GraphQL#
REST a dominé la conception d’APIs pendant une décennie, mais il montre ses limites face aux clients modernes : applications mobiles qui chargent de nombreux écrans différents, frontends en micro-services qui agrègent des données de sources multiples, systèmes où la bande passante est contrainte. GraphQL est né de ces limitations chez Facebook en 2012 avant d’être publié en 2015. Ce chapitre couvre la conception d’APIs GraphQL : schéma, requêtes, resolvers, optimisation N+1, pagination Relay et sécurité.
Pourquoi GraphQL#
Over-fetching et under-fetching#
Avec REST, la forme de la réponse est dictée par le serveur. L’endpoint GET /users/42 renvoie toujours le même objet, qu’on ait besoin de 2 champs ou de 20. Ce problème s’appelle l”over-fetching : on récupère plus que nécessaire.
L’inverse est tout aussi fréquent. Pour afficher le profil d’un utilisateur avec ses derniers articles et le nombre de commentaires sur chacun, il faut enchaîner trois appels : GET /users/42, GET /users/42/posts, puis GET /posts/{id}/comments/count pour chaque article. C’est l”under-fetching, ou le problème des N+1 appels côté client.
GraphQL résout les deux : le client déclare exactement les champs dont il a besoin, le serveur renvoie exactement cela, en une seule requête.
Origines et adoption#
Facebook construisait l’application iOS en 2012 sur une API REST interne. Les ingénieurs front-end se retrouvaient à jongler avec des dizaines d’endpoints, des réponses surchargées et des allers-retours réseau coûteux sur les connexions mobiles. Lee Byron, Nick Schrock et Dan Schafer ont conçu GraphQL comme une couche de requête sur le graphe de données interne de Facebook.
La spécification a été rendue publique en 2015. GitHub a migré son API publique vers GraphQL en 2016. Shopify, Twitter, Airbnb ont suivi. Aujourd’hui, GraphQL est standardisé par la GraphQL Foundation (Linux Foundation).
Limites de REST pour les clients complexes#
REST reste excellent pour les ressources simples, les APIs publiques documentées avec OpenAPI, la mise en cache HTTP native (les réponses GraphQL sont toutes des POST par défaut). GraphQL brille dans les contextes suivants :
Clients multiples aux besoins divergents : l’application mobile veut le minimum, le tableau de bord admin veut tout.
Graphe de données dense : les entités sont fortement interconnectées et les requêtes traversent plusieurs niveaux.
Développement front-end autonome : les équipes front peuvent évoluer sans coordination avec le back, tant que les types existent.
Introspection : le schéma est auto-documenté et requêtable programmatiquement.
Schéma SDL#
Le Schema Definition Language (SDL) est le langage déclaratif de GraphQL. Il décrit les types disponibles, leurs champs, et les opérations autorisées.
Types scalaires et types objets#
# Types scalaires de base
# String, Int, Float, Boolean, ID
type User {
id: ID! # ! = non-nullable
username: String!
email: String!
age: Int
score: Float
isActive: Boolean!
posts: [Post!]! # liste non-nullable de Posts non-nullables
createdAt: String!
}
type Post {
id: ID!
title: String!
content: String!
published: Boolean!
author: User!
tags: [String!]!
comments: [Comment!]!
viewCount: Int!
}
type Comment {
id: ID!
body: String!
author: User!
post: Post!
createdAt: String!
}
Types d’entrée, énumérations, interfaces, unions#
# Énumération
enum PostStatus {
DRAFT
PUBLISHED
ARCHIVED
}
# Type d'entrée (pour mutations)
input CreatePostInput {
title: String!
content: String!
status: PostStatus!
tags: [String!]
}
input UpdatePostInput {
title: String
content: String
status: PostStatus
}
# Interface
interface Node {
id: ID!
}
type Article implements Node {
id: ID!
title: String!
body: String!
}
type Video implements Node {
id: ID!
title: String!
url: String!
duration: Int!
}
# Union
union SearchResult = User | Post | Comment
# Point d'entrée obligatoire
type Query {
user(id: ID!): User
post(id: ID!): Post
search(query: String!): [SearchResult!]!
posts(status: PostStatus, first: Int, after: String): PostConnection!
}
type Mutation {
createPost(input: CreatePostInput!): Post!
updatePost(id: ID!, input: UpdatePostInput!): Post!
deletePost(id: ID!): Boolean!
}
type Subscription {
commentAdded(postId: ID!): Comment!
postPublished: Post!
}
Directives#
Les directives modifient le comportement d’exécution. Les directives natives sont @deprecated, @include, @skip. On peut définir des directives personnalisées :
directive @auth(requires: Role!) on FIELD_DEFINITION
enum Role {
USER
ADMIN
SUPERADMIN
}
type Query {
adminStats: Stats! @auth(requires: ADMIN)
publicFeed: [Post!]!
}
Queries et mutations#
Syntaxe de base#
Une requête GraphQL est envoyée en POST à un endpoint unique (souvent /graphql) avec le corps JSON {"query": "...", "variables": {...}}.
# Requête simple
query GetUser {
user(id: "42") {
id
username
email
posts {
id
title
published
}
}
}
# Avec variables (recommandé en production)
query GetUserById($userId: ID!) {
user(id: $userId) {
id
username
posts(first: 5) {
title
}
}
}
Fragments, aliases, directives de requête#
# Fragment réutilisable
fragment UserBasic on User {
id
username
email
}
# Alias pour requêtes multiples
query ComparePosts {
recent: post(id: "1") {
title
viewCount
}
popular: post(id: "2") {
title
viewCount
}
}
# @include et @skip avec variables booléennes
query GetUserConditional($withPosts: Boolean!, $skipEmail: Boolean!) {
user(id: "42") {
...UserBasic
email @skip(if: $skipEmail)
posts @include(if: $withPosts) {
title
}
}
}
Introspection#
GraphQL expose son propre schéma via des requêtes d’introspection. C’est ce qui permet aux outils comme GraphiQL et Apollo Studio de fonctionner :
query IntrospectSchema {
__schema {
types {
name
kind
fields {
name
type {
name
kind
}
}
}
}
}
query IntrospectType {
__type(name: "Post") {
name
fields {
name
type {
name
kind
ofType {
name
}
}
description
}
}
}
Subscriptions#
WebSocket sous-jacent#
Les subscriptions GraphQL permettent au serveur de pousser des données en temps réel. Le transport standard est WebSocket via le protocole graphql-ws (remplaçant de subscriptions-transport-ws).
Client → WS handshake → Serveur
Client → {"type": "connection_init"} → Serveur
Serveur → {"type": "connection_ack"} → Client
Client → {"type": "subscribe", "id": "1", "payload": {"query": "..."}} → Serveur
Serveur → {"type": "next", "id": "1", "payload": {"data": {...}}} → Client (répété)
Client → {"type": "complete", "id": "1"} → Serveur
Implémentation Strawberry#
import strawberry
from typing import AsyncGenerator
import asyncio
@strawberry.type
class Subscription:
@strawberry.subscription
async def comment_added(
self,
info: strawberry.types.Info,
post_id: strawberry.ID,
) -> AsyncGenerator[Comment, None]:
# S'abonner au broker de messages (Redis Pub/Sub, etc.)
async with info.context["pubsub"].subscribe(f"comments:{post_id}") as sub:
async for message in sub:
yield Comment(**message)
@strawberry.subscription
async def post_published(
self,
info: strawberry.types.Info,
) -> AsyncGenerator[Post, None]:
async with info.context["pubsub"].subscribe("posts:published") as sub:
async for message in sub:
yield Post(**message)
Cas d’usage#
Notifications en temps réel : nouveaux commentaires, mentions, messages.
Live updates : prix en bourse, scores sportifs, statut de livraison.
Tableaux de bord : métriques qui se rafraîchissent sans polling.
Collaboration : curseurs d’autres utilisateurs dans un éditeur collaboratif.
Resolvers#
Fonction resolver#
Chaque champ d’un type peut avoir un resolver. Un resolver est une fonction qui reçoit quatre arguments : root (l’objet parent), args (les arguments du champ), context (partagé sur toute la requête), info (métadonnées d’exécution).
import strawberry
from strawberry.types import Info
from typing import Optional, List
from dataclasses import dataclass
@dataclass
class UserModel:
id: str
username: str
email: str
@strawberry.type
class User:
id: strawberry.ID
username: str
email: str
@strawberry.field
async def posts(self, info: Info) -> List["Post"]:
# ici self est l'objet User courant
# info.context contient les dépendances injectées
db = info.context["db"]
return await db.posts.find_many(where={"author_id": self.id})
@strawberry.type
class Query:
@strawberry.field
async def user(self, info: Info, id: strawberry.ID) -> Optional[User]:
db = info.context["db"]
row = await db.users.find_unique(where={"id": id})
if row is None:
return None
return User(id=row.id, username=row.username, email=row.email)
Le problème N+1#
C’est le problème central des GraphQL resolvers. Considérons la requête suivante :
query {
posts {
title
author {
username
}
}
}
Si on a 100 posts, le resolver naïf de author fait une requête SQL SELECT * FROM users WHERE id = ? pour chaque post. Résultat : 1 requête pour les posts + 100 requêtes pour les auteurs = 101 requêtes.
# Implémentation naïve - PROBLÈME N+1
@strawberry.type
class Post:
id: strawberry.ID
title: str
author_id: str
@strawberry.field
async def author(self, info: Info) -> User:
db = info.context["db"]
# Cette ligne s'exécute UNE FOIS PAR POST
row = await db.users.find_unique(where={"id": self.author_id})
return User(id=row.id, username=row.username, email=row.email)
DataLoader#
Principe : batching et caching#
DataLoader résout le N+1 en regroupant (batching) les requêtes individuelles en une seule requête par « tick » de la boucle d’événements.
Au lieu de 100 SELECT WHERE id = 1, SELECT WHERE id = 2, …, DataLoader accumule les IDs demandés dans un même cycle et émet une seule requête SELECT WHERE id IN (1, 2, …, 100).
from strawberry.dataloader import DataLoader
from typing import List
# Fonction batch : reçoit une liste d'IDs, retourne une liste de résultats
async def batch_load_users(ids: List[str]) -> List[User]:
db = get_db()
# Une seule requête pour tous les IDs
rows = await db.users.find_many(where={"id": {"in": ids}})
# Construire un dictionnaire pour préserver l'ordre
users_by_id = {row.id: User(id=row.id, username=row.username, email=row.email)
for row in rows}
# IMPORTANT : retourner dans le même ordre que ids
return [users_by_id.get(user_id) for user_id in ids]
# Création du DataLoader (une instance par requête GraphQL)
def create_context():
return {
"db": get_db(),
"user_loader": DataLoader(load_fn=batch_load_users),
}
# Utilisation dans un resolver
@strawberry.type
class Post:
id: strawberry.ID
title: str
author_id: str
@strawberry.field
async def author(self, info: Info) -> User:
# Appel individuel, mais DataLoader accumule et batchifie
return await info.context["user_loader"].load(self.author_id)
Caching intra-requête#
DataLoader maintient un cache pendant la durée de vie d’une requête. Si le même user_id apparaît dans 5 posts différents, il ne sera chargé qu’une fois. Ce cache est par requête, pas global — il est détruit à la fin de la requête pour éviter de servir des données périmées.
Pagination Relay#
Spécification Cursor Connection#
La spécification Relay définit un pattern de pagination standard basé sur des curseurs opaques. L’avantage sur la pagination par offset (?page=3&size=20) est la stabilité : si un élément est inséré entre deux pages, la pagination par curseur n’est pas désynchronisée.
type PostConnection {
edges: [PostEdge!]!
pageInfo: PageInfo!
totalCount: Int!
}
type PostEdge {
node: Post!
cursor: String! # curseur opaque (base64 d'un ID ou timestamp)
}
type PageInfo {
hasNextPage: Boolean!
hasPreviousPage: Boolean!
startCursor: String
endCursor: String
}
type Query {
posts(
first: Int # pagination avant (les N premiers après `after`)
after: String # curseur de départ
last: Int # pagination arrière
before: String
): PostConnection!
}
Implémentation avec Strawberry#
import strawberry
from strawberry.relay import ListConnection, Node
from typing import Iterable
@strawberry.type
class Post(Node):
title: str
content: str
published: bool
@classmethod
def resolve_node(cls, node, *, info, **kwargs) -> "Post":
return cls(
id=node.id,
title=node.title,
content=node.content,
published=node.published,
)
@strawberry.type
class Query:
@strawberry.field
async def posts(self, info: strawberry.types.Info) -> ListConnection[Post]:
db = info.context["db"]
rows = await db.posts.find_many(where={"published": True})
return rows # Strawberry gère la pagination automatiquement
Requête paginée#
query GetPosts($after: String) {
posts(first: 10, after: $after) {
edges {
cursor
node {
id
title
published
}
}
pageInfo {
hasNextPage
endCursor
}
totalCount
}
}
Sécurité GraphQL#
Query depth limiting#
Un attaquant peut construire une requête récursive profonde qui surcharge le serveur :
# Requête malveillante - profondeur arbitraire
query {
user(id: "1") {
posts {
author {
posts {
author {
posts { author { posts { ... } } }
}
}
}
}
}
}
La solution est de limiter la profondeur maximale des requêtes :
from strawberry.extensions import MaxTokensLimiter
from graphql import GraphQLError
# Avec strawberry-graphql-django ou graphene
class DepthLimitExtension:
MAX_DEPTH = 7
def on_executing_start(self):
depth = self._calculate_depth(self.execution_context.document)
if depth > self.MAX_DEPTH:
raise GraphQLError(f"Profondeur maximale dépassée : {depth} > {self.MAX_DEPTH}")
Query complexity#
La profondeur seule est insuffisante : une requête large peut avoir une profondeur de 2 mais demander des milliers d’objets. On associe un coût à chaque champ :
schema = strawberry.Schema(
query=Query,
extensions=[
QueryDepthLimiter(max_depth=7),
# Coût total = somme des coûts des champs * multiplicateurs de listes
# posts (coût=10) × users (coût=1, multiplicateur=100) = 1000
]
)
Introspection en production#
L’introspection est précieuse en développement (GraphiQL, génération de code) mais expose le schéma complet en production. La désactiver réduit la surface d’attaque :
schema = strawberry.Schema(
query=Query,
mutation=Mutation,
extensions=[
# Désactiver l'introspection en production
DisableIntrospection if settings.ENV == "production" else None,
]
)
Persisted queries#
Les persisted queries (ou automated persisted queries, APQ) permettent d’envoyer uniquement un hash SHA-256 de la requête plutôt que la requête complète. Le serveur vérifie que le hash correspond à une requête pré-approuvée :
# Client envoie : {"extensions": {"persistedQuery": {"version": 1, "sha256Hash": "abc123..."}}}
# Serveur vérifie dans son registre de requêtes approuvées
# Avantages : réduit la taille des requêtes, permet de bloquer les requêtes ad-hoc
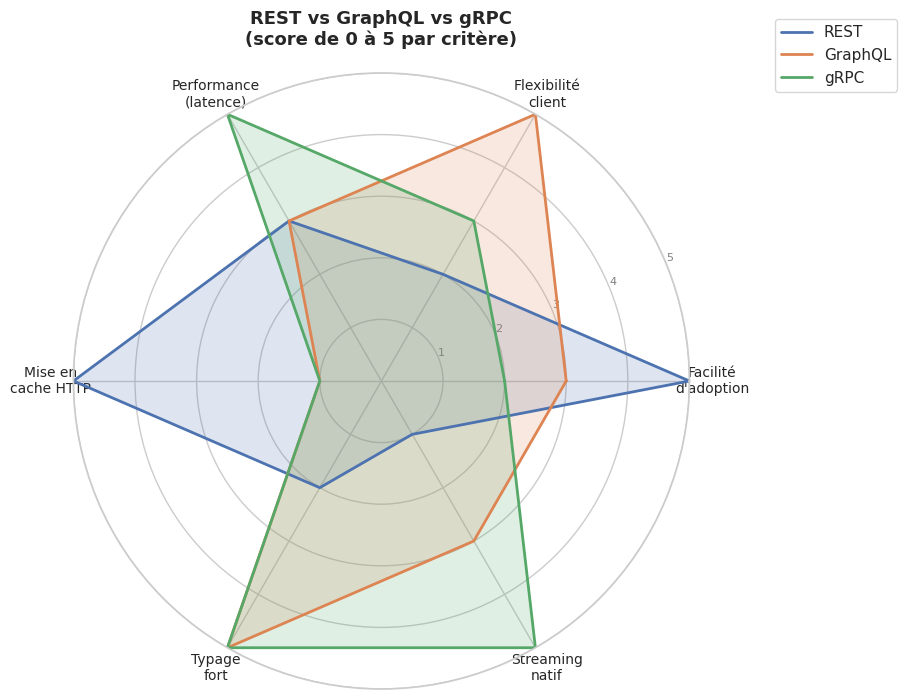
GraphQL vs REST#
Critères de choix#
Critère |
REST |
GraphQL |
gRPC |
|---|---|---|---|
Simplicité d’adoption |
Très haute |
Moyenne |
Basse |
Mise en cache HTTP |
Native |
Difficile |
N/A |
Flexibilité client |
Faible |
Très haute |
Moyenne |
Outils & écosystème |
Maturité maximale |
Très riche |
Riche |
Streaming |
Limité |
Subscriptions |
Natif |
Typage fort |
Via OpenAPI |
Natif |
Natif |
Choisir REST quand :
L’API est publique et doit être accessible à tous les clients sans outillage spécial.
La mise en cache HTTP est critique (CDN, proxies).
L’équipe est petite et la courbe d’apprentissage doit être minimale.
Les ressources sont simples et peu imbriquées.
Choisir GraphQL quand :
Les clients ont des besoins divergents (mobile léger vs dashboard riche).
Le graphe de données est dense et les requêtes traversent plusieurs niveaux.
Le développement front-end doit être découplé du back-end.
On veut de l’introspection et de la génération de code automatique.
Hybridation possible : Une architecture courante est d’exposer un endpoint GraphQL pour les clients internes (applications mobiles, SPA) tout en maintenant des endpoints REST publics pour les partenaires et intégrations tierces.
Cellules Python exécutables#
# Simulation du problème N+1 vs DataLoader
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Simulation : chargement de N posts avec leurs auteurs
def simulate_naive(n_posts: int) -> int:
"""Approche naïve : 1 requête posts + 1 requête par auteur."""
queries = 1 # SELECT * FROM posts
# Hypothèse : tous les auteurs sont différents (pire cas)
queries += n_posts # SELECT * FROM users WHERE id = ? × n_posts
return queries
def simulate_dataloader(n_posts: int, unique_authors: int) -> int:
"""DataLoader : 1 requête posts + 1 requête batch pour tous les auteurs."""
queries = 1 # SELECT * FROM posts
queries += 1 # SELECT * FROM users WHERE id IN (...)
return queries
post_counts = [10, 25, 50, 100, 200, 500]
# Dans le pire cas, autant d'auteurs que de posts
naive_queries = [simulate_naive(n) for n in post_counts]
# Avec DataLoader, indépendant du nombre de posts
dataloader_queries = [simulate_dataloader(n, n) for n in post_counts]
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# Graphique linéaire
axes[0].plot(post_counts, naive_queries, marker='o', label='Naïf (N+1)', linewidth=2.5)
axes[0].plot(post_counts, dataloader_queries, marker='s', label='DataLoader', linewidth=2.5)
axes[0].set_xlabel("Nombre de posts chargés")
axes[0].set_ylabel("Requêtes SQL émises")
axes[0].set_title("N+1 vs DataLoader : requêtes SQL")
axes[0].legend()
axes[0].set_yscale('log')
# Barplot pour n=100
categories = ['Naïf (N+1)', 'DataLoader']
values = [simulate_naive(100), simulate_dataloader(100, 100)]
bars = axes[1].bar(categories, values, color=sns.color_palette("muted", 2), width=0.5)
axes[1].set_title("Pour 100 posts : requêtes SQL comparées")
axes[1].set_ylabel("Nombre de requêtes SQL")
for bar, val in zip(bars, values):
axes[1].text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.5,
str(val), ha='center', va='bottom', fontweight='bold', fontsize=12)
plt.suptitle("Problème N+1 en GraphQL", fontweight='bold', fontsize=13)
plt.show()
print(f"Naïf (100 posts) : {simulate_naive(100)} requêtes SQL")
print(f"DataLoader (100 posts) : {simulate_dataloader(100, 100)} requêtes SQL")
print(f"Réduction : {simulate_naive(100) - simulate_dataloader(100, 100)} requêtes évitées")
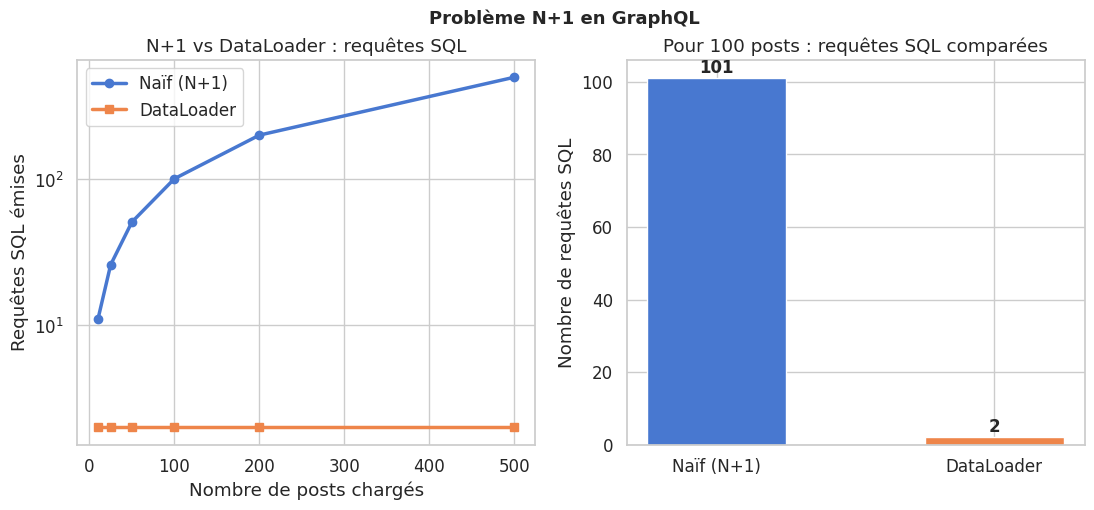
Naïf (100 posts) : 101 requêtes SQL
DataLoader (100 posts) : 2 requêtes SQL
Réduction : 99 requêtes évitées
# Parsing minimaliste d'un schéma GraphQL SDL (regex)
import re
SDL_SCHEMA = """
type User {
id: ID!
username: String!
email: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
content: String!
author: User!
tags: [String!]!
}
type Comment {
id: ID!
body: String!
author: User!
}
enum PostStatus {
DRAFT
PUBLISHED
ARCHIVED
}
input CreatePostInput {
title: String!
content: String!
status: PostStatus!
}
type Query {
user(id: ID!): User
post(id: ID!): Post
posts: [Post!]!
}
type Mutation {
createPost(input: CreatePostInput!): Post!
deletePost(id: ID!): Boolean!
}
"""
def parse_graphql_schema(sdl: str) -> dict:
"""Extrait les types, leurs catégories et leurs champs depuis un SDL GraphQL."""
result = {"types": {}, "enums": {}, "inputs": {}, "queries": [], "mutations": []}
# Pattern pour trouver les blocs de types
type_pattern = re.compile(
r'(type|enum|input)\s+(\w+)(?:\s+implements\s+\w+)?\s*\{([^}]+)\}',
re.DOTALL
)
# Pattern pour extraire les champs
field_pattern = re.compile(r'^\s*(\w+)(?:\([^)]*\))?\s*:\s*(.+?)\s*$', re.MULTILINE)
for match in type_pattern.finditer(sdl):
kind, name, body = match.groups()
fields = []
if kind == "enum":
# Extraire les valeurs d'enum
values = [v.strip() for v in body.strip().splitlines() if v.strip()]
result["enums"][name] = values
elif kind == "input":
for fm in field_pattern.finditer(body):
fields.append({"name": fm.group(1), "type": fm.group(2).strip()})
result["inputs"][name] = fields
elif kind == "type":
for fm in field_pattern.finditer(body):
fields.append({"name": fm.group(1), "type": fm.group(2).strip()})
if name == "Query":
result["queries"] = [f["name"] for f in fields]
elif name == "Mutation":
result["mutations"] = [f["name"] for f in fields]
else:
result["types"][name] = fields
return result
parsed = parse_graphql_schema(SDL_SCHEMA)
print("=== Types objets ===")
for type_name, fields in parsed["types"].items():
print(f"\n{type_name}:")
for field in fields:
print(f" - {field['name']}: {field['type']}")
print("\n=== Énumérations ===")
for enum_name, values in parsed["enums"].items():
print(f"{enum_name}: {', '.join(values)}")
print("\n=== Types d'entrée ===")
for input_name, fields in parsed["inputs"].items():
print(f"{input_name}: {[f['name'] for f in fields]}")
print(f"\n=== Query ({len(parsed['queries'])} champs) ===")
print(", ".join(parsed["queries"]))
print(f"\n=== Mutation ({len(parsed['mutations'])} champs) ===")
print(", ".join(parsed["mutations"]))
=== Types objets ===
User:
- id: ID!
- username: String!
- email: String!
- posts: [Post!]!
Post:
- id: ID!
- title: String!
- content: String!
- author: User!
- tags: [String!]!
Comment:
- id: ID!
- body: String!
- author: User!
=== Énumérations ===
PostStatus: DRAFT, PUBLISHED, ARCHIVED
=== Types d'entrée ===
CreatePostInput: ['title', 'content', 'status']
=== Query (3 champs) ===
user, post, posts
=== Mutation (2 champs) ===
createPost, deletePost
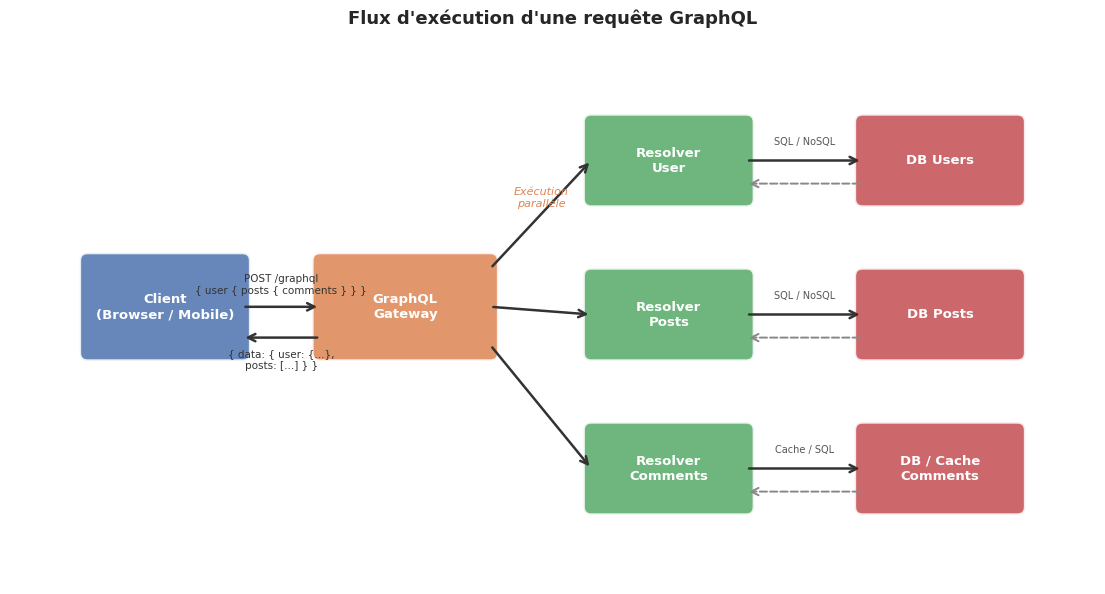
# Diagramme de flux d'une requête GraphQL
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import matplotlib.patheffects as pe
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, ax = plt.subplots(figsize=(14, 7))
ax.set_xlim(0, 14)
ax.set_ylim(0, 7)
ax.axis('off')
# Définition des boîtes
boxes = [
(1.0, 3.0, 2.0, 1.2, "Client\n(Browser / Mobile)", "#4C72B0"),
(4.0, 3.0, 2.2, 1.2, "GraphQL\nGateway", "#DD8452"),
(7.5, 5.0, 2.0, 1.0, "Resolver\nUser", "#55A868"),
(7.5, 3.0, 2.0, 1.0, "Resolver\nPosts", "#55A868"),
(7.5, 1.0, 2.0, 1.0, "Resolver\nComments", "#55A868"),
(11.0, 5.0, 2.0, 1.0, "DB Users", "#C44E52"),
(11.0, 3.0, 2.0, 1.0, "DB Posts", "#C44E52"),
(11.0, 1.0, 2.0, 1.0, "DB / Cache\nComments", "#C44E52"),
]
for (x, y, w, h, label, color) in boxes:
bbox = mpatches.FancyBboxPatch(
(x, y), w, h,
boxstyle="round,pad=0.1",
facecolor=color, edgecolor='white', linewidth=2, alpha=0.85
)
ax.add_patch(bbox)
ax.text(x + w/2, y + h/2, label, ha='center', va='center',
color='white', fontsize=9.5, fontweight='bold')
# Flèches
arrows = [
# Client → Gateway
(3.0, 3.6, 4.0, 3.6, "query { user posts\ncomments }"),
# Gateway → Resolvers
(6.2, 3.9, 7.5, 5.5),
(6.2, 3.6, 7.5, 3.5),
(6.2, 3.3, 7.5, 1.5),
# Resolvers → DB
(9.5, 5.5, 11.0, 5.5),
(9.5, 3.5, 11.0, 3.5),
(9.5, 1.5, 11.0, 1.5),
# DB → Resolvers (retour)
(11.0, 5.2, 9.5, 5.2),
(11.0, 3.2, 9.5, 3.2),
(11.0, 1.2, 9.5, 1.2),
# Gateway ← Client (réponse)
(4.0, 3.2, 3.0, 3.2),
]
arrowprops = dict(arrowstyle='->', color='#333333', lw=1.8)
# Flèches avec labels
ax.annotate("", xy=(4.0, 3.6), xytext=(3.0, 3.6), arrowprops=arrowprops)
ax.text(3.5, 3.75, "POST /graphql\n{ user { posts { comments } } }",
ha='center', va='bottom', fontsize=7.5, color='#333333')
ax.annotate("", xy=(3.0, 3.2), xytext=(4.0, 3.2), arrowprops=arrowprops)
ax.text(3.5, 3.05, "{ data: { user: {...},\nposts: [...] } }",
ha='center', va='top', fontsize=7.5, color='#333333')
# Flèches Gateway → Resolvers
ax.annotate("", xy=(7.5, 5.5), xytext=(6.2, 4.1), arrowprops=arrowprops)
ax.annotate("", xy=(7.5, 3.5), xytext=(6.2, 3.6), arrowprops=arrowprops)
ax.annotate("", xy=(7.5, 1.5), xytext=(6.2, 3.1), arrowprops=arrowprops)
# Flèches Resolvers → DB et retour
for y_val in [5.5, 3.5, 1.5]:
ax.annotate("", xy=(11.0, y_val), xytext=(9.5, y_val), arrowprops=arrowprops)
ax.annotate("", xy=(9.5, y_val - 0.3), xytext=(11.0, y_val - 0.3),
arrowprops=dict(arrowstyle='->', color='#888888', lw=1.4, linestyle='dashed'))
ax.text(10.25, 5.7, "SQL / NoSQL", ha='center', fontsize=7, color='#555555')
ax.text(10.25, 3.7, "SQL / NoSQL", ha='center', fontsize=7, color='#555555')
ax.text(10.25, 1.7, "Cache / SQL", ha='center', fontsize=7, color='#555555')
ax.text(6.85, 4.9, "Exécution\nparallèle", ha='center', fontsize=8,
color='#DD8452', fontstyle='italic')
ax.set_title("Flux d'exécution d'une requête GraphQL", fontsize=13, fontweight='bold', pad=15)
plt.show()
# Radar : comparaison REST vs GraphQL vs gRPC sur 6 critères
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
categories = [
"Facilité\nd'adoption",
"Flexibilité\nclient",
"Performance\n(latence)",
"Mise en\ncache HTTP",
"Typage\nfort",
"Streaming\nnatif"
]
N = len(categories)
# Scores de 0 à 5
scores = {
"REST": [5, 2, 3, 5, 2, 1],
"GraphQL": [3, 5, 3, 1, 5, 3],
"gRPC": [2, 3, 5, 1, 5, 5],
}
angles = [n / float(N) * 2 * np.pi for n in range(N)]
angles += angles[:1] # fermer le polygone
fig, ax = plt.subplots(figsize=(8, 8), subplot_kw=dict(polar=True))
colors = ["#4C72B0", "#DD8452", "#55A868"]
for (tech, vals), color in zip(scores.items(), colors):
values = vals + vals[:1]
ax.plot(angles, values, linewidth=2, linestyle='solid', label=tech, color=color)
ax.fill(angles, values, alpha=0.18, color=color)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, size=10)
ax.set_ylim(0, 5)
ax.set_yticks([1, 2, 3, 4, 5])
ax.set_yticklabels(["1", "2", "3", "4", "5"], size=8, color='grey')
ax.set_title("REST vs GraphQL vs gRPC\n(score de 0 à 5 par critère)",
size=13, fontweight='bold', pad=20)
ax.legend(loc='upper right', bbox_to_anchor=(1.35, 1.1), fontsize=11)
plt.show()
Résumé#
GraphQL apporte une réponse structurée aux limites de REST pour les clients complexes. Le schéma SDL est le contrat central : il décrit tous les types, les opérations disponibles et les relations entre entités. Les resolvers implémentent la logique de récupération champ par champ, ce qui rend le système composable mais expose au problème N+1 — résolu par le pattern DataLoader qui regroupe les requêtes en batches.
La pagination Relay (Connection/Edge/PageInfo) est la convention dominante pour paginer sans les instabilités de l’offset. Les subscriptions s’appuient sur WebSocket pour le temps réel. La sécurité requiert une attention particulière : limiter la profondeur et la complexité des requêtes, désactiver l’introspection en production, et privilégier les persisted queries pour les clients connus.
Le choix entre REST, GraphQL et gRPC n’est pas exclusif : beaucoup d’architectures exposent GraphQL aux clients front-end et REST aux partenaires, tout en utilisant gRPC pour la communication inter-services.