Chapitre 14 — Caching applicatif#
Le cache est l’outil le plus efficace pour améliorer les performances d’une API, et l’un des plus délicats à mettre en œuvre correctement. Stocker une réponse calculée pour l’éviter de la recalculer est simple en théorie ; maintenir la cohérence du cache avec la réalité de la base de données, sous charge, avec plusieurs instances, est un problème non trivial. Ce chapitre couvre les niveaux de cache, les stratégies d’invalidation, les patterns Redis avancés, et les pièges classiques.
Niveaux de cache pour les APIs#
Hiérarchie des niveaux#
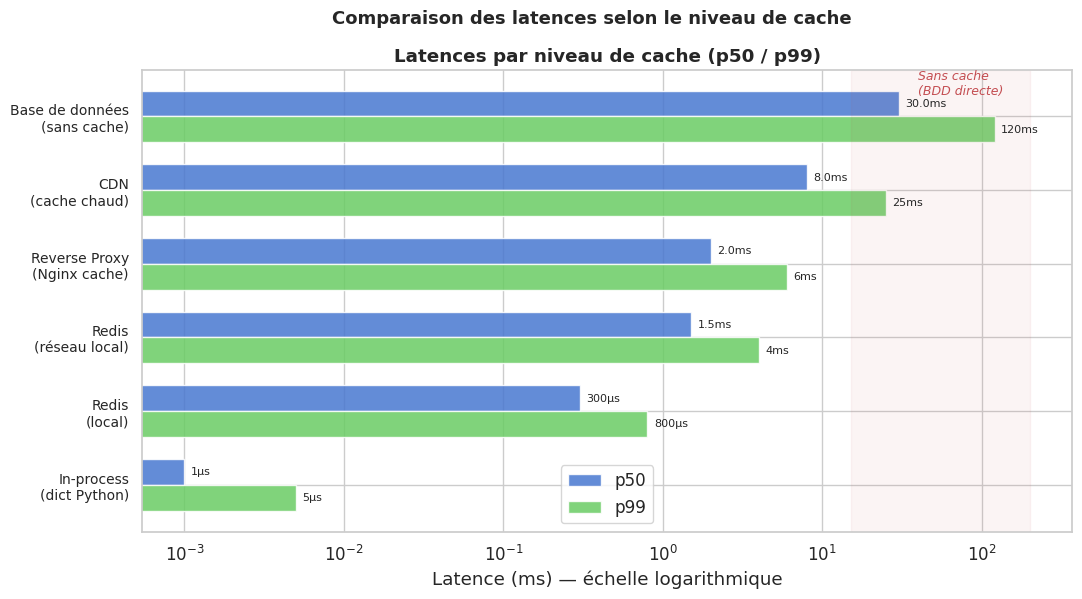
Les caches se positionnent à différents endroits de la pile, avec des compromis différents de vitesse, de capacité et de complexité :
Niveau |
Exemples |
Latence typique |
Granularité |
Cohérence |
|---|---|---|---|---|
In-process |
dict Python, LRU cache |
< 1 µs |
Instance locale |
Par instance |
Partagé |
Redis, Memcached |
0.5 – 2 ms |
Partagé entre instances |
Centralisé |
Reverse proxy |
Nginx, Varnish |
1 – 5 ms |
Réponses HTTP complètes |
Par URL |
CDN |
Cloudflare, Fastly |
5 – 50 ms |
Ressources statiques / semi-statiques |
Par POP |
Quand utiliser quel niveau#
In-process : données rarement changeantes, petits volumes, accès très fréquent (configuration applicative, liste de pays, tables de référence). Coût d’invalidation élevé (chaque instance a son propre cache) — réservé aux données quasi-statiques.
Redis/Memcached : sessions utilisateur, résultats de requêtes coûteuses, tokens, objets fréquemment accédés. Cache partagé entre toutes les instances, invalidation centralisée.
CDN : ressources publiques (images, assets), réponses d’API publiques sans authentification, géo-distribution du cache.
Reverse proxy : mise en cache de réponses d’API entières à l’edge du cluster, avant même que la requête n’atteigne l’application.
Note
Les niveaux ne s’excluent pas : une réponse peut traverser CDN → reverse proxy → cache in-process avant d’atteindre la base de données. Chaque niveau réduit la charge du suivant. Le coût est la complexité de l’invalidation coordonnée.
Stratégies de cache#
Cache-aside (lazy loading)#
Le pattern le plus répandu. L’application gère explicitement le cache :
Lecture : vérifier le cache → si présent (hit), retourner ; sinon (miss) → lire en base → stocker en cache → retourner
Écriture : écrire en base → invalider (ou mettre à jour) le cache
Avantage : le cache ne contient que les données effectivement demandées. Inconvénient : la première requête après un miss paie le coût de la base de données.
Read-through#
Le cache lui-même est responsable de remplir ses entrées manquantes en interrogeant la base de données. L’application ne parle qu’au cache. Simplifie le code applicatif, mais nécessite un cache qui supporte ce mode (Redis avec modules, ou librairies spécialisées).
Write-through#
Chaque écriture passe simultanément par le cache et la base de données. Le cache est toujours à jour mais chaque écriture est plus lente (double écriture synchrone).
Write-behind (write-back)#
L’écriture se fait d’abord dans le cache, et la persistance en base est différée (asynchrone). Meilleures performances en écriture, mais risque de perte de données si le cache tombe avant la persistance. Convient pour les données à forte écriture et tolérant une légère perte (compteurs, événements d’analytics).
Refresh-ahead#
Le cache se précharge proactivement avant l’expiration, sur la base de la fréquence d’accès. Évite les pics de latence lors des misses. Complexe à implémenter correctement.
Cache-aside avec Redis#
Implémentation Python complète#
# Exemple statique : cache-aside avec redis-py
import json
import hashlib
from functools import wraps
import redis
r = redis.Redis(host="localhost", port=6379, db=0, decode_responses=True)
def cache_key(prefix: str, *args, **kwargs) -> str:
"""Génère une clé de cache déterministe."""
payload = json.dumps({"args": args, "kwargs": kwargs}, sort_keys=True)
digest = hashlib.sha256(payload.encode()).hexdigest()[:12]
return f"{prefix}:{digest}"
def cached(prefix: str, ttl: int = 300):
"""Décorateur cache-aside générique."""
def decorator(func):
@wraps(func)
async def wrapper(*args, **kwargs):
key = cache_key(prefix, *args, **kwargs)
# 1. Vérifier le cache
cached_value = r.get(key)
if cached_value is not None:
return json.loads(cached_value)
# 2. Miss : appel à la source de vérité
result = await func(*args, **kwargs)
# 3. Stocker en cache avec TTL
r.setex(key, ttl, json.dumps(result, default=str))
return result
return wrapper
return decorator
# Utilisation
@cached(prefix="user", ttl=600)
async def get_user(user_id: str) -> dict:
# Requête base de données coûteuse
row = await db.fetchone("SELECT * FROM users WHERE id = $1", user_id)
return dict(row)
# Invalidation manuelle à l'écriture
async def update_user(user_id: str, data: dict) -> dict:
await db.execute("UPDATE users SET ... WHERE id = $1", user_id)
# Invalider toutes les clés du préfixe "user" pour cet ID
pattern = f"user:*"
keys = r.keys(pattern) # ATTENTION : KEYS bloquant en production
if keys:
r.delete(*keys)
return await get_user(user_id)
Attention
r.keys("pattern:*") effectue un scan bloquant de toutes les clés Redis — interdit en production sur une instance chargée. Utiliser r.scan_iter("pattern:*") qui est non-bloquant et itère par batches, ou mieux encore des structures de cache avec des clés connues et précises.
Redis patterns avancés#
Sessions avec renouvellement#
# Exemple statique : gestion de sessions Redis avec sliding expiration
import secrets
import time
SESSION_TTL = 3600 # 1h d'inactivité max
SESSION_RENEW_THRESHOLD = 600 # renouveler si moins de 10 min restantes
def create_session(user_id: str, metadata: dict) -> str:
session_id = secrets.token_urlsafe(32)
session_data = {
"user_id": user_id,
"created_at": int(time.time()),
**metadata,
}
r.setex(f"session:{session_id}", SESSION_TTL, json.dumps(session_data))
return session_id
def get_session(session_id: str) -> dict | None:
key = f"session:{session_id}"
data = r.get(key)
if data is None:
return None
# Sliding expiration : renouveler si proche de l'expiration
ttl = r.ttl(key)
if ttl < SESSION_RENEW_THRESHOLD:
r.expire(key, SESSION_TTL)
return json.loads(data)
def invalidate_session(session_id: str) -> None:
r.delete(f"session:{session_id}")
Rate limiting Redis (INCR + EXPIRE)#
# Exemple statique : rate limiter Redis atomique
def check_rate_limit(identifier: str, limit: int, window_seconds: int) -> tuple[bool, int]:
"""
Retourne (allowed, remaining_requests).
Utilise INCR + EXPIRE pour l'atomicité dans la fenêtre glissante.
"""
import time
window_key = f"rl:{identifier}:{int(time.time()) // window_seconds}"
pipe = r.pipeline()
pipe.incr(window_key)
pipe.expire(window_key, window_seconds * 2)
results = pipe.execute()
current_count = results[0]
allowed = current_count <= limit
remaining = max(0, limit - current_count)
return allowed, remaining
Pub/Sub pour l’invalidation de cache#
# Exemple statique : invalidation de cache cross-instances via pub/sub
import threading
def publish_invalidation(entity_type: str, entity_id: str) -> None:
"""Publie un événement d'invalidation sur le canal Redis."""
message = json.dumps({"type": entity_type, "id": entity_id})
r.publish("cache:invalidate", message)
def start_invalidation_listener(local_cache: dict) -> None:
"""Écoute les invalidations et vide le cache local correspondant."""
def listener():
pubsub = r.pubsub()
pubsub.subscribe("cache:invalidate")
for message in pubsub.listen():
if message["type"] != "message":
continue
data = json.loads(message["data"])
key = f"{data['type']}:{data['id']}"
local_cache.pop(key, None)
thread = threading.Thread(target=listener, daemon=True)
thread.start()
Sorted sets pour les leaderboards#
Redis Sorted Sets maintiennent un ensemble trié par score, idéal pour les classements :
# Exemple statique : leaderboard avec ZADD / ZREVRANGE
def update_score(leaderboard: str, user_id: str, delta: int) -> float:
"""Incrémente le score et retourne le nouveau total."""
return r.zincrby(leaderboard, delta, user_id)
def get_top_n(leaderboard: str, n: int = 10) -> list[tuple[str, float]]:
"""Retourne les n meilleurs avec leur score."""
return r.zrevrange(leaderboard, 0, n - 1, withscores=True)
def get_rank(leaderboard: str, user_id: str) -> int | None:
"""Retourne le rang (0-indexé) d'un utilisateur."""
return r.zrevrank(leaderboard, user_id)
Invalidation#
TTL simple#
Le TTL (Time To Live) est la forme d’invalidation la plus simple : chaque entrée de cache expire automatiquement après un délai fixé. Simple à implémenter, prévisible, mais accepte une fenêtre de données périmées (stale data) pendant toute la durée du TTL.
Event-based invalidation#
Les événements de domaine déclenchent l’invalidation. Quand UserUpdated(id=42) est publié sur le bus d’événements, le cache invalide user:42 immédiatement. Plus cohérent que le TTL, mais couplage entre le système d’événements et le cache.
Les deux problèmes difficiles#
« Il n’y a que deux problèmes difficiles en informatique : l’invalidation de cache et nommer les choses. » — Phil Karlton
L’invalidation de cache est difficile parce qu’elle nécessite de savoir quelles entrées de cache doivent être invalidées quand une donnée change — ce qui peut être non trivial dans un graphe de dépendances complexe. Un TTL trop court surcharge la base de données ; un TTL trop long expose des données périmées.
Cache distribué#
Partitionnement cohérent#
Dans un cluster Redis (Redis Cluster), les données sont partitionnées sur plusieurs nœuds via un hash des clés. Le partitionnement cohérent (consistent hashing) minimise les réassignations lors des changements de topologie (ajout/suppression de nœuds).
Réplication et failover#
Redis Sentinel ou Redis Cluster assurent la haute disponibilité : un nœud primaire avec un ou plusieurs réplicas. En cas de défaillance du primaire, Sentinel promeut automatiquement un réplica. Il existe une fenêtre de perte de données entre la dernière synchronisation et la défaillance (si appendfsync everysec est configuré, cette fenêtre est d’au plus 1 seconde).
Cache warming#
Lors du démarrage d’une nouvelle instance ou après un flush de cache, le « cold cache » entraîne un pic de charge sur la base de données (cache stampede). Le cache warming consiste à précharger les entrées les plus fréquemment accédées avant que l’instance ne reçoive du trafic de production.
Cache et cohérence#
Stale data intentionnel vs accidentel#
Un stale data intentionnel est accepté dans la conception : les prix affichés peuvent être ceux d’il y a 5 minutes, ce qui est acceptable. Un stale data accidentel survient suite à un bug d’invalidation : un utilisateur voit des données d’une autre session après déconnexion, ou un prix déjà modifié ne se met pas à jour.
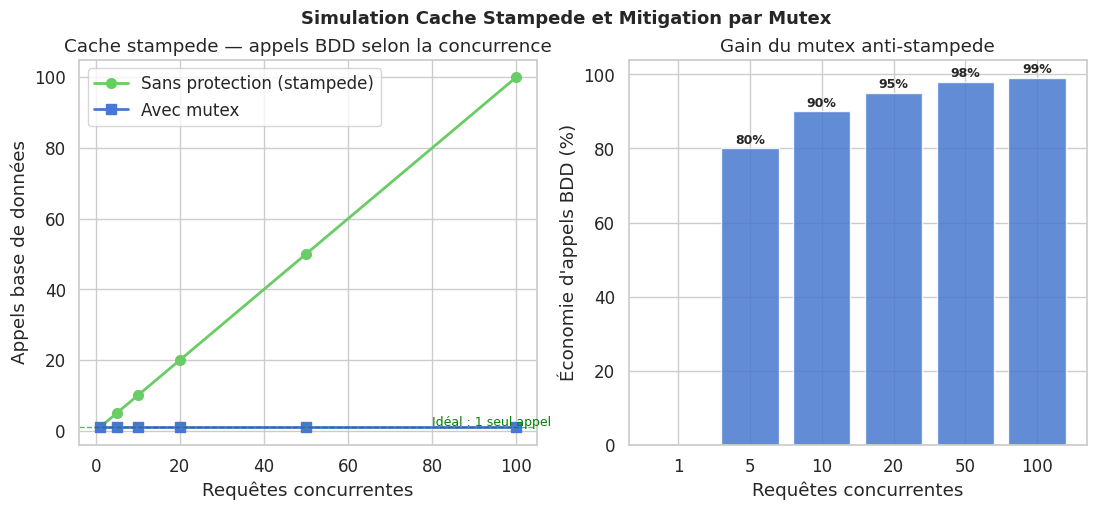
Cache stampede (dog-piling)#
Le cache stampede se produit quand une entrée populaire expire simultanément et que des centaines de requêtes concurrentes trouvent un miss et partent toutes requêter la base de données en même temps.
Mitigation 1 : Probabilistic Early Expiration (PER)
Au lieu d’attendre l’expiration stricte, chaque requête a une probabilité croissante de déclencher un renouvellement proactif à mesure que le TTL approche. Cela étale statistiquement les renouvellements.
Mitigation 2 : Mutex lock
Quand un miss est détecté, un verrou est posé (SETNX dans Redis) avant de requêter la base de données. Les autres requêtes concurrentes attendent ou retournent la valeur périmée pendant le renouvellement.
# Exemple statique : mutex anti-stampede avec SETNX
def get_with_mutex(key: str, ttl: int, loader_func) -> dict:
value = r.get(key)
if value is not None:
return json.loads(value)
lock_key = f"lock:{key}"
acquired = r.setnx(lock_key, 1)
r.expire(lock_key, 10) # expire le lock en cas de crash
if acquired:
try:
result = loader_func()
r.setex(key, ttl, json.dumps(result, default=str))
return result
finally:
r.delete(lock_key)
else:
# Attendre brièvement que le premier renouvellement finisse
import time
time.sleep(0.05)
value = r.get(key)
return json.loads(value) if value else loader_func()
Métriques cache#
Les métriques essentielles d’un cache :
Hit ratio : proportion des requêtes satisfaites par le cache (cible : > 90% pour un cache efficace)
Latence with/without cache : p50 et p99, pour quantifier le gain réel
Eviction rate : fréquence à laquelle des entrées sont expulsées faute de mémoire (signal de sous-dimensionnement)
Coût de revalidation : pour les caches stale-while-revalidate, coût des renouvellements en arrière-plan
Simulations et visualisations#
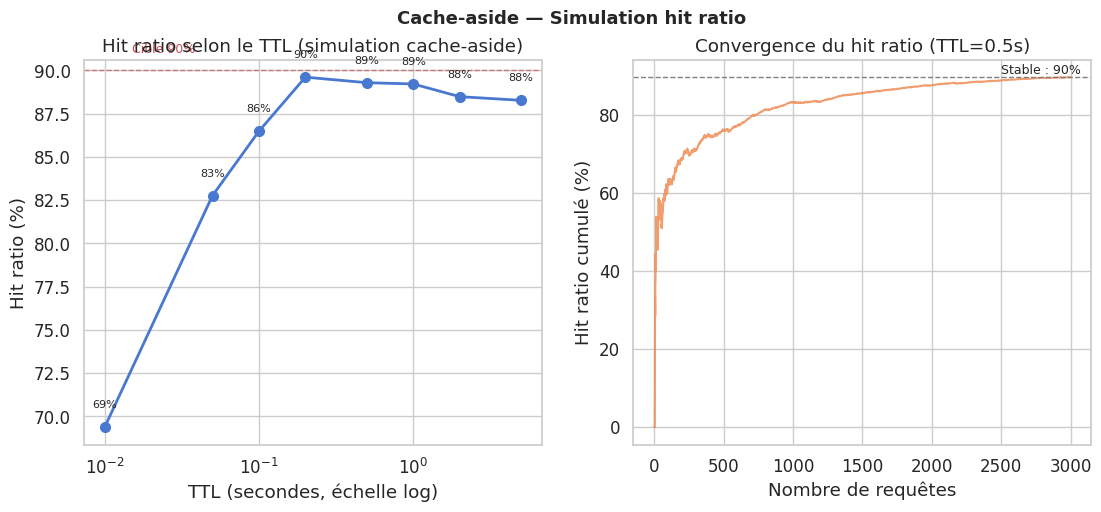
Simulation cache-aside et hit ratio selon le TTL#
import random
import time
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
class SimpleCacheAside:
"""Simulation d'un cache-aside avec TTL (cache = dict Python)."""
def __init__(self, ttl_seconds: float):
self.ttl = ttl_seconds
self.store: dict = {} # {key: (value, expiry_timestamp)}
self.hits = 0
self.misses = 0
def get(self, key: str):
entry = self.store.get(key)
if entry and time.monotonic() < entry[1]:
self.hits += 1
return entry[0]
self.misses += 1
return None
def set(self, key: str, value):
self.store[key] = (value, time.monotonic() + self.ttl)
@property
def hit_ratio(self) -> float:
total = self.hits + self.misses
return self.hits / total if total > 0 else 0.0
def simulate_workload(cache: SimpleCacheAside, n_requests: int = 2000,
n_unique_keys: int = 200, write_rate: float = 0.05) -> float:
"""Simule un workload avec distribution de Zipf sur les clés."""
# Distribution Zipf : quelques clés très fréquentes, beaucoup de rares
zipf_alpha = 1.2
keys = [f"user:{i}" for i in range(n_unique_keys)]
ranks = np.arange(1, n_unique_keys + 1)
probs = (1 / ranks ** zipf_alpha)
probs /= probs.sum()
for _ in range(n_requests):
key = np.random.choice(keys, p=probs)
if random.random() < write_rate:
# Écriture : invalider le cache
cache.store.pop(key, None)
else:
# Lecture cache-aside
value = cache.get(key)
if value is None:
# Simuler un appel base de données
value = {"id": key, "data": "db_value"}
cache.set(key, value)
return cache.hit_ratio
# Test avec différents TTL
ttl_values = [0.01, 0.05, 0.1, 0.2, 0.5, 1.0, 2.0, 5.0]
hit_ratios = []
np.random.seed(42)
random.seed(42)
for ttl in ttl_values:
cache = SimpleCacheAside(ttl_seconds=ttl)
ratio = simulate_workload(cache, n_requests=3000)
hit_ratios.append(ratio * 100)
# Également : évolution du hit ratio au fil des requêtes pour TTL=0.5s
cache_trace = SimpleCacheAside(ttl_seconds=0.5)
np.random.seed(42)
random.seed(42)
n_unique = 200
keys = [f"user:{i}" for i in range(n_unique)]
ranks = np.arange(1, n_unique + 1)
probs = (1 / ranks ** 1.2)
probs /= probs.sum()
trace_ratios = []
for i in range(1, 3001):
key = np.random.choice(keys, p=probs)
if random.random() < 0.05:
cache_trace.store.pop(key, None)
else:
v = cache_trace.get(key)
if v is None:
cache_trace.set(key, {"id": key})
trace_ratios.append(cache_trace.hit_ratio * 100)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# Graphique 1 : hit ratio selon le TTL
axes[0].semilogx(ttl_values, hit_ratios, "o-", color=sns.color_palette("muted")[0],
linewidth=2, markersize=7)
axes[0].set_xlabel("TTL (secondes, échelle log)")
axes[0].set_ylabel("Hit ratio (%)")
axes[0].set_title("Hit ratio selon le TTL (simulation cache-aside)")
axes[0].axhline(y=90, color="#C44E52", linestyle="--", linewidth=1, alpha=0.7)
axes[0].text(0.015, 91, "Cible 90%", color="#C44E52", fontsize=9)
for x, y in zip(ttl_values, hit_ratios):
axes[0].text(x, y + 1, f"{y:.0f}%", ha="center", va="bottom", fontsize=8)
# Graphique 2 : convergence du hit ratio au fil des requêtes
axes[1].plot(range(1, 3001), trace_ratios, linewidth=1.5,
color=sns.color_palette("muted")[1], alpha=0.8)
axes[1].set_xlabel("Nombre de requêtes")
axes[1].set_ylabel("Hit ratio cumulé (%)")
axes[1].set_title("Convergence du hit ratio (TTL=0.5s)")
axes[1].axhline(y=trace_ratios[-1], color="gray", linestyle="--", linewidth=1)
axes[1].text(2500, trace_ratios[-1] + 1, f"Stable : {trace_ratios[-1]:.0f}%", fontsize=9)
plt.suptitle("Cache-aside — Simulation hit ratio", fontsize=13, fontweight="bold")
plt.show()
Simulation du cache stampede et mitigation#
import threading
import time
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
class StampedeSimulator:
def __init__(self, use_mutex: bool = False):
self.use_mutex = use_mutex
self.cache: dict = {}
self.db_calls = 0
self.lock_key_acquired = threading.Lock()
self.db_call_times: list[float] = []
def _db_call(self, key: str) -> dict:
"""Simule un appel base de données lent."""
time.sleep(0.05) # 50ms
self.db_calls += 1
self.db_call_times.append(time.monotonic())
return {"key": key, "value": "from_db"}
def get(self, key: str) -> dict:
# Cache vide (simule une expiration)
if key in self.cache:
return self.cache[key]
if self.use_mutex:
acquired = self.lock_key_acquired.acquire(blocking=False)
if acquired:
try:
result = self._db_call(key)
self.cache[key] = result
finally:
self.lock_key_acquired.release()
return result
else:
# Attendre que le premier thread finisse
self.lock_key_acquired.acquire()
self.lock_key_acquired.release()
return self.cache.get(key, {})
else:
# Sans protection : toutes les requêtes concurrent vont en base
result = self._db_call(key)
self.cache[key] = result
return result
def run_stampede(n_concurrent: int, use_mutex: bool) -> tuple[int, float]:
sim = StampedeSimulator(use_mutex=use_mutex)
start = time.monotonic()
threads = [threading.Thread(target=sim.get, args=("popular_key",))
for _ in range(n_concurrent)]
for t in threads:
t.start()
for t in threads:
t.join()
duration = (time.monotonic() - start) * 1000
return sim.db_calls, duration
# Test avec différentes concurrences
concurrent_levels = [1, 5, 10, 20, 50, 100]
results_no_mutex = []
results_mutex = []
for n in concurrent_levels:
calls_no, dur_no = run_stampede(n, use_mutex=False)
calls_mu, dur_mu = run_stampede(n, use_mutex=True)
results_no_mutex.append(calls_no)
results_mutex.append(calls_mu)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
colors = sns.color_palette("muted", 3)
# Graphique 1 : nombre d'appels BDD selon la concurrence
axes[0].plot(concurrent_levels, results_no_mutex, "o-", color=colors[2],
label="Sans protection (stampede)", linewidth=2, markersize=7)
axes[0].plot(concurrent_levels, results_mutex, "s-", color=colors[0],
label="Avec mutex", linewidth=2, markersize=7)
axes[0].set_xlabel("Requêtes concurrentes")
axes[0].set_ylabel("Appels base de données")
axes[0].set_title("Cache stampede — appels BDD selon la concurrence")
axes[0].legend()
axes[0].axhline(y=1, color="green", linestyle="--", linewidth=1, alpha=0.6)
axes[0].text(80, 1.5, "Idéal : 1 seul appel", color="green", fontsize=9)
# Graphique 2 : rapport d'économie
savings = [(n - m) / n * 100 if n > 0 else 0
for n, m in zip(results_no_mutex, results_mutex)]
axes[1].bar(range(len(concurrent_levels)), savings,
color=colors[0], alpha=0.85, tick_label=concurrent_levels)
axes[1].set_xlabel("Requêtes concurrentes")
axes[1].set_ylabel("Économie d'appels BDD (%)")
axes[1].set_title("Gain du mutex anti-stampede")
for i, s in enumerate(savings):
if s > 0:
axes[1].text(i, s + 0.5, f"{s:.0f}%", ha="center", va="bottom",
fontsize=9, fontweight="bold")
plt.suptitle("Simulation Cache Stampede et Mitigation par Mutex",
fontsize=13, fontweight="bold")
plt.show()
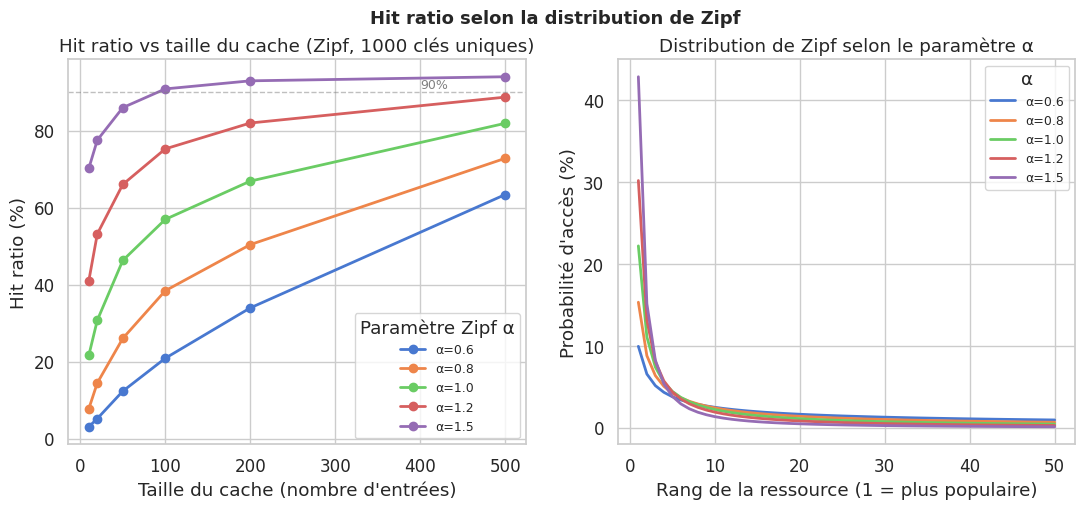
Modélisation du hit ratio selon la distribution de Zipf#
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
def simulate_hit_ratio_zipf(n_keys: int, cache_size: int, alpha: float,
n_requests: int = 10000) -> float:
"""
Simule le hit ratio d'un cache LRU de taille cache_size
sur une distribution de Zipf avec paramètre alpha.
"""
ranks = np.arange(1, n_keys + 1)
probs = 1.0 / ranks ** alpha
probs /= probs.sum()
cache = {} # {key: last_access_time} simulation LRU simplifiée
hits = 0
for i in range(n_requests):
key = int(np.random.choice(n_keys, p=probs))
if key in cache:
hits += 1
cache[key] = i # mise à jour du LRU timestamp
else:
if len(cache) >= cache_size:
# Éviction LRU : supprimer la clé la moins récemment accédée
lru_key = min(cache, key=cache.__getitem__)
del cache[lru_key]
cache[key] = i
return hits / n_requests
np.random.seed(42)
# Paramètres
n_keys = 1000
alphas = [0.6, 0.8, 1.0, 1.2, 1.5]
cache_sizes = [10, 20, 50, 100, 200, 500]
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
colors = sns.color_palette("muted", len(alphas))
# Graphique 1 : hit ratio en fonction de la taille du cache, pour différents alpha
for alpha, color in zip(alphas, colors):
ratios = [simulate_hit_ratio_zipf(n_keys, cs, alpha, n_requests=5000)
for cs in cache_sizes]
axes[0].plot(cache_sizes, [r * 100 for r in ratios], "o-",
label=f"α={alpha}", color=color, linewidth=2, markersize=6)
axes[0].set_xlabel("Taille du cache (nombre d'entrées)")
axes[0].set_ylabel("Hit ratio (%)")
axes[0].set_title(f"Hit ratio vs taille du cache (Zipf, {n_keys} clés uniques)")
axes[0].legend(title="Paramètre Zipf α", fontsize=9)
axes[0].axhline(y=90, color="gray", linestyle="--", linewidth=1, alpha=0.5)
axes[0].text(400, 91, "90%", color="gray", fontsize=9)
# Graphique 2 : distribution de Zipf pour différents alpha
ranks = np.arange(1, 51)
for alpha, color in zip(alphas, colors):
probs = 1.0 / ranks ** alpha
probs /= probs.sum()
axes[1].plot(ranks, probs * 100, "-", label=f"α={alpha}", color=color, linewidth=2)
axes[1].set_xlabel("Rang de la ressource (1 = plus populaire)")
axes[1].set_ylabel("Probabilité d'accès (%)")
axes[1].set_title("Distribution de Zipf selon le paramètre α")
axes[1].legend(title="α", fontsize=9)
plt.suptitle("Hit ratio selon la distribution de Zipf",
fontsize=13, fontweight="bold")
plt.show()
Comparaison des latences avec et sans cache#
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Latences typiques en ms (p50 et p99)
levels = [
"In-process\n(dict Python)",
"Redis\n(local)",
"Redis\n(réseau local)",
"Reverse Proxy\n(Nginx cache)",
"CDN\n(cache chaud)",
"Base de données\n(sans cache)",
]
# p50 et p99 en ms
p50_with_cache = [0.001, 0.3, 1.5, 2.0, 8.0, None]
p99_with_cache = [0.005, 0.8, 4.0, 6.0, 25.0, None]
p50_no_cache = [None, None, None, None, None, 30.0]
p99_no_cache = [None, None, None, None, None, 120.0]
# Valeurs de référence pour les barres
p50_values = [0.001, 0.3, 1.5, 2.0, 8.0, 30.0]
p99_values = [0.005, 0.8, 4.0, 6.0, 25.0, 120.0]
fig, ax = plt.subplots(figsize=(12, 6))
colors = sns.color_palette("muted", 6)
y = np.arange(len(levels))
height = 0.35
bars_p50 = ax.barh(y + height/2, p50_values, height, label="p50",
color=colors[0], alpha=0.85)
bars_p99 = ax.barh(y - height/2, p99_values, height, label="p99",
color=colors[2], alpha=0.85)
ax.set_xscale("log")
ax.set_xlabel("Latence (ms) — échelle logarithmique")
ax.set_yticks(y)
ax.set_yticklabels(levels, fontsize=10)
ax.set_title("Latences par niveau de cache (p50 / p99)", fontweight="bold")
ax.legend()
# Annotations
for bar, val in zip(bars_p50, p50_values):
label = f"{val*1000:.0f}µs" if val < 1 else f"{val:.1f}ms"
ax.text(val * 1.1, bar.get_y() + bar.get_height()/2,
label, va="center", fontsize=8)
for bar, val in zip(bars_p99, p99_values):
label = f"{val*1000:.0f}µs" if val < 1 else f"{val:.0f}ms"
ax.text(val * 1.1, bar.get_y() + bar.get_height()/2,
label, va="center", fontsize=8)
# Mise en évidence de la BDD
ax.axvspan(15, 200, alpha=0.06, color="#C44E52")
ax.text(40, len(levels) - 0.7, "Sans cache\n(BDD directe)",
color="#C44E52", fontsize=9, style="italic")
plt.suptitle("Comparaison des latences selon le niveau de cache",
fontsize=13, fontweight="bold")
plt.show()
Résumé#
Le caching applicatif opère sur plusieurs niveaux (in-process, Redis, reverse proxy, CDN) avec des compromis différents de vitesse et de complexité d’invalidation. Le pattern cache-aside est le plus répandu : il charge le cache à la demande et invalide explicitement à l’écriture. Redis enrichit ce pattern avec des structures de données avancées (sorted sets pour les leaderboards, pub/sub pour l’invalidation cross-instances) et des primitives atomiques pour le rate limiting (INCR + EXPIRE).
L’invalidation est la difficulté centrale : le TTL simple accepte des données périmées jusqu’à son expiration, l’event-based invalidation est plus cohérente mais plus couplée. Le cache stampede survient lors de l’expiration simultanée d’une entrée populaire — le mutex lock ou la probabilistic early expiration le mitiguent. Le hit ratio, principal indicateur de santé du cache, converge vers des valeurs élevées (>85%) même pour des caches dont la taille représente 10-20% du nombre de clés uniques, grâce à la distribution naturelle de Zipf des accès.