Chapitre 15 — Scalabilité et résilience des APIs#
Une API qui fonctionne correctement pour 100 requêtes par seconde peut se comporter de façon désastreuse à 10 000 req/s si elle n’a pas été conçue pour le scaling. La scalabilité n’est pas une propriété émergente — elle se conçoit dès l’architecture. Ce chapitre couvre les patterns qui permettent à une API de s’étirer horizontalement, de se dégrader gracieusement sous charge, et de résister aux défaillances partielles.
Stateless APIs#
Pas d’état serveur#
Une API stateless ne conserve aucun état de session en mémoire locale. Chaque requête porte avec elle tout le contexte nécessaire à son traitement. L’instance qui traite la requête n°1 d’un utilisateur peut être différente de celle qui traite la requête n°2 — elles produiront le même résultat.
C’est la condition nécessaire au scaling horizontal : si toutes les instances sont équivalentes, l’ajout d’une instance augmente la capacité de façon linéaire.
Session externalisée#
L’état de session est externalisé dans un store partagé (Redis). L’instance récupère la session depuis Redis à chaque requête, la modifie si nécessaire, et la réécrit. Redis est le « state layer » ; les instances API restent stateless.
# Exemple statique : middleware de session Redis dans FastAPI
from fastapi import FastAPI, Request, Response
import redis
import json
import secrets
r = redis.Redis(host="redis", port=6379, decode_responses=True)
app = FastAPI()
SESSION_COOKIE = "session_id"
SESSION_TTL = 3600
@app.middleware("http")
async def session_middleware(request: Request, call_next):
# Lecture du session ID depuis le cookie
session_id = request.cookies.get(SESSION_COOKIE)
session_data = {}
if session_id:
raw = r.get(f"session:{session_id}")
if raw:
session_data = json.loads(raw)
# Injection dans le scope de la requête
request.state.session = session_data
request.state.session_id = session_id
response = await call_next(request)
# Persistance de la session modifiée
if hasattr(request.state, "session") and request.state.session:
sid = session_id or secrets.token_urlsafe(32)
r.setex(f"session:{sid}", SESSION_TTL, json.dumps(request.state.session))
if not session_id:
response.set_cookie(SESSION_COOKIE, sid, httponly=True, samesite="strict")
return response
JWT auto-porteur#
Le JWT encode lui-même les claims nécessaires (user_id, scopes, tenant). L’instance vérifie la signature cryptographique sans consulter de store externe. C’est le mode de fonctionnement le plus scalable — aucune dépendance externe pour l’authentification. En contrepartie, la révocation avant expiration est complexe (require un store de tokens révoqués, ce qui réintroduit une dépendance).
Connection pooling#
Pools de connexions BDD#
Chaque connexion PostgreSQL consomme ~5-10 MB de mémoire côté serveur. Une instance API qui ouvre une connexion par requête concurrente épuise rapidement les ressources de la base de données. Le connection pool maintient un ensemble de connexions réutilisables.
# Exemple statique : pool asyncpg avec FastAPI
from contextlib import asynccontextmanager
import asyncpg
from fastapi import FastAPI
pool: asyncpg.Pool | None = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global pool
pool = await asyncpg.create_pool(
dsn="postgresql://user:pass@postgres:5432/mydb",
min_size=5, # connexions maintenues en permanence
max_size=20, # maximum de connexions simultanées
command_timeout=10,
max_inactive_connection_lifetime=300, # ferme les connexions inactives
)
yield
await pool.close()
app = FastAPI(lifespan=lifespan)
@app.get("/users/{user_id}")
async def get_user(user_id: str):
async with pool.acquire() as conn: # emprunte une connexion du pool
row = await conn.fetchrow("SELECT * FROM users WHERE id = $1", user_id)
return dict(row) if row else None
HTTP connection reuse avec httpx#
Pour les appels sortants vers d’autres services, maintenir un client HTTP persistant (avec keep-alive) réduit considérablement la latence en évitant la poignée de main TCP/TLS à chaque requête.
# Exemple statique : client httpx partagé entre requêtes
from contextlib import asynccontextmanager
import httpx
http_client: httpx.AsyncClient | None = None
@asynccontextmanager
async def lifespan(app):
global http_client
http_client = httpx.AsyncClient(
limits=httpx.Limits(max_connections=100, max_keepalive_connections=20),
timeout=httpx.Timeout(connect=2.0, read=10.0, write=5.0, pool=5.0),
)
yield
await http_client.aclose()
Limites des pools#
Un pool de taille 20 sur une instance API signifie que 20 requêtes au maximum peuvent interroger la base de données simultanément — les autres attendent. Sous charge, cela se manifeste par une latence en queue (p99) qui décolle bien avant que le p50 ne soit affecté. PgBouncer (pooler externe pour PostgreSQL) permet de multiplexer des milliers de connexions applicatives sur quelques dizaines de connexions réelles à PostgreSQL.
Back-pressure#
Le problème du slow consumer#
Si le producteur (arrivée de requêtes) est plus rapide que le consommateur (traitement), le système accumule des requêtes en attente. Sans mécanisme de back-pressure, les buffers croissent indéfiniment jusqu’à épuisement de la mémoire (OOM) ou dégradation catastrophique des latences.
Queue bornée#
La solution est une queue bornée (bounded queue) : dès que la file d’attente atteint sa capacité maximale, les nouvelles requêtes sont rejetées immédiatement avec 503 Service Unavailable plutôt que d’être mises en attente indéfiniment. C’est le principe de fail fast : mieux vaut rejeter rapidement que de promettre un service dont la latence sera inacceptable.
# Exemple statique : middleware de back-pressure avec queue bornée
import asyncio
from fastapi import FastAPI, Request, HTTPException
app = FastAPI()
semaphore = asyncio.Semaphore(50) # 50 requêtes concurrentes max
@app.middleware("http")
async def backpressure_middleware(request: Request, call_next):
acquired = semaphore.locked() or semaphore._value == 0
try:
# Tenter d'acquérir sans attendre
acquired = await asyncio.wait_for(semaphore.acquire(), timeout=0.1)
except asyncio.TimeoutError:
# Queue pleine : rejeter immédiatement
raise HTTPException(
status_code=503,
detail="Service temporairement saturé",
headers={"Retry-After": "5"},
)
try:
response = await call_next(request)
return response
finally:
semaphore.release()
Graceful degradation#
Feature toggles#
Les feature toggles permettent de désactiver des fonctionnalités non-critiques sous charge ou en cas de défaillance d’un service dépendant, sans déployer de nouveau code.
# Exemple statique : graceful degradation avec fallback et feature flag
import httpx
from fastapi import FastAPI
app = FastAPI()
FEATURES = {
"recommendations": True,
"personalization": True,
"analytics_events": True,
}
@app.get("/feed/{user_id}")
async def get_feed(user_id: str):
feed_items = await get_core_feed(user_id) # critique, pas de fallback
# Recommandations : non-critique, fallback sur liste vide
recommendations = []
if FEATURES["recommendations"]:
try:
async with httpx.AsyncClient(timeout=2.0) as client:
resp = await client.get(f"http://reco-svc/recommend/{user_id}")
recommendations = resp.json().get("items", [])
except (httpx.RequestError, httpx.TimeoutException):
# Dégradation gracieuse : on continue sans les recommandations
FEATURES["recommendations"] = False # circuit ouvert temporairement
pass
return {"feed": feed_items, "recommendations": recommendations}
Multi-Status#
Quand une requête agrège plusieurs ressources et que certaines échouent, le code 207 Multi-Status permet de retourner un succès partiel plutôt qu’un échec global.
# Exemple statique : réponse 207 Multi-Status pour l'agrégation partielle
from fastapi import FastAPI
from fastapi.responses import JSONResponse
@app.get("/batch/users")
async def batch_get_users(ids: list[str]):
results = []
for uid in ids:
try:
user = await fetch_user(uid)
results.append({"id": uid, "status": 200, "data": user})
except UserNotFoundError:
results.append({"id": uid, "status": 404, "error": "not_found"})
except Exception as e:
results.append({"id": uid, "status": 500, "error": str(e)})
# 207 si au moins un succès et au moins un échec
has_success = any(r["status"] < 300 for r in results)
has_error = any(r["status"] >= 300 for r in results)
status_code = 207 if (has_success and has_error) else results[0]["status"]
return JSONResponse(status_code=status_code, content={"results": results})
Timeout hiérarchique#
Deadline propagation#
Dans une chaîne d’appels A → B → C, chaque service impose son propre timeout. Si A accorde 10s à B, et B accorde 8s à C, la deadline se propage en décroissant. Si C n’a plus que 50ms devant lui, il ne vaut pas la peine qu’il lance une requête vers une base de données qui prend 200ms — il doit retourner une erreur immédiatement.
gRPC implémente les deadlines nativement ; en HTTP on peut propager via un header custom (X-Request-Deadline) ou le header standard Request-Timeout (RFC 9110).
# Exemple statique : propagation de deadline avec httpx
import time
from fastapi import FastAPI, Request
app = FastAPI()
@app.get("/service-b/{resource_id}")
async def service_b(resource_id: str, request: Request):
# Lire la deadline propagée par le service appelant
deadline_header = request.headers.get("X-Request-Deadline")
remaining_ms = None
if deadline_header:
deadline_ts = float(deadline_header)
remaining_ms = max(0, (deadline_ts - time.time()) * 1000)
if remaining_ms < 50: # moins de 50ms : échouer immédiatement
return {"error": "deadline_exceeded", "remaining_ms": remaining_ms}, 504
# Propager la deadline aux services en aval
timeout = min(remaining_ms / 1000 if remaining_ms else 5.0, 5.0)
headers = {"X-Request-Deadline": deadline_header} if deadline_header else {}
async with httpx.AsyncClient(timeout=timeout) as client:
resp = await client.get(
f"http://service-c/{resource_id}",
headers=headers,
)
return resp.json()
Important
Un timeout absent (timeout=None dans httpx) est un défaut de conception courant. Sans timeout, une connexion vers un service lent peut rester ouverte indéfiniment, épuisant le pool de connexions et cascadant les défaillances vers tous les services en amont.
Canary releases pour les APIs#
Routing progressif#
Une canary release expose une nouvelle version de l’API à un sous-ensemble du trafic, progressivement. On commence à 1%, on surveille les métriques d’erreur et de latence, on monte à 5%, 10%, 50%, 100%.
Le routing peut être basé sur :
Un header spécifique (
X-Canary: true) — pour les tests internesL’identifiant utilisateur (hash modulo N) — pour une exposition déterministe
La géographie — déploiement région par région
Le plan commercial — nouveautés d’abord pour les comptes entreprise
Feature flags et A/B testing d’API#
Les feature flags permettent d’activer un comportement différent pour un sous-ensemble d’utilisateurs sans déploiement. Un A/B test d’API peut comparer deux algorithmes de recommandation en routant 50% du trafic vers chacun et en mesurant les métriques métier (taux de conversion, engagement).
Rollback#
La force de la canary release est la facilité de rollback : ramener le pourcentage à 0% est immédiat. Si la v2 montre un taux d’erreur 3× supérieur à la v1, le rollback se fait en quelques secondes, affectant au maximum le pourcentage de trafic exposé à ce moment.
Horizontal scaling#
Scaling stateless#
Une instance stateless peut être multipliée sans coordination : 10 instances derrière un load balancer ont une capacité 10× supérieure à une instance seule. Le load balancer distribue le trafic selon la stratégie configurée (round-robin, least-connections).
Les métriques de scaling automatique (autoscaling) : CPU, mémoire, nombre de requêtes concurrentes, profondeur de la queue. Kubernetes HPA (Horizontal Pod Autoscaler) peut scaler sur des métriques custom exposées via Prometheus.
Session affinity : quand elle est inévitable#
Certains cas d’usage nécessitent que le même client soit toujours routé vers la même instance : upload multipart en plusieurs requêtes, WebSocket, connexions SSE longue durée. Le load balancer peut assurer cette affinité via un cookie d’affinité ou le hash de l’IP source — mais c’est une exception, pas la règle.
Distributed rate limiting#
Avec plusieurs instances, un rate limiter in-process ne voit qu’une fraction du trafic. Un utilisateur peut contourner la limite en envoyant des requêtes simultanées sur plusieurs instances. Le rate limiting distribué centralise les compteurs dans Redis — toutes les instances partagent le même état.
Note
Redis lui-même doit être hautement disponible pour ne pas devenir un point de défaillance unique du rate limiting. En cas d’indisponibilité de Redis, la stratégie dégradée est soit d’accepter toutes les requêtes (permissive) soit de les rejeter toutes (restrictive). Le choix dépend du contexte de sécurité.
Chaos engineering pour les APIs#
Injection de latence et d’erreurs#
Le chaos engineering consiste à introduire intentionnellement des défaillances dans le système pour tester sa résilience. Pour les APIs :
Injection de latence : ajouter 200ms sur 10% des requêtes vers le service « products » — est-ce que le BFF se dégrade gracieusement ?
Injection d’erreurs : retourner
503sur 5% des appels au service « payments » — est-ce que le circuit breaker s’ouvre correctement ?Kill pod : tuer aléatoirement des instances — est-ce que le routing bascule sans erreurs pour les clients ?
Tests de résilience#
Les tests de chaos se font en production (avec précautions) ou dans un environnement de staging répliqué. Outils courants : Chaos Monkey (Netflix), Litmus (Kubernetes), Gremlin. La discipline requiert de définir les « steady state hypotheses » — les métriques qui indiquent que le système est sain — et de vérifier qu’elles tiennent sous chaos.
Simulations et visualisations#
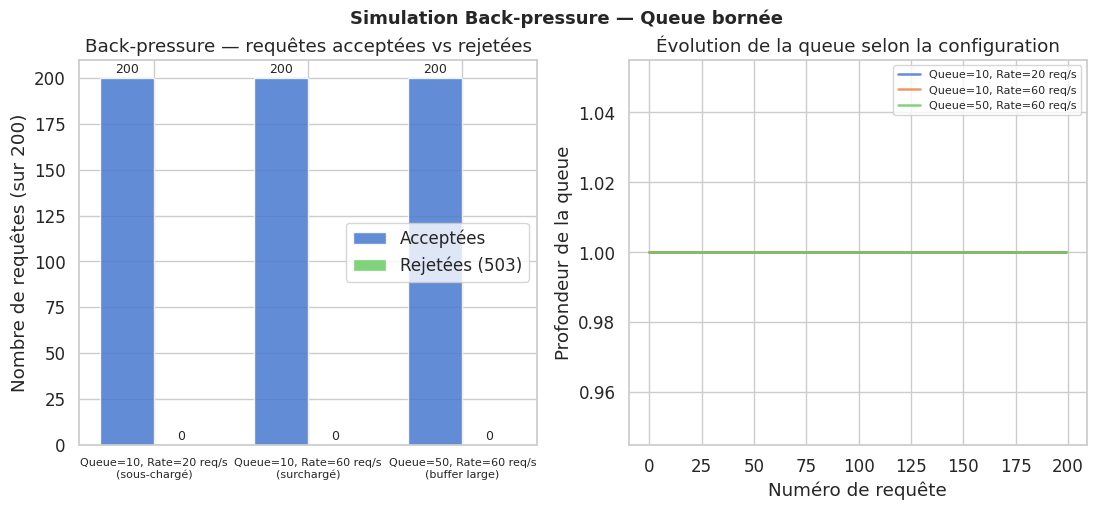
Simulation back-pressure avec queue bornée#
import threading
import queue
import time
import random
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
class BackpressureSystem:
def __init__(self, queue_size: int, processing_time_ms: float, n_workers: int):
self.q = queue.Queue(maxsize=queue_size)
self.processing_time = processing_time_ms / 1000
self.n_workers = n_workers
self.accepted = 0
self.rejected = 0
self.processed = 0
self.queue_depths: list[int] = []
self.lock = threading.Lock()
self._running = True
def worker(self):
while self._running:
try:
item = self.q.get(timeout=0.1)
time.sleep(self.processing_time * (1 + random.uniform(-0.2, 0.2)))
with self.lock:
self.processed += 1
self.q.task_done()
except queue.Empty:
continue
def produce(self, n_requests: int, arrival_rate: float):
"""Envoie n_requests à un taux de arrival_rate req/s."""
interval = 1.0 / arrival_rate
for _ in range(n_requests):
try:
self.q.put_nowait(1) # non-bloquant
with self.lock:
self.accepted += 1
except queue.Full:
with self.lock:
self.rejected += 1
self.queue_depths.append(self.q.qsize())
time.sleep(interval)
def run(self, n_requests: int, arrival_rate: float) -> dict:
workers = [threading.Thread(target=self.worker, daemon=True)
for _ in range(self.n_workers)]
for w in workers:
w.start()
self.produce(n_requests, arrival_rate)
self._running = False
return {
"accepted": self.accepted,
"rejected": self.rejected,
"processed": self.processed,
"queue_depths": self.queue_depths,
}
# Scénarios : queue petite vs grande, sous-chargé vs surchargé
configs = [
{"name": "Queue=10, Rate=20 req/s\n(sous-chargé)", "qs": 10, "rate": 20},
{"name": "Queue=10, Rate=60 req/s\n(surchargé)", "qs": 10, "rate": 60},
{"name": "Queue=50, Rate=60 req/s\n(buffer large)", "qs": 50, "rate": 60},
]
results = []
for cfg in configs:
sys = BackpressureSystem(queue_size=cfg["qs"],
processing_time_ms=30,
n_workers=8)
r = sys.run(n_requests=200, arrival_rate=cfg["rate"])
r["name"] = cfg["name"]
results.append(r)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
colors = sns.color_palette("muted", 3)
# Graphique 1 : acceptées vs rejetées
x = np.arange(len(results))
width = 0.35
acc = [r["accepted"] for r in results]
rej = [r["rejected"] for r in results]
bars1 = axes[0].bar(x - width/2, acc, width, label="Acceptées", color=colors[0], alpha=0.85)
bars2 = axes[0].bar(x + width/2, rej, width, label="Rejetées (503)", color=colors[2], alpha=0.85)
axes[0].set_xticks(x)
axes[0].set_xticklabels([r["name"] for r in results], fontsize=8)
axes[0].set_ylabel("Nombre de requêtes (sur 200)")
axes[0].set_title("Back-pressure — requêtes acceptées vs rejetées")
axes[0].legend()
for bar, val in zip(bars1, acc):
axes[0].text(bar.get_x() + bar.get_width()/2, val + 1, str(val),
ha="center", va="bottom", fontsize=9)
for bar, val in zip(bars2, rej):
axes[0].text(bar.get_x() + bar.get_width()/2, val + 1, str(val),
ha="center", va="bottom", fontsize=9)
# Graphique 2 : évolution de la profondeur de la queue pour le cas surchargé
for i, r in enumerate(results):
axes[1].plot(r["queue_depths"], label=r["name"].split("\n")[0],
color=colors[i], linewidth=1.8, alpha=0.85)
axes[1].set_xlabel("Numéro de requête")
axes[1].set_ylabel("Profondeur de la queue")
axes[1].set_title("Évolution de la queue selon la configuration")
axes[1].legend(fontsize=8)
plt.suptitle("Simulation Back-pressure — Queue bornée", fontsize=13, fontweight="bold")
plt.show()
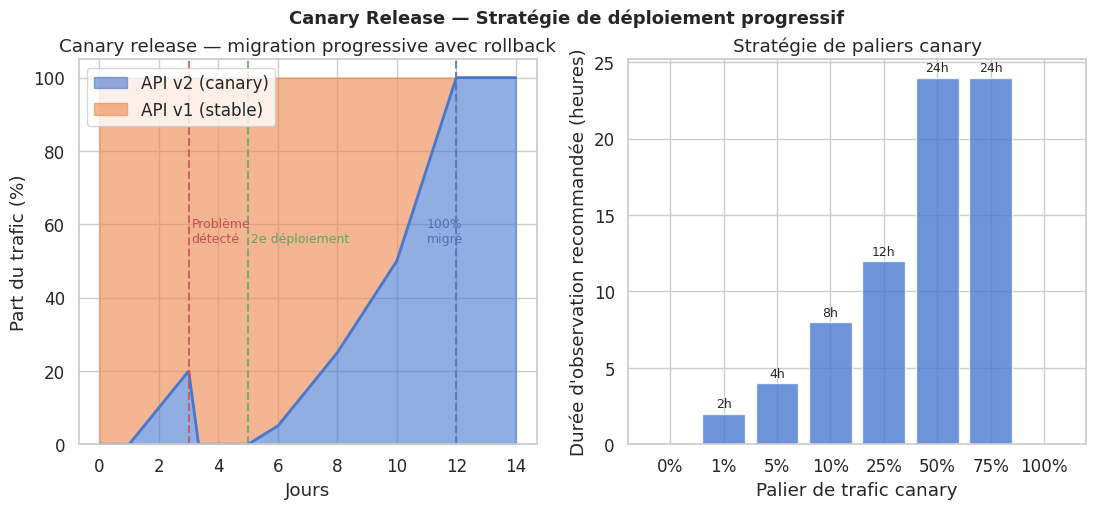
Modélisation d’une canary release progressive#
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Modélisation d'un déploiement canary sur 7 jours
# avec détection d'un problème au jour 3 et rollback, puis second déploiement
days = np.linspace(0, 14, 500)
def canary_curve(t: np.ndarray, start: float, end: float,
t_start: float, t_end: float,
rollback_at: float | None = None,
rollback_speed: float = 1.0) -> np.ndarray:
"""Courbe de migration progressive avec rollback optionnel."""
result = np.zeros_like(t)
for i, ti in enumerate(t):
if ti < t_start:
result[i] = start
elif rollback_at and ti >= rollback_at:
# Rollback : retour rapide vers start
elapsed = ti - rollback_at
result[i] = max(start, result[i-1] - rollback_speed * elapsed / len(t) * 100)
elif ti <= t_end:
progress = (ti - t_start) / (t_end - t_start)
result[i] = start + (end - start) * progress
else:
result[i] = end
return result
# Déploiement 1 : rollback au jour 3
v2_traffic_with_rollback = np.zeros(len(days))
for i, d in enumerate(days):
if d < 1:
v2_traffic_with_rollback[i] = 0
elif d < 3:
v2_traffic_with_rollback[i] = min(20, (d - 1) * 10) # monte à 20%
elif d < 4:
v2_traffic_with_rollback[i] = max(0, 20 - (d - 3) * 60) # rollback rapide
else:
v2_traffic_with_rollback[i] = 0
# Déploiement 2 : succès, montée progressive
v2_traffic_success = np.zeros(len(days))
for i, d in enumerate(days):
if d < 5:
v2_traffic_success[i] = 0
elif d < 6:
v2_traffic_success[i] = (d - 5) * 5 # 0 → 5%
elif d < 8:
v2_traffic_success[i] = 5 + (d - 6) * 10 # 5 → 25%
elif d < 10:
v2_traffic_success[i] = 25 + (d - 8) * 12.5 # 25 → 50%
elif d < 12:
v2_traffic_success[i] = 50 + (d - 10) * 25 # 50 → 100%
else:
v2_traffic_success[i] = 100
v2_total = np.maximum(v2_traffic_with_rollback, v2_traffic_success)
v1_total = 100 - v2_total
colors = sns.color_palette("muted", 4)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# Graphique 1 : évolution du trafic v1/v2
axes[0].fill_between(days, 0, v2_total, alpha=0.6, color=colors[0], label="API v2 (canary)")
axes[0].fill_between(days, v2_total, 100, alpha=0.6, color=colors[1], label="API v1 (stable)")
axes[0].plot(days, v2_total, color=colors[0], linewidth=2)
# Annotations
axes[0].axvline(x=3, color="#C44E52", linestyle="--", linewidth=1.5, alpha=0.8)
axes[0].text(3.1, 55, "Problème\ndétecté", color="#C44E52", fontsize=9)
axes[0].axvline(x=5, color="#55A868", linestyle="--", linewidth=1.5, alpha=0.8)
axes[0].text(5.1, 55, "2e déploiement", color="#55A868", fontsize=9)
axes[0].axvline(x=12, color="#4C72B0", linestyle="--", linewidth=1.5, alpha=0.8)
axes[0].text(11.0, 55, "100%\nmigré", color="#4C72B0", fontsize=9)
axes[0].set_xlabel("Jours")
axes[0].set_ylabel("Part du trafic (%)")
axes[0].set_title("Canary release — migration progressive avec rollback")
axes[0].set_ylim(0, 105)
axes[0].legend(loc="upper left")
# Graphique 2 : paliers de déploiement recommandés
checkpoints = [0, 1, 5, 10, 25, 50, 75, 100]
wait_hours = [0, 2, 4, 8, 12, 24, 24, 0] # attente recommandée à chaque palier
bar_colors = [colors[0]] * len(checkpoints)
axes[1].bar(range(len(checkpoints)), wait_hours, color=bar_colors, alpha=0.8,
tick_label=[f"{c}%" for c in checkpoints])
axes[1].set_xlabel("Palier de trafic canary")
axes[1].set_ylabel("Durée d'observation recommandée (heures)")
axes[1].set_title("Stratégie de paliers canary")
for i, h in enumerate(wait_hours):
if h > 0:
axes[1].text(i, h + 0.2, f"{h}h", ha="center", va="bottom", fontsize=9)
plt.suptitle("Canary Release — Stratégie de déploiement progressif",
fontsize=13, fontweight="bold")
plt.show()
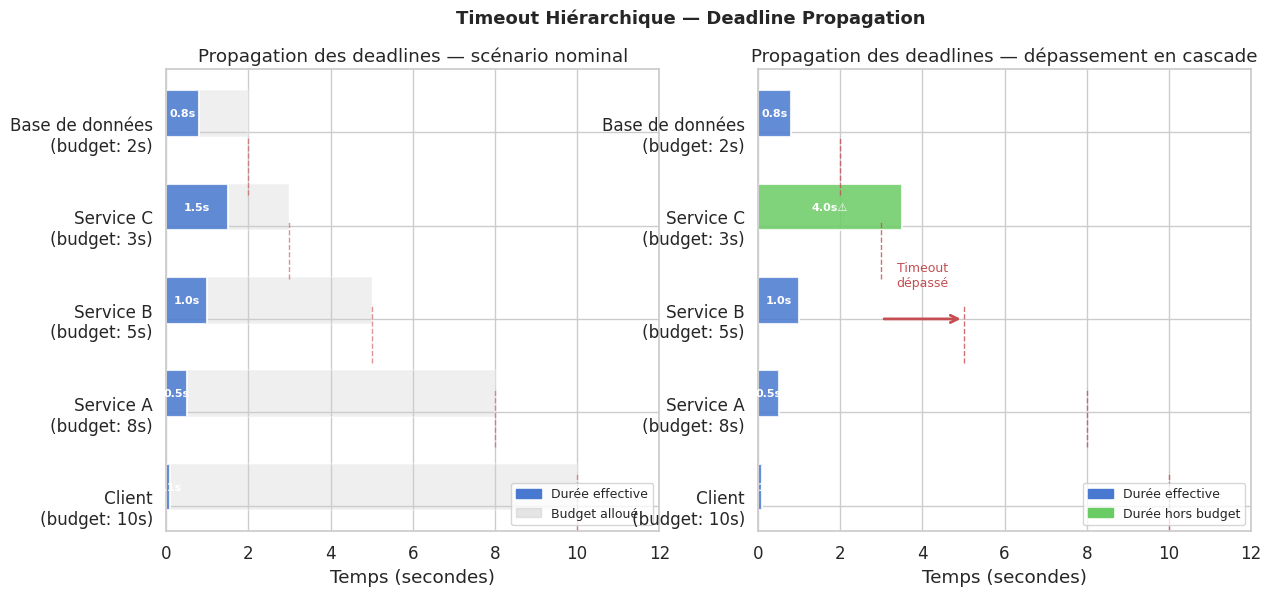
Simulation de l’impact des timeouts hiérarchiques#
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Graphique 1 : diagramme de propagation des délais (Gantt simplifié)
# Scenario : Client → A (10s) → B (5s) → C (3s) → DB (2s)
# Avec un service C qui prend 4s (dépasse son budget de 3s)
def draw_gantt_bar(ax, y, x_start, x_end, label, color, alpha=0.85):
ax.barh(y, x_end - x_start, left=x_start, height=0.5,
color=color, alpha=alpha, edgecolor="white", linewidth=1.5)
ax.text((x_start + x_end) / 2, y, label, ha="center", va="center",
color="white", fontsize=8, fontweight="bold")
colors = sns.color_palette("muted", 6)
# Scénario normal : tout dans les temps
services = ["Client", "Service A", "Service B", "Service C", "Base de données"]
budgets = [10, 8, 5, 3, 2] # budgets en secondes
actuals_ok = [0.1, 0.5, 1.0, 1.5, 0.8] # durées effectives normales
for i, (svc, budget, actual) in enumerate(zip(services, budgets, actuals_ok)):
# Budget total
draw_gantt_bar(axes[0], i + 0.2, 0, budget, "", "#cccccc", alpha=0.3)
# Temps effectif
draw_gantt_bar(axes[0], i + 0.2, 0, actual, f"{actual:.1f}s", colors[0])
# Ligne de timeout
axes[0].axvline(x=budget, ymin=(i)/5.5, ymax=(i+0.7)/5.5,
color="#C44E52", linestyle="--", linewidth=1, alpha=0.6)
axes[0].set_yticks(range(len(services)))
axes[0].set_yticklabels([f"{s}\n(budget: {b}s)" for s, b in zip(services, budgets)])
axes[0].set_xlabel("Temps (secondes)")
axes[0].set_title("Propagation des deadlines — scénario nominal")
axes[0].set_xlim(0, 12)
# Légende
patch_ok = mpatches.Patch(color=colors[0], label="Durée effective")
patch_lim = mpatches.Patch(color="#cccccc", alpha=0.5, label="Budget alloué")
axes[0].legend(handles=[patch_ok, patch_lim], loc="lower right", fontsize=9)
# Scénario de dépassement : Service C prend 4s au lieu de 3s max
actuals_fail = [0.1, 0.5, 1.0, 4.0, 0.8] # C dépasse son budget
for i, (svc, budget, actual) in enumerate(zip(services, budgets, actuals_fail)):
is_over = actual > budget
draw_gantt_bar(axes[1], i + 0.2, 0, min(actual, budget + 0.5),
f"{actual:.1f}s{'⚠' if is_over else ''}",
colors[2] if is_over else colors[0])
axes[1].axvline(x=budget, ymin=(i)/5.5, ymax=(i+0.7)/5.5,
color="#C44E52", linestyle="--", linewidth=1, alpha=0.8)
axes[1].set_yticks(range(len(services)))
axes[1].set_yticklabels([f"{s}\n(budget: {b}s)" for s, b in zip(services, budgets)])
axes[1].set_xlabel("Temps (secondes)")
axes[1].set_title("Propagation des deadlines — dépassement en cascade")
axes[1].set_xlim(0, 12)
# Flèche indiquant le dépassement
axes[1].annotate("", xy=(5, 2), xytext=(3, 2),
arrowprops=dict(arrowstyle="->", color="#C44E52", lw=2))
axes[1].text(4, 2.35, "Timeout\ndépassé", color="#C44E52", ha="center", fontsize=9)
patch_fail = mpatches.Patch(color=colors[2], label="Durée hors budget")
axes[1].legend(handles=[patch_ok, patch_fail], loc="lower right", fontsize=9)
plt.suptitle("Timeout Hiérarchique — Deadline Propagation",
fontsize=13, fontweight="bold")
plt.show()
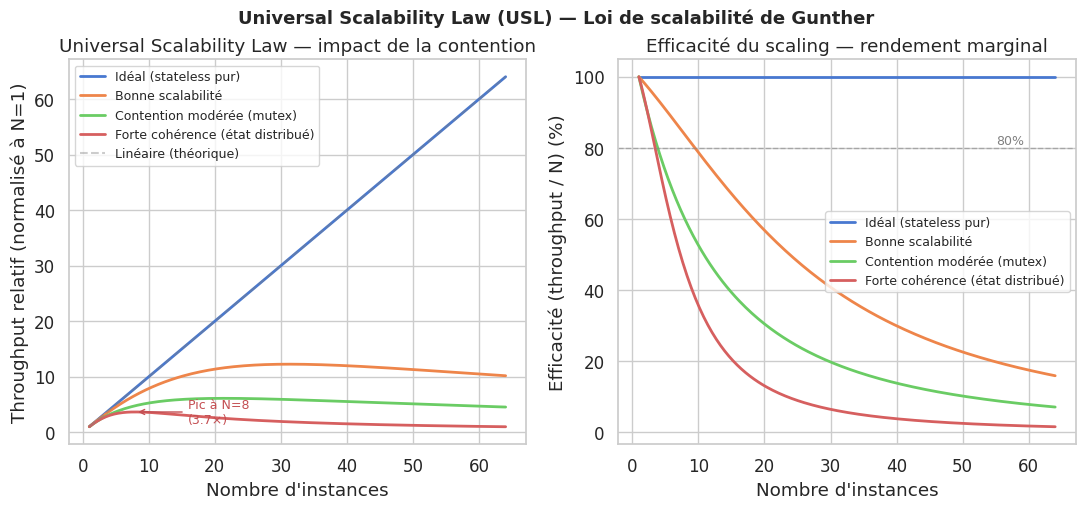
Courbe de scalabilité avec la loi USL de Gunther#
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
def usl(N: np.ndarray, sigma: float, kappa: float) -> np.ndarray:
"""
Universal Scalability Law (Neil Gunther).
N : nombre d'instances/workers
sigma : coefficient de contention (partage de ressources)
kappa : coefficient de cohérence (coordination/synchronisation)
Retourne le throughput relatif (normalisé à N=1).
"""
return N / (1 + sigma * (N - 1) + kappa * N * (N - 1))
N = np.linspace(1, 64, 200)
# Scénarios de scalabilité
scenarios = {
"Idéal (stateless pur)": {"sigma": 0.00, "kappa": 0.000, "color_idx": 0},
"Bonne scalabilité": {"sigma": 0.02, "kappa": 0.001, "color_idx": 1},
"Contention modérée (mutex)": {"sigma": 0.08, "kappa": 0.002, "color_idx": 2},
"Forte cohérence (état distribué)": {"sigma": 0.05, "kappa": 0.015, "color_idx": 3},
}
colors = sns.color_palette("muted", 6)
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# Graphique 1 : throughput relatif
for name, params in scenarios.items():
throughput = usl(N, params["sigma"], params["kappa"])
axes[0].plot(N, throughput, label=name, color=colors[params["color_idx"]], linewidth=2)
# Ligne linéaire idéale
axes[0].plot(N, N / N[0], "--", color="gray", alpha=0.4, linewidth=1.5, label="Linéaire (théorique)")
axes[0].set_xlabel("Nombre d'instances")
axes[0].set_ylabel("Throughput relatif (normalisé à N=1)")
axes[0].set_title("Universal Scalability Law — impact de la contention")
axes[0].legend(fontsize=9, loc="upper left")
# Graphique 2 : efficacité (throughput/N)
for name, params in scenarios.items():
throughput = usl(N, params["sigma"], params["kappa"])
efficiency = throughput / N * 100
axes[1].plot(N, efficiency, label=name, color=colors[params["color_idx"]], linewidth=2)
axes[1].set_xlabel("Nombre d'instances")
axes[1].set_ylabel("Efficacité (throughput / N) (%)")
axes[1].set_title("Efficacité du scaling — rendement marginal")
axes[1].axhline(y=80, color="gray", linestyle="--", linewidth=1, alpha=0.5)
axes[1].text(55, 81, "80%", color="gray", fontsize=9)
axes[1].legend(fontsize=9)
# Annotation du pic pour "forte cohérence"
params = scenarios["Forte cohérence (état distribué)"]
throughput_fc = usl(N, params["sigma"], params["kappa"])
peak_idx = np.argmax(throughput_fc)
peak_n = N[peak_idx]
peak_t = throughput_fc[peak_idx]
axes[0].annotate(
f"Pic à N={peak_n:.0f}\n({peak_t:.1f}×)",
xy=(peak_n, peak_t),
xytext=(peak_n + 8, peak_t - 2),
arrowprops=dict(arrowstyle="->", color="#C44E52"),
color="#C44E52", fontsize=9,
)
plt.suptitle("Universal Scalability Law (USL) — Loi de scalabilité de Gunther",
fontsize=13, fontweight="bold")
plt.show()
Résumé#
La scalabilité d’une API repose sur quelques principes fondamentaux. Le stateless est la condition préalable : toute l’intelligence de session est externalisée dans Redis ou portée dans le JWT, de sorte que n’importe quelle instance peut traiter n’importe quelle requête. Le connection pooling évite l’épuisement des ressources base de données en multiplexant les connexions. La back-pressure protège le système de l’engorgement en rejetant rapidement plutôt qu’en accumulant des requêtes en attente.
La dégradation gracieuse — feature toggles, fallbacks, 207 Multi-Status — maintient un service partiel quand des dépendances tombent. La propagation de deadlines évite les timeouts cascadants en terminant les appels dès que le budget temps est dépassé. Les canary releases limitent l’exposition au risque lors des déploiements grâce à une migration progressive et un rollback en quelques secondes.
La loi USL de Gunther modélise les limites du scaling horizontal : la contention (ressources partagées avec mutex) et la cohérence (coordination inter-instances) réduisent le rendement marginal de chaque instance ajoutée. L’objectif architectural est de minimiser sigma (contention) et kappa (cohérence) pour que le throughput croisse aussi linéairement que possible avec le nombre d’instances.