gRPC avancé#
Le livre « Réseaux et protocoles » de cette collection couvre les bases de gRPC : Protocol Buffers, appels unaires, génération de code. Ce chapitre approfondit les aspects de conception et de production : les quatre modes de streaming, les interceptors, le health checking, la reflection, le transcoding REST↔gRPC, gRPC-Web et la gestion des erreurs. L’objectif est de passer d’une démo fonctionnelle à un service gRPC prêt pour la production.
Rappel Protocol Buffers#
Messages et champs#
Un fichier .proto définit des messages (structures de données) et des services (interfaces RPC). Chaque champ a un nom, un type et un numéro de champ (field number) unique au sein du message.
syntax = "proto3";
package blog.v1;
option go_package = "github.com/example/blog/proto/v1";
message User {
string id = 1;
string username = 2;
string email = 3;
int32 age = 4;
bool is_active = 5;
repeated string roles = 6; // liste
map<string, string> metadata = 7; // dictionnaire
google.protobuf.Timestamp created_at = 8;
}
message Post {
string id = 1;
string title = 2;
string content = 3;
string author_id = 4;
PostStatus status = 5;
repeated string tags = 6;
}
enum PostStatus {
POST_STATUS_UNSPECIFIED = 0; // valeur zéro obligatoire en proto3
POST_STATUS_DRAFT = 1;
POST_STATUS_PUBLISHED = 2;
POST_STATUS_ARCHIVED = 3;
}
Wire format et field numbers#
Le wire format de Protocol Buffers est un encodage binaire compact. Chaque champ est encodé comme un tag (field number + wire type) suivi de la valeur.
Les entiers utilisent l’encodage varint (variable-length integer) : les petites valeurs occupent peu d’octets.
Les strings et bytes utilisent le wire type length-delimited.
Les field numbers sont critiques : ils ne changent jamais une fois déployés.
Évolution de schéma#
Protocol Buffers est conçu pour l’évolution :
Ajouter un champ : toujours compatible. Les anciens clients ignorent les nouveaux champs (unknown fields).
Supprimer un champ : utiliser
reservedpour éviter la réutilisation accidentelle du numéro.Changer un type : dangereux.
int32→int64est compatible sur le wire mais passtring→int32.
message OldMessage {
reserved 3, 4; // field numbers réservés
reserved "old_field"; // noms réservés
string id = 1;
string name = 2;
// champ 3 supprimé, champ 4 supprimé
string new_field = 5; // ajout compatible
}
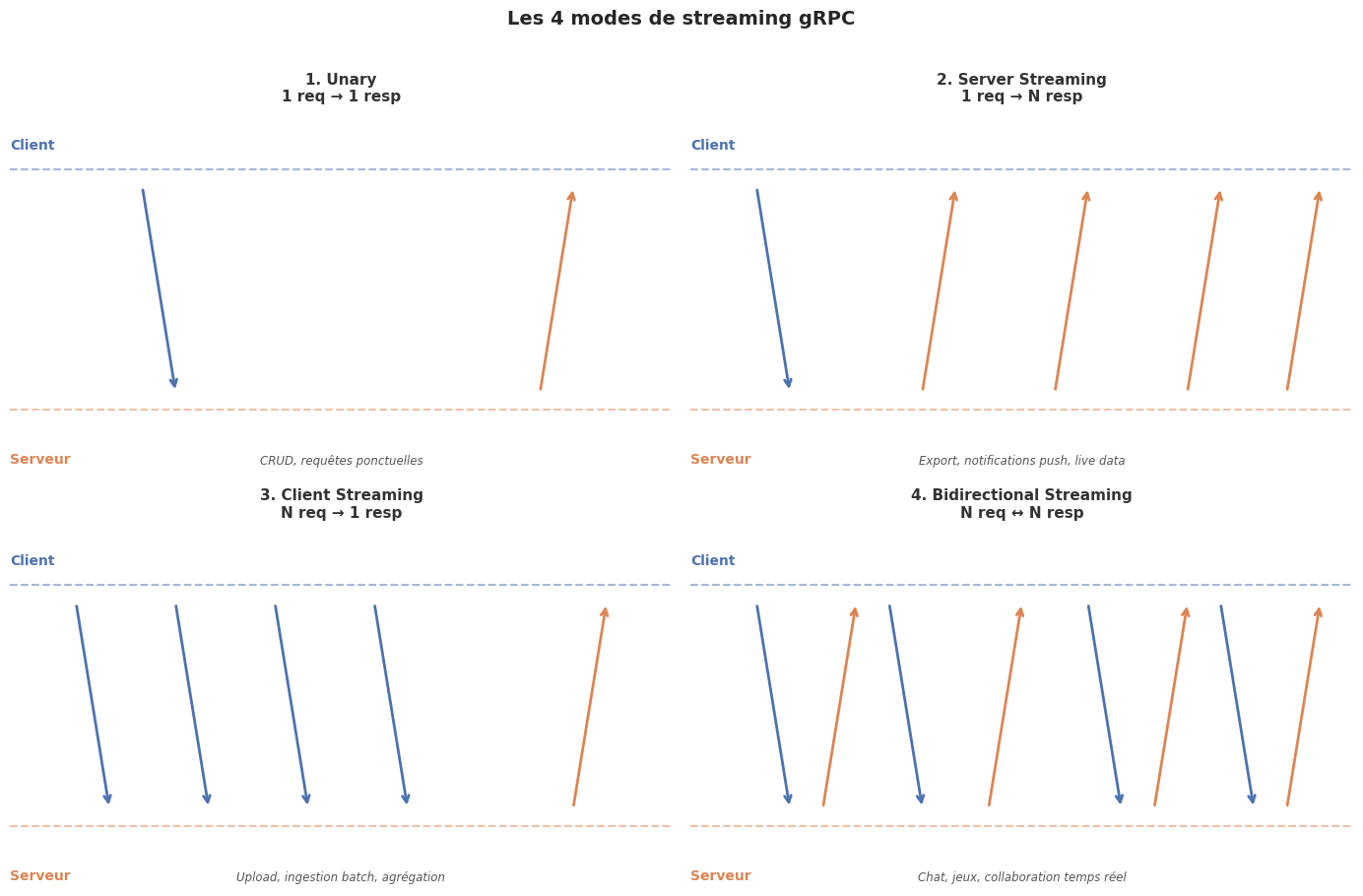
Les 4 modes de streaming gRPC#
gRPC supporte quatre modes d’appel, tous définis dans le fichier .proto :
service BlogService {
// 1. Unary : un message de requête, un message de réponse
rpc GetPost(GetPostRequest) returns (Post);
// 2. Server Streaming : un message de requête, flux de réponses
rpc ListPosts(ListPostsRequest) returns (stream Post);
// 3. Client Streaming : flux de requêtes, un message de réponse
rpc BulkCreatePosts(stream CreatePostRequest) returns (BulkCreateResponse);
// 4. Bidirectional Streaming : flux de requêtes et de réponses simultanés
rpc Chat(stream ChatMessage) returns (stream ChatMessage);
}
Unary — cas d’usage#
Le mode le plus simple et le plus courant. Équivalent d’un appel REST classique. À privilégier pour les opérations CRUD simples, les requêtes ponctuelles.
Server Streaming — cas d’usage#
Le client envoie une requête unique et reçoit un flux de réponses. Idéal pour :
Exporter un grand dataset (évite de charger tout en mémoire).
Streamer des résultats de recherche au fur et à mesure.
Notifications push du serveur vers un client spécifique.
import grpc
from blog_pb2 import ListPostsRequest
from blog_pb2_grpc import BlogServiceStub
def stream_posts(stub: BlogServiceStub):
request = ListPostsRequest(author_id="42", status="PUBLISHED")
# stream est un itérateur
for post in stub.ListPosts(request):
print(f"Post reçu : {post.title}")
Client Streaming — cas d’usage#
Le client envoie un flux de messages et reçoit une seule réponse finale. Idéal pour :
Ingestion de logs ou d’événements en batch.
Upload de fichiers découpés en chunks.
Agrégation côté serveur (somme, moyenne en temps réel).
def bulk_upload(stub: BlogServiceStub, posts: list):
def generate_requests():
for post_data in posts:
yield CreatePostRequest(
title=post_data["title"],
content=post_data["content"],
)
response = stub.BulkCreatePosts(generate_requests())
print(f"Créés : {response.created_count}, Erreurs : {response.error_count}")
Bidirectional Streaming — cas d’usage#
Les deux parties envoient et reçoivent des flux simultanément. Le protocole applicatif est libre. Idéal pour :
Chat en temps réel.
Jeux multijoueurs (positions, actions).
Traitement de flux audio/vidéo (transcription en temps réel).
Interceptors#
Les interceptors sont l’équivalent gRPC des middlewares HTTP. Ils s’insèrent dans la chaîne d’appel pour ajouter du comportement transversal.
Interceptor serveur — logging et métriques#
import grpc
import time
import logging
from typing import Callable, Any
logger = logging.getLogger(__name__)
class LoggingInterceptor(grpc.ServerInterceptor):
def intercept_service(self, continuation, handler_call_details):
method = handler_call_details.method
start = time.perf_counter()
def wrapper(request, context):
try:
response = continuation(handler_call_details)(request, context)
elapsed = (time.perf_counter() - start) * 1000
logger.info(
"gRPC %s OK | %.1fms | peer=%s",
method, elapsed, context.peer()
)
return response
except Exception as exc:
elapsed = (time.perf_counter() - start) * 1000
logger.error("gRPC %s ERROR | %.1fms | %s", method, elapsed, exc)
raise
return grpc.unary_unary_rpc_method_handler(wrapper)
Interceptor serveur — authentification JWT#
import grpc
import jwt
from functools import wraps
PUBLIC_METHODS = {"/blog.v1.BlogService/GetPost", "/grpc.health.v1.Health/Check"}
class AuthInterceptor(grpc.ServerInterceptor):
def __init__(self, secret_key: str):
self.secret_key = secret_key
def intercept_service(self, continuation, handler_call_details):
method = handler_call_details.method
if method in PUBLIC_METHODS:
return continuation(handler_call_details)
def auth_wrapper(request, context):
metadata = dict(context.invocation_metadata())
token = metadata.get("authorization", "").removeprefix("Bearer ")
if not token:
context.abort(grpc.StatusCode.UNAUTHENTICATED, "Token manquant")
return
try:
payload = jwt.decode(token, self.secret_key, algorithms=["HS256"])
# Injecter l'utilisateur dans le contexte via les métadonnées sortantes
context.set_trailing_metadata([("user-id", payload["sub"])])
except jwt.ExpiredSignatureError:
context.abort(grpc.StatusCode.UNAUTHENTICATED, "Token expiré")
return
except jwt.InvalidTokenError:
context.abort(grpc.StatusCode.UNAUTHENTICATED, "Token invalide")
return
return continuation(handler_call_details)(request, context)
return grpc.unary_unary_rpc_method_handler(auth_wrapper)
# Chaîner les interceptors lors du démarrage du serveur
server = grpc.server(
thread_pool,
interceptors=[
AuthInterceptor(secret_key=settings.JWT_SECRET),
LoggingInterceptor(),
MetricsInterceptor(), # Prometheus counters/histograms
]
)
Interceptor client — retry automatique#
class RetryInterceptor(grpc.UnaryUnaryClientInterceptor):
def __init__(self, max_attempts: int = 3, retryable_codes=None):
self.max_attempts = max_attempts
self.retryable_codes = retryable_codes or {
grpc.StatusCode.UNAVAILABLE,
grpc.StatusCode.DEADLINE_EXCEEDED,
}
def intercept_unary_unary(self, continuation, client_call_details, request):
for attempt in range(self.max_attempts):
response = continuation(client_call_details, request)
if response.exception() is None:
return response
code = response.exception().code()
if code not in self.retryable_codes or attempt == self.max_attempts - 1:
return response
time.sleep(2 ** attempt * 0.1) # backoff exponentiel
return response
Health Checking#
Protocole gRPC Health Checking#
Le protocole officiel (défini dans grpc/health/v1) standardise les vérifications de santé pour les services gRPC. Il est supporté nativement par Kubernetes, Envoy et les load balancers modernes.
// grpc/health/v1/health.proto (extrait)
service Health {
rpc Check(HealthCheckRequest) returns (HealthCheckResponse);
rpc Watch(HealthCheckRequest) returns (stream HealthCheckResponse);
}
message HealthCheckRequest {
string service = 1; // "" = service global, "blog.v1.BlogService" = service spécifique
}
message HealthCheckResponse {
enum ServingStatus {
UNKNOWN = 0;
SERVING = 1;
NOT_SERVING = 2;
SERVICE_UNKNOWN = 3;
}
ServingStatus status = 1;
}
Implémentation Python#
from grpc_health.v1 import health, health_pb2, health_pb2_grpc
from grpc_health.v1.health import HealthServicer
# Créer le servicer de health
health_servicer = health.HealthServicer()
# Enregistrer les statuts initiaux
health_servicer.set("", health_pb2.HealthCheckResponse.SERVING)
health_servicer.set("blog.v1.BlogService", health_pb2.HealthCheckResponse.SERVING)
# Ajouter au serveur gRPC
health_pb2_grpc.add_HealthServicer_to_server(health_servicer, server)
# Mettre à jour dynamiquement selon l'état réel
async def monitor_database():
while True:
try:
await db.execute("SELECT 1")
health_servicer.set(
"blog.v1.BlogService",
health_pb2.HealthCheckResponse.SERVING
)
except Exception:
health_servicer.set(
"blog.v1.BlogService",
health_pb2.HealthCheckResponse.NOT_SERVING
)
await asyncio.sleep(10)
Intégration Kubernetes#
# Liveness probe : redémarre le pod si le service est bloqué
livenessProbe:
grpc:
port: 50051
service: "" # check global
initialDelaySeconds: 10
periodSeconds: 15
# Readiness probe : retire le pod du load balancer s'il n'est pas prêt
readinessProbe:
grpc:
port: 50051
service: "blog.v1.BlogService"
initialDelaySeconds: 5
periodSeconds: 10
Reflection#
Server Reflection#
La reflection gRPC permet aux clients de découvrir le schéma d’un serveur sans avoir accès aux fichiers .proto. C’est l’équivalent de l’introspection GraphQL ou de l’endpoint OpenAPI.
from grpc_reflection.v1alpha import reflection
# Activer la reflection (développement uniquement en général)
SERVICE_NAMES = (
blog_pb2.DESCRIPTOR.services_by_name["BlogService"].full_name,
reflection.SERVICE_NAME, # grpc.reflection.v1alpha.ServerReflection
)
reflection.enable_server_reflection(SERVICE_NAMES, server)
grpcurl — exploration sans proto files#
# Lister les services disponibles
grpcurl -plaintext localhost:50051 list
# Lister les méthodes d'un service
grpcurl -plaintext localhost:50051 list blog.v1.BlogService
# Décrire un type
grpcurl -plaintext localhost:50051 describe blog.v1.Post
# Appel unaire
grpcurl -plaintext -d '{"id": "42"}' localhost:50051 blog.v1.BlogService/GetPost
# Avec authentification
grpcurl -H 'Authorization: Bearer eyJ...' -plaintext \
-d '{"title": "Mon article", "content": "..."}' \
localhost:50051 blog.v1.BlogService/CreatePost
Reflection en production
La reflection expose l’intégralité du schéma et des types. En production, désactiver la reflection ou la protéger derrière une authentification. Utiliser grpcurl avec les fichiers .proto directement : grpcurl -proto blog.proto ...
Transcoding REST↔gRPC#
google.api.http annotations#
Le transcoding permet d’exposer un service gRPC comme une API REST sans réécrire le code métier. Les annotations google.api.http dans le fichier .proto définissent le mapping :
import "google/api/annotations.proto";
service BlogService {
rpc GetPost(GetPostRequest) returns (Post) {
option (google.api.http) = {
get: "/v1/posts/{id}"
};
}
rpc CreatePost(CreatePostRequest) returns (Post) {
option (google.api.http) = {
post: "/v1/posts"
body: "*"
};
}
rpc ListPosts(ListPostsRequest) returns (ListPostsResponse) {
option (google.api.http) = {
get: "/v1/posts"
// Les paramètres de ListPostsRequest deviennent des query params
// ?author_id=42&status=PUBLISHED&page_size=20
};
}
rpc DeletePost(DeletePostRequest) returns (google.protobuf.Empty) {
option (google.api.http) = {
delete: "/v1/posts/{id}"
};
}
}
grpc-gateway#
grpc-gateway est un plugin protoc qui génère un reverse proxy Go qui traduit les requêtes REST en appels gRPC :
Client HTTP → grpc-gateway (proxy) → service gRPC
REST JSON → transcoding → Protocol Buffers
Cas d’usage#
Migration progressive : l’API REST existante continue de fonctionner pendant la migration vers gRPC.
Compatibilité partenaires : les clients externes utilisent REST, les services internes utilisent gRPC.
Environnements sans support gRPC : scripts shell, outils qui ne parlent que HTTP/JSON.
gRPC-Web#
Configuration Envoy#
# envoy.yaml - proxy gRPC-Web vers gRPC
static_resources:
listeners:
- address:
socket_address: { address: 0.0.0.0, port_value: 8080 }
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
http_filters:
- name: envoy.filters.http.grpc_web # traduction gRPC-Web → gRPC
- name: envoy.filters.http.cors
- name: envoy.filters.http.router
route_config:
virtual_hosts:
- routes:
- match: { prefix: "/" }
route:
cluster: grpc_backend
clusters:
- name: grpc_backend
type: LOGICAL_DNS
lb_policy: ROUND_ROBIN
http2_protocol_options: {} # activer HTTP/2 vers le backend
load_assignment:
cluster_name: grpc_backend
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address: { address: grpc-service, port_value: 50051 }
Error model gRPC#
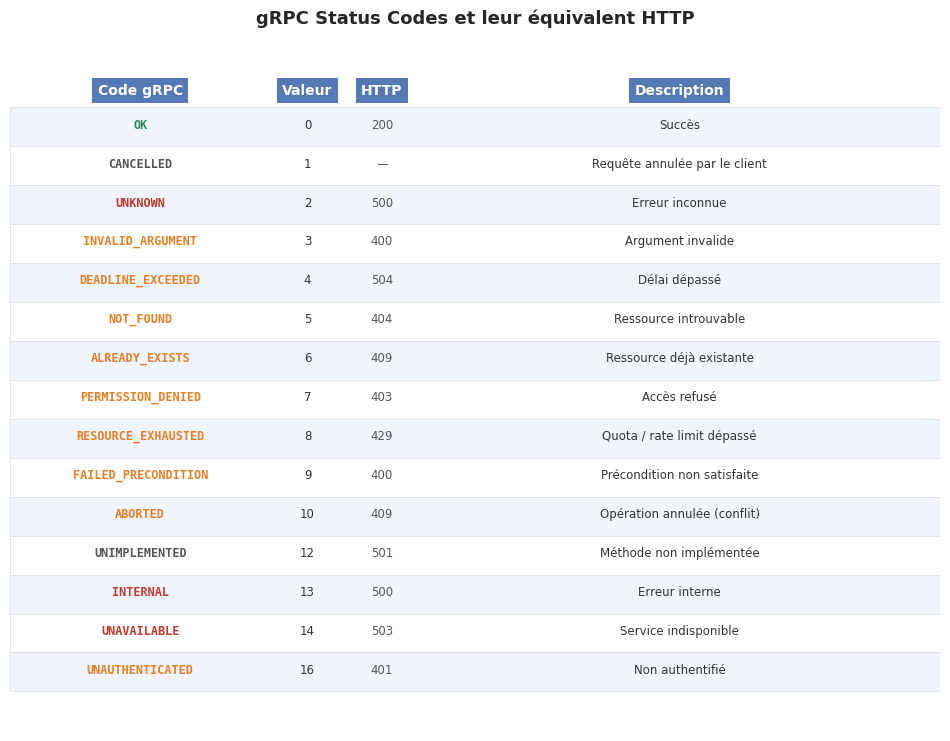
Status codes#
gRPC définit 16 codes de statut standardisés. Chaque code a une sémantique précise :
Code |
Valeur |
Usage |
|---|---|---|
OK |
0 |
Succès |
CANCELLED |
1 |
Requête annulée par le client |
UNKNOWN |
2 |
Erreur interne inconnue |
INVALID_ARGUMENT |
3 |
Argument invalide (erreur client) |
DEADLINE_EXCEEDED |
4 |
Délai dépassé |
NOT_FOUND |
5 |
Ressource introuvable |
ALREADY_EXISTS |
6 |
Ressource déjà existante |
PERMISSION_DENIED |
7 |
Permission refusée |
RESOURCE_EXHAUSTED |
8 |
Quota dépassé |
FAILED_PRECONDITION |
9 |
État du système incompatible |
ABORTED |
10 |
Conflit (transaction) |
UNAUTHENTICATED |
16 |
Non authentifié |
google.rpc.Status et error details#
Pour des erreurs riches avec des détails structurés, gRPC définit google.rpc.Status :
from grpc_status import rpc_status
from google.rpc import status_pb2, error_details_pb2
import grpc
def handle_validation_error(context, field_errors: dict):
"""Retourner une erreur INVALID_ARGUMENT avec des détails par champ."""
detail = error_details_pb2.BadRequest()
for field, description in field_errors.items():
violation = detail.field_violations.add()
violation.field = field
violation.description = description
rich_status = rpc_status.to_status(
status_pb2.Status(
code=grpc.StatusCode.INVALID_ARGUMENT.value[0],
message="Validation échouée",
details=[detail] # PackAny automatique
)
)
context.abort_with_status(rich_status)
# Côté client : décoder les détails
try:
response = stub.CreatePost(request)
except grpc.RpcError as e:
status = rpc_status.from_call(e)
if status:
for detail in status.details:
if detail.Is(error_details_pb2.BadRequest.DESCRIPTOR):
bad_request = error_details_pb2.BadRequest()
detail.Unpack(bad_request)
for violation in bad_request.field_violations:
print(f" {violation.field}: {violation.description}")
Comparaison avec les codes HTTP#
gRPC |
HTTP |
Sémantique |
|---|---|---|
INVALID_ARGUMENT |
400 |
Entrée invalide |
UNAUTHENTICATED |
401 |
Non authentifié |
PERMISSION_DENIED |
403 |
Non autorisé |
NOT_FOUND |
404 |
Introuvable |
ALREADY_EXISTS |
409 |
Conflit |
RESOURCE_EXHAUSTED |
429 |
Rate limit |
INTERNAL |
500 |
Erreur serveur |
UNAVAILABLE |
503 |
Service indisponible |
Performance#
Avantages HTTP/2#
gRPC repose sur HTTP/2, ce qui confère plusieurs avantages de performance :
Multiplexing : plusieurs appels RPC partagent une seule connexion TCP. Pas de head-of-line blocking (comparé à HTTP/1.1 avec connexions multiples).
Compression des en-têtes : HPACK réduit la taille des en-têtes répétitifs.
Binary framing : Protocol Buffers est binaire, plus compact que JSON.
Compression#
# Activer la compression gzip sur le canal
channel = grpc.insecure_channel(
'localhost:50051',
options=[
('grpc.default_compression_algorithm', grpc.Compression.Gzip),
]
)
# Ou par appel
stub.GetPost(
request,
compression=grpc.Compression.Gzip
)
Keepalive et timeouts#
# Configuration keepalive pour les connexions longue durée
channel = grpc.insecure_channel(
'localhost:50051',
options=[
('grpc.keepalive_time_ms', 30000), # ping toutes les 30s
('grpc.keepalive_timeout_ms', 10000), # timeout du ping
('grpc.keepalive_permit_without_calls', True),
('grpc.http2.max_pings_without_data', 0),
]
)
# Timeout par appel
try:
response = stub.GetPost(request, timeout=5.0) # 5 secondes
except grpc.RpcError as e:
if e.code() == grpc.StatusCode.DEADLINE_EXCEEDED:
print("Timeout dépassé")
Cellules Python exécutables#
# Simulation de l'encodage varint Protocol Buffers
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
def encode_varint(value: int) -> list:
"""Encode un entier non signé en varint Protocol Buffers."""
if value < 0:
raise ValueError("encode_varint ne supporte que les entiers non négatifs")
bytes_out = []
while True:
byte = value & 0x7F # 7 bits de données
value >>= 7
if value:
byte |= 0x80 # MSB = 1 : il y a d'autres octets
bytes_out.append(byte)
if not value:
break
return bytes_out
def varint_size(value: int) -> int:
return len(encode_varint(value))
# Comparaison varint vs int32 fixe (4 octets) vs JSON
test_values = [1, 127, 128, 300, 1000, 16383, 16384, 100000, 2**21, 2**28]
sizes_varint = [varint_size(v) for v in test_values]
sizes_int32 = [4] * len(test_values) # int32 fixe = toujours 4 octets
sizes_json = [len(str(v).encode()) for v in test_values]
x = np.arange(len(test_values))
width = 0.28
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Barplot comparaison tailles
bars1 = axes[0].bar(x - width, sizes_varint, width, label='Varint (protobuf)', color='#4C72B0')
bars2 = axes[0].bar(x, sizes_int32, width, label='Int32 fixe', color='#DD8452')
bars3 = axes[0].bar(x + width, sizes_json, width, label='JSON (texte)', color='#55A868')
axes[0].set_xticks(x)
axes[0].set_xticklabels([str(v) for v in test_values], rotation=45, ha='right', fontsize=8)
axes[0].set_ylabel("Taille (octets)")
axes[0].set_title("Encodage varint vs int32 fixe vs JSON")
axes[0].legend()
axes[0].set_ylim(0, 12)
# Visualisation bit à bit pour quelques valeurs
examples = {1: encode_varint(1), 127: encode_varint(127),
128: encode_varint(128), 300: encode_varint(300)}
ax2 = axes[1]
ax2.axis('off')
ax2.set_xlim(0, 10)
ax2.set_ylim(0, 5)
ax2.set_title("Encodage varint détaillé (MSB = continuation bit)", fontsize=11, fontweight='bold')
y_pos = 4.2
for value, encoded in examples.items():
binary_repr = " | ".join(f"0x{b:02X} ({b:08b})" for b in encoded)
ax2.text(0.3, y_pos, f"{value:>7} →", fontsize=9.5, fontweight='bold',
color='#4C72B0', va='center')
ax2.text(3.2, y_pos, binary_repr, fontsize=8.5, va='center',
fontfamily='monospace', color='#333333')
y_pos -= 0.9
ax2.axhline(y=4.65, xmin=0.02, xmax=0.98, color='#cccccc', linewidth=1)
plt.suptitle("Protocol Buffers : wire format varint", fontweight='bold', fontsize=13)
plt.show()
print("Encodages varint :")
for v in [1, 127, 128, 300, 16384]:
encoded = encode_varint(v)
print(f" {v:>6} → {len(encoded)} octet(s) : {[hex(b) for b in encoded]}")
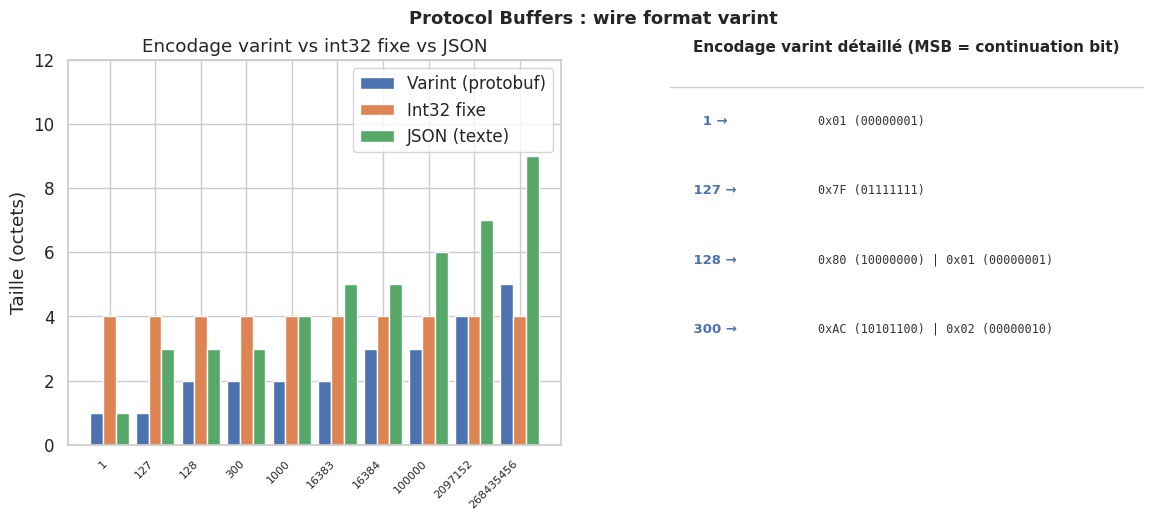
Encodages varint :
1 → 1 octet(s) : ['0x1']
127 → 1 octet(s) : ['0x7f']
128 → 2 octet(s) : ['0x80', '0x1']
300 → 2 octet(s) : ['0xac', '0x2']
16384 → 3 octet(s) : ['0x80', '0x80', '0x1']
# Diagramme des 4 modes de streaming gRPC
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
import numpy as np
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.0)
fig, axes = plt.subplots(2, 2, figsize=(14, 9))
axes = axes.flatten()
modes = [
{
"title": "1. Unary",
"subtitle": "1 req → 1 resp",
"client_msgs": [0.2],
"server_msgs": [0.8],
"use_case": "CRUD, requêtes ponctuelles"
},
{
"title": "2. Server Streaming",
"subtitle": "1 req → N resp",
"client_msgs": [0.1],
"server_msgs": [0.35, 0.55, 0.75, 0.9],
"use_case": "Export, notifications push, live data"
},
{
"title": "3. Client Streaming",
"subtitle": "N req → 1 resp",
"client_msgs": [0.1, 0.25, 0.4, 0.55],
"server_msgs": [0.85],
"use_case": "Upload, ingestion batch, agrégation"
},
{
"title": "4. Bidirectional Streaming",
"subtitle": "N req ↔ N resp",
"client_msgs": [0.1, 0.3, 0.6, 0.8],
"server_msgs": [0.2, 0.45, 0.7, 0.9],
"use_case": "Chat, jeux, collaboration temps réel"
},
]
client_color = "#4C72B0"
server_color = "#DD8452"
for ax, mode in zip(axes, modes):
ax.set_xlim(0, 1)
ax.set_ylim(-0.5, 2.5)
ax.axis('off')
# Lignes de vie
ax.axhline(y=2.0, xmin=0.0, xmax=1.0, color=client_color, linewidth=1.5, linestyle='--', alpha=0.5)
ax.axhline(y=0.0, xmin=0.0, xmax=1.0, color=server_color, linewidth=1.5, linestyle='--', alpha=0.5)
ax.text(0.0, 2.15, "Client", color=client_color, fontweight='bold', fontsize=10, va='bottom')
ax.text(0.0, -0.35, "Serveur", color=server_color, fontweight='bold', fontsize=10, va='top')
arrowprops_c2s = dict(arrowstyle='->', color=client_color, lw=2.0)
arrowprops_s2c = dict(arrowstyle='->', color=server_color, lw=2.0)
for x_pos in mode["client_msgs"]:
ax.annotate("", xy=(x_pos + 0.05, 0.15), xytext=(x_pos, 1.85),
arrowprops=arrowprops_c2s)
for x_pos in mode["server_msgs"]:
ax.annotate("", xy=(x_pos + 0.05, 1.85), xytext=(x_pos, 0.15),
arrowprops=arrowprops_s2c)
ax.set_title(f"{mode['title']}\n{mode['subtitle']}", fontsize=11,
fontweight='bold', color='#333333')
ax.text(0.5, -0.45, mode["use_case"], ha='center', fontsize=8.5,
color='#555555', fontstyle='italic')
plt.suptitle("Les 4 modes de streaming gRPC", fontsize=14, fontweight='bold', y=1.01)
plt.tight_layout()
plt.show()
# Benchmarks simulés : gRPC vs REST vs GraphQL
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
# Données simulées basées sur des benchmarks publics typiques
# (varient fortement selon le réseau, payload, nombre de connexions)
scenarios = ["Unary\n(petits payloads)", "Requêtes\nconcurrentes (×100)", "Gros payloads\n(1MB)"]
# Latence médiane en ms (valeurs représentatives, pas universelles)
latency_grpc = [1.2, 8.5, 42.0]
latency_rest = [2.1, 18.0, 95.0]
latency_graphql = [2.8, 22.0, 98.0]
# Débit en req/s (relatif, normalisé sur gRPC = 100%)
throughput_grpc = [100, 100, 100]
throughput_rest = [58, 52, 45]
throughput_graphql = [50, 44, 43]
x = np.arange(len(scenarios))
width = 0.28
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# Latence
b1 = axes[0].bar(x - width, latency_grpc, width, label='gRPC', color='#4C72B0')
b2 = axes[0].bar(x, latency_rest, width, label='REST/JSON', color='#DD8452')
b3 = axes[0].bar(x + width, latency_graphql, width, label='GraphQL', color='#55A868')
axes[0].set_xticks(x)
axes[0].set_xticklabels(scenarios, fontsize=9.5)
axes[0].set_ylabel("Latence médiane (ms)")
axes[0].set_title("Latence comparée (ms, plus bas = mieux)")
axes[0].legend()
for bars in [b1, b2, b3]:
for bar in bars:
h = bar.get_height()
axes[0].text(bar.get_x() + bar.get_width()/2, h + 0.5,
f"{h}", ha='center', va='bottom', fontsize=8)
# Débit relatif
b4 = axes[1].bar(x - width, throughput_grpc, width, label='gRPC', color='#4C72B0')
b5 = axes[1].bar(x, throughput_rest, width, label='REST/JSON', color='#DD8452')
b6 = axes[1].bar(x + width, throughput_graphql, width, label='GraphQL', color='#55A868')
axes[1].set_xticks(x)
axes[1].set_xticklabels(scenarios, fontsize=9.5)
axes[1].set_ylabel("Débit relatif (gRPC = 100%)")
axes[1].set_title("Débit comparé (%, plus haut = mieux)")
axes[1].set_ylim(0, 125)
axes[1].legend()
axes[1].axhline(y=100, color='#4C72B0', linestyle=':', alpha=0.5)
plt.suptitle("Benchmarks simulés gRPC vs REST vs GraphQL\n(valeurs indicatives — dépendent du contexte)",
fontweight='bold', fontsize=12)
plt.tight_layout()
plt.show()
print("Note : ces chiffres sont représentatifs de tendances générales.")
print("Les écarts réels dépendent du réseau, du hardware, de la taille des payloads.")
print("gRPC excelle surtout en contexte microservices (LAN, connexions persistantes).")
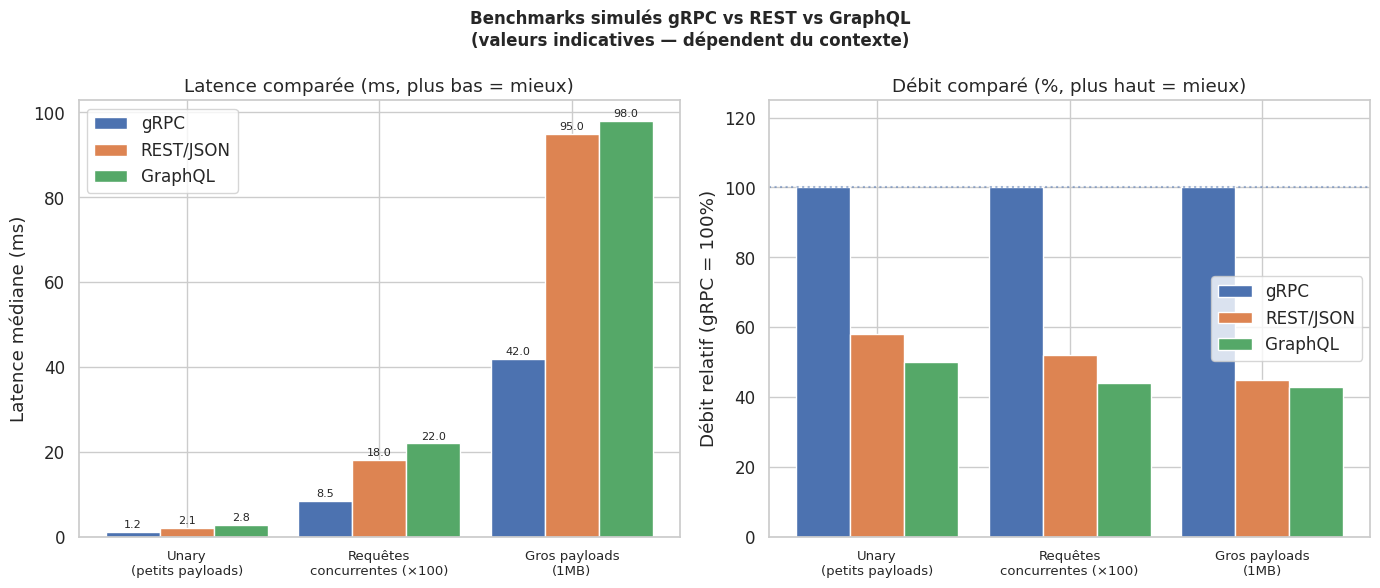
Note : ces chiffres sont représentatifs de tendances générales.
Les écarts réels dépendent du réseau, du hardware, de la taille des payloads.
gRPC excelle surtout en contexte microservices (LAN, connexions persistantes).
# Tableau visuel : gRPC status codes et leur mapping HTTP
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.0)
# (Code gRPC, Valeur, HTTP équivalent, Description)
status_codes = [
("OK", "0", "200", "Succès"),
("CANCELLED", "1", "—", "Requête annulée par le client"),
("UNKNOWN", "2", "500", "Erreur inconnue"),
("INVALID_ARGUMENT", "3", "400", "Argument invalide"),
("DEADLINE_EXCEEDED", "4", "504", "Délai dépassé"),
("NOT_FOUND", "5", "404", "Ressource introuvable"),
("ALREADY_EXISTS", "6", "409", "Ressource déjà existante"),
("PERMISSION_DENIED", "7", "403", "Accès refusé"),
("RESOURCE_EXHAUSTED", "8", "429", "Quota / rate limit dépassé"),
("FAILED_PRECONDITION", "9", "400", "Précondition non satisfaite"),
("ABORTED", "10", "409", "Opération annulée (conflit)"),
("UNIMPLEMENTED", "12", "501", "Méthode non implémentée"),
("INTERNAL", "13", "500", "Erreur interne"),
("UNAVAILABLE", "14", "503", "Service indisponible"),
("UNAUTHENTICATED", "16", "401", "Non authentifié"),
]
fig, ax = plt.subplots(figsize=(12, 9))
ax.axis('off')
col_labels = ["Code gRPC", "Valeur", "HTTP", "Description"]
col_widths = [0.28, 0.08, 0.08, 0.56]
col_starts = [0.0, 0.28, 0.36, 0.44]
# En-tête
for i, (label, x_start) in enumerate(zip(col_labels, col_starts)):
ax.text(x_start + col_widths[i]/2, 1.01, label,
ha='center', va='bottom', fontweight='bold', fontsize=10,
color='white',
bbox=dict(facecolor='#4C72B0', edgecolor='none',
boxstyle='square,pad=0.4', alpha=0.95))
row_height = 0.059
for row_idx, (grpc_code, val, http, desc) in enumerate(status_codes):
y = 1.0 - (row_idx + 1) * row_height
bg_color = '#F0F4FF' if row_idx % 2 == 0 else '#FFFFFF'
# Couleur selon la sémantique
if val == "0":
code_color = '#2d8a4e'
elif http in ("500", "503"):
code_color = '#c0392b'
elif http in ("400", "401", "403", "404", "409", "429", "504"):
code_color = '#e67e22'
else:
code_color = '#555555'
# Fond de ligne
bg_patch = mpatches.FancyBboxPatch(
(0.0, y - 0.005), 1.0, row_height,
boxstyle="square,pad=0", facecolor=bg_color, edgecolor='#dddddd', linewidth=0.5
)
ax.add_patch(bg_patch)
data = [grpc_code, val, http, desc]
colors = [code_color, '#333333', '#555555', '#333333']
weights = ['bold', 'normal', 'normal', 'normal']
for col_idx, (text, x_start, w, c, fw) in enumerate(
zip(data, col_starts, col_widths, colors, weights)):
ax.text(x_start + w/2, y + row_height/2 - 0.002, text,
ha='center', va='center', fontsize=8.5,
color=c, fontweight=fw, fontfamily='monospace' if col_idx == 0 else 'sans-serif')
ax.set_xlim(0, 1)
ax.set_ylim(0.05, 1.1)
ax.set_title("gRPC Status Codes et leur équivalent HTTP",
fontsize=13, fontweight='bold', pad=10)
plt.show()
Résumé#
gRPC est taillé pour la communication inter-services à haute performance. Les quatre modes de streaming couvrent tous les patterns de communication : de l’appel unaire au dialogue bidirectionnel temps réel. Les interceptors permettent d’ajouter logging, authentification, métriques et retry de façon transversale sans toucher au code métier.
Le health checking standardisé s’intègre nativement à Kubernetes. La reflection et grpcurl simplifient le débogage. Le transcoding REST↔gRPC via grpc-gateway permet des migrations progressives et la cohabitation avec des clients HTTP/JSON. gRPC-Web étend gRPC aux navigateurs via un proxy Envoy, avec des limitations de streaming.
La gestion des erreurs avec google.rpc.Status et les error details structurés dépasse les simples codes d’erreur : elle permet de retourner des informations de validation précises par champ. Côté performance, HTTP/2 apporte le multiplexing et la compression des en-têtes — des gains particulièrement visibles sous charge élevée et avec de nombreuses connexions concurrentes.