Conventions REST#
Une API REST techniquement correcte peut rester frustrante à utiliser si elle ne respecte pas les conventions que les développeurs ont intériorisées. Ce chapitre couvre les conventions de nommage, de versioning, de pagination, de filtrage, de tri et d’internationalisation qui constituent l’ergonomie d’une API REST professionnelle.
Nommage des URIs#
Les URIs sont la surface publique permanente d’une API. Un mauvais nommage est difficile à corriger sans breaking change.
Pluriel et kebab-case#
La convention dominante : collections en pluriel, mots séparés par des tirets (kebab-case), tout en minuscules.
# Recommandé
GET /users
GET /users/42
GET /blog-posts
GET /blog-posts/17/comments
# À éviter
GET /User
GET /blogPost
GET /blog_posts
GET /getBlogPosts
Le pluriel est logique : /users désigne une collection, /users/42 un élément de cette collection. Le kebab-case est préféré au snake_case car les tirets sont traités comme des séparateurs de mots par les moteurs de recherche et sont lisibles dans les logs.
Hiérarchie et profondeur#
La hiérarchie doit refléter les relations de possession ou de composition, pas la structure de la base de données.
# Hiérarchie appropriée
GET /orders/17/items
GET /users/5/addresses
# Trop profond — difficile à maintenir et à documenter
GET /companies/3/departments/8/teams/12/members/5/tasks
Au-delà de deux niveaux d’imbrication, envisager de retourner la ressource indépendante avec un filtre.
# Préférable à /companies/3/departments/8/teams/12/members
GET /team-members?team_id=12
Anti-patterns courants#
Anti-pattern |
Problème |
Alternative |
|---|---|---|
|
Verbe dans l’URI |
|
|
Incohérent avec les collections |
|
|
Action dans l’URI |
|
|
Majuscules |
|
|
Sémantique dans le query param |
|
Versioning#
Le versioning est inévitable : une API évolue, et certaines évolutions cassent les clients existants. La question n’est pas si versionner, mais comment.
URI versioning#
La stratégie la plus répandue : le numéro de version dans le chemin.
GET /v1/users
GET /v2/users
# FastAPI — montage de plusieurs versions
from fastapi import FastAPI
from app.v1 import router as router_v1
from app.v2 import router as router_v2
app = FastAPI()
app.include_router(router_v1, prefix="/v1")
app.include_router(router_v2, prefix="/v2")
Avantages : visible dans les logs, facilement testable dans un navigateur, simple à router. Inconvénients : les URLs ne sont plus « stables » au sens REST (une ressource = une URL), et les clients doivent mettre à jour leurs URLs de base.
Header versioning#
La version est transmise dans un header HTTP.
GET /users
Accept: application/vnd.myapi+json; version=2
ou avec un header personnalisé :
GET /users
API-Version: 2
# FastAPI — versioning par header
from fastapi import APIRouter, Header, HTTPException
router = APIRouter()
@router.get("/users")
async def get_users(api_version: str = Header(default="1")) -> list:
if api_version == "2":
return await get_users_v2()
return await get_users_v1()
Content negotiation versioning#
La version est intégrée dans le type de média via Accept.
GET /users
Accept: application/vnd.mycompany.users+json;version=2
C’est la plus conforme à la théorie REST, mais aussi la plus complexe à implémenter et à tester.
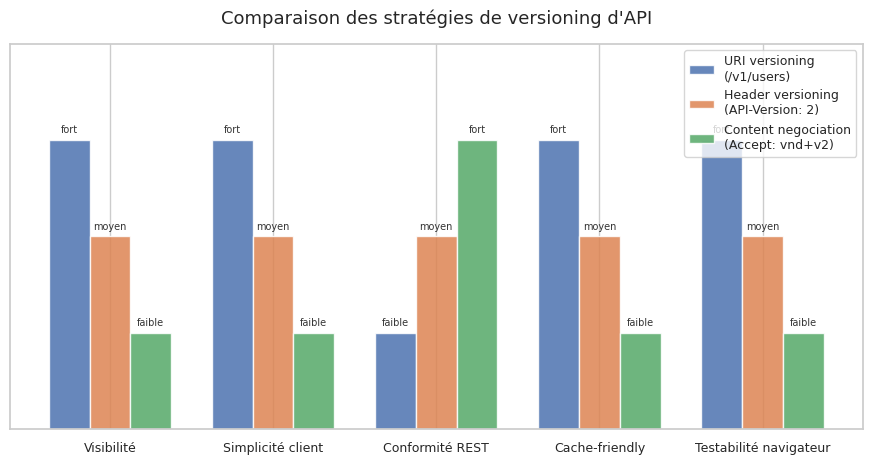
Recommandations#
Stratégie de versioning recommandée
L’URI versioning est le choix pragmatique pour la grande majorité des APIs. Il est visible, testable et compatible avec tous les clients HTTP. Le header versioning convient aux APIs très stables avec une clientèle de développeurs sophistiqués. Éviter le content negotiation versioning sauf contrainte explicite.
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
strategies = ["URI versioning\n(/v1/users)", "Header versioning\n(API-Version: 2)", "Content negociation\n(Accept: vnd+v2)"]
criteria = ["Visibilité", "Simplicité client", "Conformité REST", "Cache-friendly", "Testabilité navigateur"]
scores = [
[3, 3, 1, 3, 3],
[2, 2, 2, 2, 2],
[1, 1, 3, 1, 1],
]
colors = ["#4c72b0", "#dd8452", "#55a868"]
x = range(len(criteria))
width = 0.25
fig, ax = plt.subplots(figsize=(11, 5))
for i, (strategy, score, color) in enumerate(zip(strategies, scores, colors)):
offset = (i - 1) * width
bars = ax.bar([xi + offset for xi in x], score, width, label=strategy, color=color, alpha=0.85)
for bar, s in zip(bars, score):
labels = {1: "faible", 2: "moyen", 3: "fort"}
ax.text(
bar.get_x() + bar.get_width() / 2,
bar.get_height() + 0.05,
labels[s],
ha="center", va="bottom", fontsize=7, color="#333333"
)
ax.set_xticks(list(x))
ax.set_xticklabels(criteria, fontsize=9)
ax.set_ylim(0, 4)
ax.set_yticks([])
ax.set_title("Comparaison des stratégies de versioning d'API", fontsize=13, pad=14)
ax.legend(loc="upper right", fontsize=9)
plt.show()
Pagination#
Les collections peuvent contenir des millions d’éléments. Retourner l’intégralité d’une collection est un antipattern de performance et de sécurité.
Offset / limit#
La pagination offset est la plus intuitive.
GET /users?offset=0&limit=20
GET /users?offset=20&limit=20
GET /users?page=2&per_page=20
# FastAPI — pagination offset/limit
from fastapi import APIRouter, Query
router = APIRouter()
@router.get("/users")
async def list_users(
offset: int = Query(0, ge=0, description="Nombre d'éléments à sauter"),
limit: int = Query(20, ge=1, le=100, description="Nombre d'éléments à retourner"),
) -> dict:
total = await db.users.count()
items = await db.users.list(offset=offset, limit=limit)
return {
"data": items,
"meta": {
"total": total,
"offset": offset,
"limit": limit,
"has_next": offset + limit < total,
}
}
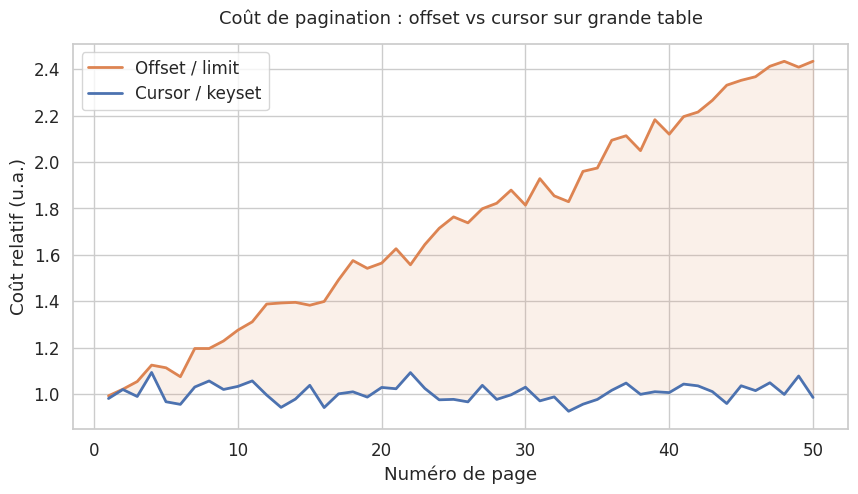
Limite principale : l’offset devient coûteux sur de grandes tables (la base de données doit compter et sauter les N premières lignes). Et si des éléments sont insérés ou supprimés entre deux pages, des entrées peuvent apparaître en double ou disparaître.
Cursor-based pagination#
Le curseur encode la position dans la liste, généralement l’identifiant ou la date du dernier élément retourné.
GET /users?limit=20
GET /users?after=eyJpZCI6IDIwfQ==&limit=20
# FastAPI — cursor pagination
import base64, json
@router.get("/users")
async def list_users_cursor(
after: str | None = Query(None, description="Curseur de pagination"),
limit: int = Query(20, ge=1, le=100),
) -> dict:
cursor_data = None
if after:
try:
cursor_data = json.loads(base64.b64decode(after))
except Exception:
raise HTTPException(status_code=400, detail="Curseur invalide")
items = await db.users.list_after_cursor(cursor_data, limit=limit + 1)
has_next = len(items) > limit
items = items[:limit]
next_cursor = None
if has_next and items:
next_cursor = base64.b64encode(
json.dumps({"id": items[-1].id}).encode()
).decode()
return {
"data": items,
"meta": {"has_next": has_next, "next_cursor": next_cursor}
}
Keyset pagination#
La keyset pagination utilise un WHERE id > last_seen_id ORDER BY id en SQL. Elle est la plus performante sur les grandes tables car elle utilise directement l’index.
# Keyset avec index
async def list_after_cursor(cursor: dict | None, limit: int) -> list:
if cursor:
return await db.execute(
"SELECT * FROM users WHERE id > $1 ORDER BY id ASC LIMIT $2",
cursor["id"], limit
)
return await db.execute(
"SELECT * FROM users ORDER BY id ASC LIMIT $1", limit
)
Link header (RFC 5988)#
Le standard HTTP pour les liens de pagination est le header Link.
Link: <https://api.example.com/users?after=eyJpZCI6IDIwfQ==>; rel="next",
<https://api.example.com/users>; rel="first"
import time
import random
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Simulation : coût relatif de chaque stratégie selon la page demandée
pages = list(range(1, 51))
def offset_cost(page, page_size=20):
"""Coût croissant avec le numéro de page (scan + skip)."""
return 1.0 + (page - 1) * page_size * 0.0015 + random.gauss(0, 0.05)
def cursor_cost(page, page_size=20):
"""Coût quasi-constant (index lookup)."""
return 1.0 + random.gauss(0, 0.04)
random.seed(42)
offset_times = [offset_cost(p) for p in pages]
cursor_times = [cursor_cost(p) for p in pages]
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(pages, offset_times, label="Offset / limit", color="#dd8452", linewidth=2)
ax.plot(pages, cursor_times, label="Cursor / keyset", color="#4c72b0", linewidth=2)
ax.fill_between(pages, cursor_times, offset_times, alpha=0.12, color="#dd8452")
ax.set_xlabel("Numéro de page")
ax.set_ylabel("Coût relatif (u.a.)")
ax.set_title("Coût de pagination : offset vs cursor sur grande table", fontsize=13, pad=14)
ax.legend()
plt.show()
Filtrage#
Le filtrage permet aux clients de réduire la collection côté serveur, évitant de transférer et de traiter des données inutiles.
Query parameters#
La convention la plus simple : un paramètre par champ.
GET /users?status=active
GET /orders?status=pending&customer_id=5
Opérateurs de comparaison#
Pour les filtres plus expressifs, des suffixes d’opérateurs sont ajoutés au nom du paramètre.
GET /products?price__gte=10&price__lte=100
GET /orders?created_at__gte=2024-01-01
GET /users?role__in=admin,moderator
GET /products?name__like=clavier
from urllib.parse import urlencode, parse_qs
import re
class QueryBuilder:
"""Construit et parse les query strings de filtrage REST."""
OPERATORS = {"eq", "gte", "lte", "gt", "lt", "in", "like", "neq"}
def __init__(self):
self._filters: list[tuple[str, str, str]] = []
self._sort: list[str] = []
self._page_params: dict = {}
def filter(self, field: str, op: str, value) -> "QueryBuilder":
if op not in self.OPERATORS:
raise ValueError(f"Opérateur inconnu : {op}. Disponibles : {self.OPERATORS}")
if op == "in" and isinstance(value, (list, tuple)):
value = ",".join(str(v) for v in value)
self._filters.append((field, op, str(value)))
return self
def sort(self, field: str, desc: bool = False) -> "QueryBuilder":
self._sort.append(f"-{field}" if desc else field)
return self
def paginate(self, limit: int = 20, offset: int = 0) -> "QueryBuilder":
self._page_params = {"limit": limit, "offset": offset}
return self
def build(self) -> str:
params = {}
for field, op, value in self._filters:
key = field if op == "eq" else f"{field}__{op}"
params[key] = value
if self._sort:
params["sort"] = ",".join(self._sort)
params.update(self._page_params)
return urlencode(params)
@classmethod
def parse(cls, query_string: str) -> list[tuple[str, str, str]]:
"""Parse une query string et retourne les filtres détectés."""
parsed = parse_qs(query_string)
filters = []
op_pattern = re.compile(r"^(.+)__(" + "|".join(cls.OPERATORS) + r")$")
for key, values in parsed.items():
m = op_pattern.match(key)
if m:
filters.append((m.group(1), m.group(2), values[0]))
elif key not in ("sort", "limit", "offset", "page", "fields"):
filters.append((key, "eq", values[0]))
return filters
# Exemple de construction
qb = (
QueryBuilder()
.filter("status", "eq", "active")
.filter("price", "gte", 10)
.filter("price", "lte", 100)
.filter("role", "in", ["admin", "moderator"])
.sort("created_at", desc=True)
.paginate(limit=20, offset=0)
)
qs = qb.build()
print("Query string construite :")
print(f" ?{qs}")
print()
print("Filtres parsés :")
for field, op, value in QueryBuilder.parse(qs):
print(f" {field} {op} {value!r}")
Query string construite :
?status=active&price__gte=10&price__lte=100&role__in=admin%2Cmoderator&sort=-created_at&limit=20&offset=0
Filtres parsés :
status eq 'active'
price gte '10'
price lte '100'
role in 'admin,moderator'
Sécurité des filtres#
Les filtres sont une surface d’attaque. Un filtre name__like=% peut forcer un scan complet de la table. Un filtre sur un champ non indexé peut saturer la base.
Validation des filtres
Toujours valider les noms de champs filtrables contre une liste blanche explicite. Ne jamais construire de SQL dynamique depuis les noms de paramètres du client. Limiter les opérateurs like et in à des champs indexés ou imposer un minimum de caractères pour like.
Tri#
Paramètre sort#
La convention répandue : un paramètre sort avec le préfixe - pour le sens descendant.
GET /products?sort=price
GET /products?sort=-price
GET /products?sort=-created_at,name
# FastAPI — parsing du paramètre sort
from fastapi import Query
from typing import Optional
@router.get("/products")
async def list_products(
sort: Optional[str] = Query(None, description="Ex: -created_at,name")
) -> list:
SORTABLE_FIELDS = {"name", "price", "created_at", "updated_at", "stock"}
order_clauses = []
if sort:
for field_spec in sort.split(","):
desc = field_spec.startswith("-")
field = field_spec.lstrip("-")
if field not in SORTABLE_FIELDS:
raise HTTPException(status_code=400, detail=f"Tri non supporté : {field}")
order_clauses.append((field, "DESC" if desc else "ASC"))
return await db.products.list(order_by=order_clauses)
Index et performance#
Chaque combinaison de champ et de sens de tri doit être couverte par un index pour éviter les full scans. Documenter explicitement quels champs sont triables et exposer une erreur 400 pour les champs non supportés.
Recherche full-text#
La recherche full-text est fondamentalement différente du filtrage : elle implique de la tokenisation, du stemming, du scoring de pertinence.
Paramètres q et search#
GET /products?q=clavier+mécanique
GET /articles?search=REST+API+design
@router.get("/products")
async def search_products(
q: Optional[str] = Query(None, min_length=2, description="Recherche full-text"),
category: Optional[str] = None,
) -> dict:
if q:
# Délégation à Elasticsearch ou pg_trgm
results = await search_engine.search(
index="products",
query=q,
filters={"category": category} if category else None,
)
else:
results = await db.products.list(category=category)
return {"data": results}
Délégation à un moteur de recherche#
PostgreSQL propose tsvector / tsquery pour la recherche full-text basique. Pour des besoins avancés (suggestion, correction orthographique, facettes), Elasticsearch ou OpenSearch s’imposent.
Filtrage vs recherche
Le filtrage (status=active) est déterministe et s’applique directement sur des index BDD. La recherche (q=clavier) implique un score de pertinence et nécessite souvent un moteur spécialisé. Proposer les deux en parallèle : filtres pour la navigation, recherche pour la découverte.
Sparse fieldsets#
Format JSON:API#
JSON:API standardise la syntaxe pour demander un sous-ensemble de champs par type de ressource.
GET /articles?fields[articles]=title,body&fields[authors]=name,bio
# FastAPI — sparse fieldsets JSON:API style
from fastapi import Query
from typing import Optional
@router.get("/articles")
async def list_articles(
fields_articles: Optional[str] = Query(None, alias="fields[articles]"),
fields_authors: Optional[str] = Query(None, alias="fields[authors]"),
include: Optional[str] = None,
) -> list:
article_fields = set(fields_articles.split(",")) if fields_articles else None
author_fields = set(fields_authors.split(",")) if fields_authors else None
articles = await db.articles.list(fields=article_fields)
if include and "authors" in include.split(","):
for article in articles:
article["author"] = await db.users.get(
article["author_id"], fields=author_fields
)
return articles
Impact sur les requêtes BDD#
Les sparse fieldsets ne sont utiles en performance que si la projection est poussée jusqu’à la couche SQL. Cela nécessite que la couche service accepte un paramètre fields et construise un SELECT col1, col2 plutôt qu’un SELECT *.
Internationalisation#
Header Accept-Language#
Le header standard pour négocier la langue de la réponse.
GET /products/42
Accept-Language: fr-FR,fr;q=0.9,en;q=0.8
# FastAPI — i18n via Accept-Language
from fastapi import Header
from typing import Optional
@router.get("/products/{product_id}")
async def get_product(
product_id: int,
accept_language: Optional[str] = Header(default="en"),
) -> dict:
lang = parse_preferred_language(accept_language, supported=["fr", "en", "de"])
product = await db.products.get(product_id, language=lang)
return product
Champs localisés dans la réponse#
# Réponse avec champs localisés
{
"id": 42,
"sku": "KB-001",
"price": 89.90,
"currency": "EUR",
"name": "Clavier mécanique compact",
"description": "Clavier TKL avec switches Cherry MX Red.",
"locale": "fr-FR"
}
Dates, nombres et devises#
Les dates doivent toujours être retournées en ISO 8601 UTC dans la réponse (2024-03-15T14:30:00Z). Le formatage pour l’affichage est de la responsabilité du client. Les montants monétaires doivent inclure la devise explicitement.
from urllib.parse import urlencode
import json
def build_link_header(base_url: str, current_offset: int, limit: int, total: int) -> str:
"""
Génère un header Link conforme RFC 5988 pour la pagination offset/limit.
Retourne une chaîne prête à être insérée dans le header HTTP Link.
"""
links = []
def make_url(offset: int) -> str:
return f"{base_url}?{urlencode({'offset': offset, 'limit': limit})}"
# first
links.append(f'<{make_url(0)}>; rel="first"')
# prev
if current_offset > 0:
prev_offset = max(0, current_offset - limit)
links.append(f'<{make_url(prev_offset)}>; rel="prev"')
# next
next_offset = current_offset + limit
if next_offset < total:
links.append(f'<{make_url(next_offset)}>; rel="next"')
# last
import math
last_offset = (math.ceil(total / limit) - 1) * limit
links.append(f'<{make_url(last_offset)}>; rel="last"')
return ",\n ".join(links)
# Simulation d'une réponse paginée
base_url = "https://api.example.com/users"
total = 243
limit = 20
print("=== Réponse paginée simulée ===\n")
for offset in [0, 20, 220]:
header = build_link_header(base_url, offset, limit, total)
page_num = offset // limit + 1
last_page = (total + limit - 1) // limit
print(f"Page {page_num}/{last_page} (offset={offset}):")
print(f" Link: {header}")
print()
=== Réponse paginée simulée ===
Page 1/13 (offset=0):
Link: <https://api.example.com/users?offset=0&limit=20>; rel="first",
<https://api.example.com/users?offset=20&limit=20>; rel="next",
<https://api.example.com/users?offset=240&limit=20>; rel="last"
Page 2/13 (offset=20):
Link: <https://api.example.com/users?offset=0&limit=20>; rel="first",
<https://api.example.com/users?offset=0&limit=20>; rel="prev",
<https://api.example.com/users?offset=40&limit=20>; rel="next",
<https://api.example.com/users?offset=240&limit=20>; rel="last"
Page 12/13 (offset=220):
Link: <https://api.example.com/users?offset=0&limit=20>; rel="first",
<https://api.example.com/users?offset=200&limit=20>; rel="prev",
<https://api.example.com/users?offset=240&limit=20>; rel="next",
<https://api.example.com/users?offset=240&limit=20>; rel="last"
Résumé#
Ce chapitre a couvert les conventions qui font l’ergonomie d’une API REST.
Le nommage des URIs suit des règles simples : pluriel, kebab-case, noms plutôt que verbes, hiérarchie limitée à deux niveaux d’imbrication.
Le versioning a trois approches principales : URI versioning (pragmatique et recommandé), header versioning (plus conforme REST mais moins visible) et content negotiation (théoriquement correct, rarement pratiqué). Le choix dépend du public cible et de la tolérance à la complexité.
La pagination doit être présente dès le premier déploiement. Offset/limit est simple mais coûteux sur les grandes tables. La pagination cursor ou keyset offre des performances stables et des pages cohérentes en cas d’insertion concurrente.
Le filtrage expose des query parameters avec opérateurs suffixés. La sécurité impose une liste blanche des champs filtrables et des opérateurs autorisés. La recherche full-text est un problème distinct, souvent délégué à un moteur spécialisé.
Les sparse fieldsets et l”internationalisation complètent le tableau : les premiers permettent de réduire la taille des réponses en ne renvoyant que les champs demandés, la seconde impose de respecter Accept-Language et de retourner les dates en ISO 8601 UTC.