Chapitre 17 — Observabilité des APIs#
Une API en production est une boîte noire pour ses concepteurs. Sans instruments de mesure, diagnostiquer une dégradation revient à deviner. L’observabilité est la propriété d’un système qui permet de comprendre son état interne à partir de ses sorties externes. Ce chapitre couvre les trois piliers — logs, métriques, traces — et leur application concrète aux APIs.
Les 3 piliers — logs, métriques, traces#
Les trois piliers de l’observabilité sont complémentaires. Chacun répond à une question différente.
Logs — Que s’est-il passé ?#
Les logs sont des enregistrements d’événements discrets. Chaque requête HTTP peut générer un ou plusieurs logs. Ils sont utiles pour le debugging : retrouver l’erreur précise qui a causé un 500, identifier la payload malformée, auditer les accès.
Limite : en volume élevé (millions de req/min), parcourir les logs à la main est impossible. Les logs doivent être structurés et indexés pour être interrogeables.
Métriques — Quel est l’état actuel ?#
Les métriques sont des mesures numériques agrégées dans le temps. Elles permettent de détecter des anomalies (le taux d’erreur a doublé), de définir des SLOs, et d’alerter. Contrairement aux logs, les métriques ne capturent pas le contexte d’un événement individuel — elles décrivent une tendance.
Traces — Pourquoi est-ce lent ?#
Une trace distribuce représente le chemin complet d’une requête à travers plusieurs services. Elle est composée de spans — chaque span est une opération (appel HTTP, requête SQL, appel de cache). Les traces permettent d’identifier les goulots d’étranglement et les dépendances lentes.
Complémentarité
Un taux d’erreur élevé (métrique) vous dit qu’il y a un problème. Les logs vous disent ce qui a échoué pour une requête spécifique. Les traces vous disent où la latence est concentrée dans le pipeline. Les trois sont nécessaires.
Logs structurés#
Un log structuré est un document JSON — pas une chaîne de texte libre. L’objectif est que chaque champ soit interrogeable dans un système de log management (Elasticsearch, Loki, CloudWatch Logs Insights).
Format recommandé#
{
"timestamp": "2024-11-15T14:32:01.234Z",
"level": "INFO",
"service": "user-api",
"version": "2.3.1",
"environment": "production",
"trace_id": "4bf92f3577b34da6a3ce929d0e0e4736",
"span_id": "00f067aa0ba902b7",
"request_id": "req-7f3a91c2-4b8d-4e1a-9c2f-1234567890ab",
"user_id": "usr-123456",
"method": "POST",
"path": "/api/v2/orders",
"status": 201,
"duration_ms": 47,
"ip": "203.0.113.42",
"user_agent": "MyApp/3.1 (iOS 17.0)"
}
Champs obligatoires#
timestamp: ISO 8601 UTC, précision millisecondelevel: DEBUG / INFO / WARNING / ERROR / CRITICALtrace_id: identifiant de la trace distribuée (W3C Trace Context)request_id: identifiant unique de la requête HTTP (généré côté serveur)user_id: identifiant de l’utilisateur authentifié (null si anonyme)path: chemin normalisé (sans les paramètres d’identifiant :/api/v2/users/:id)status: code HTTP de la réponseduration_ms: durée de traitement côté serveur en millisecondes
Middleware de log structuré — FastAPI#
import json
import time
import uuid
import logging
from fastapi import FastAPI, Request, Response
app = FastAPI()
logger = logging.getLogger("api")
@app.middleware("http")
async def structured_logging_middleware(request: Request, call_next):
request_id = str(uuid.uuid4())
start_time = time.perf_counter()
# Injecter le request_id dans le scope pour les handlers
request.state.request_id = request_id
response: Response = await call_next(request)
duration_ms = round((time.perf_counter() - start_time) * 1000, 2)
log_entry = {
"timestamp": time.strftime("%Y-%m-%dT%H:%M:%S", time.gmtime()) + "Z",
"level": "WARNING" if response.status_code >= 400 else "INFO",
"request_id": request_id,
"trace_id": request.headers.get("traceparent", ""),
"method": request.method,
"path": request.url.path,
"status": response.status_code,
"duration_ms": duration_ms,
"user_agent": request.headers.get("user-agent", ""),
}
logger.info(json.dumps(log_entry))
response.headers["X-Request-Id"] = request_id
return response
Corrélation des logs#
Le trace_id est la clé de corrélation. Il circule dans tous les services via le header traceparent (W3C Trace Context). Dans Kibana ou Grafana Loki :
{trace_id="4bf92f3577b34da6a3ce929d0e0e4736"}
Cette requête retourne tous les logs de tous les services impliqués dans la même requête utilisateur.
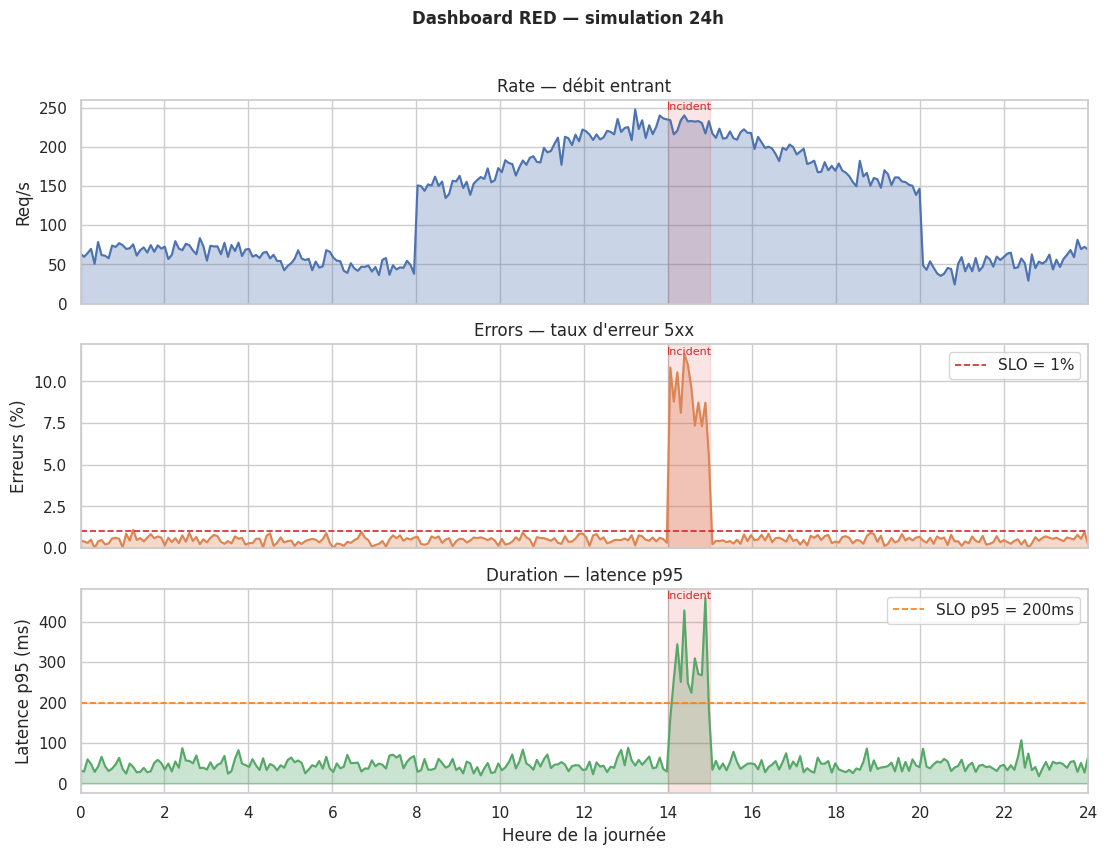
Métriques RED#
Le modèle RED (Rate, Errors, Duration) définit les trois métriques fondamentales à surveiller pour chaque service.
Rate — Débit entrant#
Nombre de requêtes par seconde, par endpoint, par version d’API, par client. Le Rate permet de détecter des pics de trafic, des baisses anormales (signe d’une panne en amont), ou des abus.
rate(http_requests_total[5m])
Errors — Taux d’erreur#
Proportion de requêtes terminées avec un code >= 400 (ou >= 500 si on exclut les erreurs client). Le taux d’erreur est souvent la première métrique à surveiller.
rate(http_requests_total{status=~"5.."}[5m])
/ rate(http_requests_total[5m])
Duration — Latence#
Distribution des temps de réponse. La latence est la métrique qui révèle les dégradations progressives.
Pourquoi suivre les trois
Un Rate normal avec un taux d’erreur élevé = bug applicatif. Un Rate normal, zéro erreur, mais latence élevée = ressource saturée (DB, service externe). Un Rate en baisse sans erreur = panne silencieuse en amont.
Middleware métriques RED — FastAPI#
from prometheus_client import Counter, Histogram, start_http_server
import time
REQUEST_COUNT = Counter(
"http_requests_total",
"Total HTTP requests",
["method", "path", "status", "version"]
)
REQUEST_DURATION = Histogram(
"http_request_duration_seconds",
"HTTP request duration",
["method", "path", "version"],
buckets=[0.005, 0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0, 2.5, 5.0]
)
@app.middleware("http")
async def metrics_middleware(request: Request, call_next):
start = time.perf_counter()
response = await call_next(request)
duration = time.perf_counter() - start
# Normaliser le path (éviter la cardinalité explosive)
path = normalize_path(request.url.path)
version = extract_version(request.url.path)
REQUEST_COUNT.labels(
method=request.method,
path=path,
status=response.status_code,
version=version
).inc()
REQUEST_DURATION.labels(
method=request.method,
path=path,
version=version
).observe(duration)
return response
Histogrammes de latence — p50/p95/p99#
La moyenne de latence est trompeuse. Si 99% des requêtes durent 10 ms mais que 1% en prend 10 secondes, la moyenne est de ~110 ms — qui ne reflète ni l’expérience des utilisateurs normaux, ni celle des utilisateurs pénalisés.
Percentiles#
p50 (médiane) : latence que 50% des requêtes ne dépassent pas. Représente l’expérience typique.
p95 : 5% des requêtes sont plus lentes que cette valeur. Latence des utilisateurs « malchanceux ».
p99 : 1% des requêtes sont plus lentes. Latence des utilisateurs les plus pénalisés — souvent corrélée aux requêtes de gros clients ou aux pics de charge.
Pourquoi les moyennes mentent#
Un appel à GET /users/{id} retourne en 5 ms pour un utilisateur avec 10 commandes, mais en 4 secondes pour un utilisateur avec 50 000 commandes. La moyenne cache cette dispersion. Un SLO basé sur la moyenne passe même quand vos meilleurs clients souffrent.
Buckets d’histogramme#
Les histogrammes Prometheus accumulent les requêtes dans des buckets de durée prédéfinis. Le choix des buckets est important : ils doivent couvrir les percentiles d’intérêt avec suffisamment de résolution.
Buckets recommandés pour une API web : [1ms, 5ms, 10ms, 25ms, 50ms, 100ms, 250ms, 500ms, 1s, 2.5s, 5s].
Exemplars#
Les exemplars (OpenMetrics / Prometheus 2.26+) attachent un trace_id à un bucket d’histogramme. Quand le p99 dégrade, vous pouvez sauter directement à une trace représentative sans chercher dans les logs.
OpenTelemetry — traces distribuées#
OpenTelemetry (OTel) est le standard open source pour l’instrumentation de l’observabilité. Il unifie logs, métriques et traces sous une API commune.
Concepts fondamentaux#
Trace : représentation du chemin complet d’une requête. Identifiée par un trace_id (16 bytes hexadécimal).
Span : opération unitaire dans la trace. Un span a un nom, une durée, un status, et des attributs. Les spans sont organisés en arbre (parent/enfant).
Context propagation : mécanisme qui transmet le trace_id et le span_id parent entre services via des headers HTTP. Standard W3C Trace Context : header traceparent.
traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01
^^ ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^^^^^ ^^
version trace-id (128 bits) span-id (64 bits) flags
Instrumentation automatique FastAPI#
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
from opentelemetry.instrumentation.httpx import HTTPXClientInstrumentor
from opentelemetry.instrumentation.sqlalchemy import SQLAlchemyInstrumentor
# Configuration du provider
provider = TracerProvider()
provider.add_span_processor(
BatchSpanProcessor(OTLPSpanExporter(endpoint="http://otel-collector:4317"))
)
trace.set_tracer_provider(provider)
# Instrumentation automatique
FastAPIInstrumentor.instrument_app(app)
HTTPXClientInstrumentor().instrument()
SQLAlchemyInstrumentor().instrument(engine=engine)
L’instrumentation automatique crée un span par requête HTTP entrant, un span par appel HTTP sortant, et un span par requête SQL — sans modification du code métier.
Spans manuels#
tracer = trace.get_tracer("user-api")
@router.post("/users/{user_id}/verify")
async def verify_user(user_id: int):
with tracer.start_as_current_span("verify_user") as span:
span.set_attribute("user.id", user_id)
with tracer.start_as_current_span("check_external_kyc"):
result = await kyc_service.verify(user_id)
span.set_attribute("kyc.result", result.status)
return {"verified": result.status == "approved"}
SLO et error budget#
Un Service Level Objective (SLO) est un engagement de fiabilité mesurable. Il permet de quantifier la qualité de service et de guider les décisions d’investissement en fiabilité.
SLI, SLO, SLA#
SLI (Service Level Indicator) : métrique qui mesure le comportement du service. Ex : « proportion de requêtes qui répondent en moins de 200 ms avec un code 2xx ».
SLO : objectif sur le SLI. Ex : « 99.5% des requêtes satisfont le SLI sur une fenêtre glissante de 30 jours ».
SLA : accord contractuel avec le client, souvent avec pénalités financières si le SLO n’est pas atteint. Le SLO interne est toujours plus strict que le SLA externe.
Error budget#
L’error budget est la quantité d’indisponibilité autorisée par le SLO :
Error budget = 1 - SLO
Pour SLO = 99.5% sur 30 jours :
Error budget = 0.5% × 30 × 24 × 60 min = 216 minutes d'indisponibilité autorisées
L’error budget guide les décisions :
Budget intact → on peut déployer plus fréquemment, prendre des risques
Budget épuisé → gel des déploiements, focus sur la fiabilité
Error budget policy#
Error budget policy
Définissez une politique avant d’avoir un incident : si l’error budget est consommé à plus de 50% à mi-mois, les déploiements nécessitent une approbation. Si le budget est épuisé, les fonctionnalités sont gelées jusqu’à la fin de la période. Cette politique transforme la fiabilité en décision business, pas en décision technique.
SLO pour une API#
Exemples de SLOs typiques pour une API REST :
Disponibilité : 99.9% des requêtes reçoivent un code != 5xx (30 jours)
Latence p95 : 95% des requêtes GET /users/* répondent < 100ms (30 jours)
Latence p99 : 99% des requêtes POST /orders répondent < 500ms (30 jours)
Fraîcheur : Les données sont à jour à ±5s de la réalité (99.9% du temps)
Dashboards#
Un bon dashboard d’API suit une hiérarchie en entonnoir : overview → service → endpoint.
Structure recommandée#
Tier 1 — Overview : vue d’ensemble du service. Métriques : rate global, taux d’erreur global, latence p99 global, état des dépendances (DB, cache, services externes).
Tier 2 — Service : métriques par version d’API, par environnement. Histogramme de latence, heatmap des status codes.
Tier 3 — Endpoint : métriques par endpoint. Utile pour l’investigation post-incident.
Alertes sur les symptômes, pas les causes#
Symptômes vs causes
Alertez sur ce que l’utilisateur ressent (taux d’erreur > 1%, latence p99 > 2s), pas sur les causes intermédiaires (CPU > 80%, connexions DB > 80%). Les alertes sur causes génèrent des faux positifs. Un CPU à 90% pendant un batch nocturne n’impacte pas les utilisateurs.
Alertes multi-fenêtre pour les SLOs#
L’alerting SLO avec fenêtre unique (ex : « taux d’erreur > 0.5% sur 1h ») rate les dégradations lentes et génère trop d’alertes pour les pics brefs. L’approche multi-fenêtre (1h + 6h) est plus robuste :
# Exemple Prometheus alerting rule
groups:
- name: slo_alerts
rules:
- alert: HighErrorRateFast
expr: |
(
rate(http_requests_total{status=~"5.."}[1h])
/ rate(http_requests_total[1h])
) > 0.01
for: 2m
labels:
severity: page
annotations:
summary: "Taux d'erreur > 1% (fenêtre 1h)"
Debugging en production#
Corrélation trace_id#
Le trace_id est le fil d’Ariane entre les trois piliers. Workflow typique d’investigation :
Alerte sur une métrique (taux d’erreur en hausse)
Logs : filtrer par
status >= 500dans la fenêtre temporelle → identifier lestrace_iden erreurTraces : charger la trace dans Jaeger/Zipkin → identifier le span en échec et sa cause
Métriques : vérifier si la dépendance identifiée montre une anomalie générale
# Ajouter le trace_id dans les réponses d'erreur (pour le débogage client)
from opentelemetry import trace as otel_trace
from fastapi import HTTPException
@app.exception_handler(Exception)
async def global_exception_handler(request: Request, exc: Exception):
span = otel_trace.get_current_span()
trace_id = format(span.get_span_context().trace_id, "032x")
return JSONResponse(
status_code=500,
content={
"error": "internal_server_error",
"trace_id": trace_id, # Le client peut fournir ce trace_id au support
"message": "An unexpected error occurred."
}
)
Profiling en production#
Le profiling continu (py-spy, Pyroscope) permet d’identifier les fonctions lentes sans redémarrer l’application. En production, utilisez le profiling par échantillonnage (1% des requêtes) pour limiter l’overhead :
import pyroscope
pyroscope.configure(
application_name="user-api",
server_address="http://pyroscope:4040",
sample_rate=100, # samples/s
)
Cellules exécutables#
Génération et analyse de logs structurés simulés#
import json
import random
import datetime
import uuid
import pandas as pd
rng = random.Random(42)
ENDPOINTS = [
("/api/v2/users", "GET", [200, 200, 200, 404]),
("/api/v2/users", "POST", [201, 201, 400, 422]),
("/api/v2/orders", "GET", [200, 200, 200, 200]),
("/api/v2/orders", "POST", [201, 201, 201, 500]),
("/api/v2/products", "GET", [200, 200, 200, 200]),
]
def generate_logs(n: int = 500) -> list[dict]:
logs = []
base_time = datetime.datetime(2024, 11, 15, 9, 0, 0)
for i in range(n):
path, method, statuses = rng.choice(ENDPOINTS)
status = rng.choice(statuses)
# Latence log-normale (typique des APIs)
if status == 500:
duration_ms = rng.gauss(800, 200)
elif status in (400, 422, 404):
duration_ms = rng.gauss(15, 5)
else:
duration_ms = abs(rng.gauss(45, 20))
logs.append({
"timestamp": (base_time + datetime.timedelta(seconds=i * 0.5)).isoformat() + "Z",
"level": "ERROR" if status >= 500 else ("WARNING" if status >= 400 else "INFO"),
"request_id": str(uuid.UUID(int=rng.getrandbits(128))),
"trace_id": str(uuid.UUID(int=rng.getrandbits(128))).replace("-", "")[:32],
"method": method,
"path": path,
"status": status,
"duration_ms": round(max(1, duration_ms), 1),
"user_id": f"usr-{rng.randint(1000, 9999)}",
})
return logs
logs = generate_logs(500)
df = pd.DataFrame(logs)
print("=== Statistiques générales ===")
print(f"Total requêtes : {len(df)}")
print(f"Taux d'erreur 5xx : {(df['status'] >= 500).mean():.2%}")
print(f"Taux d'erreur 4xx : {((df['status'] >= 400) & (df['status'] < 500)).mean():.2%}")
print(f"Latence médiane : {df['duration_ms'].median():.1f} ms")
print(f"Latence p95 : {df['duration_ms'].quantile(0.95):.1f} ms")
print(f"Latence p99 : {df['duration_ms'].quantile(0.99):.1f} ms")
print()
print("=== Taux d'erreur par endpoint ===")
by_endpoint = df.groupby("path").agg(
total=("status", "count"),
errors_5xx=("status", lambda s: (s >= 500).sum()),
p50_ms=("duration_ms", "median"),
p95_ms=("duration_ms", lambda s: s.quantile(0.95)),
).reset_index()
by_endpoint["error_rate"] = (by_endpoint["errors_5xx"] / by_endpoint["total"]).map("{:.2%}".format)
print(by_endpoint[["path", "total", "error_rate", "p50_ms", "p95_ms"]].to_string(index=False))
=== Statistiques générales ===
Total requêtes : 500
Taux d'erreur 5xx : 4.40%
Taux d'erreur 4xx : 14.60%
Latence médiane : 40.5 ms
Latence p95 : 90.1 ms
Latence p99 : 956.3 ms
=== Taux d'erreur par endpoint ===
path total error_rate p50_ms p95_ms
/api/v2/orders 209 10.53% 45.9 877.92
/api/v2/products 94 0.00% 45.2 73.59
/api/v2/users 197 0.00% 27.2 69.76
Histogramme de latence avec p50/p95/p99#
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
rng = np.random.default_rng(42)
# Distribution log-normale typique d'une API (en millisecondes)
# mu=3.5, sigma=0.7 → médiane ~33ms, longue queue
latencies = rng.lognormal(mean=3.5, sigma=0.7, size=10000)
# Quelques outliers (timeouts, retry storms)
outliers = rng.lognormal(mean=6.5, sigma=0.5, size=50)
latencies = np.concatenate([latencies, outliers])
p50 = np.percentile(latencies, 50)
p95 = np.percentile(latencies, 95)
p99 = np.percentile(latencies, 99)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(13, 5))
# --- Histogramme classique (log scale en x) ---
bins = np.logspace(np.log10(1), np.log10(latencies.max()), 60)
counts, edges, patches = ax1.hist(latencies, bins=bins, color="#4c72b0", alpha=0.75, edgecolor="white")
for pct, val, color in [(50, p50, "#2ca02c"), (95, p95, "#ff7f0e"), (99, p99, "#d62728")]:
ax1.axvline(val, color=color, linewidth=2, linestyle="--")
ax1.text(val * 1.05, counts.max() * 0.85 - pct * counts.max() / 200,
f"p{pct}\n{val:.0f}ms", color=color, fontsize=9, fontweight="bold")
ax1.set_xscale("log")
ax1.set_xlabel("Latence (ms, échelle log)")
ax1.set_ylabel("Nombre de requêtes")
ax1.set_title("Distribution de latence (10 000 requêtes)")
# --- Comparaison moyenne vs percentiles ---
categories = ["Moyenne", "p50", "p95", "p99"]
values = [latencies.mean(), p50, p95, p99]
colors_bar = ["#aec7e8", "#2ca02c", "#ff7f0e", "#d62728"]
bars = ax2.bar(categories, values, color=colors_bar, edgecolor="white", alpha=0.9)
for bar, val in zip(bars, values):
ax2.text(bar.get_x() + bar.get_width() / 2, bar.get_height() + 10,
f"{val:.0f}ms", ha="center", fontsize=10, fontweight="bold")
ax2.set_ylabel("Latence (ms)")
ax2.set_title("Moyenne vs Percentiles — l'écart révélateur")
ax2.set_ylim(0, values[-1] * 1.25)
# Annotation
ax2.annotate(
f"Moyenne gonflée\npar les outliers\n(+{latencies.mean() - p50:.0f}ms vs p50)",
xy=(0, latencies.mean()), xytext=(0.5, latencies.mean() + 150),
fontsize=8, color="#aec7e8",
arrowprops=dict(arrowstyle="->", color="#aec7e8")
)
plt.suptitle("Histogramme de latence — pourquoi la moyenne ment", fontweight="bold")
plt.show()
print(f"Moyenne : {latencies.mean():.0f} ms")
print(f"p50 : {p50:.0f} ms")
print(f"p95 : {p95:.0f} ms")
print(f"p99 : {p99:.0f} ms")
print(f"Maximum : {latencies.max():.0f} ms")
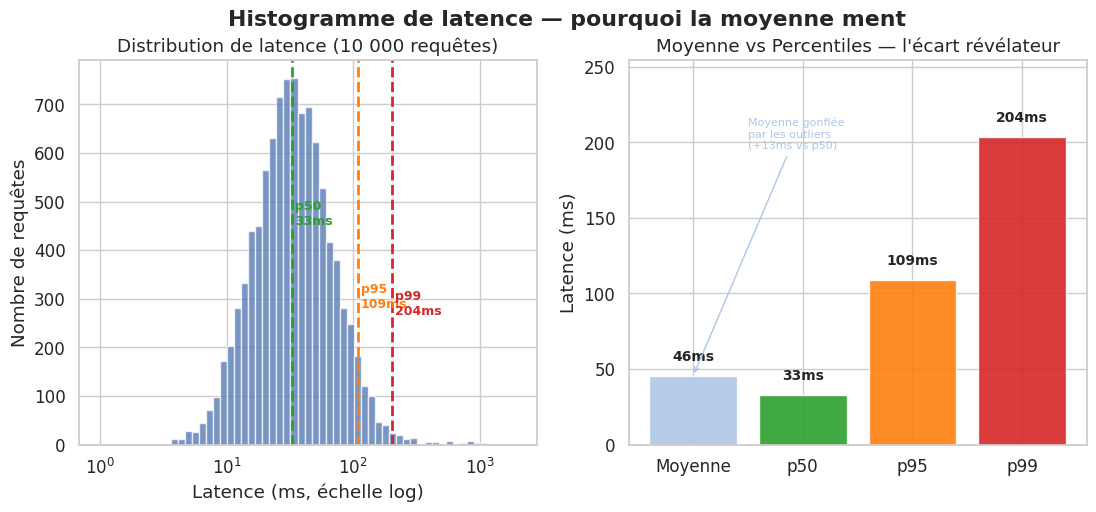
Moyenne : 46 ms
p50 : 33 ms
p95 : 109 ms
p99 : 204 ms
Maximum : 1940 ms
Error budget burndown sur 30 jours#
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
rng = np.random.default_rng(7)
# SLO : 99.5% de disponibilité sur 30 jours
# Error budget = 0.5% × 30 × 24 × 60 = 216 minutes
SLO = 0.995
WINDOW_DAYS = 30
TOTAL_MINUTES = WINDOW_DAYS * 24 * 60
ERROR_BUDGET_MINUTES = (1 - SLO) * TOTAL_MINUTES
# Simulation des erreurs jour par jour
days = np.arange(0, WINDOW_DAYS + 1)
daily_error_minutes = rng.exponential(scale=3, size=WINDOW_DAYS)
# Incidents : jours 8 (incident majeur) et 21 (incident mineur)
daily_error_minutes[7] += 45 # incident majeur : +45 min
daily_error_minutes[20] += 18 # incident mineur : +18 min
cumulative_consumed = np.concatenate([[0], np.cumsum(daily_error_minutes)])
budget_remaining = ERROR_BUDGET_MINUTES - cumulative_consumed
fig, ax = plt.subplots(figsize=(12, 5))
# Zone de budget
ax.fill_between(days, budget_remaining, 0, alpha=0.15, color="#2ca02c")
ax.fill_between(
days,
np.where(budget_remaining < 0, budget_remaining, 0),
0, alpha=0.2, color="#d62728"
)
ax.plot(days, budget_remaining, color="#2ca02c", linewidth=2.5, label="Budget restant")
ax.axhline(y=0, color="#d62728", linewidth=1.5, linestyle="--", label="Budget épuisé")
ax.axhline(y=ERROR_BUDGET_MINUTES * 0.5, color="#ff7f0e", linewidth=1.2,
linestyle=":", label="Seuil alerte (50% consommé)")
# Annotations des incidents
incidents = [(8, "Incident\nmajeur\n-45 min"), (21, "Incident\nmineur\n-18 min")]
for day, label in incidents:
ax.axvline(x=day, color="#d62728", linewidth=1, linestyle=":")
ax.text(day + 0.3, budget_remaining[day] + 8, label,
fontsize=8, color="#d62728")
ax.set_xlabel("Jour du mois")
ax.set_ylabel("Budget d'erreur restant (minutes)")
ax.set_title(f"Error budget burndown — SLO {SLO*100}% sur 30 jours\n(budget total = {ERROR_BUDGET_MINUTES:.0f} min)")
ax.legend(loc="lower left")
ax.set_xlim(0, 30)
# Afficher le budget final
final = budget_remaining[-1]
color_final = "#2ca02c" if final > 0 else "#d62728"
ax.text(29, final + 5, f"{final:.0f} min\nrestantes", ha="right",
color=color_final, fontweight="bold", fontsize=9)
plt.show()
print(f"Budget total : {ERROR_BUDGET_MINUTES:.0f} min")
print(f"Consommé : {cumulative_consumed[-1]:.0f} min ({cumulative_consumed[-1]/ERROR_BUDGET_MINUTES:.1%})")
print(f"Restant : {budget_remaining[-1]:.0f} min")
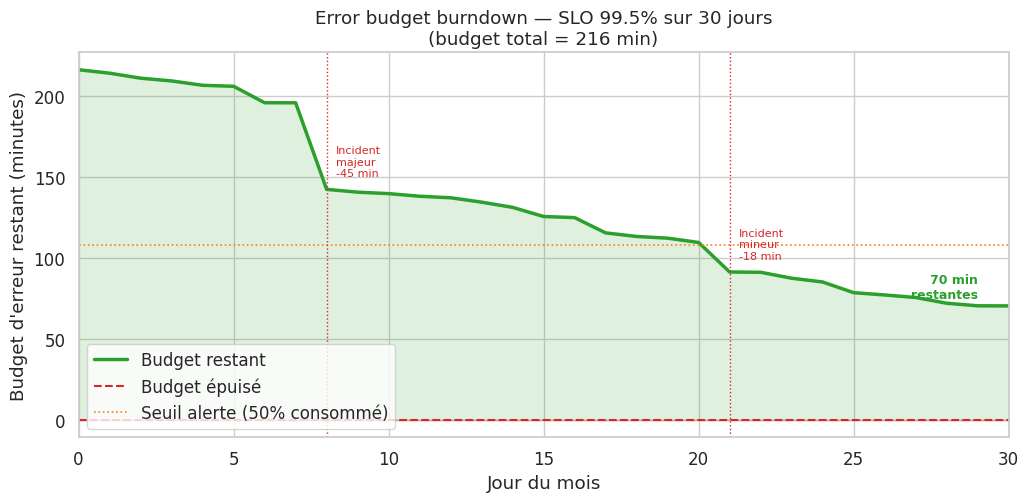
Budget total : 216 min
Consommé : 146 min (67.5%)
Restant : 70 min
Dashboard RED simulé — 24h#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.0)
rng = np.random.default_rng(99)
hours = np.linspace(0, 24, 288) # 5 minutes de résolution
# Rate : sinusoïde (pic matin + déjeuner) + bruit
base_rate = 150 + 80 * np.sin(np.pi * (hours - 8) / 12) ** 2
base_rate = np.where((hours >= 8) & (hours <= 20), base_rate, base_rate * 0.3)
rate = base_rate + rng.normal(0, 8, len(hours))
rate = np.clip(rate, 5, None)
# Incident : 14h–15h → pic d'erreurs
error_rate = rng.normal(0.005, 0.002, len(hours))
error_rate = np.clip(error_rate, 0, None)
incident_mask = (hours >= 14) & (hours <= 15)
error_rate[incident_mask] += rng.normal(0.08, 0.02, incident_mask.sum())
error_rate = np.clip(error_rate, 0, 1)
# Durée p95 : log-normale + pic pendant l'incident
duration_p95 = rng.lognormal(mean=3.8, sigma=0.3, size=len(hours))
duration_p95[incident_mask] += rng.lognormal(mean=5.5, sigma=0.5, size=incident_mask.sum())
fig, axes = plt.subplots(3, 1, figsize=(13, 9), sharex=True)
# --- Rate ---
axes[0].fill_between(hours, rate, alpha=0.3, color="#4c72b0")
axes[0].plot(hours, rate, color="#4c72b0", linewidth=1.5)
axes[0].set_ylabel("Req/s")
axes[0].set_title("Rate — débit entrant")
axes[0].set_ylim(0)
# --- Error rate ---
axes[1].fill_between(hours, error_rate * 100, alpha=0.3, color="#dd8452")
axes[1].plot(hours, error_rate * 100, color="#dd8452", linewidth=1.5)
axes[1].axhline(y=1.0, color="#d62728", linewidth=1.2, linestyle="--", label="SLO = 1%")
axes[1].set_ylabel("Erreurs (%)")
axes[1].set_title("Errors — taux d'erreur 5xx")
axes[1].set_ylim(0)
axes[1].legend(loc="upper right")
# --- Latence p95 ---
axes[2].fill_between(hours, duration_p95, alpha=0.3, color="#55a868")
axes[2].plot(hours, duration_p95, color="#55a868", linewidth=1.5)
axes[2].axhline(y=200, color="#ff7f0e", linewidth=1.2, linestyle="--", label="SLO p95 = 200ms")
axes[2].set_ylabel("Latence p95 (ms)")
axes[2].set_title("Duration — latence p95")
axes[2].set_xlabel("Heure de la journée")
axes[2].set_xlim(0, 24)
axes[2].set_xticks(range(0, 25, 2))
axes[2].legend(loc="upper right")
# Marquer l'incident sur les 3 graphes
for ax in axes:
ax.axvspan(14, 15, alpha=0.12, color="#d62728")
ax.text(14.5, ax.get_ylim()[1] * 0.95, "Incident", ha="center",
fontsize=8, color="#d62728")
fig.suptitle("Dashboard RED — simulation 24h", fontweight="bold", fontsize=12)
plt.show()
Résumé#
L’observabilité d’une API repose sur trois piliers complémentaires : les logs pour le debugging événementiel, les métriques RED pour la détection d’anomalies et les SLOs, les traces distribuées pour comprendre la latence dans un système multi-services.
Les points clés à retenir :
Les logs structurés JSON avec
trace_id,request_id,user_id,path,statusetduration_mssont la base minimale. Ils permettent la corrélation entre piliers.Les métriques RED (Rate, Errors, Duration) donnent une vue opérationnelle immédiate. Ne jamais alerter uniquement sur la moyenne de latence — utiliser les percentiles p95/p99.
OpenTelemetry est le standard à adopter pour l’instrumentation. L’instrumentation automatique couvre 80% des besoins sans modification du code métier.
Les SLOs transforment l’observabilité en outil décisionnel : l’error budget guide les priorités entre features et fiabilité.
Les alertes doivent porter sur les symptômes (ce que l’utilisateur ressent) plutôt que sur les causes intermédiaires, pour réduire le bruit et améliorer le MTTD (Mean Time To Detect).