupère l’auteur, puis les statistiques — c’est le problème N+1 côté client.
Chattiness et clients hétérogènes#
La chattiness (verbosité du dialogue réseau) est la multiplication d’allers-retours entre le client et le serveur. Sur un réseau mobile avec une latence de 80-150ms par aller-retour, enchaîner 5 appels pour construire une page signifie 400-750ms de latence réseau incompressible, avant même le rendu.
Les clients hétérogènes aggravent le problème : une Smart TV a des contraintes de mémoire différentes d’une application web, qui a des contraintes différentes d’un partenaire B2B qui consomme les données dans ses propres systèmes. Une API générique ne peut pas optimiser simultanément pour tous ces profils.
Note
L’alternative courante à BFF pour résoudre l’over/under-fetching est GraphQL, qui permet au client de spécifier exactement les champs dont il a besoin. GraphQL peut lui-même être implémenté comme un BFF — nous y revenons en section 7.
Pattern BFF#
Un BFF par type de client#
La règle de base : un BFF par client distinct. La découpe courante dans une plateforme moderne :
BFF mobile : iOS et Android partagent souvent le même BFF (mêmes contraintes réseau et affichage)
BFF web : l’application Single Page Application a ses propres besoins (pages riches, mise en cache aggressive)
BFF partenaires : les intégrations B2B ont des contrats stables, une authentification machine-to-machine, des payloads structurés pour l’ingestion par des systèmes tiers
La séparation peut être plus fine si les besoins divergent vraiment (iOS vs Android) ou plus grossière si les clients ont des besoins suffisamment proches.
Ownership par l’équipe frontend#
Le BFF appartient à l’équipe frontend qui le consomme. C’est une différence capitale par rapport à une API générique gérée par une équipe backend séparée. L’équipe mobile peut modifier son BFF sans dépendre d’une autre équipe, aligner les changements avec ses cycles de release, et choisir le format de données exactement comme il lui convient.
Cette ownership est le bénéfice principal du pattern : elle élimine les dépendances inter-équipes pour les changements d’interface.
Couplage intentionnel#
Le BFF est délibérément couplé à son client. C’est intentionnel et même souhaitable. Le BFF n’est pas une API réutilisable par d’autres clients — si une autre équipe commence à consommer le BFF mobile pour ses propres besoins, le pattern est cassé. Chaque BFF peut évoluer indépendamment avec son client.
Attention
Le principal risque du pattern BFF est la duplication de logique entre les BFF. La règle de partitionnement : la logique métier reste dans les services backend, le BFF ne contient que de la logique de présentation (agrégation, transformation de format, filtrage de champs).
Agrégation de services#
Fan-out vers les services backend#
Le BFF est l’orchestrateur de la couche de présentation. Pour construire la réponse d’un écran, il appelle plusieurs services backend en parallèle (fan-out) et assemble les résultats en une seule réponse.
# Exemple statique : BFF mobile qui agrège 3 services en parallèle
import asyncio
import httpx
from fastapi import FastAPI, HTTPException
app = FastAPI(title="BFF Mobile")
SERVICES = {
"users": "http://users-svc:8001",
"orders": "http://orders-svc:8002",
"products": "http://products-svc:8003",
}
@app.get("/mobile/dashboard/{user_id}")
async def get_mobile_dashboard(user_id: str):
"""Agrège profil + dernières commandes + recommandations en un seul appel."""
async with httpx.AsyncClient(timeout=5.0) as client:
# Fan-out : les 3 appels partent en parallèle
user_task = client.get(f"{SERVICES['users']}/users/{user_id}")
orders_task = client.get(f"{SERVICES['orders']}/orders?user_id={user_id}&limit=5")
reco_task = client.get(f"{SERVICES['products']}/recommendations/{user_id}?count=3")
try:
user_resp, orders_resp, reco_resp = await asyncio.gather(
user_task, orders_task, reco_task,
return_exceptions=False, # lève si n'importe quel appel échoue
)
except httpx.RequestError as e:
raise HTTPException(status_code=502, detail=f"Service injoignable : {e}")
user = user_resp.json()
orders = orders_resp.json()
recos = reco_resp.json()
# Transformation : payload taillé pour mobile (champs minimaux)
return {
"user": {
"id": user["id"],
"name": user["first_name"], # prénom seulement
"avatar": user["avatar_url"],
},
"recent_orders": [
{
"id": o["order_id"],
"date": o["created_at"][:10], # YYYY-MM-DD seulement
"status": o["status"],
"total": o["total_amount"],
}
for o in orders.get("items", [])
],
"recommendations": [
{"id": p["id"], "name": p["name"], "image": p["thumbnail_url"]}
for p in recos.get("products", [])
],
}
Gestion des erreurs partielles#
Dans un fan-out, la stratégie d’erreur dépend de la criticité de chaque service. Les recommandations ne sont pas critiques : si le service tombe, on peut retourner une liste vide. Le profil utilisateur est critique : sans lui, la page n’a pas de sens. asyncio.gather(return_exceptions=True) permet de traiter chaque résultat individuellement.
# Exemple statique : fan-out avec dégradation gracieuse
results = await asyncio.gather(
user_task, orders_task, reco_task,
return_exceptions=True,
)
user_result, orders_result, reco_result = results
if isinstance(user_result, Exception):
raise HTTPException(status_code=502, detail="Service utilisateur indisponible")
# Les recommandations peuvent être absentes sans bloquer la page
recos = reco_result.json() if not isinstance(reco_result, Exception) else {"products": []}
Optimisation par client#
Payload mobile : champs minimaux#
Le BFF mobile sélectionne uniquement les champs nécessaires à l’affichage mobile. Un utilisateur backend a 30 champs ; le mobile n’en affiche que 4. Transmettre les 26 autres est un gaspillage de bande passante, particulièrement critique sur les connexions 3G/4G.
Compression adaptée#
Le BFF mobile peut activer la compression gzip ou brotli plus aggressivement que le BFF web (qui peut se permettre des payloads plus larges sur fibre). Il peut aussi choisir un format plus compact (messagepack pour les connexions très contraintes).
Cache différencié#
Les stratégies de cache varient selon le client :
Mobile : cache HTTP agressif avec
Cache-Control: max-age=300(5 min) pour les données de profil, pour économiser la batterie et la dataWeb : cache plus court ou no-cache pour les données temps-réel (stock, prix)
Partenaires : pas de cache côté BFF, les partenaires gèrent leur propre cache
Authentification dans le BFF#
BFF détient la session#
Le BFF web peut détenir la session utilisateur sous forme de cookie HTTP-only (pattern BFF-session), ce qui évite d’exposer les tokens d’accès au JavaScript de la SPA — protégeant contre le vol via XSS.
Navigateur → BFF web : cookie de session (HTTP-only, Secure, SameSite=Strict)
BFF web → Services backend : Bearer token (JWT ou opaque, échangé en interne)
Le BFF est ainsi la frontière entre le monde navigateur (cookies) et le monde service (tokens).
Machine-to-machine vers les services backend#
Les appels du BFF vers les services backend utilisent des credentials machine-to-machine (client credentials OAuth 2.0). Le BFF récupère un access token avec son propre client_id et client_secret, l’inclut dans ses appels backend, et renouvelle le token avant expiration.
Versioning et évolution#
Le BFF absorbe les changements backend#
Si un service backend renomme un champ (first_name → given_name), le BFF adapte la transformation — le client mobile ne voit aucun changement. Cette indirection est la valeur principale du BFF pour l’isolation des changements.
Sans BFF, le renommage d’un champ dans un service obligerait une coordination simultanée avec toutes les équipes consommant ce service (web, mobile, partenaires). Avec des BFF dédiés, chaque équipe adapte son BFF à son rythme.
Découplage du client des services#
Le contrat entre le client et son BFF est stable et évolue selon le rythme du client. Le contrat entre le BFF et les services internes peut évoluer indépendamment. C’est le même découplage qu’un API Gateway apporte au niveau du périmètre, appliqué ici au niveau de la présentation.
GraphQL comme BFF#
GraphQL sur des APIs REST backends#
GraphQL est une implémentation naturelle du pattern BFF. Le schéma GraphQL définit exactement les données disponibles pour ce client. Les resolvers appellent les services REST backends et assemblent les résultats.
# Exemple statique : resolver GraphQL (Strawberry) qui agrège deux services REST
import strawberry
import httpx
@strawberry.type
class UserProfile:
id: str
name: str
order_count: int
last_order_date: str | None
@strawberry.type
class Query:
@strawberry.field
async def user_profile(self, user_id: str) -> UserProfile:
async with httpx.AsyncClient() as client:
user_resp, orders_resp = await asyncio.gather(
client.get(f"http://users-svc:8001/users/{user_id}"),
client.get(f"http://orders-svc:8002/orders?user_id={user_id}&limit=1"),
)
user = user_resp.json()
orders = orders_resp.json()
return UserProfile(
id=user["id"],
name=user["first_name"],
order_count=orders["total"],
last_order_date=orders["items"][0]["created_at"][:10] if orders["items"] else None,
)
schema = strawberry.Schema(query=Query)
Schema stitching et federation#
Pour les architectures avancées, Apollo Federation permet à plusieurs équipes de définir des parties du schéma GraphQL indépendamment (subgraphs), qui sont ensuite composées en un schéma unifié. Chaque subgraph est son propre BFF partiel, owné par son équipe.
BFF vs API Gateway#
Les deux patterns sont souvent confondus car ils occupent tous les deux une position intermédiaire entre les clients et les services. Leurs responsabilités sont distinctes :
Dimension |
API Gateway |
BFF |
|---|---|---|
Responsabilité |
Préoccupations transversales (auth, rate limit, routing) |
Agrégation et transformation pour un client |
Logique |
Technique uniquement |
Logique de présentation |
Généricité |
Générique, tous clients |
Spécifique à un client |
Owner |
Équipe plateforme / SRE |
Équipe frontend |
Nombre |
Un seul (ou quelques) |
Un par type de client |
Coexistence#
Dans une architecture mature, les deux coexistent : l’API Gateway traite l’authentification, le rate limiting et le routing ; les BFF se chargent de l’agrégation et de la transformation. Le client envoie sa requête → Gateway (auth, rate limit) → BFF approprié (agrégation, transformation) → Services backend.
Tip
Le BFF ne devrait pas dupliquer les fonctionnalités du gateway (pas de validation JWT dans le BFF si le gateway s’en charge déjà). La frontière : ce qui est transversal à tous les clients appartient au gateway, ce qui est spécifique à un client appartient au BFF.
Simulations et visualisations#
Simulation d’agrégation parallèle vs séquentielle#
import time
import random
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Simulation de latences de services (ms)
SERVICE_LATENCIES = {
"users": 45,
"orders": 80,
"recommendations": 120,
"notifications": 35,
"inventory": 60,
}
def call_service_sync(name: str, jitter: float = 0.2) -> float:
"""Simule un appel synchrone avec jitter."""
base = SERVICE_LATENCIES[name]
latency = base * (1 + random.uniform(-jitter, jitter))
time.sleep(latency / 1000)
return latency
def sequential_aggregation(services: list[str]) -> tuple[float, list[float]]:
"""Appels séquentiels : latence totale = somme des latences."""
latencies = []
start = time.monotonic()
for svc in services:
lat = call_service_sync(svc)
latencies.append(lat)
total = (time.monotonic() - start) * 1000
return total, latencies
def parallel_aggregation(services: list[str]) -> tuple[float, list[float]]:
"""Appels parallèles (simulés) : latence totale = max des latences."""
import threading
latencies = [0.0] * len(services)
def worker(i, name):
latencies[i] = call_service_sync(name)
start = time.monotonic()
threads = [threading.Thread(target=worker, args=(i, svc))
for i, svc in enumerate(services)]
for t in threads:
t.start()
for t in threads:
t.join()
total = (time.monotonic() - start) * 1000
return total, latencies
# Scénarios : de 2 à 5 services agrégés
random.seed(42)
scenarios = {
"2 services\n(users, orders)":
["users", "orders"],
"3 services\n(+recos)":
["users", "orders", "recommendations"],
"4 services\n(+notifs)":
["users", "orders", "recommendations", "notifications"],
"5 services\n(+inventory)":
["users", "orders", "recommendations", "notifications", "inventory"],
}
seq_totals = []
par_totals = []
theoretical_seq = []
theoretical_par = []
for scenario, services in scenarios.items():
t_seq, _ = sequential_aggregation(services)
t_par, _ = parallel_aggregation(services)
seq_totals.append(t_seq)
par_totals.append(t_par)
theoretical_seq.append(sum(SERVICE_LATENCIES[s] for s in services))
theoretical_par.append(max(SERVICE_LATENCIES[s] for s in services))
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
x = np.arange(len(scenarios))
width = 0.35
colors = sns.color_palette("muted", 4)
# Graphique 1 : latences mesurées
axes[0].bar(x - width/2, seq_totals, width, label="Séquentiel", color=colors[2], alpha=0.85)
axes[0].bar(x + width/2, par_totals, width, label="Parallèle (asyncio)", color=colors[0], alpha=0.85)
axes[0].set_xticks(x)
axes[0].set_xticklabels(list(scenarios.keys()), fontsize=9)
axes[0].set_ylabel("Latence totale (ms)")
axes[0].set_title("Latence d'agrégation : séquentiel vs parallèle")
axes[0].legend()
for i, (s, p) in enumerate(zip(seq_totals, par_totals)):
axes[0].text(i - width/2, s + 2, f"{s:.0f}ms", ha="center", va="bottom", fontsize=8)
axes[0].text(i + width/2, p + 2, f"{p:.0f}ms", ha="center", va="bottom", fontsize=8)
# Graphique 2 : gain relatif
gains = [(s - p) / s * 100 for s, p in zip(seq_totals, par_totals)]
bar_colors = [colors[0] if g > 0 else colors[2] for g in gains]
axes[1].bar(x, gains, color=bar_colors, alpha=0.85)
axes[1].set_xticks(x)
axes[1].set_xticklabels(list(scenarios.keys()), fontsize=9)
axes[1].set_ylabel("Gain de latence (%)")
axes[1].set_title("Gain relatif du parallélisme")
for i, g in enumerate(gains):
axes[1].text(i, g + 0.5, f"{g:.1f}%", ha="center", va="bottom", fontsize=9, fontweight="bold")
plt.suptitle("BFF — Agrégation parallèle vs séquentielle", fontsize=13, fontweight="bold")
plt.show()
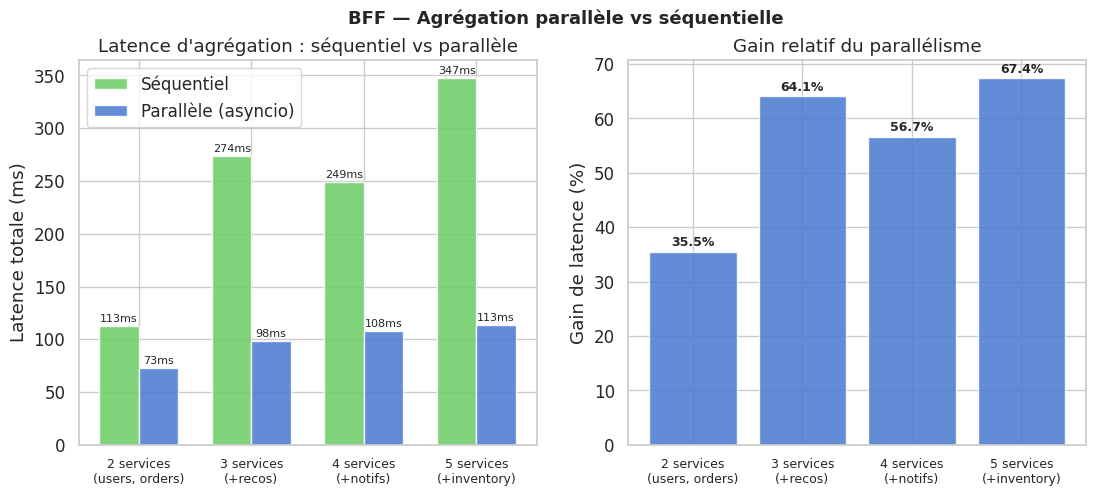
Diagramme d’architecture BFF par client#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(15, 8))
ax.set_xlim(0, 15)
ax.set_ylim(0, 9)
ax.axis("off")
def draw_box(ax, x, y, w, h, label, sublabel="", color="#4C72B0",
text_color="white", fontsize=10, alpha=1.0):
box = mpatches.FancyBboxPatch(
(x, y), w, h,
boxstyle="round,pad=0.12",
facecolor=color, edgecolor="white", linewidth=1.5, alpha=alpha
)
ax.add_patch(box)
ty = y + h / 2 + (0.15 if sublabel else 0)
ax.text(x + w/2, ty, label, ha="center", va="center",
color=text_color, fontsize=fontsize, fontweight="bold")
if sublabel:
ax.text(x + w/2, y + h/2 - 0.2, sublabel, ha="center", va="center",
color=text_color, fontsize=8, style="italic")
def arrow(ax, x1, y1, x2, y2, color="#666666", label=""):
ax.annotate("", xy=(x2, y2), xytext=(x1, y1),
arrowprops=dict(arrowstyle="->", color=color, lw=1.8))
if label:
mx, my = (x1+x2)/2, (y1+y2)/2
ax.text(mx, my + 0.15, label, ha="center", fontsize=8, color=color)
# Clients
draw_box(ax, 0.2, 7.0, 1.8, 1.0, "iOS / Android", "mobile", "#DD8452")
draw_box(ax, 0.2, 5.2, 1.8, 1.0, "SPA Web", "React/Vue", "#DD8452")
draw_box(ax, 0.2, 3.4, 1.8, 1.0, "Partenaire B2B", "API externe", "#DD8452")
# API Gateway
draw_box(ax, 2.8, 4.5, 1.8, 3.0, "API\nGateway", "auth, rate limit,\nrouting", "#55A868")
# BFFs
draw_box(ax, 5.6, 6.8, 2.2, 1.2, "BFF Mobile", "owner: équipe iOS", "#4C72B0")
draw_box(ax, 5.6, 4.8, 2.2, 1.2, "BFF Web", "owner: équipe web", "#4C72B0")
draw_box(ax, 5.6, 2.8, 2.2, 1.2, "BFF Partenaires", "owner: équipe API", "#4C72B0")
# Services backend
svc_color = "#8172B2"
draw_box(ax, 9.5, 7.2, 2.2, 0.9, "users-service", ":8001", svc_color, fontsize=9)
draw_box(ax, 9.5, 5.8, 2.2, 0.9, "orders-service", ":8002", svc_color, fontsize=9)
draw_box(ax, 9.5, 4.4, 2.2, 0.9, "products-service", ":8003", svc_color, fontsize=9)
draw_box(ax, 9.5, 3.0, 2.2, 0.9, "notifications", ":8004", svc_color, fontsize=9)
draw_box(ax, 9.5, 1.6, 2.2, 0.9, "recommendations", ":8005", svc_color, fontsize=9)
# Base de données
draw_box(ax, 12.5, 4.5, 2.0, 1.0, "PostgreSQL", "BDD principale", "#C44E52", fontsize=9)
draw_box(ax, 12.5, 3.0, 2.0, 1.0, "Redis", "cache + sessions", "#C44E52", fontsize=9)
# Flèches clients → gateway
arrow(ax, 2.0, 7.5, 2.8, 6.2, color="#888888")
arrow(ax, 2.0, 5.7, 2.8, 5.8, color="#888888")
arrow(ax, 2.0, 3.9, 2.8, 5.0, color="#888888")
# Flèches gateway → BFFs
arrow(ax, 4.6, 6.5, 5.6, 7.3, color="#55A868")
arrow(ax, 4.6, 5.8, 5.6, 5.4, color="#55A868")
arrow(ax, 4.6, 5.0, 5.6, 3.4, color="#55A868")
# Fan-out BFF mobile → services
arrow(ax, 7.8, 7.4, 9.5, 7.65, color="#4C72B0")
arrow(ax, 7.8, 7.2, 9.5, 6.25, color="#4C72B0")
arrow(ax, 7.8, 7.0, 9.5, 4.85, color="#4C72B0")
# Fan-out BFF web → services
arrow(ax, 7.8, 5.4, 9.5, 6.1, color="#5a9bd4")
arrow(ax, 7.8, 5.2, 9.5, 4.7, color="#5a9bd4")
arrow(ax, 7.8, 5.0, 9.5, 3.45, color="#5a9bd4")
# Fan-out BFF partenaires → services
arrow(ax, 7.8, 3.4, 9.5, 7.4, color="#7fbf7f")
arrow(ax, 7.8, 3.2, 9.5, 6.0, color="#7fbf7f")
arrow(ax, 7.8, 3.0, 9.5, 2.0, color="#7fbf7f")
# Services → BDD
arrow(ax, 11.7, 7.65, 12.5, 5.0, color="#aaaaaa")
arrow(ax, 11.7, 6.25, 12.5, 5.0, color="#aaaaaa")
arrow(ax, 11.7, 4.85, 12.5, 5.0, color="#aaaaaa")
arrow(ax, 11.7, 3.45, 12.5, 3.5, color="#aaaaaa")
ax.axvline(x=2.5, color="#cccccc", linestyle="--", linewidth=0.8, ymin=0.05, ymax=0.95)
ax.axvline(x=5.3, color="#cccccc", linestyle="--", linewidth=0.8, ymin=0.05, ymax=0.95)
ax.text(1.4, 0.3, "Internet", ha="center", fontsize=9, color="#888888")
ax.text(4.2, 0.3, "DMZ / Gateway", ha="center", fontsize=9, color="#55A868")
ax.text(7.5, 0.3, "BFF layer", ha="center", fontsize=9, color="#4C72B0")
ax.text(11.5, 0.3, "Services internes", ha="center", fontsize=9, color="#8172B2")
ax.set_title("Architecture BFF — un backend par type de client",
fontsize=13, fontweight="bold", pad=12)
plt.show()
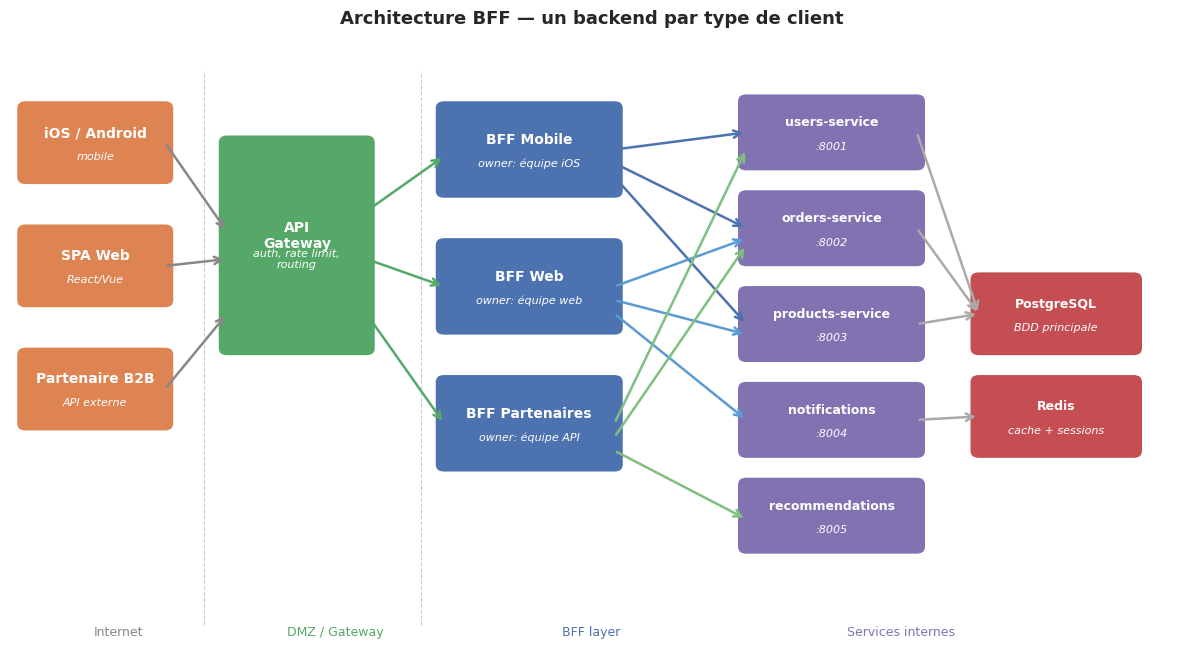
Comparaison des payloads mobile vs web#
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Taille estimée en octets par champ pour une réponse "utilisateur"
fields = [
"id",
"first_name",
"last_name",
"email",
"avatar_url",
"phone",
"address\n(objet)",
"preferences\n(objet)",
"created_at",
"last_login",
"metadata\n(objet)",
"billing_info\n(objet)",
]
# Quels champs sont inclus dans chaque BFF (1 = inclus, 0 = exclu)
web_includes = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
mobile_includes = [1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0]
# Taille approximative de chaque champ en octets
field_sizes = [20, 30, 30, 50, 80, 20, 120, 200, 30, 30, 150, 180]
web_sizes = [s * i for s, i in zip(field_sizes, web_includes)]
mobile_sizes = [s * i for s, i in zip(field_sizes, mobile_includes)]
x = np.arange(len(fields))
width = 0.38
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Graphique 1 : champ par champ
colors = sns.color_palette("muted", 2)
axes[0].barh(x + width/2, web_sizes, width, label="BFF Web", color=colors[0], alpha=0.85)
axes[0].barh(x - width/2, mobile_sizes, width, label="BFF Mobile", color=colors[1], alpha=0.85)
axes[0].set_yticks(x)
axes[0].set_yticklabels(fields, fontsize=9)
axes[0].set_xlabel("Taille (octets)")
axes[0].set_title("Payload par champ — BFF Web vs Mobile")
axes[0].legend()
axes[0].axvline(x=0, color="black", linewidth=0.5)
# Graphique 2 : total et économie
total_web = sum(web_sizes)
total_mobile = sum(mobile_sizes)
saving_pct = (total_web - total_mobile) / total_web * 100
categories = ["BFF Web", "BFF Mobile"]
totals = [total_web, total_mobile]
bar_colors = [colors[0], colors[1]]
bars = axes[1].bar(categories, totals, color=bar_colors, alpha=0.85, width=0.5)
axes[1].set_ylabel("Taille totale du payload (octets)")
axes[1].set_title(f"Payload total — économie de {saving_pct:.0f}% sur mobile")
for bar, val in zip(bars, totals):
axes[1].text(bar.get_x() + bar.get_width()/2, val + 5,
f"{val} o", ha="center", va="bottom", fontsize=11, fontweight="bold")
axes[1].annotate(
f"−{saving_pct:.0f}%\n({total_web - total_mobile} octets)",
xy=(1, total_mobile + (total_web - total_mobile)/2),
xytext=(1.4, (total_web + total_mobile)/2),
arrowprops=dict(arrowstyle="->", color="#C44E52"),
color="#C44E52", fontsize=10, fontweight="bold"
)
plt.suptitle("BFF — Optimisation du payload selon le client", fontsize=13, fontweight="bold")
plt.show()
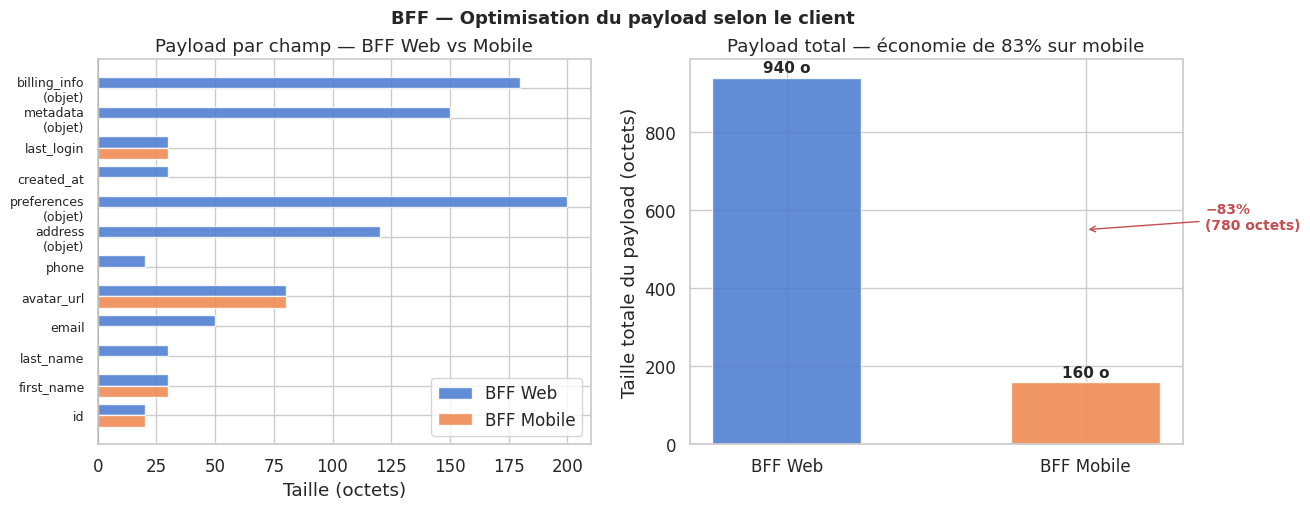
Modélisation du gain de latence : parallèle vs séquentiel#
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Modèle : n services indépendants avec des latences distribuées
# Latence séquentielle = somme des latences moyennes
# Latence parallèle = max des latences (avec variabilité)
np.random.seed(42)
n_simulations = 5000
mean_latency_per_service = 60 # ms par service (moyenne)
std_latency_per_service = 20 # écart-type
n_services_range = range(1, 11)
sequential_p50 = []
sequential_p95 = []
parallel_p50 = []
parallel_p95 = []
for n in n_services_range:
# Simulation de n_simulations requêtes, chacune avec n appels service
latencies = np.random.normal(mean_latency_per_service, std_latency_per_service,
(n_simulations, n))
latencies = np.clip(latencies, 5, None) # pas de latence négative
seq_total = latencies.sum(axis=1)
par_total = latencies.max(axis=1)
sequential_p50.append(np.percentile(seq_total, 50))
sequential_p95.append(np.percentile(seq_total, 95))
parallel_p50.append(np.percentile(par_total, 50))
parallel_p95.append(np.percentile(par_total, 95))
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
colors = sns.color_palette("muted", 4)
ns = list(n_services_range)
# Graphique 1 : latences p50 et p95
axes[0].plot(ns, sequential_p50, "o-", color=colors[2], label="Séquentiel p50", linewidth=2)
axes[0].plot(ns, sequential_p95, "s--", color=colors[2], label="Séquentiel p95",
linewidth=2, alpha=0.6)
axes[0].plot(ns, parallel_p50, "o-", color=colors[0], label="Parallèle p50", linewidth=2)
axes[0].plot(ns, parallel_p95, "s--", color=colors[0], label="Parallèle p95",
linewidth=2, alpha=0.6)
axes[0].fill_between(ns, parallel_p50, sequential_p50, alpha=0.12, color=colors[0])
axes[0].set_xlabel("Nombre de services agrégés")
axes[0].set_ylabel("Latence totale (ms)")
axes[0].set_title("Latence d'agrégation p50 et p95")
axes[0].legend(fontsize=9)
# Graphique 2 : facteur de gain (séquentiel / parallèle)
gain_p50 = [s / p for s, p in zip(sequential_p50, parallel_p50)]
gain_p95 = [s / p for s, p in zip(sequential_p95, parallel_p95)]
axes[1].plot(ns, gain_p50, "o-", color=colors[0], label="Gain p50", linewidth=2)
axes[1].plot(ns, gain_p95, "s--", color=colors[1], label="Gain p95", linewidth=2)
axes[1].axhline(y=1, color="gray", linestyle="--", linewidth=1, alpha=0.5)
axes[1].set_xlabel("Nombre de services agrégés")
axes[1].set_ylabel("Facteur de réduction de latence (×)")
axes[1].set_title("Gain du parallélisme selon le nombre de services")
axes[1].legend()
# Annotations
axes[1].text(5, gain_p50[4] + 0.1, f"×{gain_p50[4]:.1f}",
ha="center", fontsize=9, color=colors[0])
axes[1].text(10, gain_p50[9] + 0.1, f"×{gain_p50[9]:.1f}",
ha="center", fontsize=9, color=colors[0])
plt.suptitle("BFF — Modélisation du gain de latence par parallélisation",
fontsize=13, fontweight="bold")
plt.show()
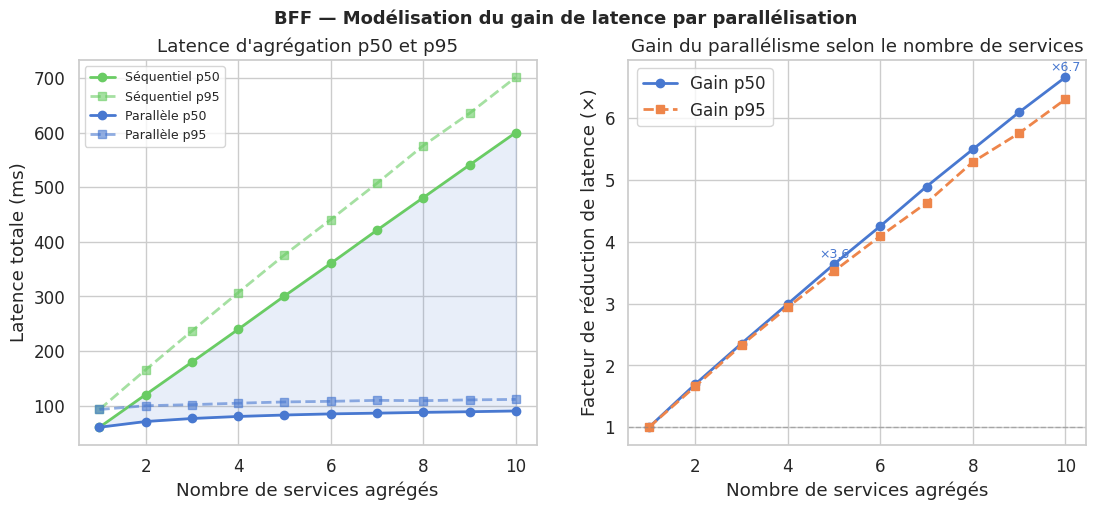
Résumé#
Le pattern BFF résout le problème structurel des APIs génériques face à des clients hétérogènes : over-fetching, under-fetching, chattiness. En dédiant un backend par type de client (mobile, web, partenaires), chaque équipe frontend contrôle son propre contrat d’API, son format de payload, et son rythme d’évolution. Le BFF agrège plusieurs services backend en parallèle (asyncio.gather) pour réduire la latence perçue, et transforme les réponses en payloads taillés au plus juste pour chaque client — typiquement 40 à 70% de réduction de taille pour le mobile.
Le BFF ne remplace pas l’API Gateway : les deux coexistent, le gateway gérant l’authentification et le rate limiting en amont, le BFF gérant l’agrégation et la présentation. GraphQL est une implémentation naturelle du pattern BFF lorsque la flexibilité des requêtes client prime sur la simplicité d’un BFF REST dédié. La frontière à respecter : pas de logique métier dans le BFF, seulement de la logique de présentation.